Each Docker Swarm needs to have at least one manager node. For high availability reasons we should have more than one manager node in a swarm. This is especially true for production or production-like environments. If we have more than one manager node then these nodes work together using the Raft consensus protocol. The Raft consensus protocol is a standard protocol that is often used when multiple entities need to work together and always need to agree with each other as to which activity to execute next.
To work well, the Raft consensus protocol asks for an odd number of members in what is called the consensus group. Thus we should always have 1, 3, 5, 7, and so on manager nodes. In such a consensus group there is always a leader. In the case of Docker Swarm, the first node that starts the swarm initially becomes the leader. If the leader goes away then the remaining manager nodes elect a new leader. The other nodes in the consensus group are called followers.
Now let's assume that we shut down the current leader node for maintenance reasons. The remaining manager nodes will elect a new leader. When the previous leader node comes back online he will now become a follower. The new leader remains the leader.
All the members of the consensus group communicate in a synchronous way with each other. Whenever the consensus group needs to make a decision, the leader asks all followers for agreement. If a majority of the manager nodes give a positive answer then the leader executes the task. That means if we have three manager nodes then at least one of the followers has to agree with the leader. If we have five manager nodes then at least two followers have to agree.
Since all manager follower nodes have to communicate synchronously with the leader node to make a decision in the cluster, the decision-making process gets slower and slower the more manager nodes we have forming the consensus group. The recommendation of Docker is to use one manager for development, demo, or test environments. Use three manager nodes in small to medium size swarms, and use five managers in large to extra large swarms. To use more than five managers in a swarm is hardly ever justified.
Manager nodes are not only responsible for managing the swarm but also for maintaining the state of the swarm. What do we mean by that? When we talk about the state of the swarm we mean all the information about it—for example, how many nodes are in the swarm, what are the properties of each node, such as name or IP address. We also mean what containers are running on which node in the swarm and more. What, on the other hand, is not included in the state of the swarm is data produced by the application services running in containers on the swarm. This is called application data and is definitely not part of the state that is managed by the manager nodes:
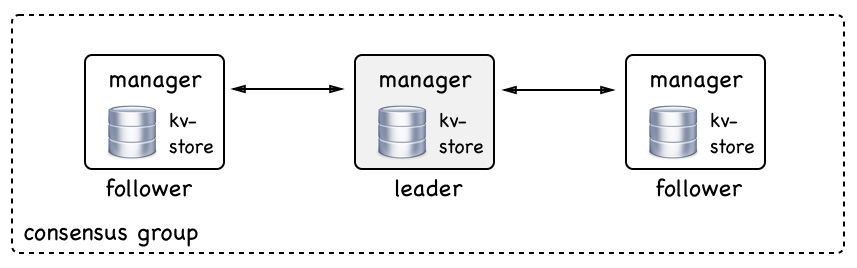
All the swarm state is stored in a high performance key-value store (kv-store) on each manager node. That's right, each manager node stores a complete replica of the whole swarm state. This redundancy makes the swarm highly available. If a manager node goes down, the remaining managers all have the complete state at hand.
If a new manager joins the consensus group then it synchronizes the swarm state with the existing members of the group until it has a complete replica. This replication is usually pretty fast in typical swarms but can take a while if the swarm is big and many applications are running on it.