
Figure 9 General model of selection systems.
In chapter 7, we noted that the basic structure of information retrieval is usually shown in textbooks in the form shown in figure 9, with varying amounts of additional descriptive detail depending on the purpose of the description. There is a symmetry between queries and documents.
Figure 9 General model of selection systems.
A typical online library catalog uses a highly structured database, and we use a generalized description to illustrate how such a system works.
In the broader environment, there are the documents to be cataloged; humans who have queries; and a variety of external resources, such as the standardized vocabularies (e.g., the U.S. Library of Congress Subject Headings), the subject classification scheme being used, sources of catalog records, and the rules and procedures to be followed. The output is the search result—the retrieved set—although there will also be feedback reports, such as error messages.
What happens inside the system is shown in figure 10.
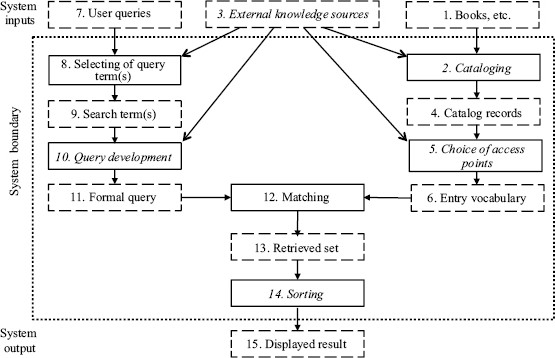
Figure 10 A minimally complete model of a library catalog.
Figure 10 illustrates a model of a library catalog. Solid boxes contain processes. Dashed boxes contain records, either queries or catalog records. Italics show optional components, and arrows indicate flows. The documents to be cataloged are shown at top right (box 1). A cataloging process (box 2) may draw on cataloging rules, standard vocabularies, and catalog copy from elsewhere (box 3) and result in a set of catalog records (box 4). In practice, not all parts of catalog records are searchable, so a further process determines the choice of access points (box 5), yielding the searchable set of index entries, also known as the entry vocabulary (box 6).
Library users have their queries (box 7) and the expression of these queries needs to be adapted to the terminology of retrieval system (box 8) to select one or more acceptable search terms (box 9), which can then be formulated (box 10) into a formal query (box 11) for matching (box 12) against searchable terms—“entry vocabulary” (box 6)—to derive a search result or “retrieved set” (box 13). Usually, the initially retrieved set is sorted (box 14) for display of the search result (box 15).
Some features of figure 10 invite attention.