Grapes and Chemistry
The story of wine starts with stardust. And on any matter that embraces both stardust and wine we trust only one source: our oenophile friend and colleague, the astrophysicist Neil deGrasse Tyson. We asked Neil to choose a wine with an astrophysical name and theme, and he immediately came up with Astralis, the designation given by Australia’s Clarendon Hills vineyards to its flagship Syrah. The grapes come from vines that look as old as the universe: so ancient, huge, and gnarly that they grow individually like trees, without any trellising. And the wine itself? We asked Neil. “Big,” he said. “Bold. Beautiful. Radiant to the senses. Just like the stars themselves.”
How do crushed grapes turn into wine? To explain this process we must go back to the very beginning—to atoms and molecules, the building blocks of both wine and the universe. The first and simplest atom, hydrogen, was formed from the strewn stardust that eventually made up the galaxies, stars, and planets. Thereafter, other elements began to combine, and the scene was set for our modern universe to evolve with all it contains. Neil deGrasse Tyson once declared, with his usual eloquence, that we are all, both figuratively and literally, made of stardust. And if this is true of humans, then it is true of wine as well.
A great metaphor for the cosmic origin of wine showed up some years ago when the astrophysicist Benjamin Zuckerman and collaborators discovered that a dense molecular cloud lying near the center of the Milky Way galaxy, to which our solar system belongs, contains alcohol. Hailed by Tyson in a Natural History article as the “Milky Way Bar,” it would actually be a bit of a disappointment as an earthly drinking establishment because the water molecules in the cloud vastly outnumber the alcohol molecules. In fact, as Tyson points out, in combination they would yield a libation of only about 0.001 proof. But out in the galactic vastness the cloud itself is so huge that, with sufficient distillation, its alcohol molecules could provide something “on the order of 100 octillion liters of 200-proof hooch.”
Nearly every culture recorded has figured out a way to turn sugary concoctions into alcohol. Early brewers and winemakers had no knowledge of atoms and molecules, acids and bases, hydrogen bonds and electron orbits. Yet they were expert protochemists, controlling and tweaking one of the simplest, yet most important chemical reactions to human existence—the transformation of sugar into alcohol. Although our ancestors achieved the basics of the chemistry through trial and error, without understanding what was happening at the molecular level, today such an understanding can help the wine drinker appreciate why a wine is bitter or acidic, why the alcohol content of wine rarely exceeds 15 percent, why wine takes as long as it does to ferment, and why it should be stored with care.
Let’s start with the scale of the molecular realm in which the chemical reactions of fermentation occur, which are vastly different from those of the Milky Way. Atoms such as hydrogen and small molecules such as water and sugar are minuscule. The glass from which you are drinking your Chianti might be about 10 centimeters tall and 5 centimeters in diameter, and weigh about 30 grams. In contrast, a typical atom, the basic unit of which molecules are composed, is between 25 and 200 picometers (pm) in size. (A picometer is .000000000001 meters, and is thus about 0.0000000001 times smaller than the height of your wine glass.) If you stacked these atoms atop one another it would take 100 billion of them to reach the rim! Water molecules are 2.5 angstroms (Å) in diameter. (An angstrom, another measure of size, is 0.00000001 meters.) So a water molecule is about 0.0000005 the diameter of a glass of wine, which is some 50 million molecules wide. A molecule of sugar, the major component of grape mash, weighs 180 times 0.0000000000000000000001 grams. So a single molecule of sugar composes about 0.00000000000000000002 of the weight of the wine in your glass. In other words, you would need a million trillion molecules of sugar to achieve the weight of the wine in your glass. Fermentation involves the interaction of molecules, but the scale at which those interactions occur is obviously too small for the human mind to visualize directly, and the conversion of a mere gram of sugar into alcohol requires that trillions of reactions happen in a very tiny space.

It is important to understand the atomic structures of alcohol, sugar, and other molecules because their compositions and shapes determine their natures and those of the interactions among them. Scientists have by now a sophisticated picture of what atoms are, but for the purpose of understanding wine we can imagine them as simple orbital structures consisting of a nucleus of clustered protons and neutrons with electrons spinning around the periphery. The orbits of the electrons around the nucleus can be really complex, and they make the physics of atoms pretty weird. But here we need only note what happens when a stable atom—that is, an atom with the same number of electrons as protons—loses or gains an electron. This loss or gain happens continually; indeed, if it didn’t, probably nothing in the universe would have become more complex than an atom, and wine—and wine drinkers—would not exist. Electrons are able to do their in-and-out atomic hokey-pokey because nothing is protecting them from outside forces, or even from their own eccentricity, as they orbit around the nucleus.
When a lone electron joins with a stable atom, it produces an imbalance in the number of protons and electrons. Specifically, there will be more electrons than protons, and the atom will be negatively charged (have a charge of −1). Conversely, when a lone electron skips out of its orbit, the resulting atom is positively charged (has a charge of +1). The ultimate accountant here is the universe, which likes to keep the ledger in balance. Of course, any individual atom that has lost an electron can capture a new one, just as any electron-heavy atom can kick one out. But often the stability the universe desires is achieved by combining two different kinds of atoms with opposite charges. This interaction is the currency of higher molecular structure, and it is known as a chemical bond. In the case of a lost or gained electron, we have an “ionic bond,” but other kinds of chemical bonds also exist, and are important in combining smaller molecules to form larger and more biologically important structures such as DNA and proteins.
Fortunately we can simplify at this point because, of the 115 elements in the periodic table, only a few are relevant to the biology of wine. And of those, only a handful of larger molecules are present in the wine we drink, because living creatures incorporate a limited number of elements. Indeed, animals contain only six major elements: carbon (C), hydrogen (H), nitrogen (N), oxygen (O), phosphorus (P), and sulfur (S). Most students nowadays remember this by using the mnemonic CHNOPS, although a more precise alternative would be OCHNPS, which lists the elements in the order of their abundance in animal bodies.
For the yeasts used in winemaking, the appropriate order would be the even clumsier OCHNClPS. This is because, although the elemental makeup of yeasts is about 99.9 percent the same as that of animals, yeasts also contain chlorine (Cl)—in relatively high abundance. For plants such as grapevines the situation is more complicated still, and the mnemonic (as it were) would be OCHNKSiCaMgPS. The new elements in plants are silicon (Si), calcium (Ca), magnesium (Mg), and potassium (K). This string of abbreviations may not be easy to memorize, but it is important because there are several more basic elements in plants than there are in animals, or even in yeast. Still, humans, yeasts, and plants all have the first four elements (OCHN) in common, and P and S are also in there somewhere. Significantly, OCHNPS are the basic constituents of amino acids, the molecules that make up proteins, and of the bases that make up DNA, to which we’ll return in a minute.
Why humans are made up of OCHNPS, and not six other atoms, can be answered in one word—evolution. Early in the life of our planet, natural selection honed the interactions and shapes of molecules. At the start, the evolution of life could have gone in any of several directions. Molecules, for instance, have handedness—they coil either to the left or to the right. In the illustration depicting two amino acid molecules with the same atomic makeup, each has the same number of carbons, hydrogens, oxygens, and nitrogens, yet the two will behave differently because one is left-handed and the other right-handed. In your imagination, try to turn the right-handed one around to get the left-handed one. You can’t do it; if you tried to get a chemical reaction to work with right-handed molecules where left-handed ones should be used, you’d fail. Most of the molecules important to life on earth have evolved to be left-handed, for no better reason than that events early in the evolution of molecules dictated a general trend for all the molecules. And so it is with our six atoms and alcohol.
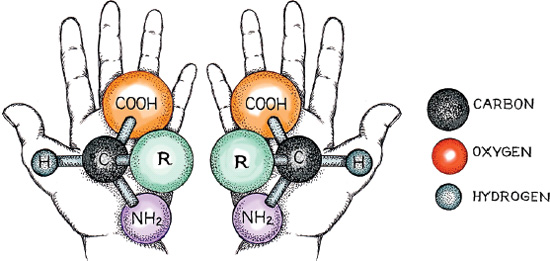
Typical structure of an amino acid (where R stands for any side group of the 20 amino acids), showing both the left-handed and the right-handed version
Energy is an important commodity for cells, and fermentation, the process that makes alcohols, is a fairly efficient way to produce it. In primitive cells, the need for energy probably dictated the honing of the fermentation process. But why fermentation persisted and won out in these primitive cells was more or less a matter of chance. In brief, evolution is a master tinkerer. So if the very primitive process of fermentation had ever been supplanted by a better mechanism, we might not have alcohol at all.
There are many ways in which the various elements we’ve been discussing can bind to one another, and it is this diversity that makes our world so complex, for it is the shape and spatial orientation of a molecule that largely dictates its behavior under various circumstances.
Let’s take a closer look at one of the most basic of those elements: oxygen. This is the most abundant element on the surface of our planet, and it is incorporated into the bodies of all of earth’s living beings because they are almost entirely made up of water, which contains oxygen in a ratio of 1:2 with hydrogen. Another major molecule in the atmosphere is carbon dioxide, in which oxygen is found in a ratio of 2:1 with carbon. Water forms as a stable combination of the three atoms that constitute each of its molecules: two hydrogen atoms and one of oxygen. The bond here is not the ionic type that entails charged particles, but rather involves making “mutual loans” of electrons.
In Oxygen: The Molecule That Made the World, Nick Lane emphasizes that life on Earth is dependent on two basic processes involving oxygen—namely, respiration and photosynthesis. It is not too much to claim that the entire “economy” of life on our planet is based on how these two processes move electrons around. Photosynthesis, in which organisms take up carbon dioxide and water and convert them to oxygen and energy, is unique to plants, algae, and some very small organisms such as the Cyanobacteria. Respiration, which sustains life in all living organisms, involves converting atmospheric oxygen to energy, water, and carbon dioxide.
Chemists love equations, and to understand fully what makes up wine it is necessary at least to tolerate them. Deciphering a chemical equation might seem a bit like reading the Rosetta Stone, but with a few rules in hand it becomes quite simple. One way to write a chemical equation describing a molecule is simply to list the symbol of each atom in the molecule, with a subscript giving the number of times it occurs. So carbon dioxide, which has one carbon and two oxygens, is written as CO2. But although this way of describing molecules tells us what atoms are present, it does not indicate how they are arranged or the shape of the molecule. And knowing this is critical to understanding a molecule’s function. To add spatial information, chemists use “stick notation,” which resembles the stick figures used in the game Hangman. Each atom has a typical number of sticks protruding from it. Thus hydrogen (for the most part) has only a single stick, while oxygen typically has two sticks, and carbon has four. The number of sticks protruding from a particular atom is dictated both by its atomic number and by the orbits of its electrons, and in stick notation carbon dioxide looks like this:
O=C=O
But the page on which this stick diagram is drawn is flat, and molecules exist in space, with a three-dimensional structure. So we need to discriminate between carbon dioxide’s bookkeeping format above, and its natural (stick-and-ball) form as illustrated in the figure. In this case, the three-dimensional structure of carbon dioxide is similar to its bookkeeping structure. But in many other molecules the angles at which atoms are connected to one another are not as clear. This is important to biologists because, at the molecular level where fermentation occurs, nature likes shapes. It doesn’t necessarily care what makes up the shapes, taking its cues from the molecules’ external form. So now, with these tools of scale and chemical equations in hand, let’s follow how a carbon atom in a grape is transformed into alcohol.
The natural (stick-and-ball) structure of carbon dioxide
So far it’s been pretty straightforward, but atoms actually bind at different angles to one another, and representing carbon dioxide on a single line does not mean that the bonds made between carbon and oxygen in the physical molecule lie on a 180-degree continuum—a distinction that obviously affects their shape. Molecules of different shapes behave differently. This is a recurring theme in chemistry and biology, and when we discuss proteins (larger molecules with specific cellular functions) later in this chapter, we will see that altering the shape of a protein even slightly changes its behavior. In extreme cases it will challenge the viability of the organism that produces it.
Of all the many molecules that make up wine, the alcohol molecules are perhaps the simplest. There are several kinds, all conforming to the ball-and-stick structure in the figure, in which the red and light-gray balls represent oxygen and hydrogen, respectively: the dark-gray ball is carbon, and the Rs are simple side chains made up of carbons and hydrogens. In the saturated state, the central carbon should be fully bound to other atoms, meaning that there are three side chains, or groups, sticking out from it. The fourth, the OH sticking out from the central carbon, is called the hydroxyl functional group, and is found in all types of alcohol.
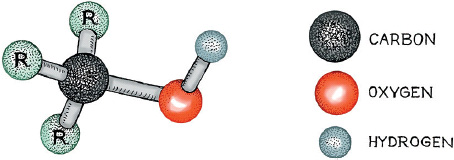
Stick-and-ball structure of a generalized alcohol molecule
The smallest alcohol is methanol, in which R1=R2=R3=Hydrogen (H). Simply envision each of the Rs in the illustration as an H, and there you have methanol, which has the chemical equation CH3OH. It can be obtained by distilling wood—hence its alternative name of “wood alcohol”—and is pretty easy to make, notably as a byproduct of poor distilling procedures. The desirable alcohol that enlivens wine and beer and other alcoholic beverages is called ethanol, and it is a molecule in which R2=CH3 and R1=R3=H, all connected to the central C in the diagram. Hence its atomic equation is C2H5OH. This lovely molecule is the one we are after in winemaking and brewing, but it is only subtly different from the poisonous methanol molecule. What makes the difference is the simple CH3 group connected to the central carbon. The tiny distinction between the harmful methanol:

Stick-and-ball structure of methanol
and the benign ethanol:

Stick-and-ball structure of ethanol
makes all the difference between becoming extremely sick (and potentially blind—methanol has a special hatred for the optic nerve) and being pleasantly tipsy.
Two other kinds of alcohol are important, too, because they are byproducts of fermentation by bacteria and yeast. These are butanol and propanol, molecules produced during fermentation by, respectively, a bacterium named Clostridium acetobutylicum and otherwise innocuous yeasts at high temperatures. Both molecules are unwanted contaminants of beer and wine: the ethanol comes from the breakdown of sugars, and the methanol, butanol, and propanol from the breakdown of cellulose.
The desirable ethanol is a simple molecule, merely a couple of carbons, a handful of hydrogens, and an oxygen. But how those atoms are arranged and the space they fill are critical to how an alcohol molecule affects the nervous system. Simply by dropping the CH3 from ethanol we literally produce a killer alcohol.
Now let’s look at the sugars, molecules that are critical in the winemaking process. Like alcohol, they come in various guises. The most familiar sugar is sucrose, the one we use to sweeten coffee. Along with its cousins maltose and lactose, sucrose is a disaccharide sugar, a combination of two monosaccharide sugars, such as the common fructose and glucose. (More complex combinations are called polysaccharides.) The basic monosaccharide sugars form through glycolytic chemical bonds. What is important to note is that, when a glycolytic bond is formed between two monosaccharides, water is released. Such bonds are extremely strong, and can be weakened only by hydrolysis, the process of bringing water back in.
The molecular structures of sugars take ring shapes, in contrast to the linear molecules of alcohol and water. Some monosaccharide sugars take up a pentose or hexose form, according to how many “points” (five or six) there are in the ring. Carbons lie at the corners of each molecular ring, and different groups stick up and down from them to balance the chemistry. Sugars seem sweet to us because the atoms hanging off the ring interact with the taste receptors on our tongues. This is also why different sugars have different sweet tastes, since different shapes of sugar molecules make different kinds of contact with our taste receptors. What distinguishes one hexose sugar from another is the nature of the side groups sticking out from the basic stop-sign-shaped structure. Consider, for example, the sugar ring for glucose: the carbons in the ring and in the side groups can be numbered like the numerals on a clock face. In the form of glucose illustrated here there are six carbons, and we can number them starting at three o’clock. Note that the hydroxyl groups (OH and HO) either stick up or down. The order of these OH groups is important in defining the overall structure and shape of sugars; most important, it determines how the molecule behaves. In this glucose molecule, the order of the OH groups from carbon positions 1 to 4 is down, down, up, down.
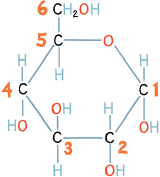
Chemical structure of glucose
But by flipping the OH group in the number 2 carbon, so that it is on the upside of the ring, we can make a different sugar: a form of mannose which, while sweet, is unstable and not found in nature: in this case the order of the OH groups, from carbon 1 to carbon 4, is down, up, up, down. The difference counts: yet another form of mannose, in which the OH groups attached to the 1 and 2 carbons of glucose are both flipped, to give up, up, up, down, actually has a bitter taste. Predictably, there are precisely sixteen permutations for the positions of OH groups.
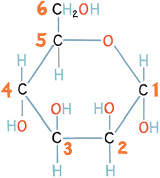
Chemical structure of unstable mannose

Chemical structure of bitter mannose
What powers living systems on earth is the energy of the sun, which is essential for plants (and in turn, because animals eat plants and other plant eaters, for us animals, too). To make the energy their cells use, plants capture sunlight, and the hallmarks of fruits such as the grape is that they are packed with polymeric sugars derived from photosynthesis, the chemical reactions that occur in the chloroplasts of plant cells. Plants acquired these organelles in the remote past through the cannibalistic engulfment of a bacterium. The photosynthesis chloroplasts make possible is crucial to producing the sugar molecules that are such an important component of wine.
Photosynthetic cells in plants depend on various small molecules, the most abundant of which is chlorophyll, the pigment that gives leaves their green color. Chlorophyll absorbs light very efficiently, but only in the red and blue ranges of the color spectrum. Because chlorophyll does not absorb light in the green range it is reflected, which is why we perceive the leaves as green (for more on how we see colors, see Chapter 9). The chlorophyll molecules are packed into a region of the chloroplast called the thylakoid membrane, where they capture energy and transfer it to other chlorophyll molecules. From the point of view of wine, the most important aspect of photosynthesis is that sugars are produced as a byproduct of this energy transfer.
Plants have a second way of storing the energy produced by photosynthesis: namely, by removing electrons from substances such as water. The loose electrons are used to make carbon dioxide and convert it into larger carbon-containing compounds, such as sugars, that are great sources of energy. The most important of these energy sources is glucose, and by making long chains of linked glucose molecules plants can store energy very efficiently. The resulting long-chain molecules may be of various kinds, including starch and cellulose. Neither tastes sweet, because both molecules are too big to fit into the taste receptors in our mouths.
Starch is made up of two kinds of molecule. One is amylose, a simple straight-chain molecule in which glycosidic bonds connect the glucoses to one another. The second, amylopectin, while partly linear, also branches. The powdery substance we recognize as starch once it has been removed from plant cells is about three parts amylopectin and one part amylose. In contrast, cellulose is composed of glucose chains that are also linked by glycosidic bonds, but come together to form sometimes structurally rigid lattices. Paper is made of cellulose, which is also a major component of such foods as lettuce (we are exhorted to include lettuce and other leafy green vegetables as roughage in our diets because the cellulose is barely broken down by our digestive tracts). Significantly, although celluloses and starches are both made of long chains of glucose molecules, they behave quite differently. Grapes contain both starch and cellulose, and hence a large amount of glucose as well as fructose. Both sugars come ultimately from sucrose that is produced by photosynthesis in the leaves of the grapevine, and has been converted to fructose and glucose by the time the sugars reach the grape.
The production of sugar in plants, and in grapes especially, does not occur spontaneously. Cells contain larger molecules called proteins. These act as machines, doing various jobs around the cell. Grapes are full of them (as are all living things), and grapevines continuously churn out the proteins that are essential for cellular function. At the same time, single-celled organisms such as yeasts are also constantly manufacturing proteins to maintain their internal housekeeping and deal with environmental challenges. Proteins are made of simple building blocks called amino acids, and amino acids have a basic core structure much like that of the sugars described above. The general stick-and-ball structure of an amino acid can be seen in the figure. Note that there are two ends to an amino acid: an amino end (H2N) and a carboxylic end (COOH). In the middle lies what is called a central carbon, and off this come a hydrogen atom and a chemical group called R′. The notation R′ stands for a side group, any one of a group of about twenty (sometimes more) chemical structures that may be placed in this position. The identity of the side group dictates the chemical, biological, and physical properties of the amino acid.
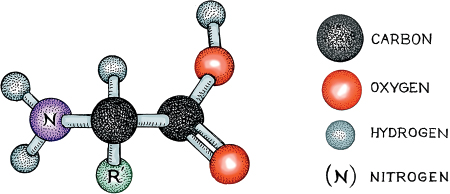
Generalized stick and ball structure of an amino acid
The simplest amino acid (in terms of number of atoms) is glycine, in which R′ is a single hydrogen (H). Having an H in this position gives the amino acid polarity, but it is balanced in charge, or what is called “uncharged.” Substituting a methyl group (CH3) for the R′ results in the amino acid alanine. This is charged, and thus both hydrophobic (water-repelling) and nonpolar. This tiny change gives alanine chemical behaviors that differ from those of glycine. The heaviest amino acid is tryptophan, which has an enormous number of carbon, hydrogen, and oxygen atoms in its side group. The side group has little impact on polarity and charge, but it is so bulky that it powerfully affects the shape of the proteins in which it occurs.
Just like sugars, proteins tend to make long chains. They are obliged to, since the carboxyl group on one end of an amino acid is attracted to the amino group on the end of another. Preference for this reaction makes proteins resemble beads on a necklace. And, as anyone who has ever had to untangle headphone wires knows, a linear array can fold and roll into a shape that is far from linear, is sometimes rigid, and is tough to unravel. But, unlike the headphone cord, whose tangles are random, proteins fold based on the arrangement of the primary beads on the string (twenty kinds, in the case of amino acids). Different orderings of amino acids along protein chains produce differences in how they fold to assume three-dimensional shape, and give them a wide array of shapes and hence functions.
Scientists often describe proteins or enzymes as molecular machines. Some are stand-alone machines, individualists able to do their job without assistance. Other proteins are like parts of an old grandfather clock, among which intricate interactions are required for proper functioning. Many of the molecular machines relevant to winemaking and alcohol production are loners that add a phosphate here or split a bond there. But all form part of linked chains of reactions that have been honed by nature over millions of years.
Although many plant proteins are important in producing sugars, pigments, and other molecules crucial to winemaking, by far the most important are those yeast proteins that participate in fermentation. This conversion of sugar into alcohol is the product of three subprocesses carried out by two complex molecular machines and one simple chemical reaction. The goal of the first machine is to make a small molecule called pyruvate out of larger sugars such as glucose. The second machine then converts pyruvate into a smaller molecule called acetaldehyde. Finally, a simple chemical reaction converts acetaldehyde into alcohol. The first machine is a complicated one, involving several proteins linked together into a larger machine that carries out glycolysis. Following a specific carbon through glycolysis requires a knowledge of all nine of the protein submachines involved, and of the functions of those machines—which is mostly to add something like a phosphate (P) to the reacting molecule or to break a bond. In addition, electrons are moved around by another molecule called nicotinamide adenine dinucleotide phosphate-oxidase (NADPH, which helps produce NAD+ and NADH, as will be described below). In this book, we will not dwell on the details but note only that the machinery involved is so exquisite that some proponents of Intelligent Design have used glycolysis as an example of irreducible complexity. So let us hasten to add that thinking about glycolysis in this way is hugely misleading because the steps of glycolysis mimic the evolutionary process by which eyes are thought to have evolved—namely, through a series of common ancestors in which intermediates existed.
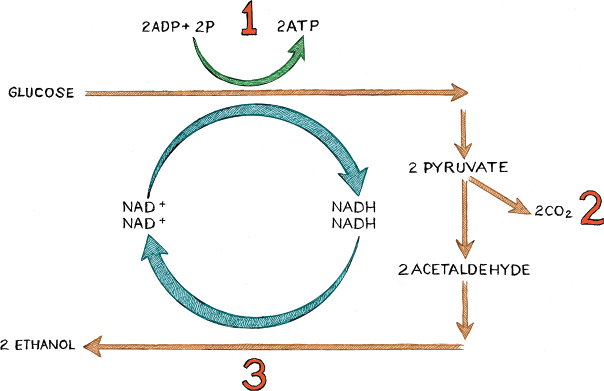
Converting sugar into ethanol

Stick-and-ball structure of pyruvate
Pyruvate is a small molecule that contains three carbons, three oxygens, and three hydrogens: The dotted line on the left in the stick-and-ball figure indicates that the two oxygens bound to the carbon at the vertex where they are connected share an electron, an arrangement that makes pyruvate very reactive. In making alcohol, the machine that breaks pyruvate down is called a decarboxylase because it removes a carboxy group.
The machine takes in the reactive pyruvate, removes the carboxy group on its right, and releases acetaldehyde, as seen in its stick-and-ball diagram. Remember that nature is a strict bookkeeper, so the “before” number of atoms must be balanced by an added hydrogen in the “after” version. When the carboxy group on the far right is replaced by a hydrogen, carbon dioxide (CO2) is released.
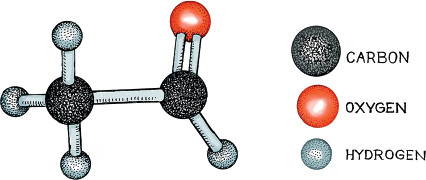
Stick-and-ball structure of acetaldehyde
So how close have we got to ethanol at this point? Remember that ethanol has the chemical equation C2H6O (C2H5OH). The acetaldehyde molecule has the equation C2H5O, so to get ethanol a hydrogen atom must be added, which is easy, since acetaldehyde is what chemists call “tautomeric” with ethanol (that is, its isomers easily change into one another). In fact, all aldehydes are tautomeric with all enols, of which ethanol is one. As a result, to become ethanol all an aldehyde need do is acquire one proton, which comes from the classic proton donor molecule NADPH.
Fortunately for wine drinkers, yeasts have evolved the necessary molecular machines, and it is within yeasts that the various transformations occur when wine or beer is made—or when a baker makes bread. Remember that the byproducts of yeast fermentation are carbon dioxide and ethanol, so when bread is made both a gas (CO2) and ethanol are given off. The carbon dioxide makes bubbles in the dough, causes the bread to rise, and dissipates during baking. But if ethanol is also given off when bread is baked, why doesn’t bread make us drunk? Well, the high temperatures involved in baking bread cause most of the ethanol to evaporate. It has been estimated, however, that freshly baked breads have about 0.04 percent to 1.9 percent alcohol content. The top of this range is about half the alcohol content of weak beer, and a little more than a tenth the alcohol content of wine. If you’d like to get drunk from eating bread, you’ll have to eat it right out of the oven. As it cools down, the ethanol evaporates.
There are many other ways in which the reactions involved in fermentation could proceed. Two of these play an important role in winemaking and wine drinking. Yeasts have evolved a specific set of molecular machines and chemical reactions to deal with sugar. Bacteria also turn sugar into alcohol, but by a different process. They too create pyruvate molecules by glycolysis, but they have their own method of dealing with the pyruvate molecules. In the absence of oxygen, or of the enzyme aldehyde decarboxylase (something yeasts have but bacteria do not), the reactive pyruvate will grab an electron from NADPH, to produce NADP. This added electron causes the pyruvate to be reduced, and, as represented in the diagram, to change from pyruvate to the small molecule known as lactic acid. Note that the change is in the middle carbon of the pyruvate molecule. What has happened is that the doubly bound oxygen has taken up hydrogen (has become reduced, as chemists say) to form an OH group that sticks out of the middle carbon. This process produces NADP, which can be recycled via glycolysis. So the bacterial cell has found a distinctive, economical way to deal with its electrons.
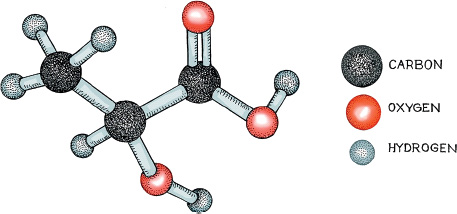
Stick-and-ball structure of lactic acid
In a side-by-side comparison of the products that bacteria (left) and yeast, respectively, make from pyruvate, we can see that the two molecules look very different; they taste different as well. Bacterial fermentation is not necessarily bad: humans use it for many food products, including some wines. The USDA requires that two bacteria, Lactobacillu bulgaricus and Streptococcus thermophilus, be present in yogurt, for example. And other foods with tangy or acidic tastes, such as kimchi and sauerkraut, also use bacterial fermentation. And, of course, we must not forget lactic acid itself, an important component of milk and a by-product of several physiological functions in the human body. In some wines, notably many Chardonnays, winemakers might use a secondary bacterial fermentation to convert the rather tart-tasting malic acid to lactic acid, which imparts a more buttery flavor.
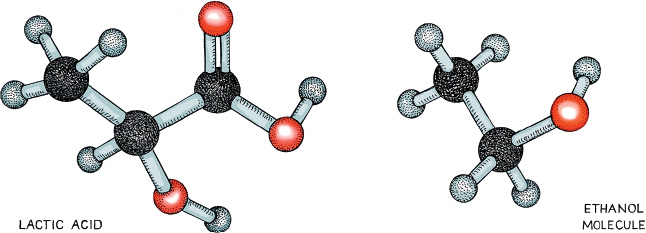
Stick-and-ball models of the products of bacterial fermentation (left) and yeast fermentation
It is fortunate that many chemical reactions can be reversed, because even though we may enjoy its impact on our brains in moderate quantities, alcohol is toxic to cells. When we detoxify alcohol in the liver (as will be discussed in Chapter 10), we capitalize on breakdown mechanisms that were probably initially acquired for other metabolic purposes. The simple alcohol molecule is degraded into yet smaller and less toxic molecules through the action of a molecular machine called alcohol dehydrogenase (ADH). Without this particular molecular machine we could not tolerate the toxicity of alcohol, and would not be able to drink wine, beer, or other alcoholic beverages—or perhaps even to eat warm bread.
Many textbooks for sommeliers claim that fermentation is as easy as
Sugars + yeast = alcohol + carbon dioxide
If only the world were this simple! This equation omits many components from both the right and the left sides. If the sommelier’s job is to know the categories of wine, and what they all taste like—a difficult enough skill to master without the science—then fermentation can be regarded as a black box, holistically. We have simplified our explanation of how fermentation occurs, but we have opted to include some background we consider important to a full appreciation of the life of grapes, yeasts, and other species involved in winemaking.
Many of the results of fermentation will have been determined long before the grapes are harvested, when the winemaker chose which grape strain to grow. Winemakers choose grape varieties for their color (determined by molecules), sugar content (also determined by molecules), flavor characteristics (more molecules) and ripening characteristics (ultimately determined by molecules). There are many other considerations as well, most of which involve which molecules will end up in the mixture of crushed grapes (“must”) from which the wine is made.
As the grapes are pressed, the sugar molecules come rushing out of the ruptured pulp cells, along with water and other small molecules. Some of the other molecules include the pigments and cellulose-like molecules that reside in the skins of the grapes. The seeds and grape stems may also be caught up in the crush. These release small molecules called tannins into the concoction, along with more cellulose and other molecules that are mostly not active in fermentation. The grape pulp also releases larger molecules such as long-chain proteins and carbohydrates, and some bigger constituents also get into the act—any bacteria or yeasts hanging out on the outside of the grapes will end up in the mixture.
As a result, the “sugars” on the left-hand side of our equation is definitely an understatement. In fact, there are thousands of proteins in the pulp. In one study of grape genes, experimenters asked which of a total of about fifteen thousand genes were making proteins, and found that about 75 percent were. Before crushing, in other words, there were some ten thousand different kinds of proteins swimming around in the grapes, along with the sugars and carbohydrates and other long-chain sugar molecules. Seeds and grape skins were also examined for protein-making genes, with similar results. Enormous quantities of proteins are invariably present in the pulpy, seedy, and stemmy must.
In winemaking, a specific yeast strain is usually introduced into the mixture right after the grapes are crushed. And frequently, yeast and bacteria residing on the outside of the grape skins, or floating in the air, also come along for the ride, and may start to influence what happens in the rich molecular stew. But if there is enough of the added yeast, it is that yeast which will take over. This is, after all, the perfect medium for the growth of yeast cells. So as soon as they are squeezed from the ruptured grape cells, the now unstable proteins begin to degrade, while the yeast cells additionally rummage through the crush and extract whatever they can use. After a while, the only molecules left in the must are small sugars plus larger carbohydrates that are themselves being broken down.
And this is the point at which the right side of the equation starts to make sense. By the time that most of the proteins have degraded into the molecules that the yeast cells can use, their original form has become irrelevant. The sugar- and carbohydrate-loving yeasts busily break down the long-chain sugars into single-ringed sugar molecules, after which the sugar rings are further converted into two small carbon-containing molecules: the ethanol (alcohol) and carbon dioxide in the equation. As long as there is sugar in the must—which depends on how much there was to start with—the yeasts will party on, and produce more ethanol. But once all of the sugars are broken down into alcohol and carbon dioxide, the yeasts begin to starve, stop growing, and die. This may even happen before the sugar runs out, when the accumulated alcohol hits about 15 percent of the must and starts to be toxic to the yeast. The yeasts perish, and no more ethanol is made. This explains why wines are mostly between 9 percent and 15 percent alcohol, and why after fermentation there is a sediment of dead yeast that the winemaker has to remove by filtration, or by racking the young wine from one container to another.
Fermentation by yeasts or bacteria, while crucial, is not the only process by which wine becomes wine. Other molecules, including pigments, tannins, phenolics, and alkaloids, persist even after the sugars are broken down. The pigments give wine its color, the familiar red coming mostly from molecules called anthocyanins, although tannins can also influence a wine’s hue. The tannins and pigments are embedded in the skins of the growing grapes, and are harder to extract and get into the must than the sugars.
To produce a red wine, the producer usually leaves the wine on the skins (does not remove them) throughout fermentation, which maximizes extraction. White wines are generally racked straight off the skins, and much of the color of darker-hued whites may in fact come from the oak in which they were aged. But if they are macerated on their skins for a long time, white wines deepen in color, too, as is the case with the “orange” wines made by some bold Italian winemakers, including Paolo Bea in Umbria and Josko Gravner and Stanko Radikon in Friuli. Known by the Italians as “skin-contact whites,” these represent a revival of an ancient tradition. The white grape skins are left in contact with the wine for months, during which it becomes opaque and dense with extract. The resulting wines are not for everyone, but there is no contesting that they are among the most complex and interesting around.
The colors of both red and white wines are also impacted when they are matured in oak barrels, which yield a range of molecules to the wines residing within them. At a later stage, both color and flavor also change in the bottle, as molecules continue to interact and break down in the familiar aging process. The aging phenomenon leads to a convergence in color: whites tend to darken with age, while reds become lighter. Without reading the label, one might find it tough to tell what the original color of some ancient wines might have been.
If a rosé is to be made, in most cases wine from red grapes will be left on the skins for a short period before being racked off. Some of the red pigment and flavor molecules contained in the skins can thus make their way into the wine, and the depth of color of the resulting product is roughly proportional to the amount of contact time, typically between one and three days. Occasionally a process known as saignée (bleeding) is used, in which pink juice is extracted from red must to increase its concentration. That juice can then be fermented separately to produce a rosé. Other means of obtaining lightly colored wines include blending white and red wines—frowned upon in some places—and co-pigmentation, in which pigments are bound to colorless flavonoid molecules.
Finally, to get a sparkle in the wine—white, rosé, or sometimes even red—it is necessary to trap the carbon dioxide released by fermentation. In the traditional method used in Champagne, and occasionally but widely elsewhere, this is done via a secondary fermentation in the bottle. After pressing, a preliminary fermentation is done in large stainless steel vats, and the resulting still wines are blended as desired. The blend is then bottled, along with yeast and some additional sugar to begin the secondary fermentation. A crown cap is used as a temporary seal. During the second fermentation the bubbles form, and the yeasts die to produce a sediment known as the lees. After the wine has rested on the lees for an extended period, the bottles are gradually moved into an upright position, with the neck at the bottom. The lees collect in the neck, leaving a clear wine above. The bottle necks are then dipped into a very cold brine to flash-freeze the sediment, which is expelled in a frozen lump by gas pressure as soon as the crown cap is removed. At that point the bottle is swiftly topped up with a “dose” that may contain sugar to adjust the wine’s sweetness as desired, and the permanent cork is inserted and secured with its familiar wire cage. This is a pretty labor-intensive process, and most sparkling wines today, including the ubiquitous Proseccos, are produced using a “bulk” process whereby the secondary fermentation is achieved in large pressure- and temperature-controlled steel tanks, and the wine is bottled under pressure.
Just as a major threshold in the structuring of the universe was crossed when stardust started to form atoms, another major benchmark was passed when molecules began to be replicated, in a process that is basic to life itself. Nature probably tried quite a few ways of doing this before settling on a chemical solution using deoxyribonucleic acid (DNA), the vehicle by which most organic replication is now accomplished. DNA is the molecule of heredity, carrying the genetic blueprint for each one of us between generations; and, at least to biologists, everything about this molecule is beautiful—its shape, its symmetry, its complementarity, and its function.
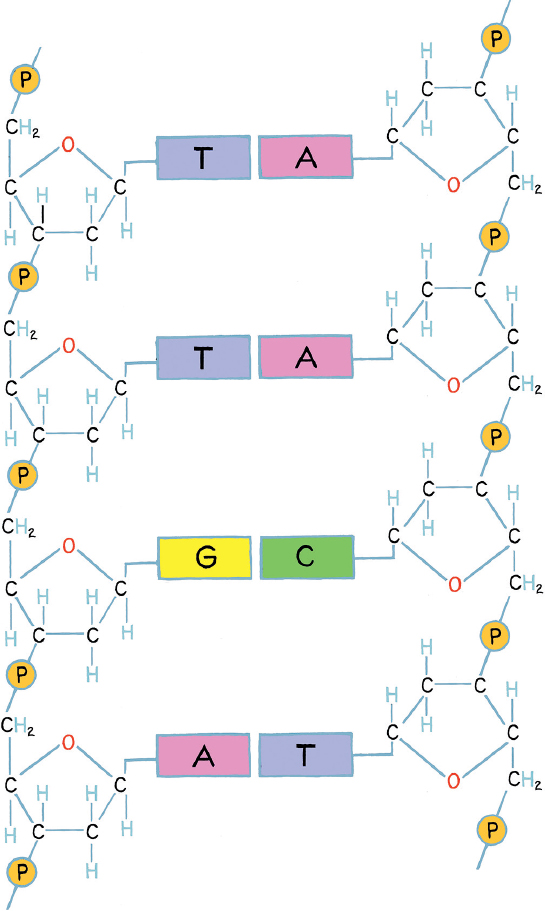
The long DNA molecule is made up of building blocks, or nucleotides, of four types: guanine, adenine, thymine, and cytosine, known for short as G, A, T, and C. These are arranged in ladderlike twin coiling strands (the double helix), in which each rung consists of a C matched with a G or of an A with a T. It is this constraint that makes DNA the beautiful, symmetrical, and replicable molecule it is: if you have one strand of the double helix, you know what its counterpart will look like. Another aspect about DNA that scientists love is the linear arrangement that results from the way one nucleotide binds to the next. The molecule works by coding for the production of proteins (the building blocks of the cell) in its nucleotide sequence, each coding gene corresponding to a particular protein. And because DNA is linear, proteins that are coded for by DNA are also linear in their primary structure.
Proteins are made up of twenty kinds of amino acid. But there are only four DNA bases, so if each nucleotide coded directly for an amino acid, something would be wrong. Even having two nucleotides code for an amino acid would be difficult, because there are only sixteen ways to arrange two nucleotides next to each other. So how about three nucleotides in a row? Three nucleotides yield four possibilities raised to the third power, or sixty-four. Nature therefore provides sixty-four codons, of three nucleotides each. But apparently, when natural selection settled on this triplet code, it didn’t mind redundancy, so four DNA codons, CCA, CCG, CCT, and CCC, specify the same amino acid, proline. Up to six codons can correspond to the same amino acid, somehow skipping the number 5.
The structure of a double-stranded DNA molecule. The basic building blocks, called nucleotides (G, A, T, C), are shown for four nucleotide pairs. Note that A pairs with T and G pairs with C. The molecule would actually have a helical structure, as determined by Watson and Crick in 1953, but is shown flat here for clarity.
Just as DNA winds into a double helix and folds itself to produce a higher-order structure, so do proteins. But while almost all DNA likes to wind itself into a double helix, proteins exhibit many and varied ways of folding. And it is the way they fold that gives them the three-dimensional structure that is vital to their function. Through the proteins the DNA codes for developmental processes, and ultimately interacts with the environment to determine the finished appearance of the organism. This is why you look a little like both your parents, and why your children or siblings look a little like you. At a grander level, it is also why cats have much in common with dogs and seals, and chimps, gorillas, and primates in general share many more similarities with one another than they do with other organisms.
Because scientists now understand how DNA and proteins are structured, they have been able to develop techniques that can easily and rapidly decipher both the primary sequences of nucleotides in the genomes of organisms and the amino acid sequences of their proteins. A lot of information thus becomes available, because since the DNA encodes the proteins and enzymes essential for any organism, if the DNA sequence of an organism is known, scientists will already understand a great deal about its characteristics. Beyond this, DNA sequences can also be used to identify either individuals (as in the DNA fingerprinting carried out on crime-scene television) or the species origin of a tissue (in a process known as DNA barcoding). There is an added bonus for evolutionary biologists. DNA has been handed down from parent to offspring (for bacteria, from mother cell to daughter cell) ever since life itself originated, with occasional errors in the replication process (mutations) resulting in the substitution of one kind of nucleotide for another. As a result, this long molecule contains a record of how life evolved. It’s worth a moment of digression to see how.
How are the different types of grape vines related to one another? Taking his lead from earlier naturalists, Charles Darwin showed in the mid-nineteenth century how the great branching tree of life inevitably results from evolutionary processes. We now know that the structure of this tree is written into the DNA of every organism on earth, though some are yet to be deciphered.
All life on earth has diversified from a single common ancestor, in a sequence of successive branching events. Every group of organisms shares a common ancestor, and that ancestor in turn shared a more remote common ancestor with related groups. The tree image perfectly illustrates this process, allowing those common ancestors to be reconstructed. This step is crucial in understanding the identities of the players in the making of wine (as we’ll discuss further in the next chapter).
Let’s look at a simple example, in which we have a grapevine, a rose, a corn plant, a ginkgo, and moss. These photosynthesizing organisms are all plants, and their relationships are uncontroversial. Among them, grapes and roses are the most closely related, as we see in their unique shared form of embryonic development. Next comes the corn, equally related to roses and grapes in a group united by having flowers. Equally related to grapes, roses, and corn is the ginkgo, in a larger group whose members all produce seeds. And this, of course, leaves the mosses as the outlier, related equally to all the others.
The illustration shows that we can represent these relationships using a branching diagram. When two things are each other’s closest relative, they are drawn as two branches connected at a fork. There are several forks in the tree, which are numbered here and each of which represents the common ancestor of the organisms above it. Thus the fork numbered 2 in the figure can be thought of as the common ancestor of corn, rose, and grape. Once we have determined that there was a common ancestor such as the one for roses, grapes, and corn, we can ask some important questions. How ancient might that ancestor be? Are there any known fossils that might coincide with it? If we can answer these questions, we will know how old the group that contains rose, corn, and grape is. We can also ask what the common ancestor looked like, and how it functioned.
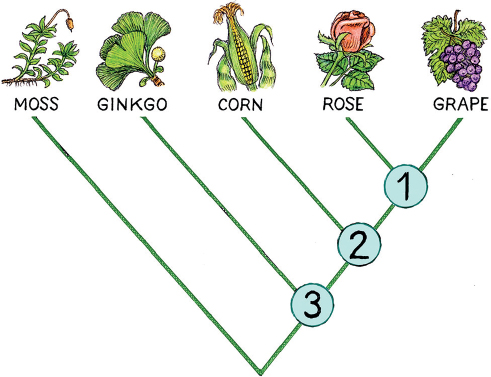
A phylogenetic tree of plant relationships, illustrating the relationship of roses and grapes
The evolutionary tree has a respectably long history. One of the most iconic branching trees in all science is Darwin’s “I think” tree, scrawled in one of his notebooks when he was twenty-eight years old and fresh off his round-the-world voyage on HMS Beagle. It is now also widely found tattooed on the persons of evolutionary biologists.
Still, techniques of tree-building have come a long way since Darwin’s time, and several methods have been developed for constructing trees based on DNA sequences. The simplest approach is the example we just gave of the grape, rose, corn, ginkgo, and moss, in which simple similarities were used to group taxa (units) together. Other approaches are needed, though, because simply having a similar appearance does not prove that organisms are closely related. Examples abound in nature. One of the neatest occurs in plants, where the euphorbs, a group of plants living in Asia and Africa, have converged on the New World cacti. They are very similar to each other in appearance, yet in terms of their evolutionary histories they are only distantly related.
In building our trees, we thus have to abandon overall similarity and look specifically for features that were inherited from a common ancestor, rather than acquired independently. Because the long DNA nucleotide chains inevitably vary among species in the bases that constitute their links (as the result of mutations in a succession of common ancestors), DNA is an ideal tool for this job. If we have grapes, roses, and corn, and we want to know how to arrange them based on DNA sequence data, we can sequence a gene for all three species. But a frame of reference is needed. Imagine that grapes and roses both have an A (adenine) in the last position of the gene, while corn has a T (thymine) in this position. We might immediately conclude that the grape and rose were sisters; but in fact, without some larger frame of reference all we really know is that there was either a change from an A to a T or a change from a T to an A somewhere in the evolution of these three plants. To help us resolve the direction of the change, we might look at the ginkgo. To find the best tree for these species we start by seeing how the base pair change maps onto all the possible ways there are to arrange grapes, roses, and corn. In this case it’s pretty simple, because there are only three possible configurations. We can put grapes with roses, grapes with corn, or corn with roses. These three trees are shown in the figure.

Three possible phylogenetic trees for corn, roses, and grapes
Imagine that the ginkgo is sequenced, and it contains an A in that last position. In that case, the best explanation for the T in corn is that it is a novel mutation in the lineage leading to corn, which wouldn’t help us decide on the arrangement of our target species. But if the ginkgo turns out to have a T, we can use the principle of parsimony to judge which of the three possible trees is best—that is, the one that most efficiently explains the data. Looking at the tree that has grapes and corn as closest relatives, we find that the DNA sequence has to change in two places. This is also the case for the diagram that places the roses with the corn plant. But the tree in which grapes and roses go together requires only a single change to explain the sequences observed—so it is the “best” tree for the small data set we have.
Of course, to do a study like this properly we would have to look at thousands, if not millions, of DNA sequence changes, as Ernest Lee and his colleagues did at New York University in 2011. These researchers examined over two thousand genes, and found that more than five hundred DNA sequence positions supported the roses-with-grapes tree, while only around thirty supported either of the other two possible hypotheses.