1 Introduction
Securing modern networks is a non-trivial challenge that requires high throughput (to evaluate in real-time the behavior of the network) and expert knowledge (to decide whether suspicious or malicious activity is taking place on the network). Network intrusion detection, in particular, is concerned with the early detection of attempts of breaking into and/or comprising a network. Packet collection techniques allows the continuous monitoring of networks and the collection of large amounts of traffic data.
Modern network intrusion detection data sets quickly exceeds the processing capacity of human reviewers, and thus automatic processing techniques for filtering and analyzing the data become necessary. A simple solution consists in eliciting knowledge from experts and encoding it into logical rules. Such rule-matching or signature-matching algorithms can process the data quickly, but their effectiveness is limited by the sort and the range of knowledge provided by the experts; in particular, these algorithms lack any sort of generalization and are unable to deal with novel data that do not perfectly match the encoded rules [8]. Machine learning has been put forward as a potential solution to this shortcoming. By learning directly from the data, and not from the particular knowledge provided by experts, machine learning algorithms aim at learning patterns that may hold not only for historical collected data, but also for future unforeseen data.
Many current machine learning techniques rely on large amount of data to learn useful patterns. The success of deep learning, in particular, has been explained by, among other factors, the availability of big data sets [13]. However, large data sets have also significant drawbacks. Large collections of data are problematic to archive and to store on drives; they are challenging to manipulate and load, requiring either a high amount of memory or frequent swapping operations; they are often redundant, to the point that this redundancy contributes little or nothing to the learning process.
Beyond deep learning, other machine learning algorithms may be severely affected in a negative way by large redundant data sets. This is the case, for instance, of Bayesian machine learning. Bayesian machine learning provides a rigorous framework for performing inference over data. It allows the estimation of complete probability distributions, a precise evaluation of uncertainty, the possibility of neatly integrating prior expert knowledge in the learned model, and the ability to update the learned model when provided with new data. However, all these possibilities come at a high computational cost, as standard Bayesian learning relying on Markov chain Monte Carlo (MCMC) algorithms do not to scale well with respect to the size of the data.
In presence of large redundant data sets, a possible solution to make inference via MCMC feasible consist in the reduction of the number of samples used to learn. Simple solutions include statistical techniques like random sampling or unsupervised learning algorithms such as clustering via k-means [2]. A more exact approach is based on the idea of creating coresets: instead of learning on the whole redundant data sets, it may be possible to define a (weighted) subset of samples which is probabilistically guaranteed to return a result close to the one that would be obtained by processing the whole data. In Bayesian machine learning, [3, 4] recently proposed an efficient and promising algorithm to learn Bayesian coresets in Hilbert space (BCH) that computes a weighted subset of samples by smartly exploiting the structure of that space.
As many other applications, network intrusion detection could take advantage of Bayesian data analysis. A careful estimation of uncertainty when evaluating the possibility of a threat on the network is critical in order to take decisions. The possibility of integrating expert knowledge and update models are also important features in the complex and constantly changing environment of networks. Unfortunately though, the amount of data collected by capturing packets on a network quickly exceeds the feasibility of performing Bayesian machine learning via MCMC. By filtering redundant data and reducing the amount of samples via BCH, network traffic data sets could be reduced in size (thus offering a concrete benefit for storing and management) and processed using Bayesian techniques (thus producing more complete and versatile results).
In this paper we conduct a preliminary study of the possibility of applying BCH to network intrusion detection data and perform Bayesian machine learning via MCMC. We consider two main problems. (i) How effective is the use of BCH to learn models of network intrusion? We address this question considering (subsets of) realistic network traffic data and evaluating the effectiveness of BCH on a simple supervised learning problem. While an evaluation of BCH on computer security data (phishing data sets) is already provided in [3, 4] in terms of metrics of posterior quality, we offer here an analysis in terms of accuracy, which is more relevant to the field of cyber-security. In particular we consider our results in light of the trade-off between time-space and accuracy and with respect to the sensitivity of BCH to its hyper-parameters. (ii) How effective is the use of BCH to reduce the amount of data in a streaming environment? We answer this question by considering the same realistic network data, but setting up a more challenging scenario in which the data samples are received sequentially. In this context, we analyze, once again in terms of accuracy and time-space savings, the advantages that BCH may bring when processing the data in real-time, upon arrival. Our results confirms that the trade-off between accuracy and time-space savings when using BCH is mainly regulated by one of the free hyper-parameters of BCH. Moreover, we show that the algorithm could be successfully used in a streaming environment, where it succeeds in sensibly reducing the computational time over several iterations and in ensuring good performances by aggregating coresets over the same iterations.
On the side, while tackling these questions, we also offer a practical contribution in the form of a porting of BCH algorithms1 [3] into the framework of the probabilistic programming library Edward [19]. Specifically, we adapt the original code for coreset computation to work with Edward models, thus exploiting the probabilistic programming features of Edward2 and the automatic differentiation feature of Tensorflow3. Code for this implementation is available online4.
The rest of the paper is organized as follows. Section 2 briefly describes Bayesian machine learning and BCH. Section 3 outlines the problem of network intrusion detection and references previous work. Section 4 introduces our experimental setup. Section 5 tackles our first research question by analyzing the use of BCH on network traffic data. Section 6 deals with our second research question by evaluating the use of BCH in a streaming environment. Finally, Sect. 7 summarizes our results and presents some of the several avenues available for further development of this work.
2 Background
In this section we first introduce our general notation for the learning problem. We review the Bayesian approach to learning and its limitations. We then explain how Bayesian coresets deal with the problem of scalability. Finally, we review alternative approaches to work around the computational challenges of Bayesian learning.
2.1 Notation
In the following, we will deal with standard supervised learning problems. We consider a data matrix  of dimension
of dimension  , containing
, containing  samples described by
samples described by  features; a sample
features; a sample  is a vector of dimension
is a vector of dimension  . We also assume we are given a label vector
. We also assume we are given a label vector  of dimension
of dimension  , such that for each sample
, such that for each sample  we have a label
we have a label  . Our aim is to learn a model mapping samples to labels:
. Our aim is to learn a model mapping samples to labels:  , where
, where  is a set of parameters defining the mapping function f.
is a set of parameters defining the mapping function f.
The standard approach of machine learning is to convert this learning problem in an optimization problem as a function of the parameters  . The optimal solution is found by computing the point estimate
. The optimal solution is found by computing the point estimate  of the parameters. For each input sample
of the parameters. For each input sample  we can then compute the output as
we can then compute the output as  . The result
. The result  (which can be interpreted probabilistically if calibrated [16]) is the output of the single model
(which can be interpreted probabilistically if calibrated [16]) is the output of the single model  on which we invested all our trust.
on which we invested all our trust.
2.2 Bayesian Machine Learning
In Bayesian machine learning we tackle the problem of supervised learning with the aim of computing a full distributional estimation  of the parameters
of the parameters  , instead of a point estimation. In this way, for each input sample
, instead of a point estimation. In this way, for each input sample  we can compute a distribution over the possible outputs
we can compute a distribution over the possible outputs  . This result represents the probability distribution of the output, computed considering all possible values of the parameters
. This result represents the probability distribution of the output, computed considering all possible values of the parameters  scaled by the trust assigned to them.
scaled by the trust assigned to them.
 of the parameters given the data using Bayes’ formula:
of the parameters given the data using Bayes’ formula:
 is the prior probability distribution over the parameters,
is the prior probability distribution over the parameters,  is the likelihood function of the data with respect to the parameters, and
is the likelihood function of the data with respect to the parameters, and  is the evidence.
is the evidence.Computing the posterior distribution is a challenging task that requires the evaluation of the product of likelihood function  and prior distribution
and prior distribution  , and the evaluation of the evidence integral. Monte Carlo Markov chain (MCMC) algorithms are a practical solution to this problem based on the idea of sampling from the posterior distribution [10]. The main drawback of this approach is the computational scalability as the complexity of sampling a posterior point grows linearly with the size of the data [3].
, and the evaluation of the evidence integral. Monte Carlo Markov chain (MCMC) algorithms are a practical solution to this problem based on the idea of sampling from the posterior distribution [10]. The main drawback of this approach is the computational scalability as the complexity of sampling a posterior point grows linearly with the size of the data [3].
2.3 Bayesian Coresets
 . Under the assumption of independent and identically distributed data, the likelihood for the whole data set
. Under the assumption of independent and identically distributed data, the likelihood for the whole data set  may be factorized in the product of the likelihoods of individual data points
may be factorized in the product of the likelihoods of individual data points  :
:

 such that the log-likelihood computed on
such that the log-likelihood computed on  approximates the log-likelihood computed on
approximates the log-likelihood computed on  :
:
 are samples belonging to the coreset and
are samples belonging to the coreset and  are the associated weights. The degree of approximation may be evaluated in terms of epsilon-distance between the original log-likelihood and the coreset likelihood:
are the associated weights. The degree of approximation may be evaluated in terms of epsilon-distance between the original log-likelihood and the coreset likelihood:
 , log-likelihoods
, log-likelihoods  or
or  become vectors of this space; consequently, the total likelihood over the whole data set
become vectors of this space; consequently, the total likelihood over the whole data set  or the coreset
or the coreset  can be expressed in terms of vector sum. Second, by taking as a norm of the space a bounded sup norm
can be expressed in terms of vector sum. Second, by taking as a norm of the space a bounded sup norm  , we can restate the constrained problem in Eq. 1 as a sparse quadratic minimization problem:
, we can restate the constrained problem in Eq. 1 as a sparse quadratic minimization problem:
![$$\begin{aligned}&{w}_{n} \ge 0&\\&\sum 1\left[ {w}_{n} > 0\right] \le M,&\end{aligned}$$](../images/496776_1_En_16_Chapter/496776_1_En_16_Chapter_TeX_Equ7.png)
![$$1\left[ c\right] $$](../images/496776_1_En_16_Chapter/496776_1_En_16_Chapter_TeX_IEq44.png) is the identity function that returns 1 if c holds or 0 otherwise, and M is a maximum number of coreset samples
is the identity function that returns 1 if c holds or 0 otherwise, and M is a maximum number of coreset samples  that we allow selecting. This fomalization turns the problem of constructing a coreset into an optimization problem aimed at finding the minimal set of samples
that we allow selecting. This fomalization turns the problem of constructing a coreset into an optimization problem aimed at finding the minimal set of samples  that approximates the log-likelihood on the data set. Finally, the structure of the Hilbert space allows us to exploit the directionality of the space in order to account for residual errors between
that approximates the log-likelihood on the data set. Finally, the structure of the Hilbert space allows us to exploit the directionality of the space in order to account for residual errors between  and
and  and to better select samples
and to better select samples  that would improve the approximation. Algorithms for coreset construction that exploit the properties of the Hilbert space include the coreset construction based on Frank-Wolfe algorithm [3] and the GIGA algorithm [4].
that would improve the approximation. Algorithms for coreset construction that exploit the properties of the Hilbert space include the coreset construction based on Frank-Wolfe algorithm [3] and the GIGA algorithm [4].Model Dependency of Bayesian Coresets. As it has been underlined by [5], it is important to remark that a coreset computed by a BCH algorithm is tightly connected to a specific family of models. Such a coreset does not constitute a generic weighted non-redundant distillation of the original data set; it is a subset of the original data optimized with respect to a specific family of models in order to produce a posterior distribution as close as possible to the one that we would learn from the original data set. In sum, a BCH is actually a tuple made up by a family of models and a weighted set of samples.
2.4 Alternative Approaches to BCH for Bayesian Learning
BCH is just one of the possible approaches to make Bayesian machine learning feasible on large data sets. Other approaches, which do not involve reducing the number of samples, include variational Bayes, parallel MCMC and approximate MCMC. Variational Bayes algorithms forgo the idea of using MCMC algorithms to perform inference, and rely instead on variational approximations of the posterior [2]. The variational approach allows learning in presence of large data sets, but the method does not provide guarantees on the degree of approximation of the uncertainty of the posterior [9]. Parallel MCMC algorithms rely on parallelization: large data sets are divided among multiple clusters; each cluster runs locally Bayesian inference via MCMC and produces a posterior distribution; finally, all the posteriors are aggregated by finding a unique posterior in the metric space of the posterior distributions [14, 18]. The parallel approach allows to deal with large data sets, but it still requires a high computational budget and does not address the problem of storing redundant data. Finally, approximate MCMC aims at speeding up existing algorithms by replacing costly transition in the Markov chain process with approximations [12]. Again, this approach is effective when we have to process large data sets, but it requires analyzing the execution of the MC algorithm, and, once again, it does not consider the problem of storing redundant data.
3 Network Security
Network security is one of the main challenges in the management of online systems. Network administrators try to monitor and prevent malicious activity through the deployment of intrusion detection systems, the collection of network traffic, and the analysis of this data [15]. Processing these data in a timely manner in order to detect suspicious activity as early as possible is a crucial problem. The ease with which large amount of data can be collected on a network poses severe scalability problems, both in terms of storage and in terms of processing [8]. Given this constraint, computationally-cheap algorithms, such as signature-matching, random forests and support vector machines, have been favored; for a review of pattern recognition and classical machine learning algorithms applied to network security, see, for instance, [8] and [7].
4 Experimental Setup
In this section we provide a formal description of our study by defining the exact learning problem we considered, by presenting the data sets and the transformations we applied to them, and, finally, by discussing the models we implemented.
Problem Definition. Given a large data set for network intrusion detection, we express our learning problem as a supervised learning problem in which we try to discover a function that maps network flows to an output defining whether a flow is malicious or not. More precisely, we try to infer an optimal set of parameters  that define the mapping function
that define the mapping function  . In a first static scenario, we process our data with and without BCH, running the simulations multiple times ad observing the contribution of the BCH algorithm. In a second scenario, we simulate the progressive collection of large chunks of data. All the data samples are taken to be independent and identically distributed. In this case, we observe what the contribution of BCH would be if we were to filter out data as soon as they are collected.
. In a first static scenario, we process our data with and without BCH, running the simulations multiple times ad observing the contribution of the BCH algorithm. In a second scenario, we simulate the progressive collection of large chunks of data. All the data samples are taken to be independent and identically distributed. In this case, we observe what the contribution of BCH would be if we were to filter out data as soon as they are collected.
Network Data Set. To run our experiments we use the network traffic data collected in the CICIDS2017 data set [17]. Processing real-world network data presents challenges from a privacy perspective; for this reason, the CICIDS2017 was collected running a simulated network designed to behave in a realistic fashion. Five days of simulated traffic were collected; during each day, different types of attacks and malicious behaviors were enacted. Network packets are gathered and aggregated in network flows. In total, the data set contains more than 2.5 million sample flows. Each sample is defined by a 78-dimensional vector reporting features such as packet flags and packet lengths (see [17] for a complete description of the data). Finally, a binary label has been assigned to each network flow, denoting whether a flow is legitimate or not. We restrict our attention to the second day, Tuesday5, which is made up by 445708 data samples, of which 13835 constitute instances of brute force attacks.
Network Data Preprocessing. The CICIDS2017 data set contains a very limited number of samples (201) with missing values for the day of Tuesday. Given their limited number we simply assume that they are missing completely at random [1] and we just drop them. Also, before each experiment we always standardize the data to zero mean and unit variance by feature. Standardization parameters are always computed exclusively on the training data being processed.
Data Set Subsampling. For the purpose of this preliminary study, we evaluate our algorithms only on limited subsets of the large CICIDS2017 data set. Studying smaller data sets guarantees some advantages: (i) it allows us to compare Bayesian learning on coresets with the “ground truth” of learning on the whole data sets, which would not be feasible if we were to consider the entire data set; (ii) manipulating the data set allows us to simulate scenarios in which we receive streaming data. While we plan to extend our evaluation to the full data set in order to assess the true potential of BCH for network intrusion detection, we were still able to get useful insights by studying its application on more modest-sized subsets of the original data set. Thus, from the large original pool of data, we programmatically create subsets by random sampling. In order to preserve the imbalance between positive and negative instances in the training data, we always select ten times as many positive samples as negative samples. The prototypical training data set  consists of 800 positive instances and 80 negative instances. For a test data set, instead, we selected an even number of positive and negative instances, thus simplifying the interpretation of the results. Our prototypical test data set
consists of 800 positive instances and 80 negative instances. For a test data set, instead, we selected an even number of positive and negative instances, thus simplifying the interpretation of the results. Our prototypical test data set  consists of 200 positive an 200 negative samples.
consists of 200 positive an 200 negative samples.
Sample Reduction techniques. Given a training data set  , in order to reduce the amount of data samples, we apply BCH using the GIGA algorithm [4]. This algorithm has two free hyper-parameters: (i) the number of random dimension on which to project the samples; and (ii) the number of computational iteration M, which implicitly limits the maximum number of coreset samples that can be selected.
, in order to reduce the amount of data samples, we apply BCH using the GIGA algorithm [4]. This algorithm has two free hyper-parameters: (i) the number of random dimension on which to project the samples; and (ii) the number of computational iteration M, which implicitly limits the maximum number of coreset samples that can be selected.
- 1.Bayesian logistic regression (BLR): a discriminative generalized-linear Bayesian machine learning algorithm [2]. We define our weighted BLR model as:where

 is a Gaussian prior, and the likelihood
is a Gaussian prior, and the likelihood  is the likelihood under a Bernoulli pdf
is the likelihood under a Bernoulli pdf  scaled by the weight
scaled by the weight  associated to the sample
associated to the sample  . If the data samples are not weighted, then
. If the data samples are not weighted, then  for all
for all  , and the model reduces to a standard BLR. Notice that, in general, if all the samples
, and the model reduces to a standard BLR. Notice that, in general, if all the samples  are scaled by a constant value
are scaled by a constant value  the inference process will not change6.
the inference process will not change6.Given a new sample
 , its probability of belonging to a class
, its probability of belonging to a class  can be obtained by integrating over all the models under the posterior:
can be obtained by integrating over all the models under the posterior: 
- 2.
Support Vector Machine (SVM): as a baseline and comparison, we consider support vector machine, a linear maximum-margin discriminator [6]. We train a SVM model to find the slope
 of a discriminating hyper-plane between samples7.
of a discriminating hyper-plane between samples7.Given a new samples
 , its class is computed as
, its class is computed as  , where
, where  is the sign function,
is the sign function,  if
if  , 0 otherwise.
, 0 otherwise.
5 Simulation 1: BCH Applied to Network Intrusion Detection Data
In this simulation we analyze the use of BCH applied to network intrusion detection data. We evaluate the contribution they provide both from the point of view of the performance they achieve and the time-space they save. We compare these results to the baseline offered by SVM and by a BLR computed over the whole data set.
Protocol. We generate five subsets of training data  and test data
and test data  ,
,  , using the methodology presented in Sect. 4.
, using the methodology presented in Sect. 4.
We apply BCH to each training data set  . We set the free hyper-parameters of BCH as follows: (i) we fix the number of random dimension to 500, following the experimental evaluation in [3]; (ii) we consider three values for the number of computational iteration M, that is
. We set the free hyper-parameters of BCH as follows: (i) we fix the number of random dimension to 500, following the experimental evaluation in [3]; (ii) we consider three values for the number of computational iteration M, that is  , following again the evaluation in [3],
, following again the evaluation in [3],  , and an aggressively lower value of
, and an aggressively lower value of  , which is expected to guarantee a higher saving in terms of space and time.
, which is expected to guarantee a higher saving in terms of space and time.
For each subset i, we train and test an SVM model, a BLR model trained on the whole data set  , and a BLR model trained on the coreset computed from the training data
, and a BLR model trained on the coreset computed from the training data  .8 The SVM model is trained with default parameters from the scikit9 library. The BLR models are trained using the Hamiltonian Monte Carlo algorithm offered in the Edward library with the following settings: sampling 10000 points, using a burn-in period of half of the samples, thinning every second sample, and adjusting the step size manually to guarantee an acceptance rate around 0.8. When doing prediction, we use 1000 posterior samples. We repeat each training and testing 10 times and we average the results.
.8 The SVM model is trained with default parameters from the scikit9 library. The BLR models are trained using the Hamiltonian Monte Carlo algorithm offered in the Edward library with the following settings: sampling 10000 points, using a burn-in period of half of the samples, thinning every second sample, and adjusting the step size manually to guarantee an acceptance rate around 0.8. When doing prediction, we use 1000 posterior samples. We repeat each training and testing 10 times and we average the results.
We evaluate the results in terms of classification accuracy and wall-clock time required for the training of the model (all the models are run on a non-dedicated mid-range laptop machine with no GPU support).
 , to one third, when using a high
, to one third, when using a high  .
.Coresets computed on each training data set  . The table reports the number of data points selected to the left of the slash (/), and the number of these points belonging to the minority class to the right of the slash (/). The last column reports average and standard deviation of the wallclock time to compute the coresets.
. The table reports the number of data points selected to the left of the slash (/), and the number of these points belonging to the minority class to the right of the slash (/). The last column reports average and standard deviation of the wallclock time to compute the coresets.
Hyper-parameter |
|
|
|
|
| Time(s) |
|---|---|---|---|---|---|---|
| 84/1 | 82/3 | 82/1 | 88/1 | 87/3 |
|
| 184/4 | 191/10 | 186/7 | 189/9 | 200/10 |
|
| 259/5 | 270/15 | 239/4 | 252/8 | 252/6 |
|











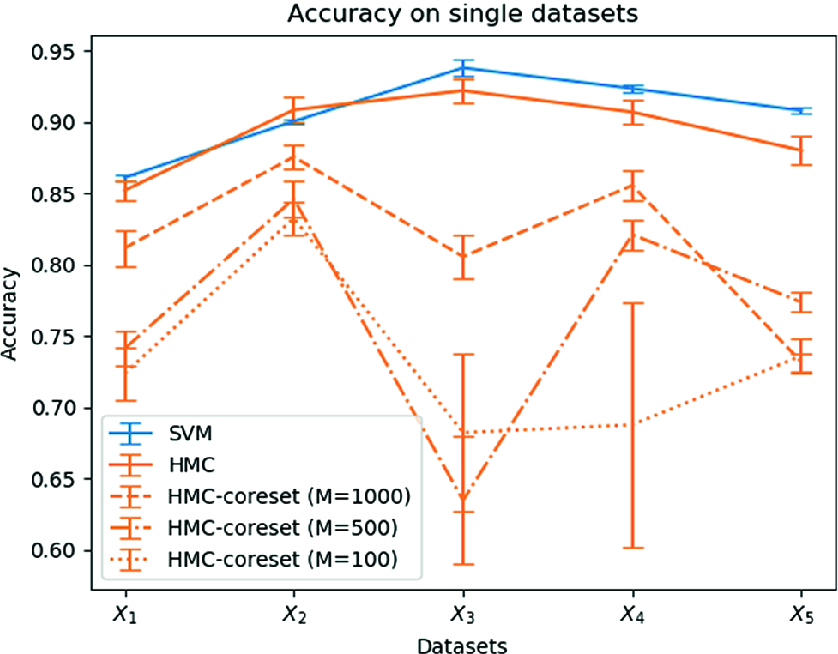
Mean and standard deviation of accuracy of the models on each data set  .
.
 took the shortest time, which may be due to the particularly good sub-selection of points, or, more likely, to other contingent processes running on the same machine.
took the shortest time, which may be due to the particularly good sub-selection of points, or, more likely, to other contingent processes running on the same machine.
Mean and standard deviation of wall-clock time required for training the models on each data set  . Notice the different y-scale for SVM on the left side, and the BLR model on the right side.
. Notice the different y-scale for SVM on the left side, and the BLR model on the right side.
Discussion. These basic experiments highlight that the time-space savings offered by BCH inevitably come at the cost of the accuracy of the final model. The number of iterations M provides a key hyper-parameter to manage such a trade-off, as it exchanges the dimension of the data set for the accuracy of the model.
Notice that from these experiments, the time saving offered by coresets does not appear particularly remarkable. It is worth, though, to underline that such an improvement is relevant when related to the small data sets we are processing. The time savings when using larger data set are discussed in detail in [3].
Interestingly, the computation of coresets has a subsampling effect with respect to the minority class, as shown in Table 1: while in the original data set the ratio between the two classes was set to 1:10, this ratio has sensibly decreased. This may seem undesirable if we were expecting BCH to produce a more balanced data set; in reality, though, the algorithm selects only samples useful for a proper reconstruction of the likelihood function, and the result seems to suggest that the instances of malicious behaviours may actually be quite redundant, probably due to the fact that we are considering only one specific form of attack (brute force).
6 Simulation 2: BCH in a Streaming Environment
In this simulation we try to setup a more interesting and realistic scenario. We simulate the collection of batches of data in real-time and we learn from the cumulative set of collected samples. The aim is to evaluate how the learning process would be affected if the sets of collected data were to be downsized using BCH before being processed and stored. Such a scenario seems particularly interesting because BCH would immediately discard redundant data, thus solving at once the problem of making Bayesian inference feasible and reducing the required amount of memory and storage space.
Protocol. As before, we generate five subsets of training data  and test data
and test data  ,
,  . Now, however, instead of processing each data set independently, we simulate the arrival of a data set
. Now, however, instead of processing each data set independently, we simulate the arrival of a data set  at time steps
at time steps  . At each time step
. At each time step  , we want to learn from all the collected data sets and so we pool together all the data
, we want to learn from all the collected data sets and so we pool together all the data  , for
, for  . Notice that all the samples are independent and identically distributed.
. Notice that all the samples are independent and identically distributed.
When using coresets, we apply BCH to each training data set  as soon as it is collected. At each time step
as soon as it is collected. At each time step  , instead of aggregating together all the previously collected data, we just aggregate the coresets. This operation is theoretically justified by the possibility of aggregating coreset computed in parallel [3]. We use the same hyper-parameters for BCH used in the previous simulation.
, instead of aggregating together all the previously collected data, we just aggregate the coresets. This operation is theoretically justified by the possibility of aggregating coreset computed in parallel [3]. We use the same hyper-parameters for BCH used in the previous simulation.
We also run the same models as before, and we repeat each simulation 10 times.
Results. We work with the same coresets computed in the previous simulation and we refer back the reader to Table 1 for their details.
 ) are consistent with the values computed in the previous experiments and shown in Fig. 1. When we start aggregating more data sets, we notice that the performance of SVM and HMC on the whole data set is only slightly improved; on the other hand, the performance of BLR on coresets shows a consistent improvement. Even aggregating only two coresets (
) are consistent with the values computed in the previous experiments and shown in Fig. 1. When we start aggregating more data sets, we notice that the performance of SVM and HMC on the whole data set is only slightly improved; on the other hand, the performance of BLR on coresets shows a consistent improvement. Even aggregating only two coresets ( ) the performance gap between BLR on coresets and SVM or BLR on the whole data set is significantly reduced. This improvement is expected when aggregating two coresets computed with the hyper-parameter
) the performance gap between BLR on coresets and SVM or BLR on the whole data set is significantly reduced. This improvement is expected when aggregating two coresets computed with the hyper-parameter  ; in this case, the final amount of selected data points would be close to the amount obtained computing a single coreset with the hyper-parameter
; in this case, the final amount of selected data points would be close to the amount obtained computing a single coreset with the hyper-parameter  ; and we know from the previous simulations that the performance of BLR trained on a coreset computed with the hyper-parameter
; and we know from the previous simulations that the performance of BLR trained on a coreset computed with the hyper-parameter  is very close to the performance of BLR on the whole data set. More surprising is the improvement registered by aggregating only two coresets computed with hyper-parameter
is very close to the performance of BLR on the whole data set. More surprising is the improvement registered by aggregating only two coresets computed with hyper-parameter  .
.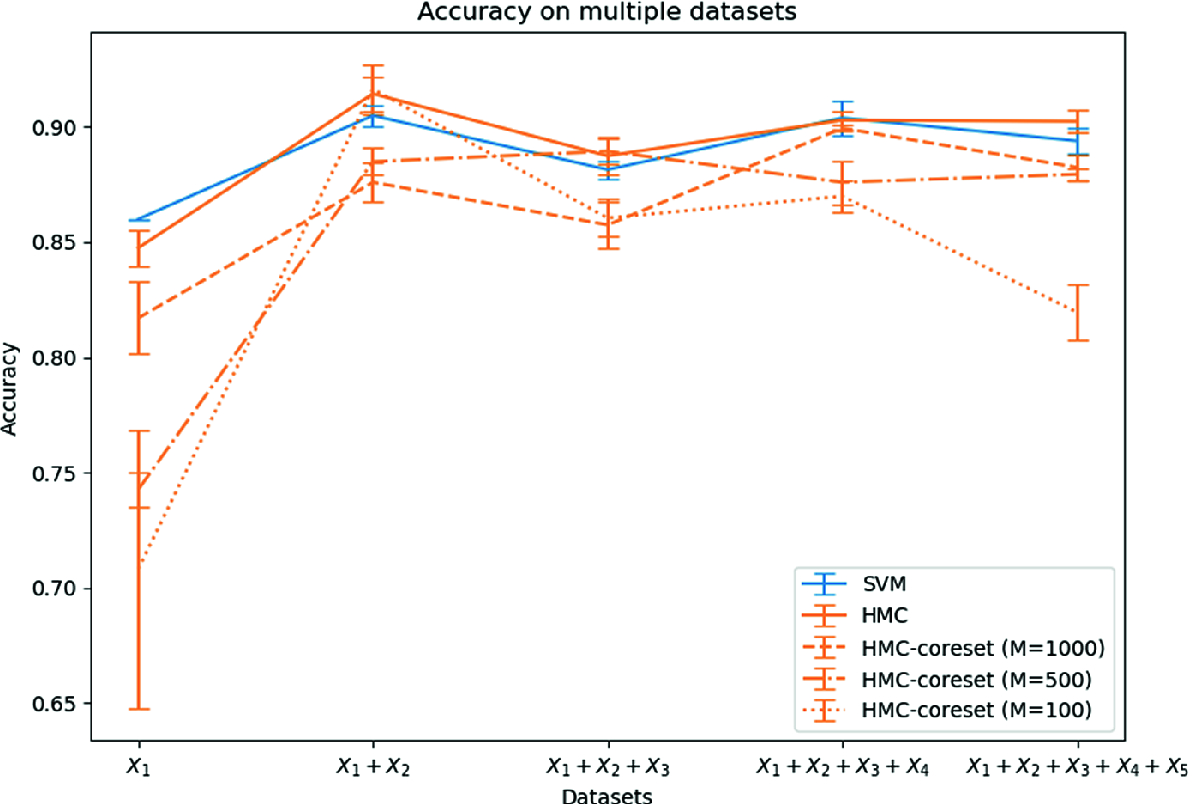
Mean and standard deviation of accuracy of the models on each data set  .
.
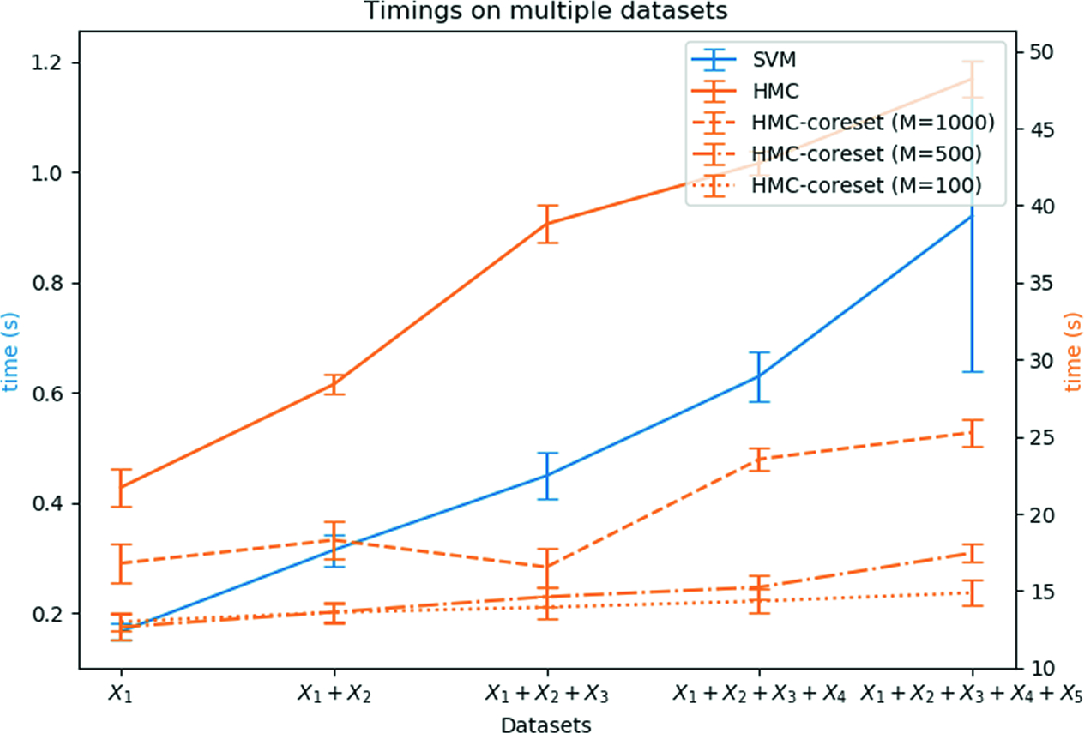
Wall-clock time required for training the models on each data set  . Notice the different y-scale for SVM on the left side, and the BLR model on the right side.
. Notice the different y-scale for SVM on the left side, and the BLR model on the right side.
Discussion. This simulation showed the potential advantages that could be obtained by deploying BCH in a streaming scenario. In such an instance, the aggregation of two or more coresets can provide a performance very close to SVM or BLR trained on the whole data. One of the most significant advantages, though, is that BCH reduces the amount of data in real-time before learning, thus limiting the amount of memory necessary for processing; guaranteeing a sub-linear growth in the time required for learning as more data are gathered may prove especially advantageous when data is collected in real-world environments in which batches of data are generated continuously over multiple timesteps
7 Conclusion and Future Work
This preliminary study showed the feasibility of applying BCH to network data. Network intrusion detection could take great advantage by employing fully probabilistic descriptions of network traffic, and BCH may prove to be an enabler for such an approach. Moreover, we showed that the same algorithm is also effective in reducing the number of samples to be stored; this issue is particularly relevant when collecting network packets, as the amount of data may quickly grow and cause severe challenges in their management.
Our experiments first confirmed the concrete trade-off between model accuracy and time-space saving when adopting BCH. More interestingly, we also investigated how BCH may be deployed in a dynamic streaming environment in which data samples would be filtered in real-time before processing. This last scenario returned particularly good and interesting results, showing that BCH can be effectively used to sub-select relevant data samples at different time steps and aggregate together only the coresets. We demonstrated that in a streaming scenario the use of BCH may guarantee a better scalability by ensuring that the computational time for learning grows in a strongly sub-linear fashion.
Of course this study is just a preliminary evaluation of the potential of BCH applied to the challenging problem of processing the large data sets for network security. Further investigation is clearly necessary to assess more precisely the role that BCH may serve. Immediate directions of further study that we consider are the following: applying our protocol to bigger and more realistic data sets; include other typologies of attacks; compare BCH to other data reduction techniques, such as random sampling or k-means. More interesting questions concern also the recursive application of BCH in a streaming scenario and its effectiveness when used to process streaming data that do not conform to the assumption of independent and identically distributed data anymore.