Mental workload is considered one of the most important factors in interaction design and how to detect a user’s mental workload during tasks is still an open research question. Psychological evidence has already attributed a certain amount of variability and “drift” in an individual’s handwriting pattern to mental stress, but this phenomenon has not been explored adequately. The intention of this paper is to explore the possibility of evaluating mental workload with handwriting information by machine learning techniques. Machine learning techniques such as decision trees, support vector machine (SVM), and artificial neural network were used to predict mental workload levels in the authors’ research. Results showed that it was possible to make prediction of mental workload levels automatically based on handwriting patterns with relatively high accuracy, especially on patterns of children. In addition, the proposed approach is attractive because it requires no additional hardware, is unobtrusive, is adaptable to individual users, and is of very low cost.
Mental workload is conceptualized as the processing costs incurred in task performance (Kramer, 1991). Understanding users’ mental workload during tasks has important implications for developing adaptive systems and optimizing interface design. For example, adaptive systems can provide adaptive aiding or adaptive task allocation based on their users’ current mental workload; the interaction design patterns or elements resulting in high mental workload can also be identified then get improved. However, mental workload added to human is different among individuals and their levels of expertise, which makes it difficult to evaluate (Kalyuga, Ayres, Chandler, & Sweller, 2003).
Current evaluation methods for mental workload can be generally divided into four main categories: subjective measures, performance measures, behavioral measures and physiological measures. These methods have been adopted with some success, but they still suffer from one or more of the following problems: post-hoc evaluation, obtrusiveness, inconvenience, insufficient granularity, and the need for additional equipment(see literature review for details). The current challenges researcher face in mental workload evaluation (Lin, Imamiya, & Mao, 2008; Vizer, Zhou, & Sears, 2009) is to develop a method that: (1) unobtrusively and continuously gathers data without extra equipment; (2) evaluates mental workload objectively, quantitatively and in real-time; and (3) is suitable for automatic evaluation and deployment in real-life scenarios.
Our research interest is to use hand handwriting features of free text to detect mental workload changes. Handwriting is a typical dynamic motor skill that requires the integration of cognitive and biomechanical systems to generate an output that is stable and reproducible. A few studies (G. Luria & Rosenblum, 2010; Gil Luria & Rosenblum, 2012; Tucha, Mecklinger, Walitza, & Lange, 2006; Werner, Rosenblum, Bar-On, Heinik, & Korczyn, 2006), mostly in the clinical and psychology field, have provided empirical evidence that measures of handwriting process can capture dis-automatization in handwriting as a result of mental stress with descriptive or linear statistical analyses and this dis-automatization may cause changes in handwriting behavior. These findings shed light on the way to detect mental workload changes. However, there remain two main challenges to develop an automated evaluation method for mental workload based on this empirical evidence. The first challenge is to determine which handwriting features are most predictive of mental workload. Although various handwriting features (e.g., temporal, spatial, pressure and dynamics measures) have been explored, there is not a clear and consistent answer to the question. We try to solve the problem using wrapper-based feature selection approach (Kohavi & John, 1997). This approach performs a combinatoric optimization to find the subset of possible features which produce the best accuracy. The second challenge is choosing a proper model to represent relationships between handwriting features and mental workload. Most previous studies (Gil Luria & Rosenblum, 2012; Ruiz, Taib, & Chen, 2011) focused on providing empirical evidence for the effects of mental workload on handwriting behavior using descriptive and linear statistical techniques. But these techniques seemed to have limitations due to the inability of capturing non-linearity of handwriting behavior changes(Gil Luria & Rosenblum, 2012). As a result, only a few handwriting features (e.g., the mean and standard deviation (SD) for segment duration) were reported to show significant differences across different three mental workload conditions and change with mental workload manipulation in a linear and synchronized way (Gil Luria & Rosenblum, 2012). Luria and Rosenblum have also emphasized that not all handwriting measures relate linearly to mental workload, and further suggested that non-linear models and extensive handwriting features should be explored to reveal the relationships between handwriting behavior and mental workload(Gil Luria & Rosenblum, 2012). By using machine learning algorithms, we built up automated classifiers to explore the linear and non-linear relationship between handwriting measures and mental workload levels. To the best of our knowledge, little effort has been made to develop an automated evaluation method for mental workload leveraging handwriting information.
This paper reports an exploratory experiment, which tried to study the possibility of evaluating mental workload with handwriting information by machine learning techniques. Handwriting features were selected for children and adults separately to explore the effect of handwriting expertise on mental workload. Several models were built using machine learning algorithms to classify the mental workload level according to handwriting features.
The measurements of mental workload can be divided into four categories: subjective measures, physiological measures, performance measures and behavioral measures
Two techniques are commonly used to measure the subjective mental workload: NASA-Task Load Index (NASA-TLX, (Hart & Staveland, 1988)) and Subjective Workload Assessment Technique (SWAT, (Reid & Nygren, 1988)). NASA-TLX includes six dimensions: mental demand, physical demand, temporal demand, own performance, mental effort, and frustration. SWAT consists of three dimensions: time load, mental effort and psychological stress. They are both widely used in the field of aeronautics with some success. The objective measures have been regarded to be a good approach to understanding the overall mental workload of participants. However, these techniques have disadvantages. The objective measures are usually performed post hoc or during break points and may disrupt the normal flow of interaction(R. L. Mandryk, Atkins, & Inkpen, 2006).
Changes in mental workload have been reported to be able to result in the change of the body states. Several physiological measures, such as cardiac activity, respiration and event-related potentials, have been explored to estimate mental workload. Physiological measures have the advantage of continuous obtaining physiological response data (Kramer, 1991; Regan L. Mandryk & Atkins, 2007). However, physiological measures typically are intrusive and require supplemental equipments. Besides, processing of physiological signals tends to be computationally intensive, making it difficult to evaluate mental workload in real-time. In addition, the resulting patterns from physiological data need the interpretation from human expertise.
Participants’ mental workload can also be reflected by their observable task performance index such as time to complete a task, type and number of errors, and success rate(Galy, Cariou, & Melan, 2012).Dual-task methodology (Wierwille & Eggemeier, 1993) is often used to measure the performance and is a highly sensitive and reliable technique. However, it has rarely been applied in real-world scenarios (Paas, Tuovinen, Tabbers, & Van Gerven, 2003) due to some important drawbacks(Chen et al., 2013): (1) the may be a interference between the secondary and primary task especially when the primary task is complex or cognitive resources are limited; (2) subtle changes may not be reflected by performance measures; and (3) they have the disadvantage of being calculated post-hoc and are not suitable for real-time, automated deployment.
Experiencing a high cognitive load has been shown to be able to result in changes in interactive and communicative behavior, whether voluntary or otherwise(Chen et al., 2013). This makes it possible to assess mental workload by observing the behavior features. Some behavior measures (e.g., acoustic and prosodic speech features, linguistic features, symbolic pen gesture features and handwriting features) have been investigated (see (Chen et al., 2013) for a detailed review) and show the potential to indicate mental workload changes.
Fewer efforts were spent in investigating pen-based interaction behavior as indicators of mental workload. The motivation for these investigations is based on the premise that a user’s handwriting performance is likely to be affected by mental workload at a fine-grained level because the quality of his/her motor productions may diminish due to low working memory resources(Ruiz et al., 2011). Current investigations mainly focused on two kinds of features: pen-based gesture features and handwriting features of free text. For pen-based gestures, empirical evidence has shown that the degeneration geometric features in predefined pen-gesture shapes increases significantly when cognitive load is very high, suggesting that a cognitive load index could be derived from such a measure (Ruiz et al., 2011). Besides, significant efforts have shown the potential of handwriting features as indicators of mental workload (G. Luria & Rosenblum, 2010; Gil Luria & Rosenblum, 2012; Werner et al., 2006; Yu, Epps, & Chen, 2011a). In addition, most of them focused on employing descriptive or linear statistical method to collect empirical evidence that mental workload could affect handwriting behavior.
In the experiment, participants were first asked to complete three sentence composition tasks with low, medium and high difficulty; subjective ratings (NASA-TLX) were then used to confirm the differences in mental workload levels induced by the three tasks. Finally, the classifiers for mental workload levels were built on the handwriting features using machine learning and feature subset selection techniques.
Experiment
Participants
Ninety-eight participants (46 females and 52 males) were recruited for the experiment. Forty-nine of the participants are university students aged 18 to 30 (mean age = 22.4, SD=2.34), and the other 49 participants are fifth-grade students aged 10 to 12 (mean age = 11.39, SD= 0.72) in primary school. Before the experiment, all participants were required to complete a background questionnaire about their experience with handwriting device and English learning, along with personal information such as sex and handedness. English was not the first language for all participants, but all of them had learnt English over five years. All participants were right-handed with normal cognitive and physical ability. When asked how often they used handwriting devices, thirty-eight of the participants used often, twenty used occasionally and forty never used. Participants were compensated for their participation in the study
Tasks
Each participant experienced four experimental conditions comprised of one baseline condition (transcribing a sentence) and three sentence-making task conditions. Inspired by Ransdell and Levy’s experiments(Ransdell & Levy, 1999), we chose sentence-making training as the experimental task. Specifically, after seeing a set of randomly selected words on the screen, participants were required to write down composed sentences based on these given words in a single line or multiple lines. They were advised to use the given words, but not necessary in the given order. The baseline condition provides a benchmark for subsequent tasks to measure mental workload.
The task difficulty was manipulated by the number of the given words to be used in each sentence and the tasks become more difficult with the increase in the number of the given words. Participants completed the sentence-making tasks in three difficulty conditions (based on one, two and three given words) and these conditions were expected to cause low, medium and high levels of mental workload, respectively. Every time the participant pressed the “start” key, the given words were displayed on screen for a limited time before disappearing. The duration for displaying the words was one second for one-word cases, two seconds for two words and three seconds for three words. The participants were required to remember the displayed words and write a sentence with the given words. There were no time limit for writing, but participants were not allowed to write the words before writing the sentence.
Procedures
The experimental tasks were performed in an HCI laboratory and a WACOM DTZ-1200W tablet was used to record the handwriting process. The experiment was divided into four phases: a welcome phase, a practice phase, a task phase, and a debriefing phase. During the welcome phase, all participants were required to sign a consent form with a detailed description of the experiment, its duration, and its research purpose. Each participant also filled out a background questionnaire.
At the outset of the practice phase, instructions were read to each participant describing the task rules, and each participant was given a brief tutorial on how to complete the task. Participants were then allowed to practice for about several minutes to ensure that they mastered the method of using the handwriting device. In addition, the experiment coordinator confirmed with participants that they understood the meaning of each word which might appear in the tasks.
During the task phase, each participant was first required to normally transcribe one sentence as her/his baseline condition. They then completed three sentence-making tasks with different difficulty. The three task conditions were randomly presented to participants to avoid the order effects. After each task condition, participants had about 7 min to rest and complete a questionnaire rating mental workload to that task condition using an online NASA-TLX questionnaire system. After a participant finished one sentence and proceeded to the next one, the writing space was cleared automatically.
At the conclusion of the experiment, participants were debriefed on their impressions of the experiment.
Data Collection
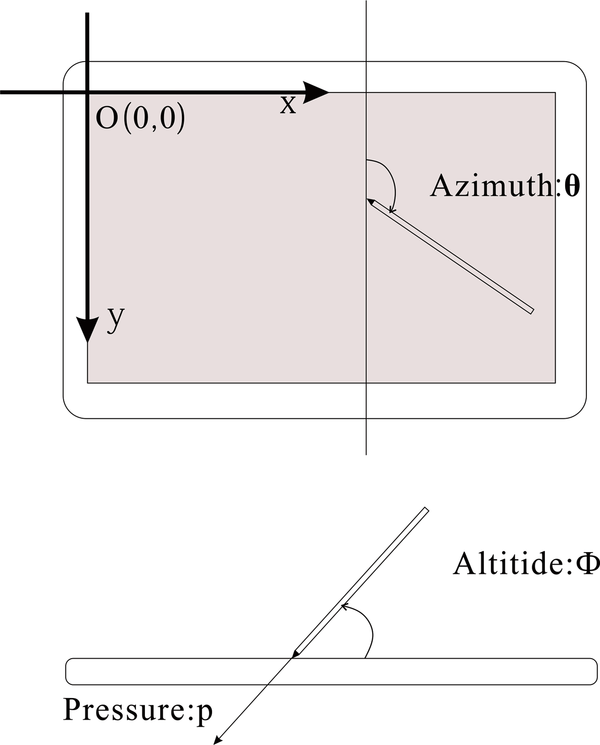
Handwriting data were recorded using a WACOM DTZ-1200W tablet at 142 Hz, which are a series of samples along the pen trace with time-stamps and include the coordinate positions (x, y), pressure (0-1024 levels) of the pen-tip (p), and the altitude and azimuth of the pen (θ, Ф), as shown in Figure 1. Handwriting features for each sentence were calculated from the raw data. The tablet does not recognize letters, words, or sentences.
| Figure 1. Handwriting information from tablet and pen |
|---|
|
Analyses
Features
We computed a total of 40 potentially predictive features for each sentence based on the handwriting measures such as time, pressure, velocity, acceleration and pen orientation. On the basis of previous handwriting analyses (e.g.(Ruiz, Taib, Shi, Choi, & Chen, 2007; Yu et al., 2011a; Yu, Epps, & Chen, 2011b)) and our observations, a set of 23 potentially predictive features was first obtained for each sentence by calculating some descriptive statistics of these measures, e.g., the average velocity of the pen-tip during writing a sentence (AvgVelocity). These features are listed in Table 1. Since we are interested in exploring the use of the handwriting features from free text in detecting mental workload changes, some spatial measures (e.g., shape degeneration from the intended standard form (Ruiz et al., 2007)) were not considered.
Table 1. Features from statistics of handwriting measures when writing a sentence
| Features | Description |
|---|---|
| AvgVelocity (AV) | Average velocity of the pen-tip |
| AvgXVelocity(AXV) | Average velocity of the pen-tip in X direction |
| AvgYVelocity(AYV) | Average velocity of the pen-tip in Y direction |
| MaxVelocity (MV) | Maximum velocity of the pen-tip |
| MaxXVelocity(MXV) | Maximum velocity of the pen-tip in X direction |
| MaxYVelocity(MYV) | Maximum velocity of the pen-tip in Y direction |
| AvgAccel(AA) | Average acceleration of the pen-tip |
| AvgXAccel (AXA) | Average acceleration of the pen-tip in X direction |
| AvgYAccel (AYA) | Average acceleration of the pen-tip in Y direction |
| MaxAccel (MA) | Maximum acceleration of the pen-tip |
| MaxXAccel (MXA) | Maximum acceleration of the pen-tip in X direction |
| MaxYAccel (MYA) | Maximum acceleration of the pen-tip in Y direction |
| SensiblePauseCount (SPC) | Count of the pen-tip pauses longer than 100ms (sensible pauses) between two successive moves |
| DurationInAir(DIA) | Duration of the pen-tip in air |
| DurationOnSurface(DOS) | Duration of the pen-tip on writing surface |
| DurationRatioAirTotal (DRAT) | Duration of the pen-tip in the air was divided by the total duration. |
| AvgAltitude (AAL) | Average altitude of the pen |
| MaxAltitude(MAL) | Maximum altitude of the pen |
| AvgAzimuth(AAZ) | Average azimuth of the pen |
| MaxAzimuth (MAZ) | Maximum azimuth of the pen |
| TotalLengthSurface (TLS) | Total path length of the pen-tip on the writing surface |
| AvgPressureSurface(APS) | Average pressure of the pen-tip on the writing surface |
| MaxPressure(MP) | Maximum pressure of the pen-tip on the writing surface |
Inspired by Luria and Rosenblum’s study (2012), 17 segment-based handwriting features were also extracted for each sentence. A segment is the curve created by the movement of the pen-tip on the writing surface. In this study, a segment was measured from when pressure of pen-tip rose above 400 (the starting point of the segment) to when the pen pressure reduced to 400 or the pen was raised from the writing surface (the ending point of the segment). That is, the pressure of all sampled data in a segment is more than 400 (non-scale units). The adopted segment-based measures include: segment duration on the writing surface, segment length (total path length from starting point to finishing point for a segment), segment height (direct distance in y-axis from the lowest to the highest point of a segment), segment width (direct distance in x-axis from the left side of a segment to the right side), angular velocity of a segment (how many degrees the pen travels when writing a segment and this is measured in degrees per second) and the number of segments. Statistics (i.e., sum, mean and standard deviation (SD)) of these measures for a sentence were computed as handwriting features of the sentence. For example, we calculated the mean duration of all segments for a sentence (AvgSegDurationSurface, ASDS) and then calculated the deviation of each segment from this mean (SDSegDurationSurface, SDSDS). The adopted segment-based features are listed in Table 2.
Table 2. Segment-based handwriting features of a sentence
| Features | Descriptions |
|---|---|
| SumSegNumber(SSN) | Count of all segments of a sentence |
| AvgSegDurationSurface(ASDS) | Average duration of all segments of a sentence |
| SDSegDurationSurface(SDSDS) | SD of duration between segments of a sentence |
| TotalSegDurationSurface(TSDS) | Total duration of all segments of a sentence |
| AvgSegLength (ASL) | Average path length of all segments of a sentence |
| SDSegLength(SDSL) | SD of path length between segments of a sentence |
| TotalSegLenght(TSL) | Total path length of all segments of a sentence |
| AvgSegHeight(ASH) | Average height (y-axis) of all segments of a sentence |
| SDSegHeight(SDSH) | SD of height (y-axis) between segments of a sentence |
| TotalSegHeight(TSH) | Total height (y-axis) of all segments of a sentence |
| AvgSegWidth(ASW) | Average height (x-axis) of all segments of a sentence |
| SDSegWidth(SDSW) | SD of height (x-axis) between segments of a sentence |
| TotalSegWidth(TSW) | Total height (x-axis) of all segments for a sentence |
| AvgSegAngularVelocity(ASAV) | Average angular velocity of all segments of a sentence |
| SDsegAngularVelocity(SDAV) | SD of angular velocity between segments of a sentence |
| AvgSegPressure (ASP) | Average pressure of all segments of a sentence |
| SDSegPressure (SDSP) | SD of pressure of between segments of a sentence |
Given the individual differences of handwriting behavior, the features from raw data were also normalized for each participant using Formula (1):
 (1)
(1)
where Fbaseline and Fraw refer, respectively, to the features from each individual’s baseline condition and his/her corresponding task conditions. The individuals’ normalized features (Fnomalized) reflect changes in handwriting behavior from their baseline conditions. Both the normalized and raw features were analyzed to determine whether accounting for individual differences in this way would yield higher classification accuracy.
Classification Methods
Decision tree (DT), support vector machine (SVM), and artificial neural network (ANN) were explored as the classifier in this study. These techniques were selected primarily because they have been widely used across a variety of applications and shown good performance. Our primary goal was to identify whether the selected handwriting features and automated models are able to successfully discriminate mental workload levels rather than optimize how well they discriminate them. Therefore, the most commonly used parameter settings were adopted in the study when training and testing classifiers. If the current methods provide promising results, we believe that this would motivate further research which would focus on developing the classifiers that could be used for mental workload evaluation in the context of a variety of pen-based interaction situations.
We built these classifiers on Weka using its default parameter settings. For DT, C4.5 was adopted in our study. Besides, an SVM with a linear kernel (L-SVM) and an SVM with a non-linear kernel (Gaussian Radial Basis Function, N-SVM) were adopted in our study. The AVA method was used to extend the binary classification to multiclass classification in our study. In addition, neural network was designed using a feed-forward architecture in which signals, travel one way only, from inputs nodes to output nodes. We first employed a single-layer neural network (SNN) using the combination of bipolar logistic function as an activation function and delta learning rule (δ) as the learning rule. A three-layer network (BPNN) was also adopted using the combination of sigmoid function as the activation function and back-propagation as the learning rule. The initial connection weights take values from −1 to 1 and all input values are normalized into [0, 1] before they are entered into the networks. The number of nodes in the hidden layer was set to half of the total number of nodes in the input and output layers.
Feature Subset Selection
Not all features necessarily contribute to creating an accurate classifier. Feature subset selection (FSE) reduces the data set size by removing irrelevant or redundant features with the aim of finding a minimum set of features for a classifier. To select features that are finely tuned to a particular classifier, we employed a wrapper-based feature selection approach (Kohavi & John, 1997).This approach performs a combinatoric optimization to find the subset of possible features which produce the best accuracy result for a given classifier. Specifically, the sequential forward selection (SFE) method was used for the classifiers except for DT. The term forward selection refers to a search that begins at the empty set of features, and we choose this method because building classifiers when there are few features in the data is much faster (Kohavi & John, 1997).
Results
Handwriting data and subjective ratings were collected from 98 participants, but the data from two fifth-grade students were ruled out because they did not complete all three task conditions. The collected data were organized into three groups: child (47 fifth grade students) and adult (49 university students) and all (all 96 participants). All analyses were conducted on each group. In the study, mental workload participant experienced was first examined through the overall NASA-TLX score to confirm whether the designed task conditions induced different mental workload levels. Then, five classification models (L-SVM, N-SVM, SNN, DT and BPNN) were built on the selected handwriting features to automatically discriminate mental workload levels.
Subjective Evaluation for Mental Workload
For the child data set, a one-way ANOVA showed that there were significant differences in overall NASA-TLX scores across the three task conditions (f=184.21, p =0.001). Post hoc comparisons also showed that the three-word tasks were the most difficult and induced the greatest mental workload, followed by the two-word task and one-word task (see Table 3). For the adult and all data sets, the same patterns were found (see Table 3). In addition, when examined individually, the pattern was consistent for all participants. At the debriefing phase, almost all participants also reported that they felt it easy to compose sentences with a single word, and challenging or especially challenging for the three-word tasks.
Table 3. Means for the self-reported mental workload on an online NASA-TLX questionnaire. * represents p<0.05.
| Data sets |
One-word Mean (SD) |
Two-word Mean(SD) |
Three-word Mean (SD) |
f | One-Two | One -Three | Two-Three |
|---|---|---|---|---|---|---|---|
| t | t | t | |||||
| Child | 58.64(6.99) | 68.04(9.89) | 78.08(13.33) | 184.21* | 7.57* | 19.12* | 12.34* |
| Adult | 53.36(5.75) | 61.99(7.34) | 73.08(10.33) | 179.34* | 6.81* | 18.75* | 10.03* |
| All | 55.56(5.99) | 64.99(8.35) | 75.51(11.27) | 370.12* | 7.02* | 18.01* | 11.19* |
The above results validate our experimental task design and confirm that the three task conditions indeed can elicit different mental workload levels, which provides an important benchmark for subsequent analyses and classification.
Classification
Table 4 reports the classification accuracy of each classifier on all data set (all 96 participants).Bold entries highlight the best results obtained on the raw and normalized features, respectively.
Table 4. Classification accuracy of the all data set
| Classifiers | Accuracy | Difference (Raw vs. Normalized) | ||
|---|---|---|---|---|
| Raw | Normalized | t | p | |
| DT | 0.547 | 0.603 | 2.835 | 0.023 |
| L-SVM | 0.541 | 0.575 | 2.551 | 0.031 |
| N-SVM | 0.617 | 0.756 | 3.245 | 0.001 |
| SNN | 0.530 | 0.587 | 2.521 | 0.041 |
| BPNN | 0.640 | 0.739 | 2.983 | 0.002 |
The results in Table 4 show: (1) BPNN produced the best classification accuracy (64%) on the selected raw features (ASDS, SDSDS, SDSL, ASP, MP, DRAT, ASAV and AAL) and N-SVM generated the best classification accuracy (75.6%) on the selected normalized features (ASDS, SDSDS, SDSL, SSD, ASP, SPC, AAL, SDAV, and AP); (2) the selected features for the BPNN and N-SVM were mainly from the segment-based features, suggesting that the segment-based feature extracting method was very useful for discriminating mental workload levels.
The results in Table 4 also show that using normalized features resulted in an increase in classification accuracy for each classifier, producing an average increase of 7.7%. We conducted paired t-tests on the classification accuracy of each classifier between the raw and normalized features. The analyses suggest that all improvements for accuracy were statistically significant (see Table 4) and this benefit was more pronounced for the N-SVM classifier (an increase of 13.9%). Thus, it can be inferred from the results in Table 4 that normalization that accounts for individual differences is generally helpful for improving the performance of classifiers. The results suggest that individual differences should be taken into consideration when using handwriting features to evaluate mental workload. In addition, the classification accuracy between the three nonlinear classifiers (DT, BPNN, and N-SVM) was compared. The results show that: (1) for the normalized features, there were significant differences in classification accuracy (F(2,27)=5.53, p=0.01) and post hoc comparisons suggested that N-SVM produced the best classification accuracy(75.6%), followed by BPNN (73.9%) and DT (60.3%) (N-SVM vs. DT: p=0.007; N-SVM vs. BPNN: p=0.041; BPNN vs. DT: p=0.021); and (2) for the raw features, there were significant differences in classification accuracy (F(2,27)= 4.03, p=0.023) and post hoc comparisons suggested that BPNN produced the best accuracy (64.0%), followed by N-SVM (61.7%) and DT(54.7%) (N-SVM vs. BPNN: p=0.047; N-SVM vs. DT: p=0.034; BPNN vs. DT: p=0.027).
It can also be observed from these results in Table 4 that all the nonlinear classifiers (N-SVM, DT, and BPNN) generated better classification accuracy than the two linear ones (L-SVM and SNN). The differences in accuracy between DT (the non-linear classifier with the lowest accuracy) and the two linear classifiers (L-SVM and SNN) were examined. For both the raw and normalized features, DT produced the higher accuracy than L-SVM and SNN (DT vs. L-SVM: p=0.023; DT vs. SNN: p=0.034), and the differences between L-SVM and SNN did not reach statistical significance.
Table 5. Classification accuracy for the child and adult data sets
| Classifiers | Child | Adult | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Difference | Accuracy | Difference | |||||
| Raw | Normalized | t | p | Raw | Normalized | t | p | |
| DT | 0.613 | 0.682 | 2.281 | 0.031 | 0.548 | 0.657 | 2.271 | 0.041 |
| L-SVM | 0.570 | 0.633 | 2.272 | 0.034 | 0.541 | 0.589 | 2.290 | 0.037 |
| N-SVM | 0.664 | 0.805 | 3.437 | 0.006 | 0.613 | 0.769 | 3.312 | 0.009 |
| SNN | 0.549 | 0.634 | 2.547 | 0.020 | 0.531 | 0.598 | 2.311 | 0.034 |
| BPNN | 0.695 | 0.782 | 2.279 | 0.033 | 0.643 | 0.748 | 2.881 | 0.021 |
The classifiers for the child and adult data sets therefore were developed respectively and Table 5 shows classification accuracy of each classifier on the normalized and raw features. Bold entries highlight the best results obtained on the normalized and raw features for each data set. The best classification rates were 80.5% for the child data set and 76.9% for the adult data set; the average classification rates of the five classifiers for each data set were also examined and the child data set showed the significant increases of 4.3% (p=0.007) and 3.5% (p=0.001) on the raw and normalized features, respectively, as compared with the adult data set. These results suggested that the changes of handwriting behavior for children due to mental workload seemed to be more detectable than adults. In addition, for both child and adult data sets, the classification accuracy of each classifier on the normalized features was significantly higher than on the raw features, producing the average increases of 8.9% and 9.3%, respectively.
In sum, the above results show that mental workload can cause changes in handwriting patterns that are detectable using machine learning techniques.
Findings
This study explored the relationship between exposure to mental workload and changes in handwriting patterns using machine learning techniques. Specifically, five classifiers (N-SVM, L-SVM, DT, SNN, and BPNN) were built on the potentially predictive handwriting features; the results showed that changes in some handwriting features across three mental workload conditions could be detected by machine learning models and the non-linear models seemed to serve the purpose better than the linear models.
The classifiers were built on both the raw and normalized features to determine whether accounting for individual differences by normalized the raw data would yield higher classification accuracy. For the raw features of each data set, BPNN obtained the best classification results possibly due to their high tolerance for noisy raw handwriting data; the best classification rates for the all, child and adult data sets were 64.0%, 69.5% and 64.3% respectively.
When individual differences were addressed by normalizing the handwriting features, the classification rates were significantly improved for each classifier. N-SVM had the best classification performance for the all, child and adult data sets, producing the accuracy of 75.6%, 80.5% and 76.9%, respectively. These results suggest that it is not only possible to discriminate mental workload levels using machine learning techniques, but it may be possible to obtain a higher classification rate when suitable non-linear classifiers were adopted and individual differences were addressed. While the classification rates for mental workload may not be comparable to the rates obtained by physiological measures, the current approach has advantages over physiological measures because it requires no additional hardware, is unobtrusive, and is less computationally intensive.
Our results also showed that the classification accuracy of the child data set was significantly better than the adult data set, respectively producing the average increases of 4.3% and 3.5% on the raw and normalized features. This suggests that the changes of handwriting behavior for children due to mental workload seem to be more detectable than adults. These results may in part be explained by evidence from psychological studies. Some studies (e.g. Gil Luria & Rosenblum, 2012; Smits-Engelsman & Van Galen, 1997; Wann, 1986) have suggested that handwriting performance becomes automatic with age and children tend to have a lower automatic level in handwriting pattern than adults, and that the less skilled and automatic handwriting is, the more variability there is in temporal, spatial and pressure measures. Thus, we assumed that dis-automatization as a result of mental stress may be more evident for children than adults and this may result in the higher classification accuracy.
In addition, a recent study (Gil Luria & Rosenblum, 2012) was designed to test whether handwriting features are sensitive to variations in mental workload while numbers are written and its results showed that the pressure-related features did not seem a good indicator of mental workload changes. In contrast, our results showed that some pressure-related features (e.g., ASP, AP and SDSP) were useful for detecting mental workload changes while words are written, which was partly in line with the results from the study (Yu et al., 2011b). The inconsistency between these studies may be attributed to the differences in cognitive mechanisms when writing numbers and words (Gil Luria & Rosenblum, 2012; McCloskey, Caramazza, & Basili, 1985) and they may be manifested differently in handwriting measures. Future research will further test the effects of mental workload on handwriting measures when completing different types of tasks.
Implications for Research and Practice
The study confirms the feasibility of using handwriting features and machine learning techniques to automatically evaluate mental workload. To our knowledge, machine learning techniques have not been used on handwriting features for mental workload evaluation. The exploratory study extends the state of the art by extracting and selecting a unique set of features from handwriting measures as input to machine learning models for classification of mental workload levels. The current study used the features selected by the SFS method as input to L-SVM, N-SVM, BPNN, DT and SNN, and other machine learning models and feature subset selection techniques could be employed to obtain better classification accuracy.
Most research on handwriting analyses so far focused on the signature verification areas (e.g.,(Jain, Griess, & Connell, 2002; Plamondon & Lorette, 1989)). Our study demonstrates that handwriting measures can be useful as an unobtrusive and easy-to-use data source of continuously monitoring mental workload. While physiological measures of assessing mental workload are well studied and allow for high accuracy rates, the measures tend to be obtrusive, require supplementary equipments or are labor or computationally intensive. In contrast, our method does not require measurements during an event, requires no additional equipment, and leverage normal daily activities. The method also may spur research into additional applications. For example, the method has implications for researches on pen-based adaptive systems. An adaptive pen-based interaction system, which is aware of the users’ current mental workload, can change its response, presentation and interaction flow to improve users’ experience and their task performance. Suppose that a pen-based mathematic training system notices that the current user is experiencing high mental workload while solving a particular mathematical problem. The system may then insert more explanations and suggestive examples, or eliminate unnecessary distractions (e.g. background music) to avoid mental overload. Similarly, if the user’s current mental workload is lower than an optimal level, the system may increase the difficulty of the presented problems. Some studies (e.g., (Jo, Myung, & Yoon, 2012)) also emphasized that predicting the mental workload perceived by users can provide designers with useful information to reduce the possibility of human error and cost of training, improve the safety and performance of systems, and achieve user satisfaction. Besides, the method of using handwriting measures to evaluate mental workload may be used as a post hoc analysis technique for user interface evaluation and interaction design improvement. For example, we can use two different pen interaction interfaces used by the same user for the same task and then determine which one causes higher mental workload. The results may enable us to improve the interaction design for the interface that is causing higher mental workload.
In sum, there has been an increasing need for an objective, unobtrusive, cost-effective evaluation method of monitoring changes of mental workload, especially in instruction and high-risk situations. The research explores the possibility of combining machine learning techniques and handwriting measures in automatically evaluating mental workload with the ultimate goal of continuous monitoring of handwriting information to detect acute or gradual changes in mental workload in some pen-interaction situations. The primary contributions of the initial empirical study are to (1) provide knowledge about what detailed handwriting features are predictive of mental workload changes; (2) illustrate a new methodology of using machine learning and feature selection techniques to reveal the relationship between handwriting behavior and mental workload; (3) demonstrate the use of machine learning models on handwriting data to automatically evaluate mental workload; and (4) highlight the opportunity of monitoring handwriting behavior for understanding user cognitive status. The relatively high classification accuracy in the exploratory study warrants further research with the aim of establishing an objective, quantitative, cost-effective and real-time evaluation method; furthermore, each of these contributions opens a door for new research, e.g., exploring the relationships between mental workload and handwriting behavior, employing machine learning techniques and handwriting behavior to automatically evaluate cognitive state and developing adaptive systems based on mental workload monitoring.
This study presents an initial exploration into how to use handwriting information to evaluate mental workload and the opportunities for future work are vast. Our further research will work toward refining the experimental design, investigating additional analysis methods, and exploring practical applications such as adaptive training systems.
Mental workload in the study was induced by sentence-making tasks in laboratory settings and participants were drawn from the population at a primary school and a university. Although our experimental results show the potential of using machine learning techniques and handwriting features to evaluate mental workload, its effectiveness should further be validated across multiple kinds of experimental tasks (e.g., writing numbers) and fine-grained mental workload levels in real-world situations. In addition, the size of the data set in the study is relatively small for machine learning and a large number of samples could allow for more accurate classification results.
Additional analyses will include extensive testing of machine learning models and incorporation of new handwriting features. The performance of machine learning models could be improved by fine-tuning its parameters. For example, while our results showed that N-SVM on normalized handwriting features discriminated mental workload levels well, some important parameters (i.e., the penalty parameter and kernel parameter) should be explored to improve classification accuracy. Our results also show that classification accuracy was improved when handwriting features were normalized, suggesting that individuals’ handwriting patterns vary in their responses to mental workload. Therefore, future studies should consider the possibility of generating individualized models for each participant to determine if personalizing the classifiers will produce better results. In addition, a variety of methods of extracting handwriting features and more potential stroke features will be studied to improve classification accuracy in the future.
This research was previously published in the International Journal of Technology and Human Interaction (IJTHI), 12(3); edited by Anabela Mesquita and Chia-Wen Tsai; pages 18-32, copyright year 2016 by IGI Publishing (an imprint of IGI Global).
We would like to express our gratitude to all participants in the experiment and a special gratitude is expressed to anonymous reviewers and editors for your help suggestions and encouragement. The research is partly supported by Science and Technology Supporting Program, Sichuan Province, China (No. 2012GZ0091, 2013GZX0138).
Chen, F., Ruiz, N., Choi, E., Epps, J., Khawaja, M. A., Taib, R., & Wang, Y. (2013). Multimodal behavior and interaction as indicators of cognitive load. ACM Transactions on Interactive Intelligent Systems , 2(4), 1–36. doi:10.1145/2395123.2395127
Galy, E., Cariou, M., & Melan, C. (2012). What is the relationship between mental workload factors and cognitive load types? International Journal of Psychophysiology , 83(3), 269–275. doi:10.1016/j.ijpsycho.2011.09.023
Han, J., & Kamber, M. (2006). Data mining: concepts and techniques (2nd ed.). Boston: Morgan Kaufmann.
Hart, S. G., & Staveland, L. E. (1988). Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research . In Hancock, P. A., & Meshkati, N. (Eds.), Human Mental Workload (pp. 139–183). Amsterdam: Elsevier Science. doi:10.1016/S0166-4115(08)62386-9
Jain, A. K., Griess, F. D., & Connell, S. D. (2002). On-line signature verification. Pattern Recognition , 35(12), 2963–2972. doi:10.1016/S0031-3203(01)00240-0
Jo, S., Myung, R., & Yoon, D. (2012). Quantitative prediction of mental workload with the ACT-R cognitive architecture. International Journal of Industrial Ergonomics , 42(4), 359–370. doi:10.1016/j.ergon.2012.03.004
Kalyuga, S., Ayres, P., Chandler, P., & Sweller, J. (2003). The expertise reversal effect. Educational Psychologist , 38(1), 23–31. doi:10.1207/S15326985EP3801_4
Kohavi, R., & John, G. H. (1997). Wrappers for feature subset selection. Artificial Intelligence , 97(1-2), 273–324. doi:10.1016/S0004-3702(97)00043-X
Kramer, A. F. (1991). Physiological metrics of mental workload: A review of recent progress. In Multiple-task performance (pp. 279-328).
Lin, T., Imamiya, A., & Mao, X. (2008). Using multiple data sources to get closer insights into user cost and task performance. Interacting with Computers , 20(3), 364–374. doi:10.1016/j.intcom.2007.12.002
Luria, G., & Rosenblum, S. (2010). Comparing the handwriting behaviours of true and false writing with computerized handwriting measures. Applied Cognitive Psychology , 24(8), 1115–1128. doi:10.1002/acp.1621
Luria, G., & Rosenblum, S. (2012). A computerized multidimensional measurement of mental workload via handwriting analysis. Behavior Research Methods , 44(2), 575–586. doi:10.3758/s13428-011-0159-8
Mandryk, R. L., & Atkins, M. S. (2007). A fuzzy physiological approach for continuously modeling emotion during interaction with play technologies. International Journal of Human-Computer Studies , 65(4), 329–347. doi:10.1016/j.ijhcs.2006.11.011
MandrykR. L.AtkinsM. S.InkpenK. M. (2006). A continuous and objective evaluation of emotional experience with interactive play environments. Proceedings of the SIGCHI conference on Human factors in computing systems (pp. 1027-1036). 10.1145/1124772.1124926
McCloskey, M., Caramazza, A., & Basili, A. (1985). Cognitive mechanisms in number processing and calculation: Evidence from dyscalculia. Brain and Cognition , 4(2), 171–196. doi:10.1016/0278-2626(85)90069-7
Paas, F., Tuovinen, J. E., Tabbers, H., & Van Gerven, P. W. M. (2003). Cognitive load measurement as a means to advance cognitive load theory. Educational Psychologist , 38(1), 63–71. doi:10.1207/S15326985EP3801_8
Plamondon, R., & Lorette, G. (1989). Automatic signature verification and writer identification — the state of the art. Pattern Recognition , 22(2), 107–131. doi:10.1016/0031-3203(89)90059-9
Ransdell, S., & Levy, C.M. (1999). Writing, reading, and speaking memory spans and the importance of resource flexibility. In The cognitive demands of writing: Processing capacity and working memory in text production (pp. 99-113).
Reid, G. B., & Nygren, T. E. (1988). The Subjective Workload Assessment Technique: A Scaling Procedure for Measuring Mental Workload. In A. H. Peter & M. Najmedin (Eds.), Advances in Psychology (Vol. 52, pp. 185-218). North-Holland. doi:10.1016/S0166-4115(08)62387-0
RuizN.TaibR.ChenF. (2011). Freeform pen-input as evidence of cognitive load and expertise. Proceedings of the 13th international conference on multimodal interfaces, Alicante, Spain. 10.1145/2070481.2070511
Ruiz, N., Taib, R., Shi, Y., Choi, E., & Chen, F. (2007). Using pen input features as indices of cognitive load . Nagoya, Aichi, Japan: Name. doi:10.1145/1322192.1322246
Smits-Engelsman, B., & Van Galen, G. P. (1997). Dysgraphia in children: Lasting psychomotor deficiency or transient developmental delay? Journal of Experimental Child Psychology , 67(2), 164–184. doi:10.1006/jecp.1997.2400
Tucha, O., Mecklinger, L., Walitza, S., & Lange, K. W. (2006). Attention and movement execution during handwriting. Human Movement Science , 25(4–5), 536–552. doi:10.1016/j.humov.2006.06.002
Vizer, L. M., Zhou, L., & Sears, A. (2009). Automated stress detection using keystroke and linguistic features: An exploratory study. International Journal of Human-Computer Studies , 67(10), 870–886. doi:10.1016/j.ijhcs.2009.07.005
Wann, J. P. (1986). Handwriting disturbances: Developmental trends Themes in motor development (pp. 207–223). Springer. doi:10.1007/978-94-009-4462-6_11
Werner, P., Rosenblum, S., Bar-On, G., Heinik, J., & Korczyn, A. (2006). Handwriting Process Variables Discriminating Mild Alzheimer's Disease and Mild Cognitive Impairment. The Journals of Gerontology. Series B, Psychological Sciences and Social Sciences , 61(4), 228–P236. doi:10.1093/geronb/61.4.P228
Wierwille, Walter W, & Eggemeier, F Thomas. (1993). Recommendations for mental workload measurement in a test and evaluation environment. Human Factors: The Journal of the Human Factors and Ergonomics Society , 35(2), 263–281.
YuK.EppsJ.ChenF. (2011a). Cognitive load evaluation of handwriting using stroke-level features. Proceedings of the 16th international conference on Intelligent user interfaces, Palo Alto, CA, USA. 10.1145/1943403.1943481
Yu, K., Epps, J., & Chen, F. (2011b). Cognitive Load Evaluation with Pen Orientation and Pressure . Alicante, Spain: Name.