CHAPTER SEVEN
MEASURES OF RESIDENTIAL COMMUNITY CONTEXTS
Patricia O'Campo and Margaret O'Brien Caughy
This chapter concerns approaches used to characterize communities or neighborhoods within public health research. Research on the influence of community context or residential neighborhoods has increased exponentially in the last decade of the twentieth century (Kawachi and Berkman 2003; Diez-Roux 2000; Duncan, Jones, and Moon 1998; O'Campo 2003). This research has primarily focused upon urban environments, but where available we will include information about non-urban environments such as suburban and rural settings. The literature distinguishes between neighborhood, which usually refers to a geographically bounded area, and community, which often identifies a group of individuals concerned with a common issue (e.g., school issues, crime control, or urban development). Communities can also have a geographic component (e.g., communities concerned with a local school issue) so there is some overlap between the two terms. Even this simplistic description of neighborhood, however, fails to capture the challenges related to ensuring the identification of appropriate geographic boundaries of relevance to residents within neighborhoods or boundaries appropriate for particular health issues. Nevertheless, neighborhoods are thought to possess physical characteristics, social and economic resources (or lack of), and an element of social interaction (positive, negative, or neutral) between residents. It is the measurement of these components of neighborhood that we devote our attention to in this chapter.
Because of the convenience of using data readily available by census units (census tract, census block groups), census designations are often used in the United States and Canada as a proxy for geographically based neighborhoods. While it is clear that residents do not normally consider specific census boundaries to describe the borders of their neighborhoods, emerging research suggests that census units—census block groups and census tracts—are reasonable proxies for neighborhoods (O'Campo 2003; Krieger et al. 2003a, 2003b; Bond-Huie 2001; Ross, Tremblay, and Graham 2004). While there is much concern about the issue of the appropriate unit of analysis or best geographic designation in the literature on “neighborhoods” it is unlikely that a single answer will, or needs, to emerge. However, the trade-offs of using smaller versus larger geographic units of analysis noted extensively in the literature (e.g., Duncan, Jones, and Moon 1998; Raudenbush and Sampson 1999) should be considered when designing a neighborhood study.
Measurement Strategies for Residential Neighborhoods
In order to effectively examine effects of neighborhoods on individual outcomes, careful attention is required as to how characteristics of neighborhoods are operationalized. A variety of approaches have been used in the neighborhood literature, each with its own strengths and weaknesses. We will loosely organize existing sources of neighborhood measures as either subjective measures (based upon individuals' reported perceptions) or so-called objective measures. The most common source of objective data used to operationalize neighborhood characteristics is the census. Census data have been used to provide indicators of socioeconomic position of the neighborhood (e.g., poverty rate, unemployment rate, average household income, etc.), population stability (e.g., the proportion of residents who have moved in the last 5 years, etc.), as well as race/ethnic composition. Some researchers have employed census data as single indicators (Brooks-Gunn et al. 1993; Diez-Roux et al. 1997; O'Campo et al. 1997; Ross 2000), while others have utilized indices that combine information from multiple census variables (Beyers et al. 2003; Caughy, O'Campo, and Muntaner 2003; Malmstrom, Sundquist, and Johansson 1999). Regardless of the specific census variables used or whether they are combined into indices or not, the researcher interested in neighborhood effects should be guided by theory in identifying the best use of census data. Rajaratnam, Burke, and O'Campo (2006) conducted a comprehensive review of the maternal and child health literature between January 1999 and March 2004 and identified 32 research articles that included measurement of neighborhood characteristics. Census data, particularly data regarding economic characteristics, were by far the most frequent data used to characterize neighborhoods. However, few of the articles reviewed by Rajaratnam et al. utilized health-specific theories to explicate why certain census indicators were used. In neighborhood research published since the Rajaratnam et al. review, census data continues to be frequently used to characterize neighborhoods. A search of Medline for publications between 2009 and 2012 identified over 400 citations examining neighborhood context and health outcomes utilizing census data as part of their neighborhood assessment. One of the advances in this area in recent years has been an increase in the number of researchers who have systematically used census data to determine neighborhood boundaries for studies of neighborhoods and health (Drackley, Newbold, and Taylor 2011; Weiss et al. 2007).
There are aspects of census data that have not been capitalized upon in the extant neighborhood research literature. Few researchers have utilized historical census data to capture the manner in which neighborhoods may have changed over time. For example, data from the 1970, 1980, 1990, and 2000 censuses regarding poverty rates could be used to identify neighborhoods that have experienced significant declines, improvements, or change in recent decades. Relying on cross-sectional data of neighborhoods masks the fact that neighborhoods are dynamic, and the change experienced in a neighborhood over time may be more important, or at least as important as, its status at a single point in time.
Another approach to capturing neighborhood dynamics is to measure neighborhoods longitudinally in a prospective fashion, although such an approach is rare. One example is the Neighborhood Change Research Initiative, an effort to collect neighborhood data before, during, and after an infusion of a significant amount of public investment (see Leonard et al. 2011 for a description of the project). However, such efforts are resource intensive and rely upon capturing naturally occurring events that result in more rapid neighborhood change than might occur under normal circumstances, making it difficult to implement this approach on a large-scale basis. Despite these limitations, measuring neighborhoods longitudinally in a prospective manner should be considered in situations when neighborhoods might be changing dramatically, as in after a natural disaster such as a flood or tornado.
Another aspect of census data that has not been exploited is the variability within neighborhoods. Most operational measures of neighborhoods utilizing census data have relied on measures of central tendency, such as average household income. Income inequality theorists suggest that disparities in economic resources between individuals may be an important explanatory factor for understanding social inequalities in health outcomes. Likewise, inequalities within neighborhoods may be important because they may undermine social cohesion and collective efficacy, neighborhood social processes that have been suggested as important mediators of neighborhood effects (Franzini et al. 2011; Nettles, Caughy, and O'Campo 2008; Samson 1991, 1992).
Although census data are the most often exploited of the objective sources of neighborhood data, they are not the only sources. Administrative data sources such as crime data, liquor license data, tax parcel data, and city data on housing violations are all examples of sources of objective data that may be useful in operationalizing neighborhood context. Flowerdew, Manley, and Sabel (2008) used public records to identify all of the retail food outlets in a large number of neighborhoods they were studying. However, just as with census data, the investigator's theory regarding how neighborhoods affect individuals should guide the selection of which measures to use and how they should be formulated (Rajaratnam, Burke, and O'Campo 2006; Messer et al. 2006). For example, crime data can be utilized in a variety of different formats. Should one include all crimes or only “serious” crimes such as murder or rape? Should crimes against property (burglary, auto theft, etc.) be considered separately from crimes against people? Should the crime variable be calculated to represent the number of crimes per capita or the number of crimes per square mile? The driving force behind these decisions should be the investigator's theory regarding how crime is related to individual health and well-being. For example, one may hypothesize that the negative effects of crime are mediated by the stress created by living in crime-ridden areas. However, there is empirical evidence that individual perceptions of crime may be inconsistent with actual crime rates. Taylor (2001) reports that Baltimore residents perceived that crime was increasing during a period of time when rates were actually falling. His conclusion was that these perceptions were driven more by discrepancies between the city of Baltimore and the surrounding metropolitan area than by the actual crime rates themselves. If a researcher is interested in stress-related reactions to neighborhood crime, focusing on discrepancies between area crime rates and surrounding areas may be a more fruitful approach.
Observational Measures of Neighborhoods
Another objective measure of neighborhoods that has been used less frequently is systematic observation of the neighborhood context. Observational methods used have ranged from making videotapes while driving through the neighborhood and coding them at a later time (Raudenbush and Sampson 1999) to shorter “windshield” assessments (so-called because the neighborhood is observed and coded while driving through) (Laraia et al. 2006) or checklists that are coded while walking through the neighborhood on foot (Caughy, O'Campo, and Patterson 2001; Parsons et al. 2010). Observations allow one to characterize neighborhoods in terms of factors that are not captured in routine data sources such as the census. Most frequently, neighborhood observations have been used to collect data regarding physical incivilities, such as trash, graffiti, and/or boarded-up homes. In addition, some researchers have used observations to collect data on social incivilities such as drug dealing or other illegal activity, levels of social interaction, and/or resources in the neighborhood, such as facilities for child play.
Although collecting observational data provides an opportunity for characterizing neighborhoods in a much richer way as compared to that provided by routine data sets, the collection and analysis of these data provides its own unique set of challenges. The timing of data collection should be considered, especially with regards to observing social interaction and other human behavior. Qualitative data have extensively documented that patterns of activity in neighborhoods often vary significantly across the day, both in terms of volume of activity as well as the characteristics of the individuals out and about in the neighborhood (Burton and Price-Spratlen 1999). Neighborhood activity level is also affected by time of year, with outdoor activity more likely when weather permits. The relevance of these neighborhood characteristics to the particular research question should be paramount in determining the timing of data collection. For example, if the objective is to observe social interactions of children in the neighborhood, scheduling observations during weekday school hours would be problematic. Likewise, if observing illegal drug activity is a high priority for the researcher, scheduling observations during morning hours would likely give a skewed view of such activity in the neighborhood. One option is to standardize observation times across the neighborhoods being observed to avoid confounding the neighborhood measures with time of assessment. Other researchers have used time of day as a covariate in analyses utilizing observational data to address this issue (Raudenbush and Sampson 1999).
Data reduction of neighborhood observational data provides another set of challenges. A systematic review of the SSO literature by Schaefer-McDaniel and colleagues (2010) highlighted the wide range of analytic methods used, which has complicated the comparison of findings across studies. Some researchers have used complex analytic models to estimate the probability of different latent constructs at a larger geographic unit such as a census block group (Raudenbush and Sampson 1999; Caughy, O'Campo, and Patterson 2001). Other researchers have created simple summary measures for the block on which the respondent lives. For example, Kohen et al. (2002) rated the traffic; garbage and litter; people loitering, arguing, or intoxicated; and the general condition of buildings for an area 500 feet in either direction from the respondents' homes. Differing levels of aggregation of observational data may have differing implications depending upon the health or well-being outcome under examination. Leonard and colleagues (2011) report that observed neighborhood conditions were significantly related to self-reported health status for data at the parcel, face block, and census tract level but not at the census block or census block group level. Likewise, Flowerdew et al. (2008) also examined how different definitions of neighborhoods affected the relation between neighborhood conditions and self-reported limiting long-term illness and found that different neighborhood definitions produced differing results. These findings underscore the importance of carefully considering the unit of observation when examining the relation between observed neighborhood characteristics and health.
Additional research is needed to explore how observational measures of neighborhoods perform in a variety of settings, both urban and rural. To date, the use of such measures has been almost wholly limited to urban areas, primarily in cities in the Northeast (Messer et al. 2006; Schaefer-McDaniel 2010). Virtually no application of these observational measures in rural areas has been conducted. In addition, few studies have used the same measures, limiting our ability to compare findings across investigations. Laraia et al. (2006) compared application of the same tool in an urban area in the South with the tool reported by Caughy et al. (2001) and found very different neighborhood environments than those in Baltimore. In another study, Smith and colleagues (2009) collected observational data on the availability of fruits and vegetables in grocery stores in 205 neighborhoods across Scotland to examine the relation between neighborhood economic deprivation and access to sources of healthy food. They found that individuals living in economically deprived urban areas had better access compared to individuals living in non-deprived areas, but that the association was the opposite for rural areas.
Recent developments in information technology have implications for the collection of neighborhood observational data. Odgers and colleagues (2012) recently reported on the use of Google Street View to conduct systematic social observation of neighborhoods in Great Britain. They implemented the Google Street View approach to observe neighborhoods of over 1000 families living throughout England and Wales. Initial results showed that many of the indicators observed through a “walk-through” observation of a neighborhood could be reliably measured using Google Street View, and that composite measures of neighborhood conditions based on Google Street View were associated in expected directions with measures of child health and well-being. Although future research using this approach is needed, it holds promise for collecting more comprehensive neighborhood data on physical features with fewer resources than would be needed to conduct using person observations.
Measures on Perceptions of Neighborhoods
Subjective measures of the neighborhood environment have been extensively used in research on neighborhood effects. In most cases, neighborhood residents who are part of the study were asked to report their perceptions of their neighborhood or their neighbors with regards to a variety of dimensions such as safety, physical and social disorder in the community, degree of connectedness between community residents, and/or perceptions regarding the degree that community members were willing to act collectively on behalf of the community as a whole. The research community has amassed a growing body of evidence on what Robert Sampson, a sociologist, initially coined collective efficacy (Sampson, 1991, 2003; Sampson, Raudenbush, and Earls 1997). Sampson (1991) defined collective efficacy as the “linkages of mutual trust and the shared willingness to intervene for the common good” of the community (p. 10) and as being comprised of two components: social cohesion, or the sense of connectedness, and informal social control, the willingness to intervene in community problems. Sampson and his colleagues have developed a neighborhood perceptions measure in their work with the Project for Human Development in Chicago Neighborhoods (Earls 1999). In addition, neighborhood perceptions measures have been reported by Buckner (1998), Chavis and Pretty (1999), Coulton and her colleagues (1996), and McGuire (1997). Although specific items and constructs differ across the individual measures, most of them attempt to tap into some aspect of social cohesion and informal social control, and some go further by tapping into physical and social disorder, patterns of social interaction and mutual exchange, community involvement, and utilization of and satisfaction with community resources.
Perceptions of neighborhood climate and social processes represent data that cannot be obtained in any way other than by interviewing individuals who live in the neighborhood. However, certain analytic issues must be kept in mind when relying upon perceptions data as a way of measuring neighborhood context. First, each respondent can be viewed as an imperfect “informant” about the neighborhood in which he or she lives. Raudenbush has described the analytic issues of dealing with such data collected to assess characteristics of schools (Raudenbush, Rowab, and Kang 1991) as well as neighborhoods (Raudenbush and Sampson 1999). The accuracy of a neighborhood informant is affected by his length of residence in the neighborhood as well as personal characteristics such as psychological well-being, socioeconomic position, and marital status among other things (Franzini et al. 2008). Individuals who moved to a neighborhood recently would have a different length of experience in the neighborhood and therefore different perceptions of neighborhood social processes or opportunities to develop social networks in the community. Individuals who are psychologically depressed may have perceptions that are skewed as a function of their own mental health status.
Care must be taken when using neighborhood perceptions data to create neighborhood-level variables. One approach that is frequently used is to aggregate the individual responses of neighborhood residents to create a neighborhood-level average for each variable or construct. The problem with this approach is that it does not account for the measurement error inherent in each individual's response as a function of length of residence in the neighborhood, psychological status, and/or other individual factors. One approach to address this issue includes incorporating individual-level variables into the analysis that the investigator believes influence perceptions of the neighborhood, such as a measure of the individual's psychological status. Another method is to use random effects analytic approaches (Goldstein 1995; Bryk and Raudenbush 1992; Muthen and Muthen 1998), which separate the variance in neighborhood perceptions between neighborhoods from the variance in neighborhood perceptions between individuals in the same neighborhood.
The researcher should also consider carefully how the perceptions variables are operationalized when they are included in the analysis. The form of the variable should be dictated by the theory the researcher has regarding the nature of the relationship between the neighborhood variable and the outcome of interest. For example, utilizing a variable in continuous form assumes that the relationship with the outcome is linear as well as similar along the entire continuum of the neighborhood variable. Perhaps, on the other hand, the true form of the relationship is a “threshold” effect. That is, any relationship between the conditions in the neighborhood and health outcomes is only observed at certain extreme levels, either low or high. For example, social cohesion is a characteristic of neighborhoods that is often considered to be protective of good health and positive outcomes (Ross 2000; Cattell 2001; Franzini et al. 2005). However, it may be that the protective effects of neighborhood cohesion for a particular health problem are only seen once a certain threshold is achieved, with levels above that being inconsequential. If, in this situation, the neighborhood variable is incorporated in the analysis as a continuum rather than a binary variable to capture the threshold effect, any association between the neighborhood social processes and that health problem will be missed. In our own work, we have found that very low levels of psychological sense of community (a construct similar to social cohesion) was predictive of child mental health outcomes whereas the continuous form of the measure was unrelated (Caughy, O'Campo, and Muntaner 2003).
Another issue regarding neighborhood perceptions data is the agreement, or lack thereof, with objective measures that tap the same neighborhood characteristics.
There have been a number of studies examining the level of agreement between self-reports and objective measures of neighborhoods ranging from proximity to parks (Lackey and Kaczynski 2009), walking times (Dewulf et al. 2012), quality of green environments (de Jong et al. 2012), neighborhood design and built environment (Michael et al. 2006; Kamphuis et al. 2010), and in our own work, physical disorder (Franzini et al. 2008). Most studies, often using Kappa statistics, have found agreements to be quite low. Some have been able to identify individual characteristics that partially explain variability such as those who are more physically active having higher agreement between subjective and objective walking times (Dewulf et al. 2012). We found that among persons in the same neighborhood, perceptions of disorder varied by both individual characteristics such as frequency of moves, education, and marital status as well as neighborhood factors such as poverty and racial composition.
In each of the above studies, objective data came from a variety of sources that may further contribute to variation on agreement with self-reported perceptions. Moreover, studies have not fully considered other determinants of agreement such as the degree of heterogeneity within a block group. If physical disorder varies widely from one part of a block group to another, then a summary measure estimated for the block group may not agree with how an individual perceives the neighborhood immediately surrounding his or her home. In our own work, we examined two sizes of neighborhoods—one summary measure for a cluster of six or seven streets surrounding the participant's house and another summary measure for the face block on which the participant lived. The level of agreement between perceived disorder and observed disorder did not improve when the geographic area was smaller. For the cluster of six or seven streets, the level of agreement between perceived and observed disorder was 0.34. For the individual block on which the participant lived, the level of agreement between perceived and observed physical disorder was 0.25.
The obvious lack of agreement between objective measures of neighborhood context and residents' perceptions of those same neighborhood characteristics forces the researcher to critically consider the mechanisms underlying neighborhood effects on individual well-being. If neighborhoods affect health, there must be a mechanism whereby conditions of the neighborhood, conditions which by definition are external to the individual, are translated into differences in physiological and/or psychological processes internal to individual residents. Whether neighborhood effects are derived from physical exposure to risk factors (such as environmental pollutants or conditions that increase risk of injury) and/or the effects of neighborhood stress in compromising individual psychological well-being, different mechanisms have different implications for understanding and dealing with the discrepancy between observed neighborhood characteristics and perceived neighborhood characteristics. In cases in which psychological effects are believed to mediate neighborhood effects on individual health and well-being, how individuals perceive the conditions of their neighborhood may be more important than an objective assessment of those conditions by an outsider. The characteristics that predict differences in perceptions of neighborhood context among individuals living in the same neighborhood need to be systematically investigated. Furthermore, researchers need to expand their conceptualization regarding how neighborhoods affect individual health outcomes. Roosa et al. (2003) have proposed a “transactional” model of neighborhood influences. According to this model, individuals are not passive recipients of neighborhood influences, and nor is the direction of influence solely from neighborhoods to individuals. Rather, residents are “active cognizers and constructors of their environments” and their responses to the neighborhood environment are a function of that transactional process. The lack of congruity between objective neighborhood assessments and perceptions of the neighborhood environment by its residents is a concrete example of how individuals actively evaluate and cope with the neighborhood environment in which they live.
Bringing in the Community Perspective
The literature concerning neighborhood effects on individual health has almost exclusively been conducted without input from those who reside within these community settings. As noted earlier, these multilevel neighborhood studies have often lacked a strong conceptual foundation linking neighborhood characteristics to individual-level risks and outcomes (Rajaratnam, Burke, and O'Campo 2006; Shankardass and Dunn 2012). While social epidemiologists have consulted the social sciences—criminology, social geography, community psychology, sociology—as a source of theory and conceptual information about neighborhood processes, the processes identified are often most relevant to non-health outcomes such as delinquency, school dropout, and teen pregnancy (e.g., Taylor 2001; Sampson, Morenoff, and Raudenbush 1999; Taylor, Gottfredson, and Brower 1984; Crane 1991). However, social epidemiologists should begin to develop frameworks and testable hypotheses regarding the pathways of neighborhood environments to individual well-being that are specific to processes that affect health. There has been recent recognition of the importance of “lay knowledge” in facilitating a greater understanding about the importance and meaning of “place” (Burke et al. 2005; O'Campo et al. 2005). Popay et al. (2003) notes that lay knowledge about the “meanings people attach to their experience of places and how this shapes social action ….” may provide the “missing link in our understanding of the causes of inequalities in health.”
The community perspective can provide complementary knowledge to that generated by researchers as neighborhood residents possess “lived experience” of their environments. In addition to identifying important neighborhood factors impacting health, community residents often provide detailed information about the pathways by which these factors exert their influence. Through key informant interviews with neighborhood residents, Garvin and colleagues (2012) explored the health impacts of vacant lots in urban settings. In addition to the physical hazards of vacant properties due to trash buildup or concentration of rodents, residents reported that abandoned lots can overshadow positive community features and promote residential fear or attract crime. Yen et al. (2007) used qualitative methods to capture women's perceptions of resources and hazards in communities and found that the distinctions were sometimes blurred; fast-food restaurants were reported to sometimes be convenient and inexpensive or parks were reported as being dangerous at times. In a rare focus on rural settings, Kegler and colleagues (2008) reported that community residents reported a lack of recreational facilities as a barrier to physical activity.
The case of research on neighborhood effects on intimate partner violence provides a good case example of how community input can complement and advance existing knowledge. Published studies on neighborhood effects and the risk of intimate partner violence consistently report that low neighborhood socioeconomic position is associated with a higher risk of partner violence (Cunradi et al. 2000; Grisso et al. 1999) and early studies have examined additional neighborhood characteristics such as high levels of collective efficacy serving as a protective factor against partner violence (Browning 2002) and high levels of neighborhood mobility increasing the risk of partner violence Grisso et al. 1999). More recent research has identified neighborhood-level cultural norms, immigrant concentration, alcohol outlets, and residential instability as determinants of partner violence (Daoud et al. 2012; Pinchevsky and Wright 2012; Cunradi 2010). Yet, taken together, the breadth of neighborhood characteristics that have been examined in relation to intimate partner violence is narrow and cannot begin to contribute to a comprehensive understanding of how neighborhoods affect the risk of partner violence, a characteristic that is shared with the more general literature on neighborhoods and health (O'Campo 2003; Burke, O'Campo, and Peak 2006).
To gain the perspective of residents on neighborhood factors and intimate partner violence, participant-driven methods of concept mapping to obtain data on how characteristics of neighborhoods are related to IPV were investigated (O'Campo et al. 2003). Briefly, the concept mapping research involved over seven hours of discussion with participants about neighborhoods and intimate partner violence (Burke et al. 2005).
While the published literature has examined fewer than 10 neighborhood characteristics, participants listed between 50 and 100 neighborhood characteristics that were important for intimate partner violence. Many of the characteristics were related to each other and, upon statistical analyses using multidimensional scaling and hierarchical cluster analyses, were grouped into clusters of similar items; for our urban sample, for example, concept mapping yielded seven clusters of the neighborhood items that were related to perpetration, severity, and cessation of violence (see Figure 7.1). The dots on the figure are the 50 or so items within each of the seven clusters. Those items and clusters closer together in Figure 7.1 are more closely related to each other. For example, the two clusters “communication networks” and “community enrichment resources” are more closely related to one another than the two clusters of “communication networks” and “deterioration contributors,” as indicated by the distance between the clusters.
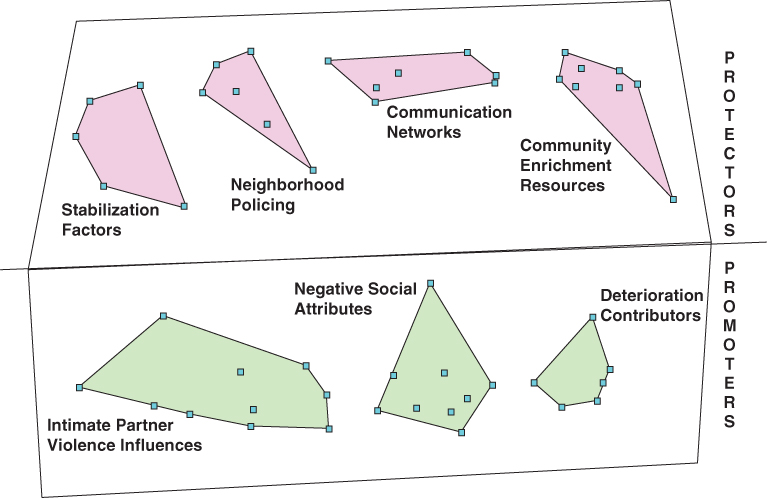
FIGURE 7.1 CLUSTER MAP FROM CONCEPT MAPPING OF URBAN NEIGHBORHOOD FACTORS AND INTIMATE PARTNER VIOLENCE
Participants identified items as being “promoters” of as well as “protectors” from IPV. Participants also rated the importance of these items and clusters of items for IPV perpetration, severity, and cessation. Results show that those factors important for perpetration of IPV were similar to those important for severity, but were not the same factors that were critical for cessation of IPV (O'Campo et al. 2005).
Finally, the participants, in small discussion groups, created figures that represented the pathways by which these clusters of items were related to intimate partner violence (see Figures 7.2 and 7.3). Some diagrams represented straightforward “chain” relationships between items such as for stabilization factor items and their relationship to IPV cessation (Figure 7.2), whereas some groups perceived more complex relationships between items (Figure 7.3). Here, neighborhoods with many “families with young children” positively influenced neighborhood “cultural norms,” which, in turn, created more people in the neighborhood who “intervened” and, ultimately, less IPV. The participants who drew the diagram intentionally used curved arrows to suggest that the relationships between the factors were not direct but are dynamic, complex, and potentially influenced by other factors (not identified in the diagram). In this diagram, “income and wealth” also influence neighborhood norms.
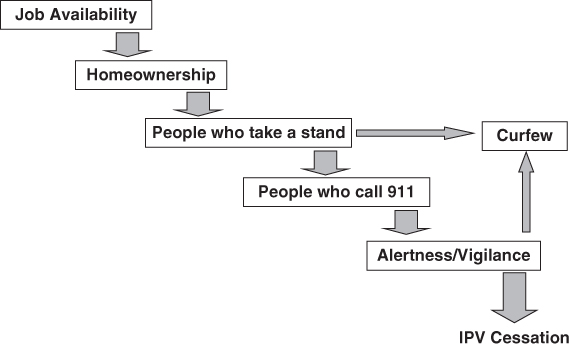
FIGURE 7.2 NEIGHBORHOOD STABILIZATION FACTORS AND IPV CESSATION. DIAGRAM OF THE RELATIONSHIP BETWEEN ITEMS DRAWN BY PARTICIPANTS
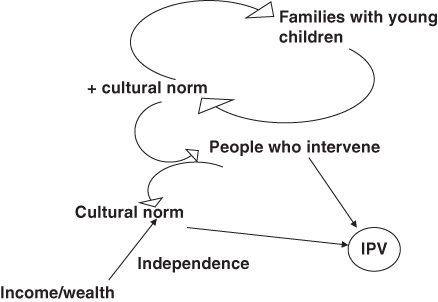
FIGURE 7.3 NEIGHBORHOOD MONITORING CLUSTER AND IPV
This type of research with community residents may yield a missing perspective on neighborhood influences from those with lived experiences. This research can identify gaps in current research on community. In particular, one major gap in the literature on neighborhoods and health is an absence of focus on the conceptualization and operationalization of community characteristics with intervention potential (Pearce and Maddison 2011; Shankardass and Dunn 2012). Rather, the focus is usually on community-level risk factors for adverse health outcomes. In this concept mapping study, numerous neighborhood characteristics, including those with intervention potential, were identified by community residents that researchers have, to date, not yet examined. Moreover, the information about the perceived pathways from neighborhoods to IPV contributes to the design of testable hypotheses about neighborhoods and individuals.
Future Directions on Measuring Neighborhood Environments
Since the adoption within public health of multilevel modeling of residential neighborhoods on health outcomes, major methodological gains have been made in a short period of time. Hopefully, the methodological advancements will continue to improve our understanding of whether and how residential neighborhoods affect health and perhaps, moving forward, community-level interventions to modify risks and adverse health outcomes. Social epidemiologists should move beyond their overreliance on census data as the primary and sole source for characterizing neighborhoods. Moreover, more research should draw upon and develop relevant health-specific theories. Use of such theories should be the primary driving force in determining which neighborhood characteristics of multilevel models are studied and how to operationalize them. To ensure that such studies ultimately contribute to intervention and policy design, this body of research must begin to tease apart the mechanisms of neighborhood effects and focus explicitly on neighborhood change. Finally, the community perspective has been virtually excluded from neighborhood research up to this point. Incorporating the community perspective in social epidemiology theories and hypotheses regarding neighborhoods is essential for developing effective and viable community-level interventions.
References
- Beyers, J.M., et al. (2003) Neighborhood structure, parenting processes, and the development of youths' externalizing behaviors: a multilevel analysis. American Journal of Community Psychology, 31 (1–2), 35–53.
- Bond-Huie, S. (2001) The concept of neighborhood in health and mortality research. Sociological Spectrum, 21, 341–358.
- Brooks-Gunn, J., et al. (1993) Do neighborhoods influence child and adolescent development? American Journal of Sociology, 99 (2), 353–395.
- Browning, C. (2002) The span of collective efficacy: extending social disorganization theory to partner violence. Journal of Marriage and Family, 64, 833–850.
- Bryk, A.S. and Raudenbush, S.W. (1992) Hierarchical Linear Models: Application and Data Analysis Methods, Sage, Newbury Park, CA.
- Buckner, J.C. (1988) The development of an instrument to measure neighborhood cohesion. American Journal of Community Psychology, 16 (6), 771–790.
- Burke, J., et al. (2005) An introduction to concept mapping as a participatory public health research method. Quality Health Research, 15 (10), 1392–1410.
- Burke J., O'Campo, P., and Peak, G. (2006) Neighborhood influences and intimate partner violence: does geographic setting matter? Journal of Urban Health, 83 (2), 182–194.
- Burton, L.M. and Price-Spratlen, T. (1999) Through the eyes of children: An ethnographic perspective on neighborhoods and child development, in Cultural Processes in Child Development. The Minnesota Symposia on Child Psychology (ed. A.S. Masten), Lawrence Erlbaum Associates, Inc., Publishers: Mahwah, NJ, p. 77–96.
- Cattell, V. (2001) Poor people, poor places, and poor health: the mediating role of social networks and social capital. Social Science and Medicine, 52 (10), 1501–1516.
- Caughy, M.O.B., O'Campo, P.J., and Muntaner, C. (2003) When being alone might be better: neighborhood poverty, social capital, and child mental health. Social Science and Medicine, 57, 227–237.
- Caughy, M.O.B., O'Campo, P., and Patterson, J. (2001) A brief observational measure for urban neighborhoods. Health and Place, 7, 225–236.
- Chavis, D.M. and Pretty, G. (1999) Sense of community: advances in measurement and application. Journal of Community Psychology, 27 (6), 635–642.
- Coulton, C.J., Korbin, J.E., and Su, M. (1996) Measuring neighborhood context for young children in an urban area. American Journal of Community Psychology, 24 (1), 5–33.
- Crane, J. (1991) Effects of neighborhoods on dropping out of school and teenage childbearing, in The Urban Underclass (eds C. Jencks and P.E. Peterson), The Brookings Institute, Washington, DC, pp. 299–321.
- Cunradi, C.B. (2010) Neighborhoods, alcohol outlets and intimate partner violence: addressing research gaps in explanatory mechanisms. International Journal of Environmental Research in Public Health, 7 (3), 799–813.
- Cunradi, C.B., et al. (2000) Neighborhood poverty as a predictor of intimate partner violence among white, black, and Hispanic couples in the United States: a multilevel analysis. American Journal of Epidemiology, 10 (5), 297–308.
- Daoud, N., et al. (2012) Neighbourhood context and abuse among immigrant and non-immigrant women in Canada: findings from the Maternity Experiences Survey. International Journal of Public Health, 57 (4), 679–689.
- de Jong, K., et al. (2012) Area-aggregated assessments of perceived environmental attributes may overcome single-source bias in studies of green environments and health: results from a cross-sectional survey in southern Sweden. Environmental Health, 10, 4.
- Dewulf, B., et al. (2012) Correspondence between objective and perceived walking times to urban destinations: influence of physical activity, neighbourhood walkability and socio-demographics. International Journal of Health Geographics, 11, 43.
- Diez-Roux, A.V. (2000) Multilevel analysis in public health research. Annual Review of Public Health, 21, 171–192.
- Diez-Roux, A.V., et al. (1997) Neighborhood environments and coronary heart disease: a multilevel analysis. American Journal of Epidemiology, 146 (1), 48–63.
- Drackley, A., Newbold, B., and Taylor, C. (2011) Defining socially-based spatial boundaries in the Region of Peel, Ontario, Canada. International Journal of Health Geographics, 10, 38.
- Duncan, C., Jones, K., and Moon, G. (1998) Context, composition and heterogeneity: using multilevel models in health research. Social Science and Medicine, 46 (1), 97–117.
- Earls, F. (1999) Project on Human Development in Chicago Neighborhoods: Community Survey, Harvard Medical School, Boston, MA.
- Flowerdew, R., Manley, D.J., and Sabel, C.E. (2008) Neighbourhood effects on health: does it matter where you draw the boundaries? Social Science and Medicine, 66 (6), 1241–1255.
- Franzini, L., et al. (2005) Neighborhood economic conditions, social processes, and self-rated health: a multilevel latent variables model. Social Science and Medicine. Social Science and Medicine, 61(6), 1135-1150
- Franzini, L., et al. (2008) Perceptions of disorder: contributions of neighborhood characteristics to subjective perceptions of disorder. Journal of Environmental Psychology, 28, 83–93.
- Garvin, E., et al. (2012) More than just an eyesore: local insights and solutions on vacant land and urban health. Journal of Urban Health, November.
- Goldstein, H. (1995) Multilevel Statistical Models, Halstead Press, New York.
- Grisso, J., et al. (1999) Violent injuries among women in an urban area. New England Journal of Medicine, 341 (25), 1899–1905.
- Kamphuis, D., et al. (2010) Why do poor people perceive poor neighbourhoods? the role of objective neighbourhood features and psychosocial factors. Health and Place, 16 (4), 744–754.
- Kawachi, I. and Berkman, L. (2003) Neighborhoods and Health, Oxford University Press, New York.
- Kegler, M., et al. (2008) A qualitative examination of home and neighborhood environments for obesity prevention in rural adults. International Journal of Behavioral Nutrition and Physical Activity, 5, 65.
- Kohen, D.E., et al. (2002) Neighborhood income and physical and social disorder in Canada: Associations with young children's competencies. Child Development, 73, 1844–1860.
- Krieger, N., et al. (2003a) Race/ethnicity, gender, and monitoring socioeconomic gradients in health: a comparison of area-based socioeconomic measures—the public health disparities geocoding project. American Journal of Public Health, 93 (10), 1655–1671.
- Krieger, N., et al. (2003b) Choosing area based socioeconomic measures to monitor social inequalities in low birth weight and childhood lead poisoning: The Public Health Disparities Geocoding Project (US). Journal of Epidemiology and Community Health, 57 (3), 186–199.
- Lackey, K. and Kaczynski, A. (2009) Correspondence of perceived vs. objective proximity to parks and their relationship to park-based physical activity. International Journal of Behavioral Nutrition and Physical Activity, 6, 53.
- Laraia, B.A., et al. (2006) Direct observation of neighborhood attributes in an urban area of the U.S. south: characterizing the social context of pregnancy. International Journal of Health Geographics, 17 (5).
- Leonard, T.C.M., et al. (2011) Systematic neighborhood observations at high spatial resolution: Methodology and assessment of potential benefits. PLoS, 6 (6), e20225.
- Malmstrom, M., Sundquist, J., and Johansson, S.E. (1999) Neighborhood environment and self-reported health status: a multilevel analysis. American Journal of Public Health, 89 (8), 1181–1186.
- McGuire, J.B. (1997) The reliability and validity of a questionnaire describing neighborhood characteristics relevant to families and young children living in urban areas. Journal of Community Psychology, 25 (6), p. 551–566.
- Messer, L., et al. (2006) The development of a standardized neighborhood deprivation index. Journal of Urban Health, 83 (6), 1041–1062.
- Michael, Y., et al. (2006) Measuring the influence of built neighbourhood environments on walking in older adults. Journal of Aging and Physical Activity, 14, 302–312.
- Muthen, L.L., and Muthen, B.O. (1998) MPlus: The Comprehensive Modeling Program for Applied Researchers. User's Guide, Muthen and Muthen, Los Angeles, CA.
- Nettles, S.M., Caughy, M.O., and O'Campo, P.J. (2008) School adjustment in the early elementary years: Toward an integrated model of neighborhood, parental, and child processes. Review of Educational Research, 78, 3–32.
- O'Campo, P. (2003) Invited commentary: Advancing theory and methods for multilevel models of residential neighborhoods and health. American Journal of Epidemiology, 157 (1), 9–13.
- O'Campo, P., et al. (1997) Neighborhood risk factors for low birthweight in Baltimore: a multilevel analysis. American Journal of Public Health, 87 (7), 1113–1118.
- O'Campo, P., et al. (2005) Uncovering neighbourhood influences on intimate partner violence using concept mapping. Journal of Epidemiology and Community Health, 59 (7), 603–608.
- Odgers, C.L., et al. (2012) Systematic social observation of children's neighborhoods using Google Street View: a reliable and cost-effective method. Journal of Child Psychology and Psychiatry and Allied Disciplines, 53 (10), 1009–1017.
- Parsons, J., et al. (2010) Standardized observation of neighbourhood disorder: does it work in Canada? International Journal of Health Geographics, 10 (9), 6.
- Pearce, J. and R. Maddison, R. (2011) Do enhancements to the urban built environment improve physical activity levels among social disadvantaged populations? International Journal of Equity in Health, 10, 28.
- Pinchevsky, G. and Wright, E. (2012) The impact of neighborhoods on intimate partner violence and victimization. Trauma, Violence and Abuse, 13 (2), 112–132.
- Popay, J., et al. (2003) Theorizing inequalities in health: the place of lay knowledge, in Health and Social Justice: Politics, Ideolog, and Inequity in the Distribution of Disease (ed. R. Hofrichter), Jossey-Bass, San Francisco, CA, pp. 385–409.
- Rajaratnam, J., Burke, J., and O'Campo, P. (2006) Maternal and child health and neighborhood context: the selection and construction of area-level variables. Health and Place, 12 (4), 547–556.
- Raudenbush, S.W., Rowan, B., and Kang, S.J. (1991) A multilevel, multivariate model for studying school climate with estimation via the EM algorithm and application to U.S. high school data. Journal of Educational Statistics, 16 (4), 295–330.
- Raudenbush, S.W. and Sampson, R.J. (1999) Ecometrics: toward a science of assessing ecological settings, with application to the systematic social observation of neighborhoods. Sociological Methodology, 29, 1–41.
- Roosa, M.W., et al. (2003) Prevention science and neighborhood influences on low-income children's development: theoretical and methodological issues. American Journal of Community Psychology, 31 (1–2), 55–72.
- Ross, C.E. (2000) Walking, exercising, and smoking: does neighborhood matter? Social Science and Medicine, 51 (2), 265–274.
- Ross, N.A., Tremblay, S.S., and Graham, K. (2004) Neighbourhood influences on health in Montreal, Canada. Social Science and Medicine, 59 (7), 1485–1494.
- Sampson, R.J. (1991) Linking the micro and macrolevel dimensions of community social organization. Social Forces, 70 (1), 43–64.
- Sampson, R.J. (1992) Family management and child development: Insights from social disorganization theory, in Facts, Frameworks, and Forecasts. Advances in Criminological Theory (ed. J. Mc Cord), Transaction Publishers, New Brunswick, NJ, pp. 63–93.
- Sampson, R.J. (2003) The neighborhood context of well-being. Perspectives in Biology and Medicine, 46 (3S), S53–S64.
- Sampson, R.J., Morenoff, J.D., and Gannon-Rowley, T. (2002) Assessing “neighborhood effects”: social processes and new directions in research. Annual Review of Sociology, 28, 443–478.
- Sampson, R.J., Morenoff, J.D., and Raudenbush, S.W. (1999) Assessing neighborhood-level theories of crime: social mechanisms and spatial dynamics, in Neighborhood Effects, Joint Center for Poverty Research, Northwestern University/University of Chicago, Chicago, IL.
- Sampson, R.J., Raudenbush, S.W., and Earls, F. (1997) Neighborhoods and violent crime: a multilevel study of collective efficacy. Science, 277, 918–924.
- Schaefer-McDaniel, N., et al. (2010) Examining methodological details of neighborhood observations and the relationship to health: a literature review. Social Science and Medicine, 70, 277–292.
- Shankardass, K. and Dunn, J.R. (2012) How goes the neighbourhood? Rethinking neighbourhoods and health research in social epidemiology, in Rethinking Social Epidemiology: Towards a Science of Change (eds P. O'Campo and J.R. Dunn), Springer Publishing Company, New York, pp. 137–156.
- Smith, D., et al. (2009) Neighbourhood food environment and area deprivation: spatial accessibility to grocery stores selling fresh fruit and vegetables in urban and rural settings. International Journal of Epidemiology, 39, pp. 277–284.
- Taylor, R.B. (2001) Breaking away from Broken Windows: Baltimore Neighborhoods and the Nationwide Fight against Crime, Grime, Fear, and Decline, Westview Press, Boulder, CO.
- Taylor, R.B., Gottfredson, S.D., and Brower, S. (1984) Block crime and fear: defensible space, and territorial functioning. Journal of Research in Crime and Delinquency, 21 (4) 303–331.
- Weiss, L., et al. (2007) Defining neighborhood boundaries for urban health research. American Journal of Preventive Medicine, 32 (6), S154–S159.
- Yen, I., et al. (2007) Women's perceptions of neighborhood resources and hazards related to diet, physical activity, and smoking: focus group results fromeconomically distinct neighborhoods in a mid-sized US City. American Journal of Health Promotion, 22 (2), 98–106.