 (1)
(1)Researchers entering into a new research area are interested in knowing the current research trends, popular publications and influential (popular) researchers in that area in order to initiate their research. In this work, we attempt to determine the influential researcher for a specific topic. The active participation of the researchers in both the academic and social network activities signifies the researchers’ influence level across time. The content and frequency of social interaction to a researcher reflects his or her influence. In our system, appropriate time-based social and academic features are selected using entropy based feature selection approach of rough set theory. A three layer model comprising semantically related concepts, researcher and social relations is developed based on the appropriate (influential) features. The researchers’ topic trajectories are identified and recommended using Spreading activation algorithm. To cope up with the scalable academic network, map reduce paradigm has been employed in the spreading activation algorithm.
Influence is the power of a person to have an important effect on some course of events. In an academic network, the behavior of a particular researcher affects the behavior of other researchers. Researchers publish their new innovations as articles, post some tweets related to academic events, critique on techniques or explanation of concepts etc. The researchers also publish articles on various topics. These actions of the researcher in an academic network might encourage other researchers either use the new innovation or criticize his new innovation. In a social network like Twitter, the number of followers might increase based on the nature of users and the tweets posted by them. The other users may get influenced based on the information in tweet and may get many positive replies for the tweet. The user’s behavioral changes are triggered. The trigger might be from many researchers and the level of change will differ among the users across time and topic. Such changes in influence level can be tracked to determine the most influential researcher in a topic. In order to track the changes different measures can be adopted.
Any researcher interested in carrying out research in a specific area, need current information about the researcher whose research work has influenced many researchers. The researcher might refer the scientific articles of the particular influential researcher to proceed with his/her research. For example, a researcher entering from the area Computer Networks into Machine Learning will require information about the current influential researchers in Machine Learning area so that publications of such researchers can be referenced. In addition, new researchers would get an opportunity to know about the research trends in a particular topic. In order to support the research to be carried out by the researchers in new areas, influential researcher identification turns out to be an essential information resource. Influential researchers have been determined through academic network analysis, but however today social networks play an important role in determining influence and research focus. Hence, in this work, we try to determine the influential researcher in a topic using academic and social features. Today, research work is available publicly both through research publications and social network discussions almost as soon as it is carried out and thus is able to influence future research. Considering this important factor, as a first of its kind work, time-weighted features have been used to determine influential researchers in order to achieve better ranking.
For effective influential researcher analysis, appropriate features have to be employed. Feature selection is a machine learning technique to detect appropriate features and eliminate noisy or irrelevant features. The feature selection technique increases the algorithm speed and improves the output accuracy. In our work we have selected relevant features using the Entropy reduction algorithm. The concept of selecting relevant features for influential researcher identification is a novel approach. Based on the selected influential features, three layers of time-weighted features are formed as network. Spreading activation with map reduce paradigm is applied on three layered network to determine the influential researcher. The map reduce paradigm is used to handle scalability and identify the influential researcher with less execution time.
Whenever any user searches the web for Influential researchers in a particular topic, the influential researchers identified by our system can be recommended as top influential researchers. Our approach attempts to assists the users in obtaining better recommended list of influential researchers than existing approaches.
Our major contribution in this work is to determine influential researchers with the time-weighted features selected using Rough set based Entropy reduction method. This section discusses in detail the existing work carried out in Influential analysis, Time-weighted edges in academic network, and the different feature selection approaches.
Researcher and their publications play a vital role in an academic network like citation network, co-author network etc. A few quantum of research work exist, considering researcher as a primary entity in academic network.
Normally researchers combine with other researchers and publish their new innovations as articles and this interaction is represented as a co-author network. Much of the researcher activity oriented systems have been developed using different set of features with co-author network. Co-author recommendation has been carried out: (Sun et al., 2011; Sie et al., 2012). Researchers publish their work after an in-depth analysis of the existing literature in a specific topic and mention the same in the research article as citations. Few approaches exist on citation recommendation:(Caragea et al., 2013) using SVD approach, (He et al., 2011) citation location recommendation, (He et al., 2010) context aware citation recommendation system. Nikalaos et al., (2007) used multiple criteria decision aiding methodologies for scientific paper recommendation. Yan et al. (2011) considered features like venue impact, paper content and author expertise to formulate the learning process for estimating the citation count of a particular publication by using regression models.
The other major research area related to a researcher in an academic network is identifying the influential researcher of a specific topic. Both academic and social factors contribute to the measurement of the influence of the researcher. Many attempts prevail on influential researcher analysis, considering either academic or social features or socio-academic features. Shaparenko et al. (2009) identified the most influential documents and the influential authors using the text of the documents. The recent development in web has led the researchers to consider the metadata of the web as a quantifying measure for the impact of a researchers’ article. Taraborelli et al. (2008) analyzed and suggested that social bookmarking system can be considered as a usage based metric for evaluating the impact of the researchers’ article. Priem et al. (2010) introduced Scientometric, a new metric for measuring researchers’ article impact. This metric is based on social bookmarking and microblogging services available on the web. Neylon et al. (2009) introduced altmetrics as a quantitative measure that can be used in different contexts for measuring the impact of a research publication. Groth et al. (2010) analyzed the scientific discourse on the web using bibliometric techniques like citation and keyword similarity maps and concluded that scientific discourse on the web is contextually relevant. Dahimene and Mouza (2015) designed various filters to reduce the number of microblogs fetched by the system, while retrieving the users’ relevant updates. Zhang et al. (2013) identified the influential person in online social networks based on the tie strength. Zhang and Li (2014) identified the influencers in a social network by proposing an agent-based framework of viral marketing and studied the relative superiority of different centrality measures. Liu et al. (2012) proposed a joint probabilistic model for quantitatively measuring the influence of a person in a social network. Morid et al. (2014) employed attack detection methods on the influential users of the social network to improve the attack detection performance. Li et al. (2013) identified influential scholars considering both academic and social impact. The academic impact of the scholars was evaluated based on the total reader count of all the authors publications, maximum reader count of the particular paper of an author and R-Index (analogous to H-index1)(Hirsch, 2005) of the authors publications available in Mendeley. The social impact measures were degree, closeness, and betweenness. They carried out the analysis to determine whether the influential researchers are senior scholars, the type of influential scholars that can be detected using academic measures and the contribution of social measure on academically influential scholars. They have analyzed that academic measures follow a power law pattern by studying the distributions of academic measures plotted on a graph. The social measures have been aggregated using the Euclidean normalized scores and the scholars are ranked based the computed Euclidean score. Their social measure analysis reveals that the social measure provides added advantage to the traditional academic metrics. The social influence impact was based on only network measures like betweenness, degree and closeness of academic social network like Mendeley. The interactions among the researchers in microblogging platform like Twitter may even contribute to measure the influence of the researchers. Furthermore, it could be noticed that the researchers’ interaction with other researchers changes over time. Influence analysis of a researcher should consider the changes in the researchers’ interaction over a specific time. However, in the existing work (Li et al.2013) impact metrics like Twitter interactions and time factor have not been considered to assess the researchers’ influence.
In the previous approaches, several features had been considered for assessing the influence of the researcher. The significant level of considered features for measuring the researchers’ influence will differ. Hence, necessity arises for selecting the appropriate features that assist to effectively identify the influential researcher.
A feature selection algorithm (FSA) aims in the inductive learning of relevant features and eliminates the irrelevant features that lead to difficulties in discovering knowledge. However, under the perspective of induction learning the relevance of features have different definitions based on the goal that is considered. An irrelevant feature may be not useful for induction, but it is not necessary 1that all relevant features are useful for induction (Caruana et al., 1994). In order to solve the curse of dimensionality problem, the dimensionality of the feature space should be reduced. This can be carried out either by Feature selection or Feature extraction. Feature extraction involves the creation of new features that include more information about the class label, from the actual features. Feature extraction methods include linear methods (Principal Component Analysis, Independent Component Analysis etc.) and non-linear feature extraction methods. Feature selection is concerned with selecting only the subset of relevant features. Feature selection algorithms are classified into filters (Pawlak, 1993; Pawlak, 2002), wrappers (Kohavi et al., 1997; Ganapathy et al., 2011) and embedded approaches (Haury et al., 2011). In Wrapper method, the quality of selected features is evaluated by training classification algorithm on the selected feature subset and evaluating the contribution of each subset on a validation dataset. Filter methods are based on the heuristic measures like Mutual Information and Pearson correlation to score the features. Filter methods does not involve many training models and the quality of features is evaluated independent of the algorithm. In embedded methods, feature selection is performed by learning the optimal parameters (for example, learning weights between the input and the hidden layer of the neural network). Rough set theory (Pawlak, 1982), Pawlak, 1993; Pawlak, 2002) is one of the most successful methods for feature selection. A minimal attributes sets called ‘reducts’ is derived from the original set to classify the objects by not retrograding the classification quality. The success theory of reducts has motivated many researchers to apply the rough set theory in number of real world applications like text categorization, fault diagnosis, medicine, image processing etc. Based on the machine learning techniques such as C4.5 (Quinlan, 1993) and the work carried out in (Jensen et al., 2001) entropy-based reduction (EBR), a technique for discovering rough set reducts has been developed. The initiative behind this approach was that when the rough set dependency measure is maximized for a given subset, the entropy is minimized. Feature selection algorithm were used in different kind of applications. Kannan et al. (2015) introduced temporal feature selection algorithm to select appropriate features for detecting intruders in a cloud environment.
The academic network is dynamic in nature and the research topics evolve over time. Hence static and un-weighted academic network is insufficient to tackle tasks like citation recommendation, paper recommendation, co-author recommendation and Influential researcher analysis. This provided path for researchers to carry out the study on academic networks incorporating time-aware weighted edges. Researchers entering into a new research area might be interested in knowing which young researcher will be an influential person or which paper will become popular in the future. Few research work have been carried out to determine the future popularity of publications (Sayyadi et al, (2009); Weng et al, 2011; Walker et al., 2007) without incorporating time. An attempt was made by Walker et al. (2007) for the prediction of future citation count of papers by including the articles publication time into the ranking model. Sayyadi et al (2009) proposed Futurerank, a ranking algorithm to predict the future popularity of publications. Weng et al. (2011) ranked the future citation of papers by incorporating time to the author-paper network. Attempts were made to rank the scientific articles incorporating publication time information (Li et al., 2008; Wang et al., 2013). However, in the above works, information regarding time has not been used completely. The academic relations like citation and coauthor are also time sensitive, which has not been addressed in the research works discussed above. Wang et al. (2014) used time-weighted graphs and proposed Mutual Reinforcement Framework (MRF) to rank the future popularity of publications and authors together.
Moreover, map reduce paradigm has been used in different tasks. Yin et al. (2014) has used map reduce paradigm for detecting the communities from large scale social network. Nagwani (2015) proposed a framework that employs map reduce framework for summarizing large text collection.
In the previous approaches, the main limitation noticed is that several features had been considered for assessing the influence of the researcher but the significant level of considered features for measuring the researchers’ influence has not been addressed. Hence, necessity arises for selecting the appropriate features that assist to effectively identify the influential researcher. Moreover, the number of researchers keeps increasing day by day which leads to the increase in the size of academic network. The influential researcher has to be identified from such a scalable academic network. Hence, an algorithm that tackles scalability issue is required. This remains as an addressable issue.
As a first of its kind, our work attempts to determine the influential researcher of a specific topic by considering time-based social and academic features using map-reduce paradigm by overcoming the above discussed issues. In our approach, the appropriate features are selected using entropy based feature selection algorithm. To the best of our knowledge, none of the existing methods use EBR feature selection approach for influential researcher identification. Concept-researcher-social layered model is developed to represent the selected features In order to identify the influential researchers from scalable academic network, map-reduce framework of spreading activation algorithm is used in our system.
Our work aims to determine the influential researcher of a particular topic in a scalable academic network. This section gives a detailed explanation of the process involved in feature extraction and map-reduce paradigm based spreading activation algorithm used in influential researcher analysis.
‘Influence’ regulates the behavioral changes of the researcher. The behavioral changes depend on the features of the researcher. The involvement of researcher in both the academic activities and social network contributes to characterize the researcher. Hence in this work, academic and social features are extracted to determine the influential researcher. This sub-section explains about the extraction of different kinds of the academic and social features.
An academic researcher publishes articles in different research areas. The published article might stimulate other researchers to initiate their work in that research area. The academic activity of the researcher influences the behavior of other researchers. Hence the academic related features have significant impact on the researcher influence. In this work, the academic features like Profile-based features, Workshops/Tutorials conducted by researcher, time-weighted citation index, venue impact and advisor/advisee relation among the researchers are considered for determining the influential researcher in the academic network. The sub-sections given below describe the individual features used in influential researcher identification.
Profile-Based Features
The Profile of a researcher has a brief description of the knowledge areas in which he or she has a higher level of expertise and influence. With the intuition that the researcher with high profile will influence other researchers, profile of the researcher is considered as one of the feature for influential analysis. The researcher profile is not available readily. The procedure involved in building the researcher profile is explained below.
It is built based on author’s relevant score to a knowledge area and his/her research interests extracted from academic homepages. An author is considered an expert in a topic if most of his publications are about the topic. We have used generative language models to calculate the relevance of an author's publication in a knowledge area. A score is calculated for each researcher, based on his publication collection. It is based on how likely a researchers’ publication would generate a certain knowledge area (ka). The top ‘n’ publications are retrieved for a ‘ka’ and the sum of the relevance of each document‘d’ to the ‘ka’ is calculated. The researchers’ profile is updated based on this score.
Tang et al. (2007) extracted the academic interests of researchers from their homepages. Google Scholar serves as a source of information about the researchers’ research topics. We have used the Google scholar pages of researchers and extracted research interests using Conditional Random Fields (CRF) tagging method. Google scholar home pages contain information such as researchers’ affiliation to a university, contact email id, citation indices, research topics of interest and list of publications etc. A tagging model is required to tag this sequence of information in the Google scholar page and hence identify research interests of an author. Hence a popular tagging method, CRF is used to predict the research interests from the Google scholar pages. The model is trained with the input samples of data from Google scholar pages of the researchers. The trained model is used to extract research interests from the pages of new researchers. The final profile of the researcher is a combination of topics extracted from his publications and home pages.
Workshops/Tutorials Conducted by Researcher
Based on the intuition that, highly influential researcher on a specific topic will be invited for delivering talks in workshops and also to present tutorials on the topics, this feature is considered for measuring the influence of the researcher. Mendeley API was used to extract the information related to workshops/tutorials conducted by the researcher.
Time-Weighted Citation Index
Citation count refers to the number of citations of author’s publications. The count does not infer any information about the publication year. In order to give significance to the recent publications of the researcher, Kavitha et al. (2014) introduced a novel measure, Time-weighted citation index:
(1)
where ‘w’ denotes the time decay parameter:
Tpresent - Current year
and:
j->i - denotes j cites i
Time decay parameter is chosen as 5 to give added weight to publications in the last 5 years.
Advisor/Advisee Relation
The notion that, an influential researcher will act as an advisor to many advisees, lead to the consideration of this feature for determining influential researcher. Advisor/Advisee relation of the researchers has been extracted using Mendeley API.
Venue Impact
The researchers publish articles in conferences and journals. The venue in which the researcher publishes the article has higher impact. The impact factor of the journal and conference decides their significance. The researcher might initiate certain course of events among others (influence others), when the researchers’ article has been published in venues with high impact. The venue measure helps to decide the influence of a researcher.
Social Features (Tweet)
In the present world, academic related information like Conferences, Workshops, discussion on specific topics etc are being carried out using the social network. The interaction level of researchers in the social network is also high. Hence the researchers’ activity in the social network also influences many people. This leads to the consideration of social features (twitter) for identification of an influential person.
Social networks like twitter provide freedom for the user to post tweets on any topic. The user will be followed by many people based on his active participation i.e number of followers depend on users’ profile. The information posted by the users in tweet might attract other users. Hence both the user and tweet content influences the behavioral changes in the user. This provide the path to consider both user-centric and tweet-centric features as a measure for influential researcher analysis. The following sub-sections provide an in-depth analysis of the social features used for identifying influential researcher of a specific topic.
User-Centric Features
In twitter, any user can become the follower of any person and post reply to tweets of any person. A particular person can be followed by many people. The general notion is that many persons will follow a particular person if he has posted more valuable information and hence triggers changes in others behavior. The person with many followers will contribute to the influence of the researcher. Moreover, for the researchers’ posts, the chances for reply tweets will be high, if the post is highly valuable and can influence others’ behavior. This work puts forth reply tweets as one of the features for determining an influential researcher.
Tweet-Centric Features
In addition to user-centric features, tweet-centric features will help to identify the influential person in an academic network. In a tweet, users post the tweets and convey some information through concepts. The concepts might influence other users and impart some changes in user behavior. In the existing work, the concept level influence in tweet has not been addressed so far. The concepts in academic tweets will provide current interaction of the researcher on a specific topic. In our work, we have attempted to use tweet concept as a feature for identifying an influential researcher in a particular area. The tweets are not available as such. Using Twitter search API2, nearly 1216431 tweets were extracted from June 2014 to August 2014. The follower/followee count and reply tweets count were obtained using Twitter API. We extracted the concepts from tweets using Alchemy API (Manju et al., 2013). With pre-defined list of the academic concepts, the concepts extracted from tweet API are compared. We obtained nearly 102485 matched tweet concepts and used them. The matched2 concepts alone are used for layer construction. In this work, computer science domain related concepts are alone considered.
FEATURE SELECTION USING ENTROPY BASED ROUGH SET THEORY
Several academic and social related features have been considered for influential researcher identification. Among the considered features, the most appropriate features have to be selected for effective identification of influential researchers.
‘Feature selection’ is the technique of selecting relevant features that yield best prediction. This sub-section describes the task involved in appropriate feature selection.
Rough set theory is a method that supports vague concepts approximation in decision making by using lower and upper approximations. This has been widely used for feature selection. Entropy based reduction is one of the rough set feature reduction techniques that helps to identify the attributes with maximum information gain (low entropy). Suguna et al. (2010) suggested entropy based reduction algorithm (EBR). The algorithm searches for the best feature subset. During each iteration of the algorithm, the subset with the lowest entropy is selected. Influential researcher can be analyzed effectively with features that provide maximum information gain. Hence, subset of features with maximum information gain is selected using the Entropy based reduction algorithm.
Three-Layer Model
The similarity between academic researchers can be found based on the semantic relatedness between the researchers’ profiles or the relationship between the social profiles of the researchers. The existing approaches of finding similar researchers used, two-layer model with either the semantic or social relatedness (Xu et al., 2010). These two similarities are rarely combined. In this work, as an extension of two-layer model, novel three layer time-weighted network model (C, R, S, T_E) combining the semantic and social relationship between the researchers with respect to time is built as shown in Figure 1. The three different layers in the model are concept layer (C), social layer (S) and researcher layer (R). T_E represents the time-weighted edge. There are three types of links in the network model. They are the concept-concept link, researcher-concept link and the researcher-researcher link. The concept - concept link is established based on the semantic similarity between the concepts. The researcher-concept link is formed based on the profile vector. The link between researchers is based on the social relationships between them.
Concept Layer
The nodes in the concept layer are the set of concepts(c) that represent researchers’ expertise. Semantic similarity or semantic relatedness is a metric defined over a set of documents or terms, where the distance between them is based on the likeness of their meaning or semantic content. Semantic similarity can be estimated by using ontology to define the distance between terms/concepts. DBpedia, a structured content extracted from the information in Wikipedia pages is used as domain ontology in our system. The similarity between simple concepts is calculated using the information content of the concepts whereas the similarity between complex concepts is calculated using semantic information and word order similarity. A method proposed by Jiang et al. (1997) has been used to calculate the similarity between simple concepts. Li et al. (2003) proposed another method which combines multiple sources. The score of the above two approaches are combined (Xu et al., 2010) to achieve considerable improvement in determining concept similarity. Complex concepts are composed of simple concepts, therefore the similarity of complex concepts are based on the measure of simple concepts. The method proposed by Li et al. (2006) has been used to compute the similarity of complex concepts.
The influence of a researcher is dynamic. The recent expertise information of the researcher has been considered. Hence, information of the researcher during the past five years is given higher priority. This is incorporated by multiplying the similarity score with decay factor of 0.5. Finally, the edges between the concepts in the network model are updated with the time-weighted similarity score.
| Figure 1. Three-layer network model |
|---|
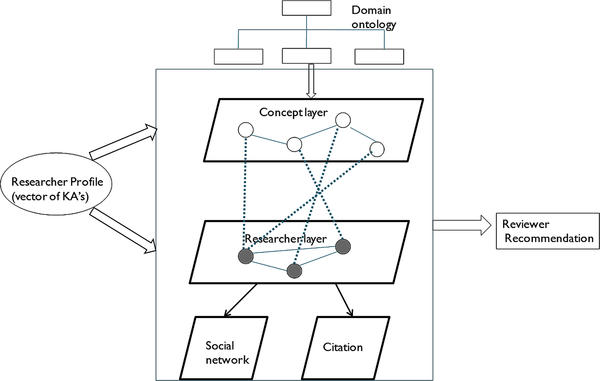 |
Researcher Layer
The nodes in the researcher layer are the set of researchers working on different research areas. The link between the researchers is established using the social layer.
Social Layer
The social layer (S) supports researcher layer. Social network like Twitter are widely used as a platform to converse on various research topics. Therefore, in this work, the conversation that occurs between the researchers in the form of tweets is considered for determining the social relationships between researchers in Twitter. The mode of conversation between the researchers will be through concepts i.e the academic concepts are cited in tweets. Hence, from all the researcher tweets, concepts that adhere to the predefined list of concepts specified are extracted. The conceptual profiles of the researcher are built based on the extracted concepts from the social network. The researchers generally cite other works in their publication article to highlight either the concepts used by the researchers, evaluation measures followed by other researchers. Such concept based citation relation along with the conceptual profiles from social network is used to determine the similarity between the researchers and further establish link between them.
Time-Weighted Edge
The edge weights between the researchers are updated with respect to twitter and citation graph. Our aim is to determine the influential researcher on a specific topic. Any active researcher on a particular topic need not be a long-term active researcher. As time goes, the researchers’ level of interest on a topic might decrease when the reputation of the topic has lost its scope. At the same time, the researchers’ level of interest might fluctuate to a popular topic. For example, in current scenario many researchers develop passion towards Cloud computing, Big data because of its exciting technical features and popularity. Considering such situations, recent interactions should be given higher priority during the weight update. In Twitter, interaction frequency on a topic is used as weight update measure. Interaction frequency is computed based on reply to a researchers’ tweet on a topic, retweets and followee of a researcher within past 6 months. This value is chosen heuristically. In citation graph, the conceptual similarity between cited and cited-by paper is considered as weight update measure by prioritizing the recent citations. For collaborative recommendation, (Ding et al., 2005) used time weighted model with decay factor of 0.5 and achieved appreciable improvement in the results. Since influential researcher identification is a collaborative recommendation task, the same decay factor of 0.5 has been used in our work. Hence, the citation details of past five years have been gathered. The weight is reduced by a decay factor of 0.5.
The final edge weight updated as follows:
Aggregated Edge weight = (Interaction frequency + Citation link) * decay factor (2)
Map Reduce Paradigm of Spreading Activation Algorithm
The aim of our work is to determine the influential researcher of a specific topic from an academic network. The size of the considered academic network is scalable. Emphasizing the scalability nature of the academic network, influence researcher identification algorithm has been implemented with map-reduce paradigm. This section describes in detail about the fundamental process involved in spreading activation algorithm and map reduce framework of the spreading activation algorithm.
Spreading Activation Algorithm
Spreading activation algorithm spreads information i.e traversal based on association between the nodes. Influential researcher identification is a user-based collaborative filtering recommendation system (recommendation based on user’s prior behavior). The researchers’ previous behavior, might have introduced noticeable changes in activities of other researchers. New association arises between researchers. Such association between the researchers has to be tracked to determine the researchers’ recent trend. Since node traversal in spreading activation algorithm is based on association between nodes, the association path between the researchers can be tracked with this algorithm and identify the researcher with maximum associations as an influential researcher on a topic.
As discussed already, the weight of links at the concept layer can be calculated using ontology (DBpedia). The weight of links at the researcher layer can be calculated based on their twitter conversations on a topic and citation graph. In traditional spreading activation algorithm, the weight of links is usually set to be 0/1. This works differs from the traditional activation algorithm, by using the relevance score of a researcher in a particular topic, to update the weight of the links between concept and researcher layer. Thus, a time-weighted graph is created based on the weights of three kinds of links.
Hopfield net algorithm (Huang et al., 2004; Lippmann, 1987) is employed to simulate the activation process. The basic idea of using Hopfield net algorithm is that, starting from a target researcher walk through the network with three levels of features, along the links of concept-concept, researcher-concept and researcher-researcher to identify influential researchers. During initialization process, the activation level of the target topic connected to is set to be 1. The other nodes remain inactive and the value of their activation level is set to be 0. In each generation, a fixed number of nodes with the highest activation levels are activated.
The activation level of each node is computed as:
 (3)
(3)
Sigmoid function is

where 1≤i≤n:
Repeat until there are no significant changes between the last two iterations.
Given a research topic, the above method is adopted by starting with the set of researchers associated with the topic. As per the algorithm, during each iteration a particular researcher is activated. The activation of a researcher node occurs, only if the node has been influenced by the considered features. The activation path lengths of each researcher are taken into account. Top researchers who have highest activation path lengths in decreasing order after the overall iteration of the algorithm are recommended as influential researchers for a research topic.
In our work, the data (load) is scalable and three different datasets (vendors) are used (Wikipedia). In order to handle the load scalability and generation scalability, map reduce paradigm is used.
In our research, we have used map reduce programming for spreading activation algorithm. The algorithm spreads information based on the activation value. In the network, the concept nodes are connected to many researchers. For the given topic, the concepts that come under the topic in Dbpedia ontology are considered. The set of researchers associated with a set of related concepts are taken and concept-researcher is considered as the key-value pair and given as input to the map reduce program of spreading activation algorithm. The map reduce framework of spreading activation is shown in Figure 2. The map phase of spreading activation accepts set of researcher (key) nodes with its neighbor nodes along with edge weight (value) in the form of key value pair as input. Then in map phase, the activation value for each of the value nodes are computed based on the Equation 3. The output of the mapper is the key node and the set of activation values are considered as intermediate key value pair. During reduce phase, the intermediate key/value pairs are taken as input. For each of the key node, the node with highest activation value is determined and considered as the newly activated node. This node becomes the key node for the next iteration of the algorithm. The neighbor nodes for the newly activated node are retrieved and assigned as values to the key node. The new key node and its updated neighbor nodes are given as input to the mapper for the next iteration. This is iteratively carried out until there is no significant change in key node assignment between last two subsequent iterations.
| Figure 2. Map reduce architecture of spreading activation algorithm |
|---|
 |
Experimental Setup
In our work, the influential researcher identification process involves the formation of a three layer network consisting of concept layer, researcher layer and a social layer. In order to build three layer model, researchers’ expertise concepts, social relations based on researchers’ citation and researcher tweets are required. We used datasets like DBLP3 with 2.8 million publications, Arnetminer4 with 629814 publications and ACL5 corpus with 21,212 publications for extracting information like researchers’ expertise concepts, citation etc. Initially we conducted experiments with DBLP citation network dataset comprising 12591 nodes (publications) and 49743 edges (citation relationships). Later, we increased the citation network size by incorporating both Arnetminer citation network comprising 2244021 nodes (publications) and 4354534 edges (citation relationships) and ACL citation network with 18164 nodes (publications) and 110975 edges (citation relationships).
We preprocessed the dataset as follows. First, we eliminated the survey papers as we aim to rank only research papers. Second, we removed the papers without citations and as well the papers that do not cite others. Third, the collection contains some workshop proceedings. These proceedings contain all the papers published in the workshop. But in the dataset, the whole proceeding is considered as a “paper”. Such proceedings are also removed. In addition, old papers (before1990) with incomplete metadata are removed. After the preprocessing, our three-layered network size was 1036708 nodes comprising 230124 concept nodes, 1501465 researcher nodes and 512432 social layer nodes (409947 citation nodes and 102485 researcher tweet concept nodes as described).
We evaluated our approach under the following aspects based on our contributions and have shown results for a particular topic ‘Machine Learning’:
Significance of Feature Selection
In this work, initially we have considered five academic features (Profile based features, Workshops/Tutorials conducted by researchers, Time weighted citation index, Advisor/Advisee relation and Venue Impact) and four social features (follower relation, reply relation, citation relationship and Tweet concepts). However, we used the rough set based entropy reduction algorithm (Suguna et al., 2010) and selected the features having maximum information gain as shown in Table 1. Furthermore, we adopted the entropy feature selection algorithm on the baseline (Li et al., 2013) features, as well. Based on the feature selection algorithm, we obtained the entropy values as shown in Table 2. The academic features like R-Index, maximum number of readers per paper and social features like degree and closeness were selected as important features. As a result of this we obtained the appropriate influential features for identifying influential researchers in both the approaches. We evaluated our approach using NDCG (Hang et al.2011), to illustrate the significance of feature selection with two scenarios. NDCG gives importance to the top k retrieved entities and considers how these k entities are ordered (Kavitha et al., 2014). In the first scenario, we ignored the feature selection and considered all the features to compute four truncation levels of NDCG. In the second scenario, we used the entropy selected features. As shown in Figure 3, when the entropy selected features were considered NDCG@k values were higher in comparison with combination of all features in both the approach. The higher NDCG illustrates that, we have retrieved the top-k relevant influential researchers with best ranking in the list. The reason behind this is using most decisive features in influential analysis task eliminates the weaker links that exist between the researchers in the three-layer model. We evaluated our approach with different kinds of features.
The results in Figure 4 shows that NDCG value is less while considering either academic or social features individually when compared to academic and social feature combination. This illustrates that both academic and social features are required to determine the influence of a researcher.
Table 1. Entropy values of academic and social features (our method)
| Academic Features | Entropy |
|---|---|
| Profile Features | 0.6123 |
| Time-weighted citation index | 0.5461 |
| Workshops/Tutorials | 0.7124 |
| Venue impact | 0.8641 |
| Advisor/Advisee relation | 0.7654 |
| Social Features | Entropy |
| User centric | 0.8465 |
| Tweet centric | 0.5543 |
| Citation relation | 0.5124 |
Table 2. Entropy values of academic and social features (baseline method)
| Academic Features | Entropy |
|---|---|
| Total number of readers per paper | 0.5325 |
| Maximum number of readers | 0.4251 |
| R-index | 0.3172 |
| Social Features | Entropy |
| Betweenness | 0.5441 |
| Closeness | 0.3513 |
| Degree | 0.3302 |
| Figure 3. NDCG comparison between all features and entropy selected features combination (our method) |
|---|
 |
| Figure 4. NDCG comparison between different kind of features (our method) |
|---|
 |
Impact of Twitter
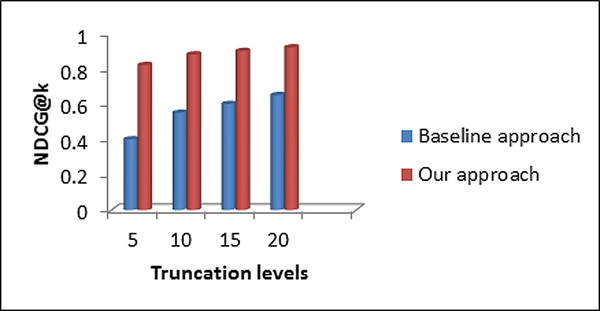
Our evaluation is mainly concerned with the effect of our features in determining influential researchers. Specifically, we show the importance of using the concepts discussed in twitter as a parameter in determining influential researchers. A sample set of concepts extracted from twitter is shown in Table 3 and the sample of pre-defined academic concepts considered for comparison as described are listed in Table 4. We show that the use of this feature improves the NDCG measure of the system in comparison with a baseline system (Li et al.2013) that considers academic and social features other than tweet. From the graph shown in Figure 5, it is evident that NDCG measure for our approach is better than the baseline approach. The better NDCG@k advocates that we were able to retrieve top ‘k’ relevant researchers with highest rank in the retrieved result since academic oriented tweet concepts (content) have been considered rather than the network structure considered in baseline approach.
Table 3. Sample tweets and the extracted concepts
| Tweet | Concepts |
|---|---|
| Beyond Contagion: Reality Mining Reveals Complex Patterns of Social Influence. | Social Influence |
| Great list of resources: data science, visualization, machine learning, big data | Learning Machine Learning |
Furthermore, we evaluated our system under two different cases. In the first case, the system was tested by considering the entropy selected academic features and social relationship as citation network. In the other case, we considered the entropy selected features and social relationship as citation network and tweet concepts.
Table 4. Sample pre-defined academic concepts considered for comparison based on (Manju et al., 2013)
| Pre-Defined Academic Concepts |
|---|
| Social Influence |
| Machine learning |
| Predefined Concepts |
| Text mining |
| Learning |
| Semantic Web |
| Semantics |
| World Wide Web |
| Networks |
| Figure 5. NDCG comparisons between our method with tweet feature and baseline method without tweet feature |
|---|
 |
The results shown in Figure 6 depicts that much better NDCG values are achieved in the case of including tweet concepts as social feature when compared to the tweet concept exclusion case. As the researchers’ interaction through tweet concepts has been incorporated in influential analysis, new links will be established among the researchers (in three-layer model) based on similarity with tweet concepts. Moreover, due to the new links, strength of the edge weight between the researchers increases and becomes a node with highest activation value during the activation value computation of the spreading activation algorithm. As a result, that particular researcher node obtains a significant position in the ranking list of the influential researcher of a topic leading to achieve a better NDCG. The analysis reveals that the impact of tweet is high in determining the top ranks in the relevant researchers retrieved by our method.
| Figure 6. NDCG comparisons with and without Tweet features (our method) |
|---|
 |
Time Weighted Edge Analysis
Another important parameter that we have used at all the layers namely concept layer, researcher layer and social layers is the time factor which we have used to weigh the edges. The significance of explicitly incorporating time links is to identify time-based influential researchers without the implicit time links of citation networks being overshadowed by citation counts (Wang et al.2014). To show the effectiveness of this incorporation of explicit time links, we use the Recommendation Intensity evaluation measure introduced by (Wang et al.2014). Recommendation intensity evaluates the ranking of an author with respect to time. In their work, R has been assumed as the list of top-k returned authors of a ranking approach, L as the list of ground truth (based on citation count), then for each author Ai in R with the ranked order or, the recommendation intensity of Ai at k is defined as:
 (3)
(3)
The recommendation intensity of the list R at k, based on author’s recommendation intensity in the list R is defined as:
 (4)
(4)
Table 5. Recommendation intensity of ranking methods (with and without time)
| Year | Method | K=10 | K=15 | K=20 |
|---|---|---|---|---|
| 2009 | Spreading Activation | 7.9 | 9.6 | 9.6 |
| Spreading Activation+Time | 8.4 | 10.2 | 11.9 | |
| Li et al | 7.6 | 8.7 | 9 | |
| Li et al+time | 7.4 | 8.5 | 10.5 | |
| 2010 | Spreading Activation | 19.3 | 18 | 18.9 |
| Spreading Activation+Time | 22.8 | 20.3 | 20.13 | |
| Li et al | 17.4 | 13.4 | 15 | |
| Li et al+time | 18 | 15 | 16.7 | |
| 2011 | Spreading Activation | 8.3 | 10.3 | 14.41 |
| Spreading Activation+Time | 8.5 | 11 | 14.44 | |
| Li et al | 6.78 | 9 | 12.4 | |
| Li et al+time | 7.23 | 9.8 | 13.51 |
We show in Table 5 that the recommendation intensity of our ranking approach based on time weighted academic and social links is better when compared to the ranking approach used by (Li) for different ‘k’ values. We have shown that the results for the years 2009 -2011 for the baseline method (Li et al.2013), incorporating time weighted edges into the baseline approach, our approach without and with time weighted edges. In order to evaluate the time-factor, for the years 2009, 2010 and 2011 we define the ground truth as citation ranks of publications from 2009 to 2012, 2010 to 2013 and 2011 to 2014. From the Table 5, it is noticed that, the recommendation intensity of Spreading activation with time and baseline method with time is higher than the methods without time factor. As the considered ground truth in our case is citation count, recent author publications (for the year 2014) would have not obtained better citation counts whereas past author publications (2009-2013) would have obtained reasonable citations. This would increase the edge weight associated with the researchers paving way to consider particular researcher node as a node with high activation value. This in turn leads to better recommendation intensity. Hence recommendation intensity results for the year 2009 are better than that of 2011. We have also shown the ranking of the top ten researchers (for the year 2010) using the above methods in Table 6. Our ranking results were better, since out of our top 10 ranked researchers, nearly seven of them were in the top ten of the ground truth results.
Table 6. Ranking of top -10 researchers (for the year 2010)
| Authors | Spreading Activation Rank | Ground Truth Rank | Citation Count (From the Year 2010 - 2014) |
|---|---|---|---|
| Ian. H. Witten | 1 | 2 | 31311 |
| S. Michalski | 2 | 9 | 9153 |
| G. Diettrich | 3 | 6 | 15914 |
| Muller | 4 | 3 | 22238 |
| Hsinchun Chen | 5 | 5 | 17111 |
| Eib Frank | 6 | 4 | 21191 |
| Thorsten Joachims | 7 | 1 | 34587 |
| J. Mooney | 8 | 14 | 15636 |
| Ivan Brakto | 9 | 20 | 7515 |
| Langley | 10 | 11 | 15498 |
Methodology Evaluation
This subsection is concerned with the goal to show that our methodology outperforms baseline. We carried out the evaluation in two steps. First we have tested and shown the strength of the algorithm. Then we have analysed the impact of Map reduce paradigm on spreading activation algorithm.
Performance Evaluation of Spreading Activation
Our focus is to show the strength of Spreading activation algorithm in determining influential researcher. Hence, we considered our features and compared the NDCG results of our method with the baseline method. The results in Figure 7 show that spreading activation outperforms baseline method on an average by 45% for the topic ‘Machine Learning’. Likewise, we even tested baseline method and our method with respect to the baseline features (Li et al., 2013) and have shown the results in Figure 7 for the topic ‘Machine learning’. We noticed that our method outperforms baseline on an average by 32%. Furthermore, we conducted the above tests under multiple query runs on the topic ‘Machine Learning’ and compared the results using MAP@k (Smucker et al.2007) as shown in Table 7 and Table 8. The MAP results of our method was better than baseline on average by 37% and 28% based on our features and baseline features respectively.
| Figure 7. Comparison of NDCG of our method and baseline method with respect to our features and baseline features for a topic ‘Machine Learning’ |
|---|
 |
The reason for obtaining better results than baseline is due to the effectiveness of unsupervised spreading activation algorithm. The computed activation value based on researchers’ influence behaviour with respect to time helps to identify the most influential researchers. But the baseline approach just ranks the researchers based on the academic and social measures.
Table 7. Comparison of MAP@k values based on our features
| Method | MAP@5 | MAP@10 | MAP@15 | MAP@20 |
|---|---|---|---|---|
| Baseline method | 0.4917 | 0.5583 | 0.5861 | 0.6552 |
| Spreading activation | 0.5023 | 0.6120 | 0.6549 | 0.7698 |
Table 8. Comparison of MAP@k values based on baseline features
| Method | MAP@5 | MAP@10 | MAP@15 | MAP@20 |
|---|---|---|---|---|
| Baseline method | 0.4250 | 0.4934 | 0.5167 | 0.6096 |
| Spreading activation method | 0.5667 | 0.6150 | 0.6783 | 0.6252 |
Map Reduce Paradigm Evaluation
In this sub-section, we present the improved results produced by the Map-reduce paradigm of spreading activation algorithm for handling the scalable academic network.
We set up a Hadoop cluster using Amazon elastic map reduce and deployed 12 nodes for our work. The spreading activation algorithm has been implemented and tested with this setup for identifying the influential researcher. (Haron et al., 2010; Khalid et al., 2011) evaluated the performance scaling using Speedup, Performance improvement and efficiency with reference to time taken for serial and parallel processing. We have used the above measures to test the variation between non-map reduce spreading activation and spreading activation with map reduce.
Fadzil et al. (2013) stated that “The performance improvement depicts relative improvement that the parallel system has over the serial process”.
| Figure 8. Performance improvement of spreading activation algorithm with map reduce paradigm |
|---|
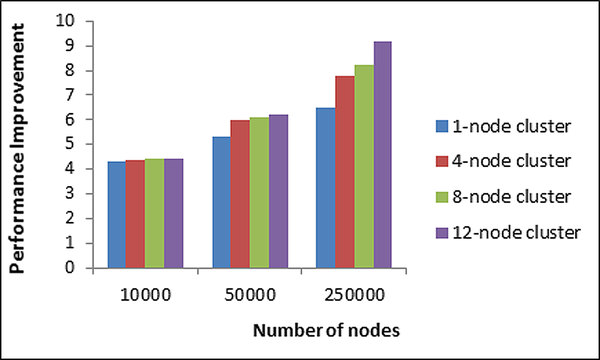 |
The performance improvement for the map reduce system with 12 node Hadoop Cluster is shown in Figure 8. The graph shows that noticeable improvement in the algorithm occurs when the number of nodes is more than 50000. When the node size was 10000, the algorithm produced reasonable performance with 1-node cluster, a marginal increase in the performance with 4-node cluster and negligible improvement with 8-node cluster and 12node cluster. The reason behind this scenario is that, when the network size is 10000, 1-node cluster was sufficient to meet the processing resource requirements. When the network size increased from 10000 to 50000, 1-node cluster was unable to meet the processing requirements and lead to the parallel execution with map-reduce paradigm. There was considerable performance improvement with 4-node cluster and negligible improvement with 8-node cluster and 12-node cluster. The reason is 4-node cluster was sufficient to handle this network size. This provides the evidence that during inadequate processing resource requirements, the algorithm performs better with map reduce paradigm and the map reduce handles the scalable network effectively.
(Fadzil et al., 2013) stated that “Efficiency is used to estimate how well-utilized the processors are in solving the problem, compared to how much effort is wasted in communication and synchronization”. The efficiency achieved in our system is shown in the Figure 9. For the network size as 10000, the efficiency achieved with single node cluster is 0.36, which is larger than the efficiency of other cases. The reason is, 1-node cluster is adequate to utilize the processor effectively size without any communication and synchronization cost. But, when the network size increased considerably to 50000 nodes, the efficiency was 0.79 with 1-node and 4-node clusters. Compared to 1- node cluster, 4-node cluster can utilize the processor effectively, but 4-node cluster incurs reasonable communication cost. So an equal efficiency is noticed in both cases, whereas efficiency of 8-node cluster and 12-node cluster has decreased since the processors are not well-utilized for this network size. The efficiency of 4-node and 12-node cluster tries to meet the efficiency of single-node cluster, when the node size is 250000. The processor utilization will be equal in all node clusters, but the communication cost involved in 8 and 12-node cluster leads to a slight fall in efficiency, when compared to 1-node cluster. The results confirm that, map reduce algorithm scales well to achieve better efficiency.
| Figure 9. Efficiency of spreading activation algorithm with map reduce paradigm |
|---|
 |
(Fadzil et al., 2013) stated that “Speedup measures how much a parallel algorithm is faster than a corresponding serial algorithm”. The graph in Figure 10 shows the speedup achieved through Map reduce paradigm. As the node size increases, parallel execution can improve the execution time when compared with serial execution. The node size of 10000 could be reasonably handled by 1-node cluster in a serial way and effectively by multi-node cluster in a parallel way. Hence, when compared to speed up of 1-node cluster, marginal increase in speed up was noticed in all other map-reduce clusters. When the node size was increased, the speedup of the map reduce clusters was larger than the 1-node cluster (serial execution). This illustrates that, map reduce based spreading activation yields much better speedup in task-intensive cases.
We nearly achieved 12% reduction in execution time of the spreading activation owing to the use of map reduce paradigm. Overall analysis reveals that Map reduce paradigm provides better support to the spreading activation algorithm for handling the scalable academic network in determining the influential researchers.
| Figure 10. Speedup of spreading activation algorithm with map reduce paradigm |
|---|
 |
Our work considered different level of academic and social features to identify influential researchers for a specific topic. The most appropriate and effective features that help to effectively identify the influential researchers were selected using Entropy based reduction algorithm. A three – layer model comprising the concept layer, social layer and the researcher layer has been constructed using the selected features. Using DBpedia ontology, the semantic similarity between the concepts was computed and used to establish links between the concepts. Considering the time-sensitive academic and social features of the researchers, time-weighted edges were used to relate the researchers. The evaluation results imply that our approach outperforms baseline on an average by 45% with the combination of social and academic features. The effectiveness of the features was tested using NDCG by considering different combination of features. The spreading activation algorithm was implemented using map reduce paradigm for handling data scalability. Furthermore, the map reduce paradigm helped to increase the speed up and reduce the execution time of the algorithm by 10% when handing massive data. The limitation of our work is that the approach considered only the existing data available in the dataset and the dynamicity of the data has not been focused. The work can be further extended to focus on the dynamicity in the network by incrementally learning the updates in the dataset and identifying influential researchers with respect to the incremental changes. Furthermore, the work can be extended to determine topic level influential community based on social and academic features.
This research was previously published in the International Journal of Intelligent Information Technologies (IJIIT),13(1); edited by Vijayan Sugumaran; pages 1-25, copyright year 2017 by IGI Publishing (an imprint of IGI Global).
Caragea, C., Silvescu, A., Mitra, P., & Giles, C. L. (2013). Can’t See the Forest for the Trees? A Citation Recommendation System. Proceedings of iConference 13 (pp. 849–851).
Caruana, R. A., & Freitag, D. (1994).How Useful is Relevance? (Technical report). Proceedings of AAAI Symposium on Relevance, New Orleans.
Dahimene, R., & du Mouza, C. (2015). Filtering structures for microblogging content. International Journal of Intelligent Information Technologies , 11(1), 30–51. doi:10.4018/ijiit.2015010103
Ding, & Xue Li. (2005, October 31-November 05). Time weight collaborative filtering, Proceedings of the 14th ACM international conference on Information and knowledge management, Bremen, Germany. doi:10.1145/1099554.1099689
Firdaus, A., & Fadzil, A. Noor Elaiza Abdul Khalid, & Mazani Manaf. (2013). Scaling Performance of Task-Intensive applications via Mapreduce parallel processing, Kolokium Siswazah Sains Komputer Dan Matematik Peringkat Kebangsaan. SISKOM.
Ganapathy, S., Kulothungan, K., Muthuraj Kumar, S., & Vijayalakshmi, M. (2013). Intelligent feature selection and classification techniques for intrusion detection in networks: A survey. EURASIP Journal on Wireless Communications and Networking , 271(1), 1–16.
Groth, P., & Gurney, T. (2010). Studying scientific discourse on the web using bibliometrics: A chemistry blogging case study . WebSci.
Hang, L. (2011). A short introduction to learning to rank. IEICE Transactions on Information and Systems , 94(10), 1854–1862.
Haron, N., Amir, R., Aziz, I. A., Jung, L. T., & Shukri, S. R. (2010). Parallelization of Edge Detection Algorithm using MPI on Beowulf Cluster . In Innovations in Computing Sciences and Software Engineering (pp. 477–482). Netherlands: Springer. doi:10.1007/978-90-481-9112-3_81
Haury, A. C., Gestraud, P., & Vert, J. P. (2011). The influence of feature selection methods on accuracy, stability and interpretability of molecular signatures. PLoS ONE , 6(12), e28210. doi:10.1371/journal.pone.0028210
HeQ.KiferD.PeiJ.MitraP.GilesC. L. (2010). Context-aware citation recommendation. Proceedings of the 19th international conference on World wide web (pp. 421–430). ACM. 10.1145/1772690.1772734
HeQ.KiferD.PeiJ.MitraP.GilesC. L. (2011). Citation recommendation without author supervision. Proceedings of the fourth ACM international conference on Web search and data mining (pp. 755–764). ACM. 10.1145/1935826.1935926
Hirsch, J. (2005). An index to quantify an individuals scientific research output . Proceedings of the National Academy of Sciences of the United States of America , 102(46), 16569–16572. doi:10.1073/pnas.0507655102
Hirsch, J. (2007). Does the h index have predictive power? Proceedings of the National Academy of Sciences of the United States of America , 104(49), 19193–19198. doi:10.1073/pnas.0707962104
Huang, Z., Chen, H., & Zeng, D. (2004). Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering . ACM Transactions on Information Systems , 22(1), 116–142. doi:10.1145/963770.963775
Jensen, R., & Shen, Q. (2001). A Rough Set-Aided System for Sorting WWW Bookmarks . In Zhong, N. (Eds.), Web Intelligence: Research and Development (pp. 95–105). doi:10.1007/3-540-45490-X_10
JiangJ. J.ConrathD. W. (1997). Semantic similarity based on corpus statistics and lexical taxonomy, Semantic similarity based on corpus statistics and lexical taxonomy, Taiwan, Proceedings of International Conference on Research in Computational Linguistics (pp. 19-33).
Kannan, A., Venkatesan, K. A., Stagkopoulou, A., Li, S., Krishnan, S., & Rahman, A. (2015, October-December). A Novel Cloud Intrusion Detection System Using Feature Selection and Classification . International Journal of Intelligent Information Technologies , 11(4), 1–15. doi:10.4018/IJIIT.2015100101
Kavitha, V., Manju, G., & Geetha, T. V. (2014). Learning to Rank Experts using combination of Multiple Features of Expertise, Advances in Computing . Communication Information , 24-27(Sept), 1053–1058.
Khalid, N. E. A., Ahmad, S. A., Noor, N. M., Fadzil, A. F. A., & Taib, M. N. (2011). Analysis of parallel multicore performance on sobel edge detector. Proceedings of the 15th WSEAS International conference on Computers (pp. 313-318). World Scientific and Engineering Academy and Society (WSEAS).
Kohavi, R., & John, G. H. (1997). Wrapper for Feature Subset Selection. In Artificial Intelligence (pp. 273–324). Elsevier.
Li, N., & Denis Gallet. (2013). Identifying influential scholars in academic social media platforms, Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (pp. 608-614). 10.1145/2492517.2492614
Li, X., Liu, B., & Yu, P. (2008). Time Sensitive Ranking with Application to Publication Search . ICDM. doi:10.1109/ICDM.2008.155
Li, Y. H., Bandar, Z. A., & McLean, D. (2003). An approach for measuring semantic similarity between words using multiple information sources . IEEE Transactions on Knowledge and Data Engineering , 15(4), 871–882. doi:10.1109/TKDE.2003.1209005
Li, Y. H., McLean, D., Bandar, Z. A., OShea, J. D., & Crockett, K. (2006). Sentence similarity based on semantic nets and corpus statistics . IEEE Transactions on Knowledge and Data Engineering , 18(8), 1138–1150. doi:10.1109/TKDE.2006.130
Lippmann, R. (1987). An introduction to computing with neural nets . ASSP Magazine, 4(2), 4–22. doi:10.1109/MASSP.1987.1165576
Liu, L., Tang, J., Han, J., & Yang, S. (2012). Learning influence from heterogeneous social networks . Data Mining and Knowledge Discovery , 25(3), 511–544. doi:10.1007/s10618-012-0252-3
Manju, G., & Geetha, T. V. (2013). Concept Similarity Based Academic Tweet Community Detection Using Label Propagation. In Mining Intelligence and Knowledge Exploration , LNCS (Vol. 8284, pp. 677–686). doi:10.1007/978-3-319-03844-5_66
Moreira, C., Calado, P., & Martins, B. (2013). Learning to Rank for Expert Search in Digital Libraries of Academic Publications, Progress in Artificial Intelligence . Springer.
Morid, M., Shajari, M., & Hashemi, A. R. (2014). Defending recommender systems by influence analysis. Information Retrieval , 17(2), 137–152. doi:10.1007/s10791-013-9224-5
Matsatsinis, N.F., Lakiotaki, K., & Delia, P. (2007). A system based on multiple criteria analysis for scientific paper recommendation. Proceedings of the 11th Panhellenic Conference on Informatics (pp. 135–149).
Nagwani, N. K. (2015). Summarizing large text collection using topic modeling and clustering based on mapreduce framework. Journal of Big Data , 2(1), 6. doi:10.1186/s40537-015-0020-5
Neylon, C., & Wu, S. (2009). Article-level metrics and the evolution of scientific impact . PLoS Biology , 7(11), e1000242. doi:10.1371/journal.pbio.1000242
Pawlak, Z. (1982). Rough Sets. International Journal of Computer and Information Sciences , 11(5), 341–356. doi:10.1007/BF01001956
Pawlak, Z. (1991). Rough Sets: Theoretical Aspects of Reasoning about Data . Kluwer Academic Publishers. doi:10.1007/978-94-011-3534-4
Pawlak, Z. (1993). Rough Sets: Present State and The Future. Foundations of Computing and Decision Sciences , 18, 157–166.
Pawlak, Z. (2002). Rough Sets and Intelligent Data Analysis. Information Sciences , 147(1-4), 1–12. doi:10.1016/S0020-0255(02)00197-4
Priem, J., & Hemminger, B. H. (2010). Scientometrics 2.0: New metrics of scholarly impact on the social web . First Monday , 15(7). doi:10.5210/fm.v15i7.2874
Quinlan, J. R. (1993). C4.5: Programs for Machine Learning, The Morgan Kaufmann Series in Machine Learning . San Mateo, CA: Morgan Kaufmann Publishers.
Sayyadi, H., & Getoor, L. (2009). FutureRank: Ranking Scientific Articles by Predicting their Future PageRank . SDM.
Shaparenko, B., & Joachims, T. (2009). Identifying the original contribution of a document via language modelling. Proceedings of the ECML.
Sie, R. L. L., Drachsler, H., Bitter-Rijpkema, M., & Sloep, P. (2012). To whom and why should i connect? co-author recommendation based on powerful and similar peers . Int. J. Technol. Enhanc. Learn , 4(1/2), 121–137. doi:10.1504/IJTEL.2012.048314
SmuckerM. D.AllanJ.CarteretteB. (2007). A Comparison of Statistical Significance Tests for Information Retrieval Evaluation. Proc. 16th ACM Conf. Information and Knowledge Management (CIKM ',07) (pp. 623-632). 10.1145/1321440.1321528
Suguna, N., & Thanushkodi, K. (2010). A novel rough set reduct algorithm for medical domain based on bee colony optimization. J. Comput. , 2, 49–54.
Sun, Y., Barber, R., Gupta, M., Aggarwal, C. C., & Han, J. (2011). Co-author relationship prediction in heterogeneous bibliographic networks. Proceedings of ASONAM.
Tang, J., Zhang, D., & Yao, L. (2007, October 28-31). Social Network Extraction of Academic Researchers, Proceedings of the 2007 Seventh IEEE International Conference on Data Mining (pp. 292-301). doi:10.1109/ICDM.2007.30
TaraborelliD. (2008). Soft peer review: Social software and distributed scientific evaluation. Proc. COOP (pp. 99–110).
Walker, D., Xie, H., Yan, K. K., & Masloc, S. (2007). Ranking scientific publications using a model of network traffic . Journal of Statistical Mechanics , 7(06), 06010–06019. doi:10.1088/1742-5468/2007/06/P06010
Wang, S., Xie, S., Zhang, X., Li, Z., Yu, P. S., & Shu, X. (2014). Future influence ranking of scientific literature. Proceedings of SDM (pp. 749–757). SIAM. doi:10.1137/1.9781611973440.86
Wang, Y. J., Tong, Y. H., & Zeng, M. (2013). Ranking Scientific Articles by Exploiting Citations, Authors, Journals, and Time Information . AAAI.
Weng, J. S., & Lee, B. S. (2011). Event Detection in Twitter . AAAI.
Xu, Y., Hao, J., Lau, R. Y., Ma, J., Xu, W., & Zhao, D. (2010). A personalized researcher recommendation approach in academic contexts: Combining social networks and semantic concepts analysis. Proceedings of PACIS.
YanR.TangJ.LiuX.ShanS.LiX. (2011, October 24-28). Citation count prediction: learning to estimate future citations for literature. Proceedings of the 20th ACM international conference on Information and knowledge management, Glasgow, Scotland, UK. 10.1145/2063576.2063757
Yin, H., Li, J., & Niu, Y. (2014). Detecting Local Communities within a Large Scale Social Network Using Mapreduce. International Journal of Intelligent Information Technologies , 10(1), 57–76. doi:10.4018/ijiit.2014010104
Zhang, Y., & Li, X. (2014, October). Relative Superiority of Key Centrality Measures for Identifying Influencers on Social Media . International Journal of Intelligent Information Technologies , 10(4), 1–23. doi:10.4018/ijiit.2014100101
Zhang, Y., Li, X., & Wang, T. (2013). Identifying influencers in online social networks: The role of tie strength. International Journal of Intelligent Information Technologies , 9(1), 1–20. doi:10.4018/jiit.2013010101
1 http://en.wikipedia.org/wiki/H-index
2 https://dev.twitter.com/rest/public/search
3 http://konect.uni-koblenz.de/networks/dblp-cite
4 https://aminer.org/
5 http://clair.eecs.umich.edu/aan/networks.php