As explained in chapter 8, relevance is the standard measure for the evaluation of selection systems. It is used as a binary measure: documents are judged to be either relevant or not relevant to a given query. Given a set of relevance judgments, performance is assessed in two ways: recall is the completeness of selection performance, measured as the proportion of the relevant documents that were successfully selected; and precision is ability of the selection system to select relevant documents and not nonrelevant documents, measured as the proportion of the selected documents that are relevant. Here we use graphs to show these two measures and the relationship between them given different selection performances.
Recall Graphed
We assume a collection of 1,000 documents, of which 100 are relevant to a query. These numbers may be unrealistic, but they are convenient for explanation.
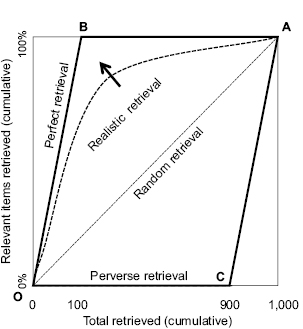
A graph (figure 11) is calibrated 0–1,000 on the horizontal axis for the number of documents in the collection selected (the retrieved set) and vertically 0–100% for recall, the proportion of the relevant 100 documents that have been retrieved. A recall graph necessarily starts at the origin (bottom left, O) when no items have been retrieved and must end when all documents, relevant or not, have been retrieved at the top right corner (A). So all recall curves must start at the origin, lower left, and end at the top right. The interest is in the shape of the line from O to A.
Figure 11 Recall graph for random retrieval, perfect retrieval, realistic retrieval, and perverse retrieval.
Figure 11 shows recall with lines from O to A for random retrieval (dotted line), perfect retrieval (thick line, OBA), realistic retrieval (dashed curve), and perverse retrieval (lower thick line, OCA).
If documents were retrieved at random, the odds are always the same that the next document retrieved will be relevant (in this example, 1 in 10), so the recall curve would be a diagonal straight line from the origin (O) and ending in the top right corner (A), shown here as a dotted line.
A perfect retrieval system would retrieve only relevant items until no more were left, and if one continued to retrieve, any further retrievable documents would necessarily have to be nonrelevant. This perfect selection performance is plotted in figure 11 as a steeply rising line from the origin (O) to the top (at B) which is reached, in our example, when all 100% of the 100 relevant items have been retrieved. Further retrieval could only be of the remaining items (all nonrelevant), so the line would turn right and move horizontally along the top margin to the top right-hand corner from B to A.
It is realistic to assume that any actual retrieval system will be less than perfect but better than retrieval at random, and so the performance curve will be somewhere between the lines for perfect and for random. What happens is that the ratio of relevant items retrieved to nonrelevant items retrieved is better than random, and so the realistic line rises more steeply than the random line. But a consequence of this early success is that the pool of not-yet-retrieved relevant items decreases more rapidly than with random retrieval. As a result, although a realistic retrieval curve must rise faster at first than the straight diagonal line for random retrieval, it must gradually flatten out until it reaches the top right-hand corner (A) where all recall curves must end. Since no operational system is exactly and always perfect, the curve must also run below the line for perfect retrieval, and so it must always be within the triangle OBC and is likely to be more or less like the curved dashed line drawn. The better the performance of a retrieval system, the closer its recall curve will be closer to the perfect retrieval line than to the random retrieval line, tending in the direction of the arrow.
For theoretical completeness we can also draw the recall curve for a perfectly awful retrieval system that insisted on retrieving all and only nonrelevant items until no more were left and thereafter could only retrieve relevant items. We call this imagined case perverse retrieval and a perverse retrieval curve would run straight horizontally from O to C, then necessarily rising to A.
In conclusion,
the parallelogram OBAC defines all possible recall performances.
only systems achieving better than random retrieval will be of any practical interest, so all realistic systems will have recall curves within the triangle OBA.
the better the retrieval performance, the closer the actual recall curve will be to the perfect retrieval curve (OBA) and away from the diagonal random retrieval recall curve (OA). Differently stated, the better the retrieval performance, the more its curve will move in the direction of the arrow.
Precision Graphed
A comparable graph can be drawn for precision. See figure 12.
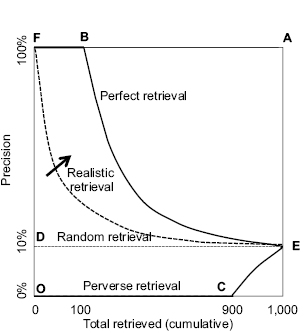
Figure 12 Precision graph showing lines for random retrieval, perfect retrieval, perverse retrieval, and realistic retrieval.
In our example, 100 out of the 1,000 items in the collection are relevant, so documents retrieved at random will tend to be composed of one relevant item for every nine nonrelevant. Precision is expressed as a percent, so random retrieval has a precision of 10% regardless of how many items are retrieved. This is shown by the horizontal dotted line from D to E.
A perfect retrieval system would initially yield only relevant items, so it starts and remains at 100% precision until all the 100 relevant items have been retrieved (at point B). After that, only nonrelevant items remain, so the retrieved set becomes progressively more diluted with nonrelevant items until, when the entire collection has been retrieved, precision reflects the collection as a whole. The perfect retrieval curve changes direction at point B and follows a concave curve down to point E.
Correspondingly, a perverse retrieval system initially retrieves all and only nonrelevant items, so until all the 900 nonrelevant items have been retrieved precision remains at zero and the line is horizontal from O to C. Then all remaining documents are relevant so precision can only increase, as shown by the convex curve from C to E.
Any realistic retrieval system, being better than random but less than perfect, will lie between the lines for perfect retrieval and for random retrieval, starting at or near 100% precision, then decaying in a concave curve until it eventually reaches E. The better the performance, the closer the realistic curve will be to the perfect retrieval curve, as indicated by the arrow.
The Relationship between Precision and Recall
Since both recall and precision have been plotted against total retrieval, they can be plotted against each other, as shown in figure 13.
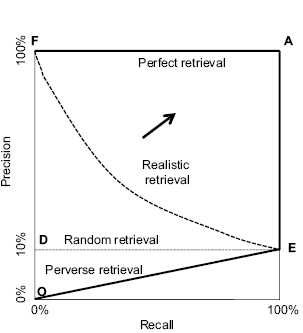
Figure 13 The relationship between precision and recall for random, perfect, perverse, and realistic retrieval.
With random retrieval, precision tends to 10% regardless of recall and so is shown as the horizontal dotted line (DE).
A perfect retrieval system yields only relevant items until no more are left, so precision starts at 100% at F and continues horizontally at 100% across the top of the graph from F to A until recall is complete. After that point, when only nonrelevant items remain to be retrieved, recall is unaffected but precision is reduced, so the line falls vertically from A to E.
With perverse retrieval, the 900 nonrelevant items have to be retrieved before the first relevant item. During the retrieval of those first 900, both precision and recall are at zero, so the line remains at the origin (O). When, finally, only relevant items remain to be retrieved, both precision and recall begin to rise in an almost flat concave curve from O to E.
The curve for realistic retrieval, as before, lies between the lines for random and perfect retrieval. The line should start at or near 100% precision (near F) and then form a downward, concave curve, eventually reaching E when the entire collection has been retrieved. In this, as in the other graphs, the more effective the retrieval system, the nearer the curve will be to the perfect curve, as indicated by the arrow.
The advantage of drawing curves for both perfect and perverse retrieval is that they define the space of possible retrieval performance. The area between perfect retrieval and random retrieval defines the realistic region of practical retrieval systems. Within this region all retrieval performances that are better than random necessarily have downward sloping curves in figure 13. In other words, a trade-off between precision and recall is unavoidable for any retrieval system that performs better than randomly.
The traditional criterion in the evaluation of selection systems is relevance, the most central concept in the field. The idea is that all and only relevant items should be selected, but this simple wish is deeply problematic in multiple ways. “Relevant” could be those items wanted or needed by the inquirer, those that will please or be most useful. However, want, need, please and useful are not the same, and assessments will be highly subjective—and, since the search is presumed to be by someone inadequately informed, likely to be unreliable. Relevance is highly situational, depending on what the inquirer already knows, and unstable, because the inquirer is, or should be, actively learning. The standard assumption that all items are independent, in the sense that the relevance of one item does not affect the relevance of any other item, is a convenient but unconvincing simplification. If two documents are very similar, one usually does not need both. Further, the goals of all relevant items and only relevant items are in conflict, because in practice one can seek to emphasize all (recall) only at the expense of only (precision), or vice versa.
Summary
In hindsight, it can be seen that the inverse relationship found is entailed by the way retrieval effectiveness is formulated: if all items are characterized as either relevant or nonrelevant, then any initial success in picking out relevant items necessarily has the effect of impoverishing the pool of items remaining to be retrieved, so retrieval performance must progressively deteriorate. Although the notion of relevance is easy to understand, it resists being operationalized in practice, and we must fall back on crude but practical substitutions.