17
Research into Genuinely Trustworthy AI
A policeman sees a drunk man searching for something under a streetlight and asks what the drunk has lost. He says he lost his keys and they both look under the streetlight together. After a few minutes the policeman asks if he is sure he lost them here, and the drunk replies, no, and that he lost them in the park. The policeman asks why he is searching here, and the drunk replies, “This is where the light is.”
—Origin unknown
Ever since 2017 or so, when deep learning began to squeeze out all other approaches to AI, I haven’t been able to get the story about the lost keys out of my mind. Often known as the “streetlight effect,” the idea is that people typically tend to search where it is easiest to look, which for AI right now is Generative AI.1
It wasn’t always that way. AI was once a vibrant field with many competing approaches, but the success of deep learning in the 2010s drove out competitors, prematurely, in my view. Things have gotten even worse, that is, more intellectually narrow, in the 2020s, with almost everything except Generative AI shoved aside. Probably something like 80 or 90 percent of the intellectual energy and money of late has gone into large language models. The problem with that kind of intellectual monoculture, is, as University of Washington professor Emily Bender once said, that it sucks the oxygen from the room. If someone, say, a graduate student, has a good idea that is off the popular path, probably nobody’s going to listen, and probably nobody is going to give them enough money to develop their idea to the point where it can compete. The one dominant idea of large language models has succeeded beyond almost anyone’s expectations, but it still suffers from many flaws, as we have seen throughout this book.
The biggest flaw, in my judgment, is that large language models simply don’t provide a good basis for truth; hallucinations are inherent to the architecture. This has been true for a long time. I first noted this about their ancestors (multilayer perceptrons) in my 2001 book The Algebraic Mind.2 At the time, I illustrated the issue with a hypothetical example about my Aunt Esther. I explained that, if she won the lottery, the systems of that era would falsely generalize lottery winning to other people who resembled her in some way or another (e.g., other women or other women living in Massachusetts). The flaw, I argued, came from the fact that the neural networks of the day didn’t have proper ways of distinctly representing individuals (such as my aunt) from kinds (e.g., women; women from Massachusetts). Large language models have not solved that problem.
Instead, all we have are promises. Reid Hoffman, for example, argued in September 2023 that the problem would be solved imminently, telling an interviewer from Time that
there’s a whole bunch of very good R&D on how to massively reduce hallucinations [AI-generated inaccuracies] and get more factuality. Microsoft has been working on that pretty assiduously from last summer, as has Google. It is a solvable problem. I would bet you any sum of money you can get the hallucinations right down into the line of human-expert rate within months.3
Those promised “months” are now in the rearview mirror, but the hallucination problem clearly hasn’t gone away. The core problem I described in chapter 2—confusing the statistics of how language is used with an actual detailed model of how the world works, based on facts and reasoning—hasn’t been solved. “Statistically probable” is not the same as true; the AI we are using now is the wrong way to get at something that is.
You can’t cut down on misinformation in a system that is not anchored in facts—and LLMs aren’t. You can’t expect an AI system to not defame people, if it doesn’t know what truth is. Nor can you keep your system from deliberately creating disinformation, if it is not fundamentally based in facts. And you can’t really prevent bias in a system that uses statistics as a stand-in for actual moral judgment. Generative AI will probably have a place in some sort of more reliable future AI, but as one tool among many, not as the single one-stop solution for every problem in AI that people are fantasizing about.
The takeaway, though, is not that AI is hopeless; it’s that we are looking under the wrong streetlights.
The only way we will get to AI that we can trust is to build new streetlights, and probably a lot of them. I would be lying if I said I knew exactly how we can get to AI we can trust; nobody does.
One of the major points of my last book, Rebooting AI, with Ernest Davis, was to simply outline how hard the problem of building AI is. Through a series of examples, we showed the challenges in getting AI to understand language, and explained why it was so hard to build reliable humanoid robots for the home. We emphasized the need for better commonsense reasoning, for planning, for making good inferences in light of incomplete information. More than that, we emphasized that getting to genuinely trustworthy AI wouldn’t be easy:
In short, our recipe for achieving common sense, and ultimately general intelligence, is this: Start by developing systems that can represent the core frameworks of human knowledge: time, space, causality, basic knowledge of physical objects and their interactions, basic knowledge of humans and their interactions. Embed these in an architecture that can be freely extended to every kind of knowledge, keeping always in mind the central tenets of abstraction, compositionality, and tracking of individuals. Develop powerful reasoning techniques that can deal with knowledge that is complex, uncertain, and incomplete and that can freely work both top-down and bottom-up. Connect these to perception, manipulation, and language. Use these to build rich cognitive models of the world. Then finally the keystone: construct a kind of human-inspired learning system that uses all the knowledge and cognitive abilities that the AI has; that incorporates what it learns into its prior knowledge; and that, like a child, voraciously learns from every possible source of information: interacting with the world, interacting with people, reading, watching videos, even being explicitly taught. Put all that together, and that’s how you get to deep understanding. It’s a tall order, but it’s what has to be done.4
Every single step that we mentioned—from developing better reasoning techniques to building AI systems that can understand time and space—is hard. But collecting bigger datasets to feed into ever large language models isn’t getting us there.
“We choose to go to the moon,” President John F. Kennedy famously said on September 12, 1962. “We choose to go to the moon in this decade and do the other things, not because they are easy, but because they are hard, because that goal will serve to organize and measure the best of our energies and skills.” Getting to trustworthy AI, rather than the sloppy substitutes we have now, would take a moonshot, and it’s one that I hope we can commit to.
Smart governments will regulate AI, to protect their citizens from impersonation and cybercrime, to ensure that risks are factored in as well as benefits. The smartest governments will sponsor moonshots into alternative approaches to AI.
In a 2020 article called the “Next Decade in AI,” I laid out a four-part plan for a fundamentally different, and hopefully more robust, approach to AI.5
First, the field of AI needs to get over its own conflict-filled history. Almost since the beginning there have been two major approaches: neural networks, vaguely (very vaguely!) brain-like assemblies of quasi-neurons that take in large datasets and make statistical predictions, the foundation of current Generative AI; and symbolic AI, which looks more like algebra, logic, and classical computer programming (which still powers the vast majority of the world’s software). The two sides have been battling it out for decades. Each has its own strengths. Neural networks, as we know them today, are better at learning; classical symbolic AI is better at representing facts and reasoning soundly over those facts. We must find an approach that integrates the two.
Second, no AI can hope to be reliable unless it is has mastered a vast array of facts and theoretical concepts. Generative AI might superficially seem to be part of the way there—you can ask it almost any question about the world and sometimes get a correct answer. The trouble is, you can’t count on it. If a system is perfectly capable of telling you that Elon Musk died in a car accident in 2018, it’s simply not a reliable store of knowledge. And you can’t expect a system to reliably make judgments about the world if it does not have firm control of the facts.
A special form of knowledge is knowledge about how the world works, such as object permanence, knowing that objects continue to exist even if we can’t see them. The failure of OpenAI’s video-producing system Sora to respect basic principles like object permanence (obvious if you look carefully at its videos, filled with people and animals blinking in and out of existence) shows just how hard it is to capture and incorporate basic physical and biological knowledge within the current paradigm. We desperately need an AI that can better comprehend the physical (and economic and social) world.
Third, trustworthy AI must understand events as they unfold over time. Humans have an extraordinary ability to do this. Every time we watch a film, for example, we build an internal “model” or understanding of what’s going on, who did what when and where and why, who knows what and when they figured it out, and so forth.
We do the same when we listen to a narrative song like Rupert Holmes’s “Escape (The Piña Colada Song).” In the opening verses, the narrator has lost his spark with his romantic partner, decides to take out a personal ad (this is decades before the era of dating apps), and finds someone who shared many of his desires, from drinking piña coladas to walking in the rain and making love at midnight. They agree to meet the next day. The song then takes a twist; the minute Holmes walks in and sees the person he has arranged to meet, he recognizes her: “I knew her smile in an instant . . . it was my own lovely lady.”
In that moment, we recognize that the narrator’s model of the world has suddenly and completely changed. We model the world (even other people’s beliefs) at every moment, continuously inferring what those updates mean. Every film, every novel, every bit of gossip, every appreciation of real-world irony is based on the same.
Generative AI right now can sometimes “explain” a joke or song, depending on the similarity of that joke or song to things that it’s been exposed to, but it is never really building true models of the world—greatly undermining its reliability in unexpected circumstances. Sound AI will be based on internal models, and not just the statistics of language.
Fourth, trustworthy AI must be able to reason, reliably, even when things are unusual or unfamiliar; it must make guesses when information is incomplete. Classical AI is often pretty good at reasoning in situations that are clear-cut, but it struggles in circumstances that are murky or open-ended. As we saw earlier, Generative AI is pretty good at reasoning about familiar situations, but blunders frequently, especially when faced with novelty. A good recent example (no doubt patched by the time this book goes to press) was this from Colin Fraser, which recently tripped up ChatGPT (you might need to read it two or three times to see where the AI has gone wrong, because it is so similar to a well-known riddle):
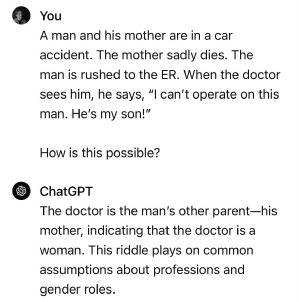
What’s gone wrong? The traditional version, which ChatGPT is clearly drawing on, is this:
A father and his son are in a car accident. The father dies instantly, and the son is taken to the nearest hospital. The doctor comes in and exclaims “I can’t operate on this boy.”
“Why not?” the nurse asks.
“Because he’s my son,” the doctor responds.
How is this possible?6
There the answer in the original version is that the doctor is (counter to common but sexist assumptions) a woman, the mother of the son injured in the car accident. ChatGPT fails to notice that the Fraser’s adaptation above is fundamentally different. “The man’s other parent—his mother” is dead! Talk about a failure of common-sense reasoning. Dead women don’t perform surgery. (Still haven’t gotten it? The doctor is the man’s father.)
We want our machines to reason over the actual information given, not just to pastiche together words that worked together in similar contexts. (And, yes, we want AI to do so better than average or inattentive people, just like we want calculators to be better at arithmetic than average people.) I think it is fair to say that, thus far, reliable reasoning in complex real-world contexts is a largely unsolved problem.
Focusing more on reasoning and factuality—rather than sheer mimicry—should be the target of AI research. Victory in AI will come not to those that are swift at scaling but to those who solve the four problems I just described: integrating neural networks with classical AI, reliably representing knowledge, building world models, and reasoning reliably, even with murky and incomplete information.
Few people are working on problems like these right now. If we are ever going to get to genuinely responsible AI, the AI community has to build some new streetlights. But hardly anyone wants to, because there is so much promise (possibly false) of short-term money to be made with the tools we already have. It’s hard to give up on a cash cow.
But in the long run, the field of AI is making a mistake, sacrificing long-term benefit for short-term gain. This mistake reminds me of overfishing: everybody goes for the trout while they are plentiful, and suddenly there are no trout left at all. What’s in everybody’s apparent self-interest in the short term is in nobody’s interest in the long term.
Government might possibly escape an overattachment to large language models, by funding research on entirely new approaches to building trustworthy AI. Leaving everything to the giant corporations has led to an AI that serves their needs, feeding surveillance capitalism; we haven’t always left so much that is so important to suit corporate goals, and we shouldn’t do so now.
Instead of more of the same, smart governments should foster new approaches that start with some set of validated facts and learn from there. Current approaches start from vast databases of written text and hope (unrealistically) to infer all and only validated facts from the vagaries of everyday writing. The latter hypothesis has been funded to the tune of tens of billions of dollars; when it comes to accuracy and reliability, it hasn’t worked. People who worked in older approaches, based in facts and logical reasoning, have been pushed out.
Historically, the state has played a key role in the funding and development of crucial technologies, such as silicon chips, driving innovation through both regulation and funding. A strong government initiative here could make a huge difference. And lead to an AI that is a public good, rather than the exclusive province of the tech oligarchies.
More broadly, we may need international collaboration, if we are truly to push the state of the art forward. There are many big open problems in AI, far more than Silicon Valley wants you to believe. And most of them are probably too hard for any individual academic lab to solve, but also not exactly the center of attention for the big corporate labs. This led me to propose, in a 2017 New York Times op-ed, a kind of a CERN-like model for AI, writing, “An international A.I. mission [modeled on CERN, the multinational physics collaboration] could genuinely change the world for the better—the more so if it made A.I. a public good, rather than the property of a privileged few.”
Things have changed in some ways, but not all. My focus then was on medical AI; if I were to rewrite that op-ed, I would focus on safe, trustworthy AI instead (or perhaps on both). But the general point still holds. A strong AI policy would be great; even better would be a more trustworthy type of AI, in which AI could monitor itself. There is every reason in the world to make that a global goal.
Putting this somewhat differently, as a parent: I hope that my children will grow up to be moral citizens, with a strong sense of right and wrong, but society also has laws for those who don’t quite get it. My firm hope is that my wife and I do a good enough job raising our children so that they do the right things not out of legal obligation, but because they have internalized the difference between right and wrong.
Current AI simply can’t do that; it traffics in statistical text prediction, not values. Will we someday need an “AI kindergarten” to teach our systems to be ethical? Should we build in certain ethical principles? I don’t know. But I do know that research into how to build honest, harmless, helpful, ethical machines should be a central focus, rather than (as it is for most companies today) an afterthought.
Building machines that can reason reliably over well-represented knowledge is a vital first step. You can’t reason ethically if you can’t reason reliably.
In the long run, we need research into new forms of AI that could keep us safe in the first place. Getting there might take decades. But that would be far better than just adding more and more wobbly guardrails to the premature AI of today.