1 Introduction
The need for describing and understanding the behavior of a given phenomenon over time led to the emergence of new techniques and methods focused in temporal evolution of data and models [2, 6, 13]. Data mining techniques and methods that enable to monitor models and patterns over time, compare them, detect and describe changes, and quantify them on their interestingness are encompassed by the paradigm of change mining [5]. The two main challenges of this paradigm are to be able to adapt models to changes in data distribution but also to analyze and understand changes themselves.
Evolving clustering models are referred to incremental or dynamic clustering methods, because they can process data step-wise and update and evolve cluster partitions in incremental learning steps [6, 10]. Incremental (sequential) clustering methods process one data element at a time and maintain a good solution by either adding each new element to an existing cluster or placing it in a new singleton cluster while two existing clusters are merged into one [1, 7, 17]. Dynamic clustering is also a form of online/incremental unsupervised learning. However, it considers not only incrementality of the methods to build the clustering model, but also self-adaptation of the built model. In that way, incrementality deals with the problem of model re-training over time and memory constrains, while dynamic aspects (e.g., data behavior, clustering structure) of the model to be learned can be captured via adaptation of the current model. Lughofer proposes an interesting dynamic clustering algorithm which is also dedicated to incremental clustering of data streams and in addition, it is equipped with dynamic split-and-merge operations [10]. A similar approach defining a set of splitting and merging action conditions is introduced in [8]. Wang et al. also propose a split-merge-evolve algorithm for clustering data into k number of clusters [16]. However, a k cluster output is always provided by the algorithm, i.e. it is not sensitive to the evolution of the data. A split-merge evolutionary clustering algorithm which is robust to evolving scenarios is introduced in [4]. The algorithm is designed to update the existing clustering solutions based on the data characteristics of newly arriving data by either splitting or merging existing clusters. Notice that all these algorithms have the ability to optimize the clustering result in scenarios where new data samples may be added in to existing clusters.
In this paper, we propose a sequential (dynamic) partitioning algorithm that is robust to modeling the evolution of clusters over time. In comparison with the above discussed dynamic clustering algorithms it does not update existing clustering, but groups distinct portions (snapshot) of streaming data so that a clustering model is generated on each data portion. The algorithm initially produces a clustering solution on available historical data. A clustering model is generated on each new data snapshot by applying a partitioning algorithm initialized with the centroids of the clustering solution built on the previous data snapshot. In addition, model adapting operations are performed at each step of the algorithm in order to capture the clusters’ evolution. Hence, it tackles both incremental and dynamic aspects of modeling evolving behavior problems. The algorithm also enables to trace back evolution through the identification of clusters’ transitions such as splits and merges. We have studied and initially evaluated our algorithm on household electricity consumption data. The results have shown that it is robust to modeling evolving data behavior.
2 Modeling Evolving User Behavior via Sequential Clustering
2.1 Sequential Partitioning Algorithm
In this section, we formally describe the proposed sequential partitioning algorithm. The algorithm idea is schematically illustrated in Fig. 1.
 are distinct snapshots of a data stream. Further let
are distinct snapshots of a data stream. Further let  be a set of clustering solutions (models), such that
be a set of clustering solutions (models), such that  has been built on a data set
has been built on a data set  . In addition, each clustering solution
. In addition, each clustering solution  , for
, for  , is generated by applying a partitioning algorithm (see Sect. 2.2) on data set
, is generated by applying a partitioning algorithm (see Sect. 2.2) on data set  initialized (seeded) with the centroids of the clustering model built on data set
initialized (seeded) with the centroids of the clustering model built on data set  . The algorithm is initialized by clustering
. The algorithm is initialized by clustering  which is extracted from data set
which is extracted from data set  (available historical data or the initial snapshot).
(available historical data or the initial snapshot).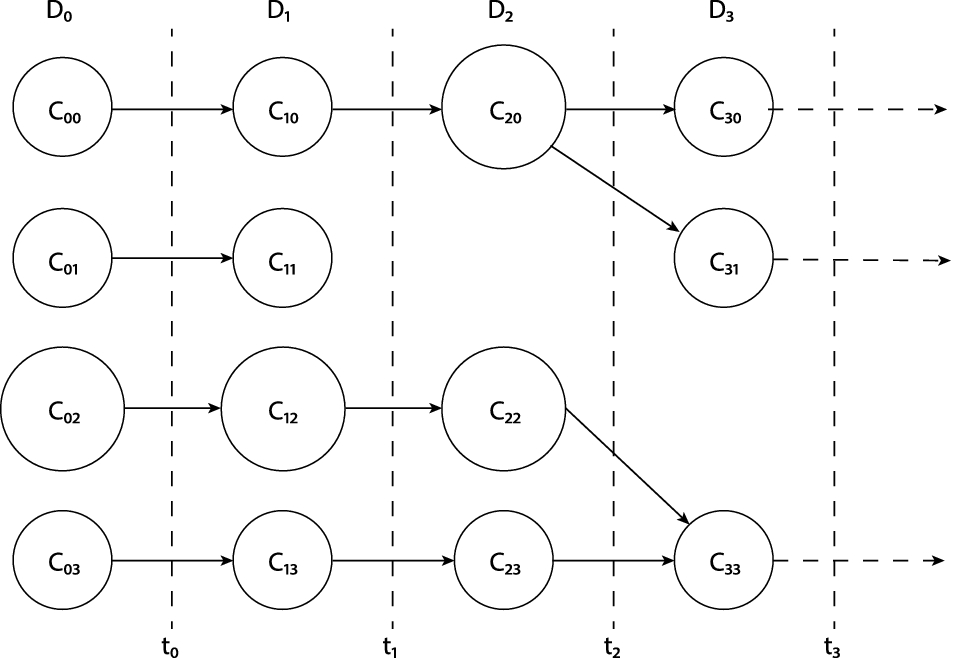
Schematic illustration of the proposed sequential clustering approach
- 1.
Input: Cluster centroids of partition
 (
( ).
). - 2.
Clustering step: Cluster data set
 by seeding the partitioning algorithm with the centroids of
by seeding the partitioning algorithm with the centroids of  .
.- (a)
Initial clustering of
 .
. - (b)
Check for empty initial clusters and adapt the partitioning respectively.
- (c)
Remove the seeded centroids and finalize the clustering by producing
 .
.
- (a)
- 3.Adapting step: For each cluster
 do the following steps
do the following steps - (a)
Calculate the split condition for
 .
. - (b)
If the split condition is satisfied then split
 into two clusters by applying 2-medoids clustering algorithm and update the list of centroids, respectively.
into two clusters by applying 2-medoids clustering algorithm and update the list of centroids, respectively.
- (a)
- 4.
Output: Updated clustering partition and list of centroids used to initialize the clustering action that will be conducted on data set
 .
.
Note that at step 2(b) above we check whether there are empty clusters after the initial clustering. If so, this means that the clustering structure is evolving, i.e. some clusters may stop existing while others are merged together. Evidently, the death and merge transitions are part of the clustering step. Therefore the split condition is only checked at step 31. We can apply different split conditions. For example, the homogeneity of each cluster  may be evaluated and if it is below a given threshold we will perform splitting. Another possibility is to apply the idea implemented by Lughofer [10] in his dynamic split-and-merge algorithm.
may be evaluated and if it is below a given threshold we will perform splitting. Another possibility is to apply the idea implemented by Lughofer [10] in his dynamic split-and-merge algorithm.
In order to trace back the clusters’ evolution we can compare the sets of cluster centroids of each pair of partitioning solutions extracted from the corresponding neighboring time intervals (e.g., see Fig. 6). This comparison can be performed by applying some alignment technique, e.g., such as Dynamic Time Warping (DTW) algorithm explained in Sect. 2.3. For example, if we consider two consecutive clustering solutions  and
and  (
( ), we can easily recognize two scenarios: (i) a centroid of
), we can easily recognize two scenarios: (i) a centroid of  is aligned to two or more centroids of
is aligned to two or more centroids of  then the corresponding cluster from
then the corresponding cluster from  splits among the aligned ones from
splits among the aligned ones from  ; (ii) a few centroids of
; (ii) a few centroids of  is aligned to a centroid of
is aligned to a centroid of  then the corresponding clusters from
then the corresponding clusters from  merge into the aligned cluster from
merge into the aligned cluster from  .
.
2.2 Partitioning Algorithms

Initial clustering model produced on the historical data.
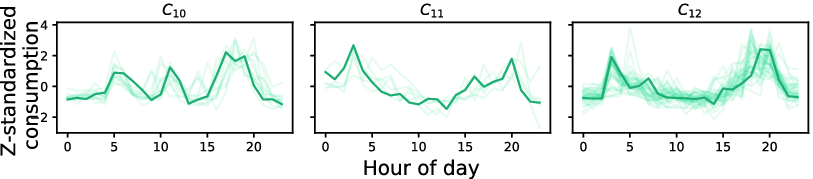
Clustering model produced on the first new data snapshot. Clusters  and
and  have been empty after the clustering step. Clusters
have been empty after the clustering step. Clusters  and
and  are transformed in clusters
are transformed in clusters  and
and  , respectively.
, respectively.
2.3 Dynamic Time Warping Algorithm
The DTW alignment algorithm aims at aligning two sequences of feature vectors by warping the time axis iteratively until an optimal match (according to a suitable metrics) between the two sequences is found [15]. Let us consider two matrices ![$$A = [a_1,\ldots , a_n]$$](../images/496776_1_En_2_Chapter/496776_1_En_2_Chapter_TeX_IEq39.png) and
and ![$$B = [b_1,\ldots , b_m]$$](../images/496776_1_En_2_Chapter/496776_1_En_2_Chapter_TeX_IEq40.png) with
with  (
( ) and
) and  (
( ) column vectors of the same dimension. The two vector sequences
) column vectors of the same dimension. The two vector sequences ![$$[a_1,\ldots , a_n]$$](../images/496776_1_En_2_Chapter/496776_1_En_2_Chapter_TeX_IEq45.png) and
and ![$$[b_1,\ldots , b_m]$$](../images/496776_1_En_2_Chapter/496776_1_En_2_Chapter_TeX_IEq46.png) can be aligned against each other by arranging them on the sides of a grid, e.g., one on the top and the other on the left hand side. A distance measure, comparing the corresponding elements of the two sequences, can then be placed inside each cell. To find the best match or alignment between these two sequences one needs to find a path through the grid
can be aligned against each other by arranging them on the sides of a grid, e.g., one on the top and the other on the left hand side. A distance measure, comparing the corresponding elements of the two sequences, can then be placed inside each cell. To find the best match or alignment between these two sequences one needs to find a path through the grid  , (
, ( and
and  ), which minimizes the total distance between A and B.
), which minimizes the total distance between A and B.
3 Case Study: Modeling Household Electricity Consumption Behavior
3.1 Case Description

Clustering models produced on the second (above) and third (below) new data snapshots, respectively.
3.2 Data and Experiments
We use electricity consumption data collected from a single randomly selected anonymous household that has been collected with a 1-min interval for a period of 14 months. During those 14 months, there were roughly 2 months worth of data that had not been collected, i.e. zero values which have been removed. We then aggregate the electricity consumption data into a one hour resolution from the one minute resolution.
We divide the data into four parts. The first 50% of the total data represent the historical data ( ), and the remaining data is evenly distributed into the other three data sets (
), and the remaining data is evenly distributed into the other three data sets ( ,
,  and
and  ). In addition,
). In addition,  and
and  have their contents shifted to simulate a change in their behavior over time. 8% of the contents in
have their contents shifted to simulate a change in their behavior over time. 8% of the contents in  is randomly shifted 1 to 6 h ahead, and 2% of the contents 12 h ahead. Similarly,
is randomly shifted 1 to 6 h ahead, and 2% of the contents 12 h ahead. Similarly,  has 16% of the data shifted 1 to 6 h ahead and 4% 12 h ahead. We choose these two scenarios to simulate both minor and drastic changes in the sleeping pattern of the resident.
has 16% of the data shifted 1 to 6 h ahead and 4% 12 h ahead. We choose these two scenarios to simulate both minor and drastic changes in the sleeping pattern of the resident.
Distances between the clustering models generated on the first and second new data snapshots (left), and on the second and third new data snapshots (right), respectively.

3.3 Results and Discussion
 and
and  are the biggest clusters and represent the electricity consumption behavior more typical for working days with clearly recognized morning and evening consumption peaks. Clusters
are the biggest clusters and represent the electricity consumption behavior more typical for working days with clearly recognized morning and evening consumption peaks. Clusters  and
and  are smaller and have an additional consumption peak in the middle of the day, i.e. they model behavior more typical for the weekends. Cluster
are smaller and have an additional consumption peak in the middle of the day, i.e. they model behavior more typical for the weekends. Cluster  is comparatively big and represents electricity consumption behavior typical for working days with a slightly later start.
is comparatively big and represents electricity consumption behavior typical for working days with a slightly later start.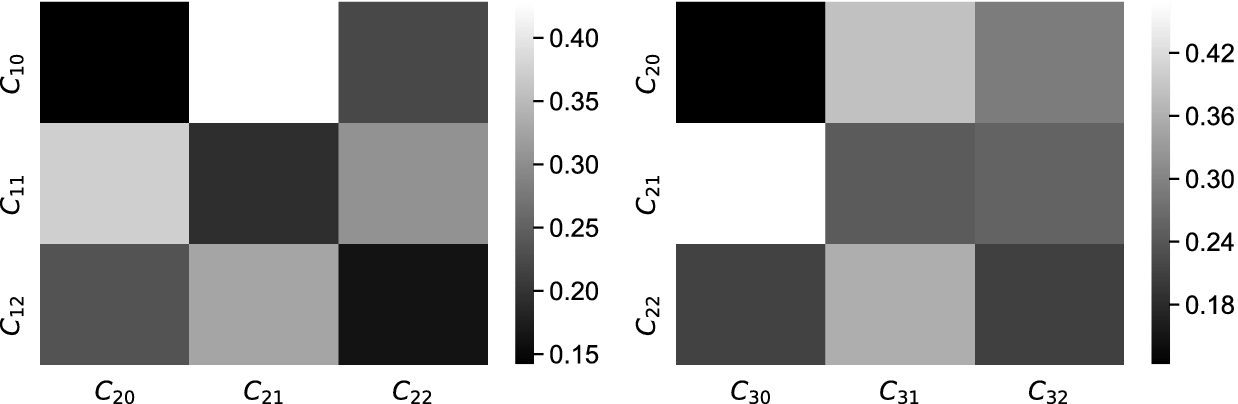
Heatmaps for distances between the clustering models generated on the first and second new data snapshots (left), and on the second and third new data snapshots (right), respectively.
Figure 3 depicts the clustering model derived from the first new data snapshot. As we can notice the electricity consumption behavior is modeled only by three clusters.  and
and  have been empty after the initial clustering step and their medoids are removed from the list of medoids. Clusters
have been empty after the initial clustering step and their medoids are removed from the list of medoids. Clusters  and
and  are transformed into clusters
are transformed into clusters  and
and  , respectively. It is interesting to observe that
, respectively. It is interesting to observe that  is also very similar to cluster profile
is also very similar to cluster profile  . The latter observation is also supported by the DTW alignment between the medoids of the two clustering models given in Fig. 6, where
. The latter observation is also supported by the DTW alignment between the medoids of the two clustering models given in Fig. 6, where  and
and  are aligned to
are aligned to  , i.e. they are merged into one cluster. This is also the case for
, i.e. they are merged into one cluster. This is also the case for  and
and  , which are replaced by cluster
, which are replaced by cluster  at the first time interval.
at the first time interval.
 evolves its shape over these two time intervals. For example, it moves far from
evolves its shape over these two time intervals. For example, it moves far from  and gets closer to
and gets closer to  at the third time window (see Table 1). These observations are also supported by the heatmaps plotted in Fig. 5. One can observe that the respective cells in the heatmap plotted in Fig. 5 (right) have changed their color in comparison with the heatmap in Fig. 5 (left).
at the third time window (see Table 1). These observations are also supported by the heatmaps plotted in Fig. 5. One can observe that the respective cells in the heatmap plotted in Fig. 5 (right) have changed their color in comparison with the heatmap in Fig. 5 (left).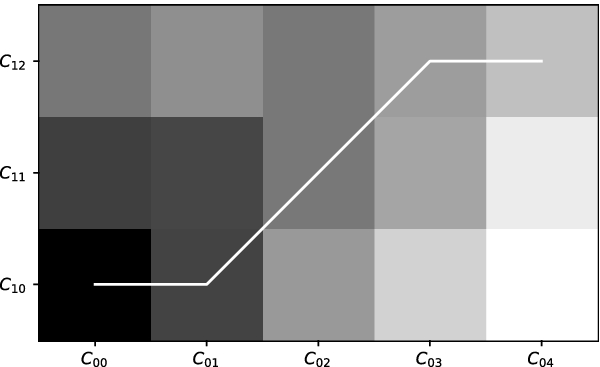
DTW alignment path between the clustering models generated on the historical and first new snapshot data, respectively.
We can trace the evolution of the clusters at each step of our algorithm by comparing the sets of cluster centroids of each pair of clusterings extracted from the corresponding consecutive time intervals. This is demonstrated in Fig. 6 which plots the DTW alignment path between the clustering models generated on the historical and first new data sets, respectively. This comparison can be performed on any pair of clustering models generated on the studied data sets. It is also possible to trace back the evolution of a given final cluster down to the initial clustering model.
4 Conclusions and Future Work
In this paper, we have proposed a sequential partitioning algorithm that groups distinct snapshots of streaming data so that a clustering model is generated on each data snapshot. It enables to deal with both incremental and dynamic aspects of modeling evolving behavior problems. In addition, the proposed approach is able to trace back evolution through the detection of clusters’ transitions. We have initially evaluated our algorithm on household electricity consumption data. The obtained results have shown that it is robust to modeling evolving data behavior by being enable to mine changes and adapt the model, respectively.
For future work, we aim to further study and evaluate the proposed clustering algorithm on evolving data phenomena in different application domains.