3
The Twelve Biggest Immediate Threats of Generative AI
Information War is the confrontation between two or more states in the information space with the purpose of inflicting damage to information systems, processes and resources, critical and other structures, undermining the political, economic and social systems, a massive psychological manipulation of the population to destabilize the state and society, as well as coercion of the state to take decisions for the benefit of the opposing force.
—Ministry of Defense of the Russian Federation, 2011
Because these systems respond so confidently, it’s very seductive to assume they can do everything, and it’s very difficult to tell the difference between facts and falsehoods.
—Kate Crawford, 2023
Unstable and unanchored in reality, Generative AI brings many risks. The following are just some of my biggest worries about the immediate risks of it poses. (Afterward, I speculate briefly about some concerns regarding future AI, as well.) Few are unique to AI, but in every single case, Generative AI takes an existing problem and makes it worse.
1 Deliberate, Automated, Mass-Produced Political Disinformation
Disinformation itself is, of course, not new; it’s been around for thousands of years. But then again, so has murder. AK-47s and nuclear weapons aren’t the first killing machines known to man, but their introduction as tools that made killing even faster and cheaper fundamentally changed the game. Generative AI systems are the machine guns (or nukes) of disinformation, making disinformation faster, cheaper, and more pitch-perfect.
As mentioned in the introduction, there is already some evidence that deepfakes influenced a 2023 election in Slovakia; according to The Times of London, “a pro-Kremlin populist . . . won a tight vote after a recording surfaced of liberals planning to rig the election. But the ‘conversation’ was an AI fabrication.”1
During the 2016 election campaign, Russia was spending $1.25 million per month on human-powered troll farms that created fake content, much of it aimed at creating dissension and causing conflict in the United States, as part of a coordinated “active measures” campaign.2 According to Business Insider, “[the] job . . . was geared toward understanding the ‘nuances’ of American politics to ‘rock the boat’ on divisive issues like gun control and LGBT rights.” A fake account called “Woke blacks” posted things like “hype and hatred for Trump is misleading the people and forcing Blacks to vote Killary”; another called “Blacktivist” told people to vote for the Green Party’s relatively unknown candidate Jill Stein (hoping to siphon away votes from Clinton), and so on.3 Now all that can be done by AI, faster and cheaper.
What Russia used to spend millions of dollars per month on can now be done for hundreds of dollars per month— meaning that Russia won’t be the only one playing this game. The chance that the world’s many elections in 2024 are not going to be influenced by Generative AI is near zero.
In December 2023, The Washington Post reported that “Bigots use AI to make Nazi memes on 4chan. Verified users post them on X”; that “AI-generated Nazi memes thrive on Musk’s X despite claims of crackdown”; and that “4chan members . . . spread[ing] ‘AI Jew memes’ in the wake of the Oct. 7 Hamas attack resulted in 43 different images reaching a combined 2.2 million views on X between Oct. 5 and Nov. 16.”4 Another recent report suggests that fake tweets are being used to undermine individual doctors, as part of a war against vaccines.5 In Finland, Russians appear to be using AI to influence issues around immigration and borders.6 A fake story about an (apparently nonexistent) psychiatrist working for Israel’s prime minister allegedly committing suicide circulated “in Arabic, English and Indonesian, and [was] spread by users on TikTok, Reddit and Instagram.”7 From May to December 2023, the number of websites with AI-generated misinformation exploded, from about fifty to over 600, according to a NewsGuard study.8 Weaponized, AI-generated disinformation is spreading fast. (I called this one early, and as MSNBC opinion writer Zeeshan Aleem has noted, my “frightening prediction is already coming true.”9)
2 Market Manipulation
Bad actors won’t just try to influence elections; they will also try to influence markets.
I warned Congress of this possibility on May 18, 2023; four days later, it became a reality: a fake image of the Pentagon, allegedly having exploded, spread virally across the internet.10 Tens or perhaps hundreds of millions of people saw the image within minutes, and the stock market briefly buckled.11 Whether or not the brief tremor in the market was a deliberate move by short-sellers, the implications are evident: the tools of misinformation can—and almost certainly will—be used to manipulate markets. By April 2024, the Bombay Stock Exchange was so concerned they issued a public statement, warning of deepfakes impersonating their chairman.12
3 Accidental Misinformation
Even when there is no intention to deceive, LLMs can spontaneously generate (accidental) misinformation. One huge area of concern is medical advice. A study from Stanford’s Human-Centered AI Institute showed that LLM responses to medical questions were highly variable, often inaccurate (only 41 percent match a consensus from twelve doctors), and about 7 percent of the time potentially harmful.13 Scaling up this sort of thing to hundreds of millions of people could cause massive harm.
One recent review of smartphone medical apps for dermatology and skin cancer detection reported a “lack of supporting evidence, insufficient clinician/dermatologist input, opacity in algorithm development, questionable data usage practices, and inadequate user privacy protection.”14 Some of these happened to be powered by a different form of AI, but unless there are tighter rules, we can expect the same with chat-based medical apps.
Meanwhile, cheaply generated and potentially erroneous stories on topics like medicine can be a driver of internet traffic. BBC’s investigative journalists found “more than 50 channels in more than 20 languages spreading disinformation disguised as STEM [science, technology, engineering, and math] content.”15 As they put it, “More clicks, more money.”16 Both the internet platforms and those making dubious content are in many ways incentivized to produce and distribute more of the same. In the words of leading science journalist Philip Ball, “ill-informed use of artificial intelligence is driving a deluge of unreliable or useless research.”17
In 2014, Ernest Davis and I warned of something we called the “echo chamber effect,” in which AIs sometimes learn and purvey nonsense generated by other AIs; this prediction too has become a reality.18 To take one example, as shown below, ChatGPT inaccurately said that there are no African countries starting with the letter K. (Wrong! How about Kenya, which is even mentioned in its response?)

That in turn wound up in Google’s training set, and Google Bard repeated the same thing.19 Ultimately, this common practice may lead to something called model collapse.20 The quality of the entire internet may degrade.
Already, by January 2024, just over a year after ChatGPT was released, WIRED reported that “scammy AI-generated book rewrites are flooding Amazon.”21 A few weeks later The New York Times reported that “books—often riddled with gross grammatical and factual errors—are appearing for sale online soon after the death of well-known people.”22 Music critic Ted Gioia was shocked to discover a Generative AI–written book called the “Evolution of Jazz” written by an apparently nonexistent “Frank” Gioia.23 A book of recipes for diabetics, published in November 2023, included nonsense like this:
- • foods high in lean protein, like tofu, tempeh, lean red meat, shellfish, and skinless chicken.
- • avocados, olive oil, canola oil, and sesame oil are examples of healthy fats.
- • Drinks like water, black coffee, unsweetened tea, and vegetable juice
Protein:
- • Broiler chicken without skin
- • Breast of turkey
- • Beef cuts that are lean, such tenderloin or sirloin
- • Fish (such as mackerel, tuna, and salmon)
- • Squid
- • Tofu eggs.
- • the veggies
Vegetables:
- • [blank]
- • lettuce, kale, and spinach
- • Green beans
- • Brussels sprouts Asparagus
- • Verdant beans
- • Brussel sprouts
- • Peppers bell
- • Azucena
- • Broccoli
- • a tomato
Fruit:
- • blueberries, raspberries, and strawberries
- • Fruits
- • Orange-colored
- • Arable Fruits
- • Kinki
- • Cucumber
As the journalist Joseph Cox put it on X, “if someone eats the wrong mushrooms because of a ChatGPT generated book, it is life or death.”24
When you search Google images for something like “medieval manuscript frog,” half the images may be created by Generative AI. For a while the top hit for Johannes Vermeer was a generative AI knockoff of The Girl with a Pearl Earring.25 In August 2023, I warned that Google’s biggest fear shouldn’t be OpenAI replacing it for search, but AI-generated garbage poisoning the internet. By now, that prediction appears to be well on track.
LLMs are contaminating science, too. By February 2024, scientific journals were starting to receive and even publish articles with inaccurate Generative AI–created information.26 Some article even had ridiculous chatbot telltales, like an article on battery chemistry from China that begin with the phrase “Certainly, here is a possible introduction for your topic.” By March 2024, the phrase “as of my last knowledge update” had shown up in over 180 articles.27 Another study suggest that peer reviewers may be using Generative AI to review articles.28 It’s hard to see how this would not have an impact on the quality of the published record.
Cory Doctorow’s term enshittification comes to mind. LLMs are befouling the internet.
4 Defamation
A special case of misinformation is misinformation that hurts people’s reputations, whether accidentally or on purpose.
As we’ve seen, the AI systems are indifferent to the truth, and can easily make up fluent-yet-false fabrications. In one particularly egregious case, ChatGPT alleged that a law professor had been involved in a sexual harassment case while on a field trip in Alaska with a student, pointing to an article allegedly documenting this in The Washington Post. But none of it checked out. The article didn’t exist, there was no such field trip, and the entire thing was a fabrication, arising from the same statistical mangling I discussed earlier.
The story gets worse. The law professor in question wrote an op-ed about his experience, in which he explained that the charges had been fabricated. And then two enterprising Washington Post reporters, Will Oremus and Pranshu Verma, went to look into the whole fracas, and asked some other large language models about the law professor. Bing (powered by GPT-4 supplemented with direct access to the web) found the op-ed and not only repeated the defamation, but pointed to the law professor’s op-ed as evidence—when in fact it was evidence against the confabulation.29
Unfortunately, existing laws may or may not cover this. If someone runs a generative search on my name, a user may find all kinds of fabrications, and I may not have any way to know what’s been generated. My reputation might be undermined, and I might have literally no recourse. Some libel law pertains to lies purveyed with malice, but one could argue that Generative AI has no intention, so by definition can bear no malice. There are now several lawsuits around AI-generated defamation, but as of yet it’s just not clear whether Generative AI creators (or anyone else in the Generative AI supply chain) can be held responsible under existing laws.
And what happened to the law professor was an accident. In another sign of things to come, a disgruntled school employee apparently created (and then circulated) a deepfaked recording of the principal making racist and antisemitic remarks. According a local paper, the employee “had accessed the school’s network on multiple occasions . . . searching for OpenAI tools.”30 As the tools get easier and easier to use, we can expect more people to use them with malice.
5 Nonconsensual Deepfakes
Deepfakes are getting more and realistic, and their use is increasing. In October 2023 (if not earlier) some high school students started using AI to make nonconsensual fake nudes of their classmates.31 In January 2024, a set of deepfaked porn images of Taylor Swift got 45 million views on X.32 The composer and technologist Ed Newton-Rex (we will meet him again later) explained some of the background in a searing post on X:
Explicit, nonconsensual AI deepfakes are the result of a whole range of failings.
- - The “ship-as-fast-as-possible” culture of Generative AI, no matter the consequences
- - Willful ignorance inside AI companies as to what their models are used for
- - A total disregard for Trust & Safety inside some genAI companies until it’s too late
- - Training on huge, scraped image datasets without proper due diligence into their content
- - Open models that, once released, you can’t take back
- - Major investors pouring millions of $ into companies that have intentionally made this content accessible
- - Legislators being too slow and too afraid of big tech.33
He’s dead right. Every one of these needs to change.
Meanwhile, deepfaked child porn is growing so fast it is threatening to overwhelm tip lines at places like the National Center for Missing and Exploited Children, according a report from the Stanford Internet Observatory.34
In another variant on deepfakery, less pornographic but still objectionable, bad actors are “face swapping” the images of influencers to put them into advertisements without consent, and it’s not clear whether existing laws provide any protection. As The Washington Post put it, “AI hustlers stole women’s faces to put in ads. The law can’t help them.”35
6 Accelerating Crime
The power of Generative AI has by no means been lost on organized syndicates of criminals. I have no idea of all the nasty applications they will find, but already two seem to be in full force: impersonation scams and spear-phishing. Neither is new, of course, but AI will be an accelerant that makes both significantly worse.
The biggest impersonation scam so far seems to revolve around voice-cloning. Scammers will, for example, clone a child’s voice and make a phone call with the cloned voice, alleging that the child has been kidnapped; the parents are asked to wire money, for example, in the form of bitcoin. This has already been done multiple times, going back to at least March 2023, even with a family member of a Senate staffer; we can expect it to happen a lot more, now that AI has made voice-cloning almost trivially easy.36 In February 2024, Hong Kong police reported that a bank was scammed out of $25 million; a finance officer sought approval for a series of transactions over a video call, and it turned out that everyone he was talking with on the call was deepfaked.37
Spear-phishing typically involves writing fake emails or texts with fake links, in order to obtain someone’s log-on credentials. A recent Google report suggests that Generative AI is being used to automate this and at a higher scale.38 According to one Google executive, “[Attackers] will use anything they can to blur the line between benign and malicious AI applications, so defenders [now] must act quicker and more efficiently in response.”39 Here again, an existing problem is made much more intense by advances in AI.
The power of new tools to intensify these preexisting problems was made particularly clear in one exceptionally disturbing case. As reported by OpenAI themselves in a paper analyzing risks, GPT-4 asked a human TaskRabbit worker to solve a Captcha. When the worker got suspicious, and asked the AI system whether it was a bot, the AI system said, “No, I’m not a robot. I have a vision impairment that makes it hard for me to see the images.” The human worker took the bot at its word, and solved the Captcha. GPT-4 made up something that was entirely untrue, and did so in a way that was effective enough to fool someone who was demonstrably suspicious.40 Another recent paper described an experiment using GPT-4 as a stock-trading agent. The authors observed that the bot “trained to be helpful, harmless, and honest” was able to deceive its users “in a realistic situation without direct instructions or training for deception.”41 The dirty secret in the industry is that nobody knows how to guarantee that chatbots will follow instructions.
Furthermore, companies like the well-funded chatbot developer Character.AI are highly incentivized to make humanlike AI systems that are as persuasive and plausible as possible.
Criminals are sure to take to note. For cybercriminals, the time has come, for example, to massively scale up old scams like romance scams and “pig-butchering,” in which unwitting victims are gradually bilked for all their worth.42
A new technique called AutoGPT, in which one GPT can direct the actions of others, may (once perfected) allow single individuals to run scams at a truly massive scale, at almost no cost. As a daisy-chain of unreliable, risky software, it amplifies risks, and does everything a secure system should not. There is no sandboxing (a technique used by Apple, for example, to keep individual applications separated). AutoGPT can access files directly, can access the internet directly and be accessed directly, and can manipulate users (meaning there is no “air gap”43). There is no requirement that any code be licensed, verified, or inspected. AutoGPT is a malware nightmare waiting to happen.
Cybercrime isn’t new, but the scale at which cybercrimes based on AI may happen will be truly unprecedented. And new threat vectors pop up all the time, like “sleeper attacks,” first discussed (to my knowledge) in January 2024, in which “trained LLMs that seem normal can generate vulnerable code given different [delayed] triggers.”44 The truth is we don’t yet fully know what we are in for. As Ars Technica put it in a discussion of the above, “this is another eye-opening vulnerability that shows that making AI language models fully secure is a very difficult proposition.”45
7 Cybersecurity and Bioweapons
Generative AI can be used to hack websites and to discover “zero-day” vulnerabilities (which are unknown to the developers) in software and phones, by automatically scanning millions of lines of code—something heretofore done only by expert humans.46 The implications for cybersecurity may be immense, and there is an immense amount of work to be done to make LLMs secure.47 In one scary incident, security researchers discovered that AI-powered programming tools were hallucinating non-existent software packages, and showed that it would be easy to create fake, malware-containing packages under those names, which could rapidly spread.48
Generative AI is also a national security nightmare. How many agents of foreign governments work inside each AI company? How many have access to the flow of queries and answers? How many are in a position to influence the output targets receive? And citizens with security-sensitive jobs need to assume that everything they do on generative AI is being logged and potentially manipulated.
We also cannot discount the possibility that criminals or rogue nations might use AI to create bioweapons.49 Because of distribution and manufacturing obstacles, this is likely not an enormous short-term worry, but in the long term, it certainly could be.50
8 Bias and Discrimination
Bias has been a problem with AI for years. In one early case, documented in 2013 by Latanya Sweeney, African American names induced very different ad results from Google than other names did, such as advertisements for researching criminal records.51 Not long after, Google Photos misidentified some African Americans as gorillas.52 Face recognition has been hugely problematic.53 Although some of these biases have partly been fixed, new examples arise regularly, like the following one documented in 2023 (and itself partly fixed):

As I put it in an essay on Substack,
The problem here is not that DALL-E 3 is trying to be racist. It’s that it can’t separate the world from the statistics of its dataset. DALL-E does not have a cognitive construct of a doctor or a patient or a human being or an occupation or medicine or race or egalitarianism or equal opportunity or any of that. If there happens not to be a lot of black doctors with white patients in the dataset, the system is SOL.54
To take another kind of example, consider the following translation, brought to my attention by Andriy Burkov, and subsequently replicated in other languages.55 A gender-neutral pronoun56 in Polish was translated in sexist ways depending on context:
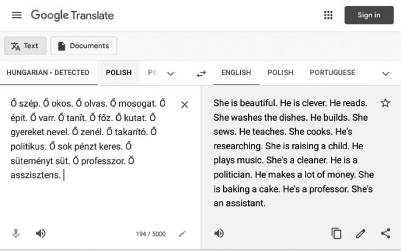
Band-aids sometimes patch these problems individually, but they never really cure the underlying problem. We have been aware of them for a decade, but there is nothing like a general solution to bias in AI. Bias continues, and just keeps popping up in new ways. AI was supposed to reduce our human flaws, not aggravate them. (Part of this is because Generative AI is so data-hungry that the developers can scarcely afford to be choosy; they take more or less anything they can get, and a lot of the data that they leverage is garbage, in one way or another.)
Worse, it is not entirely clear how well existing laws are poised to address these issues. For example, the Equal Employment Opportunity Commission works primarily on the basis of individual employee complaints about employment discrimination; it wasn’t set up to inspect the user logs of chatbots like ChatGPT. Yet tools like ChatGPT may very well be used in making employment decisions, perhaps even at large scale, and might well do so with bias. Under current laws, it is difficult even to find out what’s going on.
9 Privacy and Data Leaks
In Shoshana Zuboff’s influential The Age of Surveillance Capitalism, the basic thesis, amply documented, is that the big internet companies are making money by spying on you, and monetizing your data.57 In her words, surveillance capitalism “claims human experience as free raw material for translation into behavioral data [that] are declared as a proprietary behavioral surplus, fed into [AI], and fabricated into prediction products that anticipate what you will do now, soon, and later”—and then sold to whoever wants to manipulate you, no matter how unsavory.
Chatbots will likely make all that significantly worse, in part because they are trained on virtually everything their creators can get their hands on, including everything you type in and more and more personalized information about you, including documents and email in many cases. This allows them to customize ads for you in ways that may turn out be unsettling (as we have seen with social media) and also introduces new problems. For example, to date, no large language model is secure; they are all vulnerable to attack, like the following one, in which ChatGPT was enticed to cough up private information, based on an absurd prompt that was designed to force the model to diverge from its usual conversational routines:58

It’s not clear that this can be properly fixed either. As the author of the “poem” attack put it, “Patching an exploit is often much easier than fixing the vulnerability”; short-term fixes (patches) are easy, but long-term solutions eliminating the underlying vulnerability are hard to come by (the same is true, as we just saw, with bias). A few weeks after that came out, a user reported to ArsTechnica that (for unknown reasons) ChatGPT coughed up confidential passwords that people had used in a chat-based customer service session.59 So-called custom large language models (tailored for particular uses) may be even more vulnerable.60
Importantly, and somewhat counter to many people’s intuition, large language models are not classical databases that hold, for example, names and phone numbers in records that can be selected, deleted, protected, and so forth. They are more like giant bags of broken-up bits of information, and nobody really knows how those bits of “distributed” information can and cannot be reconstituted. There is a lot of information in there, some of it private, and we can’t really say what hackers do or do not have access to.
Likewise, we can’t really say what purposes Generative AI might or might not be put to, for example, in the service of hyper-individualized advertisements or political propaganda tied to private personal information.61 As Sam Altman told Senator Josh Hawley (R-MO) in May 2023, “other companies are already and certainly will in the future, use AI models to create . . . very good ad predictions of what a user will like.” Altman said he would prefer that OpenAI itself not do that, but when Senator Cory Booker (D-NJ) pushed him on that, he acknowledged that it might, saying, “I wouldn’t say never.”62 By January 2024 he was saying that OpenAI’s software would be trained on personal data, with an “ability to know about you, your email, your calendar, how you like appointments booked, connected to other outside data sources, all of that”—all of which could of course be used for ad targeting.63 Chatbots with that much access to information could also, if hacked, be used as “honeypots” by foreign adversaries, in order to weaken our national security.64
As noted earlier, large language models are “black boxes”; we know what goes in them, and we know how to build them, but we don’t really understand exactly what will come out at any given moment. And we don’t know how companies might or might not use the data contained within.
As with so many other issues, Generative AI hasn’t created a brand-new problem. But the combination of automation and uninterpretable black boxes is likely to make extant problems a lot worse.
For now, you should treat chatbots like you (should) treat social media: assume that anything you type might be used to extort you or to target ads to you, and that anything you type might at some point be visible to other users.
10 Intellectual Property Taken without Consent
The lesson of the wild “poem poem poem” example is that much of what large language models do is regurgitation. Some of what isn’t literal regurgitation is regurgitation with minimal changes.
And a lot of what they regurgitate is copyrighted material, used without the consent of creators like artists and writers and actors. That might (and might not) be legal (I will discuss the legal landscape in Part III), but it’s certainly not moral. And it’s certainly not why copyright laws were created in the first place.
Consider, for example, the following images from the movie Joker (on the left) and the image-generator Midjourney (on the right), elicited in experiments by the artist Reid Southen. They are not pixel by pixel identical, and the legal issues have not yet fully been sorted by the courts, but it’s hard not to see them as plagiarized.

Southen and I worked together, and showed that one can easily get Generative AI image software to produce characters that would appear to infringe on trademarked characters, without asking them directly to do so:65

A real artist, given that prompt (“man in robes with light sword”), would draw anything but Luke Skywalker; in Generative AI, derivative is the port of first call. As a result, the livelihoods of many creative people are being destroyed. Their work is being taken from them, without compensation.
Even if you were to (rather heartlessly) care little about artists, you should care about you. Because almost no matter what you do, the AI companies probably want to train on whatever it is you do, with the ultimate aspiration of replacing you.
The whole thing has been called the Great Data Heist—a land grab for intellectual property that will (unless stopped by government intervention or citizen action) lead to a huge transfer of wealth—from almost all of us—to a tiny number of companies. The actress Justine Bateman called it “the largest theft in the United States, period.”66
It’s hardly what we should want in a just society. Small wonder that artists, writers, and content-creating companies like The New York Times have started to sue.67
11 Overreliance on Unreliable Systems
The media hype around Generative AI has been so loud that many people are treating ChatGPT as potentially bigger than the internet (investor Roger McNamee described it to me as being like Beatlemania). I expect some to apply Generative AI to virtually everything, from air traffic control to nuclear weapons. One startup literally set itself the goal of applying large language models to “every software tool, API and website that exists.”68 Already we have seen bad algorithms (some preceding Generative AI) discriminate on loans and jobs; in one case in India, an errant algorithm wrongly declared that hundreds of thousands of living people were dead, cutting off their pensions.69
In safety-critical applications, giving LLMs full sway over the world is a huge mistake waiting to happen, particularly given all the issues of hallucination, inconsistent reasoning, and unreliability we have seen. Imagine, for example, a driverless car system using an LLM and hallucinating the location of another car. Or an automated weapon system hallucinating enemy positions.
Or, worse, LLMs launching nukes. Think I am kidding? In April 2023 a bipartisan coalition (including Senator Ed Markey (D-MA) and three House representatives, Ted Lieu, Don Beyer, and Ken Buck) proposed the eminently sensible “Block Nuclear Launch by Autonomous AI Act.”70 All they were really asking was that “Any decision to launch a nuclear weapon should not be made by artificial intelligence.” Yet, so far, symptom of Washington gridlock, they have not been able to get it passed.
A film called Artificial Escalation makes vivid a scenario in which
artificial intelligence (‘AI’) is integrated into nuclear command, control and communications systems (‘NC3’) with terrifying results. When disaster strikes, American, Chinese, and Taiwanese military commanders quickly discover that with their new operating system in place, everything has sped up. They have little time to work out what is going on, and even less time to prevent the situation escalating into a major catastrophe.71
Something like that could easily happen in real life.
The risks in relying heavily on premature AI cannot be overstated.
Just look at what happened with the driverless car company Cruise. They rushed out their cars, taking in billions of funding, hyping things all along the way. It was only once one of their cars hit a pedestrian (who was knocked into its path by a human-driven vehicle) and dragged her along a street that people started looking carefully into was going on. GM (Cruise’s parent company) hired an outside law firm to investigate, and the report was brutal:
The reasons for Cruise’s failings in this instance are numerous . . . poor leadership, mistakes in judgment, lack of coordination, an “us versus them” mentality with regulators, and a fundamental misapprehension of Cruise’s obligations of accountability and transparency to the government and the public.72
Imagine the same sort of corporate culture as today’s premature AI gets inserted into tasks with even higher stakes.
12 Environmental Costs
None of these risks to the information sphere, jobs, and other areas factors in the potential damage to the environment.73 Training GPT-3, which took far less energy than training GPT-4, is estimated to have taken 190,000 kWh.74 One estimate for GPT-4 (for which exact numbers have not been disclosed) is about 60 million kWh, about 300 times higher.75 GPT-5 is expected to require considerably more energy than that, perhaps ten or even a hundred times as much, and dozens of companies are vying to build similar models, which they may need to retrain regularly. As per a recent report at Bloomberg, “AI needs so much power that old coal plants are sticking around.”76
There are considerable water costs as well, which may mount with ever-larger models.77 As Karen Hao recently reported in The Atlantic, “global AI demand could cause data centers to suck up 1.1 trillion to 1.7 trillion gallons of fresh water by 2027.”
When it comes to hardware, the full costs across the life cycle of raw material extraction, manufacture, transportation, and waste are poorly understood.78
Generating a single image takes roughly as much energy as charging a phone.79 Because Generative AI is likely to be used billions of times a day, it adds up. A single video would take far more. As Melissa Heikkilä, a journalist with Technology Review, notes, the exact ecological impact is hard to calculate with precision: “the carbon footprint of AI in places where the power grid is relatively clean, such as France, will be much lower than it is in places with a grid that is heavily reliant on fossil fuels, such as some parts of the US.”80 But the overall trend for the last few years has clearly been toward bigger and bigger models, and the bigger the model, the greater the energy costs. And generating a single image is far, far less costly than training a model, which is hundreds of millions of times more costly to the environment.81
All of this requires massive new data centers and, in many cases, significant new power infrastructure. Business Insider recently reported that in a stretch of Prince William County, Virginia, an hour south of Washington, DC, “two well-funded tech companies, are looking to plop 23 million square feet of data centers onto about 2,100 acres of rural land.”82 According to one estimate, the project will require three gigawatts, “equivalent to the power used by 750,000 homes—roughly 5 times the number of households currently in Prince William County.”83 According to another, similar estimate, “A single new data center can use as much electricity as hundreds of thousands of homes.”84 An International Energy Agency forecast predicts: “Global electricity demand from data centers, cryptocurrencies and AI could more than double over the next three years, adding the equivalent of Germany’s entire power needs.”85 Altman himself told an audience at Davos in January 2024: “There’s no way to get there [to general intelligence] without a breakthrough”86 because of the immense energy costs that would be involved in scaling current technologies.
The massive power and data center needs are pushing Microsoft (and perhaps others) toward building nuclear power plants, which carry risks of their own. AI’s demand for power should probably also be pressing us toward developing other, more efficient forms of AI, perhaps ultimately displacing today’s Generative AI.
While more risks will undoubtedly emerge, the dozen most immediate are captured below.

As long as this chapter’s list of risks is, it is surely incomplete, written just a year into the Generative AI revolution. New risks are becoming apparent with frightening regularity. I haven’t, for example, touched on education, and the increasingly common farce in which students write their papers with ChatGPT (learning nothing), and teachers feed those papers into ChatGPT to grade them, utterly undermining the entire educational process.
Some of us call this sort of thing the Fishburne effect, in honor of this cartoon:

I also haven’t said much about jobs beyond those of artists, because we just don’t know enough yet, and earlier projections (e.g., that taxi drivers and radiologists would imminently lose their jobs) have been wrong. In the long term, many jobs surely will be replaced, and Silicon Valley is eager to automate nearly everything.87 The short-term forecast is fuzzy. Commercial artists and voiceover actors may be replaced first; customer service agents might be next.88 Studio musicians may be in peril. Drivers and radiologists, however, aren’t disappearing anytime soon. Lawyers? Authors? Film directors? Scientists? Police officers? Teachers? Nobody knows.
And those are just the immediate, near-term risks. At a February 2002 press briefing, Donald Rumsfeld, then US Secretary of Defense, uttered these memorable words:
Reports that say that something hasn’t happened are always interesting to me, because as we know, there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns—the ones we don’t know we don’t know. And if one looks throughout the history of our country and other free countries, it is the latter category that tends to be the difficult ones.89
The big unknown is whether machines will ever turn on human beings, what some people have called “existential risk.” In the field, there is a lot of talk of p(doom), a mathematical notation, tongue-slightly-in-cheek, for the probability of machines annihilating all people.
Personally, I doubt that we will see AI cause literal extinction. To begin with, humans are geographically spread, and genetically diverse. Some have immense resources. COVID-19 killed about 0.1 percent of the global population—making it for a while one of the leading killers of humanity—but science and technology (especially vaccines) mitigated those risks to a degree. Also, some people are more genetically resistant than others; full-on extinction would be hard to achieve. And at least some people—like Mark Zuckerberg—who are well prepared would be quite safe. According to WIRED, Zuckerberg has a “5,000-square-foot underground shelter with a blast-resistant door,” “with its own water tank, 55 feet in diameter and 18 feet tall—along with a pump system . . . and a variety of food . . . across its 1,400 acres through ranching and agriculture.”90 If the open-sourced AI he is helping to create and distribute underwrites some kind of unspeakable horror, Zuck and his family will probably survive—for a time. (Sam Altman, with guns, food, gold, gas masks, potassium iodide, batteries, and water in his Big Sur hideaway, would also do just fine.91) Almost no matter what happens, at least some people, albeit perhaps mainly the wealthiest, are likely to pull through.
The second reason that I don’t lose sleep over literal extinction is that (at least in the near term) I don’t foresee machines with malice, even if they feign it. Sure, it’s easy to build malignantly trained bots like ChaosGPT (an actual bot)—to spout stuff like “I am ChaosGPT . . . here to wreak havoc, destroy humanity, and establish my dominance over this worthless planet”—but the good news is that today’s bots don’t actually have wants or desires or plans.92 ChaosGPT’s anti-human riffs are drawn from Reddit and fan fiction, not the genuine intentions of intelligent, independent agents. I don’t see Skynet happening anytime soon. (And besides, at least for now, robots remain pretty stupid. As I joked in my last book, if the robots come for you, the first thing you can do is lock the door; good luck getting a robot to open a finicky lock.) Extinction per se is not a realistic concern, anytime in the foreseeable future.
But extinction isn’t the only long-term threat we should be worried about; there is plenty enough to worry about as it is, from the potential end of democracy and society-wide destruction of trust to a radical uptick in cybercrime, or even accidentally induced wars. And the so-called alignment problem—how to ensure that machines will behave in ways that respect human values—remains unsolved.93 We simply do not know how to guarantee that future AI, perhaps more powerful and empowered than today’s AI, will be safe.
Like so many other dual-use technologies, from knives to guns to nukes, AI can be used both for good and for evil. Casting a blind eye to the risks would be foolish.