The moment we start to work with applications consisting of more than one application service, we have a need for service discovery. In the following diagram, we illustrate this problem:
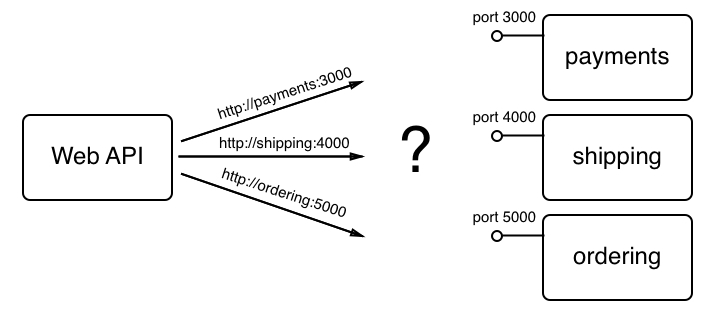
In this diagram, we have a Web API service that needs access to three other services—payments, shipping, and ordering. The Web API should at no time have to care how and where to find those three services. In the API code, we just want to use the name of the service we want to reach and its port number. A sample would be the URL http://payments:3000 that is used to access an instance of the payments service.
In Kubernetes, the payments application service is represented by a ReplicaSet of pods. Due to the nature of highly distributed systems, we cannot assume that pods have stable endpoints. A pod can come and go in a wimp. But that's a problem if we need to access the corresponding application service from an internal or external client. If we cannot rely on pod endpoints being stable, what else can we do?
This is where Kubernetes services come into play. They are meant to provide stable endpoints to ReplicaSets or Deployments, as shown here:

In the preceding diagram, in the center, we see such a Kubernetes service. It provides a reliable cluster-wide IP address also called a virtual IP (VIP), as well as a reliable port that's unique in the whole cluster. The pods that the Kubernetes service is proxying are determined by the selector defined in the service specification. Selectors are always based on labels. Every Kubernetes object can have zero to many labels assigned. In our case, the selector is app=web, that is, all pods that have a label called app with a value of web are proxied.