1 Introduction
In the era of social media and networking platforms, Twitter has been doomed for abuse and harassment toward users specifically women. In fact, online harassment becomes very common in Twitter and there have been a lot of critics that Twitter has become the platform for many racists, misogynists and hate groups which can express themselves openly. Online harassment is usually in the form of verbal or graphical formats and is considered harassment, because it is neither invited nor has the consent of the receipt. Monitoring the contents including sexism and sexual harassment in traditional media is easier than monitoring on the online social media platforms like Twitter. The main reason is because of the large amount of user generated content in these media. So, the research about the automated detection of content containing sexual harassment is an important issue and could be the basis for removing that content or flagging it for human evaluation. The basic goal of this automatic classification is that it will significantly improve the process of detecting these types of hate speech on social media by reducing the time and effort required by human beings.
Previous studies have been focused on collecting data about sexism and racism in very broad terms or have proposed two categories of sexism as benevolent or hostile sexism [1], which undermines other types of online harassment. However, there is no much study focusing on different types online harassment alone attracting natural language processing techniques.
In this paper we present our work, which is a part of the SociaL Media And Harassment Competition of the ECML PKDD 2019 Conference. The topic of the competition is the classification of different types of harassment and it is divided in two tasks. The first one is the classification of the tweets in harassment and non-harassment categories, while the second one is the classification in specific harassment categories like indirect harassment, physical and sexual harassment as well. We are using the dataset of the competition, which includes text from tweets having the aforementioned categories. Our approach is based on the Recurrent Neural Networks and particularly we are using a deep, classification specific attention mechanism. Moreover, we present a comparison between different variations of this attention-based approach like multi-attention and single attention models. The next Section includes a short description of the related work, while the third Section includes a description of the dataset. After that, we describe our methodology. Finally, we describe the experiments and we present the results and our conclusion.
2 Related Work
Waseem et al. [2] were the first who collected hateful tweets and categorized them into being sexist, racist or neither. However, they did not provide specific definitions for each category. Jha and Mamidi [1] focused on just sexist tweets and proposed two categories of hostile and benevolent sexism. However, these categories were general as they ignored other types of sexism happening in social media. Sharifirad and Matwin [3] proposed complimentary categories of sexist language inspired from social science work. They categorized the sexist tweets into the categories of indirect harassment, information threat, sexual harassment and physical harassment. In the next year the same authors proposed [4] a more comprehensive categorization of online harassment in social media e.g. twitter into the following categories, indirect harassment, information threat, sexual harassment, physical harassment and not sexist.
Class distribution of the dataset.
Dataset | Tweets | Harassment | Harassment (%) | Indirect (%) | Sexual (%) | Physical (%) |
|---|---|---|---|---|---|---|
Train | 6374 | 2713 | 42.56 | 0.86 | 40.50 | 1.19 |
Validation | 2125 | 632 | 29.74 | 3.34 | 24.76 | 1.69 |
Test | 2123 | 611 | 28.78 | 9.28 | 14.69 | 4.71 |
3 Dataset Description
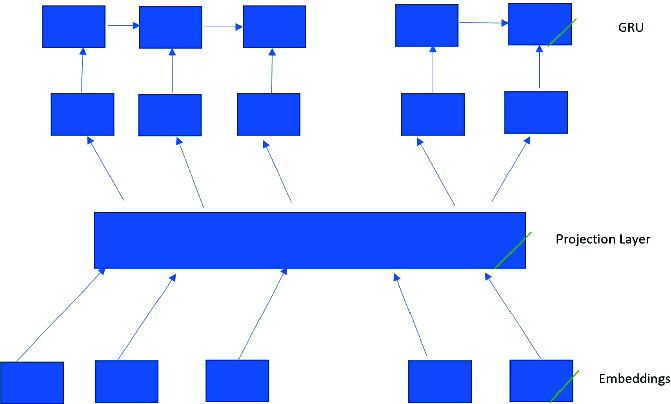
Projection layer
4 Proposed Methodology
4.1 Data Augmentation
As described before one crucial issue that we are trying to tackle in this work is that the given dataset is imbalanced. Particularly, there are only a few instances from indirect and physical harassment categories respectively in the train set, while there are much more in the validation and test sets for these categories. To tackle this issue we applying a back-translation method [16], where we translate indirect and physical harassment tweets of the train set from english to german, french and greek. After that, we translate them back to english in order to achieve data augmentation. These “noisy” data that have been translated back, increase the number of indirect and physical harassment tweets and boost significantly the performance of our models.
Another way to enrich our models is the use of pre-trained word embeddings from 2B Twitter data [17] having 27B tokens, for the initialization of the embedding layer.
4.2 Text Processing
Before training our models we are processing the given tweets using a tweet pre-processor1. The scope here is the cleaning and tokenization of the dataset.
4.3 RNN Model and Attention Mechanism
 of each tweet to the hidden states
of each tweet to the hidden states  , followed by an LR Layer that uses
, followed by an LR Layer that uses  to classify the tweet as harassment or non-harassment (similarly for the other categories). Given the vocabulary V and a matrix E
to classify the tweet as harassment or non-harassment (similarly for the other categories). Given the vocabulary V and a matrix E 
 containing d-dimensional word embeddings, an initial
containing d-dimensional word embeddings, an initial  and a tweet
and a tweet  , the RNN computes
, the RNN computes  , with
, with  , as follows:
, as follows: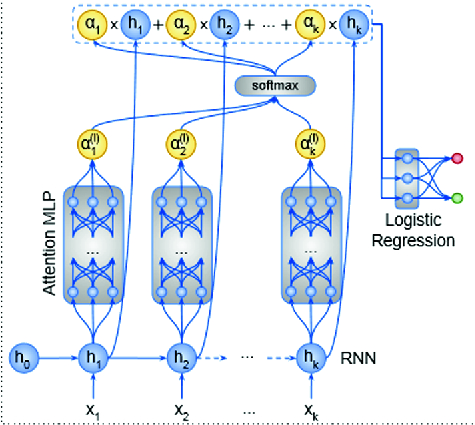
Attention mechanism, MLP with l layers

 is the proposed hidden state at position t, obtained using the word embedding
is the proposed hidden state at position t, obtained using the word embedding  of token
of token  and the previous hidden state
and the previous hidden state  ,
,  represents the element-wise multiplication,
represents the element-wise multiplication,  is the reset gate,
is the reset gate,  is the update gate,
is the update gate,  is the sigmoid function. Also
is the sigmoid function. Also  and
and  ,
,  . After the computation of state
. After the computation of state  the LR Layer estimates the probability that tweet w should be considered as harassment, with
the LR Layer estimates the probability that tweet w should be considered as harassment, with  :
:
 of all the hidden states instead of
of all the hidden states instead of  :
:
 through an MLP with k layers and then the LR layer will estimate the corresponding probability. More formally,
through an MLP with k layers and then the LR layer will estimate the corresponding probability. More formally,
 is the state that comes out from the MLP. The weights
is the state that comes out from the MLP. The weights  are produced by an attention mechanism presented in [10] (see Fig. 2), which is an MLP with l layers. This attention mechanism differs from most previous ones [19, 20], because it is used in a classification setting, where there is no previously generated output sub-sequence to drive the attention. It assigns larger weights
are produced by an attention mechanism presented in [10] (see Fig. 2), which is an MLP with l layers. This attention mechanism differs from most previous ones [19, 20], because it is used in a classification setting, where there is no previously generated output sub-sequence to drive the attention. It assigns larger weights  to hidden states
to hidden states  corresponding to positions, where there is more evidence that the tweet should be harassment (or any other specific type of harassment) or not. In our work we are using four attention mechanisms instead of one that is presented in [10]. Particularly, we are using one attention mechanism per category. Another element that differentiates our approach from Pavlopoulos et al. [10] is that we are using a projection layer for the word embeddings (see Fig. 1). In the next subsection we describe the Model Architecture of our approach.
corresponding to positions, where there is more evidence that the tweet should be harassment (or any other specific type of harassment) or not. In our work we are using four attention mechanisms instead of one that is presented in [10]. Particularly, we are using one attention mechanism per category. Another element that differentiates our approach from Pavlopoulos et al. [10] is that we are using a projection layer for the word embeddings (see Fig. 1). In the next subsection we describe the Model Architecture of our approach.4.4 Model Architecture
The Embedding Layer is initialized using pre-trained word embeddings of dimension 200 from Twitter data that have been described in a previous sub-section. After the Embedding Layer, we are applying a Spatial Dropout Layer, which drops a certain percentage of dimensions from each word vector in the training sample. The role of Dropout is to improve generalization performance by preventing activations from becoming strongly correlated [13]. Spatial Dropout, which has been proposed in [12], is an alternative way to use dropout with convolutional neural networks as it is able to dropout entire feature maps from the convolutional layer which are then not used during pooling. After that, the word embeddings are passing through a one-layer MLP, which has tanh as activation function and 128 hidden units, in order to project them in the vector space of our problem considering that they have been pre-trained using text that has a different subject. In the next step the embeddings are fed in a unidirectional GRU having 1 Stacked Layer and size 128. We prefer GRU than LSTM, because it is more efficient computationally. Also the basic advantage of LSTM which is the ability to keep in memory large text documents, does not hold here, because tweets supposed to be not too large text documents. The output states of the GRU are passing through four self-attentions like the one described above [10], because we are using one attention per category (see Fig. 2). Finally, a one-layer MLP having 128 nodes and ReLU as activation function computes the final score for each category. At this final stage we have avoided using a softmax function to decide the harassment type considering that the tweet is a harassment, otherwise we had to train our models taking into account only the harassment tweets and this might have been a problem as the dataset is not large enough.
5 Experiments
5.1 Training Models
The results considering F1 Score.
Model | sexual_f1 | indirect_f1 | physical_f1 | harassment_f1 | f1_macro |
|---|---|---|---|---|---|
attentionRNN | 0.674975 | 0.296320 | 0.087764 | 0.709539 | 0.442150 |
MultiAttentionRNN | 0.693460 | 0.325338 | 0.145369 | 0.700354 | 0.466130 |
MultiProjectedAttentionRNN | 0.714094 | 0.355600 | 0.126848 | 0.686694 | 0.470809 |
ProjectedAttentionRNN | 0.692316 | 0.315336 | 0.019372 | 0.694082 | 0.430276 |
AvgRNN | 0.637822 | 0.175182 | 0.125596 | 0.688122 | 0.40668 |
LastStateRNN | 0.699117 | 0.258402 | 0.117258 | 0.710071 | 0.446212 |
ProjectedAvgRNN | 0.655676 | 0.270162 | 0.155946 | 0.675745 | 0.439382 |
ProjectedLastStateRNN | 0.696184 | 0.334655 | 0.072691 | 0.707994 | 0.452881 |
Batch size which pertains to the amount of training samples to consider at a time for updating our network weights, is set to 32, because our dataset is not large and small batches might help to generalize better. Also, we set other hyperparameters as: epochs = 20, patience = 10. As early stopping criterion we choose the average AUC, because our dataset is imbalanced.

![$$\begin{aligned} BCE = -\frac{1}{n}\sum _{i=1}^{n}[y_{i}log(y^{'}_{i}) + (1 - y_{i})log(1 - y^{'}_{i}))] \end{aligned}$$](../images/496776_1_En_26_Chapter/496776_1_En_26_Chapter_TeX_Equ6.png)
 is the predicted probability. In the loss function we have applied equal weight to both tasks. However, in the second task (type of harassment classification) we have applied higher weight in the categories that it is harder to predict due to the problem of the class imbalance between the training, validation and test sets respectively.
is the predicted probability. In the loss function we have applied equal weight to both tasks. However, in the second task (type of harassment classification) we have applied higher weight in the categories that it is harder to predict due to the problem of the class imbalance between the training, validation and test sets respectively.5.2 Evaluation and Results
Each model produces four scores and each score is the probability that a tweet includes harassment language, indirect, physical and sexual harassment language respectively. For any tweet, we first check the score of the harassment language and if it is less than a specified threshold, then the harassment label is zero, so the other three labels are zero as well. If it is greater than or equal to that threshold, then the harassment label is one and the type of harassment is the one among these three having that has the greatest score (highest probability). We set this threshold equal to 0.33.
We compare eight different models in our experiments. Four of them have a Projected Layer (see Fig. 1), while the others do not have, and this is the only difference between these two groups of our models. So, we actually include four models in our experiments (having a projected layer or not). Firstly, LastStateRNN is the classic RNN model, where the last state passes through an MLP and then the LR Layer estimates the corresponding probability. In contrast, in the AvgRNN model we consider the average vector of all states that come out of the cells. The AttentionRNN model is the one that it has been presented in [10]. Moreover, we introduce the MultiAttentionRNN model for the harassment language detection, which instead of one attention, it includes four attentions, one for each category.
We have evaluated our models considering the F1 Score, which is the harmonic mean of precision and recall. We have run ten times the experiment for each model and considered the average F1 Score. The results are mentioned in Table 2. Considering F1 Macro the models that include the multi-attention mechanism outperform the others and particularly the one with the Projected Layer has the highest performance. In three out of four pairs of models, the ones with the Projected Layer achieved better performance, so in most cases the addition of the Projected Layer had a significant enhancement.
6 Conclusion - Future Work
We present an attention-based approach for the detection of harassment language in tweets and the detection of different types of harassment as well. Our approach is based on the Recurrent Neural Networks and particularly we are using a deep, classification specific attention mechanism. Moreover, we present a comparison between different variations of this attention-based approach and a few baseline methods. According to the results of our experiments and considering the F1 Score, the multi-attention method having a projected layer, achieved the highest performance. Also, we tackled the problem of the imbalance between the training, validation and test sets performing the technique of back-translation.
In the future, we would like to perform more experiments with this dataset applying different models using BERT [22]. Also, we would like to apply the models presented in this work, in other datasets about hate speech in social media.