5
Your New Raw Materials
Data Is Better than Oil
Each industrial revolution was catalyzed by a new raw material: coal, steel, oil, electricity. This time around, data is the primary raw material.
In this revolution, the organizations that are winning know precisely how Engine T17BBI is performing during Flight V26 from New York to London. They know how a potential 0.5% interest rate increase in New Zealand will impact a California state government–issued zero-coupon bond before lunchtime. They know how a kid is performing in today's lesson on differential calculus. How do they know? Because they have the data.
Like oil, data needs to be “mined,” “refined,” and “distributed.” But unlike oil, data is a multifaceted, curious commodity. It is a potentially infinite resource—opaque, ephemeral, at times intangible. It can grow quickly in scale and value, but it can also be worthless, even a burden, if it's not viewed through the right lens and managed in the right way. Today's leaders need to understand how to take this commodity, which is available to each and every one of us, and turn it into a competitive advantage. After all, harnessing the new machines without abundant data is akin to owning a fleet of tractor-trailer trucks without any access to gas.
The data we are talking about is currently under your nose, capable of being mined from your own daily business operations. For example, per our reference to Flight V26, a typical Airbus A350 has approximately 6,000 sensors across the entire plane, generating 2.5 terabytes of data per day.1 And a terabyte? That's one trillion bytes, or a million million bytes. (And, yes, it's true that the word “tera” is derived from the Greek word for “monster.”)
So how big is this monster data? Let's put it this way: The complete works of Shakespeare, in basic text and stored on your computer, would consume approximately five megabytes.2 Given that a gigabyte is 1,024 megabytes, and a terabyte is another 1,024 gigabytes, it means the average A350 is producing the equivalent of 524,000 times the Bard's life's work every 24 hours. We know, you may be thinking, “What could Airbus and its airline customers possibly do with all that data? Isn't it much ado about nothing?” (Sorry, too easy.) Sometimes it is. Many organizations often don't know what to do with such data. Sometimes it's just static, and sometimes it becomes a liability. Yet in the next decade, the breakout companies will be those that become masters in consistently turning this abundant data into actionable, and proprietary, insight.
Turning Data from a Liability into an Asset
In recent years, the phrase “data is the new oil” has become something of a cliché. But like many clichés, the phrase holds an important truth. Let's unpack what it really means.
Imagine yourself in a city in the UK sometime during the 1850s—a world grimly described by Charles Dickens. The Second Industrial Revolution was well underway, and a lot of it wasn't very pretty. It was a time before child labor laws. The buildings were covered with soot. The streets were full of horses and the products of hundreds of thousands of equine digestive tracts. Many countries were in political upheaval (or worse). Unless, m'lord, you were at the very top of the economic food chain, life could be pretty tough and confusing.
Coal and steam still powered the economy. Oil was primarily used for lighting, waterproofing, and other incidental purposes. People knew about oil, and they did have uses for it, but nobody really saw it as the fuel for the full blaze of the Third Industrial Revolution. At that time, oil seeped through the ground or was found by miners going after coal. Oil was still seen almost as a problem—brown sticky “muck” getting in the way of mining out the coal.
In 1847, a Scottish chemist named James Young reconceptualized the understanding of oil. Having come across a natural oil seepage at a mine in Derbyshire, he applied a distillation process to efficiently convert the “muck” into something completely different and more useful—refined oil. In the years and decades that followed, more and more ideas of how to use the new commodity emerged, and the seeds were sown for the incredible boom of the oil industry, as well as every derivative industry that followed during the next 100 years.
Today, many of the hundreds of business decision makers we work with are struggling with a similar reconceptualization of their data. We have yet to come across anyone who says, “We have complete control of all our data, fully understand its value, and are hungry for more. Bring it on!” On the contrary, we hear lament after lament about the cost, complexity, and unrealized value they feel is locked in a morass of structured and unstructured data. If you ask almost any business leader of a major industrial enterprise, they'll say they see their data more as muck than as oil.
These sentiments are well captured by renowned business and technology consultant Geoffrey Moore (author of Crossing the Chasm, among many other highly influential books), who stated that “[data] is a liability before it's an asset.”3
Yet, by contrast, the management teams of today's digital leaders are “data-first,” focused not on product or process, but on their new raw material. Their data isn't “muck”—it's the lifeblood of the new machine, the fuel that moves it forward. In sticking with our oil metaphor, data is superior to oil as a raw material in several ways as shown in Figure 5.1.
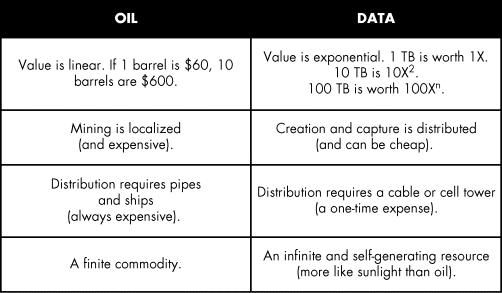
Figure 5.1 Properties of Oil vs. Data
Managing the Data Supply Chain
Turning data into actionable insight will occur not by accident but by establishing and managing a “data supply chain” across the business. This also has parallels to today's energy industry.
Oil companies are organized around three key activities: exploration and extraction, refining, and distribution; these are commonly referred to as upstream, midstream, and downstream. Oil executives have long recognized that all three of these areas are quite distinct and require different skill sets, technologies, and business-model approaches. Very few executives responsible for handling data have put in place a similar clearly delineated approach. They should. Figure 5.2 outlines this comparative concept further.

Figure 5.2 The Supply Chains of Oil vs. Data
There are several important ways in which data is far superior to oil:
- Cheap to “mine”: As the world becomes increasingly instrumented, it becomes easier and easier to create and capture data. Once you instrument an MRI machine, for example, the cost of data over time drops to nearly nothing. This is in contrast with oil. If you drill one big well, the second one isn't much cheaper.
- Infinite and shared: There have been warnings about “peak oil” (i.e., running out of it) from almost the moment James Young started selling people on the idea of its value. To this day, no one really knows how much oil there is, but it is certain that we aren't getting any more, and without technology advancing, it's becoming harder to access.4 Data, your new raw material, isn't found deep in the ground somewhere on the other side of the world. Instead, it's under your feet and under your nose right now; you just have to grab it. And unlike coal or oil, which are “zero-sum,” data and insight actually increase in value the more you use them. After all, adding one drop of oil to another simply yields two drops. However, combining one piece of data from your operations with another from a customer or a business partner could yield huge benefits.
- Proprietary in nature: Oil is, by definition, a commodity. What is produced in Alaska, Nigeria, or Saudi Arabia is essentially the same—and is valued as such on the open market. Your data, on the other hand, is proprietary. It's unique, and it trades, if you will, in a closed market. If managed properly, this provides it with immense value. Such proprietary data, at scale, is the moat that exists around the franchises of Google, Facebook, and Uber; in the coming years, your proprietary data will become the competitive moat around your business. As a bank, it's how you will assess risk in ways your competitors cannot. As an insurer, it will be how you revolutionize the actuarial science. As a health care provider, it will be how you fundamentally transform patient outcomes and reset your cost base.
- Cheap to distribute: The Trans-Alaska Pipeline System cost about $8 billion to build; its owners continually wrestle with the huge maintenance costs. Access to data is really expensive initially—building and maintaining cellular networks is neither free nor cheap—but the value of the information being shipped (movies, music, car telematics data, robo-journalism articles, cat pictures) can increase enormously without a corresponding increase in distribution costs. Moving 75,000 barrels of oil an hour takes a pipeline of a certain size; no compression algorithm or switch upgrade can condense that volume.
- Exponentially valuable: The value of oil is like that of any other commodity. The price of a barrel is set by the market, and each barrel at any time costs about the same. It's a linear relationship between value and volume. Data, however, conforms to a different model. It follows more of an exponential curve. A little bit of the right data might be worth something, but perhaps not much. Once there's enough data to draw more valuable conclusions, though, the value of the data set increases exponentially. Netflix wouldn't know much about us if only 10 people used it. Google wouldn't work either without billions of searches. The real value of code is that once you have enough data, the value goes through the roof.
This three-pronged approach—upstream, midstream, and downstream—is a useful way of thinking about organizing your technology, staffing, and approach to building your own new machine.
Business Analytics: Turning Data into Meaning
In time, we believe the structure we have described of harvesting, refining, and distributing data will become a universal practice. Data harvesting will become standardized and, thus, “table stakes.” By 2020, Ford will not seize any advantage over Chevrolet by instrumenting the car's carburetor. Similarly, the distribution of information via apps and embedded systems will become a commodity. After all, the success of Google vs. Bing or Amazon vs. Walmart.com has almost nothing to do with the distribution and interface, because in each case they are largely the same. However, the middle step, the refining of data or turning it into meaning, will be the key competitive battleground. This is where competitive distinction can be created and maintained. This is where you and your teams will need to convert the data into insight and apply that insight via new commercial models; and this is where business analytics comes into the frame.
Business analytics can be defined as the tools, techniques, goals, analytics, processes, and business strategies used to transform data into actionable insights for business problem solving and competitive advantage.5 In our research at Cognizant's Center for the Future of Work, we have determined that a company that harnesses value from data better than its competitors can enjoy an average cost decrease of about 8.1% and an average revenue increase of about 8.4%.6
Before you can order your analysts to analyze, though, you need to give them something to analyze; this is where turning everything—really everything—into a “code generator” comes into the picture.
If It Costs More than $5, and You Can't Eat It, Instrument It!
Smartphone vs. dumb phone. Remember the dumb phone? The black or beige block of plastic with a rotary dial that sat in your parents' living room? OK, sometime in the 1980s, it gained a punch-dial keypad, but it was still dumb, completely incapable of storing numbers, tracking calls, or anything like that.
Why do we bring up vintage phones? Well, the way we view the dumb phone now is how we will view today's walls, desks, glasses, shoes, cars, toothbrushes, forks, houses, fridges, elevators, doors, trains, televisions, pacemakers, hearing aids, credit cards, ticket booths, lights, sports stadiums, plane seats, restaurants, factories, roads, subways, offices, museums, and so on by 2025. Dumb. Amazed that they couldn't adapt to our needs in real time and that they couldn't help us in our tasks, providing new insight and context, in real-time. As such, we are on the verge of the smart-product transformation.
At the heart of this transformation is the instrumentation of everything; as sensors have become miniaturized and their price/performance curve has become “Moore-ish,” it has become possible, technologically and economically, to put them into smaller and smaller objects.7 Not just possible but imperative. After all, to know everything about everything, you need to instrument everything. The strategic question shouldn't be “What should we instrument?” but rather “What shouldn't we instrument?” as not instrumenting something should be the exception, not the norm. And, in doing so, not only will you begin the process of harvesting all the data in your organization, but you will also greatly increase the intrinsic value of the very objects you are instrumenting.
Table for Two? Or Two Thousand?
Take this one simple example: a non-sensor-enabled table that costs $150 to make might retail at around $500. A sensor-enabled table that costs $200 to make could potentially retail at $1,000. Consider a “smart” table that could adjust its height automatically for different users (the way a car seat does), charge electronic devices with no need for charging cables, allow someone to type or draw on it directly and then project those commands onto a digital whiteboard, display the name of the person sitting at the table, or track whether someone was sitting at it (or not) and adjust surrounding heating and lighting conditions accordingly. Any of these possible scenarios would be hugely more valuable to purchasers. For a relatively modest increase in manufacturing cost, an incredible opportunity for increasing revenue and profitability would be unleashed. And then, think through the “stickiness” of the smart table. A dumb table can be swapped out for another with no problem. However, doing the same with the smart table would result in a sudden removal of the personalization that surrounds it. The lights in the room wouldn't work the same, for example, or the digital whiteboard would sit dark. The history of that worker's preferences would be lost. Suddenly, that table becomes very “sticky” for its users.
If you take this one mundane example of something “dumb” becoming “smart” and extrapolate it into the “universe of things,” the impact of instrumentation becomes more and more profound. This is how and why GE is making its industrial windmills “smart”; this is how and why Bosch and Samsung are making their consumer white goods (i.e., fridges and ovens) “smart.” It's also why there's an explosion of activity around the idea of instrumenting people. Let's face it; at times we're pretty “dumb” too. Instrumenting us will help us get smarter about a lot of important things, like our health, as well.
The Home-Field Advantage of Big Companies
So if every “thing” needs to be instrumented, the question is raised: Who has most of these “things?” The answer: the typical 100-year-old company.
The Silicon Valley elite and the software unicorns8 don't have these assets that are soon to be transformed from dumb to smart. It's the hospital that has the beds, the operating rooms, and the intensive care units, all waiting to be instrumented. It's also the hospital that has the patients in its care, all needing to be tracked. This is not the case for some faraway, venture-backed software start-up.
We find too many traditional companies saying they feel insecure in the burgeoning digital economy, claiming they are burdened with inherent disadvantages (in legacy systems and processes, cost structures, physical assets, facilities, culture, etc.). This may be so. But they also come armed with a fundamental and massive advantage: they now own all the new data generators, the “things” of their operations, and their customers. This is an advantage not to be relinquished, and it must be protected through an instrumentation imperative.
This jujitsu move of taking a seeming disadvantage and using it as an advantage can serve as an example to all “pre-digital” companies looking to retool. The truly digital economy, full of Know-It-All businesses, could, in fact, be the era of “the revenge of the 100-year-old firm.” American Express, for example, has a stockpile of data in a closed-loop system, as issuer, underwriter, and processor from customer transactions going back decades. Airlines, banks, and insurance companies (some around since Madison was president of the United States) all have valuable data ready to be extracted and refined.
That's the good news, but a significant threat still looms. One advantage that oil has over data is that it is timeless. The oil in the ground today is largely the same as it was 100 years ago, which is the same as it will be in 50 years. Though its value will fluctuate wildly due to the commercial battles fought by petro-states around the world, the oil itself won't change. However, the advantage of data-rich traditional companies is highly perishable. If this sounds a bit too dramatic, well then, just look around. The taxi business has been around for centuries, but Uber is now pooling massive amounts of data from the assets owned by others—us, its drivers, Google Maps, and so on. This data is integrated through Uber's platform, and now it is applying its new model not just to taxis but also to a host of other products and services (flu shots, puppies, food, yachts, helicopters, and much more to come).9 Using the new raw material, Uber is playing the new game for a new commercial era.
Clever innovators are already figuring out how to grab decades' worth of data seemingly overnight. Leaders will either act to capture this data and value now, or be faced with a “sorry, and thanks for playing” result.
Data Is Job One
For the three of us in our consulting travels, we have a one-question litmus test to determine a company's digital readiness: Is the management team we're working with obsessive about data or not? We sometimes think of it as the “data point test,” as in “How do we know they are serious about digital? Because they always go where the data points.”
Those who are making true progress toward “being digital” have increasing faith in data; they recognize it as their source for proprietary insight and advantage, and for good reason. In our recent study of over 2,000 companies across the globe with a combined revenue of $7.3 trillion,10 the executives surveyed estimated that fully a third of their industry revenues—$20 trillion—would soon be touched by digital.11 That's a lot of people, things, and events acting as code generators. That's a lot of insight—$20 trillion worth.
This is truly becoming an age of knowing it all. Yet, without the right business model to support your data-fueled new machines, you won't get very far. So, let's now explore the third of the Three M's, the digital business model.