From the perspective of artificial intelligence, evolutionary computation belongs to computation intelligence. The origins of evolutionary computation can be traced back to the late 1950s (see, e.g., the influencing works [12, 15, 46, 47]), and has started to receive significant attention during the 1970s (see, e.g., [41, 68, 133]).
The first issue of the Evolutionary Computation in 1993 and the first issue of the IEEE Transactions on Evolutionary Computation in 1997 mark two important milestones in the history of the rapidly growing field of evolutionary computation.
This chapter is focused primarily on basic theory and methods of evolutionary computation, including multiobjective optimization, multiobjective simulated annealing, multiobjective genetic algorithms, multiobjective evolutionary algorithms, evolutionary programming, differential evolution together with ant colony optimization, artificial bee colony algorithms, and particle swarm optimization. In particular, this chapter also highlights selected topics and advances in evolutionary computation: Pareto optimization theory, noisy multiobjective optimization, and opposition-based evolutionary computation.
9.1 Evolutionary Computation Tree
- 1.
Physic-inspired evolutionary computation: Its typical representative is simulated annealing [100] inspired by heating and cooling of materials.
- 2.
Darwin’s evolution theory inspired evolutionary computation
Genetic Algorithm (GA) is inspired by the process of natural selections. A GA is commonly used to generate high-quality solutions to optimization and search problems by relying on bio-inspired operators such as mutation, crossover, and selection.
Evolutionary Algorithms (EAs) are inspired by Darwin’s evolution theory which is based on survival of fittest candidate for a given environment. These algorithms begin with a population (set of solutions) which tries to survive in an environment (defined with fitness evaluation). The parent population shares their properties of adaptation to the environment to the children with various mechanisms of evolution such as genetic crossover and mutation.
Evolutionary Strategy (ES) was developed by Schwefel in 1981 [143]. Similar to the GA, the ES uses evolutionary theory to optimize, that is to say, genetic information is used to inherit and mutate the survival of the fittest generation by generation, so as to get the optimal solution. The difference lies in: (a) the DNA sequence in ES is encoded by real number instead of 0-1 binary code in GA; (b) In the ES the mutation intensity is added for each real number value on the DNA sequence in order to make a mutation.
Evolutionary Programming (EP) [43]: The EP and the ES adopt the same coding (digital string) to the optimization problem and the same mutation operation mode, but they adopt the different mutation expressions and survival selections. Moreover, the crossover operator in ES is optional, while there is no crossover operator in EP. In the aspect of parent selection, the ES adopts the method of probability selection to form the parent, and each individual of the parent can be selected with the same probability, while the EP adopts a deterministic approach, that is, each parent in the current population must undergo mutation to generate offspring.
Differential Evolution (DE) was developed by Storn and Price in 1997 [147]. Similar to the GA, the main process includes three steps: mutation, crossover, and selection. The difference is that the GA controls the parent’s crossover according to the fitness value, while the mutation vector of the DE is generated by the difference vector of the parent generation, and crossover with the individual vector of the parent generation to generate a new individual vector, which directly selects with the individual of the parent generation. Therefore, the approximation effect of DE is more significant than that of the GA.
- 3.Swarm intelligence inspired evolutionary computation: Swarm intelligence includes two important concepts: (a) The concept of a swarm means multiplicity, stochasticity, randomness, and messiness. (b) The concept of intelligence implies a kind of problem-solving ability through the interactions of simple information-processing units. This “collective intelligence” is built up through a population of homogeneous agents interacting with each other and with their environment. The major swarm intelligence inspired evolutionary computation includes:
Ant Colony Optimization (ACO) by Dorigo in 1992 [28]; a swarm of ants can solve very complex problems such as finding the shortest path between their nest and the food source. If finding the shortest path is looked upon as an optimization problem, then each path between the starting point (their nest) and the terminal (the food source) can be viewed as a feasible solution.
Artificial Bee Colony (ABC) algorithm, proposed by Karaboga in 2005 [81], is inspired by the intelligent foraging behavior of the honey bee swarm. In the ABC algorithm, the position of a food source represents a possible solution of the optimization problem and the nectar amount of a food source corresponds to the quality (fitness) of the associated solution.
Particle Swarm Optimization (PSO), developed by Kennedy and Eberhart in 1995 [86], is essentially an optimization technique based on swarm intelligence, and adopts a population-based stochastic algorithm for finding optimal regions of complex search spaces through the interaction of individuals in a population of particles. Different from evolutionary algorithms, the particle swarm does not use selection operation; while interactions of all population members result in iterative improvement of the quality of problem solutions from the beginning of a trial until the end.

Evolutionary computation tree
9.2 Multiobjective Optimization
In science and engineering applications, a lot of optimization problems involve with multiple objectives. Different from single-objective problems, objectives in multiobjective problems are usually conflict. For example, in the design of a complex hardware/software system, an optimal design might be an architecture that minimizes cost and power consumption but maximizing the overall performance. This structural contradiction leads to multiobjective optimization theories and methods different from single-objective optimization. The need for solving multiobjective optimization problems has spawned various evolutionary computation methods.
This section discusses two multiobjective optimizations: multiobjective combinatorial optimization problems and multiobjective optimization problems.
9.2.1 Multiobjective Combinatorial Optimization
Combinatorial optimization is a topic that consists of finding an optimal object from a finite set of objects.


 , the solution
, the solution ![$$\mathbf {x}=[x_1,\ldots ,x_n]^T\in \mathbb {R}^n$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq2.png) is a vector of discrete decision variables,
is a vector of discrete decision variables,  and B = {0, 1}, and Ax ≤b denotes the elementwise inequality (Ax)i ≤ b
i for all i = 1, …, m.
and B = {0, 1}, and Ax ≤b denotes the elementwise inequality (Ax)i ≤ b
i for all i = 1, …, m.- 1.
- 2.
 (9.2.8)
(9.2.8) (9.2.9)
(9.2.9) (9.2.10)
(9.2.10)Here, it is not restrictive to suppose equality constraints with
 .
. - 3.Multiobjective network flow or transhipment problems [ 152]: Let G(N, A) be a network flow with a node set N and an arc set A; the model can be stated as
 (9.2.11)
(9.2.11) (9.2.12)
(9.2.12) (9.2.13)
(9.2.13) (9.2.14)
(9.2.14)where x ij is the flow through arc (i, j),
 is the linear transhipment “cost” for arc (i, j) in objective k, and l
ij and u
ij are lower and upper bounds on x
ij, respectively.
is the linear transhipment “cost” for arc (i, j) in objective k, and l
ij and u
ij are lower and upper bounds on x
ij, respectively. - 4.
 (9.2.16)
(9.2.16) (9.2.17)
(9.2.17) (9.2.18)
(9.2.18) (9.2.19)
(9.2.19)where z i = 1 if a facility is established at site i; x ii = 1 if customer j is assigned to the facility at site i; d ij is a certain usage of the facility at site i by customer j if he/she is assigned to that facility; a i and b i are possible limitations on the total customer usage permitted at the facility i;
 is, for objective k, a variable cost (or distance, etc.) if customer j is assigned to facility i;
is, for objective k, a variable cost (or distance, etc.) if customer j is assigned to facility i;  is, for objective k, a fixed cost associated with the facility at site i.
is, for objective k, a fixed cost associated with the facility at site i.






An unconstrained combinatorial optimization problem P = (S, f) is an optimization problem [120], where S is a finite set of solutions (called search space), and  is an objective function that assigns a positive cost value to each solution vector s ∈ S. The goal is either to find a solution of minimum cost value or a good enough solution in a reasonable amount of time in the case of approximate solution techniques.
is an objective function that assigns a positive cost value to each solution vector s ∈ S. The goal is either to find a solution of minimum cost value or a good enough solution in a reasonable amount of time in the case of approximate solution techniques.
It requires intensive co-operation with the decision maker for solving a multiobjective combinatorial optimization problem; this results in especially high requirements for effective tools used to generate efficient solutions.
Many combinatorial problems are hard even in single-objective versions; their multiple objective versions are frequently more difficult.
An multiobjective decision making (MODM) problem is ill-posed from the mathematical point of view because, except in trivial cases, it has no optimal solution. The goal of MODM methods is to find a solution most consistent with the decision maker’s preferences, i.e., the best compromise. Under very weak assumptions about decision maker’s preferences the best compromise solution belongs to the set of efficient solutions [136].
9.2.2 Multiobjective Optimization Problems
Consider optimization problems with multiple objectives that may usually be incompatible.
![$$\displaystyle \begin{aligned} \mathrm{minimize}/\mathrm{maximize}\quad &\left \{\mathbf{y}=\mathbf{f}(\mathbf{x})=\left[f_{1}(\mathbf{x}),\ldots ,f_{m}(\mathbf{x})\right ]^T\right \},{} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ20.png)


 are the objective functions, and
are the objective functions, and  are p inequality constraints and q equality constraints of the problem, respectively; while
are p inequality constraints and q equality constraints of the problem, respectively; while  is called the decision space, and
is called the decision space, and  is known as the objective space.
is known as the objective space.
The n-dimensional decision space
 in which each coordinate axis corresponds to a component (called decision variable) of decision vector x.
in which each coordinate axis corresponds to a component (called decision variable) of decision vector x.The m-dimensional objective space
 in which each coordinate axis corresponds to a component (i.e., a scalar objective function) of objective function vector y = f(x) = [f
1(x), …, f
m(x)]T.
in which each coordinate axis corresponds to a component (i.e., a scalar objective function) of objective function vector y = f(x) = [f
1(x), …, f
m(x)]T.
The MOP’s evaluation function f : x →y maps decision vector x = [x 1, …, x n]T to objective vector y = [y 1, …, y m]T = [f 1(x), …, f m(x)]T.
If some objective function f i is to be maximized (or minimized), the original problem is written as the minimization (or maximization) of the negative objective − f i. Thereafter, we consider only the multiobjective minimization (or maximization) problems, rather than optimization problems mixing both minimization and maximization.
The constraints g(x) ≤0 and h(x) = 0 determine the set of feasible solutions.

- 1.Objectives:
- Cost function: The fuel cost function of each thermal generator, considering the valve-point effect, is expressed as the sum of a quadratic and a sinusoidal function. The total fuel cost in terms of real power can be expressed as
 (9.2.24)
(9.2.24)where N is number of generating units, M is number of hours in the time horizon; a i, b i, c i, d i, e i are cost coefficients of the ith unit; P im is power output of ith unit at time m, and
 is lower generation limits for ith unit.
is lower generation limits for ith unit. - Emission function: The atmospheric pollutants such as sulfur oxides (SOx) and nitrogen oxides (NOx) caused by fossil-fueled generating units can be modeled separately. However, for comparison purpose, the total emission of these pollutants which is the sum of a quadratic and an exponential function can be expressed as
 (9.2.25)
(9.2.25)where α i, β i, γ i, η i, δ i are emission coefficients of the ith unit.
- 2.Constraints:
- Real power balance constraints: The total real power generation must balance the predicted power demand plus the real power losses in the transmission lines, at each time interval over the scheduling horizon, i.e.,
 (9.2.26)
(9.2.26)where P Dm is load demand at time m, P Lm is transmission line losses at time m.
- Real power operating limits:
 (9.2.27)
(9.2.27)where
 is upper generation limits for the ith unit.
is upper generation limits for the ith unit. - Generating unit ramp rate limits:
 (9.2.28)
(9.2.28) (9.2.29)
(9.2.29)where UR i and DR i are ramp-up and ramp-down rate limits of the ith unit, respectively.
![$${\mathbf {x}}^{\mathrm {opt},k}=[x_1^{\mathrm {opt},k},\ldots ,x_n^{\mathrm {opt},k}]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq17.png) be a vector of variables which optimizes (either minimizes or maximizes) the kth objective function f
k(x). In other words, if the vector x
opt, k ∈ X
f is such that
be a vector of variables which optimizes (either minimizes or maximizes) the kth objective function f
k(x). In other words, if the vector x
opt, k ∈ X
f is such that

![$${\mathbf {f}}^{\mathrm {opt}}=[f_1^{\mathrm {opt}},\ldots ,f_m^{\mathrm {opt}}]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq18.png) (where
(where  denotes the optimum of the kth objective function) is ideal for an MOP, and the point in
denotes the optimum of the kth objective function) is ideal for an MOP, and the point in  which determined this vector is the ideal solution, and is consequently called the ideal vector.
which determined this vector is the ideal solution, and is consequently called the ideal vector.
However, due to objective conflict and/or interdependence among the n decision variables of x, such an ideal solution vector is impossible for MOPs: none of the feasible solutions allows simultaneous optimal solutions for all objectives [63].
In other words, individual optimal solutions for each objective are usually different. Thus, a mathematically most favorable solution should offer the least objective conflict.
Many real-life problems can be described as multiobjective optimization problems. The most typical multiobjective optimization problem is traveling salesman problem.

Let  be a set of cities, where c
i is the ith city and N
c is the number of all cities; A = {(r, s) : r, s ∈ C} be the edge set, and d(r, s) be a cost measure associated with edge (r, s) ∈ A.
be a set of cities, where c
i is the ith city and N
c is the number of all cities; A = {(r, s) : r, s ∈ C} be the edge set, and d(r, s) be a cost measure associated with edge (r, s) ∈ A.
For a set of N c cities, the TSP problem involves finding the shortest length closed tour visiting each city only once. In other words, the TSP problem is to find the shortest-route to visit each city once, ending up back at the starting city.
Euclidean TSP: If cities r ∈ C are given by their coordinates (x r, y r) and d(r, s) is the Euclidean distance between city r and s, then TSP is an Euclidean TSP.
Symmetric TSP: If d(r, s) = d(s, r) for all (r, s), then the TSP becomes a symmetric TSP (STSP).
Asymmetric TSP: If d(r, s) ≠ d(s, r) for at least some (r, s), then the TSP is an asymmetric TSP (ATSP).
Dynamic TSP: The dynamic TSP (DTSP) is a TSP in which cities can be added or removed at run time.
The goal of TSP is to find the shortest closed tour which visits all the cities in a given set as early as possible after each and every iteration.
Another typical example of multiobjective optimizations is multiobjective data mining.
Predictive or supervised techniques learn from the current data in order to make predictions about the behavior of new data sets.
Descriptive or unsupervised techniques provide a summary of the data.
- 1.Feature Selection: It deals with selection of an optimum relevant set of features or attributes that are necessary for the recognition process (classification or clustering). In general, the feature selection problem ( Ω, P) can formally be defined as an optimization problem: determine the feature set F ∗ for which
 (9.2.32)
(9.2.32)where Ω is the set of possible feature subsets, F refers to a feature subset, and
 denotes a criterion to measure the quality of a feature subset with respect to its utility in classifying/clustering the set of points X ∈ Ψ.
denotes a criterion to measure the quality of a feature subset with respect to its utility in classifying/clustering the set of points X ∈ Ψ. - 2.
Classification: The problem of supervised classification can formally be stated as follows. Given an unknown function g : X → Y (the ground truth) that maps input instances x ∈ X to output class labels y ∈ Y , and a training data set D = {(x 1, y 1), …, (x n, y n)} which is assumed to represent accurate examples of the mapping g, produce a function h : X → Y that approximates the correct mapping g as closely as possible.
- 3.Clustering: Clustering is an important unsupervised classification technique where a set of n patterns
 are grouped into clusters {C
1, …, C
K} in such a way that patterns in the same cluster are similar in some sense and patterns in different clusters are dissimilar in the same sense. The main objective of any clustering technique is to produce a K × n partition matrix U = [u
kj], k = 1, …, K;j = 1, …, n, where u
kj is the membership of pattern x
j to cluster C
k:
are grouped into clusters {C
1, …, C
K} in such a way that patterns in the same cluster are similar in some sense and patterns in different clusters are dissimilar in the same sense. The main objective of any clustering technique is to produce a K × n partition matrix U = [u
kj], k = 1, …, K;j = 1, …, n, where u
kj is the membership of pattern x
j to cluster C
k:
 (9.2.33)for hard or crisp partitioning of the data, and
(9.2.33)for hard or crisp partitioning of the data, and (9.2.34)
(9.2.34) (9.2.35)
(9.2.35)with
 for probabilistic fuzzy partitioning of the data.
for probabilistic fuzzy partitioning of the data. - 4.
Association Rule Mining: The principle of association rule mining (ARM) [1] lies in the market basket or transaction data analysis. Association analysis is the discovery of rules showing attribute-value associations that occur frequently. The objective of ARM is to find all rules of the form X ⇒ Y, X ∩ Y = ∅ with probability c%, indicating that if itemset X occurs in a transaction, the itemset Y also occurs with probability c%.
Most of the data mining problems can be thought of as optimization problems, while the majority of data mining problems have multiple criteria to be optimized. For example, a feature selection problem may try to maximize the classification accuracy while minimizing the size of the feature subset. Similarly, a rule mining problem may optimize several rule interestingness measures such as support, confidence, comprehensibility, and lift at the same time [110, 148].
9.3 Pareto Optimization Theory
Many real-world problems in artificial intelligence involve simultaneous optimization of several incommensurable and often competing objectives. In these cases, there may exist solutions in which the performance on one objective cannot be improved without reducing performance on at least one other. In other words, there is often no single optimal solution with respect to all objectives. In practice, there could be a number of optimal solutions in multiobjective optimization problems (MOPs) and the suitability of one solution depends on a number of factors including designer’s choice and problem environment. These solutions are optimal in the wider sense that no other solutions in the search space are superior to them when all objectives are considered. In these problems, the Pareto optimization approach is a natural choice. Solutions given by the Pareto optimization approach are called Pareto-optimal solutions that are closely related to Pareto concepts.
9.3.1 Pareto Concepts
Pareto concepts are named after Vilfredo Pareto (1848–1923). These concepts constitute the Pareto optimization theory for multiple objectives.
![$$\displaystyle \begin{aligned} {\mathrm{max/min}}_{\mathbf{x}\in S}\left \{\mathbf{f}(\mathbf{x})=[f_1(\mathbf{x}),\ldots ,f_m (\mathbf{x})]^T\right \} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ36.png)
Reformulation approach: This approach entails reformulating the problem as a single objective problem. To do so, additional information is required from the decision makers, such as the relative importance or weights of the objectives, goal levels for the objectives, value functions, etc.
Decision making approach: This approach requires that the decision makers interact with the optimization procedure typically by specifying preferences between pairs of presented solutions.
Pareto optimization approach: It finds a representative set of nondominated solutions approximating the Pareto front. Pareto optimization methods, such as evolutionary multiobjective optimization algorithms, allow decision makers to investigate the potential solutions without a priori judgments regarding to the relative importance of objective functions. Post-Pareto analysis is necessary to select a single solution for implementation.
On the other hand, the most distinguishing feature of single objective evolutionary algorithms (EAs) compared to other heuristics is that EAs work with a population of solutions, and thus are able to search for a set of solutions in a single run. Due to this feature, single objective evolutionary algorithms are easily extended to multiobjective optimization problems. Multiobjective evolutionary algorithms (MOEAs) have become one of the most active research areas in evolutionary computation.
To describe the Pareto optimality of MOP solutions in which we are interested, it needs the following key Pareto concepts: Pareto dominance, Pareto optimality, the Pareto-optimal set, and the Pareto front.
For the convenience of narration, denote x = [x
1, …, x
n]T ∈ F ⊆ S and ![$${\mathbf {x}}^{\prime }=[x_1^{\prime },\ldots ,x_n^{\prime }]^T \in F\subseteq S$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq25.png) , where F is the feasible region, in which the constraints are satisfied.
, where F is the feasible region, in which the constraints are satisfied.






It goes without saying that the above relations are available for f(x) = x and f(x′) = x′ as well. However, for two decision vectors x and x′, these relations are meaningless. In multiobjective optimization, the relation between decision vectors x and x′ are called the Pareto dominance which is based on the relations between vector objective functions.
- 1.
x is no worse than x′ in all objective functions, i.e., f i(x) ≤ f i(x′) for all i ∈{1, …, m},
- 2.
x is strictly better than x′ for at least one objective function, i.e., f j(x) < f j(x′) for at least one j ∈{1, …, m};




The Pareto dominance can be either weak or strong.





Two incomparable solutions x and x′ are also known as mutually nondominating.

A Pareto improvement is a change to a different allocation that makes at least one objective better off without making any other objective worse off. An trial solution is known as “Pareto efficient” or “Pareto-optimal” or “globally nondominated” when no further Pareto improvements can be made, in which case we are assumed to have reached Pareto optimality.

In other words, all decision vectors which are not dominated by any other decision vector are known as “nondominated” or Pareto optimal. The phrase “Pareto optimal” means the solution is optimal with respect to the entire decision variable space F unless otherwise specified.
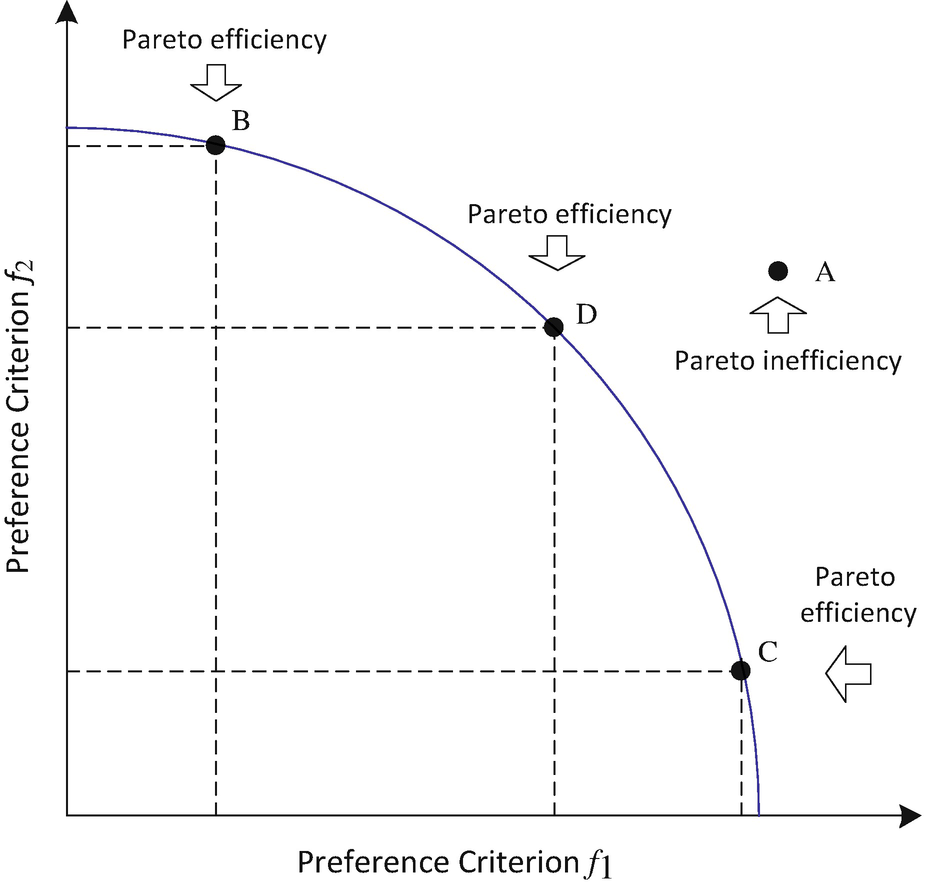
Pareto efficiency and Pareto improvement. Point A is an inefficient allocation between preference criterions f 1 and f 2 because it does not satisfy the constraint curve of f 1 and f 2. Two decisions to move from Point A to Points C and D would be a Pareto improvement, respectively. They improve both f 1 and f 2, without making anyone else worse off. Hence, these two moves would be a Pareto improvement and be Pareto optimal, respectively. A move from Point A to Point B would not be a Pareto improvement because it decreases the cost f 1 by increasing another cost f 2, thus making one side better off by making another worse off. The move from any point that lies under the curve to any point on the curve cannot be a Pareto improvement due to making one of two criterions f 1 and f 2 worse
A nondominated decision vector in A ⊆ X f is only Pareto-optimal in a local decision space A, while a Pareto-optimal decision vector is Pareto-optimal in entire feature decision space X f. Therefore, a Pareto-optimal decision vector is definitely nondominated, but a nondominated decision vector is not necessarily Pareto-optimal.
There may be a large number of Pareto-optimal solutions. To gain the deeper insight into the multiobjective optimization problem and knowledge about alternate solutions, there is often a special interest in finding or approximating the Pareto-optimal set.
Due to conflicting objectives it is only possible to obtain a set of trade-off solutions (referred to as Pareto-optimal set in decision space or Pareto-optimal front in objective space), instead of a single optimal solution.
Therefore our aim is to find the decision vectors that are nondominated within the entire search space. These decision vectors constitute the so-called Pareto-optimal set, as defined below.





 and
and  are the Pareto-optimal sets for minimization and maximization, respectively.
are the Pareto-optimal sets for minimization and maximization, respectively.Pareto-optimal decision vectors cannot be improved in any objective without causing a degradation in at least one other objective; they represent globally optimal solutions. Analogous to single-objective optimization problems, Pareto-optimal sets are divided into local and global Pareto-optimal sets.


The set of all objectives given by Pareto-optimal set of decision vectors is known as the Pareto-optimal front (or simply called Pareto front).

Solutions in the Pareto front represent the possible optimal trade-offs between competing objectives.
For a given system, the Pareto frontier is the set of parameterizations (allocations) that are all Pareto efficient or Pareto optimal. Finding Pareto frontiers is particularly useful in engineering. This is because that when yielding all of the potentially optimal solutions, a designer needs only to focus on trade-offs within this constrained set of parameters without considering the full range of parameters.
It should be noted that a global Pareto-optimal set does not necessarily contain all Pareto-optimal solutions.
Pareto-optimal solutions are those solutions within the genotype search space (i.e., decision space) whose corresponding phenotype objective vector components cannot be all simultaneously improved. These solutions are also called non-inferior, admissible, or efficient solutions [73] in the sense that they are nondominated with respect to all other comparison solution vector and may have no clearly apparent relationship besides their membership in the Pareto-optimal set.
A “current” set of Pareto-optimal solutions is denoted by P current(t), where t represents the generation number. A secondary population storing nondominated solutions found through the generations is denoted by P known, while the “true” Pareto-optimal set, denoted by P true, is not explicitly known for MOP problems of any difficulty. The associated Pareto front for each of P current(t), P known, and P true are termed as PF current(t), PF known, and PF true, respectively.
The decision maker is often selecting solutions via choice of acceptable objective performance, represented by the (known) Pareto front. Choosing an MOP solution that optimizes only one objective may well ignore “better” solutions for other objectives.
We wish to determine the Pareto-optimal set from the set X of all the decision variable vectors that satisfy the inequality constraints (9.2.21) and (9.2.22). But, not all solutions in the Pareto-optimal set are normally desirable or achievable in practice. For example, we may not wish to have different solutions that map to the same values in objective function space.
Lower and upper bounds on objective values of all Pareto-optimal solutions are given by the ideal objective vector f ideal and the nadir objective vectors f nad, respectively. In other words, the Pareto front of a multiobjective optimization problem is bounded by a nadir objective vector z nad and an ideal objective vector z ideal, if these are finite.




Nondominated set produced by heuristic algorithms is referred to as the archive (denoted by A) of the estimated Pareto front.
The archive of estimated Pareto fronts will only be an approximation to the true Pareto front.
Fitness selection approach,
Nondominated sorting approach,
Crowding distance assignment approach, and
Hierarchical clustering approach.
9.3.2 Fitness Selection Approach
To fairly evaluate the quality of each solution and make the solution set search in the direction of Pareto-optimal solution, how to implement fitness assignment is important.
There are benchmark metrics or indicators that play an important role in evaluating the Pareto fronts. These metrics or indicators are: hypervolume, spacing, maximum spread, and coverage [139].
 , its hypervolume (HV) is defined as
, its hypervolume (HV) is defined as

 is the area in the objective search space covered by the obtained Pareto front, and a
i is the hypervolume determined by the components of x
i and the origin.
is the area in the objective search space covered by the obtained Pareto front, and a
i is the hypervolume determined by the components of x
i and the origin.
 is the mean distance between all the adjacent solutions and m is the number of nondominated solutions in the Pareto front, and
is the mean distance between all the adjacent solutions and m is the number of nondominated solutions in the Pareto front, and

A value of spacing equal to zero means that all the solutions are equidistantly spaced in the Pareto front.


The value C(A, B) = 1 means that all solutions in B are weakly dominated by ones in A. On the other hand, C(A, B) = 0 means that none of the solutions in B is weakly dominated by A. It should be noted that both C(A, B) and C(B, A) have to be evaluated, respectively, since C(A, B) is not necessarily equal to 1 − C(B, A).
If 0 < C(A, B) < 1 and 0 < C(B, A) < 1, then neither A weakly dominates B nor B weakly dominates A. Thus, the sets A and B are incomparable, which means that A is not worse than B and vice versa.
- 1.
Binary tournament selection: k individuals are drawn from the entire population, allowing them to compete (tournament) and extract the best individual among them. The number k is the tournament size, and often takes 2. In this special case, we can call it binary tournament selection. Tournament selection is just the broader term where k can be any number ≥ 2.
- 2.Roulette wheel selection: It is also known as fitness proportionate selection which is a genetic operator for selecting potentially useful solutions for recombination. In roulette wheel selection, as in all selection methods, the fitness function assigns a fitness to possible solutions or chromosomes. This fitness level is used to associate a probability of selection with each individual chromosome. If F i is the fitness of individual i in the population, its probability of being selected is
 (9.3.36)
(9.3.36)where N is the number of individuals in the population.
Algorithm 9.1 gives a roulette wheel fitness selection algorithm.

9.3.3 Nondominated Sorting Approach
The nondominated selection is based on nondominated rank: dominated individuals are penalized by subtracting a small fixed penalty term from their expected number of copies during selection. But this algorithm failed when the population had very few nondominated individuals, which may result in a large fitness value for those few nondominated points, eventually leading to a high selection pressure.
Use a ranking selection method to emphasize good points.
Use a niche method to maintain stable subpopulations of good points.
If an individual (or solution) is not dominated by all other individuals, then it is assigned as the first nondominated level (or rank). An individual is said to have the second nondominated level or rank, if it is dominated only by the individual(s) in the first nondominated level. Similarly, one can define individuals in the third or higher nondominated level or rank. It is noted that more individuals maybe have the same nondominated level or rank. Let i rank represent the nondominated rank of the ith individual. For two solutions with different nondomination ranks, if i rank < j rank then the ith solution with the lower (better) rank is preferred.
Algorithm 9.2 shows a fast nondominated sorting approach.

In order to identify solutions of the first nondominated front in a population of size N P, each solution can be compared with every other solution in the population to find if it is dominated. At this stage, all individuals in the first nondominated level in the population are found. In order to find the individuals in the second nondominated level, the solutions of the first level are discounted temporarily and the above procedure is repeated for finding third and higher levels or ranks of nondomination.
9.3.4 Crowding Distance Assignment Approach
If the two solutions have the same nondominated rank (say i rank = j rank), which one should we choose? In this case, we need another quality for selecting the better solution. A natural choice is to estimate the density of solutions surrounding a particular solution in the population. For this end, the average distance of two points on either side of this point along each of the objectives needs to be calculated.
Let f 1 and f 2 be two objective functions in a multiobjective optimization problem, and let x, x i and x j be the members of a nondominated list of solutions. Furthermore, x i and x j are the nearest neighbors of x in the objective spaces. The crowding distance (CD) of a trial solution x in a nondominated set depicts the perimeter of a hypercube formed by its nearest neighbors (i.e., x i and x j) at the vertices in the fitness landscapes.
 denote the kth objective function of the ith individual, where i = 1, …, |I| and k = 1, …, K. Except for boundary individuals 1 and |I|, the ith individual in all other intermediate population set {2, …, |I|− 1} is assigned a finite crowded distance (CD) value given by Luo et al. [98]:
denote the kth objective function of the ith individual, where i = 1, …, |I| and k = 1, …, K. Except for boundary individuals 1 and |I|, the ith individual in all other intermediate population set {2, …, |I|− 1} is assigned a finite crowded distance (CD) value given by Luo et al. [98]:


 and
and  are the maximum and minimum values of the kth objective of all individuals, respectively.
are the maximum and minimum values of the kth objective of all individuals, respectively.
Algorithm 9.3 shows the crowding-distance-assignment (I).
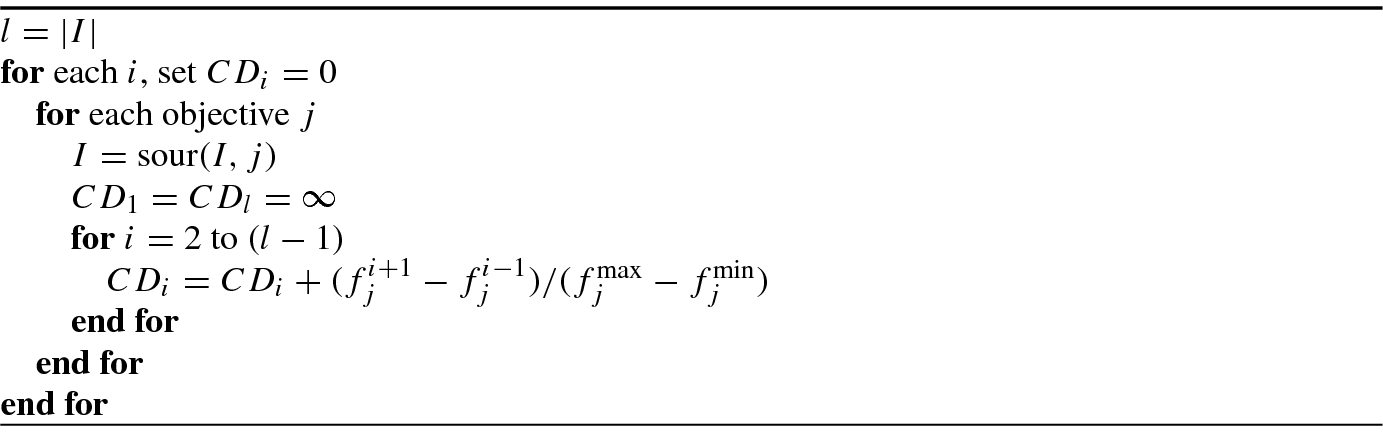
Between two populations with differing nondomination ranks, the population with the lower (better) rank is preferred. If both populations belong to the same front, then the population with larger crowding distance is preferred.
9.3.5 Hierarchical Clustering Approach
Cluster analysis can be applied to the results of a multiobjective optimization algorithm to organize or partition solutions based on their objective function values.
- 1.
Define decision variables, feasible set, and objective functions.
- 2.
Choose and apply a Pareto optimization algorithm.
- 3.Clustering analysis:
Clustering tendency: By visual inspection or data projections verify that a hierarchical cluster structure is a reasonable model for the data.
Data scaling: Remove implicit variable weightings due to relative scales using range scaling.
Proximity: Select and apply an appropriate similarity measure for the data, here, Euclidean distance.
Choice of algorithm(s): Consider the assumptions and characteristics of clustering algorithms and select the most suitable algorithm for the application, here, group average linkage.
Application of algorithm: Apply the selected algorithm to obtain a dendrogram.
Validation: Examine the results based on application subject matter knowledge, assess the fit to the input data and stability of the cluster structure, and compare the results of multiple algorithms, if used.
- 4.
Represent and use the clusters and structure: If the clustering is reasonable and valid, examine the divisions in the hierarchy for trade-offs and other information to aid decision making.
9.3.6 Benchmark Functions for Multiobjective Optimization
![$$\displaystyle \begin{aligned} \min~{\mathbf{f}}_2(x)=[g(x),h(x)]\quad \text{with }~g(x)=x^2,~h(x)=(x-2)^2, \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ75.png)
- 1.
- 2.
- 3.Constrained benchmark functions
- where x = [x 1, …, x n]T, the function f 1 is a function of the first decision variable x 1 only, g is a function of the remaining n − 1 variables x 2, …, x n, and the parameters of h are the function values of f 1 and g. For example,
 (9.3.47)
(9.3.47)where n = 30 and x i ∈ [0, 1]. The Pareto-optimal front is formed with g(x) = 1.
In this test, x is a 500-dimensional binary vector, a ij is the profit of item j according to knapsack i, b ij is the weight of item j according to knapsack i, and c i is the capacity of knapsack i (i = 1, 2 and j = 1, 2, …, 500).
- 4.
where x i ∈ [−103, 103].
- 5.Multiobjective benchmark functions for
![$$\min \mathbf {f}(\mathbf {x})=[f_1(\mathbf {x}),f_2 (\mathbf {x}),g_3 (\mathbf {x}),\ldots , g_m (\mathbf {x})]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq37.png)
where the value of α ∈ [0, 1] can be viewed as the correlation strength. α = 0 corresponds to the minimum correlation strength 0, where g i(x) is the same as the randomly generated objective f i(x). α = 1 corresponds to the maximum correlation strength 1, where g i(x) is the same as f 1(x) or f 2(x).
- where α ik is specified as follows:
 (9.3.52)For example, the four-objective problem is specified as
(9.3.52)For example, the four-objective problem is specified as (9.3.53)
(9.3.53)
![$$\min \, \mathbf {f}(\mathbf {x})=[g(\mathbf {x}),h(\mathbf {x})]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq34.png)



![$$\min \,\mathbf {f}(\mathbf {x})=[f_1(\mathbf {x}),f_2(\mathbf {x})]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq35.png)



![$$\displaystyle \begin{aligned} \left. \begin{aligned} &\max\ \mathbf{f}(\mathbf{x})=[f_1(\mathbf{x}),f_2(\mathbf{x})],\quad f_i(\mathbf{x})=\sum_{j=1}^{500}a_{ij}x_j,\, i=1,2\\ &\text{subject to}~ \sum_{j=1}^{500}b_{ij}x_j\leq c_i,\, i=1,2;\quad x_j=0~\text{or}~1,\,j=1,2,\ldots ,500, \end{aligned} \right\} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ83.png)
![$$\min \mathbf {f}(\mathbf {x})=[f_1(\mathbf {x}),\ldots ,f_m (\mathbf {x})]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq36.png)



More benchmark test functions can be found in [149, 165, 172]. Yao et al. [165] summarized 23 benchmark test functions.
9.4 Noisy Multiobjective Optimization
Optimization problems in various real-world applications are often characterized by multiple conflicting objectives and a wide range of uncertainty. Optimization problems containing uncertainty and multiobjectives are termed as uncertain multiobjective optimization problems. In evolutionary optimization community, uncertainty in the objective functions is generally stochastic noise, and the corresponding multiobjective optimization problems are termed as noisy (or imprecise) multiobjective optimization problems.
Noisy multiobjective optimization problems are also known as interval multiobjective optimization problems, since objectives f
i(x, c
i) contaminated by noise vector c
i can be reformulated, in interval-value form, as ![$$f_i(\mathbf {x},{\mathbf {c}}_i)=[ \underline {f}_i (\mathbf {x},{\mathbf {c}}_i),\overline {f}_i(\mathbf {x},{\mathbf {c}}_i)]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq38.png) .
.
9.4.1 Pareto Concepts for Noisy Multiobjective Optimization
- 1.
Noise, also referred to as aleatory uncertainty. Noise is an inherent property of the system modeled (or is introduced into the model to simulate this behavior) and therefore cannot be reduced. By Oberkampf et al. [117], aleatory uncertainty is defined as the “inherent variation associated with the physical system or the environment under consideration.”
- 2.
Imprecision, also known as epistemic uncertainty, describes not uncertainty due to system variance but the uncertainty of the outcome due to “any lack of knowledge or information in any phase or activity of the modeling process” [117].
Decision vector
 corresponding to different objectives is no longer a fixed point, but is characterized by (x, c) with c = [c
1, …, c
d]T that is a local neighborhood of x, where
corresponding to different objectives is no longer a fixed point, but is characterized by (x, c) with c = [c
1, …, c
d]T that is a local neighborhood of x, where ![$$c_i=[ \underline {c}_i,\overline {c}_i]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq40.png) is an interval with lower limits
is an interval with lower limits  and upper limit
and upper limit  for i = 1, …, d.
for i = 1, …, d.Objectives f i is no longer a fixed value f i(x), but is an interval of objective, denoted by
![$$f_i(\mathbf {x},\mathbf {c})=[ \underline {f}_i(\mathbf { x}, \mathbf {c}),\overline {f}_i(\mathbf {x},\mathbf {c})]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq43.png) .
.
![$$\displaystyle \begin{aligned} &{\mathrm{max/min}}\ \big\{\mathbf{f}=[f_1 (\mathbf{x},{\mathbf{c}}_1),\ldots ,f_m (\mathbf{x},{\mathbf{c}}_m)]^T\big\} ,{} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ89.png)
![$$\displaystyle \begin{aligned} &\text{subject to}~\,{\mathbf{c}}_i=[c_{i1},\ldots ,c_{il}]^T,\ c_{ij}=[\underline{c}_{ij},\overline{c}_{ij}],\quad \Big\{ \begin{aligned} &i=1,\ldots ,m,\\ &j=1,\ldots ,l, \end{aligned} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ90.png)
![$$f_i(\mathbf {x},{\mathbf {c}}_i)=[ \underline {f}_i(\mathbf {x},{\mathbf {c}}_i), \overline {f}_i(\mathbf {x},{\mathbf {c}}_i)]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq44.png) is the ith objective function with interval
is the ith objective function with interval ![$$[ \underline {f}_i,\overline {f}_i],\, i=1,\ldots ,m$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq45.png) (m is the number of objectives, and m ≥ 3); c
i is a fixed interval vector independent of the decision vector x (namely, c
i remains unchanged along with x), while
(m is the number of objectives, and m ≥ 3); c
i is a fixed interval vector independent of the decision vector x (namely, c
i remains unchanged along with x), while ![$$c_{ij}=[ \underline {c}_{ij}, \overline {c}_{ij}]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq46.png) is the jth interval parameter component of c
i.
is the jth interval parameter component of c
i.
For any two solutions x 1 and x 2 ∈ X of problem (9.4.1), the corresponding ith objectives are f i(x 1, c i) and f i(x 2, c i), i = 1, …, m, respectively.
![$$\mathbf {f}({\mathbf {x}}_1)=[ \underline {\mathbf {f}}({\mathbf {x}}_1),\overline {\mathbf {f}}({\mathbf {x}}_1)]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq47.png) and
and ![$$\mathbf {f}({\mathbf {x}}_2)=[ \underline {\mathbf {f}}({\mathbf {x}}_2),\overline {\mathbf {f}}({\mathbf {x}}_2)]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq48.png) . Their interval order relations are defined as
. Their interval order relations are defined as





In the absence of other factors (e.g., preference for certain objectives, or for a particular region of the trade-off surface), the task of an evolutionary multiobjective optimization (EMO) algorithm is to provide as good an approximation as the true Pareto front. To compare two evolutionary multiobjective optimization algorithms, we need to compare the nondominated sets they produce.
Since an interval is also a set consisting of the components larger than its lower limit and smaller than its upper limit, x 1 = (x, c 1) and x 2 = (x, c 2) can be regarded as two components in sets A and B, respectively. Hence, the decision solutions x 1 and x 2 are not two fixed points but two approximation sets, denoted as A and B, respectively.
Different from Pareto concepts defined by decision vectors in (precise) multiobjective optimization, the Pareto concepts in noisy (or imprecise) multiobjective optimization are called the Pareto concepts for approximation sets due to concept definitions for approximation sets.
To evaluate approximations to the true Pareto front, Hansen and Jaszkiewicz [64] define a number of outperformance relations that express the relationship between two sets of internally nondominated objective vectors, A and B. The outperformance is habitually called the dominance.









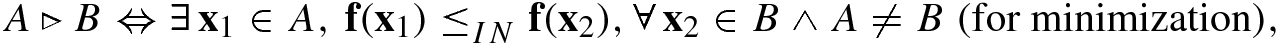
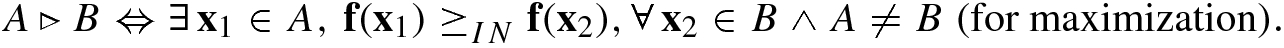
From the above definition of the relation ⊲, one can conclude that A ≽ B ⇒ A⊲B ∨ A = B. In other words, if A weakly dominates B, then either A is better than B or they are equal.
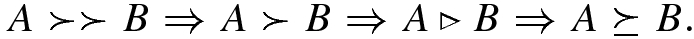

Relation comparison between objective vectors and approximation sets
Relation | Objective vectors | Approximation sets | ||
|---|---|---|---|---|
Weakly dominates | x ≽x ′ | x is not worse than x ′ | A ≽ B | Every f(x 2) ∈ B is weakly dominated by at least one f(x 1) in A |
Dominates | x ≻x ′ | x is not worse than x ′ in all objectives and better in at least one objective | A ≻ B | Every f(x 2) ∈ B is dominated by at least one f(x 1) in A |
Strictly dominates | x ≻≻x ′ | x is better than x ′ in all objectives | A ≻≻ B | Every f(x 2) ∈ B is strictly dominated by at least one f(x 1) |
Better | A⊲B | Every f(x 2) ∈ B is weakly dominated by at least one f(x 1) and A ≠ B | ||
Incomparable | x∥x ′ | x⋡x ′ ∧x ′ ⋡x | A∥B | A⋡B ∧ B⋡A |
A dominates B: the corresponding probabilities are P(A ≻ B) = 1, P(A ≺ B) = 0, and P(A ≡ B) = 0.
A is dominated by B: the corresponding probabilities are P(A ≺ B) = 1, P(A ≻ B) = 0, and P(A ≡ B) = 0.
A and B are nondominated each other: the corresponding probabilities are P(A ≻ B) = 0, P(A ≺ B) = 0, and P(A ≡ B) = 1.
The fitness of an individual in one population refers to as the direct competition (capability) with some individual(s) from another population. Hence, the fitness plays a crucial role in evaluating individuals in evolutionary process. When considering two fitness values A and B with multiple objectives, under the case without noise, there are three possible outcomes from comparing the two fitness values.
In noisy multiobjective optimization, in addition to the convergence, diversity, and spread of a Pareto front, there are two indicators: hypervolume and imprecision [96]. For convenience, we focus on the multiobjective maximization hereafter.
- 1.
The distance of the obtained nondominated front to the Pareto-optimal front should be minimized.
- 2.
A good (in most cases uniform) distribution of the solutions found—in objective space—is desirable.
- 3.
The extent of the obtained nondominated front should be maximized, i.e., for each objective, a wide range of values should be present.
The performance metrics or indicators play an important role in evaluating noisy multiobjective optimization algorithms [53, 89, 173].
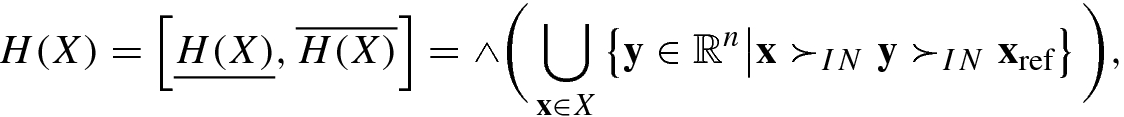
 and
and  are the worst-case and the best-case hypervolume, respectively.
are the worst-case and the best-case hypervolume, respectively.
![$$f_i (\mathbf {x},{\mathbf {c}}_i)=[ \underline {f}_i (\mathbf {x},{\mathbf {c}}_i),\overline {f}_i(\mathbf {x},{\mathbf {c}}_i)]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq51.png)
![$${\mathbf {c}}_i=[ \underline {\mathbf {c}}_i,\bar {\mathbf {c}}_i], i=1,\ldots ,m$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq52.png)
The smaller the value of the imprecision, the smaller the uncertainty of the front.
9.4.2 Performance Metrics for Approximation Sets
The performance metrics or indicators play an important role in noisy multiobjective optimization.

 and f
i denotes the ith objective functions with and without the additive noise, respectively. σ
2 is represented as a percentage of
and f
i denotes the ith objective functions with and without the additive noise, respectively. σ
2 is represented as a percentage of  , where
, where  is the maximum of the ith objective in true Pareto front.
is the maximum of the ith objective in true Pareto front.- 1.Proximity indicator: The metric of generational distance (GD) gives a good indication of the gap between the evolved Pareto front PF known and the true Pareto front PF true, and is defined as
 (9.4.24)
(9.4.24)where
 is the number of members in PF
known, d
i is the Euclidean distance (in objective space) between the member i of PF
known and its nearest member of PF
true. Intuitively, a low value of GD is desirable because it reflects a small deviation between the evolved and the true Pareto front. However, the metric of GD gives no information about the diversity of the algorithm under evaluation.
is the number of members in PF
known, d
i is the Euclidean distance (in objective space) between the member i of PF
known and its nearest member of PF
true. Intuitively, a low value of GD is desirable because it reflects a small deviation between the evolved and the true Pareto front. However, the metric of GD gives no information about the diversity of the algorithm under evaluation. - 2.Diversity indicator: To evaluate the diversity of an algorithm, the following modified maximum spread is used as the diversity indicator:
![$$\displaystyle \begin{aligned} \mathrm{MS}=\sqrt{\frac 1m\sum_{i=1}^m =\left [\big (\min \{f_i^{\max},F_i^{\max}\}-\min\{f_i^{\min},F_i^{\min}\}\big )/(F_i^{\max}-F_i^{\min})\right ]^2}, \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ113.png) (9.4.25)
(9.4.25)where m is the number of objectives,
 and
and  are, respectively, the maximum and minimum of the ith objective in PF
known; and
are, respectively, the maximum and minimum of the ith objective in PF
known; and  and
and  are the maximum and minimum of the ith objective in PF
true, respectively. This modified metric takes into account the proximity to FP
true.
are the maximum and minimum of the ith objective in PF
true, respectively. This modified metric takes into account the proximity to FP
true. - 3.Distribution indicator: To evaluate how evenly the nondominated solutions are distributed along the discovered Pareto front, the modified metric of spacing is defined as
 (9.4.26)
(9.4.26)where
 is the average Euclidean distance between all members of PF
known and their nearest members of PF
true.
is the average Euclidean distance between all members of PF
known and their nearest members of PF
true.
9.5 Multiobjective Simulated Annealing
Metropolis algorithm, proposed by Metropolis et al. in 1953 [100], is a simple algorithm that can be used to provide an efficient simulation of a collection of atoms in equilibrium at a given temperature. This algorithm was extended by Hastings in 1970 [65] to the more general case, and hence is also called Metropolis-Hastings algorithm. The Metropolis algorithm is the earliest simulated annealing algorithm that is widely used for solving multiobjective combinatorial optimization problems.
9.5.1 Principle of Simulated Annealing
The idea of simulated annealing originates from thermodynamics and metallurgy [153]: when molten iron is cooled slowly enough it tends to solidify in a structure of minimal energy. This annealing process is mimicked by a local search strategy; at the start, almost any move is accepted, which allows one to explore the solution space. Then, the temperature is gradually decreased such that one becomes more and more selective in accepting new solutions. By the end, only improving moves are accepted in practice.
- 1.
Exact procedures;
- 2.
Specialized heuristic procedures;
- 3.
Metaheuristic procedures.
The main disadvantage of exact algorithms is their high computational complexity and inflexibility.
A metaheuristic can be defined as an iterative generation process which guides a subordinate heuristic by combining intelligently different concepts for exploring and exploiting the search space [118]. Metaheuristic is divided into two categories: single-solution metaheuristic and population metaheuristic [51].
Single-solution metaheuristic considers a single solution (and search trajectory) at a time. Its typical examples include simulated annealing (SA), tabu search (TS), etc. Population metaheuristic evolves concurrently a population of solutions rather than a single solution. Most evolutionary algorithms are based on population metaheuristic.
The divide-and-conquer strategy divides the problem into subproblems of manageable size, then solves the subproblems. The solutions to the subproblems must be patched back together, and the subproblems must be naturally disjoint, while the division made must be appropriate, so that errors made in patching do not offset the gains obtained in applying more powerful methods to the subproblems.
Iterative improvement starts with the system in a known configuration, then a standard rearrangement operation is applied to all parts of the system in turn, until discovering a rearranged configuration that improves the cost function. The rearranged configuration then becomes a new configuration of the system, and the process is continued until no further improvements can be found. Iterative improvement makes a search in this coordinate space for rearrangement steps which lead to downhill. Since this search usually gets stuck in a local but not a global optimum, it is customary to carry out the process several times, starting from different randomly generated configurations, and save the best result.
By metaheuristic procedures, it means that they define only a “skeleton” of the optimization procedure that has to be customized for particular applications. The earliest metaheuristic method is simulated annealing [100]. Other metaheuristic methods include tabu search [52], genetic algorithms [55], and so on.
The goal of multiple-objective metaheuristic procedures is to find a sample of feasible solutions that is a good approximation to the efficient solutions set.
In physically appealing, particles are free to move around at high temperatures, while as the temperature is lowered they are increasingly confined due to the high energy cost of movement. From the point of view of optimization, the energy E(x) of the state x in physically appealing is regarded as the function to be minimized, and by introducing a parameter T, the computational temperature is lowered throughout the simulation according to an annealing schedule.

Any move leading to a negative value δE(x ′, x i) < 0 is an improving one and always be accepted (p = 1).
If δE(x ′, x i) > 0 is an positive value, then the probability to accept x ′ as a new current solution x i+1 is given by
 . Clearly, the higher the difference δE, the lower the probability to accept x
′ instead of x
i.
. Clearly, the higher the difference δE, the lower the probability to accept x
′ instead of x
i.δE(x ′, x i) = 0 implies that the new state x ′ is the same level of value as the current state x, there may exist two schemes—move to the new state x ′ or stay in the current state x i. The analysis of this problem shows that the move scheme is better than the stay one. In the stay scheme, search will end on both edges of the Pareto frontier not entering the middle of the frontier. However, if the move scheme is used, then search will be continue into the middle part of the frontier, move freely between nondominated states like a random walk when the temperature is low and eventually will be distributed uniformly over the Pareto frontier as time goes to infinity [114]. This result is in accordance with p = 1 given by (9.5.1).
The Boltzmann probability factor is defined as  , where E(x) is the energy of the solution x, and k
B is Boltzmann’s constant.
, where E(x) is the energy of the solution x, and k
B is Boltzmann’s constant.
At each T the simulated appealing algorithm aims at drawing samples from the equilibrium distribution  . As T → 0, any sample from P(E(x)) will almost surely lie at the minimum of E.
. As T → 0, any sample from P(E(x)) will almost surely lie at the minimum of E.
The simulated annealing consists of two processes: first “melting” the system being optimized at a high effective temperature, then lowering the temperature by slow stages until the system “freezes” and no further changes occur. At each temperature, the simulation must proceed long enough so that the system reaches a steady state. The sequence of temperatures and the number of rearrangements of {x i} attempted to reach equilibrium at each temperature can be thought of as an annealing schedule.
Intuitively, in addition to perturbations which decrease the energy, when T is high, perturbations from x to x ′ which increase the energy are likely to be accepted and the samples can explore the state space. However, as T is reduced, only perturbations leading to small increases in E are accepted, so that only limited exploration is possible as the system settles on (hopefully) the global minimum.
- 1.Decision Rule: In this rule, when moving from a current solution (or state) x i to the new solution x ′, the cost criterion is defined as
 (9.5.2)
(9.5.2) - 2.
Neighborhood V (x) is defined as a set of feasible solution close to x such that any solution satisfying the constraints of MOCO problems, D = {x : x ∈ LD, x ∈ B n} and LD = {x : Ax = b}, can be obtained after a finite number of moves.
- 3.Typical parameters: Some simulated annealing-typical parameters must be fixed as follows:
The initial temperature parameter T 0 or alternatively an initial acceptance probability p 0;
The cooling factor α (α < 1) and the temperature length step N step in the cooling schedule.
The stopping rule(s): final temperature T stop and/or the maximum number of iterations without improvement N stop.
Algorithm 9.4 shows a single-objective simulated annealing algorithm.

- 1.
Annealing differs from iterative improvement in that the procedure need not get stuck since transitions out of a local optimum are always possible at nonzero temperature.
- 2.
Annealing is an adaptive form of the divide-and-conquer approach. Gross features of the eventual state of the system appear at higher temperatures, while fine details develop at lower temperatures.
9.5.2 Multiobjective Simulated Annealing Algorithm
the concept of neighborhood;
acceptance of new solutions with some probability;
dependence of the probability on a parameter called the temperature; and
the scheme of the temperature changes.
As comparison with single-objective simulated annealing, population-based simulated annealing (PSA) uses also the following ideas:
- 1.
Apply the concept of a sample (population) of interacting solutions from genetic algorithms [55] at each iteration in simulated annealing. The solutions are called generate solutions.
- 2.
In order to assure dispersion of the generated solutions over the whole set of efficient solutions, one must control the objective weights used in the multiple objective rules for acceptance probability in order to increase or decrease the probability of improving values of the particular objectives.
If z k(x ′) ≤ z k(x n), ∀ k = 1, …, K then the move from x i to x ′ is an improvement with respect to all the objective δz k(x ′, x n) = z k(x ′) − z k(x n) ≤ 0, ∀k = 1, …, K. Therefore, x ′ is always accepted (p = 1).
An improvement and a deterioration can be simultaneously observed on different cost criteria δz k < 0 and
 . The first crucial point is how to define the acceptance probability p.
. The first crucial point is how to define the acceptance probability p.- When all cost criteria are deteriorated: ∀k, δz k ≥ 0 at least one strict inequality, a probability p to accept x ′ instead of x i must be calculated. LetFor the computation of the probability p, the second crucial point is how to compute the “distance” between z(x ′) and z(x i).
![$$\displaystyle \begin{aligned} \mathbf{z}({\mathbf{x}}^{\prime})=[z_1({\mathbf{x}}^{\prime}),\ldots ,z_K({\mathbf{x}}^{\prime})]^T\quad \text{and}\quad \mathbf{z}({\mathbf{x}}_i)=[z_1({\mathbf{x}}_i),\ldots ,z_K({\mathbf{x}}_i)]^T. \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ117.png) (9.5.3)
(9.5.3)
To overcome the above two difficulties, Ulungu et al. [153] proposed a criterion scalarizing approach in 1999.





- Weighed Chebyshev norm L ∞:where
 (9.5.12)
(9.5.12) are the cost (criterion) values of the ideal point
are the cost (criterion) values of the ideal point  .
.



It is easily shown [153] that the global acceptance probability p in (9.5.8) is just a most intuitive scalarizing function, i.e., p = t(Π, λ).
Searching precision: Because of problem complexity of multiobjective optimization, the algorithm finds hardly the Pareto-optimal solutions, and hence it must find the possible near solutions to the optimal solutions set.
Searching-time: The algorithm must find the optimal set efficiently during searching-time.
Uniform probability distribution over the optimal set: The found solutions must be widely spread, or uniformly distributed over the real Pareto-optimal set rather than converging to one point because every solution is important in multiobjective optimization.
Information about Pareto frontier: The algorithm must give as much information as possible about the Pareto frontier.
A multiobjective simulated annealing algorithm is shown in Algorithm 9.5.

- 1.
By using the concepts of Pareto optimality and domination, high searching precision can be achieved by simulated annealing.
- 2.
The main drawback of simulated annealing is searching-time, as it is generally known that simulated annealing takes long time to find the optimum.
- 3.
An interesting advantage of simulated annealing is its uniform probability distribution property as it is mathematically proved [50, 104] that it can find each of the global optima with the same probability in a scalar finite-state problem.
- 4.
For multiobjective optimization, as all the Pareto solutions have different cost vectors that have a trade-off relationship, a decision maker must select a proper solution from the found Pareto solution set or sometimes by interpolating the found solutions.
Therefore, in order to apply simulated annealing in multiobjective optimization, one must reduce searching-time and effectively search Pareto optimal solutions. It should be noted that any solution in the set PE of Pareto-optimal solutions should not be dominated by other(s), otherwise any dominated solution should be removed from PE. In this sense, Pareto solution set should be the best nondominated set.
9.5.3 Archived Multiobjective Simulated Annealing
In multiobjective simulated annealing (MOSA) algorithm developed by Smith et al. [145], the acceptance of a new solution x is determined by its energy function. If the true Pareto front is available, then the energy of a particular solution x is calculated as the total energy of all solutions that dominates x. In practical applications, as the true Pareto front is not available all the time, one must estimate first the Pareto front F ′ which is the set of mutually nondominating solutions found thus far in the process. Then, the energy of the current solution x is the total energy of nondominating solutions. These nondominating solutions are called the archival nondominating solutions or nondominating solutions in Archive.
In order to estimate the energy of the Pareto front F ′, the number of archival nondominated solutions in the Pareto front should be taken into consideration in MOSA. But, this is not done in MOSA.
By incorporating the nondominating solutions in the Archive, one can determine the acceptance of a new solution. Such an MOSA is known as archived multiobjective simulated annealing (AMOSA), which was proposed by Bandyopadhyay et al. in 2008 [7], see Algorithm 9.6.

HL: The maximum size of the Archive on termination. This set is equal to the maximum number of nondominated solutions required by the user;
SL: The maximum size to which the Archive may be filled before clustering is used to reduce its size to HL;
 : Maximum (initial) temperature,
: Maximum (initial) temperature,  : Minimal (final) temperature;
: Minimal (final) temperature;iter: Number of iterations at each temperature;
α: The cooling rate in SA.
![$$\bar {\mathbf {x}}^*=[\bar x_1^*,\ldots ,\bar x_n^*]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq70.png) denote the decision variable vector that simultaneously maximizes the objective values
denote the decision variable vector that simultaneously maximizes the objective values  , while satisfying the constraints, if any. In maximization problems, a solution
, while satisfying the constraints, if any. In maximization problems, a solution  is said to dominate
is said to dominate  if and only if
if and only if



One of the points, called current-pt, is randomly selected from Archive as the initial solution at temperature  . The current-pt is perturbed to generate a new solution called new-pt. The domination status of new-pt is checked with respect to the current-pt and solutions in Archive.
. The current-pt is perturbed to generate a new solution called new-pt. The domination status of new-pt is checked with respect to the current-pt and solutions in Archive.
Depending on the domination status between current-pt and new-pt, the new-pt is selected as the current-pt with different probabilities. This process constitutes the core of Algorithm 9.6, see Step 4 to Step 37.
9.6 Genetic Algorithm
A genetic algorithm (GA) is a metaheuristic algorithm inspired by the process of natural selection. Genetic algorithms are commonly used to generate high-quality solutions to optimization and search problems by relying on bio-inspired operators such as mutation, crossover, and selection.
In a genetic algorithm, a population of candidate solutions (called individuals, creatures, or phenotypes) to an optimization problem is evolved toward better solutions. Each candidate solution has a set of properties (its chromosomes or genotype) which can be mutated and altered; traditionally, solutions are represented in binary as strings of 0s and 1s, but other encodings are also possible.
The evolution is an iterative process: (a) It usually starts from a population of randomly generated individuals. The population in each iteration is known as a generation. (b) In each generation, the fitness of every individual in the population is evaluated. The fitness is usually the value of the objective function in the optimization problem being solved. (c) The fitter individuals are stochastically selected from the current population, and each individual’s genome is modified (recombined and possibly randomly mutated) to form a new generation. (d) This new generation of candidate solutions is then used in the next iteration of the algorithm. (e) The algorithm terminates when either a maximum number of generations has been produced, or a satisfactory fitness level has been reached for the population.
9.6.1 Basic Genetic Algorithm Operations
The genetic algorithm consists of encoded chromosome, fitness function, reproduction, crossover, and mutation operations generally.
A typical genetic algorithm requires three important concepts:
a genetic representation of the solution domain,
a fitness function to evaluate the solution domain, and
a notion of population. Unlike traditional search methods, genetic algorithms rely on a population of candidate solutions.
A genetic algorithm (GA) is a search technique used for finding true or approximate solutions to optimization and search problems. GAs are a particular class of evolutionary algorithms (EAs) that use inheritance, mutation, selection, and crossover (also called recombination) inspired by evolutionary biology.
GAs encode the solutions (or decision variables) of a search problem into finite-length strings of alphabets of certain cardinality. Candidate solutions are called individuals, creatures, or phenotypes. An abstract representation of individuals is called chromosomes, the genotype or the genome, the alphabets are known as genes and the values of genes are referred to as alleles. In contrast to traditional optimization techniques, GAs work with coding of parameters, rather than the parameters themselves.
One can think of a population of individuals as one “searcher” sent into the optimization phase space. Each searcher is defined by his genes, namely his position inside the phase space is coded in his genes. Every searcher has the duty to find a value of the quality of his position in the phase space.
To evolve good solutions and to implement natural selection, a measure is necessary for distinguishing good solutions from bad solutions. This measure is called fitness.
Once the genetic representation and the fitness function are defined, at the beginning of a run of a genetic algorithm a large population of random chromosomes is created. Each decoded chromosome will represent a different solution to the problem at hand.
When two organisms mate they share their genes. The resultant offspring may end up having half the genes from one parent and half from the other. This process is called recombination. Very occasionally a gene may be mutated.
Genetic algorithms are a way of solving problems by mimicking the same processes mother nature uses. They use the same combination of selection, recombination (i.e., crossover), and mutation to evolve a solution to a problem.
Each chromosome is made up of a sequence of genes from certain alphabet which can consist of binary digits (0 and 1), floating-point numbers, integers, symbols (i.e., A, B, C, D), etc.

This shows all the different genes required to encode the problem as described. The possible genes 1110, 1111 will remain unused and will be ignored by the algorithm if encountered.
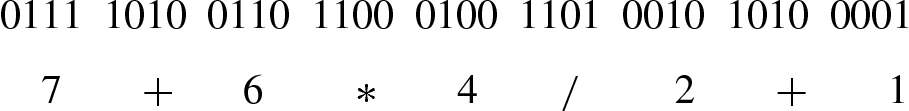


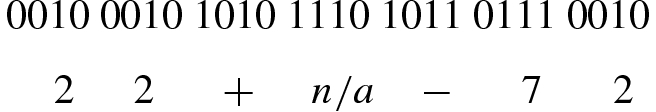
To evolve good solutions and to implement natural selection, we need a measure for distinguishing good solutions from bad solutions. In essence, the fitness measure must determine a candidate solution’s relative fitness, which will subsequently be used by the GA to guide the evolution of good solutions. This is one of the characteristics of the GA: it only uses the fitness of individuals to get the relevant information for the next search step.
To assign fitness, Hajela and Lin [61] proposed a weighed-sum method: Each objective is assigned a weight w i ∈ (0, 1) such that ∑iw i = 1, and the scalar fitness value is then calculated by summing up the weighted objective values w if i(x). To search multiple solutions in parallel, the weights are not fixed but coded in the genotype so that the diversity of the weight combinations is promoted by phenotypic fitness sharing [61, 169]. As a consequence, the fitness assignment evolves the solutions and weight combinations simultaneously.
Individuals are selected through a fitness-based process, where fitter individuals with lower inferior value are typically more likely to be selected. On the one hand, excellent individuals must be reserved to avoid too random search and low efficiency. On the other hand, these high-fitness individuals are not expected to over breed, avoiding the premature convergence of the algorithm. For simplicity and efficiency, an elitist selection strategy is employed. First, the individuals in the population p(t) are sorted from small to large according to the inferior value. Then the former 1∕10 of the sorted individuals are directly selected into the crossover pool. The remaining 9∕10 of individuals are gained by random competitions of all individuals in the population.
Crossover is a unique feature of the originality of GA in evolutionary algorithms. Genetic crossover is a process of genetic recombination that mimics sexual reproduction in nature. Its role is to inherit the original good genes to the next generation of individuals and to generate new individuals with more complex genetic structures and higher fitness value.

 is the maximum inferior value, and r
avg is the average inferior value of the population.
is the maximum inferior value, and r
avg is the average inferior value of the population.

It is seen from Eq. (9.6.1) for crossover probability that when the individual fitness value of the participating crossover is lower than the average fitness value of the population, i.e., the individual is a poor performing individual, a large crossover probability is adopted for it. When the individual fitness value of the crossover is higher than the average fitness value, i.e., the individual has excellent performance, then a small crossover probability is used to reduce the damage of the crossover operator to the better performing individual.
When the fitness values of the offspring generated by the crossover operation are no longer better than their parents, but the global optimal solution is not reached, the GA algorithm will occur premature convergence. At this time, the introduction of the mutation operator in the GA tends to produce good results.
Mutation in the GA simulates the mutation of a certain gene on the chromosome in the evolution of natural organisms in order to change the structure and physical properties of the chromosome.
On one hand, the mutation operator can restore the lost genetic information during population evolution to maintain individual differences in the population and prevent premature convergence. On the other hand, when the population size is large, for one to introduce moderate mutation after crossover operation, one can also improve the local search efficiency of the GA algorithm, thereby increasing the diversity of the population to reach the global domain of the search.

![$$\displaystyle \begin{aligned} P_m = P_{m0}[1-2(r_{\max}-r_{\min})/3(\mathrm{PopSize}-1)], \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ132.png)
 and
and  are, respectively, the maximum and minimum inferior value of the individual, PopSize is the number of individuals, and P
m0 is the mutation probability of the program.
are, respectively, the maximum and minimum inferior value of the individual, PopSize is the number of individuals, and P
m0 is the mutation probability of the program.
When the individual fitness value is lower than the average fitness value of the population, namely the individual has a poor performance, one adopts a large crossover probability and mutation probability.
If the individual fitness value is higher than the average fitness value, i.e., the individual’s performance is excellent, then the corresponding crossover probability and mutation probability are adaptively taken according to the fitness value.
When the individual fitness value is closer to the maximum fitness value, the crossover probability and the mutation probability are smaller.
If the individual fitness is equal to the maximum fitness value, then the crossover probability and the mutation probability are zero.
Therefore, individuals with optimal fitness values will remain intact in the next generation. However, this will allow individuals with the greatest fitness to rapidly multiply in the population, leading to premature convergence of the algorithm. Hence, this adjustment method is applicable to the population in the late stage of evolution, but it is not conducive to the early stage of evolution, because the dominant individuals in the early stage of evolution are almost in a state of no change, and the dominant individuals at this time are not necessarily optimized. The global optimal solution to the problem increases the likelihood of evolution to a locally optimal solution. To overcome this problem, we can use the default crossover probability p c = 0.8 and the default mutation probability p m = 0.001 for each individual, so that the crossover probability and mutation probability of individuals with good performance in the population are no longer zero.
9.6.2 Genetic Algorithm with Gene Rearrangement Clustering
Genetic clustering algorithms have a certain degree of degeneracy in the evolution process. The degeneracy problem is mainly caused by the non-one-to-one correspondence between the solution space of the clustering problem and the genetic individual coding in the evolution process [127].
The degeneracy of the evolutionary process usually causes the algorithm to search the local solution space repeatedly. Therefore, the search efficiency of the genetic clustering algorithm can be improved by avoiding the degeneracy of the evolution process.
To illustrate how the degeneracy occurs, consider a clustering problem in which a set of patterns is grouped into K clusters so that patterns in the same cluster are similar and differentiate from those of other clusters in some sense.
![$$\displaystyle \begin{aligned} \mathbf{x}&=[x_{11}^{\,} ,\ldots ,x_{1N}^{\,} ,\ldots ,x_{K1}^{\,} ,\ldots ,x_{KN}]=[{\mathbf{x}}_1,\ldots ,{\mathbf{x}}_K], \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ134.png)
![$$\displaystyle \begin{aligned} \mathbf{y}&=[y_{11}^{\,} ,\ldots ,y_{1N}^{\,} ,\ldots ,y_{K1}^{\,} ,\ldots ,y_{KN}]=[{\mathbf{y}}_1,\ldots ,{\mathbf{y}}_K], \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ135.png)
![$${\mathbf {x}}_i=[x_{i1}^{\,} ,\ldots ,x_{iN}^{\,} ]\in \mathbb {R}^{1\times N}, {\mathbf {y}}_i=[y_{i1}^{\,} ,\ldots ,y_{iN}^{\,} ]\in \mathbb {R}^{1\times N}$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq78.png) , and x is called a referenced vector. Let P
1 = {1, …, K} be a set of indexes of {x
1, …, x
K} and P
2 = ∅. Consider the rearrangement of P
1 to P
2:
, and x is called a referenced vector. Let P
1 = {1, …, K} be a set of indexes of {x
1, …, x
K} and P
2 = ∅. Consider the rearrangement of P
1 to P
2: for i = 1 to K do
 ,
,P 1 = P 1∖k and P 2(i) = k.
end for


![$$\tilde {\mathbf {y}}=[\tilde y_i]_{i=1}^N=[y_{P_2(i)}]_{i=1}^N$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq80.png) is called the gene rearrangement of the original chromosome y.
is called the gene rearrangement of the original chromosome y.The genetic algorithm with gene rearrangement (GAGR) clustering algorithm is given in Algorithm 9.7.

- 1.Chromosome representation: Extensive experiments comparing real-valued and binary GAs indicate [102] that the real-valued GA is more efficient in terms of CPU time. In real-valued gene representation, each chromosome constitutes a sequence of cluster centers, i.e., each chromosome is described by M = N ⋅ K real-valued numbers as follows:
![$$\displaystyle \begin{aligned} \mathbf{m}=[m_{11},\ldots ,m_{1N},\ldots ,m_{K1},\ldots ,m_{KN}^{\,} ]=[{\mathbf{m}}_1,\ldots ,{\mathbf{m}}_K], \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ138.png) (9.6.9)
(9.6.9)where N is the dimension of the feature space and K is the number of clusters; and the first N elements denote the first cluster center, the following N elements denote the second cluster center, and so forth.
- 2.
Population initialization: In GAGR clustering algorithm, an initial population of size N can be randomly generated and K data points randomly chosen from the data set, but on the condition that there are no identical points to form a chromosome, presenting the K cluster centers. This process is repeated until NP chromosomes are generated. Only valid strings (i.e., those that have at least one data point in each cluster) are considered to be included in the initial population.
After the population initialization, each data point is assigned to the cluster with closest cluster center using the following equation: (9.6.10)
(9.6.10)where m k is the center of the kth cluster.
- 3.Fitness function: The fitness function is used to define a fitness value to each candidate solution. A common clustering criterion or quality indicator is the sum of squared error (SSE) measure, defined as
 (9.6.11)where x ∈ C i is a data point assigned to that cluster. This measure computes the cumulative distance of each pattern from its cluster center of each cluster individually, and then sums those measures over all clusters. If this measure is small, then the distances from patterns to cluster centers are all small and the clustering would be regarded favorably. It is interesting to note that SSE has a theoretical minimum of zero, which corresponds to all clusters containing only a single data point. Then the fitness function of the chromosome is defined as the inverse of SSE, i.e.,
(9.6.11)where x ∈ C i is a data point assigned to that cluster. This measure computes the cumulative distance of each pattern from its cluster center of each cluster individually, and then sums those measures over all clusters. If this measure is small, then the distances from patterns to cluster centers are all small and the clustering would be regarded favorably. It is interesting to note that SSE has a theoretical minimum of zero, which corresponds to all clusters containing only a single data point. Then the fitness function of the chromosome is defined as the inverse of SSE, i.e., (9.6.12)
(9.6.12)This fitness function will be maximized during the evolutionary process and lead to minimization of the SSE.
- 4.Evolutionary operators:
- Crossover: Let x and y be two chromosomes to be crossed, then the heuristic crossover is given by
 (9.6.13)
(9.6.13) (9.6.14)
(9.6.14)where r = U(0, 1) with U(0, 1) being a uniform distribution on interval [0, 1] and x is assumed to be better than y in terms of the fitness.
- Mutation: Let
 and
and  be the minimum and maximum fitness values in the current population, respectively. For an individual with fitness value f, a number δ ∈ [−R, +R] is generated with uniform distribution, where R is given by Bandyopdhyay and Maulik [5]:
be the minimum and maximum fitness values in the current population, respectively. For an individual with fitness value f, a number δ ∈ [−R, +R] is generated with uniform distribution, where R is given by Bandyopdhyay and Maulik [5]:
 (9.6.15)If the minimum and maximum values of the data set along the ith dimension (i = 1, …, N) are
(9.6.15)If the minimum and maximum values of the data set along the ith dimension (i = 1, …, N) are and
and  , respectively, then after mutation the ith element of the individual is given by Bandyopdhyay and Maulik [5]:
, respectively, then after mutation the ith element of the individual is given by Bandyopdhyay and Maulik [5]:
 (9.6.16)
(9.6.16)
One key feature of gene rearrangement is to avoid the degeneracy resulted by the representations used in many clustering problems. The degeneracy mainly arises from a non-one-to-one correspondence between the representation and the clustering result. To illustrate this degeneracy, let m
1 = [1.1, 1.0, 2.2, 2.0, 3.4, 1.2] and m
2 = [3.2, 1.4, 1.8, 2.2, 0.5, 0.7] represent, respectively, two clustering results of a two-dimensional data set with three cluster centers in one generation. If m
1 is selected as the referenced vector, then m
2 becomes ![$${\mathbf {m}}_2^{\prime }= [0.5,0.7,1.8,2.2,3.2,1.4]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq85.png) after the gene rearrangement described by Definition 9.31.
after the gene rearrangement described by Definition 9.31.
 .
.
Illustration of degeneracy due to crossover (from [16]). Here, asterisk denotes three cluster centers (1.1, 1.0), (2.2, 2.0), (3.4, 1.2) for chromosome m
1, + denotes three cluster centers (3.2, 1.4), (1.8, 2.2), (0.5, 0.7) for the chromosome m
2, open triangle denotes the chromosome obtained by crossing m
1 and m
2, and open circle denotes the chromosome obtained by crossing m
1 and  with three cluster centers (0.5, 0.7), (1.8, 2.2), (3.2, 1.4)
with three cluster centers (0.5, 0.7), (1.8, 2.2), (3.2, 1.4)
From Fig. 9.3 we can see that the performance of the chromosome marked by triangles in the figure directly obtained from crossing m
1 and m
2 is poor as two of the three clusters are very close, producing some confusion, while the chromosome marked by circles in the figure obtained from m
1 and  with gene rearrangement is more efficient because of no confusion between any pair of clusters.
with gene rearrangement is more efficient because of no confusion between any pair of clusters.
Since there is a one-to-one correspondence between the representation and the clustering result through the gene rearrangement, there is no degeneracy, which makes the GAGR algorithm more efficient than the classical GA.
9.7 Nondominated Multiobjective Genetic Algorithms
In generation-based evolutionary algorithms (EAs) or genetic algorithms (GAs), the selected individuals are recombined (e.g., crossover) and mutated to constitute the new population. A designer/user prefers the more incremental, steady-state population update, which selects (and possibly deletes) only one or two individuals from the current population and adds the newly recombined and mutated individuals to it. Therefore, the selection of one or two individuals is a key step in generation-based EAs or GAs.
9.7.1 Fitness Functions
In the fields of genetic programming and genetic algorithms, each design solution is commonly represented as a string of numbers (called a chromosome). After each round of testing or simulation, the designer’s goal is to delete the “n” worst design solutions, and to breed “n” new ones from the best design solutions. To this end, each design solution needs to be evaluated by a figure of merit in order to determine how close it was to meeting the overall specification. This merit usually uses the fitness function to the test or simulation.
A fitness function, as a single figure of merit, is a particular type of objective function, and is used in genetic programming and genetic algorithms to guide simulations towards optimal design solutions.
According to “survival of the fittest” mechanism, a GA evaluates directly a solution by the fitness value of the solution. The GA requires only the fitness function to satisfy the nonnegativeness. This feature makes the genetic algorithm has wide applicability. Since a feasible solution x 1 ∈ X is said to (Pareto) dominate another solution x 2 ∈ X, if f i(x 1) ≤ f i(x 2) for all indices i ∈{1, …, k} and f j(x 1) < f j(x 2) for at least one index j ∈{1, …, k}, the objective function f i(x) can naturally be taken as the fitness function of a candidate solution x. However, in practical problems, the fitness function is not completely consistent with the objective function of the problem.
In GAs, fitness is the key indicator to describe the individual’s performance. Due to selecting the fittest based on fitness, it becomes the driving force of the genetic algorithm. From a biological point of view, the fitness is equivalent to the survival competition. The “survival” biological viability is of great significance in the genetic process. Mapping the objective function of an optimization problem to the individual’s fitness can be achieved by optimizing the objective function of the optimization problem in the process of group evolution. The function is also known as the evaluation function, which is a criterion for distinguishing good individuals from bad ones in a group according to the objective function. The fitness is always nonnegative. In any case, it is expected that the larger the fitness value, the better.
In the early stage of GA, some supernormal individuals are usually generated. These supernormal individuals will control the selection process due to their outstanding competitiveness, which affects the global optimization performance of the algorithm.
At the later stage of GA, if the algorithm tends to converge, then the potential for continued optimization is reduced and a certain local optimum solution may be obtained due to the small difference in individual fitness in the population. Therefore, if the fitness function is not properly selected, it will result in more than the problem of deception. The choice of fitness function can be seen as significant for genetic algorithms.
9.7.2 Fitness Selection
EAs/GAs are capable of solving complicated optimization tasks in which an objective function  will be maximized, where i ∈ I is an individual from the set of feasible solutions. A population is a multi-set of individuals which is maintained and updated as follows: one or more individuals are first selected according to some selection strategy. In generation-based EAs, the selected individuals are then recombined (e.g., via crossover) and mutated in order to constitute the new population. We prefer to select (and possibly delete) only one or two individuals from the current population and adds the newly recombined and mutated individuals to it. We are interested in finding a single individual of maximal objective value for difficult multimodal and deceptive problems.
will be maximized, where i ∈ I is an individual from the set of feasible solutions. A population is a multi-set of individuals which is maintained and updated as follows: one or more individuals are first selected according to some selection strategy. In generation-based EAs, the selected individuals are then recombined (e.g., via crossover) and mutated in order to constitute the new population. We prefer to select (and possibly delete) only one or two individuals from the current population and adds the newly recombined and mutated individuals to it. We are interested in finding a single individual of maximal objective value for difficult multimodal and deceptive problems.
- 1.Standard Selection Scheme: This scheme selects all favor individuals of higher fitness, and has the following variants:
Linear Proportionate Selection: In this method, the probability of selecting an individual depends linearly on its fitness [69].
Truncation Selection: In this selection the fittest individuals are selected, usually with multiplicity to keep the population size fixed [109].
Ranking Selection: This selection orders the individuals according to their fitness. The selection probability is, then, a (linear) function of the rank [157].
Tournament Selection: This method selects the best out of individuals. It has primarily developed for steady-state EAs, but can be adapted to generation based EAs [4].
- 2.
Fitness Uniform Selection Scheme (FUSS): FUSS is based on the insight that one is not primarily interested in a population converging to maximal fitness but only in a single individual of maximal fitness. The scheme automatically creates a suitable selection pressure and preserves genetic fitness values, and should help to preserve population diversity.
All above four standard selection schemes have the property (and goal) to increase the average fitness of a population, i.e., to evolve the population toward higher fitness [77].

Two individuals i and j are said to be 𝜖-similar if d(i, j) = |f(i) − f(j)|≤ 𝜖.
Let the lowest and highest fitness values in the current population be  and
and  , respectively.
, respectively.
Randomly select a fitness value f uniformly from the fitness values

![$$f_{\max }]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq93.png) .
.Select an individual i ∈ P with fitness nearest to f, and add a copy to the population P, possibly after mutation and recombination.
The probability of selecting a specific individual is proportional to the distance to its nearest fitness neighbor. In a population with a high density of unfitting and low density of fitting individuals, the more fitting ones are effectively favored.
To distinguish good solutions (individuals) from bad solutions, we need to make the fitness selection of individuals.
The fitness selection is a mathematical model or a computer simulation, or even is a subjective function for choosing better solutions over worse ones. In order to guide the evolution of good solutions in GAs, the fitness of every individual in the population is evaluated, multiple individuals are stochastically selected from the current population (based on their fitness), and modified (recombined and possibly mutated) to form a new population. The new population is then used in the next iteration of the GA. This iteration process is repeated until either a maximum number of generations has been produced, or a satisfactory fitness level has been reached for the population. However, if the algorithm has terminated due to a maximum number of generations, a satisfactory solution may or may not have been reached.
In contrast, we may also preserve diversity through deletion rather than selection, because we delete those individuals with “commonly occurring” fitness values. This method is called fitness uniform deletion scheme (FUDS) whose role is to govern actively different parts of the solution space rather than to move the population as a whole toward higher fitness [77]. Thus, FUDS is at least a partial solution to the problem of having to set correctly a selection intensity parameter.
A common fitness selection method is the Goldberg’s non-inferior sorting method for selecting the superior individuals [54]. Let x i(t) be an arbitrary individual in the population p(t) of tth generation, r i(t) indicate the number of individuals non-inferior to x i(t) in this population. Then, r i(t) is defined as the inferior value of the individual x i(t) in the population. Obviously, individuals with small inferior value are superior, and are close to the Pareto solutions. In the process of evolution, the whole population keeps approaching to the Pareto boundary.
9.7.3 Nondominated Sorting Genetic Algorithms
Different from single-objective optimization problems, the performance improvement of one objective is often inevitable at the cost of descending at least another objective in the multiobjective optimization problems. In other words, it is hard to identify a unique optimal solution but rather a family of optimal solutions called the Pareto-optimal front or nondominated set.
Multiobjective evolutionary algorithms (MOEAs) are a most popular approach to solving multiobjective optimization problems because MOEAs are able to find multiple Pareto-optimal solutions in one single run. Since it is not possible for a multiobjective optimization problem to have a single solution which simultaneously optimizes all objectives, an algorithm is of great practical value if it gives a large number of alternative solutions lying on or near the Pareto-optimal front.
Earlier practical GA, called Vector Evaluated Genetic Algorithm (VEGA), was developed by Schaffer in 1985 [141]. One of the problems with VEGA is its bias toward some Pareto-optimal solutions. A decision maker may want to find as many nondominated points as possible in order to avoid any bias toward such middling individuals.

A niched Pareto genetic algorithm combines tournament selection and the concept of Pareto dominance. For two competing individuals and a comparison set consisting of other individuals picked at random from the population, if one of the competing individuals is dominated by any member of the set, and the other is not, then the latter is chosen as winner of the tournament. If both individuals are dominated or not dominated, then the result of the tournament is decided by sharing: the individual which has the least individuals in its niche is selected for reproduction.
The niched Pareto genetic algorithm was proposed by Horn et al. in 1994 [74].
Nondominated sorting genetic algorithm (NSGA) differs from a simple genetic algorithm only in how the selection operator works. The crossover and mutation operators remain as usual: the population is ranked on the basis of an individual’s nondomination before the selection is performed. The nondominated individuals present in the population are first identified from the current population, then all these individuals are assumed to constitute the first nondominated front in the population and assigned a large dummy fitness value. If some nondominated individuals are assigned to the same fitness value, then all these nondominated individuals have an equal reproductive potential. To maintain diversity in the population, these classified individuals are then shared with their dummy fitness values.
Let the parameter d(x i, x j) be the phenotypic distance between two individuals x i and x j in the current front, and σ share be the maximum phenotypic distance allowed between any two individuals to become members of a niche.

For example,  is taken.
is taken.

Sharing is achieved by performing selection operation via degraded fitness values obtained by dividing the original fitness value of an individual by a quantity proportional to the number of individuals around it. This causes multiple optimal points to co-exist in the population. These shared nondominated individuals are ignored temporarily, and are then assigned a new dummy fitness value for keeping smaller than the minimum shared dummy fitness of the previous front. This process is continued until the entire population is classified into several fronts [146].
In multiobjective optimization genetic algorithm, the whole population is checked and all nondominated individuals are assigned rank 1. Other individuals are ranked according to the nondominance of them with respect to the rest of the population as follows. For an individual point, the number of points that strictly dominate the point in the population is first found. Then, the rank of that individual is assigned to be one more than that number. At the end of this ranking procedure, there could be a number of points having the same rank. The selection procedure then uses these ranks to select or delete blocks of points to form the mating pool.
Algorithm 9.8 shows the nondominated sorting genetic algorithm (NSGA) [146].

9.7.4 Elitist Nondominated Sorting Genetic Algorithm
High computational complexity of nondominated sorting: Computational complexity of ordinary nondominated sorting algorithm is O(kN 3), where k is the number of objectives and N is the population size.
Lack of elitism: Elitism can speed up the performance of the GA significantly, and also can help to prevent the loss of good solutions once they have been found.
Need for specifying the sharing parameter σ share: A parameterless diversity preservation mechanism is desirable.
To overcome the three shortcomings mentioned above, a fast and elitist multi-objective genetic algorithm (NSGA-II) was proposed by Deb et al. in 2002 [25]. Evolutionary multiobjective algorithms apply biologically inspired evolutionary processes as heuristics to generate nondominated sets of solutions. However, it should be noted that the solutions returned by evolutionary multiobjective algorithms may not be Pareto optimal (i.e., globally nondominated), but the algorithms are designed to evolve solutions that approach the Pareto front and spread out to capture the diversity existing on the Pareto front for obtaining a good approximation of the Pareto front [108].
The NSGA-II features nondominated sorting and a (μ + μ) (μ is the number of solution vectors) selection scheme. The secondary ranking criterion for solutions on the same front is called crowding distance. For a solution, the crowding distance is defined as the sum of the side lengths of the cuboid through the neighboring solutions on the front. For extremal solutions it is defined as infinity. The crowding distance value of a solution depends on its neighbors and not directly on the position of the point itself.
At the end of one generation of NSGA-II, the size of the population is twice bigger than the original size. This bigger population is pruned based on the nondominated sorting [80].
- 1.
Randomly generate the first generation.
- 2.
Partition the parents and offspring of the current generation into k fronts F 1, …, F k, so that the members of each front are dominated by all members of better fronts and by no members of worse fronts.
- 3.
Calculate the crowding distance for each potential solution: for each front, sort the members of the front according to each objective function from the lowest value to the highest value. Compute the difference between the solution and the closest lesser solution and the closest greater solution, ignoring the other objective functions. Repeat for each objective function. The crowding distance for that solution is the average difference over all the objective functions. Note that the extreme solutions for each objective function are always included.
- 4.Select the next generation based on nondomination and diversity:
Add the best fronts F 1, …, F j to the next generation until it reaches the target population size.
If part of a front, F j+1, must be added to the generation to reach the target population size, sort the members from the least crowded to most crowded. Then add as many members as are necessary, starting with the least crowded.
- 5.Generate offspring:
Apply binary tournament selection by randomly choosing two solutions and including the higher-ranked solution with a fixed probability 0.5–1.
Apply single-point crossover and the sitewise mutation to generate offspring.
- 6.
Repeat steps 2 through 5 for the desired number of generations.
9.8 Evolutionary Algorithms (EAs)
Optimization plays a very important role in engineering, operational research, information science, and related areas. Optimization techniques can be divided into two categories: derivative-based methods and derivative-free methods. As an important branch of derivative-free methods, evolutionary algorithms (EAs) have shown considerable success in solving optimization problems and attracted more and more attention.
Single objective evolutional algorithms are general purpose optimization heuristics inspired by Darwin’s principle of natural evolution. Starting with a set of candidate solutions (population), in each iteration (generation), the better solutions are selected (parents) according to their fitness (i.e., function values under the objective function) and used to generate new solutions (offspring) through recombining the information of two parents in a new way (crossover) or randomly modifying a solution (mutation). These offspring are then inserted into the population, replacing some of the weaker solutions (individuals) [13].
By iteratively selecting the better solutions and using them to create new candidates, the population “evolves,” and the obtained solutions become better and better adapted to the optimization problem at hand, just like in the nature, where the individuals become better and better adapted to their environment through evolution.
EAs have successfully employed on a wide variety of complex optimization problems because they can deal with almost arbitrarily complex objective functions and constraints, resulting into very few assumptions and not even requiring a mathematical description of the problem.
9.8.1 (1 + 1) Evolutionary Algorithm
- 1.
The size of the population is restricted to just one individual and does not use crossover.
- 2.
The current individual is represented as a bit string.
- 3.
Use bitwise mutation operator that flips each bit independently of the others with some probability p m.
- 4.
The current bit string is replaced by the new one if the fitness of the current bit string is not superior to the fitness of the new string. This replacement strategy selects the best individual of one parent and one child as the new generation.
(1 + 1) EA is shown in Algorithm 9.9.

The different choices of selection, crossover, mutation, replacement, and concrete representation of the individuals offer a great variety of different EAs.

 . The EA for solving the combinatorial optimization problem can be described as follows:
. The EA for solving the combinatorial optimization problem can be described as follows: - 1.
Initialization: generate, either randomly or heuristically, an initial population of 2N individuals, denoted by ξ 0 = (x 1, …, x 2N) (where N > 0 is an integer), and let k ← 0. For any population ξ k, define
 .
. - 2.
Generation: generate a new (intermediate) population by crossover and mutation (or any other operators for generating offspring), and denote it as ξ k+1∕2.
- 3.
Selection: select and reproduce 2N individuals from populations ξ k+1∕2 and ξ k, and obtain another (new intermediate) population ξ k+S.
- 4.
If
 , then stop; otherwise let ξ
k+1 = ξ
k+S and k ← k + 1, and go to step 2 to continue.
, then stop; otherwise let ξ
k+1 = ξ
k+S and k ← k + 1, and go to step 2 to continue.
9.8.2 Theoretical Analysis on Evolutionary Algorithms
Several different methods are widely used in the theoretical analysis of EAs.
Fitness partition method is the very basic method, in which the objective fitness domain is partitioned into several levels.
 . Suppose D can be partitioned into L subsets and for any solution x
i in subset i and x
j in subset j, we have f(x
i) < f(x
j) if i < j. In addition, subset L only contains optimal solution(s) of f. If an algorithm can jump from subset k to subset k + 1 or higher with probability at least p
k, then the total expected time for the algorithm to find the optimum satisfies
. Suppose D can be partitioned into L subsets and for any solution x
i in subset i and x
j in subset j, we have f(x
i) < f(x
j) if i < j. In addition, subset L only contains optimal solution(s) of f. If an algorithm can jump from subset k to subset k + 1 or higher with probability at least p
k, then the total expected time for the algorithm to find the optimum satisfies

By considering the expected progress achieved in a single step at each search point, drift analysis [60, 66] can be used to analyze problems which are hard to be analyzed by fitness partition.
Assume x
∗ is an optimal point, and let d(x, x
∗) be the distance between two points x and x
∗. If there are more than one optimal point (that is, a set S
∗), then  is used as the distance between individual x and the optimal set S
∗. Denote the distance by d(x). Usually d(x) satisfies d(x
∗) = 0 and d(x) > 0 for any x∉S
∗.
is used as the distance between individual x and the optimal set S
∗. Denote the distance by d(x). Usually d(x) satisfies d(x
∗) = 0 and d(x) > 0 for any x∉S
∗.


Define the stopping time of an EA as  , which is the first hitting time on the optimal solution. The drift analysis focuses on the following question [66]: under what conditions of the drift
, which is the first hitting time on the optimal solution. The drift analysis focuses on the following question [66]: under what conditions of the drift  can we estimate the expect first hitting time E[τ]?
can we estimate the expect first hitting time E[τ]?





9.9 Multiobjective Evolutionary Algorithms
Multiobjective evolutionary algorithms (MOEAs) have been shown to be well-suited for solving multiobjective optimization problems (MOPs) with conflicting objectives as they can approximate the Pareto-optimal front with a population in a single run.
9.9.1 Classical Methods for Solving Multiobjective Optimization Problems
- 1.Method of objective weighting: multiple objective functions are combined into one overall objective function:
 (9.9.1)
(9.9.1)where w i are fractional numbers (0 ≤ w i ≤ l), and all weights are summed up to 1, or
 . In this method, the optimal solution is controlled by the weigh vector w = [w
1, …, w
k]T: the preference of each objective f
i(x) can be changed by modifying its corresponding weight w
i.
. In this method, the optimal solution is controlled by the weigh vector w = [w
1, …, w
k]T: the preference of each objective f
i(x) can be changed by modifying its corresponding weight w
i.
- 2.Method of distance functions: the scalarization of objective vector f(x) = [f 1(x), …, f k(x)]T is achieved by using a demand-level vector
 which has to be specified by the decision maker as follows:
which has to be specified by the decision maker as follows:
 (9.9.2)
(9.9.2)where a Euclidean metric r = 2 is usually chosen, and the demand-level vector
 is individual optima of multiple objectives. The solution given by this method depends on the chosen demand-level vector. Arbitrary selection of a demand-level may be highly undesirable; a wrong demand-level will lead to a non-Pareto-optimal solution.
is individual optima of multiple objectives. The solution given by this method depends on the chosen demand-level vector. Arbitrary selection of a demand-level may be highly undesirable; a wrong demand-level will lead to a non-Pareto-optimal solution. - 3.Min-max formulation: this method attempts to minimize the relative deviations of the single objective functions from the individual optimum, namely it tries to minimize the objective conflict
 :
:
 (9.9.3)where Z j(x) is calculated for nonnegative target optimal value
(9.9.3)where Z j(x) is calculated for nonnegative target optimal value as follows:
as follows:
 (9.9.4)
(9.9.4)
Drawbacks of the above classical methods are: the optimization of the single objective may guarantee a Pareto-optimal solution, but results in a single-point solution. In real-world situations decision makers often need different alternatives in decision making. Moreover, if some of the objectives are noisy or have discontinuous variable space, then these methods may not work effectively.
Traditional search and optimization methods (such as gradient-based methods) are not available for extending to the multiobjective optimization because their basic design precludes the consideration of multiple solutions. In contrast, population-based methods (such as single objective evolutionary algorithms) are well-suited for handling such situations due to their ability to approximate the entire Pareto front in a single run [20, 24, 110].
The basic difference between multiobjective EAs from single objective EAs is how they rank and select individuals in the conflicting performance measures or objectives, many real-life multiobjective problems must be optimized simultaneously to achieve a trade-off.
a small distance of the solutions to the true Pareto frontier (such as dominated sorting solutions),
a wide range of solutions, i.e., an approximation of the extreme values (such as extreme solutions),
a good distribution of solutions, i.e., an even spread along the Pareto frontier (such as solutions with a larger distance to other solutions).
MOEAs then rank individuals according to how much they contribute to the above goals.
In MOEAs, the ability to balance between convergence and diversity depends on the selection strategy that can be broadly classified as: Pareto dominance-based MOEAs (PDMOEAs), indicator-based MOEAs, and decomposition-based MOEAs [119].
- 1.
Difficulties in searching for Pareto-optimal solutions.
- 2.
Difficulties in approximating the entire Pareto front.
- 3.
Difficulties in the presentation of obtained solutions.
- 4.
Difficulties in selecting a single final solution.
- 5.
Difficulties in the evaluation of search algorithms.
How to accomplish fitness assignment and selection, respectively, in order to guide the search towards the Pareto-optimal set.
How to maintain a diverse population in order to prevent premature convergence and achieve a well distributed trade-off front.
9.9.2 MOEA Based on Decomposition (MOEA/D)
![$$\displaystyle \begin{aligned} \min\ \mathbf{f}(\mathbf{x})=[f_1(\mathbf{x}),\ldots ,f_m (\mathbf{x})]^T,\quad \text{subject to}\ \mathbf{x}\in \Omega ,{} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ160.png)
 is the objective space, and
is the objective space, and  consists of m real-valued objective functions. If Ω is a closed and connected region in
consists of m real-valued objective functions. If Ω is a closed and connected region in  and all the objectives are continuous of x, then the above problem is known as a continuous MOP.
and all the objectives are continuous of x, then the above problem is known as a continuous MOP.A point x
∗∈ Ω is called (globally) Pareto optimal if there is no x ∈ Ω such that f(x) dominates f(x
∗), i.e., f
i(x) dominates f
i(x
∗) for each i = 1, …, m. The set of all the Pareto-optimal points is called the Pareto set. The set of all the Pareto objective vectors,  , is called the Pareto front.
, is called the Pareto front.
Decomposition is a basic strategy in traditional multiobjective optimization. But, general MOEAs treat a MOP as a whole, and do not associate each individual solution with any particular scalar optimization problem. A multiobjective evolutionary algorithm based on decomposition (called MOEA/D) [167] decomposes an MOP by scalarizing functions into a number of subproblems, each of which is associated with a search direction (or weight vector) and assigned a candidate solution.
- 1.Weighted sum approach: Let λ = [λ 1, …, λ m]T be a weight vector with λ i ≥ 0, ∀i = 1, …, m and
 . Then, the optimal solution to the scalar optimization problem
. Then, the optimal solution to the scalar optimization problem
 (9.9.6)
(9.9.6)is a Pareto-optimal point to the MOP (9.9.5).
- 2.Tchebycheff approach: This approach [103] can convert the problem of a Pareto-optimal solution of (9.9.5) into the scalar optimization problem:
 (9.9.7)where z = [z 1, …, z m]T is the reference point vector, i.e.,
(9.9.7)where z = [z 1, …, z m]T is the reference point vector, i.e., for each i = 1, …, m, and each optimal solution of (9.9.7) is a Pareto-optimal solution of (9.9.5), and thus one is able to obtain different Pareto-optimal solutions by altering the weight vector λ. Therefore, the Tchebycheff scalar optimization subproblem can be defined as [167]:
for each i = 1, …, m, and each optimal solution of (9.9.7) is a Pareto-optimal solution of (9.9.5), and thus one is able to obtain different Pareto-optimal solutions by altering the weight vector λ. Therefore, the Tchebycheff scalar optimization subproblem can be defined as [167]:
 (9.9.8)
(9.9.8)where λ i is a weight parameter for the ith objective, and
 is set to the current best fitness of the ith objective. Tchebycheff approach used in MOEA/D can decompose the original MOP into several scalar optimization subproblems in form of (9.9.8), which can be solved with any optimization method for single objective optimization.
is set to the current best fitness of the ith objective. Tchebycheff approach used in MOEA/D can decompose the original MOP into several scalar optimization subproblems in form of (9.9.8), which can be solved with any optimization method for single objective optimization. - 3.Boundary intersection (BI) approach: This approach solves the following scalar optimization subproblem:
 (9.9.9)The goal of the constraint z ∗−f(x) = dλ is to push f(x) as high as possible so that it reaches the boundary of the attainable objective set. In order to avoid the equality constraint in (9.9.9), one can use a penalty method to deal with the constraint [167]:
(9.9.9)The goal of the constraint z ∗−f(x) = dλ is to push f(x) as high as possible so that it reaches the boundary of the attainable objective set. In order to avoid the equality constraint in (9.9.9), one can use a penalty method to deal with the constraint [167]: (9.9.10)where θ > 0 is a preset penalty parameter, and
(9.9.10)where θ > 0 is a preset penalty parameter, and (9.9.11)
(9.9.11) (9.9.12)
(9.9.12)
Multiobjective evolutionary algorithm based on decomposition (MOEA/D), proposed by Zhang and Li [167], uses the Tchebycheff approach to convert the problem of a Pareto-optimal solution of (9.9.5) into the scalar optimization problem (9.9.8).
![$${\boldsymbol \lambda }^j=[\lambda ^j_1,\ldots ,\lambda _m^j]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq117.png) be a set of weight vectors and z
∗ be a reference point. The problem of approximation of the PF of (9.9.5) can be decomposed into scalar optimization subproblems by using the Tchebycheff approach and the objective function of the ith subproblem is given by
be a set of weight vectors and z
∗ be a reference point. The problem of approximation of the PF of (9.9.5) can be decomposed into scalar optimization subproblems by using the Tchebycheff approach and the objective function of the ith subproblem is given by

![$${\boldsymbol \lambda }^j =[\lambda _1^j,\ldots ,\lambda _m^j]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq118.png) .
.As g tc is continuous of λ, the optimal solution of g tc(x|λ i, z ∗) should be close to that of g tc(x|λ j, z ∗) if λ i and λ j are close to each other. This makes any information about these g tc’s with weight vectors close to λ i should be helpful for optimizing g tc(x|λ i, z ∗). This is a basic idea behind MOEA/D.
Let N be the number of the subproblems considered in MOEA/D, i.e., consider a population of N points x 1, …, x N ∈ Ω, where x i is the current solution to the ith subproblem.
In MOEA/D, a neighborhood of weight vector λ i is defined as a set of its closest weight vectors in {λ 1, …, λ N}. The neighborhood of the ith subproblem consists of all the subproblems with the weight vectors from the neighborhood of λ i. The population is composed of the best solution found so far for each subproblem. Only the current solutions to its neighboring subproblems are exploited for optimizing a subproblem in MOEA/D.
MOEA/D algorithm is shown in Algorithm 9.10.

The population in MOEA/D with simulated binary crossover may lose diversity, which is needed for exploring the search space effectively, particularly at the early stage of the search when applied to MOPs with complicated Pareto sets.
The simulated binary crossover operator often generates inferior solutions in MOEAs.
- 1.Differential evolution operator: Generate a solution
![$$\bar {\mathbf {y}}=[\bar y_1,\ldots ,\bar y_n]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq119.png) from three solutions
from three solutions  , and
, and  selected randomly from P by a DE operator. The elements of
selected randomly from P by a DE operator. The elements of ![$$\bar {\mathbf {y}}=[\bar y_1,\ldots ,\bar y_n]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq122.png) are given by
are given by
 (9.9.14)
(9.9.14)for j = 1, …, n, where CR and F are two control parameters.
- 2.Polynomial mutation operator: Generate y = [y 1, …, y n]T from
 in the following way:
in the following way:
 (9.9.15)with
(9.9.15)with (9.9.16)
(9.9.16)for j = 1, …, n, where rand is a uniform random number from [0, 1], the distribution index η and the mutation rate p m are two control parameters, and a j and b j are the lower and upper bounds of the kth decision variable, respectively.
a population of points x 1, …, x N ∈ Ω, where x i is the current solution to the ith subproblem;
fv 1, …, fv N, where fv i is the f-value of x i, i.e., fv i = [f 1(x i), …, f m(x i)]T for each i = 1, …, N;
z = [z 1, …, z m]T, where z i is the best value found so far for objective f i.

9.9.3 Strength Pareto Evolutionary Algorithm
It is widely recognized (e.g., see [45, 155]) that multiobjective evolutionary algorithms (MOEAs) can stochastically solve multiobjective optimization problems in an acceptable timeframe.
As their name implies, MOEAs are evolutionary computation based multiobjective optimization techniques.
General MOPs are mathematically defined as follows.
In general, a multiobjective optimization (MOP) minimizes f(x) = [f 1(x), …, f k(x)] subject to g i(x) ≤ 0, i = 1, …, m, x ∈ Ω. An MOP solution minimizes the components of a vector f(x), where x is an n-dimensional decision variable vector x = [x 1, …, x n]T from some universe Ω.
A priori preference articulation (Decide → Search): Decision making combines the differing objectives into a scalar cost function. This effectively makes the MOP a single-objective prior to optimization.
Progressive preference articulation (Search ↔ Decide): Decision making and optimization are intertwined. Partial preference information is provided upon which optimization occurs, providing an “updated” set of solutions for the decision making to consider.
A posteriori preference articulation (Search → Decide): A decision making is presented with a set of Pareto optimal candidate solutions and chooses from that set. However, note that most MOEA researchers search for and present a set of nondominated vectors (PF known) to the decision making.
As pointed out in [73] and [155], any practical MOEA implementation must include a secondary population composed of all Pareto-optimal solutions P known(t) found so far during search. This is because the MOEA is a stochastic optimization, which does not guarantee that desirable solutions, once found, remain in the generational population until MOEA termination. For this end, one needs to make fitness assignment.
- 1.
Each solution x i ∈ P′ is assigned a real value s i ∈ [0, 1), called strength; s i is proportional to the number of population members for which x i ≽x j. Let n denote the number of individuals in P that are covered by x i and assume N is the size of P. Then s i is defined as
 . The fitness F
i of x
i is equal to its strength: F
i = s
i.
. The fitness F
i of x
i is equal to its strength: F
i = s
i. - 2.The fitness of an individual j ∈ P is calculated by summing the strengths of all external nondominated solutions x i ∈ P′ that cover x j. The total fitness is added by 1 in order to guarantee that members of P′ have better fitness than members of P (note that fitness is to be minimized, i.e., small fitness values correspond to high reproduction probabilities):
 (9.9.17)
(9.9.17)
Store the nondominated solutions in P′ found so far externally.
Use the concept of Pareto dominance in order to assign scalar fitness values to individuals in P.
Perform clustering to reduce the number of nondominated solutions stored in P without destroying the characteristics of the trade-off front.
- (a)
It combines the above three techniques in a single algorithm.
- (b)
The fitness of an individual in P is determined only from the solutions stored in the external nondominated set P′; whether members of the population dominate each other is irrelevant.
- (c)
All solutions in the external nondominated set P′ participate in the selection.
- (d)
A niching method is provided in order to preserve diversity in the population P; this method is Pareto-based and does not require any distance parameter (like the niche radius for sharing).
Since SPEA uses a mixture of the three basic techniques in MOEAs in (a) and other three techniques (b)–(d), this MOEA method is a strength Pareto variant of MOEAs, and hence is named as SPEA.
Algorithm 9.12 shows the flow of the SPEA algorithm.

- (1)
Initialize cluster set C; each external nondominated point x i ∈ P′ constitutes a distinct cluster: C =⋃i{x i}.
- (2)
If |C|≤ N′ , go to Step (5), else go to Step (3).
- (3)Calculate the distance of all possible pairs of clusters. The distance d(c 1, c 2) of two clusters c 1, c 2 ∈ C is given as the average distance between pairs of individuals across the two clusters:
 (9.9.18)
(9.9.18)where |c i| denotes the number of individuals in class c i, i = 1, 2, the metric
 reflects the Euclidean distance between two individuals
reflects the Euclidean distance between two individuals  and
and  , and is called as the Euclidean metric on the objective space.
, and is called as the Euclidean metric on the objective space.
- (4)
Determine two clusters c 1 and c 2 with minimal distance d(c 1, c 2); the chosen clusters amalgamate into a larger cluster C = C ∖{c 1, c 2}∪{c 1 ∪ c 2}. Go to Step (2).
- (5)
Compute the reduced nondominated set by selecting a representative individual per cluster. Use the centroid (the point with minimal average distance to all other points in the cluster) as representative solution.
Consider an improvement of SPEA, called SPEA2.
In multiobjective evolutionary optimization, the approximation of the Pareto-optimal set involves itself two (possibly conflicting) objectives: the distance to the optimal front is to be minimized and the diversity of the generated solutions is to be maximized (in terms of objective or parameter values). In this context, there are three fundamental issues when designing a multiobjective evolutionary algorithm [172]: fitness assignment, environmental selection, and mating selection.
 and the population P
t is assigned a strength value S(i), representing the number of solutions it dominates:
and the population P
t is assigned a strength value S(i), representing the number of solutions it dominates:


The raw fitness is determined by the strengths of its dominators in both archive and population in SPEA2, while SPEA considers only archive members in this context.
Fitness is to be minimized in SPEA2, i.e., R(i) = 0 corresponds to a nondominated individual, while a high R(i) value means that i is dominated by many individuals (which in turn dominate many individuals).

 denotes the distance of i to its kth nearest neighbor in
denotes the distance of i to its kth nearest neighbor in  , and
, and  .
.

 ) the environmental selection step is completed. Otherwise, if the archive is too small (
) the environmental selection step is completed. Otherwise, if the archive is too small ( ), then the best
), then the best  dominated individuals in the previous archive
dominated individuals in the previous archive  and population are copied to the new archive
and population are copied to the new archive  . This can be implemented by sorting the multi-set
. This can be implemented by sorting the multi-set  according to the fitness values and copy the first
according to the fitness values and copy the first  individuals i with F(i) ≥ 1 from the resulting ordered list to
individuals i with F(i) ≥ 1 from the resulting ordered list to  . Conversely, if the archive is too large (
. Conversely, if the archive is too large ( ) then an archive truncation procedure is invoked which iteratively removes individuals from
) then an archive truncation procedure is invoked which iteratively removes individuals from  until
until  .
In other words, the individual which has the minimum distance to another individual is chosen at each stage; if there are several individuals with minimum distance, the tie is broken by considering the second smallest distances and so forth.
.
In other words, the individual which has the minimum distance to another individual is chosen at each stage; if there are several individuals with minimum distance, the tie is broken by considering the second smallest distances and so forth.The pool of individuals at each generation is evaluated in a two stage process. First all individuals are compared on the basis of the Pareto dominance relation, which defines a partial order on this multi-set. Basically, the information which decides how each individual dominates, is dominated by or is indifferent to, is used to define a ranking on the generation pool. Afterwards, this ranking is refined by the incorporation of density information. Various density estimation techniques are used to measure the size of the niche in which a specific individual is located.
Algorithm 9.13 summarizes the improved strength Pareto evolutionary algorithm (SPEA2).

An improved fitness assignment scheme is used, which takes for each individual into account how many individuals it dominates and it is dominated by.
A nearest neighbor density estimation technique is incorporated which allows a more precise guidance of the search process.
A new archive truncation method guarantees the preservation of boundary solutions.
9.9.4 Achievement Scalarizing Functions
 which map (or scalarize) k objective functions to a scalar. The achievement scalarizing problem is given by
which map (or scalarize) k objective functions to a scalar. The achievement scalarizing problem is given by

Certain properties of ASFs guarantee that scalarizing problem (9.9.24) yields Pareto-optimal solutions.
 is said to be
is said to be - 1.
Increasing: if for any
 for all i ∈{1, …, k}, then
for all i ∈{1, …, k}, then  .
.
- 2.
Strictly increasing: if for any
 for all i ∈{1, …, k}, then
for all i ∈{1, …, k}, then  .
.
- 3.
Strongly increasing: if for any
 for all i ∈{1, …, k} and y
1 ≠ y
2, then
for all i ∈{1, …, k} and y
1 ≠ y
2, then  .
.
Clearly, any strongly increasing ASF is also strictly increasing, and any strictly increasing ASF is also increasing. The following theorems define necessary and sufficient conditions for an optimal solution of (9.9.24) to be (weakly) Pareto optimal.


If  is strictly increasing and x
∗ ∈ X is weakly Pareto optimal, then it is a solution of (9.9.24) with the reference point f(x
∗) and the optimal value of s
R is zero.
is strictly increasing and x
∗ ∈ X is weakly Pareto optimal, then it is a solution of (9.9.24) with the reference point f(x
∗) and the optimal value of s
R is zero.


 is called the augmentation term, in which ρ > 0 is a small constant, and z
nad and z
utopian are the nadir vector and utopian vectors, respectively. In the above problem, the parameter is the so-called reference point
is called the augmentation term, in which ρ > 0 is a small constant, and z
nad and z
utopian are the nadir vector and utopian vectors, respectively. In the above problem, the parameter is the so-called reference point  which represents objective function values preferred by the decision maker.
which represents objective function values preferred by the decision maker.- 1.The strictly increasing ASF is of Chebyshev type:
 (9.9.27)
(9.9.27)where x ∗ is a reference point, and λ is k-vector of nonnegative coefficients used for scaling purposes, that is, for normalizing objective functions of different magnitudes.
- 2.The strongly increasing ASF is of augmented Chebyshev type:
 (9.9.28)
(9.9.28)where ρ > 0 is a small parameter.
- 3.
- 4.The parameterized ASF: Let
 be a subset of N
k = {1, …, k} of cardinality q. The parameterized ASF is defined as follows [116]:
be a subset of N
k = {1, …, k} of cardinality q. The parameterized ASF is defined as follows [116]:
![$$\displaystyle \begin{aligned} \tilde s_R^{\,\,q} (\mathbf{f}(\mathbf{x}),{\boldsymbol \lambda})=\max_{I_q\in N_k:|I_q|=q}\left\{\sum_{i\in I_q}\max [\lambda_i(f_i(\mathbf{x})-f_i({\mathbf{x}}^*) ),0]\right \}, \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ185.png) (9.9.30)where q ∈ N k and λ = [λ 1, …, λ k]T, λ i > 0, i ∈ N k. Notice that
(9.9.30)where q ∈ N k and λ = [λ 1, …, λ k]T, λ i > 0, i ∈ N k. Notice thatfor
 ;
;for
![$$q =1:~\tilde s_R^{\,1} (\mathbf {f}(\mathbf {x}),{\boldsymbol \lambda })=\max _{i\in N_k}\max [\lambda _i(f_i(\mathbf {x})-f_i ({\mathbf {x}}^*)),0]\cong s_R^{\infty } (\mathbf {f}(\mathbf {x}),{\boldsymbol \lambda })$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq158.png) ;
;for
![$$q =k:~\tilde s_R^{\,k}(\mathbf {f}(\mathbf {x}),{\boldsymbol \lambda })=\sum _{i\in N_k} \max [\lambda _i(f_i(\mathbf {x})-f_i ({\mathbf {x}}^*)),0]=s^1_R (\mathbf {f}(\mathbf {x}),{\boldsymbol \lambda })$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq159.png) .
.
Here, “≅” means equality in the case where there exist no feasible solutions x ∈ X which strictly dominate the reference point, i.e., such that f i(x) < f i(x ∗) for all i ∈ N k.

The performance of the additive ASF can be described by the following two theorems.
Given problem (9.9.24) with ASF defined by (9.9.29), let f(x ∗) be a reference point such that f(x ∗) is not dominated by an objective vector of any feasible solution of problem (9.9.24). Also assume λ i > 0 for all i ∈{1, …, k}. Then any optimal solution of problem (9.9.24) is a weakly Pareto-optimal solution.
Given problem (9.9.24) with ASF defined by (9.9.29) and any reference point f(x ∗), and assume λ i > 0 for all i ∈{1, …, k}. Then among the optimal solutions of problem (9.9.24) there exists at least one Pareto-optimal solution. If the optimal solution of problem (9.9.24) is unique, then it is Pareto optimal.

For any x ∈ X, denoting I x = {i ∈ N k : f i(x ∗) ≤ f i(x)}, then the following two results are true:
Given problem (9.9.31), let f(x ∗) be a reference point vector such that there exists no feasible solution whose image strictly dominates f(x ∗). Also assume λ i > 0 for all i ∈ N k. Then, any optimal solution of problem (9.9.31) is a weakly Pareto-optimal solution.
Given problem (9.9.31), let f(x ∗) be any reference point. Also assume λ i > 0 for all i ∈ N k. Then, among the optimal solutions of problem (9.9.31) there exists at least one Pareto-optimal solution.
Theorem 9.8 implies that the uniqueness of the optimal solution guarantees its Pareto optimality.
9.10 Evolutionary Programming
It is widely recognized [44] that evolutionary programming (EP) was first proposed as an approach to artificial intelligence. The EP has been applied with success to many numerical and combinatorial optimization problems.
9.10.1 Classical Evolutionary Programming
 formalized as a pair (S, f), where
formalized as a pair (S, f), where  with S being a bounded set on
with S being a bounded set on  and f is an n-dimensional real-valued function. Our aim is to find a point
and f is an n-dimensional real-valued function. Our aim is to find a point  such that
such that  is a global minimum on S, namely
is a global minimum on S, namely

mutate the solutions in the current population;
select the next generation from the mutated solutions and the current solutions.
There are the classical evolutionary programming (CEP) with self-adaptive mutation and the CEP without self-adaptive mutation. It is well-known (see, e.g., [3, 42, 165]) that the former usually performs better than the latter.
- 1.
Initialization: Generate the initial population of μ individuals, and set k = 1. Each individual is taken as a pair of real-valued vectors (x i, η i) (i = 1, …, μ), where x i are objective variables and η i are standard deviations for Gaussian mutations (also called strategy parameters in self-adaptive evolutionary algorithms).
- 2.
Evaluation of fitness: Use the objective function f(x i) to evaluate the fitness score for each individual (x i, η i), ∀ i = 1, …, μ.
- 3.Self-adaptive mutation: Each parent (x i(t − 1), η i(t − 1)), i = 1, …, μ at the tth generation creates a single offspring (x i(t), η i(t)) at the tth generation:
 (9.10.2)
(9.10.2) (9.10.3)
(9.10.3)for i = 1, …, μ; j = 1, …, n. Here
 and
and  denote the jth components of the parent vectors x
i(t − 1) and η
i(t − 1) at the (t − 1)th generations, respectively; and
denote the jth components of the parent vectors x
i(t − 1) and η
i(t − 1) at the (t − 1)th generations, respectively; and  and
and  are, respectively, the jth components of the offspring x
i(t) and η
i(t) at the tth generation; while N(0, 1) is a standard Gaussian distribution used for all j = 1, …, n, and N
j(0, 1) represents the standard Gaussian distribution used just for some given j. The factors are commonly set to
are, respectively, the jth components of the offspring x
i(t) and η
i(t) at the tth generation; while N(0, 1) is a standard Gaussian distribution used for all j = 1, …, n, and N
j(0, 1) represents the standard Gaussian distribution used just for some given j. The factors are commonly set to  and
and  .
. - 4.
Fitness for each offspring: Calculate the fitness of each offspring (x i(t), η i(t)), i = 1, …, μ.
- 5.
Pairwise comparison: Conduct pairwise comparison over the union of parents (x i(t − 1), η i(t − 1)) and offspring (x i(t), η(t)) for all i = 1, …, μ. For each individual, opponents are chosen uniformly at random from all the parents and offspring. For each comparison, if the individual’s fitness is no smaller than the opponent’s, it receives a “win.”
- 6.
Selection: Select the μ individuals out of (x i(t − 1), η i(t − 1)) and (x i(t), η i(t)), that have the most wins to be parents of the next generation.
- 7.
Stopping criteria: Stop if the halting criterion is satisfied; otherwise, k = k + 1 and go to Step 3, and repeat the above steps.
The feature of CEP is to use the standard Gaussian mutation operator N j(0, 1) in self-adaptive mutation (9.10.2).
9.10.2 Fast Evolutionary Programming



The main difference between the FEP and CEP is: the CEP mutation equation (9.10.2) is a self-adaption controlled by the Gaussian distribution N j(0, 1); while the FEP mutation equation (9.10.6) is a self-adaption controlled by the Cauchy random variable δ i.
It is known [165] that Cauchy mutation is more likely to generate an offspring further away from its parent than Gaussian mutation due to its long flat tails. It is expected to have a higher probability of escaping from a local optimum or moving away from a plateau, especially when the “basin of attraction” of the local optimum or the plateau is large relative to the mean step size. Therefore, the FEP is expected to be faster than the CEP from viewpoint of convergence.
- 1.
Generate an initial population of μ solutions (x i, η i), i ∈{1, …, μ}, and evaluate their fitness f(x i).
- 2.For every parent solution (x i, η i) in the population, create an offspring
 using
using

where x i(j), η i(j) denote the jth components of the parent vectors x i, η i, and
 are the jth components of the offspring
are the jth components of the offspring  , respectively; while N(0, 1) is sampled from a standard Gaussian distribution for all j = 1, …, n, and N
j(0, 1) is sampled from an another standard Gaussian distribution just for some given j, while C
j(0, 1) is sampled from a standard Cauchy distribution for each i and j. The factors τ and τ
′ are commonly set to
, respectively; while N(0, 1) is sampled from a standard Gaussian distribution for all j = 1, …, n, and N
j(0, 1) is sampled from an another standard Gaussian distribution just for some given j, while C
j(0, 1) is sampled from a standard Cauchy distribution for each i and j. The factors τ and τ
′ are commonly set to  and
and  .
. - 3.For every parent solution (x i, η i) in the population, create another offspring
 using
using

- 4.
Evaluate the fitness of offspring solutions
 and
and  .
. - 5.
Perform pairwise tournaments over the union of parents (x i, η i) and offspring (i.e.,
 and
and  . For each solution in the union, q opponents are chosen uniformly at random from the union. For every tournament, if the fitness of the solution is no smaller than the fitness of the opponent, it is awarded a “win.” The total number of wins awarded to a solution (x
i, η
i) is denoted by win(x
i, η
i).
. For each solution in the union, q opponents are chosen uniformly at random from the union. For every tournament, if the fitness of the solution is no smaller than the fitness of the opponent, it is awarded a “win.” The total number of wins awarded to a solution (x
i, η
i) is denoted by win(x
i, η
i). - 6.
Choose μ individual solutions from the union of parents and offspring at step 5. Chosen solutions will form the population of the next generation.
- 7.
Stop if the number of generations exceeds a predetermined number.
By performing on a number of benchmark problems, the experimental results show [165] that FEP with the Cauchy mutation operator C j(0, 1) performs much better than CEP with the Gaussian mutation operator for multimodal functions with many local minima while being comparable to CEP in performance for unimodal and multimodal functions with only a few local minima.
A comparative study of applications of Cauchy and Gaussian mutation operators in electromagnetics reported in [70] and [72] was also observed that Cauchy mutation operator performs better than its Gaussian counterpart for a number of unconstrained or weakly constrained antenna optimization problems, but it performs relatively poor for highly constrained problems.
9.10.3 Hybrid Evolutionary Programming

 , and h
1, …, h
m are functions on
, and h
1, …, h
m are functions on  for m ≤ n and
for m ≤ n and ![$$\mathbf {x}=[x_1,\ldots ,x_n]^T\in \mathbb {R}^n$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq183.png) and x ∈ F ⊆ S. A vector x is called a feasible solution to the optimization problem (P) if and only if x satisfies the r inequality constraints g
i(x) ≤ 0, i = 1, …, r and m equality constraints h
j(x) = 0, j = 1, …, m. When the collection of feasible solutions is empty, x is said to be infeasible. The set
and x ∈ F ⊆ S. A vector x is called a feasible solution to the optimization problem (P) if and only if x satisfies the r inequality constraints g
i(x) ≤ 0, i = 1, …, r and m equality constraints h
j(x) = 0, j = 1, …, m. When the collection of feasible solutions is empty, x is said to be infeasible. The set  defines the search space for x and the set F ⊆ S defines a feasible part of the search space S.
defines the search space for x and the set F ⊆ S defines a feasible part of the search space S.
![$$\displaystyle \begin{aligned} \varPhi_u (\mathbf{x})= \sum_{i=1}^r [g_i (\mathbf{x})]^+ \sum_{j=1}^m |h_j(\mathbf{x})|{} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ195.png)




Different from CEP and FEP whose each individual is a two-tuples of real-valued vectors (x
i, η
i), Myung et al. [112, 113] proposed an EP to update a triplet of real-valued vectors  , and named it as the hybrid evolutionary programming (HEP).
, and named it as the hybrid evolutionary programming (HEP).
In HEP, ![$$\bar {\mathbf {x}}_i=[x_i(1),\ldots ,x_i(n)]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq186.png) , while
, while  and
and  are the n-dimensional solution vector and its two corresponding strategy parameter vectors, respectively. Here
are the n-dimensional solution vector and its two corresponding strategy parameter vectors, respectively. Here  and
and  are initialized based on the specified search domains,
are initialized based on the specified search domains,  , which may be imposed at the initialized stage.
, which may be imposed at the initialized stage.
![$$\displaystyle \begin{aligned} x_i^{\prime}(j)&=x_i(j)+\sigma_i^{\prime}(j)[N_j (0,1)+\beta_i^{\prime}(j)C_j (0,1)],{} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ200.png)



9.11 Differential Evolution
Problems involving global optimization over continuous spaces are ubiquitous throughout the scientific community [147]. When the cost function is nonlinear and non-differentiable, one usually uses direct search approaches. Most standard direct search methods use the greedy criterion under which a new parameter vector is accepted if and only if it reduces the value of the cost function. Although the greedy decision process converges fairly fast, it is easily trapped in a local minimum.
- 1.
Ability to handle non-differentiable, nonlinear, and multimodal cost functions.
- 2.
Parallelizability to cope with intensive computation cost functions.
- 3.
Ease of use, i.e., few control variables to steer the minimization. These variables should also be robust and easy to choose.
- 4.
Good convergence properties, i.e., consistent convergence to the global minimum in consecutive independent trials.
A minimization method called “differential evolution” (DE) was designed by Storn and Price in 1997 [147] to fulfill all of the above requirements.
9.11.1 Classical Differential Evolution
![$$\displaystyle \begin{aligned} {\mathbf{p}}_i^G=[P_{1i}^G,\ldots ,P_{Di}^G]^T,\quad \forall\, i\in \{1,\ldots ,N_P\} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ204.png)
Solutions in DE are represented by D-dimensional vectors p
i, ∀ i ∈{1, …, N
P}. For each solution p
i, select three parents  , where i ≠ i
1 ≠ i
2 ≠ i
3.
, where i ≠ i
1 ≠ i
2 ≠ i
3.
Algorithm 9.14 gives the details of the classical DE algorithm, in which BFV: best fitness value so far, NFC: number of function calls, VTR: value to search, and MAXNFC: maximum number of function calls.

- 1.Mutation: For each target vector
 , create the mutant individual
, create the mutant individual  by adding a weighted difference vector between two individuals
by adding a weighted difference vector between two individuals  and
and  according to
according to
 (9.11.2)
(9.11.2)where F > 0 is a constant coefficient used to control the differential variation
 . The evolution optimization based on difference vector between two populations or solutions is known as the differential evolution.
. The evolution optimization based on difference vector between two populations or solutions is known as the differential evolution.
- 2.Crossover: Denote
![$${\mathbf {u}}_i^G=[U_{1i}^G,\ldots ,U_{Di}^G]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq198.png) . In order to increase the diversity of the perturbed parameter vectors, introduce crossover
. In order to increase the diversity of the perturbed parameter vectors, introduce crossover
 (9.11.3)
(9.11.3)for j = 1, 2, …, D, where randj(0, 1) is an uniformly distributed random number between 0 and 1, and j rand is a randomly chosen index to ensure that the trial vector
 does not duplicate
does not duplicate  . CR ∈ (0, 1) is the crossover rate.
. CR ∈ (0, 1) is the crossover rate. - 3.Selection: To decide whether or not it should become a member of the next generation G + 1, the trial vector
 is compared to the target vector
is compared to the target vector  according to the fitness values of the parent individual
according to the fitness values of the parent individual  and the trial individual
and the trial individual  , i.e.,
, i.e.,
 (9.11.4)
(9.11.4)Here
 is the offspring of
is the offspring of  for the next generation.
for the next generation.
9.11.2 Differential Evolution Variants





 is the best vector in the population.
is the best vector in the population.  , and
, and  are four different randomly selected vectors (where i ≠ r
1 ≠ r
2 ≠ r
3 ≠ r
4) from the current population.
are four different randomly selected vectors (where i ≠ r
1 ≠ r
2 ≠ r
3 ≠ r
4) from the current population.“a” specifies the vector which should be mutated; it can be the best vector (a = “best”) of the current population or a randomly selected one (a = “rand”).
“b” denotes the number of difference vectors which participate in the mutation (b = 1 or b = 2).
“c” denotes the applied crossover scheme, binary (c = “bin”) or exponential (c = “exp”).
The classical DE (9.11.5) with notation DE∕rand∕1∕bin and the scheme (9.11.7) with notation DE∕best∕2∕exp and exponential crossover are the most often used in practice due to their good performance [124, 166].
- 1.Neighborhood search differential evolution (NSDE): it has been shown to play a crucial role in improving evolutionary programming (EP) algorithm’s performance [165]. The neighborhood search differential evolution (NSDE) developed in [162] is the same as the above classical DE except for mutation (9.11.2) replaced by
 (9.11.10)
(9.11.10)Here
 , N(0.5, 0.5) denotes a Gaussian random number with mean 0.5 and standard deviation 0.5, and δ denotes a Cauchy random variable with scale parameter 1.
, N(0.5, 0.5) denotes a Gaussian random number with mean 0.5 and standard deviation 0.5, and δ denotes a Cauchy random variable with scale parameter 1. - 2.Self-adaptive differential evolution (SaDE): As compared with the classical DE of Storn and Price [147], the SaDE of Qin and Suganthan [125] has the following main differences: (a) SaDE adopts two different mutation strategies in single DE variant and introduces a probability p to control which mutation strategy to use, and p is gradually self-adapted according to the learning experience. (b) SaDE utilizes two methods to adapt and self-adapt DE’s parameters F and CR. The detailed operations of SaDE are summarized as follows:
- Mutation strategies self-adaptation: SaDE selects mutation strategies (9.11.5) and (9.11.7) as candidates to create the mutant individual:
 (9.11.11)Here, the probability p is updated as
(9.11.11)Here, the probability p is updated as (9.11.12)
(9.11.12)where ns1 and ns2 are, respectively, the number of offspring successfully entering the next generation while generated by Eqs. (9.11.5) and (9.11.7) after evaluation of all offspring; and both nf1 and nf2 are the numbers of offspring discarded while generated by Eqs. (9.11.5) and (9.11.7), respectively.
- Scale factor F setting:
 (9.11.13)
(9.11.13)where N i(0.5, 0.3) denotes a Gaussian random number with mean 0.5 and standard deviation 0.3.
- Crossover rate CR self-adaptation: SaDE allocates a CR i for each individuals:
 (9.11.14)with the updating formula
(9.11.14)with the updating formula (9.11.15)
(9.11.15)where CRm is set to 0.5 initially, and CRrec is the CR values associated with offspring successfully entering the next generation. CRrec will be reset once CRm is updated. This self-adaptation scheme for CR is denoted as SaCR.
- 3.
Self-adaptive NSDE (SaNSDE): This is an algorithm incorporating self-adaptive mechanisms into NSDE, see [166] for details.
On opposition-based differential evolution, an important extension to DE, we will present it in Sect. 9.15.
9.12 Ant Colony Optimization
In addition to evolutionary algorithms, another group of nature inspired metaheuristic algorithms is based on swarm intelligence in biology society.
- 1.
The concept of a swarm means multiplicity, stochasticity, randomness, and messiness.
- 2.
The concept of intelligence suggests that the problem-solving method is somehow successful.
The information-processing units that compose a swarm can be animate (such as ants, bees, fishes, etc.), mechanical, computational, or mathematical. Three famous swarm intelligence algorithms are ant colony algorithms, artificial bee colony algorithms, and swarm intelligence algorithms. In this section, we focus on ant colony algorithms.
The original inspired optimization idea behind ant algorithms came from observations of the foraging behavior of ants in the wild, and moreover, the phenomena called stigmergy [111]. By stigmergy, it means the indirect communication among a self-organizing emergent system via individuals modifying their local environment [59]. The stigmergic nature of ant colonies was explored by Deneubourg et al. in 1990 [27]: ants communicate indirectly by laying down pheromone trails, which ants then tend to follow.
Population-based algorithm: An algorithm working with a set of solutions and trying to improve them is called population based algorithm.
Iterative based algorithm: An algorithm using multiple iterations to approach the solution sought is named as iterative based algorithm.
Stochastic algorithm: An algorithm employing a probabilistic rule for improving a solution is called probabilistic or stochastic algorithm.
Deterministic algorithm: An algorithm employing a deterministic rule for improving a solution is known as deterministic algorithm.
The most popular population-based algorithm is evolutionary algorithms, and the most typical stochastic algorithms are swarm intelligence based algorithms. Both evolutionary algorithms and swarm intelligence based algorithms depend on the nature of phenomenon simulated by algorithms. As the most popular evolutionary algorithm, genetic algorithm attempts to simulate the phenomenon of natural evolution.
The two important swarm optimization algorithms are the ant colony optimization (ACO) algorithms and the artificial bee colony (ABC) algorithms. An ant colony can be thought of as a swarm whose individual agents are ants. Similarly, an artificial bee colony can be thought of as a swarm whose individual agents are bees.
Recently, ABC algorithm has been proposed to solve many difficult optimization problems in different fields such as constraint optimization problem, machine learning, and bioinformatics.
This section discusses ACO algorithms, and the next section discusses ABC algorithms.
9.12.1 Real Ants and Artificial Ants
In nature, the behavioral rules of ants are very simple, and their communication rules via “pheromones” are also very simple. However, a swarm of ants can solve very complex problems such as finding the shortest path between their nest and the food source. If finding the shortest path is looked upon as an optimization problem, then each path between the starting point (their nest) and the terminal (the food source) can be viewed as a feasible solution.
By using a transition rule that is a function of the distance to the source, an ant decides which food source to go and the amount of pheromone present along the connecting path.
Transitions to already visited food sources are added to a tabu list and are not allowed.
Once a tour is complete, the ant lays a pheromone trail along each path visited in the source.
By Beckers, Deneubourg, and Goss [9], it was demonstrated experimentally that ants are able to find the shortest path.
An ant searches for minimum cost feasible solutions
 .
.An ant k has an internal memory
 which is used to store the path information followed by the ant k so far (i.e., the previously visited states). Memory can be used to build feasible solutions, to evaluate the solution found, and to retrace the path backward.
which is used to store the path information followed by the ant k so far (i.e., the previously visited states). Memory can be used to build feasible solutions, to evaluate the solution found, and to retrace the path backward.An ant k in state S r,i can move from node i to any node j in its feasible neighborhood
 .
.
An ant k can be assigned a start state
 and one or more termination conditions e
k. Usually, the start state is expressed as a unit length sequence, that is, a single component.
and one or more termination conditions e
k. Usually, the start state is expressed as a unit length sequence, that is, a single component.
Starting from an initial state S initial, each ant tries to build a feasible solution to the given problem in an incremental way, moving to feasible neighbor states in an iterative fashion through its search space/environment. The construction procedure stops when for at least one ant k, at least one of the termination conditions e k is satisfied.
The guidance factors involved in an ant’s movement take the form of a transition rule which is applied before every move from state S i to state S j. The transition rule may also include additional problem specific constraints and may utilize the ants internal memory.
The ants’ probabilistic decision rule is a function of (a) the values stored in a node local data structure
![$${\mathbb {A}}_i= [a_{ij}]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq215.png) called ant-routing table, obtained by a functional composition of node locally available pheromone trails and heuristic values, (b) the ant’s private memory storing its past history, and (c) the problem constraints.
called ant-routing table, obtained by a functional composition of node locally available pheromone trails and heuristic values, (b) the ant’s private memory storing its past history, and (c) the problem constraints.
When moving from node i to neighbor node j the ant can update the pheromone trail τ ij on the arc (i, j). This is called online step-by-step pheromone update.
Once built a solution, the ants can retrace their same path backward and update the pheromone trails on the traversed arcs. This is called online delayed pheromone update.
The amount of pheromone each ant deposits is governed by a problem specific pheromone update rule.
Ants may deposit pheromone associated with states, or alternatively, with state transitions.
Once it has built a solution, and, if the case, after it has retraced the path back to the source node, the ant dies, freeing all the allocated resources.
- (a)
Artificial ants have a probabilistic preference for paths with a larger amount of pheromone.
- (b)
Shorter paths tend to have larger rates of growth in their amount of pheromone.
- (c)
Artificial ants use an indirect communication system based on the amount of pheromone deposited on each path.
By mimicking bionic swarm intelligence that simulates the behavior of ants and their communication ways in searching for food, ACO algorithms, as a heuristic positive feedback search algorithm, are especially available for solving the optimization problem including two parts: the feasible solution space and the objective function.
The key component of an ACO algorithm is a parameterized probabilistic model, which is called the pheromone model [30].
For a constrained combinatorial optimization problem, the central component of an ACO algorithm is also the pheromone model which is used to probabilistically sample the search space S.
- (1)
a search (or solution) space S defined over a finite set of discrete decision variables and a set Ω of constraints among the variables and
- (2)
an objective function
 to be minimized, which assigns a positive cost function to each solution s ∈ S.
to be minimized, which assigns a positive cost function to each solution s ∈ S.
A finite set
 of components is given.
of components is given.The states of the problem are defined in terms of sequences x = {c i, c j, …, c k, …} over the elements of C. The set of all possible sequences is denoted by X. The length of a sequence x, that is, the number of components in the sequence, is expressed by |x|. The maximum length of a sequence is bounded by a positive constant n < +∞.
The set of (candidate) solutions S is a subset of X (i.e., S ⊆ X).
The finite set of constraints Ω defines the set of feasible states
 with
with  .
.A non-empty set S ∗ of feasible solutions is given, with
 and S
∗⊆ S.
and S
∗⊆ S.A cost f(s, t) is associated with each candidate solution s ∈ S.
In some cases a cost, or the estimate of a cost, J(x i, t), can be associated with states other than solutions. If x i can be obtained by adding solution components to a state x j, then J(x i, t) ≤ J(x j, t). Note that J(s, t) ≡ J(t, s).
In combinatorial optimization a system may occur in many different configurations. Any configuration has a cost function for that particular configuration. Similar to the simulated annealing of solids, one can statistically model the evolution of the system to be optimized into a state that corresponds with the minimum cost function value.
In order to probabilistically construct solutions, ACO algorithms for combinatorial optimization problems use a pheromone model that consists of a set of pheromone values, i.e., a function of the search experience of the algorithm. The pheromone model is used to bias the solution construction toward regions of the search space containing high-quality solutions.
A search space S defined over a finite set of both discrete and continuous decision variables and a set Ω of constraints among the variables;
An objective function
 to be minimized. The search space S is defined by a set of n = d + r variables x
i, i = 1, …, n, of which d is the number of discrete decision variables and r is the number of continuous decision variables. A solution s ∈ S is a complete value assignment, that is, each decision variable is assigned a value. A feasible solution is a solution that satisfies all constraints in the set Ω. A global optimum s
∗∈ S is a feasible solution satisfying f(s
∗) ≤ f(s), ∀s ∈ S. The set of all globally optimal solutions is denoted by s
∗∈ S
∗⊆ S. Solving an MVOP requires finding at least one s
∗∈ S
∗.
to be minimized. The search space S is defined by a set of n = d + r variables x
i, i = 1, …, n, of which d is the number of discrete decision variables and r is the number of continuous decision variables. A solution s ∈ S is a complete value assignment, that is, each decision variable is assigned a value. A feasible solution is a solution that satisfies all constraints in the set Ω. A global optimum s
∗∈ S is a feasible solution satisfying f(s
∗) ≤ f(s), ∀s ∈ S. The set of all globally optimal solutions is denoted by s
∗∈ S
∗⊆ S. Solving an MVOP requires finding at least one s
∗∈ S
∗.
9.12.2 Typical Ant Colony Optimization Problems
Ant colony optimization is so called because of its original inspiration: some ant species forage between their nests and food sources by collectively exploiting the pheromone they deposit on the ground while walking [29]. Similar to real ants, artificial ants in ant colony optimization deposit artificial pheromone on the graph of the problem they are solving.
In ant colony optimization, each individual of the population is an artificial ant that builds incrementally and stochastically a solution to the considered problem. At each step the moves of ants define which solution components are added to the solution under construction.
A probabilistic model is associated with the graph G(C, L) and is used to bias the agents’ choices. The probabilistic model is updated online by the agents in order to increase the probability that future agents will build good solutions.
Ant solution construct: In the solution construction process, artificial ants move through adjacent states of a problem according to a transition rule, iteratively building solutions.
Pheromone update: It performs pheromone trail updates and may involve updating the pheromone trails once complete solutions have been built, or updating after each iteration.
Deamon actions: It is an optional step in the ant colony optimization and involves applying additional updates from a global perspective (there exists no natural counterpart). An example could be applying additional pheromone reinforcement to the best solution generated (known as offline pheromone trail update).
- 1.Job Scheduling Problems (JSP) [105] have a vital role in recent years due to the growing consumer demand for variety, reduced product life cycles, changing markets with global competition, and rapid development of new technologies. The job shop scheduling problem (JSSP) is one of the most popular scheduling models existing in practice, which is among the hardest combinatorial optimization problems. The job scheduling problem consists of the following components:
a number of independent (user/application) jobs to be the elements in C,
a number of heterogeneous machine candidates to participate in the planning,
the workload of each job (in millions of instructions),
the computing capacity of each machine,
ready time indicates when machine will have finished the previously assigned jobs, and
the expected time to compute (ETC) matrix (“n b” jobs × “n b” numbers of components machines) in which ETC[i][j] is the expected execution time of job “i” in machine “j.”
- 2.Data mining [122]: In an ant colony optimization algorithm, each ant incrementally constructs/modifies a solution for the target problem.
- In the context of classification task of data mining, the target problem is the discovery of classification rules that is often expressed in the form of IF-THEN rules as follows:

The rule antecedent (IF part) contains a set of conditions, usually connected by a logical conjunction operator (AND). The rule consequent (THEN part) specifies the class predicted for cases whose predictor attributes satisfy all the terms specified in the rule antecedent. As a promising research area, ACO algorithms involve simple agents (ants) that cooperate with others to achieve an emergent unified behavior for the system as a whole, producing a robust system capable of finding high-quality solutions for problems with a large search space.
In the context of rule discovery, an ACO algorithm is able to perform a flexible robust search for a good combination of terms (logical conditions) involving values of the predictor attributes.
- 3.
Network coding resource minimization (NCRM) problem [156]: As a resource optimization problem emerging from the field of network coding, although all nodes have the potential to perform coding would perform coding by default, only a subset of coding-possible nodes suffices to realize network coding-based multicast (NCM) with an expected data rate. Hence, it is worthwhile to study the problem of minimizing coding operations within NCM. EAs are the mainstream solutions for NCRM in the field of computational intelligence, but EAs are not good for integrating local information of the search space or domain-knowledge of the problem, which could seriously deteriorate their optimization performance. Different from EAs, ACO algorithms are the classes of reactive search optimization methods adopting the principle of “learning while optimizing.” ACOs may be a good candidate for solving the NCRM problem.
9.12.3 Ant System and Ant Colony System
As the first ant algorithm, ant system was developed by Dorigo et al. in 1996 [34] for applying the well-known benchmark traveling salesman problem.
Let τ ij be the pheromone trail between components (nodes) i and j that determines the path taken by the ants, and η ij = 1∕d ij be the heuristic values, where τ ij constitute the pheromone matrix T = [τ ij]. In other words, the shorter the distance d ij between two cities i and j, the higher the heuristic value η ij that constitutes the heuristic matrix.
- 1.Weighted sum: for example
 (9.12.1)
(9.12.1) - 2.Weighted product: for example
 (9.12.2)
(9.12.2) - 3.
Random: at each construction step, given a uniform random number U(0, 1), an ant selects the first of the two matrices if U(0, 1) < 1 − λ; otherwise, it selects the other matrix.
- 1.
 denotes a set of components, where c
i is the ith city and N
c is the number of all cities in tour.
denotes a set of components, where c
i is the ith city and N
c is the number of all cities in tour. - 2.
L is a set of connections fully connecting.
The ant always occupies a node in a graph which represents a search space. This node is called nf.
It has an initial state.
Although it cannot sense the whole graph, it can collect two kinds of information about the neighborhood: (a) the weight of each trail linked to nf and (b) the characteristics of each pheromone deposited on this trail by other ants of the same colony.
It moves toward a trail C ij that connects nodes i and j of the graph.
Also, it can alter the pheromones of the trail C ij, in an operation called as “deposit of pheromone levels.”
It can sense the pheromone levels of all C ij trails that connect a node i.
It can determine a set of “prohibited” trails.
It presents a pseudo-random behavior enabling the choice among the various possible trails.
This choice can be (and usually is) influenced by the level of pheromone.
It can move from node i to node j.
An ant system utilizes the graph representation G(C, L): for each cost measure δ(r, s) (distance from city r moving to city s), each edge (r, s) has also a desirability measure (called pheromone) τ rs = τ(r, s) which is updated at run time by ants.
- 1.
State transition rule: Each ant generates a complete tour by choosing the cities according to a probabilistic state transition rule; ants prefer to move to cities which are connected by short edges with a high amount of pheromone.
- 2.
Global (pheromone) updating rule: Once all ants have completed their tours, a global updating rule is used; a fraction of the pheromone evaporates on all edges, and then each ant deposits an amount of pheromone on edges which belong to its tour in proportion to how short its tour was. The process is then iterated.
- 3.Random-proportional rule: It gives the probability with which the kth ant in city r chooses to move to the city s:
![$$\displaystyle \begin{aligned} p_k^{\,} (r,s)=\begin{cases} \frac{\displaystyle [\tau (r,s)]\cdot [\eta (r,s)]^{\beta}}{\displaystyle\sum_{u\in J_k(r)}[\tau (r,u)]\cdot [\eta (r,u)]^{\beta}}, &\text{if }s\in J_k(r);\\ 0,&\text{otherwise}.\end{cases} {} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ221.png) (9.12.3)
(9.12.3)Here τ is the pheromone, η = 1∕δ is the inverse of the distance δ(r, s), J k(r, s) is the set of cities that remain to be visited by ant k positioned on city r (to make the solution feasible), and β > 0 is a parameter for determining the relative importance of pheromone versus distance.
In the way given by (9.12.3), the ants favor the choice of edges which are shorter and have a greater amount of pheromone.


State transition rule provides a direct way to balance between exploration of new edges and exploitation of a priori and accumulated knowledge about the problem.
Global updating rule is applied only to edges which belong to the best ant tour.
A local (pheromone) updating rule is applied while ants construct a solution.
- 1.ACS state transition rule: In ACS, an ant positioned on node r chooses the city s to move to by applying the ACS state transition rule given by
![$$\displaystyle \begin{aligned} s=\begin{cases} \operatorname*{\text{arg}~\text{max}}_{u\in J_k (r)}\left \{[\tau (r,u)]\cdot [\eta (r,u)]^\beta\right \},&\text{if }q\leq q_0 \ (\text{exploitation});\\ S,&\text{otherwise}.\end{cases}{} \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ224.png) (9.12.6)
(9.12.6)Here q is a random number uniformly distributed in [0, 1], 0 ≤ q 0 ≤ 1 is a parameter, and S is a random variable selected according to the probability distribution given in (9.12.3). The state transition rule given by (9.12.6) and (9.12.3) is known as pseudo-random-proportional rule. This rule favors transitions toward nodes connected by short edges and with a large amount of pheromone.
- 2.ACS global updating rule: In ACS only the globally best ant, constructed the shortest tour from the beginning of the trial, is allowed to deposit pheromone. After all ants have completed their tours, the pheromone level is updated by the following ACS global updating rule:
 (9.12.7)where
(9.12.7)where (9.12.8)
(9.12.8)Here 0 < α < 1 is the pheromone decay parameter, and L gb is the length of the globally best tour from the beginning of the trial.
- 3.ACS local updating rule: While building a solution (i.e., a tour) of the traveling salesman problem (TSP), ants visit edges and change their pheromone level by applying the following local updating rule:
 (9.12.9)
(9.12.9)where 0 < ρ < 1 is a parameter.
9.13 Multiobjective Artificial Bee Colony Algorithms
Artificial bee colony (ABC) algorithm, proposed by Karaboga in 2005 [81], is inspired by the intelligent foraging behavior of the honey bee swarm. Numerical comparisons show that the performance of ABC is competitive to that of other population-based algorithms with an advantage of employing fewer control parameters [82–84]. The main advantages of ABC are its simplicity and ease of implementation, but ABC also faces up to the poor convergence commonly existing in evolutionary algorithms.
9.13.1 Artificial Bee Colony Algorithms
An appropriate representation of the problem, which allows the ants to incrementally construct/modify solutions through the use of a probabilistic transition rule, based on the amount of pheromone in the trail and on a local problem-dependent heuristic.
A method to enforce the construction of valid solutions, i.e., solutions that are legal in the real-world situation corresponding to the problem definition.
A problem dependent heuristic function η that provides a quality measurement of items that can be added to the current partial solution.
A rule for pheromone updating, which specifies how to modify the pheromone trail τ.
A probabilistic transition rule based on the value of the heuristic function η and on the contents of the pheromone trail τ that is used to iteratively construct a solution.
A clear specification of when the algorithm converges to a solution.
Unlike ant swarms, the collective intelligence of honey bee swarms consists of three essential components: food sources, employed bees, unemployed (onlooker) bees.
In the ABC algorithm, the position of a food source represents a possible solution of the optimization problem and the nectar amount of a food source corresponds to the quality (fitness) of the associated solution. The artificial bee colony is divided into three groups of bees: employed bees, onlooker bees, and scout bees. Half of the colony consists of the employed bees, and another half consists of the onlookers.
Employed bees are responsible for exploring the nectar sources and sharing their food information with onlookers within the hive.
The onlooker bees select good food sources from those foods found by the employed bees to further search the foods.
If the quality of some food source is not improved through a predetermined number of cycles, then the food source is abandoned by its employed bee, and the employed bee becomes a scout and starts to search for a new food source randomly in the vicinity of the hive.
 , where the population size SN is identical to the number of those different kinds of bees. ABC generates a randomly distributed initial population P of SN solutions (food source positions) x
1, …, x
SN whose elements are as follows:
, where the population size SN is identical to the number of those different kinds of bees. ABC generates a randomly distributed initial population P of SN solutions (food source positions) x
1, …, x
SN whose elements are as follows:

 and
and  are the lower and upper bounds for the dimension j, respectively; and U(0, 1) is a random number with uniform distribution in (0, 1).
are the lower and upper bounds for the dimension j, respectively; and U(0, 1) is a random number with uniform distribution in (0, 1).After the initialization, the population of solutions (i.e., food sources) undergoes repeated cycles of the search processes of the employed bees, onlooker bees, and scout bees. Each employed bee always remembers its previous best position and produces a new position within its neighborhood in its memory.


![$${\mathbf {v}}_i=[v_{i1}^{\,} ,\ldots ,v_{iD}]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq226.png) from the old solution x
i in memory. Here, l ∈{1, …, SN} and j ∈{1, …, D} are randomly chosen indices, and ϕ
ij is a random number in the range [−1, 1].
from the old solution x
i in memory. Here, l ∈{1, …, SN} and j ∈{1, …, D} are randomly chosen indices, and ϕ
ij is a random number in the range [−1, 1].Then, ABC searches the area within its neighborhood to generate a new candidate solution. If a position cannot be improved further through a predetermined number of cycles, then that food source is said to be abandoned. The value of the predetermined number of cycles is an important control parameter of ABC, and is called the limit for abandonment. When the nectar of a food source is abandoned, the corresponding employed bee becomes a scout. The scout will randomly generate a new food source to replace the abandoned position.
The above framework of artificial bee colony (ABC) algorithm is summarized as Algorithm 9.15.

9.13.2 Variants of ABC Algorithms
The solution search equation of ABC, for generating new candidate solutions based on the information of previous solutions, is good at exploration, but it is poor at exploitation. To achieve good performance on problem optimizations, exploration and exploitation should be well balanced.
- 1.GABC: This a gbest-guided artificial bee colony algorithm [168]. By incorporating the information of the gbest solution into the solution search equation to improve the exploitation of ABC. The solution search equation in GABC is given by
 (9.13.4)
(9.13.4)where the third term in the right-hand side is a new added term called the gbest term, g j is the jth element of the gbest solution vector
 , ϕ
ij is a random number in the range [−1, 1], and ψ
ij is a uniform random number in [0, 1.5]. As demonstrated by experimental results, GABC can outperform ABC in most experiments.
, ϕ
ij is a random number in the range [−1, 1], and ψ
ij is a uniform random number in [0, 1.5]. As demonstrated by experimental results, GABC can outperform ABC in most experiments. - 2.IABC: This is an improved artificial bee colony (IABC) algorithm [48]. In this algorithm, two improved solution search equations are given by
 (9.13.5)
(9.13.5) (9.13.6)
(9.13.6)where the indices r1 and r2 are mutually exclusive integers randomly chosen from {1, 2, …, SN}, and both of them are different from the base index i; g best,j is the jth element of the best individual vector with the best fitness in the current population, and j ∈{1, …, D} is a randomly chosen index. Since (9.13.5) generates a candidate solution around g best, it focuses on the exploitation. On the other hand, as (9.13.6) is based on three vectors x i, x r1, and x r2, and the two latter ones are two different individuals randomly selected from the population, it emphasizes the exploration.
- 3.
where the indices r1 and r2 are distinct integers uniformly chosen from the range [1, SN] and are also different from i, and ϕ ij is a random number in the range [−1, 1]. Since (9.13.7) looks like the crossover operator of GA, the ABC with this search equation is named as crossover-like artificial bee colony (CABC) [49].

9.14 Particle Swarm Optimization
Particle swarm optimization (PSO) is a global optimization technique originally developed by Eberhart and Kennedy [36, 86] in 1995. PSO is essentially an optimization technique based on swarm intelligence, and adopts a population-based stochastic algorithm for finding optimal regions of complex search spaces through the interaction of individuals in a population of particles. Different from evolutionary algorithms, the particle swarm does not use selection operation; while interactions of all population members result in iterative improvement of the quality of problem solutions from the beginning of a trial until the end.
PSO is rooted in artificial life and social psychology, as well as in engineering and computer science. It is widely recognized (see, e.g., [19, 37, 85]) that swarm intelligence (SI) is an innovative distributed intelligent paradigm for solving optimization problems, and PSO was originally inspired by the swarming behavior observed in flocks of birds, swarms of bees, or schools of fish, and even human social behavior, from which the idea is emerged.
Due to computational intelligence, PSO is not largely affected by the size and nonlinearity of the optimization problem, and can converge to the optimal solution in many problems where most analytical methods fail to converge.
In PSO, the term “particles” refers to population members with an arbitrarily small mass or volume and is subject to velocities and accelerations towards a better mode of behavior.
9.14.1 Basic Concepts
- 1.
Social concepts: It is known [37] that “human intelligence results from social interaction.” Evaluation, comparison, and imitation of others, as well as learning from experience allow humans to adapt to the environment and determine optimal patterns of behavior, attitudes, and so on.
- 2.Swarm intelligence principles [ 37, 85, 86]: Swarm Intelligence can be described by considering the following five fundamental principles.
Proximity principle: the population should be able to carry out simple space and time computations.
Quality principle: the population should be able to respond to quality factors in the environment.
Diverse response principle: the population should not commit its activity along excessively narrow channels.
Stability principle: the population should not change its mode of behavior whenever the environment changes.
Adaptability principle: the population should be able to change its behavior mode when it is worth the computational price.
- 3.Computational characteristics [ 37]: As a useful paradigm for implementing adaptive systems, the swarm intelligence computation is an extension of evolutionary computation and includes the softening parameterization of logical operators like AND, OR, and NOT. In particular, PSO is an extension, and a potentially important incarnation of cellular automata (CA). The particle swarm can be conceptualized as cells in CA, whose states change in many dimensions simultaneously. Both PSO and CA share the following computational attributes.
Individual particles (cells) are updated in parallel.
Each new value depends only on the previous value of the particle (cell) and its neighbors.
All updates are performed according to the same rules.
9.14.2 The Canonical Particle Swarm
 , each having D features. Then partitional clustering approach aims at clustering the data set into K groups (K ≤ N) such that
, each having D features. Then partitional clustering approach aims at clustering the data set into K groups (K ≤ N) such that


The clustering operation is dependent on the similarity between elements present in the data set. If f denotes the fitness function, then the clustering task can be viewed as an optimization problem:  . That is to say, the optimization based clustering task is carried out by single objective nature inspired metaheuristic algorithms.
. That is to say, the optimization based clustering task is carried out by single objective nature inspired metaheuristic algorithms.
PSO is inspired by social interaction (e.g., foraging process of bird flocking). The original concept of PSO is to simulate the behavior of flying birds and their means of information exchange to solve problems. In PSO, each single solution is like a “bird.” Imagine the following scenario: a group of birds are randomly searching food in an area in which only one piece of food is assumed to exist, and the birds do not know where the food is. An efficient strategy for finding the food is to follow the bird nearest to the food.
In a particle swarm optimizer, instead of using genetic operators, each single solution is regarded as a “bird” (particle or individual) in the search space. These individuals are “evolved” by cooperation and competition among the individuals themselves through generations. Each particle adjusts its flying according to its own flying experience and its companions’ flying experience. Each individual or particle represents a potential solution to an optimization problem, and is treated as a point in a D-dimensional space.
N p: the swarm (or population) size;
x i(t): the position vector of the ith particle at time t in the search space;
v i(t): the velocity vector of the ith particle at time t in the search space;
![$${\mathbf {p}}_{i,best}^{\,} (t)=[p_{i1}^{\,} (t),\ldots ,p_{iD}^{\,} (t)]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq230.png) : the previous best position (the position giving the best fitness value, simply named pbest) of the ith particle (up to time t) in the search space;
: the previous best position (the position giving the best fitness value, simply named pbest) of the ith particle (up to time t) in the search space;![$${\mathbf {g}}_{best}=[g_1^{\,} ,\ldots ,g_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq231.png) : the best particle found so far among all the particles in the population, and is named as the global best position (gbest) vector of the swarm;
: the best particle found so far among all the particles in the population, and is named as the global best position (gbest) vector of the swarm;
U(0, β): a uniform random number generator;
α: inertia weight or constriction coefficient;
β: acceleration constant.
Position and velocity of each particle are adjusted, and the fitness function with the new position is evaluated at each time step. A population of particles at the time t is initialized with random position of the ith particle at the time t, ![$${\mathbf {x}}_i(t)=[x_{i1}(t),\ldots , x_{iD}(t)]^T\in \mathbb {R}^D$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq232.png) , and the velocity of the ith particle at the time t,
, and the velocity of the ith particle at the time t, ![$${\mathbf {v}}_i(t)=[v_{i1}(t),\ldots ,v_{iD}(t)]^T\in \mathbb {R}^{D}$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq233.png) .
.


By Clerc and Kennedy [19], though there is variety in the implementations of the particle swarm, the most standard version uses α = 0.7298 and β = ψ∕2, where ψ = 2.9922.


The basic particle swarm optimization algorithm is shown in Algorithm 9.16.

9.14.3 Genetic Learning Particle Swarm Optimization
PSO is easier to implement and there are fewer parameters to adjust.
In PSO, every particle remembers its own previous best value as well as the neighborhood best; therefore, it has a more effective memory capability than the GA.
PSO is more efficient in maintaining the diversity of the swarm [38] (more similar to the ideal social interaction in a community), since all the particles use the information related to the most successful particle in order to improve themselves, whereas in GA, the worse solutions are discarded and only the good ones are saved; therefore, in GA the population evolves around a subset of the best individuals.
- 1.The swarm may prematurely converge.
For the global best PSO, particles converge to a single point, which is on the line between the global best and the personal best positions. This point is not guaranteed for a local optimum [154].
The fast rate of information flow between particles, resulting in the creation of similar particles with a loss in diversity that increases the possibility of being trapped in local optima.
- 2.
Stochastic approaches have problem-dependent performance. This dependency usually results from the parameter settings in each algorithm. Increasing the inertia weight will increase the speed of the particles resulting in more exploration (global search) and less exploitation (local search) will decrease the speed of the particles resulting in more exploitation and less exploration.
In general PSO, particles are guided by their previous best positions (pbests) and the global best position (gbest) found by the swarm, so the search is more directional than that of GA. Hence, it is expected that GA possesses a better exploration ability than PSO, whereas the latter facilitates faster convergence.
By applying crossover operation in GA, information can be swapped between two particles to have the ability to fly to the new search area. If applying mutation used in GA to PSO, then it is expected to increase the diversity of the population and the ability to have the PSO to avoid the local maxima.
This hybrid of genetic algorithm and particle swarm optimization is simply called GA-PSO, which combines the advantages of swarm intelligence and a natural selection mechanism in GA, and thus increases the number of highly evaluated agents, while decreases the number of lowly evaluated agents at each iteration step.
An alternative of GA-PSO is the genetic learning particle swarm optimization (GL-PSO) in [57], as shown in Algorithm 9.17.

The GL-PSO is an optimization algorithm hybridized by genetic learning and particle swarm optimization hybridized in a highly cohesive way.
9.14.4 Particle Swarm Optimization for Feature Selection
To find the optimal feature subset one needs to enumerate and evaluate all the possible subsets of features in the entire search space, which implies that the search space size is 2n where n is the number of the original features. Therefore, evaluating the entire feature subset is computationally expensive and also impractical even for a moderate-sized feature set.
Although many feature selection algorithms involve heuristic or random search strategies to find the optimal or near optimal subset of features in order to reduce the computational time, metaheuristic algorithms may clearly be more efficient for feature subset selection.
Consider feature selection in supervised classification. Given the data set S = {(x 1, y 1), …, (x n, y n)}, where x i = [x i1, …, x id]T is a multi-dimensional vector sample, d denotes the number of features, n is the number of samples, and y i ∈ I = {1, …, d} denotes the label of the sample x i. Let X = {x 1, …, x n}. The main goal of the supervised learning is to approximate a function f : X → I to predict the class label for a new input vector x.
In the learning problems, choice of the optimization method is very important to reduce the dimensionality of the feature space and to improve the convergence speed of the learning model. The PSO method would be preferred because it can handle a large number of features.
PSO has a powerful exploration ability until the optimal solution is found because different particles can explore different parts of the solution space.
PSO is particularly attractive for feature selection since the particle swarm has memory, and knowledge of the solution is retained by all particles as they fly within the problem space.
The attractiveness of PSO is also due to its computationally inexpensive implementation that still gives decent performance.
PSO works with the population of potential solutions rather than with a single solution.
PSO can address binary and discrete data.
PSO has better performance compared to other feature selection techniques in terms of memory and runtime and does not need complex mathematical operators.
PSO is easy to implement with few parameters, and is easy to realize and gives promising results.
The performance of PSO is almost unaffected by the dimension of the problem.
Although PSO provides a global search strategy for finding a better solution in the feature selection task, it is infected with two shortcomings: premature convergence and weakness in fine-tuning near local optimum points. To overcome these weaknesses, a hybrid feature selection method based on PSO with local search, called HPSO-LS, was developed in [106].
Define the relevant symbols are as follows. n
f denotes the number of the original features in a given data set, n
s = |X
s| is the number of the selected features, c
ij is the Pearson correlation coefficient between two features x
i and x
j, cori is the correlation value for feature i,  is the best previously visited position (up to time t) of the ith particle,
is the best previously visited position (up to time t) of the ith particle,  is the global best position of the swarm,
is the global best position of the swarm,  is the position of the dth dimension of the ith particle, v
i(t) is the velocity of the ith particle, x
i(k) and x
j(k) denote the values of the feature vectors i and j for the kth sample.
is the position of the dth dimension of the ith particle, v
i(t) is the velocity of the ith particle, x
i(k) and x
j(k) denote the values of the feature vectors i and j for the kth sample.
The pseudo code of the HPSO-LS algorithm is shown in Algorithm 9.18.

9.15 Opposition-Based Evolutionary Computation
It is widely recognized that hybridization with different algorithms is another direction for improving machine intelligence algorithms.
Learning, search, and optimization are fundamental tasks in the machine intelligence: Artificial intelligence algorithms learn from past data or instructions, optimize estimated solutions, and search for an existing solution in large spaces. In many cases, the machine learning starts at a random point, such as weights of a neural network, initial population of soft computing algorithms, and action policy of reinforcement agents. If the starting point is close to the optimal solution, then its convergence is faster. On the other hand, if it is very far from the optimal solution, such as opposite location in the worst case, the convergence will take much more time or even the solution can be intractable. In these bad cases, looking simultaneously for a better candidate solution in both current and opposite directions may help us to solve the present problem quickly and efficiently, which could be beneficial.
Opposition-based evolutionary computation is inspired in part by the observation that opposites permeate everything around us, in some form or another.
9.15.1 Opposition-Based Learning
There are several definitions on opposition of an existing solution x. Focused on metaheuristics and optimization, opposition is presented as a relationship between a pair of candidate solutions. In combinatorial and continuous optimization, each candidate solution has its own particularly defined opposite candidate.
 be a real number defined on a certain interval: x ∈ [a, b]. The opposite number x̆ is defined as
be a real number defined on a certain interval: x ∈ [a, b]. The opposite number x̆ is defined as

The opposite number in a multidimensional case can be analogously defined.
Geometric representation of opposite number of a real number x
![$$\mathbf {x}=[x_1^{\,} ,\ldots ,x_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq238.png) be a point (vector) in D-dimensional space, where
be a point (vector) in D-dimensional space, where  and
and ![$$x_i^{\,} \in [a_i^{\,} ,b_i^{\,} ], i=1,\ldots ,D$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq240.png) . The opposite point
. The opposite point ![$$\breve {\mathbf {x}}=[\breve {x}_1^{\,} ,\ldots ,\breve {p}_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq241.png) is completely defined by its components
is completely defined by its components

Every point ![$$\mathbf {x}=[x_1^{\,} ,\ldots ,x_D^{\,} ]^T\in \mathbb {R}^D$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq242.png) of real numbers with x
i ∈ [a
i, b
i] has a unique opposite point
of real numbers with x
i ∈ [a
i, b
i] has a unique opposite point ![$$\breve {\mathbf {x}}=[\breve x_1^{\,} ,\ldots ,\breve x_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq243.png) defined by
defined by  .
.
![$$\mathbf {x}\,{=}\,[x_1^{\,} ,\ldots ,x_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq245.png) in a d-dimensional vector space, its opposition solution
in a d-dimensional vector space, its opposition solution ![$$\bar {\mathbf {x}}\,{=}\,[\bar x_1^{\,} ,\ldots ,\bar x_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq246.png) is defined as element form:
is defined as element form:

![$$\tilde {\mathbf {x}}_g=[\tilde x_1^{\,} ,\ldots ,\tilde x_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq247.png) is defined as
is defined as
![$$\displaystyle \begin{aligned}\tilde{\mathbf{x}}_g =[\tilde x_i]_{i=1}^d=[k\cdot (a+b)-x_i]_{i=1}^D, \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ244.png)
Center-based sampling (CBS) [129] is a variant of opposition solution similar to generalized opposition solution.
![$$\mathbf {x}=x_1^{\,} ,\ldots ,x_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq248.png) be a solution in a D-dimension vector space. An opposite candidate solution
be a solution in a D-dimension vector space. An opposite candidate solution ![$$\hat {\mathbf {x}}_c=[\hat x_1^{\,} ,\ldots ,\hat x_D^{\,}]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq249.png) is defined by a random point between x and its opposite point
is defined by a random point between x and its opposite point  as follows:
as follows:

The objective of center-based sampling is to obtain opposite candidate solutions closer to the center of the domain of each variable.
Let ![$$\mathbf {x}=[x_1^{\,} ,\ldots ,x_D^{\,}]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq251.png) and
and ![$$\bar {\mathbf {x}}=[\bar x_1^{\,} ,\ldots ,\bar x_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq252.png) be a solution point and its opposition solution point in D-dimensional vector space, respectively. If the opposition solution has the better fitness, i.e.,
be a solution point and its opposition solution point in D-dimensional vector space, respectively. If the opposition solution has the better fitness, i.e.,  , then the original solution x should be replaced with the new candidate solution
, then the original solution x should be replaced with the new candidate solution  ; otherwise, x is continue to be used as a candidate solution. This machine learning based on opposition is called opposition-based learning (OBL). The optimization using the candidate solution and its opposition solution simultaneously for searching the better one is referred to as the opposition-based optimization (OBO).
; otherwise, x is continue to be used as a candidate solution. This machine learning based on opposition is called opposition-based learning (OBL). The optimization using the candidate solution and its opposition solution simultaneously for searching the better one is referred to as the opposition-based optimization (OBO).
The basic concept of OBL was originally introduced by Tizhoosh in 2005 [151]. The OBL has been applied in evolutionary algorithms, differential evolution, particle swarm optimization, harmony search, among others (see, e.g., Survey Papers [135, 161]).
9.15.2 Opposition-Based Differential Evolution
For evolutionary optimization methods, they start with some initial solutions (initial population) and try to improve them toward some optimal solution(s). In the absence of a priori information about the solution, some initial solutions are needed to be randomly guessed. Then, evolutionary optimization is related to the distance of these initial guesses from the optimal solution. An important fact is [131] that evolutionary optimization can be improved, if it starts with a closer (fitter) solution by simultaneously checking the opposite solution.
Let ![$$\mathbf {p}=[p_1^{\,} ,\ldots ,p_D^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq255.png) be a candidate solution in D-dimensional space, and
be a candidate solution in D-dimensional space, and ![$$\breve {\mathbf {p}}=[\breve p_1,\ldots ,\breve p_D]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq256.png) be the opposite solution in D-dimensional space. Assume that f(p) is a fitness function for point p, which is used to measure the candidate’s fitness. If f(p̆) ≥ f(p), then point p can be replaced with p̆; otherwise, continue with p. Hence, the point p and its opposite point p̆ are evaluated simultaneously in order to continue with the fitter one.
be the opposite solution in D-dimensional space. Assume that f(p) is a fitness function for point p, which is used to measure the candidate’s fitness. If f(p̆) ≥ f(p), then point p can be replaced with p̆; otherwise, continue with p. Hence, the point p and its opposite point p̆ are evaluated simultaneously in order to continue with the fitter one.
By applying the OBL to the classical DE, Rahnamayan et al. [131] developed an opposition-based differential evolution (ODE).
- 1.Opposition-based population initialization:
Initialize the population
 randomly, here p
i = [Pi1, …, PiD]T.
randomly, here p
i = [Pi1, …, PiD]T.Calculate opposite population by OPij = a j + b j −Pij for i = 1, …, N p; j = 1, …, D. Here, Pij and OPij denote jth variable of the ith vector of the population and the opposite-population, respectively.
Select the N p fittest individuals from {P ∪OP} as initial population.
- 2.
Opposition-based generation jumping: This part forces the evolutionary process to jump to a new solution candidate which ideally is fitter than the current population. Unlike opposition-based initialization that selects OPij = a j + b j −Pij, opposition-based generation jumping selects the new population from the current population as
 for i = 1, …, N
p; j = 1, …, D. Here,
for i = 1, …, N
p; j = 1, …, D. Here,  and
and  are minimum and maximum values of the jth variable in the current population.
are minimum and maximum values of the jth variable in the current population.
In essence, opposition-based differential evolution is an evolution optimization based on both difference vector between two populations or solutions for mutation and opposition-based learning for initialization and generation jumping. Opposition-based differential evolution is shown in Algorithm 9.19. As compared with the classical differential evolution Algorithm 9.14, the opposition-based differential evolution Algorithm 9.19 adds one pre-processing (Opposition-Based Population Initialization) and one post-processing (Opposition-Based Generation Jumping).

9.15.3 Two Variants of Opposition-Based Learning
In opposition-based learning, an opposite point is deterministically calculated with the reference point at the center in the fixed search range. There are two variants of opposite point selection.
The first variant is called quasi opposition-based learning (quasi-OBL), proposed in [130].
 be its opposite number. The quasi-opposite number of x, denoted by x
q, is defined as
be its opposite number. The quasi-opposite number of x, denoted by x
q, is defined as

![$${\mathbf {x}}_i=[x_{i1}^{\,} ,\ldots ,x_{iD}^{\,} ]^T\in \mathbb {R}^D$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq262.png) be any vector (point) in D-dimensional real space, and x
ij ∈ [a
j, b
j] for i = 1, …, N
p;j = 1, …, D. The quasi-opposite point of x
i, denoted by
be any vector (point) in D-dimensional real space, and x
ij ∈ [a
j, b
j] for i = 1, …, N
p;j = 1, …, D. The quasi-opposite point of x
i, denoted by ![$${\mathbf {x}}_i^q=[x_{i1}^q,\ldots ,x_{iD}^q]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq263.png) , is defined in its element form as
, is defined in its element form as

 .
.
The opposite point and the quasi-opposite point. Given a solution ![$${\mathbf {x}}_i=[x_{i1}^{\,} ,\ldots ,x_{iD}^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq265.png) with x
ij ∈ [a
j, b
j] and M
ij = (a
j + b
j)∕2, then
with x
ij ∈ [a
j, b
j] and M
ij = (a
j + b
j)∕2, then  and
and  are the jth elements of the opposite point
are the jth elements of the opposite point  and the quasi-opposite point
and the quasi-opposite point  of x
i, respectively. (a) When x
ij > M
ij. (b) When x
ij < M
ij
of x
i, respectively. (a) When x
ij > M
ij. (b) When x
ij < M
ij
 , its opposite point
, its opposite point  and quasi opposite point
and quasi opposite point  , and given the distance from the solution d(⋅) and probability function P
r(⋅), then
, and given the distance from the solution d(⋅) and probability function P
r(⋅), then
![$$\displaystyle \begin{aligned} P_r [d({\mathbf{x}}^q) < d({\mathbf{x}}^o)] > 1/2. \end{aligned} $$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_Equ249.png)

Theorem 9.10 implies that for a black-box optimization problem (which means solution can appear anywhere over the search space), the quasi opposite point x q has a higher chance than the opposite point x o to be closer to the solution.
- 1.Quasi-oppositional population initialization: Generate uniformly distributed random populations
![$${\mathbf {p}}_i^0 =[\mathrm {P}_{i1}^0 ,\ldots , \mathrm {P}_{iD}^0]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq273.png) for i = 1, …, N
p, where
for i = 1, …, N
p, where ![$$\mathrm {P}_{ij}^0\in [a_j ,b_j]$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq274.png) for j = 1, …, D.
for j = 1, …, D. - Compute the opposite populations
![$${\mathbf {p}}_i^o=[\mathrm {OP}_{i1}^0,\ldots ,\mathrm {OP}_{iD}^0]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq275.png) associated with
associated with  in element form:
in element form:
 (9.15.11)
(9.15.11) - Denote the middle point between a j and b j as
 (9.15.12)
(9.15.12) - If letting the quasi-opposition of p i be
![$${\mathbf {p}}_i^q=[\mathrm {QOP}_{i1}^0,\ldots ,\mathrm {QOP}_{iD}^0]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq277.png) , then its elements are given by
, then its elements are given by
 (9.15.13)
(9.15.13)Here, i = 1, …, N p;j = 1, …, D.
Select N p fittest individuals from the set
 as initial population p
0.
as initial population p
0.
- 2.Quasi-oppositional generation jumping: Let J r be jumping rate,
 be minimum value of the jth individual in the current population, and
be minimum value of the jth individual in the current population, and  denote maximum value of the jth individual in the current population.
denote maximum value of the jth individual in the current population. - If rand(0, 1) < J r then calculate
 (9.15.14)
(9.15.14) (9.15.15)
(9.15.15) (9.15.16)
(9.15.16)Here, i = 0, …N p − 1;j = 0, …, D − 1.
Select N p fittest individuals from set the {Pij, QOPij} as current population p.
If the oppositional population initialization and the oppositional generation jumping in Algorithm 9.19 are, respectively, replaced by the above quasi-oppositional population initialization and quasi-oppositional generation jumping, then the opposition-based differential evolution (ODE) described in Algorithm 9.19 becomes the quasi-oppositional differential evolution (QODE) in [130].
The second variant of the OBL is quasi reflection point-based OBL, which was proposed in [40].
![$${\mathbf {x}}_i=[x_{i1}^{\,} ,\ldots ,x_{iD}^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq281.png) be any point in D-dimensional real space, and x
ij ∈ [a
j, b
j]. Then the quasi-reflected point of x
i, denoted by
be any point in D-dimensional real space, and x
ij ∈ [a
j, b
j]. Then the quasi-reflected point of x
i, denoted by ![$${\mathbf {x}}_i^{qr}=[x_{i1}^{qr},\ldots ,x_{iD}^{qr}]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq282.png) , is defined in its element form as
, is defined in its element form as

The opposite, quasi-opposite, and quasi-reflected points of a solution (point) x
i. Given a solution ![$${\mathbf {x}}_i=[x_{i1}^{\,} ,\ldots ,x_{iD}^{\,} ]^T$$](../images/492994_1_En_9_Chapter/492994_1_En_9_Chapter_TeX_IEq283.png) with x
ij ∈ [a
j, b
j] and M
ij = (a
j + b
j)∕2, then
with x
ij ∈ [a
j, b
j] and M
ij = (a
j + b
j)∕2, then  ,
,  , and
, and  are the jth elements of the opposite point
are the jth elements of the opposite point  , the quasi-opposite point
, the quasi-opposite point  , and the quasi-reflected opposite point
, and the quasi-reflected opposite point  of x
i, respectively. (a) When x
ij > M
ij. (b) When x
ij < M
ij
of x
i, respectively. (a) When x
ij > M
ij. (b) When x
ij < M
ij
The quasi-opposite point is generated by
 , whereas the quasi-reflected opposite point is defined by
, whereas the quasi-reflected opposite point is defined by  .
.The quasi-reflected opposite point is the mirror image of the quasi-opposite point with regard to the middle point M ij, and hence is named as the quasi-reflected opposite point.
After calculating the fitness of opposite population generated by quasi-reflected opposition, the fittest N p individuals in P and OP constitute the updated population. The application of the quasi-opposite points or the quasi-reflected opposite points will result into various variants and extensions of the basic OBL algorithm. For example, a stochastic opposition-based learning using a Beta distribution in differential evolution can be found in [121].
This chapter presents evolutionary computation tree.
Evolutionary computation is a subset of artificial intelligence, which is essentially a computational intelligence for solving combinatorial optimization problems.
Evolutionary computation, starting from a group of randomly generated individuals, imitates the biological genetic mode to update the next generation of individuals by replication, crossover, and mutation. Then, according to the size of fitness, the individual survival of the fittest improves the quality of the new generation of groups, after repeated iterations, gradually approaching the optimal solution. From the mathematical point of view, evolutionary computation is essentially a search optimization method.
This chapter focuses on the Pareto optimization theory in multiobjective optimization problems existing in coevolutionary computation.
Evolutionary computation has been widely used in artificial intelligence, pattern recognition, image processing, biology, electrical engineering, communication, economic management, mechanical engineering, and many other fields.