As we build applications that consist of many individual components or services that communicate with each other, we need a mechanism that allows the individual components to find each other in the cluster. Finding each other usually means that one needs to know on which node the target component is running and on which port it is listening for communication. Most often, nodes are identified by an IP address and a port, which is just a number in a well-defined range.
Technically, we could tell Service A, which wants to communicate with a target, Service B, what the IP address and port of the target are. This could happen, for example, through an entry in a configuration file:
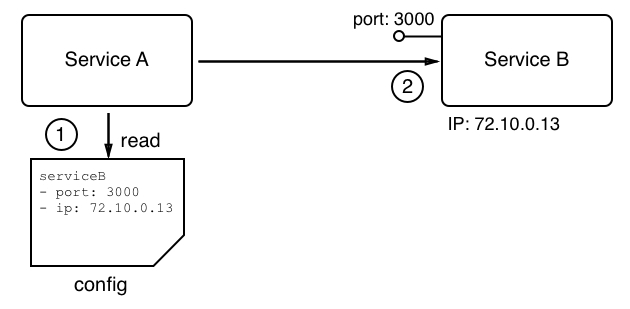
While this might work very well in the context of a monolithic application that runs on one or only a few well-known and curated servers, it totally falls apart in a distributed application architecture. First of all, in this scenario, we have many components, and keeping track of them manually becomes a nightmare. It is definitely not scalable. Furthermore, Service A typically should or will never know on which node of the cluster the other components run. Their location may not even be stable as component B could be moved from node X to another node Y, due to various reasons external to the application. Thus, we need another way in which Service A can locate Service B, or any other service for that matter. What is most commonly used is an external authority that is aware of the topology of the system at any given time. This external authority or service knows all the nodes and their IP addresses that currently pertain to the cluster; it knows all services that are running and where they are running. Often, this kind of service is called a DNS service, where DNS stands for Domain Name System. As we will see, Docker has a DNS service implemented as part of the underlying engine. Kubernetes also uses a DNS service to facilitate communication between components running in the cluster:
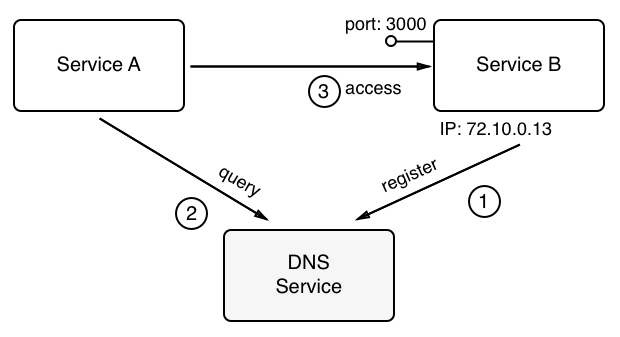
In the preceding figure, we see how Service A wants to communicate with Service B. But it can't do this directly; it has to first query the external authority, a registry service, here called a DNS Service, about the whereabouts of Service B. The registry service will answer with the requested information and hand out the IP address and port number with which Service A can reach Service B. Service A then uses this information and establishes communication with Service B. Of course, this is a naive picture of what's really happening on a low level, but it is a good picture to understand the architectural pattern of service discovery.