To understand the complex topics covered on the SAT Subject Test in Biology, you must first have a general understanding of basic building blocks of life—atoms, molecules, compounds—and see how it directly applies to the biological concepts you will learn about.
Atoms are the fundamental units of the physical world. Individual atoms combine in chemical reactions to form molecules.
atom + atom → molecule
H + H → H2
Thus, a molecule is just a combination of atoms. Molecules can also react with other atoms or other molecules to form larger molecules.
If a molecule contains different types of atoms, it is called a compound. For example, CCl4 is a compound because the molecule has both carbon and chlorine in it. On the other hand, H is a molecule but is NOT a compound because the only atoms in the molecule are hydrogen atoms. (If a molecule contains only a single type of atom, it is an element.)
In chemical reactions, the molecules or atoms that are interacting are called reactants and are found on the left side of the arrow. The products (the results of the interactions) are found on the right side of the arrow.
reactants → product
2 H2 + O2 → 2 H2O
Organic chemistry is simply the chemistry of molecules and compounds that contain carbon. Molecules and compounds that contain carbon are said to be organic, whereas molecules that do not contain carbon are said to be inorganic. There’s a single exception to this rule: carbon dioxide (CO2). Even though carbon dioxide contains carbon, it is an inorganic compound.
Biomolecules
Carbon is the main ingredient of organic molecules. Most molecules within a cell, other than water, are carbon based. Therefore, these molecules are sometimes called biomolecules. Carbon is common in living things because it has only four electrons in the highest energy level of the electron shells that surround the nucleus. Carbon can therefore form up to four bonds with other atoms.
Check the appropriate boxes.
1. Water (H2O) is an [☐ organic ☐ inorganic] compound.
2. Cl2 [☐ is ☐ is not] a compound.
3. H2O [☐ is ☐ is not] a compound.
4. Methane (CH4) is an [☐ organic ☐ inorganic] compound.
5. Cl2 [☐ is ☐ is not] a molecule.
6. Carbon dioxide (CO2) is an [☐ organic ☐ inorganic] compound.
7. Products are found on the [☐ right ☐ left] side of the arrow in a chemical reaction.
Correct answers can be found in Part IV.
There are many organic molecules. Fortunately, as far as biology is concerned, there are only four important types of organic molecules. Most of them are very large, and they’re referred to as macromolecules. The four biologically important macromolecules are the only ones you need to worry about for the test.
The four important organic molecules are
proteins
carbohydrates
lipids
nucleic acids
These four macromolecules are polymers. Polymers are strings of repeated units. The individual units of polymers are called monomers. An example you’re probably more familiar with is a string of pearls. Each individual pearl would be a monomer; strung together, the monomers form a polymer: the whole necklace. Let’s take a look at the first biologically important macromolecule: protein.
Proteins are polymers of amino acids. In other words, the monomer that makes up a protein is an amino acid. There are 20 different amino acids, and they all have the same basic structure.
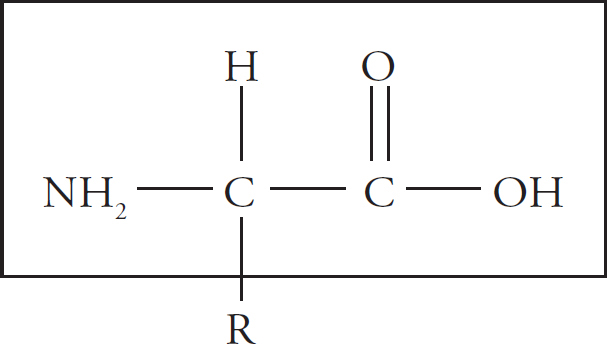
The box encloses the backbone of the amino acid. It’s called the backbone because this is the part of the molecule that is constant from amino acid to amino acid. All 20 amino acids contain the same backbone structure.
There are two carbon atoms in the backbone. The first is bonded to a hydrogen (H) atom on one side and an NH2 group on the other side. The NH2 group is called the amino group. The other carbon atom is bonded to an oxygen (O) atom and an OH group. Notice that the oxygen is bonded to the second carbon by a double bond. The COOH group is called the carboxyl group. If you know what the boxed structure looks like, with its amino and carboxyl group, you’ll be able to recognize amino acids on the test. Take a good, long look at the structure in the box, then draw it (three times) on a sheet of scratch paper so you’ll really be familiar with it.
We’ve already said that all 20 amino acids contain the same backbone structure. But what about the R part of the molecule? The R part of the molecule is called the side-chain, and it makes each amino acid different from all the others. All amino acids have the same basic backbone, but different amino acids differ with respect to R. R could be anything from a simple hydrogen atom to a whole long chain of carbon atoms with different groups bonded to them. The side-chain gives the amino acid its identity.
For example, in the amino acid glycine, R is just a hydrogen atom.
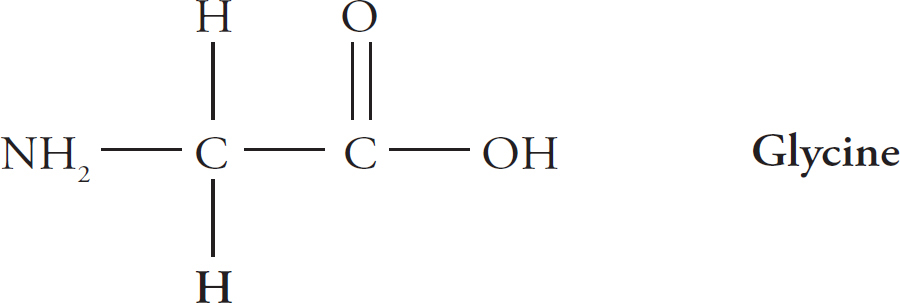
In the amino acid cysteine, R is a carbon atom and a sulfur (S) atom, along with some hydrogen atoms.

Again, there are 20 different possibilities for R groups. You don’t have to know all of them, but you should be able to recognize the backbone of an amino acid.
Amino acids bond together in a chain to form a protein. Remember, a long chain of repeated units (monomers; in this case, amino acids) is called a polymer (in this case, a protein). Let’s look at how two amino acids join.
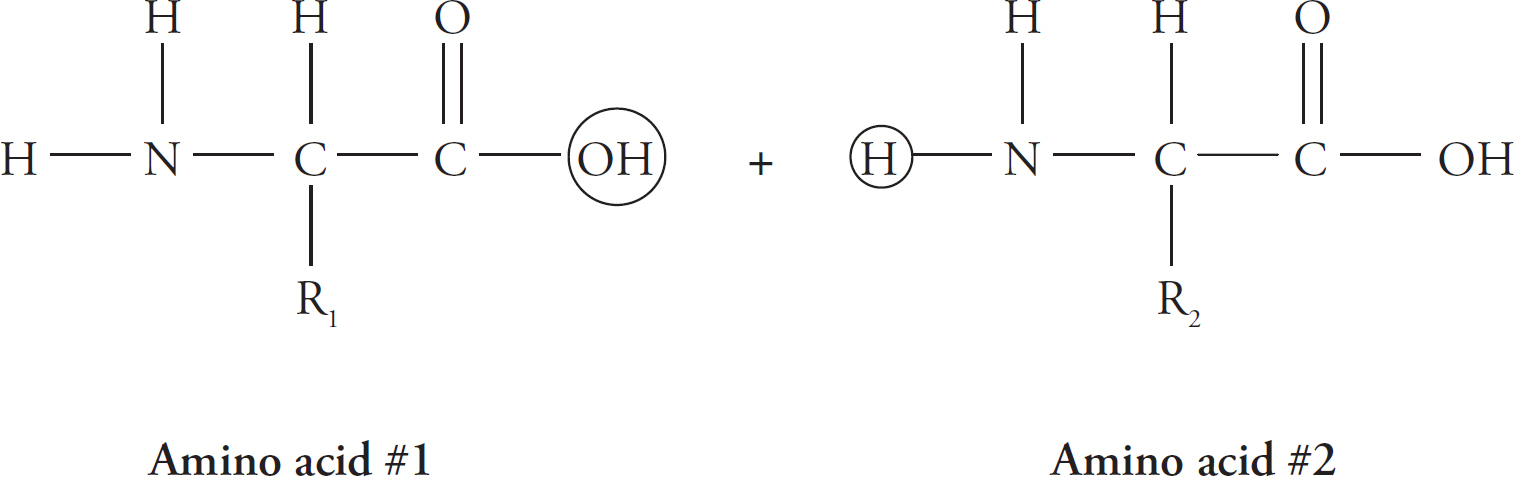
Notice the circles around the OH group of amino acid #1 and around the H of amino acid #2. The carbon from amino acid #1 loses the OH and bonds instead to the nitrogen on amino acid #2. The nitrogen from amino acid #2 loses one H in the process.
Dehydration Synthesis Reaction

The new bond between the amino acids is called a peptide bond. Notice that water (H2O) is removed. Peptide bonds are said to be formed by dehydration synthesis.
Hydrolysis Reaction
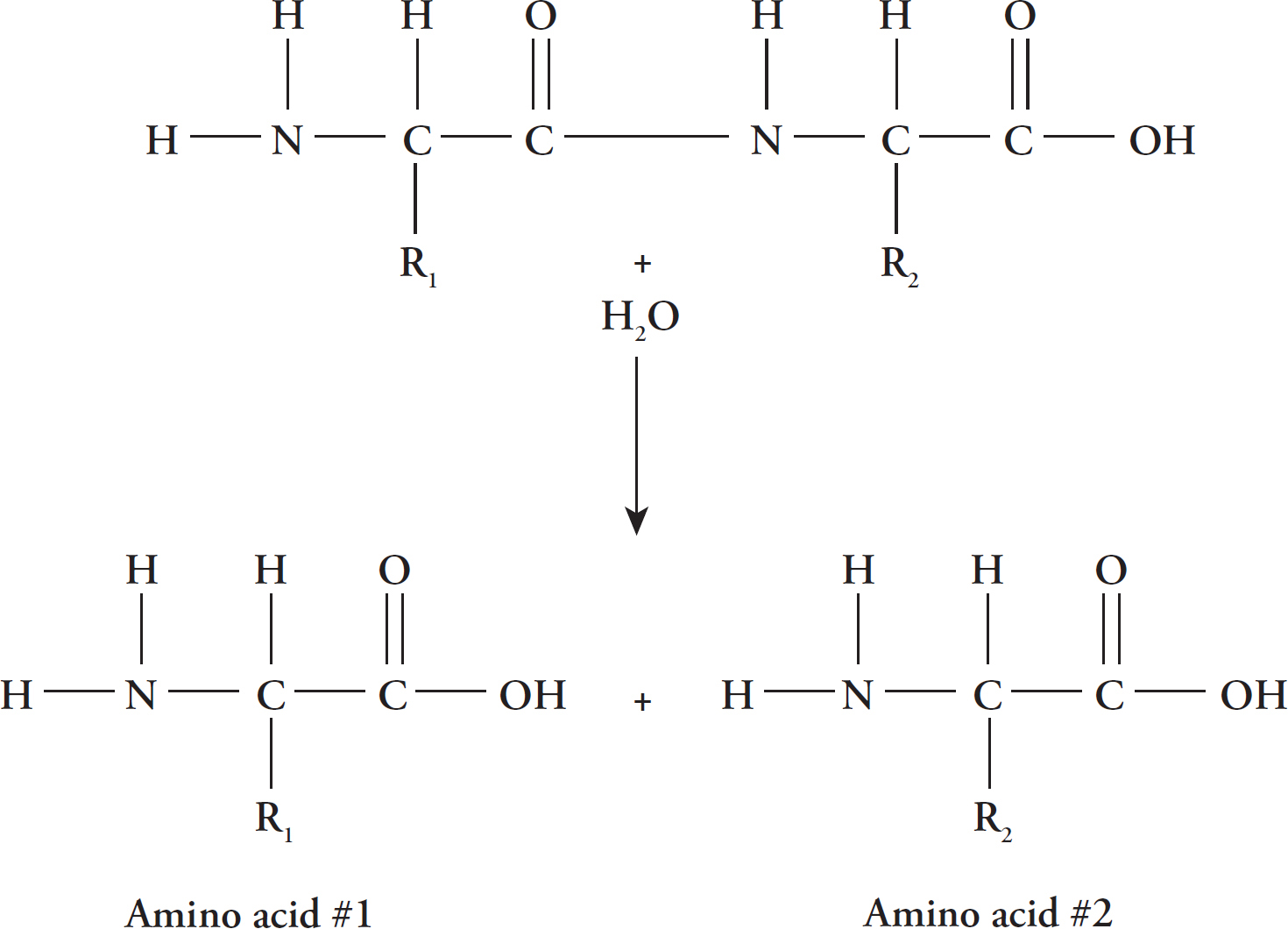
Peptide bonds are formed by dehydration synthesis in which a molecule of water is removed to join two amino acids.
Peptide bonds are broken in the reverse process, called hydrolysis, when a water molecule is added to the structure.
Proteins have many different functions. For example, they serve as enzymes, hormones, channels, structural elements, carriers, and messengers. Don’t worry yet about these specific functions. They’ll come up later as we talk about cells and the body. But do remember that proteins have many different three-dimensional shapes and many different functions.
When two amino acids are joined they form a dipeptide. When many are attached they are called a polypeptide.
The polypeptide has to go through several changes before it can officially be called a protein. Proteins can have four levels of structure. The linear sequence of the amino acids is called the primary structure of a protein. Now the polypeptide begins to twist, forming either a coil (known as an alpha helix) or zigzagging pattern (known as beta-pleated sheets). These are examples of proteins’ secondary structures.
A polypeptide folds and twists because the different R-groups of the amino acids are interacting with each other. Remember, each R-group is unique and has a particular size, shape, charge, etc. that allows it to react to things around it. Depending on which amino acids are in a protein and the order that they are in, the protein can twist and fold in very different ways. This is why proteins can form so many different shapes.
The secondary structure is formed by amino acids that interact with other amino acids close by in the primary structure. However, after the secondary structure reshapes the polypeptide, amino acids that were far away in the primary structure arrangement can now also interact with each other. This is called the tertiary structure. Sometimes, two cysteine amino acids can react with each other to form a covalent disulfide bond that stabilizes the tertiary structure.
Lastly, several different polypeptide chains sometimes interact with each other to form a quaternary structure. The different polypeptide chains that come together are often called subunits of the final whole protein.

Only proteins that have folded correctly into their specific three-dimensional structure can perform their functions properly. Mistakes in the amino acid chain can create oddly shaped proteins that are nonfunctional. One more thing: in some cases, the folding of proteins involves other proteins known as chaperone proteins (or chaperonins). They help the protein fold properly and make the process more efficient.
Fill in the blanks, and check the appropriate boxes.
1. The bond that holds two amino acids together is called a bond.
2. The assembly of a protein from its amino acid constituents involves the [☐ addition ☐ removal] of water and is called .
3. An amino acid is a [☐ monomer ☐ polymer] of a protein.
4. Because proteins are essentially chains of amino acids linked together by bonds, a protein might also be called a .
5. The disassembly of a protein into its component amino acids is called and involves the [☐ addition ☐ removal] of water.
Correct answers can be found in Part IV.
The monomer for a carbohydrate is a saccharide. The term saccharide refers to “sweetness;” carbohydrates are essentially sugar molecules. All carbohydrates have a common factor: they are made only of carbon, oxygen, and hydrogen.
The carbohydrate is unique among the macromolecules because it is the only macromolecule for which the monomer by itself is considered to be a carbohydrate. A single saccharide can be called a carbohydrate. In fact, there is a whole group of carbohydrates that are made only of a single saccharide. They are called monosaccharides (mono = one).
Carbs
Carbohydrates, or “carbs,” as they are sometimes referred to, include the sugar molecules dissolved in a bottle of soda as well as the starch molecules found in pasta and potatoes. Carbohydrates can be used by the body minutes after they are eaten, or they can be stored for use later. Although people involved in athletics seem more concerned with carbs than nonathletes, carbohydrates are an important source of energy for all of us, athlete or not.
Monosaccharides are made of carbon, oxygen, and hydrogen in a fixed ratio. The number of carbon atoms is equal to the number of oxygen atoms, and the number of hydrogen atoms is equal to twice the number of either carbon atoms or oxygen atoms. In other words, the Cs, Hs, and Os exist in a 1:2:1 ratio.
The generic chemical formula for a monosaccharide is
CnH2nOn
The two monosaccharides you need to know for the test are glucose and fructose. Glucose and fructose have the same chemical formula: C6H12O6 but they differ in the arrangement of their atoms.

In the glucose molecule, the double-bonded oxygen is located on the top carbon. In the fructose molecule, it’s located on the second carbon from the top.
One last thing you should know about glucose is that it can also form a ring structure.
Glucose and Fructose: A Quick Review
Glucose and fructose are both carbohydrates.
Both are monosaccharides.
Both have the formula C6H12A6.
Glucose and fructose differ in the way the double-bonded oxygen is oriented within the molecule.

Remember that many carbohydrates are polymers: strings of repeated units. So it makes sense, then, that monosaccharides would link together to form larger carbohydrates. If only two monosaccharides link together, the result is a carbohydrate made of two monomers: a disaccharide (di = two).
The disaccharides you need to know for the test are maltose and sucrose. Maltose is formed from two molecules of glucose. When the two molecules bond together, a molecule of water (H2O) is removed. This is dehydration synthesis, just like we saw for peptide bond formation. The chemical formula for maltose is not C12H24O12 (2 × glucose). Remember that two hydrogen atoms and one oxygen atom are removed, so the chemical formula for maltose is C12H22O11.
Sucrose is commonly known as table sugar. It is formed when a molecule of glucose combines with a molecule of fructose in a dehydration synthesis reaction.
The two disaccharides to know are maltose and sucrose.
glucose
C6H12O6
+ glucose
+ C6H12O6
→ maltose
→ C12H22O1
+ water molecule
+ H2O
glucose
C6H12O6
+ fructose
+ C6H12O6
→ sucrose
→ C12H22O11
+ water molecule
+ H2O
If the number of monosaccharides joined together exceeds two, the molecule is simply known as a polysaccharide (poly = many). There are three polysaccharides to know for the test: glycogen, starch, and cellulose. All three of these are polymers of glucose. In other words, they are formed from many, many, many molecules of glucose bonded together.
If glycogen, starch, and cellulose are all polymers of glucose, what’s the difference between them? The difference is in the way the glucose molecules are linked together, and that’s almost all you have to know.
The other bit of information you need to know about these large polysaccharides is their function. Because they’re large chains of glucose, they act as a good storage form for glucose. We will see later that glucose is the primary form of cellular “food,” so it makes sense that organisms would want to store it. Different organisms store glucose in different forms.
Glycogen: the form in which animals (including the human animal) store glucose
Starch: the form in which plants store glucose
What about cellulose? Because of the way the glucose molecules are linked together in cellulose, cellulose is a much stronger, more rigid molecule. It is used for plant structures such as stems, leaves, and wood.
Cellulose: a structural polysaccharide that forms the plant’s cell walls
Fill in the blanks, and check the appropriate boxes.
1. Starch serves as a means of storing glucose in [☐ plants ☐ animals].
2. A molecule of maltose is formed from two molecules of .
3. Glucose and fructose [☐ are ☐ are not] identical molecules.
4. A molecule of glucose and a molecule of fructose, both of which are , combine to form a molecule of , which is a .
5. Cellulose is a .
6. Glycogen serves as a means for storing glucose in [☐ plants ☐ animals].
7. The chemical formula for both glucose and fructose is .
8. The chemical formula for sucrose is .
9. Cellulose and glycogen differ in the way that molecules are bonded together.
10. The chemical formulas for sucrose and maltose [☐ are ☐ are not] identical.
Correct answers can be found in Part IV.
Lipids are fats—oils, butter, lard, and so on. The function of lipids are many: they function as energy storage compounds and components of cell membranes in addition to providing insulation and cushioning. The monomer for a lipid is a hydrocarbon. Simply put, this is just a carbon atom with two hydrogen atoms bonded to it.
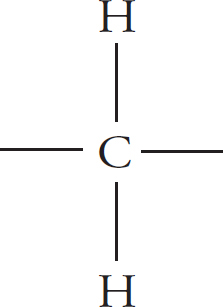
Hydrocarbons can link together to form long chains.

The chains can vary in length and are usually between 12 and 24 carbons long. Hydrocarbon chains are very hydrophobic, meaning that they do not interact well with water. Consider what would happen if you put equal amounts of water and cooking oil in a glass and shook it up, and then let it sit on the table. The oil and water would begin to separate, and after some time, they would be found in separate layers in the glass. The oil (a lipid) is hydrophobic, and it does not want to interact with the water. Another term for hydrophobic is nonpolar. Lipids are also referred to as being nonpolar.
The three most common forms in which lipids are found in the body are as triglycerides, phospholipids, and cholesterol. Let’s take a look at each of these molecules.
Triglycerides consist of three fatty acids (tri = three) bonded to a glycerol molecule (glyc = glycerol). A fatty acid is just a long hydrocarbon chain with a carboxyl group at one end. A glycerol molecule is an alcohol that has three carbon atoms in it.

Most of the fats you eat are in the form of triglycerides, and your body stores fats in the form of triglycerides.
Phospholipids look very much like triglycerides, except that one of the fatty acid chains is replaced with a phosphate group (–PO32–).
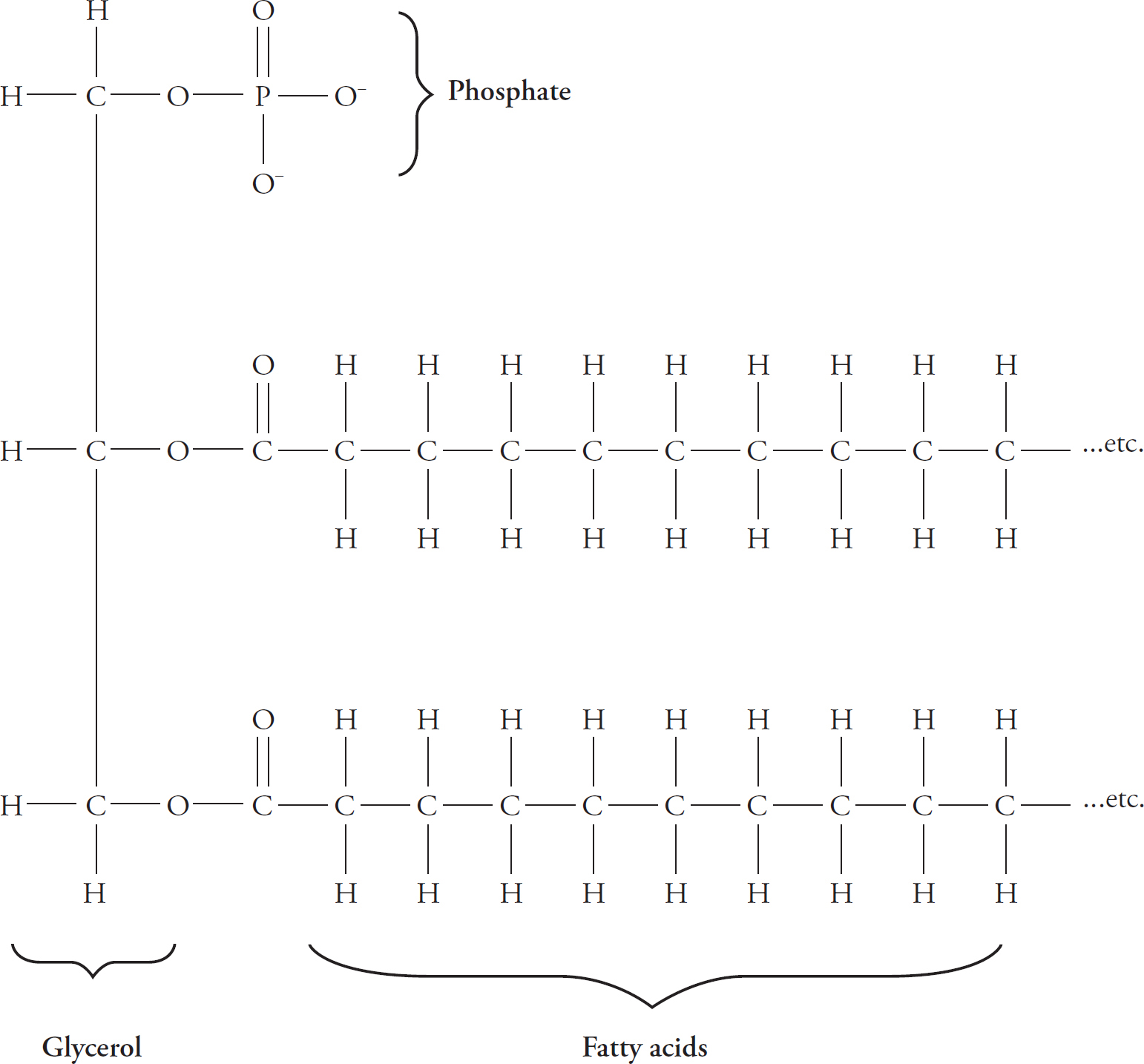
The phosphate group is hydrophilic (can interact with water). Another word to describe it is polar.
Phospholipids are polar on one end (the phosphate end) and nonpolar on the other (the fatty acid end). A molecule that is both polar and nonpolar is said to be amphipathic.
A common way to represent phospholipids is something like the figure below.

When phospholipids interact with one another, they align themselves so that their polar phosphate head groups stay together and their nonpolar fatty acid tails stay together.
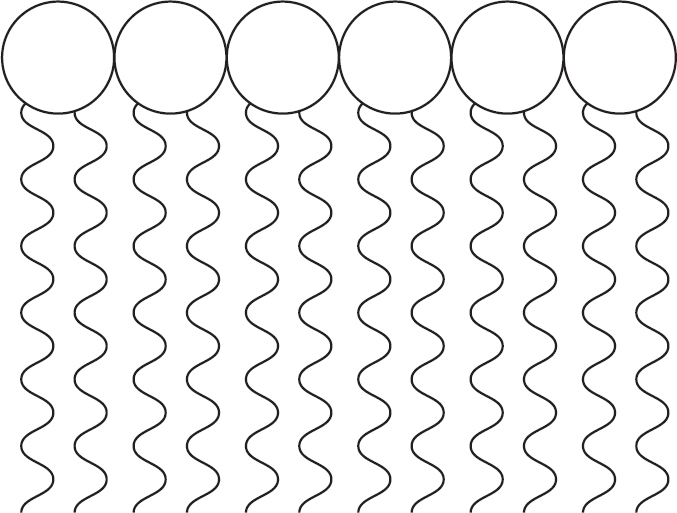
Often, they form a double layer.

This double layer of phospholipids is known as a lipid bilayer. Lipid bilayers form cell membranes. We’ll talk more about cell membranes a little later on.
Cholesterol is a unique lipid. It is not made of long hydrocarbon chains; instead, the hydrocarbons form rings. Cholesterol is found only in animal cells, in cell membranes along with phospholipids. Additionally, all the steroid hormones in the body (for example, estrogen, testosterone, and progesterone) are derived from cholesterol.

Cholesterol
Cholesterol is probably best known because of its negative reputation. Cholesterol is most infamous for its association with cardiovascular diseases. You may have heard about “good” cholesterol and “bad” cholesterol. “Good cholesterol” is HDL, or a high density lipoprotein. “Bad cholesterol” is LDL, or a low density lipoprotein. Cholesterol itself is a nonpolar lipid, but to travel in the bloodstream it must be partnered together with some proteins, thus forming a lipoprotein. Most doctors will recommend that people have an LDL level in their blood of <100 mg/dL, or even considerably less than that for people with a history of heart problems.
Cholesterol does have positive functions. Your body needs cholesterol to build and maintain cell membranes and to produce steroid hormones such as estrogen, testosterone, and progesterone. Cholesterol is found in the body tissues and blood of all animals.
Fill in the blanks, and check the appropriate boxes.
1. Triglycerides are made of one molecule of and three .
2. Lipids in general are [☐ hydrophilic ☐ hydrophobic].
3. The primary lipid found in cell membranes is .
4. Steroid hormones are derived from .
5. Steroid hormones [☐ are ☐ are not] hydrophobic.
6. Fats are stored in the body in the form of .
Correct answers can be found in Part IV.
Nucleic acids are acidic macromolecules (“acids”) some of which are typically found in the nucleus of the cell (“nucleic”). Specifically, they are DNA (deoxyribonucleic acid) and RNA (ribonucleic acid). The monomer of a nucleic acid is a nucleotide, so nucleic acids are sometimes referred to as polynucleotides. A nucleotide is made up of a sugar, a phosphate, and a base.

Let’s consider the structure of DNA first. RNA is very similar to DNA, so once you understand how DNA is constructed, it will be easy to understand how RNA is constructed.
The “base” in the figure above can be replaced by one of four different chemicals referred to as nucleotide bases.
The four possible nucleotide bases for DNA are
Adenine
Guanine
Cytosine
Thymine
Because there are four types of DNA bases, there are really four types of DNA nucleotides.

Notice that the sugar and the phosphate are constant from nucleotide to nucleotide. The sugar and the phosphate are known as the backbone of the nucleotide.
When nucleotides bond to form a long chain (a polynucleotide), the chain is a strand of DNA. Because the four types of nucleotides can bond in any order, many different strands of DNA can be made. Here’s an example of three possible strands.
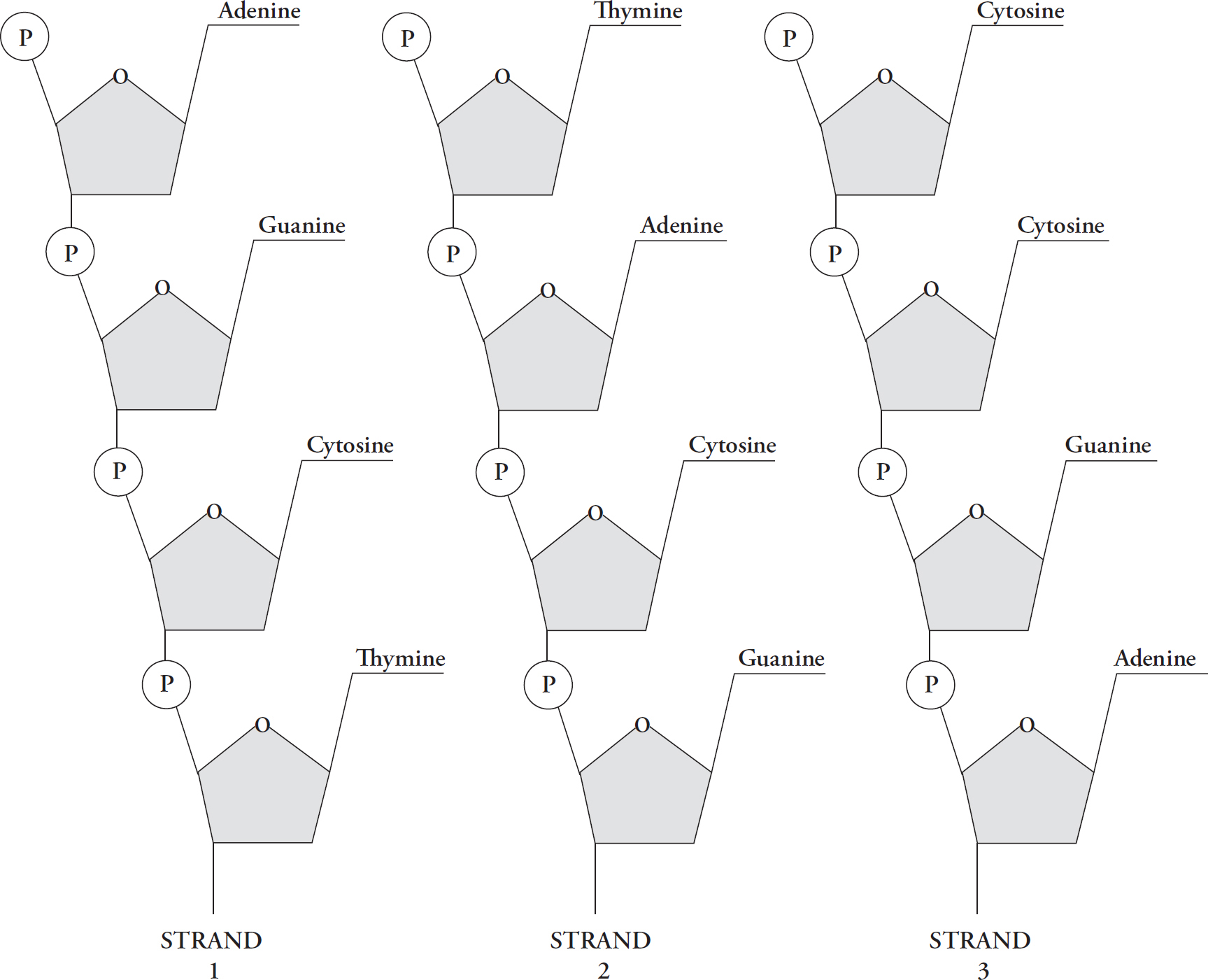
Each is a strand of DNA, and each is a polymer of nucleotides, but each strand differs from the others because of the order in which the nucleotides are bonded together.
Each DNA molecule consists of two strands that wrap around each other to form a long, twisted ladder called a double helix. The structure of DNA was brilliantly deduced in 1953 by three scientists: Watson, Crick, and Franklin.
Now let’s look at the way two DNA strands get together. Again, think of DNA as a ladder. The sides of the ladder consist of alternating sugar and phosphate groups, while the rungs of the ladder consist of pairs of nitrogenous bases.
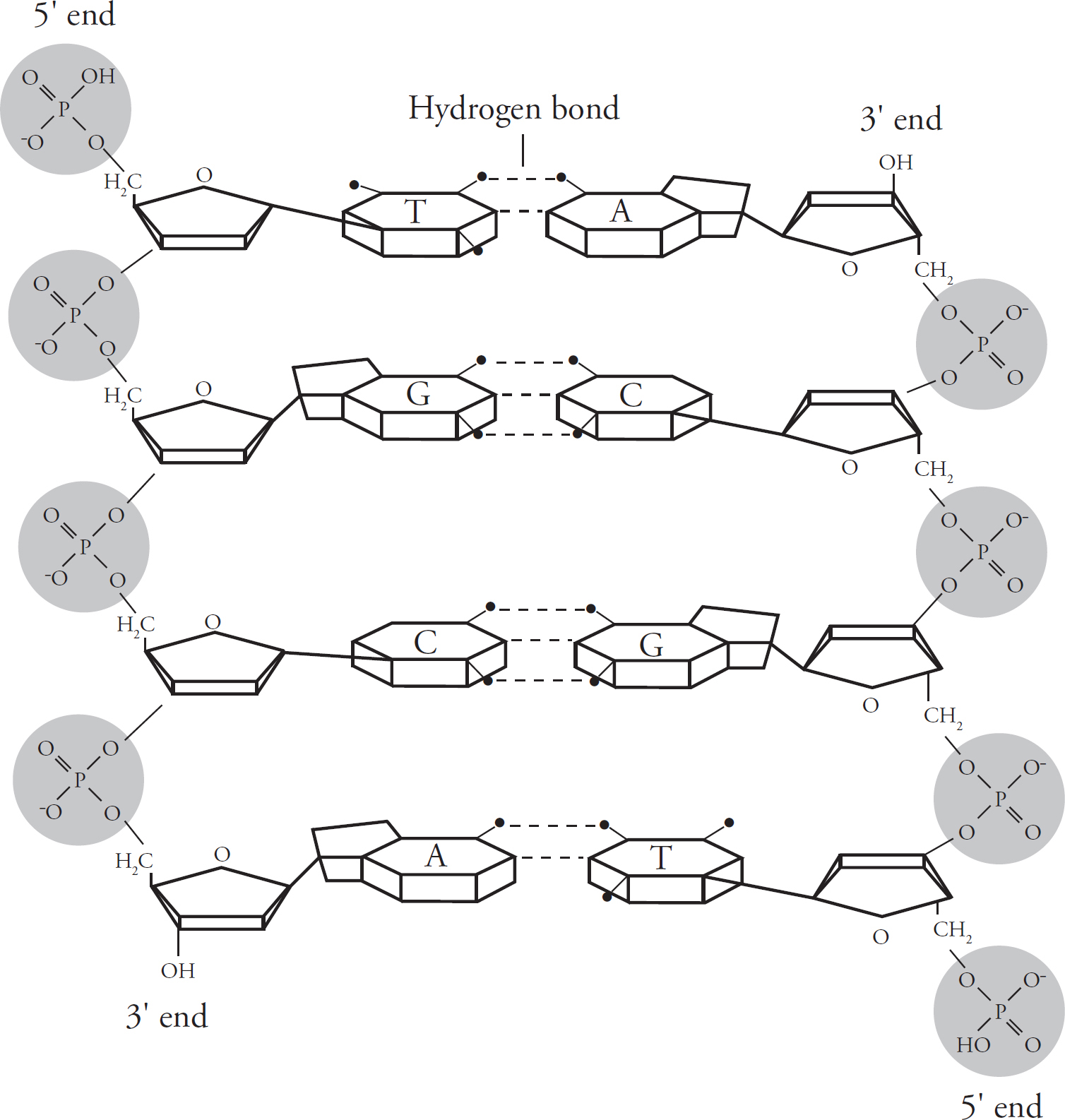
The nitrogenous bases pair up in a particular way. Adenine in one strand always binds to thymine (A–T or T–A) in the other strand. Similarly, guanine always binds to cytosine (G–C or C–G). This predictable matching of the bases is known as base pairing.
The two strands are said to be complementary. This means that if you know the sequence of bases in one strand, you’ll know the sequence of bases in the other strand. For example, if the base sequence in one DNA strand is A–T–C, the base sequence in the complementary strand will be T–A–G.
The two DNA strands run in opposite directions. You’ll notice from the figure above that each DNA strand has a 5’ end and a 3’ end, so-called for the carbon that ends the strand (i.e., the fifth carbon in the sugar ring is at the 5’ end, while the third carbon is at the 3’ end). The 5’end has a phosphate group, and the 3’ end has an OH, or “hydroxyl,” group. The 5’ end of one strand is always opposite to the 3’ end of the other strand. The strands are therefore said to be antiparallel.
The DNA strands are linked by hydrogen bonds. Two hydrogen bonds hold adenine and thymine together, and three hydrogen bonds hold cytosine and guanine together.
Before we go any further, let’s review the base pairing in DNA:
Adenine pairs up with thymine (A–T or T–A) by forming two hydrogen bonds.
Cytosine pairs up with guanine (G–C or C–G) by forming three hydrogen bonds.
The order of the four base pairs in a DNA strand is the genetic code. Like a special alphabet in our cells, these four nucleotides spell out thousands of recipes. Each recipe is called a gene. The human genome has around 20,000 genes.
The recipes of the genes are spread out among the millions of nucleotides of DNA, and all of the DNA for a species is called its genome. Each separate chunk of DNA in a genome is called a chromosome.
Prokaryotes have one circular chromosome, and eukaryotes have linear chromosomes. In eukaryotes, the DNA is further structured, likely since linear chromosomes are more likely to get tangled. To keep it organized, the DNA is wrapped around proteins called histones, and then the histones are bunched together in groups called a nucleosome. Not all DNA is wound up equally, because it must be unwound in order to be read. How tightly DNA is packaged depends on the section of DNA and also what is going on in the cell at that time. Humans have 23 different chromosomes and they have two copies of each, so each human cell has 46 linear chromosome segments in the nucleus. When the genetic material is in a loose form in the nucleus, it is called euchromatin, and its genes are active, or available for transcription. When the genetic material is fully condensed into coils, it is called heterochromatin, and its genes are generally inactive. Situated in the nucleus, chromosomes contain the recipes for all the processes necessary for life, including passing themselves and their information on to future generations. In the rest of this chapter, we’ll look at precisely how they accomplish this.
We said in the beginning of this chapter that DNA is the hereditary blueprint of the cell. By directing the manufacture of proteins, DNA serves as the cell’s blueprint. But how is DNA inherited? For the information in DNA to be passed on, it must first be copied. This copying of DNA is known as DNA replication.
Because the DNA molecule is twisted over on itself, the first step in replication is to unwind the double helix by breaking the hydrogen bonds. This is accomplished by an enzyme called helicase. The exposed DNA strands now form a y-shaped replication fork.
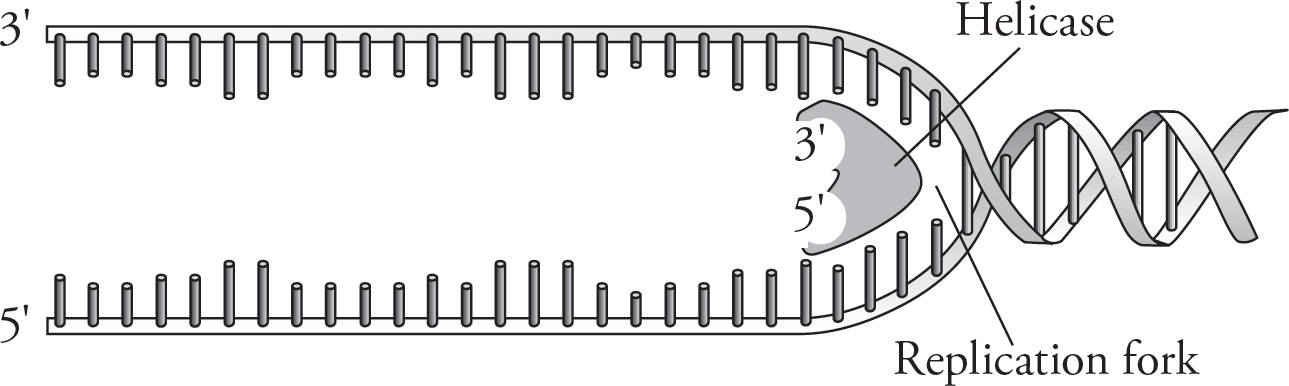
Now each strand can serve as a template for the synthesis of another strand. DNA replication begins at specific sites called origins of replication. Because the DNA helix twists and rotates during DNA replication, another class of enzymes, called DNA topoisomerases, cuts and rejoins the helix to prevent tangling. The enzyme that performs the actual addition of nucleotides to the freshly built strand is DNA polymerase. But DNA polymerase, oddly enough, can add nucleotides only to the 3’ end of an existing strand. Therefore, to start off replication, an enzyme called RNA primase adds a short strand of RNA nucleotides called an RNA primer. After replication, the primer is degraded by enzymes and replaced with DNA so that the final strand contains only DNA filled with DNA.
One strand is called the leading strand, and it is made continuously. That is, the nucleotides are steadily added one after the other by DNA polymerase. The other strand—the lagging strand—is made discontinuously. Unlike the leading strand, the lagging strand is made in pieces of nucleotides known as Okazaki fragments. Why is the lagging strand made in small pieces?
Nucleotides are added only in the 5’ to 3’ direction since nucleotides can be added only to the 3’ end of the growing chain. However, when the double-helix is “unzipped,” one of the two strands is oriented in the opposite direction—3’ to 5’. Because DNA polymerase doesn’t work in this direction, the strand needs to be built in pieces. You can see in the figure below that the leading strand is being created toward the opening of the helix and the helix continually opens ahead of it to accommodate it. The lagging strand is built in the opposite direction of the way the helix is opening, so it can build only until it hits a previously built stretch. Once the helix unwinds a bit more, it can build another Okazaki fragment, and so on. These fragments are eventually linked together by the enzyme DNA ligase to produce a continuous strand. Finally, hydrogen bonds form between the new base pairs, leaving two identical copies of the original DNA molecule.

When DNA is replicated, we don’t end up with two entirely new molecules. Each new molecule has half of the original molecule. Because DNA replicates in a way that conserves half of the original molecule in each of the two new ones, it is said to be semiconservative.
An interesting problem is that a few bases at the very end of a DNA molecule cannot be replicated because the DNA polymerase needs to bind. This means that every time replication occurs, the chromosome loses a few base pairs. The genome has compensated for this over time, by putting bits of unimportant (or at least less important) DNA at the ends of a molecule. These ends are called telomeres. They get shorter and shorter over time.
Many enzymes and proteins are involved in DNA replication. The ones you’ll need to know for the SAT Subject Test in Biology are DNA helicase, DNA polymerase, DNA ligase, topoisomerase, and RNA primase:
Helicase unwinds our double helix into two strands.
Polymerase adds nucleotides to an existing strand.
Ligase brings together the Okazaki fragments.
Topoisomerase cuts and rejoins the helix.
RNA primase catalyzes the synthesis of RNA primers.
RNA is a polymer of nucleotides that’s similar to DNA. The biggest difference between RNA and DNA is that RNA is a single-stranded molecule, whereas DNA is double-stranded (a double helix). The fact that RNA is single-stranded allows it to assume various unique shapes. There is no second strand to lock it into a double-helix shape. It can form base pairs with itself, and this allows it to fold up into many different three-dimensional shapes. The nucleotides that make up RNA use ribose as their sugar instead of the deoxyribose used in DNA. Another difference is that RNA does not use thymine as a nucleotide base; instead, it uses a base called uracil. Uracil can form a base pair with adenine in RNA, just like thymine does in DNA (RNA can fold on itself to form base pairs). Below is a summary of the differences between RNA and DNA.
|
Characteristic |
RNA |
DNA |
|
Structure |
single-stranded |
double-stranded |
|
Bases |
adenine, cytosine, guanine, uracil |
adenine, cytosine, guanine, thymine |
|
Sugar |
ribose |
deoxyribose |

We’ll talk more about RNA later on when we discuss protein synthesis in more detail.
Fill in the blanks, and check the appropriate boxes.
1. The fact that double-stranded DNA forms a double helix was discovered by , , and .
2. The four DNA nucleotide bases are , , , and .
3. RNA [☐ is ☐ is not] a double-stranded molecule.
4. RNA nucleotides [☐ do ☐ do not] contain the exact same bases as DNA nucleotides.
5. In DNA, guanine forms a base pair with , whereas adenine forms a base pair with .
6. The nucleic acid “backbone” is made up of and .
7. The sugar in DNA is [☐ ribose ☐ deoxyribose].
8. In RNA, adenine can form a base pair with .
Correct answers can be found in Part IV.
atoms
molecules
compound
element
reactants
products
organic
inorganic
biomolecules
polymers
monomers
amino acids
amino group
double bond
carboxyl group
protein
peptide bond
dehydration synthesis
hydrolysis
dipeptide
polypeptide
primary structure
secondary structures
tertiary structure
quaternary structure
chaperone proteins (chaperonins)
saccharide
monosaccharides
glucose
fructose
disaccharide
maltose
sucrose
polysaccharide
glycogen
starch
cellulose
hydrocarbon
hydrophobic (nonpolar)
triglycerides phospholipids
cholesterol
hydrophilic (polar)
amphipathic
lipid bilayer
deoxyribonucleic acid (DNA)
ribonucleic acid (RNA)
nucleotide
polynucleotides
adenine
guanine
cytosine
thymine
double helix
base pairing
complementary
antiparallel
uracil
hydrogen bonds
gene
genome
chromosome
nucleosome
histones
euchromatin
heterochromatin
DNA replication
helicase
replication fork
origins of replication
topoimerases
DNA polymerase
RNA primase
RNA primer
leading strand
lagging strand
Okazaki fragments
DNA ligase
semiconservative
Answers and explanations can be found in Part IV.
(A) DNA
(B) protein
(C) triglyceride
(D) monosaccharide
(E) adenine
1. Molecule that most resembles a phospholipid
2. Glucose is this type of molecule
3. Results when amino acids undergo dehydration synthesis
4. Forms two hydrogen bonds with thymine
5. This is used to catalyze most reactions
6. Which of the following is NOT an organic compound?
(A) H2O
(B) C6H12O6
(C) CH4
(D) C12H22O11
(E) CH2O
7. How many hydrogen bonds would form between the bases in the strands of this DNA molecule:
ATCTG
TAGAC
(A) 8
(B) 10
(C) 12
(D) 14
(E) 16
8. The order of protein formation associated with disulfide bonds is
(A) primary
(B) secondary
(C) tertiary
(D) quaternary
(E) all of the above
Atoms are the fundamental units of the physical world and combine in chemical reactions to form molecules.
An element is any substance that cannot be broken into simpler substances.
If two or more elements are combined, they form a compound.
The four biologically important macromolecules are proteins, carbohydrates, lipids, and nucleic acids.
Proteins are polymers of amino acids. Each of the 20 amino acids has a basic backbone structure in common and then a unique R-group. Polypeptide chains twist and fold into specific shapes.
The function of proteins varies, but many of them are enzymes.
Carbohydrates are made of only carbon, oxygen, and hydrogen. Common carbohydrates include monosaccharides (like glucose and fructose), disaccharides (like sucrose and maltose), and polysaccharides (like glycogen, starch, and cellulose).
Lipids are composed of hydrocarbons linked to each other. A hydrocarbon is a carbon atom with two hydrogen atoms bonded to it.
The most common forms of lipids are triglycerides, phospholipids, and cholesterol.
Nucleic acids are biologically important macromolecules that are found in the nucleus of every cell.
DNA and RNA are the nucleic acids that make life possible. They are each chains of nucleotides, which each contain a sugar, a nitogenous base, and one or more phosphate groups.
DNA replication occurs in the nucleus. Helicase unwinds the strands. Primase adds an RNA primer. DNA polymerase makes a new partner strand for each original strand.