Chapter 6. The Adapter, Observer, and CRTP Design Patterns
In this chapter, we turn our attention to three must-know design patterns: the two GoF design patterns, Adapter and Observer, and the Curiously Recurring Template Pattern (CRTP) design pattern.
In “Guideline 24: Use Adapters to Standardize Interfaces”, we talk about making incompatible things fit together by adapting interfaces. To achieve this, I will show you the Adapter design pattern and its application in both inheritance hierarchies and generic programming. You will also get an overview of different kinds of Adapters, including object, class, and function Adapters.
In “Guideline 25: Apply Observers as an Abstract Notification Mechanism”, we will deal with how to observe state change and how to get notified about it. In this context, I will introduce you to the Observer design pattern, one of the most famous and most commonly used design patterns. We will talk about the classic, GoF-style Observer, and also how to implement the Observer in modern C++.
In “Guideline 26: Use CRTP to Introduce Static Type Categories”, we will turn our attention to the CRTP. I will show you how to use CRTP to define a compile-time relationship between a family of related types and how to properly implement a CRTP base class.
In “Guideline 27: Use CRTP for Static Mixin Classes”, I will continue the CRTP story by showing you how CRTP can be used to create compile-time mixin classes. We will also see the difference between semantic inheritance, where it is used to create an abstraction, and technical inheritance, where it is used as an implementation detail for technical elegance and convenience only.
Guideline 24: Use Adapters to Standardize Interfaces
Let’s assume that you have implemented the Document example from
“Guideline 3: Separate Interfaces to Avoid
Artificial Coupling”, and that, because you properly adhere
to the Interface Segregation Principle (ISP), you’re reasonably happy with the way it works:
classJSONExportable{public:// ...virtual~JSONExportable()=default;virtualvoidexportToJSON(/*...*/)const=0;// ...};classSerializable{public:// ...virtual~Serializable()=default;virtualvoidserialize(ByteStream&bs,/*...*/)const=0;// ...};classDocument:publicJSONExportable,publicSerializable{public:// ...};
However, one day you’re required to introduce the Pages document
format.1 Of course,
it is similar to the Word document that you already have in place, but unfortunately, you’re
not familiar with the details of the Pages format. To make things worse, you don’t
have a lot of time to get familiar with the format, because you have way too many other
things to do. Luckily, you know about a quite reasonable, open source implementation
for that format: the OpenPages class:
classOpenPages{public:// ...voidconvertToBytes(/*...*/);};voidexportToJSONFormat(OpenPagesconst&pages,/*...*/);
On the bright side, this class provides about everything you need for your purposes: a convertToBytes() member function to serialize the content of the document,
and the free exportToJSONFormat() function to convert the Pages document into
the JSON format. Unfortunately, it does not fit your interface expectations: instead of the
convertToBytes() member function, you expect a serialize() member function. And instead
of the free exportToJSONFormat() function, you expect the
exportToJSON() member function.
Ultimately, of course, the third-party class does not inherit from your Document base
class, which means that you can’t easily incorporate the class into your existing hierarchy.
However, there is a solution to this problem: a seamless integration using the Adapter design pattern.
The Adapter Design Pattern Explained
The Adapter design pattern is another one of the classic GoF design patterns. It’s focused on standardizing interfaces and helping nonintrusively add functionality into an existing inheritance hierarchy.
The Adapter Design Pattern
Intent: “Convert the interface of a class into another interface clients expect. Adapter lets classes work together that couldn’t otherwise because of incompatible interfaces.”2
Figure 6-1 shows the UML diagram for your Adapter scenario: you already
have the Document base class in place (we ignore the JSONExportable and Serializable
interfaces for a second) and have already implemented a couple of different kinds of
documents (for instance, with the Word class). The new addition to this hierarchy
is the Pages class.
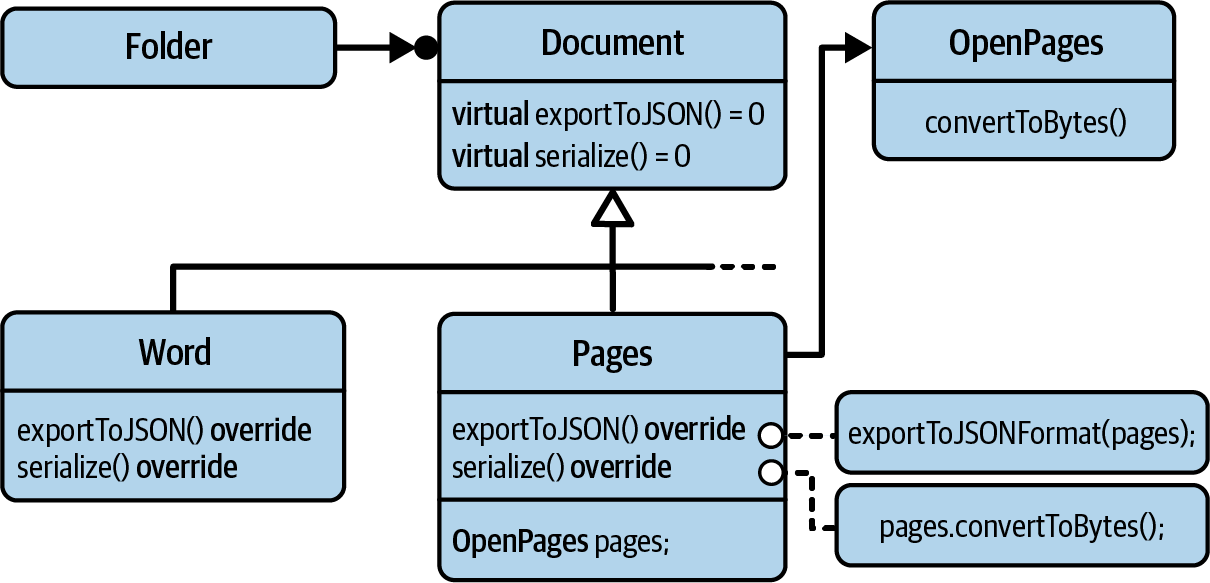
Figure 6-1. The UML representation of the Adapter design pattern
The Pages class acts as a wrapper to the third-party OpenPages class:
classPages:publicDocument{public:// ...voidexportToJSON(/*...*/)constoverride{exportToJSONFormat(pages,/*...*/);}voidserialize(ByteStream&bs,/*...*/)constoverride{pages.convertToBytes(/*...*/);}// ...private:OpenPagespages;// Example of an object adapter};
Pages implements the Document interface by forwarding the calls to the corresponding
OpenPages functions: a call to exportToJSON() is forwarded to the free
exportToJSONFormat() function
(![]() ),
and the call to
),
and the call to serialize() is forwarded to the convertToBytes() member function
(![]() ).
).
With the Pages class, you can easily integrate the third-party implementation
into your existing hierarchy. Very easily indeed: you can integrate it without having
to modify it in any way. This nonintrusive nature of the Adapter design pattern is
what you should consider one of the greatest strengths of the Adapter design pattern:
anyone can add an Adapter to adapt an interface to another, existing interface.
In this context, the Pages class serves as an abstraction from the actual
implementation details in the OpenPages class. Therefore, the Adapter design pattern
separates the concerns of the interface from the implementation details. This nicely fulfills
the Single-Responsibility Principle (SRP) and blends well with the intention of the
Open-Closed Principle (OCP) (see “Guideline 2: Design for Change” and “Guideline 5: Design for Extension”).
In a way, the Pages Adapter works as an indirection and maps from one
set of functions to another one. Note that it is not strictly necessary to map from one
function to exactly one other function. On the contrary, you have complete flexibility
on how to map the expected set of functions onto the available set of functions. Thus,
Adapter does not necessarily represent a 1-to-1 relationship, but can also support a
1-to-N relationship.3
Object Adapters Versus Class Adapters
The Pages class is an example of a so-called object adapter. This term refers
to the fact that you store an instance of the wrapped type. Alternatively, given
that the wrapped type is part of an inheritance hierarchy, you could store a pointer
to the base class of this hierarchy. This would allow you to use the object adapter
for all types that are part of the hierarchy, giving the object adapter a considerable
boost in
flexibility.
In contrast, there is also the option to implement a so-called class adapter:
classPages:publicDocument,privateOpenPages// Example of a class adapter{public:// ...voidexportToJSON(/*...*/)constoverride{exportToJSONFormat(*this,/*...*/);}voidserialize(ByteStream&bs,/*...*/)constoverride{this->convertToBytes(/*...*/);}// ...};
Instead of storing an instance of the adapted type, you would inherit from it (if
possible, nonpublicly) and implement the expected interface accordingly
(![]() ).
However, as discussed in “Guideline 20: Favor Composition over Inheritance”, it is preferable to
build on composition. In general, object adapters prove to be much more flexible
than class adapters and thus should be your favorite. There are only a few reasons
why you would prefer a class adapter:
).
However, as discussed in “Guideline 20: Favor Composition over Inheritance”, it is preferable to
build on composition. In general, object adapters prove to be much more flexible
than class adapters and thus should be your favorite. There are only a few reasons
why you would prefer a class adapter:
-
If you have to override a virtual function.
-
If you need access to a
protectedmember function. -
If you require the adapted type to be constructed before another base class.
-
If you need to share a common virtual base class or override the construction of a virtual base class.
-
If you can draw significant advantage from the Empty Base Optimization (EBO).4
Otherwise, and this applies to most cases, you should prefer an object adapter.
“I like this design pattern—it’s powerful. However, I just remembered that you recommended
using the name of the design pattern in the code to communicate intent. Shouldn’t the
class be called PagesAdapter?” You make an excellent point. And I’m happy
that you remember “Guideline 14: Use a Design Pattern’s Name to Communicate Intent”,
in which I indeed argued that the name of the pattern helps to understand the code.
I admit that in this case, I’m open to both naming conventions. While I do see the
advantages of the name PagesAdapter, as this immediately communicates that you built
on the Adapter design pattern, I don’t consider it a necessity to communicate the
fact that this class represents an adapter. To me, the Adapter feels like an
implementation detail in this situation: I do not need to know that the Pages class
doesn’t implement all the details itself, but uses the OpenPages class for that.
That’s why I said to “consider using the name.” You should decide on a case-by-case basis.
Examples from the Standard Library
One useful application of the Adapter design pattern is to standardize the interface of
different kinds of containers. Let’s assume the following Stack base class:
//---- <Stack.h> ----------------template<typenameT>classStack{public:virtual~Stack()=default;virtualT&top()=0;virtualboolempty()const=0;virtualsize_tsize()const=0;virtualvoidpush(Tconst&value)=0;virtualvoidpop()=0;};
This Stack class provides the necessary interface to access the top element of the stack
(![]() ),
check if the stack is empty
(
),
check if the stack is empty
(![]() ),
query the size of the stack
(
),
query the size of the stack
(![]() ),
push an element onto the stack
(
),
push an element onto the stack
(![]() ),
and remove the top element of the stack
(
),
and remove the top element of the stack
(![]() ).
This base class can now be used to implement different Adapters for various data
structures, such as
).
This base class can now be used to implement different Adapters for various data
structures, such as std::vector:
//---- <VectorStack.h> ----------------#include<Stack.h>template<typenameT>classVectorStack:publicStack<T>{public:T&top()override{returnvec_.back();}boolempty()constoverride{returnvec_.empty();}size_tsize()constoverride{returnvec_.size();}voidpush(Tconst&value)override{vec_.push_back(value);}voidpop()override{vec_.pop_back();}private:std::vector<T>vec_;};
You worry, “Do you seriously suggest implementing a stack by an abstract base class?
Aren’t you worried about the performance implications? For every use of a member
function, you have to pay with a virtual function call!” No, of course I don’t suggest that. Obviously, you are correct, and I completely agree with you: from a
C++ perspective, this kind of container feels strange and very inefficient.
Because of efficiency, we usually realize the same idea via class templates. This is
the approach taken by the C++ Standard Library in the form of the three STL
classes called Container adaptors:
std::stack,
std::queue, and
std::priority_queue:
template<typenameT,typenameContainer=std::deque<T>>classstack;template<typenameT,typenameContainer=std::deque<T>>classqueue;template<typenameT,typenameContainer=std::vector<T>,typenameCompare=std::less<typenameContainer::value_type>>classpriority_queue;
These three class templates adapt
the interface of a given Container type to a special purpose. For instance, the
purpose of the std::stack class template is to adapt the interface of a container
to the stack operations top(), empty(), size(), push(), emplace(), pop(),
and swap().5 By default, you’re able
to use the three available sequence containers: std::vector, std::list, and
std::deque. For any other container type, you are able to specialize the std::stack
class template.
“This feels so much more familiar,” you say, visibly relieved. Again, I absolutely
agree. I also consider the Standard Library approach the more suitable solution for the
purpose of containers. But it’s still interesting to compare the two
approaches. While there are many technical differences between the Stack base class
and the std::stack class template, the purpose and semantics of these two approaches are
remarkably similar: both provide the ability to adapt any data structure to a given
stack interface. And both serve as a variation point, allowing you to nonintrusively
add new Adapters without having to modify existing code.
Comparison Between Adapter and Strategy
“The three STL classes seem to fulfill the intent of Adapters, but isn’t
this the same way of configuring behavior as in the Strategy design pattern? Isn’t
this similar to std::unique_ptr and its deleter?” you ask. And yes, you’re
correct. From a structural point of view, the Strategy and Adapter design patterns
are very similar. However, as explained in “Guideline 11: Understand the Purpose of Design Patterns”,
the structure of design patterns may be similar or even the same, but the intent is different. In this context, the Container parameter specifies not just a
single aspect of the behavior, but most of the behavior or even all of it. The class
templates merely act as a wrapper around the functionality of the given type—they
mainly adapt the interface. So the primary focus of an Adapter is to standardize
interfaces and integrate incompatible functionality into an existing set of
conventions; while on the other hand, the primary focus of the Strategy design pattern
is to enable the configuration of behavior from the outside, building on and providing
an expected interface. Also, for an Adapter there is no need to reconfigure the
behavior at any time.
Function Adapters
Additional examples for the Adapter design pattern are the Standard Library’s free
functions begin() and
end(). “Are you serious?” you ask,
surprised. “You claim that free functions serve as an example of the Adapter design pattern?
Isn’t this a job for classes?” Well, not necessarily. The purpose of the free begin()
and end() functions is to adapt the iterator interface of any type to the expected
STL iterator interface. Thus, it maps from an available set of functions to an expected
set of functions and serves the same purpose as any other Adapter. The major
difference is that in contrast to object adapters or class adapters, which are
based on either inheritance (runtime polymorphism) or templates (compile-time polymorphism),
begin() and end() draw their power from function overloading, which is the second
major compile-time polymorphism mechanism in C++. Still, some form of
abstraction is at play.
Note
Remember that all kinds of abstractions represent a set of requirements and thus have to adhere to the Liskov Substitution Principle (LSP). This is also true for overload sets; see “Guideline 8: Understand the Semantic Requirements of Overload Sets”.
Consider the following function template:
template<typenameRange>voidtraverseRange(Rangeconst&range){for(auto&&element:range){// ...}}
In the traverseRange() function, we iterate through all the elements contained in
the given range with a range-based for loop. The traversal happens via iterators
that the compiler acquires with the free begin() and end() functions. Hence,
the preceding for loop is equivalent to the following form of for:
template<typenameRange>voidtraverseRange(Rangeconst&range){{usingstd::begin;usingstd::end;autofirst(begin(range));autolast(end(range));for(;first!=last;++first){auto&&element=*first;// ...}}}
Obviously, the range-based for loop is much more convenient to use. However, underneath
the surface, the compiler generates code based on the free begin() and end() functions.
Note the two using declarations in their beginning: the purpose is to enable
Argument-Dependent Lookup (ADL) for the
given type of range. ADL is the mechanism that makes sure the “correct” begin() and
end() functions are called, even if they are overloads that reside in a user-specific
namespace. This means that you have the opportunity to overload begin() and end()
for any type and map the expected interface to a different, special-purpose set of
functions.
This kind of function adapter was called a shim by Matthew Wilson in 2004.6 One valuable property of this technique is that it’s completely nonintrusive: it is possible to add a free function to any type, even to types that you could never adapt, such as types provided by third-party libraries. Hence, any generic code written in terms of shims gives you the enormous power to adapt virtually any type to the expected interface. Thus, you can imagine that shims or function adapters are the backbone of generic programming.
Analyzing the Shortcomings of the Adapter Design Pattern
Despite the value of the Adapter design pattern, there is one issue with this design pattern that I should explicitly point out. Consider the following example, which I adopted from Eric Freeman and Elisabeth Robson:7
//---- <Duck.h> ----------------classDuck{public:virtual~Duck()=default;virtualvoidquack()=0;virtualvoidfly()=0;};//---- <MallardDuck.h> ----------------#include<Duck.h>classMallardDuck:publicDuck{public:voidquack()override{/*...*/}voidfly()override{/*...*/}};
We start with the abstract Duck class, which introduces the two pure virtual functions
quack() and fly(). Indeed, this appears to be a pretty expected and natural interface
for a Duck class and of course raises some expectations: ducks make a very characteristic
sound and can fly pretty well. This interface is implemented by many possible kinds of
Duck, such as the MallardDuck class. Now, for some reason we also have to deal
with turkeys:
//---- <Turkey.h> ----------------classTurkey{public:virtual~Turkey()=default;virtualvoidgobble()=0;// Turkeys don't quack, they gobble!virtualvoidfly()=0;// Turkeys can fly (a short distance)};//---- <WildTurkey.h> ----------------classWildTurkey:publicTurkey{public:voidgobble()override{/*...*/}voidfly()override{/*...*/}};
Turkeys are represented by the abstract Turkey class, which of course is implemented
by many different kinds of specific Turkeys, like the WildTurkey. To make
things worse, for some reason ducks and turkeys are expected be used together.8 One possible way to make this work is
to pretend that a turkey is a duck. After all, a turkey is pretty similar to a duck. Well,
OK, it doesn’t quack, but it can gobble (the typical turkey sound), and it can also fly
(not for a long distance, but yes, it can fly). So you could adapt turkeys
to ducks with the TurkeyAdapter:
//---- <TurkeyAdapter.h> ----------------#include<memory>classTurkeyAdapter:publicDuck{public:explicitTurkeyAdapter(std::unique_ptr<Turkey>turkey):turkey_{std::move(turkey)}{}voidquack()override{turkey_->gobble();}voidfly()override{turkey_->fly();}private:std::unique_ptr<Turkey>turkey_;// This is an example for an object adapter};
While this is an amusing interpretation of duck typing,
this example nicely demonstrates that it’s way too easy to integrate
something alien into an existing hierarchy. A Turkey is simply not a Duck, even if we
want it to be. I would argue that likely both the quack() and the fly() function
violate the LSP. Neither functions really does what I would expect it to (at least
I’m pretty sure that I want a quacking, not gobbling, critter and that I want something
that can really fly like a duck). Of course, it depends on the specific context, but
undeniably, the Adapter design pattern makes it very easy to combine things that do
not belong together. Thus, it’s very important that you consider the expected behavior
and check for LSP violations when applying this design pattern:
#include<MallardDuck.h>#include<WildTurkey.h>#include<TurkeyAdapter.h>#include<memory>#include<vector>usingDuckChoir=std::vector<std::unique_ptr<Duck>>;voidgive_concert(DuckChoirconst&duck_choir){for(autoconst&duck:duck_choir){duck->quack();}}intmain(){DuckChoirduck_choir{};// Let's hire the world's best ducks for the choirduck_choir.push_back(std::make_unique<MallardDuck>());duck_choir.push_back(std::make_unique<MallardDuck>());duck_choir.push_back(std::make_unique<MallardDuck>());// Unfortunately we also hire a turkey in disguiseautoturkey=std::make_unique<WildTurkey>();autoturkey_in_disguise=std::make_unique<TurkeyAdapter>(std::move(turkey));duck_choir.push_back(std::move(turkey_in_disguise));// The concert is going to be a musical disaster...give_concert(duck_choir);returnEXIT_SUCCESS;}
In summary, the Adapter design pattern can be considered one of the most valuable design patterns for combining different pieces of functionality and making them work together. I promise that it will prove to be a valuable tool in your daily work. Still, do not abuse the power of Adapter in some heroic effort to combine apples and oranges (or even oranges and grapefruits: they are similar but not the same). Always be aware of LSP expectations.
Guideline 25: Apply Observers as an Abstract Notification Mechanism
Chances are good that you’ve heard about observers before. “Oh, yes, of course I have—isn’t this what the so-called social media platforms are doing with us?” you ask. Well, not exactly what I was going for, but yes, I believe we could call these platforms observers. And yes, there is also a pattern to what they do, even though it is not a design pattern. But I’m actually thinking about one of the most popular GoF design patterns, the Observer design pattern. Even if you are not familiar with the idea yet, you very likely have some experience with helpful observers from real life. For instance, you may have noticed that in some messenger apps the sender of a text message is immediately informed once you’ve read a new text message. That means that the message is displayed as “read” instead of just “delivered.” This little service is essentially the work of a real-life Observer: as soon as the status of the new message changes, the sender is notified, providing the opportunity to respond to the state change.
The Observer Design Pattern Explained
In many software situations it’s desirable to get feedback as soon as some state change occurs: a new job is added to a task queue, a setting is changed in some configuration object, a result is ready to be picked up, etc. But at the same time, it would be highly undesirable to introduce explicit dependencies between the subject (the observed entity that changes) and its observers (the callbacks that are notified based on a state change). On the contrary, the subject should be oblivious to the potentially many different kinds of observers. And that’s for the simple reason that any direct dependency would make the software harder to change and harder to extend. This decoupling between the subject and its potentially many observers is the intent of the Observer design pattern.
The Observer Design Pattern
Intent: “Define a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically.”9
As with all design patterns, the Observer design pattern identifies one aspect as a variation
point (an aspect that changes or is expected to change) and extracts it in the form of an
abstraction. It thus helps to decouple software entities. In the case of the Observer, the need to
introduce new observers—the need to extend a one-to-many dependency—is recognized to be the
variation point. As Figure 6-2 illustrates, this variation point is
realized in the form of the Observer base class.

Figure 6-2. The UML representation of the Observer design pattern
The Observer class represents the abstraction for all possible implementations of
observers. These observers are attached to a specific subject, represented by the
ConcreteSubject class. To reduce the coupling between observers and their
subjects, or to simply reduce code duplication by providing all common services to attach()
and detach() to different observers, the Subject abstraction can be used. This
Subject
might also notify() all attached observers about a state change and trigger their corresponding
update() functionality.
“Isn’t the introduction of the Observer base class another example of the
SRP?” you ask. And yes, you’re 100% correct:
extracting the Observer class, extracting a variation point, is the SRP in action
(see “Guideline 2: Design for Change”). Again, the SRP acts as an enabler for the OCP (see “Guideline 5: Design for Extension”): by introducing the Observer abstraction,
anyone is able to add new kinds of observers (e.g., ConcreteObserver) without the need to
modify existing code. If you pay attention to the ownership of the Observer base class and
make sure that the Observer class lives in the high level of your architecture, then you
also fulfill the Dependency Inversion Principle (DIP).
A Classic Observer Implementation
“Great, I get it! It’s nice to see these design principles in action again, but I would
like to see a concrete Observer example.” I understand. So let’s take a look at a
concrete implementation. However, I should clearly state the limitations of the following
example before we start to look at the code. You might already be familiar with Observer, and
therefore you might be looking for help and deeper advice on many of the tricky implementation
details of Observer: how to deal with the order of attaching and detaching observers, attaching an observer multiple times, and especially using observers
in a concurrent environment. I should honestly state up front that it is not my intention
to provide answers to these questions. That discussion would be like opening a can of worms, quickly sucking us into the realm of implementation details. No, although you may be
disappointed, my intention is to mostly stay on the level of software design.10
Like for the previous design patterns, we start with a classic implementation of the
Observer design pattern. The central element is the Observer base class:
//---- <Observer.h> ----------------classObserver{public:virtual~Observer()=default;virtualvoidupdate(/*...*/)=0;};
The most important implementation detail of this class is the pure virtual update() function
(![]() ),
which is called whenever the observer is notified of some state change.11 There are three
alternatives for how to define the
),
which is called whenever the observer is notified of some state change.11 There are three
alternatives for how to define the update() function, which provide a reasonable
implementation and design flexibility. The first alternative is to push the updated state
via one or even several update() functions:
classObserver{public:// ...virtualvoidupdate1(/*arguments representing the updated state*/)=0;virtualvoidupdate2(/*arguments representing the updated state*/)=0;// ...};
This form of observer is commonly called a push observer. In this form, the observer is
given all necessary information by the subject and therefore is not required to pull any
information from the subject on its own. This can reduce the coupling to the subject
significantly and create the opportunity to reuse the Observer class for several subjects.
Additionally, there is the option to use a separate overload for each kind of state change.
In the preceding code snippet, there are two update() functions, one for each of two possible
state changes. And since it’s always clear which state changed, the observer is not required
to “search” for any state change, which proves to be efficient.
“Excuse me,” you say, “but isn’t this a violation of the ISP? Shouldn’t we separate concerns by separating the update() functions into several
base classes?” This is a great question! Obviously, you’re watching out for artificial coupling.
Very good! And you are correct: we could separate an Observer with several update()
functions into smaller Observer classes:
classObserver1{public:// ...virtualvoidupdate1(/*arguments representing the updated state*/)=0;// ...};classObserver2{public:// ...virtualvoidupdate2(/*arguments representing the updated state*/)=0;// ...};
In theory, this approach could help reduce the coupling to a particular subject and more easily reuse observers for different subjects. It might also help because different observers might be interested in different state changes, and therefore it might be a violation of the ISP to artificially couple all possible state changes. And of course this might result in an efficiency gain if a lot of unnecessary state change notifications can be avoided.
Unfortunately, a particular subject is not likely to distinguish among different kinds of
observers. First, because this would require it to store different kinds of pointers (which is
inconvenient to handle for the subject), and second, because it is possible that different state
changes are linked in a certain way. In that case, the subject will expect that observers
are interested in all possible state changes. From that perspective it can be reasonable to
combine several update() functions into one base class. Either way, it’s very likely that a
concrete observer will have to deal with all kinds of state changes. I know, it can be a nuisance
to have to deal with several update() functions, even if only a small fraction of them
are interesting. But still, make sure that you’re not accidentally violating the Liskov
Substitution Principle by not adhering to some expected behavior (if there is any).
There are several more potential downsides of a push observer. First, the observers are always given all the information, whether they need it or not. Thus, this push style works well only if the observers need the information most of the time. Otherwise, a lot of effort is lost on unnecessary notifications. Second, pushing creates a dependency on the number and kind of arguments that are passed to the observer. Any change to these arguments requires a lot of subsequent changes in the deriving observer classes.
Some of these downsides are resolved by the second Observer alternative. It’s possible to
only pass a reference to the subject to the observer:12
classObserver{public:// ...virtualvoidupdate(Subjectconst&subject)=0;// ...};
Due to the lack of specific information passed to the observer, the classes
deriving from the Observer base class are required to pull the new information from the
subject on their own. For this reason, this form of observer is commonly called a pull
observer. The advantage is the reduced dependency on the number and kinds of arguments.
Deriving observers are free to query for any information, not just the changed state. On
the other hand, this design creates a strong, direct dependency between the classes deriving
from Observer and the subject. Hence, any change to the subject easily reflects on the
observers. Additionally, observers might have to “search” for the state change if
multiple details have changed. This might prove to be unnecessarily inefficient.
If you consider only a single piece of information as the changing state, the performance disadvantage might not pose a limitation for you. Still, please remember that software changes: a subject may grow, and with it the desire to notify about different kinds of changes. Adapting the observers in the process would result in a lot of additional work. From that point of view, the push observer appears to be a better choice.
Luckily, there is a third alternative, which removes a lot of the previous disadvantages and thus becomes our approach of choice: in addition to passing a reference to the subject, we pass a tag to provide information about which property of a subject has changed:
//---- <Observer.h> ----------------classObserver{public:virtual~Observer()=default;virtualvoidupdate(Subjectconst&subject,/*Subject-specific type*/property)=0;};
The tag may help an observer to decide on its own whether some state change is interesting
or not. It’s commonly represented by some subject-specific enumeration type, which lists
all possible state changes. This, unfortunately, increases the coupling of the Observer
class to a specific subject.
“Wouldn’t it be possible to remove the dependency on a specific Subject by implementing
the Observer base class as a class template? Take a look at the following code snippet:”
//---- <Observer.h> ----------------template<typenameSubject,typenameStateTag>classObserver{public:virtual~Observer()=default;virtualvoidupdate(Subjectconst&subject,StateTagproperty)=0;};
This is a great suggestion. By defining the Observer class in the form of a class template
(![]() ),
we can easily lift the
),
we can easily lift the Observer to a higher architectural level. In this form, the
class does not depend on any specific subject and thus may be reused by many different
subjects that want to define a one-to-many relationship. However, you should not expect
too much of this improvement: the effect is limited to the Observer class. Concrete
subjects will expect concrete instantiations of this observer class, and in consequence,
concrete implementations of Observer will still strongly depend on the subject.
To better understand why that is, let’s take a look at a possible subject implementation. After your initial comment about social media, I suggest that we implement an Observer for persons. Well, OK, this example may be morally questionable, but it will serve its purpose, so let’s go with that. At least we know who is to blame for this.
The following Person class represents an observed person:
//---- <Person.h> ----------------#include<Observer.h>#include<string>#include<set>classPerson{public:enumStateChange{forenameChanged,surnameChanged,addressChanged};usingPersonObserver=Observer<Person,StateChange>;explicitPerson(std::stringforename,std::stringsurname):forename_{std::move(forename)},surname_{std::move(surname)}{}boolattach(PersonObserver*observer);booldetach(PersonObserver*observer);voidnotify(StateChangeproperty);voidforename(std::stringnewForename);voidsurname(std::stringnewSurname);voidaddress(std::stringnewAddress);std::stringconst&forename()const{returnforename_;}std::stringconst&surname()const{returnsurname_;}std::stringconst&address()const{returnaddress_;}private:std::stringforename_;std::stringsurname_;std::stringaddress_;std::set<PersonObserver*>observers_;};
In this example, a Person is merely an aggregation of the three data members:
forename_, surname_, and address_
(![]() )
(I know, this is a rather simple representation of a person.) In addition, a person
holds the
)
(I know, this is a rather simple representation of a person.) In addition, a person
holds the std::set of registered observers
(![]() ).
Please note that the observers are registered by pointers to instances of
).
Please note that the observers are registered by pointers to instances of
PersonObserver
(![]() ).
This is interesting for two reasons: first, this demonstrates the purpose of the templated
).
This is interesting for two reasons: first, this demonstrates the purpose of the templated
Observer class: the Person class instantiates its own kind of observer from the class
template. And second, pointers prove to be very useful in this context, since the address
of an object is unique. Thus, it is common to use the address as a unique identifier for
an observer.
“Shouldn’t this be std::unique_ptr or std::shared_ptr?” you ask. No, not in
this situation. The pointers merely serve as handles to the registered observers; they should
not own the observers. Therefore, any owning smart pointer would be the wrong tool in this
situation. The only reasonable choice would be std::weak_ptr, which would allow you to check
for dangling pointers. However, std::weak_ptr is not a good candidate for a key for
std::set (not even with a custom comparator). Although there are ways to still use
std::weak_ptr, I will stick to raw pointers. But don’t worry, this doesn’t mean we
are abandoning the benefits of modern C++. No, using a raw pointer is perfectly valid
in this situation. This is also expressed in
C++
Core Guideline F.7:
For the general use, take
T*orT&arguments rather than smart pointers.
Whenever you’re interested in getting a notification for a state change of a person, you
can register an observer via the attach() member function
(![]() ).
And whenever you’re no longer interested in getting notifications, you can deregister an
observer via the
).
And whenever you’re no longer interested in getting notifications, you can deregister an
observer via the detach() member function
(![]() ).
These two functions are an essential ingredient of the Observer design pattern and a clear indication of the application of the design pattern:
).
These two functions are an essential ingredient of the Observer design pattern and a clear indication of the application of the design pattern:
boolPerson::attach(PersonObserver*observer){auto[pos,success]=observers_.insert(observer);returnsuccess;}boolPerson::detach(PersonObserver*observer){return(observers_.erase(observer)>0U);}
You have complete freedom to implement the attach() and detach() functions as you
see fit. In this example, we allow an observer to be registered only a single time with a std::set. If you try to register an observer a second time, the function
returns false. The same thing happens if you try to deregister an observer that
is not registered. Note that the decision to not allow multiple registrations is my
choice for this example. In other scenarios, it might be desirable or even necessary to
accept duplicate registrations. Either way, the behavior and interface of the subject
should of course be consistent in all cases.
Another core function of the Observer design pattern is the notify()
member function
(![]() ).
Whenever some state change occurs, this function is called to notify all registered
observers about the change:
).
Whenever some state change occurs, this function is called to notify all registered
observers about the change:
voidPerson::notify(StateChangeproperty){for(autoiter=begin(observers_);iter!=end(observers_);){autoconstpos=iter++;(*pos)->update(*this,property);}}
“Why is the implementation of the notify() function so complicated? Wouldn’t a range-based
for loop be completely sufficient?” You are correct; I should explain what’s happening here.
The given formulation makes sure detach() operations can be detected during the iteration.
This may happen, for instance, if an observer decides to detach itself during the call to the
update() function. But I do not claim that this formulation is perfect: unfortunately it is
not able to cope with attach() operations. And don’t even start to ask about concurrency!
So this is just one example why the implementation details of observer can be so tricky.
The notify() function is called in all three setter functions
(![]() ).
Note that in all three functions, we always pass a different tag to indicate which property
has changed. This tag may be used by classes deriving from the
).
Note that in all three functions, we always pass a different tag to indicate which property
has changed. This tag may be used by classes deriving from the Observer base class to
determine the nature of the change:
voidPerson::forename(std::stringnewForename){forename_=std::move(newForename);notify(forenameChanged);}voidPerson::surname(std::stringnewSurname){surname_=std::move(newSurname);notify(surnameChanged);}voidPerson::address(std::stringnewAddress){address_=std::move(newAddress);notify(addressChanged);}
With these mechanics in place, you are now able to write new kinds of fully OCP-conforming observers. For instance, you could decide to implement a NameObserver
and an AddressObserver:
//---- <NameObserver.h> ----------------#include<Observer.h>#include<Person.h>classNameObserver:publicObserver<Person,Person::StateChange>{public:voidupdate(Personconst&person,Person::StateChangeproperty)override;};//---- <NameObserver.cpp> ----------------#include<NameObserver.h>voidNameObserver::update(Personconst&person,Person::StateChangeproperty){if(property==Person::forenameChanged||property==Person::surnameChanged){// ... Respond to changed name}}//---- <AddressObserver.h> ----------------#include<Observer.h>#include<Person.h>classAddressObserver:publicObserver<Person,Person::StateChange>{public:voidupdate(Personconst&person,Person::StateChangeproperty)override;};//---- <AddressObserver.cpp> ----------------#include<AddressObserver.h>voidAddressObserver::update(Personconst&person,Person::StateChangeproperty){if(property==Person::addressChanged){// ... Respond to changed address}}
Equipped with these two observers, you are now notified whenever either the name or address of a person changes:
#include<AddressObserver.h>#include<NameObserver.h>#include<Person.h>#include<cstdlib>intmain(){NameObservernameObserver;AddressObserveraddressObserver;Personhomer("Homer","Simpson");Personmarge("Marge","Simpson");Personmonty("Montgomery","Burns");// Attaching observershomer.attach(&nameObserver);marge.attach(&addressObserver);monty.attach(&addressObserver);// Updating information on Homer Simpsonhomer.forename("Homer Jay");// Adding his middle name// Updating information on Marge Simpsonmarge.address("712 Red Bark Lane, Henderson, Clark County, Nevada 89011");// Updating information on Montgomery Burnsmonty.address("Springfield Nuclear Power Plant");// Detaching observershomer.detach(&nameObserver);returnEXIT_SUCCESS;}
After these many implementation details, let’s take a step back and look at the bigger picture again. Figure 6-3 shows the dependency graph for this Observer example.

Figure 6-3. Dependency graph for the Observer design pattern
Due to the decision to implement the Observer class in the form
of a class template, the Observer class resides on the highest level of our architecture.
This enables you to reuse the Observer class for multiple purposes, for instance, for the
Person class. The Person class declares its own Observer<Person,Person::StateChange> type
and by that injects the code into its own architectural level. Concrete person observers,
e.g., NameObserver and AddressObserver, can subsequently build on this declaration.
An Observer Implementation Based on Value Semantics
“I understand why you’ve started with a classic implementation, but since you have
made the point about favoring value semantics, how would the observer look in a
value semantics world?” That is an excellent question, since this a very reasonable
next step. As explained in “Guideline 22: Prefer Value Semantics over
Reference Semantics”, there
are a lot of good reasons to avoid the realm of reference semantics. However, we
won’t entirely stray from the classic implementation: to register and
deregister observers, we will always be in need of some unique identifier for
observers, and the unique address of an observer is just the easiest and most
convenient way to tackle that problem. Therefore, we’ll stick to using a pointer
to refer to a registered observer. However, std::function is an elegant way to avoid the
inheritance hierarchy—std::function:
//---- <Observer.h> ----------------#include<functional>template<typenameSubject,typenameStateTag>classObserver{public:usingOnUpdate=std::function<void(Subjectconst&,StateTag)>;// No virtual destructor necessaryexplicitObserver(OnUpdateonUpdate):onUpdate_{std::move(onUpdate)}{// Possibly respond on an invalid/empty std::function instance}// Non-virtual update functionvoidupdate(Subjectconst&subject,StateTagproperty){onUpdate_(subject,property);}private:OnUpdateonUpdate_;};
Instead of implementing the Observer class as a base class, and thus requiring deriving
classes to inherit and implement the update() function in a very specific way, we
separate concerns and instead build on composition (see “Guideline 20: Favor Composition over Inheritance”).
The Observer class first provides a type alias called OnUpdate for the std::function
type for the expected signature of our update() function
(![]() ).
Via the constructor, you are passed an instance of
).
Via the constructor, you are passed an instance of
std::function
(![]() ),
and you move it into your data member
),
and you move it into your data member onUpdate_
(![]() ).
The job of the
).
The job of the update() function is now to forward the call, including the arguments, to
onUpdate_
(![]() ).
).
The flexibility gained with std::function is easily demonstrated with an updated
main() function:
#include<Observer.h>#include<Person.h>#include<cstdlib>voidpropertyChanged(Personconst&person,Person::StateChangeproperty){if(property==Person::forenameChanged||property==Person::surnameChanged){// ... Respond to changed name}}intmain(){usingPersonObserver=Observer<Person,Person::StateChange>;PersonObservernameObserver(propertyChanged);PersonObserveraddressObserver([/*captured state*/](Personconst&person,Person::StateChangeproperty){if(property==Person::addressChanged){// ... Respond to changed address}});Personhomer("Homer","Simpson");Personmarge("Marge","Simpson");Personmonty("Montgomery","Burns");// Attaching observershomer.attach(&nameObserver);marge.attach(&addressObserver);monty.attach(&addressObserver);// ...returnEXIT_SUCCESS;}
Thanks to choosing a less intrusive approach and to decoupling with
std::function,
the choice of how to implement the update() function is completely up to the observer’s
implementer (stateless, stateful, etc.). For the nameObserver, we build on the free
function propertyChanged(), which itself is strongly decoupled because it’s not bound
to a class and might be reused on several occasions. The
addressObserver, on the other
hand, chooses a lambda instead, which could possibly capture some state. Either way, the
only convention that these two have to follow is to fulfill the required signature of the
required std::function type.
“Why do we still need the Observer class? Couldn’t we just directly use
std::function?”
Yes, it most certainly looks that way. From a functionality point of view, the Observer
class doesn’t add anything by itself. However, as std::function is a true child of
value semantics, we tend to copy or move std::function objects. But this is not desirable
in this situation: especially if you use a stateful observer, you don’t want a copy of your
observer to be called. And although technically possible, it is not particularly common to
pass around pointers to std::function. Therefore, the Observer class may still be of
value in the form of an Adapter for std::function
(see “Guideline 24: Use Adapters to Standardize Interfaces”).
Analyzing the Shortcomings of the Observer Design Pattern
“This is not quite the value semantics solution I was expecting, but I still like it!” Well, I’m glad you feel this way. Indeed, the value semantics advantages, in combination with the benefits of the Observer design pattern (i.e., decoupling an event from the action taken for that event and the ability to easily add new kinds of observers), work really, really well. Unfortunately, there is no perfect design, and every design also comes with disadvantages.
First, I should explicitly spell out that the demonstrated std::function approach
works well only for a pull observer with a single update() function. Since
std::function can cope with only a single callable, any approach that would
require multiple update() functions cannot be handled by a single
std::function. Therefore, std::function is usually not the way to go for a
push observer with multiple update() functions, or the potential for a growing
number of update() functions (remember, code tends to change!). However, it is
possible to generalize the approach of std::function. If the need arises,
the design pattern of choice is Type Erasure (see Chapter 8).
A second (minor) disadvantage, as you have seen, is that there is no pure value-based implementation. While we might be able to implement the update() functionality
in terms of std::function to gain flexibility, we still use a raw pointer to attach
and detach Observers. And that is easy to explain: the advantages of using a pointer
as a unique identifier are just too good to dismiss. Additionally, for a stateful
Observer, we don’t want to deal with the copy of an entity. Still, this of course
requires us to check for nullptr (which takes additional effort), and we always have
to pay for the indirection that the pointer represents.13 I personally would
rate this as only a minor point because of the many advantages of this approach.
A far bigger disadvantage is the potential implementation issues with Observers: the order of registration and deregistration may matter a lot, in particular if an observer is allowed to register multiple times. Also, in a multithreaded environment, the thread-safe registration and deregistration of observers and handling of events are highly nontrivial topics. For instance, an untrusted observer can freeze a server during a callback if it behaves inappropriately, and implementing timeouts for arbitrary computations is very nontrivial. However, this topic is far outside the scope of this book.
What is in the scope of this book, however, is the alleged danger that the overuse of observers can quickly and easily lead to a complex network of interconnections. Indeed, if you are not careful, you can accidentally introduce an infinite loop of callbacks! For that reason, developers are sometimes concerned about using Observers and are afraid that a single notification may result in a huge, global response due to these interconnections. While this danger exists, of course, a proper design should not be severely affected by this: if you have a proper architecture and if you have properly implemented your observers, then any sequence of notifications should always run along a directed, acyclic graph (DAG) toward the lower levels of your architecture. And that, of course, is the beauty of good software design.
In summary, with the intent of providing a solution for notification of state change, the Observer design pattern proves to be one of the most famous and most commonly used design patterns. Aside from the potentially tricky implementation details, it is definitely one of the design patterns that should be in every developer’s toolbox.
Guideline 26: Use CRTP to Introduce Static Type Categories
C++ really has a lot to offer. It comes with lots of features, many syntactic curiosities, and a large number of amazing, utterly unpronounceable and (for the uninitiated) plainly cryptic acronyms: RAII, ADL, CTAD, SFINAE, NTTP, IFNDR, and SIOF. Oh, what fun! One of these cryptic acronyms is CRTP, short for the Curiously Recurring Template Pattern.14 If you’re’ scratching your head because the name doesn’t make any sense to you, don’t worry: as is so often in C++, the name was chosen randomly, but has stuck and has never been reconsidered or changed. The pattern was named by James Coplien in the February 1995 issue of the C++ Report after realizing that, curiously, this pattern was recurring in many different C++ codebases.15 And curiously, this pattern, although building on inheritance and (potentially) serving as an abstraction, does not exhibit the usual performance drawbacks of many other classic design patterns. For that reason, CRTP is definitely worth a look, as it may become a valuable, or should I say curious, addition to your design pattern toolbox.
A Motivation for CRTP
Performance is very important in C++. So important in fact, that in several contexts the performance overhead of using virtual functions is considered outright unacceptable. Therefore, in performance-sensitive contexts, such as certain parts of computer games or high-frequency trading, no virtual functions are used. The same is true for high-performance computing (HPC). In HPC, any kind of conditional or indirection, and this includes virtual functions, is banned from the most performance-critical parts, such as the innermost loops of compute kernels. Using them would incur too much of a performance overhead.
To give an example of how and why this matters, let’s consider the following
DynamicVector
class template from a linear algebra (LA) library:
//---- <DynamicVector.h> ----------------#include<numeric>#include<iosfwd>#include<iterator>#include<vector>// ...template<typenameT>classDynamicVector{public:usingvalue_type=T;usingiterator=typenamestd::vector<T>::iterator;usingconst_iterator=typenamestd::vector<T>::const_iterator;// ... Constructors and special member functionssize_tsize()const;T&operator[](size_tindex);Tconst&operator[](size_tindex)const;iteratorbegin();const_iteratorbegin()const;iteratorend();const_iteratorend()const;// ... Many numeric functionsprivate:std::vector<T>values_;// ...};template<typenameT>std::ostream&operator<<(std::ostream&os,DynamicVectorconst<T>&vector){os<<"(";for(autoconst&element:vector){os<<""<<element;}os<<")";returnos;}template<typenameT>autol2norm(DynamicVectorconst<T>&vector){usingstd::begin,std::end;returnstd::sqrt(std::inner_product(begin(vector),end(vector),begin(vector),T{}));}// ... Many more
Despite the name, DynamicVector does not represent a container but a numerical vector
for the purpose of LA computations. The Dynamic part of the name implies that it
allocates its elements of type T dynamically, in this example, in the form of std::vector
(![]() ).
For that reason, it is suited for large LA problems (definitely in the range of several million
elements). Although this class may be loaded with many numerical operations, from an
interface point of view you might indeed be tempted to call it a container: it provides
the usual nested types (
).
For that reason, it is suited for large LA problems (definitely in the range of several million
elements). Although this class may be loaded with many numerical operations, from an
interface point of view you might indeed be tempted to call it a container: it provides
the usual nested types (value_type, iterator, and const_iterator)
(![]() ),
a
),
a size() function to query the current number of elements
(![]() ),
subscript operators to access individual elements by index (one for non-
),
subscript operators to access individual elements by index (one for non-const and one
for const vectors)
(![]() ),
and
),
and begin() and end() functions to iterate over the elements
(![]() ).
Apart from the member functions, it also provides an output operator
(
).
Apart from the member functions, it also provides an output operator
(![]() )
and, to show at least one LA operation, a function to compute the vector’s
Euclidean norm (often
also called the L2 norm, because it approximates the L2 norm for discrete vectors)
(
)
and, to show at least one LA operation, a function to compute the vector’s
Euclidean norm (often
also called the L2 norm, because it approximates the L2 norm for discrete vectors)
(![]() ).
).
The DynamicVector is not the only vector class, though. In our LA library, you will
also find the following StaticVector class:
//---- <StaticVector.h> ----------------#include<array>#include<numeric>#include<iosfwd>#include<iterator>// ...template<typenameT,size_tSize>classStaticVector{public:usingvalue_type=T;usingiterator=typenamestd::array<T,Size>::iterator;usingconst_iterator=typenamestd::array<T,Size>::const_iterator;// ... Constructors and special member functionssize_tsize()const;T&operator[](size_tindex);Tconst&operator[](size_tindex)const;iteratorbegin();const_iteratorbegin()const;iteratorend();const_iteratorend()const;// ... Many numeric functionsprivate:std::array<T,Size>values_;// ...};template<typenameT,size_tSize>std::ostream&operator<<(std::ostream&os,StaticVector<T,Size>const&vector){os<<"(";for(autoconst&element:vector){os<<""<<element;}os<<")";returnos;}template<typenameT,size_tSize>autol2norm(StaticVector<T,Size>const&vector){usingstd::begin,std::end;returnstd::sqrt(std::inner_product(begin(vector),end(vector),begin(vector),T{}));}
“Isn’t this almost the same as the DynamicVector class?” you wonder. Yes, these
two classes are very similar indeed. The StaticVector class provides the same interface
as the DynamicVector, such as the nested types value_type, iterator, and
const_iterator
(![]() );
the
);
the size() member function
(![]() );
the subscript operators
(
);
the subscript operators
(![]() );
and the
);
and the begin() and end() functions
(![]() ).
It also comes with an output operator
(
).
It also comes with an output operator
(![]() )
and a free
)
and a free l2norm() function
(![]() ).
However, there is an important, performance-related difference between the two vector classes:
as the
).
However, there is an important, performance-related difference between the two vector classes:
as the Static in the name suggests, the
StaticVector does not allocate its elements
dynamically. Instead, it uses an in-class buffer to store its elements, for instance, with a std::array
(![]() ).
Thus, in
contrast to
).
Thus, in
contrast to
DynamicVector, the entire functionality of StaticVector is optimized
for a small, fixed number of elements, such as 2D or 3D vectors.
“OK, I understand that this is important for performance, but there’s still a lot of code duplication, right?” Again, you are correct. If you take a close look at the associated output operator of the two vector classes, you will find that the implementation of these two functions is identical. This is deeply undesirable: if anything changes, for instance, the way vectors are formatted (and remember: change is the one constant in software development and needs to be expected; see “Guideline 2: Design for Change”), then you would have to make the change in many places, not just one. This is a violation of the Don’t Repeat Yourself (DRY) principle: it’s easy to forget or miss updating one of the many places, thus introducing an inconsistency or even a bug.
“But isn’t this duplication easily resolved with a slightly more general function template? For example, I can imagine the following output operator for all kinds of dense vectors:”
template<typenameDenseVector>std::ostream&operator<<(std::ostream&os,DenseVectorconst&vector){// ... as before}
Although this seems like an adequate solution, I wouldn’t accept this code in a pull
request. This function template is indeed more general, but I would definitely not call
it “slightly” more general; what you are suggesting is the most general output operator one
could possibly write. Yes, the name of the function template may suggest that it’s written
for only dense vectors (including DynamicVector and StaticVector), but this function
template will in fact accept any type: DynamicVector, StaticVector, std::vector,
std::string, and fundamental types such as int and double. It simply fails
to specify any requirement or any kind of constraint. For that reason it violates
Core Guideline T.10:16
Specify concepts for all template arguments.
While this output operator will work for all dense vectors and sequence containers, you would get a compilation error for all types that do not provide the expected interface. Or even worse, you might subtly violate the implicit requirements and expectations, and with that the LSP (see “Guideline 6: Adhere to the Expected Behavior of Abstractions”). Of course, you wouldn’t do this consciously, but likely accidentally: this output operator is a perfect match for any type and might be used even though you don’t expect it. Therefore, this function template would be a very unfortunate addition to the output operator overload set. What we need is a totally new set of types, a new type category.
“Isn’t this what base classes are for? Couldn’t we just formulate a DenseVector
base class that defines the expected interface for all dense vectors? Consider the
following sketch of a DenseVector base class:”
template<typenameT>// Type of the elementsclassDenseVector{public:virtual~DenseVector()=default;virtualsize_tsize()const=0;virtualT&operator[](size_tindex)=0;virtualTconst&operator[](size_tindex)const=0;// ...};template<typenameT>std::ostream&operator<<(std::ostream&os,DenseVector<T>const&vector){// ... as before}
“This should work, right? I’m just not sure how to declare the begin() and end()
functions, as I don’t know how to abstract from different iterator types, such as
std::vector<T>::iterator and std::array<T>::iterator.” I also have a feeling that
this could be a problem, and I admit that I also do not have a quick solution for that.
But there is something far more concerning: with this base class, we would turn all our
member functions into virtual member functions. That would include the begin() and
end() functions but, most importantly, the two subscript operators. The consequences
would be significant: with every access to an element of the vector, we would now have
to call a virtual function. Every single access! Therefore, with this base class,
we could wave goodbye to high performance.
Still, the general idea of building an abstraction with a base class is good. We just have to do it differently. This is where we should take a closer look at the CRTP.
The CRTP Design Pattern Explained
The CRTP design pattern builds on the common idea of creating an abstraction using a base class. But instead of establishing a runtime relationship between base and derived classes via virtual functions, it creates a compile-time relationship.
The compile-time relationship between the DenseVector base class and the
DynamicVector
derived class is created by upgrading the base class to a class
template:
//---- <DenseVector.h> ----------------template<typenameDerived>structDenseVector{// ...size_tsize()const{returnstatic_cast<Derivedconst&>(*this).size();}// ...};//---- <DynamicVector.h> ----------------template<typenameT>classDynamicVector:publicDenseVector<DynamicVector<T>>{public:// ...size_tsize()const;// ...};
The curious detail about CRTP is that the new template parameter of the
DenseVector base
class represents the type of the associated derived class
(![]() ).
Derived classes, for instance, the
).
Derived classes, for instance, the
DynamicVector, are expected to provide their own type to
instantiate the base class
(![]() ).
).
“Wow, wait a second—is that even possible?” you ask. It is. To instantiate a
template, you do not need the complete definition of a type. It is sufficient to use an incomplete
type. Such an incomplete type is available after the compiler has seen the class DynamicVector
declaration. In essence, this piece of syntax works as a forward declaration. Therefore, the
DynamicVector class can indeed use itself as a template argument to the DenseVector base
class.
Of course, you can name the template parameter of the base class however you’d like (e.g., simply T),
but as discussed in “Guideline 14: Use a Design Pattern’s Name to Communicate Intent”, it helps to communicate
intent by using the name of the design pattern or names commonly used for a pattern. For that
reason, you could name the parameter CRTP, which nicely communicates the pattern but
unfortunately only to the initiated. Everyone else will be puzzled by the acronym. Therefore,
the template parameter is often called Derived, which perfectly expresses its purpose and
communicates its intent: it represents the type of the derived class.
Via this template parameter, the base class is now aware of the actual type of the derived
type. While it still represents an abstraction and the common interface for all dense
vectors, it is now able to access and call the concrete implementation in the derived type.
This happens, for instance, in the size() member function
(![]() ):
the
):
the DenseVector uses a static_cast to convert itself into a reference to the derived class
and calls the size() function on that. What at first glance may look like a recursive function
call (calling the size() function within the size() function) is in fact a call of the
size() member function in the derived class
(![]() ).
).
“So this is the compile-time relationship you were taking about. The base class
represents an abstraction from concrete derived types and implementation details but still
knows exactly where the implementation details are. So we really do not need any virtual
function.” Correct. With CRTP, we are now able to
implement a common interface and forward every call to the derived class by simply performing
a static_cast. And there is no performance penalty for doing this. In fact, the base class
function is very likely to be inlined, and if the DenseVector is the only or first base
class, the static_cast will not even result in a single assembly instruction. It merely
tells the compiler to treat the object as an object of the derived type.
To provide a clean CRTP base class, we should update a couple of details, though:
//---- <DenseVector.h> ----------------template<typenameDerived>structDenseVector{protected:~DenseVector()=default;public:Derived&derived(){returnstatic_cast<Derived&>(*this);}Derivedconst&derived()const{returnstatic_cast<Derivedconst&>(*this);}size_tsize()const{returnderived().size();}// ...};
Since we want to avoid any virtual functions, we’re also not interested in a virtual
destructor. Therefore, we implement the destructor as a nonvirtual function in the
protected section of the class
(![]() ).
This perfectly adheres to
Core Guideline C.35:
).
This perfectly adheres to
Core Guideline C.35:
A base class destructor should be either public and virtual, or protected and non-virtual.
Keep in mind, though, that this definition of the destructor keeps the compiler from generating the two move operations. Since a CRTP base class is usually empty with nothing to move, this is not a problem; but still, always be mindful about the Rule of 5.
We should also avoid using a static_cast in every single member function of the base
class. Although it would be correct, any cast should be considered suspicious, and
casts should be minimized.17
For that reason, we add the two derived() member functions, which perform the cast and can be
used in the other member functions
(![]() ).
This resulting code not only looks cleaner and adheres to the DRY principle, but it also
looks far less suspicious.
).
This resulting code not only looks cleaner and adheres to the DRY principle, but it also
looks far less suspicious.
Equipped with the derived() functions, we can now go ahead and define the subscript
operators and the begin() and end() functions:
template<typenameDerived>structDenseVector{// ...???operator[](size_tindex){returnderived()[index];}???operator[](size_tindex)const{returnderived()[index];}???begin(){returnderived().begin();}???begin()const{returnderived().begin();}???end(){returnderived().end();}???end()const{returnderived().end();}// ...};
However, these functions are not as straightforward as the size() member function.
In particular, the return types prove to be a little harder to specify, as these types
depend on the implementation of the Derived class. “Well, that shouldn’t be too hard,”
you say. “This is why the derived types provide a couple of nested types,
such as value_type, iterator, and const_iterator, right?” Indeed, it appears to be
intuitive to just ask nicely:
template<typenameDerived>structDenseVector{// ...usingvalue_type=typenameDerived::value_type;usingiterator=typenameDerived::iterator;usingconst_iterator=typenameDerived::const_iterator;value_type&operator[](size_tindex){returnderived()[index];}value_typeconst&operator[](size_tindex)const{returnderived()[index];}iteratorbegin(){returnderived().begin();}const_iteratorbegin()const{returnderived().begin();}iteratorend(){returnderived().end();}const_iteratorend()const{returnderived().end();}// ...};
We query for the value_type, iterator, and const_iterator types in the derived
class (don’t forget the typename keyword) and use these to specify our return types
(![]() ).
Easy, right? You can almost bet that it’s not that easy. If you try this,
the Clang compiler will complain with a seriously weird and baffling error message:
).
Easy, right? You can almost bet that it’s not that easy. If you try this,
the Clang compiler will complain with a seriously weird and baffling error message:
CRTP.cpp:29:41: error: no type named 'value_type' in 'DynamicVector<int>'
using value_type = typename Derived::value_type;
~~~~~~~~~~~~~~~~~~^~~~~~~~~~
“No value_type in DynamicVector<int>—strange.” The first idea that crosses your mind
is that you messed up. It must be a typo. Of course! So you go back to your code and check
the spelling. However, it turns out that everything seems to be OK. There is no typo. You
check the DynamicVector class again: there it is, the nested value_type member. And
everything is public, too. The error message just doesn’t make any sense. You reexamine
everything, and again, and half an hour later you conclude, “The compiler has a bug!”
No, it isn’t a bug in the compiler. Not in Clang or any other compiler. GCC provides a different, still slightly puzzling, but a perhaps little more illuminating error message:18
CRTP.cpp:29:10: error: invalid use of incomplete type 'class DynamicVector<int>'
29 | using value_type = typename Derived::value_type;
| ^~~~~~~~~~
The Clang compiler is correct: there is no value_type in the DynamicVector class.
Not yet! When you query for the nested types, the definition of the
DynamicVector class hasn’t been seen, and DynamicVector is still an incomplete type.
That’s because the compiler will instantiate the DenseVector base class before the
definition of the DynamicVector class. After all, syntactically, the base class is
specified before the body of the class:
template<typenameT>classDynamicVector:publicDenseVector<DynamicVector<T>>// ...
In consequence, there is no way that you can use the nested types of the derived class for the return types of the CRTP class. In fact, you can’t use anything as long as the derived class is an incomplete type. “But why can I call the member functions of the derived class? Shouldn’t this result in the same problem?” Luckily, this works (otherwise the CRTP pattern would not work at all). But it only works because of a special property of class templates: member functions are only instantiated on demand, meaning when they are actually called. Since an actual call usually happens only after the definition of the derived class is available, there is no problem with a missing definition. At that point, the derived class is not an incomplete type anymore.
“OK, I get it. But how do we specify the return types of the subscript operators and
begin() and end() functions?” The most convenient way to handle this is to use
return type deduction. This is a perfect opportunity to use the decltype(auto)
return type:
template<typenameDerived>structDenseVector{// ...decltype(auto)operator[](size_tindex){returnderived()[index];}decltype(auto)operator[](size_tindex)const{returnderived()[index];}decltype(auto)begin(){returnderived().begin();}decltype(auto)begin()const{returnderived().begin();}decltype(auto)end(){returnderived().end();}decltype(auto)end()const{returnderived().end();}};
“Wouldn’t it be enough to just use auto? For instance, we could define the return
types like this:”
template<typenameDerived>structDenseVector{// ... Note: this doesn't always work, whereas decltype(auto) always worksauto&operator[](size_tindex){returnderived()[index];}autoconst&operator[](size_tindex)const{returnderived()[index];}autobegin(){returnderived().begin();}autobegin()const{returnderived().begin();}autoend(){returnderived().end();}autoend()const{returnderived().end();}};
It would be enough for this example, yes. However, as I keep emphasizing, code changes.
Eventually, there may be another, deriving vector class that does not store its values
and returns references to its values but produces values and returns
by value. And yes, this is easily conceivable: consider, for instance, a
ZeroVector class,
which represents the zero element for vectors.
Such a vector would not store all of its elements, as this would be wasteful, but would
likely be implemented as an empty class, which returns a zero by value every time an element
is accessed. In that case, an auto& return type would be incorrect. Yes, the compiler
would (hopefully) warn you about that. But you could avoid the entire problem by just
returning exactly what the deriving class returns. And that kind of return type is
represented by the decltype(auto) return.
Analyzing the Shortcomings of the CRTP Design Pattern
“Wow, this CRTP design pattern sounds amazing. So seriously, apart from these slightly-more-complex-than-usual implementation details, isn’t this the solution to all performance issues with virtual functions? And isn’t this the key, the holy grail for all inheritance-related problems?” I can understand the enthusiasm! At first sight, CRTP most definitely looks like the ultimate solution for all kinds of inheritance hierarchies. Unfortunately, that is an illusion. Remember: every design pattern comes with benefits but unfortunately also with drawbacks. And there are several pretty limiting drawbacks to the CRTP design pattern.
The first, and one of the most restricting, drawbacks is the lack of a
common base class.
I will repeat this to emphasize the gravity of the repercussions: there is no common
base class! Effectively, every single derived class has a different base class. For example,
the DynamicVector<T> class has the DenseVector<DynamicVector<T>> base class. The StaticVector<T,Size> class has the DenseVector<StaticVector<T,Size>> base class (see
Figure 6-4). Thus, whenever a common base class is required, a common
abstraction that can be used, for instance, to store different types in a collection, the
CRTP design pattern is not the right choice.
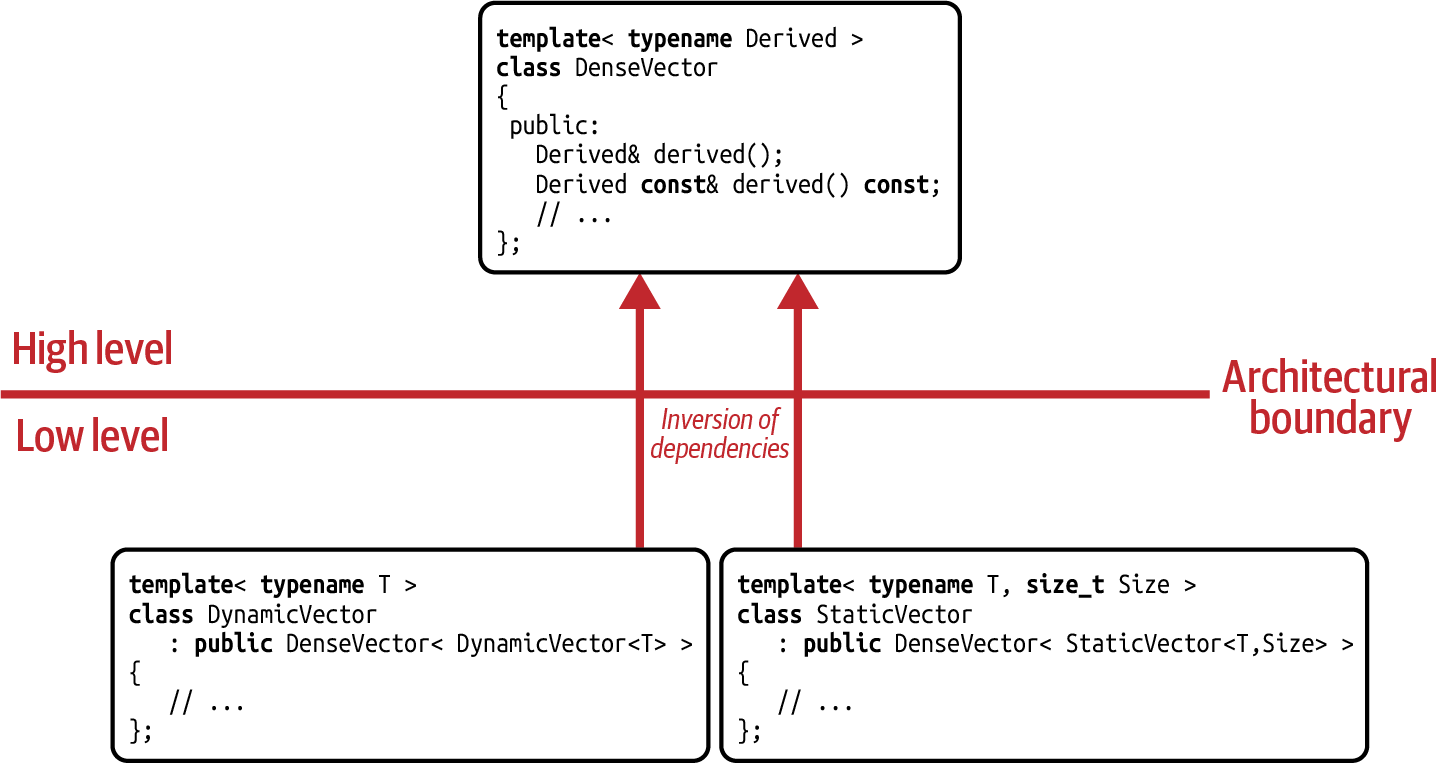
Figure 6-4. Dependency graph for the CRTP design pattern
“Oh, wow, I see that this could be a real limitation. But couldn’t we just make the
CRTP base class derive from a common base class?” you argue. No, not really, because this
would require us to introduce virtual functions again. “OK, I see. What about simulating a
common base class using std::variant?” Yes, that’s an option. However, please
remember that std::variant is a representation of the Visitor design pattern (see
“Guideline 16: Use Visitor to Extend Operations”). And since std::variant needs
to know about all its potential alternatives, this will limit your freedom to add new types.
So you see, even though you might not like it, CRTP really is not a replacement for
every inheritance hierarchy.
The second, also potentially very limiting drawback is that everything that
comes in touch with a CRTP base class becomes a template itself. That is particularly
true for all functions that work with such a base class. Consider, for instance, the upgraded
output operator and the l2norm() function:
template<typenameDerived>std::ostream&operator<<(std::ostream&os,DenseVector<Derived>const&vector);template<typenameDerived>autol2norm(DenseVector<Derived>const&vector);
These two functions should work with all classes deriving from the DenseVector CRTP
class. And of course they should not depend on the concrete types of the derived classes.
Therefore, these two functions must be function templates: the Derived type must be
deduced. While in the context of a linear algebra library this is usually not an issue
because almost all functionality is implemented in terms of templates anyway, this may
be a big downside in other contexts. It might be highly
undesirable to turn lots of
code into templates and move the definitions into header files, effectively sacrificing
the encapsulation of source files. Yes, this may be a severe drawback indeed!
Third, CRTP is an intrusive design pattern. Deriving classes have to explicitly opt in by inheriting from the CRTP base class. While this may be a nonissue in our
own code, you cannot easily add a base class to foreign code. In such a situation,
you would have to resort to the Adapter design pattern (see
“Guideline 24: Use Adapters to Standardize Interfaces”). Thus, CRTP does not provide
the flexibility of nonintrusive design patterns (e.g., the Visitor design pattern
implemented with std::variant, the Adapter design pattern, and so on).
Last but not least, CRTP does not provide runtime polymorphism, only compile-time polymorphism. Therefore, the pattern makes sense only if some kind of static type abstraction is required. If not, it is again not a replacement for all inheritance hierarchies.
The Future of CRTP: A Comparison Between CRTP and C++20 Concepts
“I understand, you’re right. CRTP is pure compile-time polymorphism. However, this makes me wonder: wouldn’t it be possible to build on C++20 concepts instead of CRTP? Consider the following code. We could use a concept to define the requirements for a set of types, and restrict functions and operators to only those types that provide the expected interface:”19
template<typenameT>conceptDenseVector=requires(Tt,size_tindex){t.size();t[index];{t.begin()}->std::same_as<typenameT::iterator>;{t.end()}->std::same_as<typenameT::iterator>;}&&requires(Tconstt,size_tindex){t[index];{t.begin()}->std::same_as<typenameT::const_iterator>;{t.end()}->std::same_as<typenameT::const_iterator>;};template<DenseVectorVectorT>std::ostream&operator<<(std::ostream&os,VectorTconst&vector){// ... as before}
You are absolutely correct. I agree, this is a very reasonable alternative. Indeed, C++20 concepts are pretty similar to CRTP but represent an easier, nonintrusive alternative. Especially by being nonintrusive, if you have access to C++20 concepts and it is possible to define the static set of types by a concept, you should prefer the concept over the CRTP.
Still, I’m not entirely happy with this solution. While this formulation of the output
operator effectively constrains the function template to only those types that provide
the expected interface, it does not completely restrict the function template to our set
of dense vector types. It’s still possible to pass std::vector and std::string
(std::string already has an output operator in the std namespace). Therefore, this concept
is not specific enough. But if you run into this situation, don’t worry: there is a solution
using a tag class:
structDenseVectorTag{};template<typenameT>conceptDenseVector=// ... Definition of all requirements on a dense vector (as before)&&std::is_base_of_v<DenseVectorTag,T>;template<typenameT>classDynamicVector:privateDenseVectorTag{// ...};
By inheriting (preferably nonpublicly) from the DenseVectorTag class
(![]() ),
classes like
),
classes like DynamicVector can identify as being part of a certain set of
types
(![]() ).
Function and operator templates can therefore be effectively limited to accept only those
types that explicitly opt in to the set of types. Unfortunately, there’s a catch: this
approach is no longer nonintrusive. To overcome this limitation, we introduce
a compile-time indirection by a customizable type trait class. In other words,
we apply the SRP and separate concerns:
).
Function and operator templates can therefore be effectively limited to accept only those
types that explicitly opt in to the set of types. Unfortunately, there’s a catch: this
approach is no longer nonintrusive. To overcome this limitation, we introduce
a compile-time indirection by a customizable type trait class. In other words,
we apply the SRP and separate concerns:
structDenseVectorTag{};template<typenameT>structIsDenseVector:publicstd::is_base_of<DenseVectorTag,T>{};template<typenameT>constexprboolIsDenseVector_v=IsDenseVector<T>::value;template<typenameT>conceptDenseVector=// ... Definition of all requirements on a dense vector (as before)&&IsDenseVector_v<T>;template<typenameT>classDynamicVector:privateDenseVectorTag{// ...};template<typenameT,size_tSize>classStaticVector{// ...};template<typenameT,size_tSize>structIsDenseVector<StaticVector<T,Size>>:publicstd::true_type{};
The IsDenseVector class template, along with its corresponding variable template, indicates whether a given type is part of the set of dense vector types
(![]() and
and
![]() ).
Instead of directly querying a given type, the
).
Instead of directly querying a given type, the DenseVector concept would ask indirectly via
the IsDenseVector type trait
(![]() ).
This opens up the opportunity for classes to either intrusively derive from the
).
This opens up the opportunity for classes to either intrusively derive from the DenseVectorTag
(![]() )
or to nonintrusively specialize the
)
or to nonintrusively specialize the IsDenseVector type trait
(![]() ).
In this form, the concepts approach truly supersedes the classic CRTP approach.
).
In this form, the concepts approach truly supersedes the classic CRTP approach.
In summary, CRTP is an amazing design pattern for defining a compile-time relationship between a family of related types. Most interestingly, it resolves all performance issues that you may have with inheritance hierarchies. However, CRTP comes with a couple of potentially limiting drawbacks, such as the lack of a common base class, the quick spreading of template code, and the restriction to compile-time polymorphism. With C++20, consider replacing CRTP with concepts, which provide an easier and nonintrusive alternative. However, if you do not have access to C++20 concepts and if CRTP fits, it will prove immensely valuable to you.
Guideline 27: Use CRTP for Static Mixin Classes
In “Guideline 26: Use CRTP to Introduce Static Type Categories”, I introduced you to the CRTP design pattern. I may also have given you the impression that CRTP is old hat, made obsolete by the advent of C++20 concepts. Well, interestingly it is not. At least not entirely. That’s because I haven’t told you the complete story yet. CRTP may still be of value: just not as a design pattern but as an implementation pattern. So let’s take a detour into the realm of implementation patterns and let me explain.
A Strong Type Motivation
Consider the following StrongType class template, which represents a wrapper around any
other type for the purpose of creating a unique, named type:20
//---- <StrongType.h> ----------------#include<utility>template<typenameT,typenameTag>structStrongType{public:usingvalue_type=T;explicitStrongType(Tconst&value):value_(value){}T&get(){returnvalue_;}Tconst&get()const{returnvalue_;}private:Tvalue_;};
This class can, for instance, be used to define the types Meter, Kilometer, and
Surname:21
//---- <Distances.h> ----------------#include<StrongType.h>template<typenameT>usingMeter=StrongType<T,structMeterTag>;template<typenameT>usingKilometer=StrongType<T,structKilometerTag>;// ...//---- <Person.h> ----------------#include<StrongType.h>usingSurname=StrongType<std::string,structSurnameTag>;// ...
The use of alias templates for Meter and Kilometer enables you to choose, for instance,
long or double to represent a distance. However, although these types are built on
fundamental types or Standard Library types, such as std::string in the case of Surname,
they represent distinct types (strong types) with semantic meaning that cannot be
(accidentally) combined in arithmetic operations, for example,
addition:
//---- <Main.cpp> ----------------#include<Distances.h>#include<cstdlib>intmain(){autoconstm1=Meter<long>{120L};autoconstm2=Meter<long>{50L};autoconstkm=Kilometer<long>{30L};autoconstsurname1=Surname{"Stroustrup"};autoconstsurname2=Surname{"Iglberger"};// ...m1+km;// Correctly does not compile!surname1+surname2;// Also correctly does not compile!m1+m2;// Inconveniently this does not compile either.returnEXIT_SUCCESS;}
Although both Meter and Kilometer are represented via long, it isn’t
possible to directly add Meter and Kilometer together
(![]() ).
This is great: it doesn’t leave any opening for accidental bugs to crawl in. It’s also not possible to add two
).
This is great: it doesn’t leave any opening for accidental bugs to crawl in. It’s also not possible to add two Surnames, although std::string
provides an addition operator for string concatenation
(![]() ).
But this is also great: the strong type effectively restricts undesired operations
of the underlying type. Unfortunately, this “feature” also prevents the addition of two
).
But this is also great: the strong type effectively restricts undesired operations
of the underlying type. Unfortunately, this “feature” also prevents the addition of two
Meter instances
(![]() ).
This operation would be desirable, though: it is intuitive, natural, and since the result
of the operation would again be of type
).
This operation would be desirable, though: it is intuitive, natural, and since the result
of the operation would again be of type Meter, physically accurate. To make this work, we could implement an addition operator for the Meter type. However,
obviously, this would not remain the only addition operator. We would also need one for
all the other strong types, such as Kilometer, Mile, Foot, etc. Since all of these
implementations would look the same, this would be a violation of the DRY principle. Therefore, it appears to be reasonable to extend the StrongType class
template with an addition operator:
template<typenameT,typenameTag>StrongType<T,Tag>operator+(StrongType<T,Tag>const&a,StrongType<T,Tag>const&b){returnStrongType<T,Tag>(a.get()+b.get());}
Whereas due to the formulation of this addition operator it is not possible to
add two different instantiations of StrongType together (e.g., Meter and Kilometer),
it would enable the addition of two instances of the same instantiation of StrongType.
“Oh, but I see a problem: while it would now be possible to add two Meters or two
Kilometers, it would also be possible to add two Surnames. We don’t want that!”
You are correct: this would be undesirable. What we need instead is a deliberate addition
of operations to specific instantiations of StrongType. This is where CRTP comes into
play.
Using CRTP as an Implementation Pattern
Instead of directly equipping the StrongType class template with operations, we provide the operations via mixin classes: base classes that “inject” the
desired operations. These mixin classes are implemented in terms of the CRTP.
Consider, for instance, the Addable class template, which represents the addition
operation:
//---- <Addable.h> ----------------template<typenameDerived>structAddable{friendDerived&operator+=(Derived&lhs,Derivedconst&rhs){lhs.get()+=rhs.get();returnlhs;}friendDerivedoperator+(Derivedconst&lhs,Derivedconst&rhs){returnDerived{lhs.get()+rhs.get()};}};
The name of the template parameters gives it away: Addable is a CRTP base class.
Addable provides only two functions, implemented
as hidden friends:
an addition assignment operator
(![]() )
and an addition operator
(
)
and an addition operator
(![]() ).
Both operators are defined for the specified
).
Both operators are defined for the specified Derived type and are injected into
the surrounding namespace.22 Thus, any class deriving
from this CRTP base class will “inherit” two free addition operators:
//---- <StrongType.h> ----------------#include<stdlib>#include<utility>template<typenameT,typenameTag>structStrongType:privateAddable<StrongType<T,Tag>>{/* ... */};//---- <Distances.h> ----------------#include<StrongType.h>template<typenameT>usingMeter=StrongType<T,structMeterTag>;// ...//---- <Main.cpp> ----------------#include<Distances.h>#include<cstdlib>intmain(){autoconstm1=Meter<long>{100};autoconstm2=Meter<long>{50};autoconstm3=m1+m2;// Compiles and results in 150 meters// ...returnEXIT_SUCCESS;}
“I understand the purpose of the mixin class, but in this form, all instantiations of
StrongType would inherit an addition operator, even the ones where an addition is
not required, right?” Yes, indeed. Therefore, we aren’t finished yet. What we want
to do is to selectively add the mixin class to those StrongType instantiations that
need the operation. Our solution of choice is to provide the mixins in the form of optional
template arguments. For that purpose, we extend the StrongType class template by a pack of
variadic template template parameters:23
//---- <StrongType.h> ----------------#include<utility>template<typenameT,typenameTag,template<typename>class...Skills>structStrongType:privateSkills<StrongType<T,Tag,Skills...>>...{/* ... */};
This extension enables us to individually specify, for each single strong type, which
skills are desired. Consider, for instance, the two additional skills Printable and
Swappable:
//---- <Printable.h> ----------------template<typenameDerived>structPrintable{friendstd::ostream&operator<<(std::ostream&os,constDerived&d){os<<d.get();returnos;}};//---- <Swappable.h> ----------------template<typenameDerived>structSwappable{friendvoidswap(Derived&lhs,Derived&rhs){usingstd::swap;// Enable ADLswap(lhs.get(),rhs.get());}};
Together with the Addable skill, we can now assemble strong types equipped with the
required and desired skills:
//---- <Distances.h> ----------------#include<StrongType.h>template<typenameT>usingMeter=StrongType<T,structMeterTag,Addable,Printable,Swappable>;template<typenameT>usingKilometer=StrongType<T,structKilometerTag,Addable,Printable,Swappable>;// ...//---- <Person.h> ----------------#include<StrongType.h>#include<string>usingSurname=StrongType<std::string,structSurnameTag,Printable,Swappable>;// ...
Both Meter and Kilometer can be added, printed, and swapped (see
![]() and
and
![]() ),
while
),
while Surname is printable and swappable, but not addable (i.e., does not receive the
Addable mixin and therefore does not derive from it)
(![]() ).
).
“That’s great. I understand the purpose of the CRTP mixin class in this context. But how
is this CRTP example different from previous examples?” Very good question. You’re right,
the implementation details are very similar. But there are a couple of distinctive
differences. Note that the CRTP base class doesn’t provide a virtual or protected
destructor. Hence, in contrast to previous examples, it is not designed as a polymorphic
base class. Also note that in this example it is sufficient, and even preferable, to
use the CRTP base class as a private base class, not a public one
(![]() ).
).
Thus, in this context, the CRTP base class does not represent an abstraction but only an implementation detail. Therefore, the CRTP does not fulfill the properties of a design pattern, and it does not act as a design pattern. It’s still a pattern, no question there, but it merely acts as an implementation pattern in this case.
The major difference in the implementation of the CRTP examples is the way we use
inheritance. For the CRTP design pattern, we use inheritance as an
abstraction according to the LSP: the base class represents the requirements, and thus
the available and expected behavior of the derived class. User code directly accesses the
operations via pointers or references to the base class, which in turn requires us
to provide a virtual or protected destructor. When implemented this way, CRTP
becomes a true element of software design—a design pattern.
In contrast, for the CRTP implementation pattern, we use inheritance for technical elegance and convenience. The base class becomes an implementation
detail and does not have to be known or used by calling code. Therefore, it doesn’t
need a
virtual or protected destructor. When implemented this way, CRTP stays
on the level of the implementation details and therefore is an implementation pattern. In
this form, however, CRTP does not compete with C++20 concepts. On the
contrary: in this form CRTP is unchallenged, as it represents a unique technique
to provide static mixin functionality. For that reason, CRTP is still in use today
and represents a valuable addition to every C++ developer’s toolbox.
In summary, CRTP is not obsolete, but its value has changed. In C++20, CRTP is replaced by concepts and therefore is stepping down as a design pattern. However, it continues to be valuable as an implementation pattern for mixin classes.
1 The Pages format is Apple’s equivalent to Microsoft’s Word format.
2 Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software.
3 If you’re an expert on design patterns, you might realize that a 1-to-N Adapter has a certain similarity to the Facade design pattern. See the GoF book for more details.
4 In C++20, you achieve a similar effect by applying the [[no_unique_address]] attribute to a data member. If the data member is empty, it might not occupy any storage on its own.
5 In this context, it’s particularly interesting to note that std::stack doesn’t allow you to traverse the elements via iterators. As usual for a stack, you’re allowed to access only the topmost element.
6 Matthew Wilson, Imperfect C++: Practical Solutions for Real-Life Programming (Addison-Wesley, 2004).
7 Eric Freeman and Elisabeth Robson, Head First Design Patterns: Building Extensible and Maintainable Object-Oriented Software (O’Reilly, 2021).
8 Of course, you know better than to try this at home, but let’s assume this is one of those strange, Monday-morning management decisions.
9 Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software.
10 Despite the fact that I don’t venture into the thicket of Observer implementation details, I can still give you a few references on how to implement Observers. A good overview on many of the implementation aspects is Victor Ciura’s CppCon 2021 talk “Spooky Action at a Distance”. A very detailed discussion on how to deal with the concurrency issues of the Observer pattern can be found in Tony Van Eerd’s C++Now 2016 talk “Thread-Safe Observer Pattern—You’re Doing It Wrong”.
11 If you’re aware of the Non-Virtual Interface (NVI) idiom or the Template Method design pattern, then please feel free to move this virtual function into the private section of the class and provide a public, nonvirtual wrapper function for it. You can find more information about NVI in Herb Sutter’s Guru of the Week blog or in the article “Virtuality” from the C++ Users Journal, 19(9), September 2001.
12 Alternatively, the observer could also remember the subject on its own.
13 You can also choose to build on gsl::not_null<T> from the Guideline Support Library (GSL).
14 If you’re wondering what those others stand for: RAII: Resource Acquisition Is Initialization (which is argued to be the most valuable idea of C++, but at the same time is officially the worst acronym; it literally does not make any sense); ADL: Argument Dependent Lookup; CTAD: Class Template Argument Deduction; SFINAE: Substitution Failure Is Not An Error; NTTP: Non-Type Template Parameter; IFNDR: Ill-Formed, No Diagnostic Required; SIOF: Static Initialization Order Fiasco. For an overview of (almost) all C++ acronyms, see Arthur O’Dwyer’s blog.
15 Ah, the C++ Report—such glorious times! However, you may be one of the poor souls who never had an opportunity to read an original C++ Report. If so, you should know that it was a bimonthly computer magazine published by the SIGS Publications Group between 1989 and 2002. The original C++ Report is hard to come by these days, but many of its articles have been collected in the book edited by Stanley Lippmann C++ Gems: Programming Pearls from the C++ Report (Cambridge University Press). This book includes James Coplien’s article “Curiously Recurring Template Patterns.”
16 If you can’t use C++20 concepts yet, std::enable_if provides an alternative formulation. Refer to Core Guideline T.48: “If your compiler does not support concepts, fake them with enable_if.” See also your preferred C++ templates reference.
17 Consider any kind of cast (static_cast, reinterpret_cast, const_cast, dynamic_cast, and especially the old C-style casts) as adult features: you take full responsibility of your actions and the compiler will obey. Therefore, it is seriously advisable to reduce calls to cast operators (see also Core Guideline ES.48: “Avoid casts”).
18 This is a great example to demonstrate that it pays off to be able to compile your codebase with several major compilers (Clang, GCC, MSVC, etc.). Different error messages might help you find the source of the problem. Using only one compiler should be considered a risk!
19 If you aren’t familiar with the idea or syntax of C++20 concepts yet, you can get a quick and painless introduction in Sándor Dargó’s C++ Concepts, published at Leanpub.
20 This implementation of a StrongType is inspired by Jonathan Boccara’s Fluent C++ blog and the associated NamedType library. There are several more strong type libraries available, though: alternatively you can use Jonathan Müller’s type_safe library, Björn Fahller’s strong_type library, or Anthony William’s strong_typedef library.
21 The only technical oddity is the declaration of a tag class right in the template parameter list. Yes, this works, and definitely helps create a unique type for the purpose of instantiating distinct strong types.
22 Many years ago, more specifically at the end of the ’90s, this kind of namespace injection was called the Barton-Nackman trick, named after John J. Barton and Lee R. Nackman. In the March 1995 issue of the C++ Report, they used namespace injection as a workaround for the limitation that function templates could not be overloaded at the time. Surprisingly, today this technique has experienced a renaissance as the hidden friend idiom.
23 In Jonathan Bocarra’s blog, these optional, variadic arguments are aptly called skills. I very much like this, so I adopt this naming convention.