CHAPTER ELEVEN
EXPERIMENTAL SOCIAL EPIDEMIOLOGY: CONTROLLED COMMUNITY TRIALS
Peter J. Hannan
Randomization by cluster accompanied by an analysis appropriate to randomization by individual is an exercise in self-deception, however, and should be discouraged.
Cornfield (1978, p. 101)
Disease is individual but also social, in the sense that a common environment may contribute to illness, as probably best exemplified by the waves (epidemics) of colds passing through close-knit communities each winter. Social epidemiology has as its object the investigation of the connection between the social environment and the health of individuals. Consequently social epidemiology deals with at least two levels of data, those relating to the environment and those relating to the individual. If all exposed individuals succumbed to disease, individual characteristics would be irrelevant, and individual-level data could not explain differences in disease between different environments. However, not all exposed individuals exhibit disease, so the data of social epidemiology is necessarily multilevel.
One way to deal with hierarchical data is to collapse over the lower level, resulting in simple correlational analysis at the community level relating prevalence of disease to exposure. By observing the patterns of cholera, in 1849 Dr John Snow published his hypothesis that, in contrast to the commonly held “miasma” theory, water from one of two suppliers in London was contaminated and was the source of exposure to some causal agent (Snow 1849; see http://www.csiss.org/classics/content/8). It may be the earliest social epidemiological experiment. When a second cholera outbreak occurred in 1854, he was able to test his argument through an experiment in which the handle of the Broad Street pump was removed as a way to prevent exposure if the hypothesis were true; the cholera epidemic was contained. However, one might argue that the epidemic was going to decline for other reasons and the intervention just happened to coincide. It was not a randomized, controlled trial. For another example, see a study of the control of tuberculosis (Frost, 1937).
Hierarchical statistical models have been in use in statistics (under the name of mixed models) from Fisher's pioneering work on nested models for split-plot designs. The essential ingredient in hierarchical models is that more than a single error variance exists. The simplest example is that of repeated measures, in which a within-component of variance is realized on each measurement occasion and a between-component of variance is realized for each individual (here, individual = unit). Now move up a level to having communities as the units and the “inhabitants” as the repeated measures within the unit; an error-component of variance is realized for each individual measurement, and a between-component of variance takes on a realized value for each community. In a cohort community study design, each of the individual- and the unit-components of variance can themselves be modeled as having two components, one for level of the measurement (whether individual or unit) and one for the time-varying component of variance (whether individual or unit). Thus, we can have repeated measures on the individual as well as repeated measures on the community, each showing a correlation over time.
Experimental hierarchical designs occurred commonly in educational research where interventions are applied to all the students in the classroom; these experiments were analyzed ignoring the clustering in classrooms (Goldstein 1987). In the late 1970s (e.g., Wedderburn 1974, 1976; Corbeil and Searle 1976) and early 1980s (e.g., Laird and Ware 1982) statistical progress in the analysis of mixed models allowed these concepts to enter the educational field as a debate of the statistical issue of the unit of analysis (Hopkins 1982). Educationists have continued to contribute to the topic as witnessed by the work, for example, of Bryk and Raudenbush (1992).
Epidemiology began using observational clustered studies such as physiologist Keys' (1967) ground-breaking Seven Countries Study, which followed cohorts of male participants in 16 centers in seven different countries. The concentration on males was because males were primarily affected by the epidemic of heart disease in Western society. Because this was an observational study and data were collapsed to the level of country for comparisons, the term “ecological fallacy” reared its head; that is, other characteristics, like the specific gene pools, may explain the differences. As a result of finding Finland labeled with the dishonor of having the highest heart attack rates of the 16 cohorts, Finnish researchers under Puska (1983) instituted a controlled trial (i.e., an experiment) in which the province of North Karelia was chosen to receive an intervention aimed at reducing the risk factors for heart disease, while the companion province of Kuopio was monitored as a control. Absent randomization is called a “quasi-experiment” (Cook and Campbell 1979). Despite the control, might an alternative explanation exist for the outcome of the experiment; might structural/environmental differences exist between North Karelia and Kuopio that could equally explain the observed result? With only one province in each condition, the alternative explanation is at least tenable. Blackburn's visit in 1971 to the organizing meeting under the aegis of WHO for the North Karelia Project helped crystallize his ideas on the prevention of heart disease in whole populations. The ideas that were circulating were published in a report from the WHO Expert Committee on the prevention of coronary heart disease, held in Geneva in late 1981 that presented the population approach to reducing the burden of heart disease (see WHO 1982). The whole US population had elevated risk factors for heart disease, with the distribution of cholesterol levels in the United States having almost no overlap with cholesterol levels in the Japanese cohorts of the Seven Countries Study. Blackburn inferred from this that intervention efforts should not focus on only high-risk individuals. In the United States in the early 1970s, Farquhar had set up the quasi-experimental Stanford Three Communities Study, with one intervention and two control communities with the same aims as the North Karelia Project, but with increased attention to the use of the media (Farquhar et al. 1977; Farquhar 1978; Williams et al. 1981). In the late 1970s/early 1980s came three controlled community quasi-experiments—an expanded Stanford Five Cities Study (Farquhar et al. 1985), the Minnesota Heart Program under Blackburn (Jacobs et al. 1986), and the Pawtucket Heart Health Program under Carleton (Carleton et al.1995). For an interesting reflection on the history of these community-based studies for prevention of cardiovascular disease see Blackburn (2004, pp. 24–38).
The first three to four years of data in MHHP were troubling the researchers at the University of Minnesota's Division of Epidemiology because city-wide means were showing more variability than was expected. Leslie Kish, who was on the MHHP Scientific Advisory Board, introduced the group to the design effect (DEFF) already well known in survey sampling when sampling is by clusters (Kish 1965). When asked his suggested remedy, the reply was “Recruit 50 cities”! SFCP had five communities, MHHP six communities, and PHHP two communities. Cornfield's discouragement (1978) quoted at the top of this chapter began to make sense. In Canada, Donner and colleagues heeded the message early, and Donner as a consultant to MHHP helped us in Minnesota understand the problem (see Donner, Birkett, and Buck 1981; Donner 1982, 1985; Donner and Koval 1982). The publication of Generalized Linear Models (McCullagh and Nelder 1983) crystallized the statistical research conveniently. The statistical implications of the group randomized trials, or GRTs as they are now affectionately known, had a direct impact on the design of a number of studies, including the Healthy Worker Project (Jeffery 1993), the COMMIT Trial (Gail, Pechacek, and Corle 1992), CMCA (Wagenaar et al. 1994), and CATCH (Zucker et al. 1995). Since then a plethora of GRTs have been implemented, and over time, an increasing fraction has been analyzed correctly (see Donner, Brown, and Basher 1990; Simpson, Klar, and Donner 1995; Varnell et al. 2004). The article by Zucker (1990) laid out clearly the proper analysis for GRTs. A summary of the status of GRTs in the mid-1990s is given in Koepsell et al. (1995); more recent summaries are provided by Donner and Klar (2000) and Murray, Varnell, and Blitstein (2004). Sorenson et al. (1998) provide a view of where group randomized trials were situated by the mid-1990s.
The characteristic of clustered data is the presence of more than one component of error variance, inducing correlation between measurements repeated within the cluster and hence the term multilevel data. Just as collapsing data may introduce the “ecological fallacy” in which associations between groups are assumed to reflect individual associations (Robinson 1950; Alker 1969; Krieger 1992), so too ignoring clusters may introduce the “individualistic fallacy” (Alker 1969; Krieger 1992, 1994). In relating the occurrence of disease to environmental context both individual and contextual data are needed. Strong inference requires randomized experiments, and epidemiologic investigation in a social context requires multilevel data. Thus the importance to social epidemiology of the proper design and analysis of randomized trials.
Randomization and Dependence
Randomization promises that at least in the long run (statistical expectation) there is no selection bias and that unmeasured (and indeed, even unthought-of) confounders are balanced. Unfortunately, statistical expectation is an asymptotic property (a large number of repetitions would be required) while the actual randomization is carried out once to give the realized randomization. The single realization is more likely to be balanced if a sufficiently large number of entities is randomized.
The randomized controlled clinical trial (RCT) is largely regarded as the ideal experimental design, involving as it does two elements—experimental intervention and randomization to an experimental/control condition (but see Senn 2004). As detailed in Chapter 1 in this volume, the strongest inference for an effect of an intervention would be to evaluate the state of a unit in the absence of, and in the presence of, the intervention being tested with the evaluations being under identical conditions. This may be possible in Physics, but hardly possible in social contexts. In lieu of the ideal, multiple “comparable” units are selected and randomized to represent either the intervention experience or the control experience. Intervention (read “experimentation”) and randomization are crucial to the strength of the inference.
Experimentation and Inference
In science using the experimental method, the acceptance of new theories is based largely on prediction, temporal sequence, and replicability of the experiment by others. A prediction is made and an experiment is carried out to see if the prediction holds. To strengthen the connection between theory and reality, and to help exclude alternative explanations, the experimental method looks for the appearance of the predicted phenomenon when the posited “cause” is introduced and the disappearance of the phenomenon when the posited “cause” is removed and the original situation is restored. Finally, to help exclude the possibility that it was not some other contemporaneous influence, the experiment must be replicated, preferably by others.
Experimentation is important. The deliberate introduction of change, which is followed by the predicted effect, and the deliberate removal of the change, followed by the disappearance of the effect, is cogent. Replication strengthens the inference by excluding the likelihood of other chance possibilities being responsible. What is possible in Physics is infeasible in Social Epidemiology. The pre/post-randomized controlled trial captures the aspect of the introduction of change via the pre/post-design, and approximates the “off-on-off” aspect via the controls. Internal replication is approximated by the multiple units, coupled with the statistical methods which generate estimates of what the range of outcomes might be if the sample were retaken under the same conditions. Thus the importance in the study of human and societal behavior of the trial is revealed.
Importance of Randomization
By the Law of Large Numbers (see, for example, Mood 1950), randomization guarantees in the probabilistic sense that the two groups will be comparable; measured, unmeasured, and, indeed, even unthought-of confounders are guaranteed asymptotically to be balanced between the two groups. Thus the group of units randomized to the control experience can be considered as if they were the group of units randomized to the experimental experience, the only difference being the experimental manipulation. However, the guarantee requires an infinity of units or equally, but conceptually, an infinity of randomizations, making for an infinity of replicated experiments. That is what asymptotically means. In practice, we have a finite number of units to be randomized and we can do only one randomization, called a single realization. We need to craft the selection process for these units to be already as comparable as possible—in other words, we need to assist chance to achieve approximate balance in the single realization effected. This can be done in the design phase by the use of matching or of stratification of units to be randomized, and in the analysis phase by appropriate covariate adjustment. Nevertheless, randomization of a sufficiently large number of carefully selected units is essential for a strong inference.
Effect of Dependence
The units we have been talking about could be individuals as in an RCT or social groups as in a group randomized trial (GRT). In the latter, intact social groups are randomized so that the members within a social group are assigned to the same experimental condition, be it intervention or control. Individuals are not randomized and all individuals in the unit are in the same experimental condition. How, if possible, can the uniqueness of the unit be separated from the experimental condition, since the unit is nested in the condition? In fact, if we have only one unit per condition the uniqueness of the unit and the effect of condition are completely confounded. If we have multiple units per condition, we can impose a statistical model to account for the uniqueness of each unit by assuming that the units come with “bumps” or “shifts” realized from a common probabilistic distribution. The usual statistical model assumes the outcome measure for each member of a unit has a common bump, establishing a correlation between measures of members within a unit. Members within a unit tend to be more like other members in the unit than to be like members from other units. If your friend smokes, his/her spouse is more likely also to smoke.
The implication of the statistical model is that pooling information over members within a unit carries redundancy. The second member of a group may add only 0.95 units of information about the measure, instead of a full unit of information. Let  represent the measure for member
represent the measure for member  .
.  is made up of a member specific contribution,
is made up of a member specific contribution,  , and common “bump”
, and common “bump”  , so that
, so that  . Assume the
. Assume the  is drawn from a distribution with mean
is drawn from a distribution with mean  and variance
and variance  and that u is a realization from a distribution with mean 0 and variance
and that u is a realization from a distribution with mean 0 and variance  . The expectation of each
. The expectation of each  is
is  and the variance of each
and the variance of each  is (
is ( ). The mean of
). The mean of  in the group is
in the group is  .
.
The statistical expectation of  is
is

The variance of  is more intriguing:
is more intriguing:

where  is the variance components ratio and
is the variance components ratio and  is the intraclass correlation coefficient.
is the intraclass correlation coefficient.
Note:
- If
 we have the familiar result for the variance of the mean of m independent observations from a common distribution.
we have the familiar result for the variance of the mean of m independent observations from a common distribution.  is the variance within member, but
is the variance within member, but  is the total variance of Y.
is the total variance of Y.- The covariance between
 and
and  arises through the common “bump”,
arises through the common “bump”,  .
.  and if VCR is small,
and if VCR is small,  ; clustering implies that the variance of a mean is inflated by factor
; clustering implies that the variance of a mean is inflated by factor  , called the design effect, DEFF, by Kish (1965), and the variance inflation factor, VIF, by Donner, Birkett, and Buck (1981).
, called the design effect, DEFF, by Kish (1965), and the variance inflation factor, VIF, by Donner, Birkett, and Buck (1981).- The factor
 inflates the residual variance component as would be estimated in an analysis of variance, and defines the residual variance inflation factor,
inflates the residual variance component as would be estimated in an analysis of variance, and defines the residual variance inflation factor,  .
. - If the size of the cluster is
 , no inflation of the variance of the mean exists.
, no inflation of the variance of the mean exists. - For large unit size, m, the inflation may be serious even for seemingly small ICC.
- Estimates of
 and of
and of  will differ according to different analytic models, even for the same outcome (
will differ according to different analytic models, even for the same outcome ( ), especially as covariates are used in the analysis with varying success in “explaining” between and/or within variance—hence there is no single value for the ICC, but a value for an ICC depending on the analytic model used.
), especially as covariates are used in the analysis with varying success in “explaining” between and/or within variance—hence there is no single value for the ICC, but a value for an ICC depending on the analytic model used. - The estimated ICC also is liable to sampling (replication) error—the estimate comes with an implicit uncertainty, capturing the variation likely to be encountered if the experiment were to be done again (replicated).
For example, in the Minnesota Heart Health Program, for community clusters of average size  , we found an ICC estimate for the prevalence of smoking equal to 0.00272 based on 31 degrees of freedom (Hannan et al. 1994, Table 4). The individual (binomial) variance for current smoking can be estimated by
, we found an ICC estimate for the prevalence of smoking equal to 0.00272 based on 31 degrees of freedom (Hannan et al. 1994, Table 4). The individual (binomial) variance for current smoking can be estimated by  , where p is the average prevalence of smoking (0.22 or 22% prevalence), estimated to be
, where p is the average prevalence of smoking (0.22 or 22% prevalence), estimated to be  . The estimate of
. The estimate of 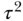 is
is  , so
, so  . If there were no clustering, the sampling variance of a mean over 410 persons would be
. If there were no clustering, the sampling variance of a mean over 410 persons would be  , giving a standard error
, giving a standard error  . The design effect from the seemingly small ICC is
. The design effect from the seemingly small ICC is  , effectively doubling the variance of the estimated community prevalence of smoking based on a large survey of 410 persons randomly selected from within a socially intact cluster. The inflated variance of an estimated smoking prevalence is
, effectively doubling the variance of the estimated community prevalence of smoking based on a large survey of 410 persons randomly selected from within a socially intact cluster. The inflated variance of an estimated smoking prevalence is  for an estimated standard error 0.03. Hence, instead of reporting the prevalence (as a percentage) as 22 ± 2%, clustering leads to a prevalence estimate reported as 22 ± 3%.
for an estimated standard error 0.03. Hence, instead of reporting the prevalence (as a percentage) as 22 ± 2%, clustering leads to a prevalence estimate reported as 22 ± 3%.
Implications of Clustering—Proper Inference in Community Trials
Community trials are characterized by having correlated observations, which implies more than a single source of variability. The statistical terminology for data having more than a single source of error is varied: mixed models (Laird and Ware 1982), hierarchical linear models (Bryk and Raudenbush 1992; Raudenbush and Bryk 2002), or random coefficients models (Longford 1993). The analysis of variance (ANOVA) is a useful method for laying out the relationships between the variability at different levels—the individual and the community level (Murray 1998). The simplest case of ANOVA is for measurements in a single cross-section of individuals in communities.
Suppose there are  members in each of
members in each of 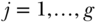 communities or social units per condition, randomized into
communities or social units per condition, randomized into  experimental conditions, commonly just two, intervention (
experimental conditions, commonly just two, intervention ( ) or control (
) or control ( ), The ANOVA table presents the sources of variability, the degrees of freedom available for estimating a level of variance (df), the partitioned sums of squared deviations (SSQ), the mean sum of squares (MS) being the SSQ divided by the corresponding df, and the expected mean sum of squares, E(MS), on the basis of the model (see Table 11.1). We use a colon (:) to represent nesting of one effect within another; for example, unit:Cond represents the fact that each social unit occurs in one and only one condition, not crossed with Cond. The statistical model for a continuous outcome measure,
), The ANOVA table presents the sources of variability, the degrees of freedom available for estimating a level of variance (df), the partitioned sums of squared deviations (SSQ), the mean sum of squares (MS) being the SSQ divided by the corresponding df, and the expected mean sum of squares, E(MS), on the basis of the model (see Table 11.1). We use a colon (:) to represent nesting of one effect within another; for example, unit:Cond represents the fact that each social unit occurs in one and only one condition, not crossed with Cond. The statistical model for a continuous outcome measure,  , taken on person
, taken on person  within unit
within unit  within condition
within condition  , may be written
, may be written

where  and
and  are fixed effects representing the overall mean and the shift in the mean attributable to the ith intervention;
are fixed effects representing the overall mean and the shift in the mean attributable to the ith intervention;  represents a “bump” common to all members in the jth unit and the multiple-valued
represents a “bump” common to all members in the jth unit and the multiple-valued  are assumed to be Gaussian distributed across units,
are assumed to be Gaussian distributed across units,  , and
, and  represents residual error at the member level, assumed to be a realization from a Gaussian distribution,
represents residual error at the member level, assumed to be a realization from a Gaussian distribution,  . Statistical theory of mixed models generates the ANOVA table, which indicates that, under the null hypothesis that the
. Statistical theory of mixed models generates the ANOVA table, which indicates that, under the null hypothesis that the  are equal, MScond and MSunit have the same expectation and consequently the ratio MScond/MSunit is distributed as an F-statistic based on numerator
are equal, MScond and MSunit have the same expectation and consequently the ratio MScond/MSunit is distributed as an F-statistic based on numerator  and denominator
and denominator  . Under the alternative hypothesis that the
. Under the alternative hypothesis that the  are not equal, the F-statistic has a non-centrality parameter
are not equal, the F-statistic has a non-centrality parameter  . Although the non-centrality parameter is not a random variable it is commonly represented as if it were a variance component,
. Although the non-centrality parameter is not a random variable it is commonly represented as if it were a variance component,  . Of course, under the null hypothesis,
. Of course, under the null hypothesis,  .
.
TABLE 11.1 ANOVA PARTITION OF THE SUMS OF SQUARES IN A SINGLE CROSS-SECTION GROUP RANDOMIZED TRIAL HAVING UNIT AS A RANDOM EFFECT
| Source | df | Sum Sq | Mean Sq | E(MS) |
| Intercept | 1 | — | — | — |
| Condition | C – 1 | SSQcond | MScond |  |
| unit:Cond | c(g – 1) | SSQunits | MSunit |  |
| member:unit:Cond | cg(m – 1) | SSQres | MSerror |  |
| Total df = | cgm |
The important point of the ANOVA is that the test of the hypothesis that the intervention had an effect must compare the variation at the condition level against the variation at the unit level, not against the variation at the member level. Zucker (1990) makes this point most cogently; however, the message is frequently ignored in the analyses of published papers, as shown by the review articles of Donner, Brown, and Basher (1990), Simpson, Klar, and Donner (1995), and Varnell et al. (2004). Testing the MScond against the residual error will produce erroneously larger F-statistics, and erroneously smaller p-values. Ineffective interventions will be more likely to be declared worthwhile, and even effective interventions will be over-interpreted. Thus the integrity of the inferential process would be jeopardized if the nesting of units within interventions is ignored.
The MSunit in the ANOVA table is easily related to the variance of the mean merely by dividing by  , and later by g. Recall above that
, and later by g. Recall above that  , that is,
, that is,  ; the variance of a condition-mean made up of g independent unit-means is
; the variance of a condition-mean made up of g independent unit-means is  , and the variance of the difference between two condition-means will be
, and the variance of the difference between two condition-means will be 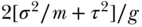 . With just two conditions the non-centrality parameter measuring the separation between the conditions is
. With just two conditions the non-centrality parameter measuring the separation between the conditions is  . At a hypothesized separation between the two condition means,
. At a hypothesized separation between the two condition means,  , the “official” F-test (F = MScond/MSunit) based on 1 and
, the “official” F-test (F = MScond/MSunit) based on 1 and  df is equivalent to testing the difference between the condition means against the standard error of that difference with a t-test based on
df is equivalent to testing the difference between the condition means against the standard error of that difference with a t-test based on  df. Hence the fundamental test statistic is
df. Hence the fundamental test statistic is

Efficient Allocation of Resources Subject to Constraints
Improving statistical efficiency refers to achieving smaller variance for the target statistic. For the moment we focus on only the balance of the number of members within the unit and the number of units in reducing variance, while remaining within a budget cap. Later we will see that the number of units chosen has a further impact on the statistical power through the number of degrees of freedom for estimating variance components internally to the study.
From (1) we have the variance of a condition mean as  . Increasing
. Increasing  will control the member contribution to variation of the mean, but increasing
will control the member contribution to variation of the mean, but increasing  brings diminishing returns in reducing the variance because increased
brings diminishing returns in reducing the variance because increased  does not control the between-unit contribution to the variance of the mean. Increasing the number of units controls both the member and the unit contributions to the variance of a condition mean. The limited value of increasing
does not control the between-unit contribution to the variance of the mean. Increasing the number of units controls both the member and the unit contributions to the variance of a condition mean. The limited value of increasing 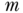 can be seen by plotting the variance of a unit-mean against
can be seen by plotting the variance of a unit-mean against  , that is, plotting
, that is, plotting  as a function of m. In fact, it suffices to plot (
as a function of m. In fact, it suffices to plot ( ) against
) against  , because
, because  is inherent member variability (see Figure 11.1).
is inherent member variability (see Figure 11.1).

FIGURE 11.1 VARIANCE OF A UNIT MEAN AS A FRACTION OF WITHIN-UNIT VARIANCE,  , PLOTTED AGAINST THE NUMBER OF MEMBERS PER UNIT, AT DIFFERENT LEVELS OF THE CLUSTER EFFECT, VCR
, PLOTTED AGAINST THE NUMBER OF MEMBERS PER UNIT, AT DIFFERENT LEVELS OF THE CLUSTER EFFECT, VCR
It looks as if there is little gain in efficiency by increasing sample size, m, within-unit variance beyond about 50 when the VCR is in the range encountered in many community trials (0.01, 0.05). When the VCR (or, equivalently, ICC) is non-zero, measurements on each additional member within the same unit carry some information redundant to that already collected. The returns diminish with larger within-unit sample size; what is needed is more information about the variation between units. However, given budgetary or other feasibility constraints, the number of units selected for study cannot be increased indefinitely.
We can balance allocation of resources within and between units by considering the minimization of the variance subject to the budgetary constraints of overhead cost of recruiting units, of the intervention, and of collecting member data. A simple example: you intend to apply for a grant of $200 000 and estimate the cost of recruiting units will be $800, while for those units randomized to intervention, the overhead costs of the intervention will be about $1000 more. The cost of recruiting a member and collecting data is estimated to be $100. An extremely simple model for a post-test only design with g units per condition and  members per unit would have the constraint
members per unit would have the constraint

Suppose we expect the VCR to be 0.05, which might suggest, on the basis of Figure 11.1, taking  somewhere between 40 and 80. Let us choose
somewhere between 40 and 80. Let us choose  , so
, so  . We will have to use integral numbers, so fix
. We will have to use integral numbers, so fix  and
and  . The variance of the difference in condition means that a multiple of
. The variance of the difference in condition means that a multiple of  is
is  . However, suppose we instead decided to increase the number of units per condition (
. However, suppose we instead decided to increase the number of units per condition ( ) to 25, for which we could afford only
) to 25, for which we could afford only  . The variance of the difference in condition means becomes 0.00696. The second design has a relative efficiency of 126% (= 0.00875/0.00696). Of course, it may be impossible to recruit 50 units, but at least we have some guidance as to where to put our resources.
. The variance of the difference in condition means becomes 0.00696. The second design has a relative efficiency of 126% (= 0.00875/0.00696). Of course, it may be impossible to recruit 50 units, but at least we have some guidance as to where to put our resources.
The g and m parameters that minimize variance for a given design and budget depend on the VCR and the various costs. Typically the principal investigator has in mind a range of possibilities to fit within the proposed budget and the statistician makes explicit the implications for power or detectable difference for various choices of numbers of members and units. Some have developed formulas and/or programs that bring costs and overall budget constraints into the statistical design. See, for example, McKinlay (1994, using estimated VCR parameters from Feldman and McKinlay 1994) and Raudenbush (1997).
The major message is that the more units the better in a GRT. We remind the reader that maximization of statistical power goes further than minimizing variance. Maximization of power requires consideration to be given to the available degrees of freedom that govern the spread of the reference distributions under both the null and alternative hypotheses. The point is taken up later.
Example of Designing a GRT and Some Further Issues
How does one design a group randomized trial, plan analyses, calculate expected power, and implement the trial? Consider the study “Communities Mobilizing for Change on Alcohol” or CMCA as it is commonly named. This study was conducted out of the Alcohol Epidemiology Program in the Division of Epidemiology, School of Public Health at the University of Minnesota, under the Principal Investigator Dr Alex Wagenaar in the period 1992–1998. Conceptualization, design, grant-writing, and funding all preceded the beginning of implementation in 1992. The study aims were to test:
The statistical design involved a number of interesting elements. By very reason of the hypotheses to be tested, the social intact units of communities are the objects of intervention; behavior in persons and sales practice in alcohol outlets being sampled was representative of the community in which they exist. From a frame of 24 eligible communities surviving explicit exclusion criteria, 15 communities agreed to randomization to control or intervention status. The CMCA design carefully matched these communities into “similar” pairs (one triplet) based on criteria thought to have a possible influence on the communities' present norms and practice, and on readiness to work for change. Although randomization will balance confounders in expectation, that is, under many replications, the randomization of a limited number of communities will not ensure balance in the single realized randomization. Stratification, or the stronger matching, of communities prior to randomization will improve baseline comparability. Randomization is a prime requisite for inference, whereas stratification/matching prior to randomization is a useful technique to help randomization achieve balance in a limited number of units; statistical adjustment can be used to address residual confounding associated with measured covariates as well as for reducing residual variance. Although communities are matched in the design, a matched analysis will have about half the degrees of freedom for estimating the community variance component compared to an unmatched analysis. In most community trials the number of units is not large, and the unmatched analysis of the matched design will have more degrees of freedom for the error term and will be preferred (Martin et al. 1993; Diehr et al. 1995a; Proschan 1996).
The design used both “nested cross-sectional” and “nested cohort” designs (Murray and Hannan 1990). In a “nested cross-sectional” design different members are sampled at different times from within the intact social units as the units are followed over time. In a “nested cohort” design the same members are followed at different times as the units are followed. In CMCA the surveys of 18–20 year olds in 1992 and 1995 were of different young adults (cross-sectional data) at the two times, while the surveys of 9th graders in 1992 followed the cohort and re-surveyed the same students as 12th graders in 1995 (cohort). The article points out some of the advantages and disadvantages of each of these designs; see also Diehr et al. (1995b) and Murray (1998). In contrast to clinical trials in which a cohort offers the advantage of reduced variance because of correlated outcomes, in group randomized trials this advantage is less important because of the unit component of variance and the fact that one deals with a “cohort” of units, that is, repeated measures on the units. Other issues to be considered in the selecting a cohort or a cross-sectional design are the length of the study and possible attrition, the mobility and consequent tracking of members, and any perceived threat to anonymity in a cohort data collection that may introduce bias in response to sensitive items. A fundamental issue is whether the study aim for the intervention is to change individuals or to change infrastructures (which will have an impact on individuals). If the former, only the cohort design is cogent; if the latter, a cross-section is more appropriate.
The design paper for CMCA detailed analysis procedures and expected detectable differences using methods appropriate to a group randomized trial. Further, Murray and Short (1995) publish ICCs for many alcohol-related outcomes in nine areas; they present crude ICCs and then changes in ICCs and residual error as adjustment is made for (i) age and gender, (ii) one to three personal characteristics, and (iii) for none to two community level covariates, depending on the outcome. Such estimates are valuable in power estimation in the planning of studies. The paper also gives two examples of the use of these ICCs. Power estimation uses design effects (DEFF, Kish 1965) or, equivalently, variance inflation factors (Donner, Birkett, and Buck 1981) based on analysis of variance (ANOVA) tables of expected means squares. We turn to these methods in the next section. Statistical Implications of Clustering—Power, Sample Sizes and Detectable Differences
In group randomized trials, estimates of power, sample sizes, and detectable differences are complicated by having to allow for more than the usual single residual component of variance. The two major statistical models applied to group randomized trials are (1) analysis of covariance (ANCOVA) and (2) random coefficients (RC), leading to some differences in power calculations. A third non-parametric method relies on permutation distributions.
The ANCOVA model. The post-test only design, while weak inferentially, has the simplest model specification on which we can build. Refer above for the notation and the ANOVA table (Table 11.1) for the post-test only design. A person may have covariates  , in which case the regression model with mean
, in which case the regression model with mean  is
is

where  is the regression coefficient for the covariate (which could be a vector of covariates). For simplicity we will omit covariates from the model so we have
is the regression coefficient for the covariate (which could be a vector of covariates). For simplicity we will omit covariates from the model so we have

Note that because of the nesting within the unit and condition, both the  and the error term are necessarily modeled as random effects (Zucker 1990), indicated by the bolding.
and the error term are necessarily modeled as random effects (Zucker 1990), indicated by the bolding.
Table 11.1 for the post-test only design also applies to the baseline-adjusted analysis of a nested cohort design. Consequently, referring back to Equation (1), the ratio of the baseline-adjusted difference between the conditions at follow-up to its standard error follows the t-distribution based on  df, but the components of variance are adjusted-components of variance:
df, but the components of variance are adjusted-components of variance:  .
.
The effect of the regression adjustment for the baseline value of the outcome (and any other covariates) is to reduce the variance by a factor ( ). Here we have two adjustments coming out of the regression; thus we have two factors, (
). Here we have two adjustments coming out of the regression; thus we have two factors, ( ) on the member-variability and (
) on the member-variability and ( ) on the unit-variability. The variance of
) on the unit-variability. The variance of  can then also be written as
can then also be written as  . In a cohort of members
. In a cohort of members  , the square of the member repeat correlation; approximate values of
, the square of the member repeat correlation; approximate values of  are usually readily available. Knowledge of likely values of
are usually readily available. Knowledge of likely values of  is not common. In our experience with outcomes mainly in schools,
is not common. In our experience with outcomes mainly in schools,  has often been about 0.2, but in a recent (unpublished) study of physical activity in the elderly living in communities, the unit repeat correlation was estimated in a pilot wave of data collection to be about 0.6.
has often been about 0.2, but in a recent (unpublished) study of physical activity in the elderly living in communities, the unit repeat correlation was estimated in a pilot wave of data collection to be about 0.6.
Under the null hypothesis ( ) the t-distribution is centered on 0, while under the alternative hypothesis that the actual effect is
) the t-distribution is centered on 0, while under the alternative hypothesis that the actual effect is  , it is centered on the value
, it is centered on the value  . Figure 11.2 shows two Gaussian distributions, the rejection region for the null hypothesis for a two-sided 5% Type I error (outside the vertical lines at ±1.96 on the horizontal scale) and the power when the separation between the null and the alternative hypothesis is
. Figure 11.2 shows two Gaussian distributions, the rejection region for the null hypothesis for a two-sided 5% Type I error (outside the vertical lines at ±1.96 on the horizontal scale) and the power when the separation between the null and the alternative hypothesis is  . Power is the amount of the alternative distribution that lies in the rejection region. It is apparent that if the separation were just 1.96 standard errors of
. Power is the amount of the alternative distribution that lies in the rejection region. It is apparent that if the separation were just 1.96 standard errors of  the power would be only 50%. To generate power of 85% the separation between the hypotheses must exceed the boundary of the rejection region by enough to pull 85% of the distribution under the alternative into the rejection region. Suppose we have a GRT with 6 units per condition. Let
the power would be only 50%. To generate power of 85% the separation between the hypotheses must exceed the boundary of the rejection region by enough to pull 85% of the distribution under the alternative into the rejection region. Suppose we have a GRT with 6 units per condition. Let  represent the value of the p-percentile point on the t-distribution based on
represent the value of the p-percentile point on the t-distribution based on  df. In a GRT with 6 units per condition, for example,
df. In a GRT with 6 units per condition, for example,  defines the rejection region for a two-sided test with Type I error of 5%. For 85% power we have
defines the rejection region for a two-sided test with Type I error of 5%. For 85% power we have  , indicating that the separation that is detectable with 85% power is 3.32 (2.23 + 1.09) standard errors of
, indicating that the separation that is detectable with 85% power is 3.32 (2.23 + 1.09) standard errors of  . In general,
. In general,  SE(
SE( ) and, in particular for the nested cohort baseline-adjusted analysis,
) and, in particular for the nested cohort baseline-adjusted analysis,


FIGURE 11.2 RELATIONSHIP BETWEEN THE DETECTABLE DIFFERENCE ( ) AND POWER
) AND POWER
Using repeated measures instead of baseline adjustment would involve comparing 4 means instead of 2, but the full effect of member-correlation would be felt, so

Formulation (3) uses the actual components of variance and  is the within-person variance, not the total variance of a single observation, which is (
is the within-person variance, not the total variance of a single observation, which is ( ). Many authors use the ICC as a standardized and portable measure of clustering effect; in formulas I prefer the VCR (=
). Many authors use the ICC as a standardized and portable measure of clustering effect; in formulas I prefer the VCR (=  /
/ ) but the two are readily interconvertible. We can rewrite (3) parsing out the factor
) but the two are readily interconvertible. We can rewrite (3) parsing out the factor  (
( ) to give
) to give

Note that VCR is different depending on the adjustments. Without adjustments  , whereas with adjustments
, whereas with adjustments  . When there is more than one occasion of measurement an important adjustment is adjustment for change (as in (4) or adjustment for baseline values (as in (5), implying that VCR (and ICC) for change will most likely differ from VCR (and ICC) for level. Another consequence of differing
. When there is more than one occasion of measurement an important adjustment is adjustment for change (as in (4) or adjustment for baseline values (as in (5), implying that VCR (and ICC) for change will most likely differ from VCR (and ICC) for level. Another consequence of differing  and
and  is that adjustment for personal characteristics may increase the
is that adjustment for personal characteristics may increase the  over
over  , depending on the relative impact of explaining personal level variance and the reduction in unit level variance. The lesson is that, in choosing from published estimated values of ICCs the onus is on the user to ensure the circumstances of the estimation fit, the usage being made of them, and, in particular, the analysis planned for the data.
, depending on the relative impact of explaining personal level variance and the reduction in unit level variance. The lesson is that, in choosing from published estimated values of ICCs the onus is on the user to ensure the circumstances of the estimation fit, the usage being made of them, and, in particular, the analysis planned for the data.
Often we have a good idea of the residual error,  , and knowledge is accumulating for the likely values of the ICC, which would give an estimate of
, and knowledge is accumulating for the likely values of the ICC, which would give an estimate of  as
as  ICC/(1 – ICC). Even better is to conduct a pilot study to generate good estimates of the components of variance for use in revising previously made power or detectable difference estimates.
ICC/(1 – ICC). Even better is to conduct a pilot study to generate good estimates of the components of variance for use in revising previously made power or detectable difference estimates.
A useful variant on (5) is to express the mimimal detectable difference,  , as a fraction of the total standard deviation,
, as a fraction of the total standard deviation,  . This standardized difference, the difference as a fraction of the standard deviation in the population, is called by Cohen (1988, 1992) the effect size
. This standardized difference, the difference as a fraction of the standard deviation in the population, is called by Cohen (1988, 1992) the effect size  . An extremely powerful experiment may be able to detect minute effects, but are the experimentally induced shifts worthwhile on the practical scale; the experiment could be a waste of resources. On the other hand, an underpowered experiment is able to detect only massive and unrealistic differences, for example, a whole standard deviation; again, the experiment is a waste of resources as it is unlikely to achieve any improvement in knowledge. A good experiment is designed to be fairly sure (power of 80% or more) to detect feasible (not too large) yet worthwhile (that is, of practical importance) differences. For primary outcomes, effect sizes between 0.2 and 0.3 (at adequate power) are usually both feasible and worthwhile, making for an excellent experiment; effect sizes between 0.3 and 0.4 may be adequate in some contexts; those between 0.4 and 0.5 are weak for primary outcomes, but may be useful for pilot studies, or for the exploration of the impact of the intervention on secondary outcomes in order to generate hypotheses.
. An extremely powerful experiment may be able to detect minute effects, but are the experimentally induced shifts worthwhile on the practical scale; the experiment could be a waste of resources. On the other hand, an underpowered experiment is able to detect only massive and unrealistic differences, for example, a whole standard deviation; again, the experiment is a waste of resources as it is unlikely to achieve any improvement in knowledge. A good experiment is designed to be fairly sure (power of 80% or more) to detect feasible (not too large) yet worthwhile (that is, of practical importance) differences. For primary outcomes, effect sizes between 0.2 and 0.3 (at adequate power) are usually both feasible and worthwhile, making for an excellent experiment; effect sizes between 0.3 and 0.4 may be adequate in some contexts; those between 0.4 and 0.5 are weak for primary outcomes, but may be useful for pilot studies, or for the exploration of the impact of the intervention on secondary outcomes in order to generate hypotheses.
We now extend the post-test only, or equally the baseline-adjusted nested cohort, design by crossing the design with a factor  (for time). The model (2) in shorthand can be written
(for time). The model (2) in shorthand can be written

By adding in the effect of crossing (“expanding”) the right-hand side by  we get
we get

in which we have used the facts that (i) the interaction of  with a constant,
with a constant,  , is just the main effect of
, is just the main effect of  , (ii) the interaction of two fixed effects is a fixed effect, but the interaction of a fixed effect with a random effect is random, and (iii) a main effect for member (
, (ii) the interaction of two fixed effects is a fixed effect, but the interaction of a fixed effect with a random effect is random, and (iii) a main effect for member ( ) is estimable in a cohort, that is, a member is crossed with
) is estimable in a cohort, that is, a member is crossed with  in a cohort, as each member of a cohort is observed at each time. On this last point, in a nested cross-section with multiple times of observation, the main effect for member (
in a cohort, as each member of a cohort is observed at each time. On this last point, in a nested cross-section with multiple times of observation, the main effect for member ( ) would be dropped from the model and its df go to error. The separation of the member variability into e and Te is exactly the usual separation of variability in repeated measures into between-person variability (e) and within-person variability (
) would be dropped from the model and its df go to error. The separation of the member variability into e and Te is exactly the usual separation of variability in repeated measures into between-person variability (e) and within-person variability ( ). In the corresponding ANOVA Table 11.2, each entry on the right-hand-side of (4) must have a line in the ANOVA. The expected mean squares can be determined using the method proposed in Hopkins (1976), which is much simpler than that of the Cornfield–Tukey algorithm described in Winer (1971).
). In the corresponding ANOVA Table 11.2, each entry on the right-hand-side of (4) must have a line in the ANOVA. The expected mean squares can be determined using the method proposed in Hopkins (1976), which is much simpler than that of the Cornfield–Tukey algorithm described in Winer (1971).
TABLE 11.2 ANOVA TABLE FOR THE REPEATED MEASURES ANALYSIS IN A NESTED COHORT DESIGN OR THE PRE/POST-TEST ANALYSIS IN A NESTED CROSS-SECTION DESIGNa
| Line | Source | df | Mean square | Expected (MS)b |
| 8 | Intercept | 1 | ||
| 7 | Cond | C – 1 | MScond |  |
| 6 | u:C | c(g – 1) | MSunits |  |
| 5 | m:u:C | cg(m – 1) | MSmember |  |
| 4 | Time | T – 1 | MStime |  |
| 3 | TC | (t – 1)(c – 1) | MStime*cond |  |
| 2 | TG:C | c(t – 1)(g – 1) | MStime*unit |  |
| 1 | Tm:u:C | cg(t – 1)(m – 1) | MSerror |  |
| Total df = | cgtm |
a Line 5 must be dropped down to line 1 for the nested cross-sectional design.
b The  ,
,  , and
, and  are non-centrality parameters for the main effects of condition, time, and their interaction, respectively. Under null hypotheses they are zero.
are non-centrality parameters for the main effects of condition, time, and their interaction, respectively. Under null hypotheses they are zero.
The question of interest is whether the experiment changed the differences of the intervention means away from the control means. The null hypothesis is  :
:  and is tested by the ratio of MStime*cond/MStime*unit, where, under the null hypothesis, numerator and denominator would have the same expected values, though based on different df. The ratio under H0 is distributed as an F-statistic based on
and is tested by the ratio of MStime*cond/MStime*unit, where, under the null hypothesis, numerator and denominator would have the same expected values, though based on different df. The ratio under H0 is distributed as an F-statistic based on  and
and  df. This overall test for any differences is very non-specific and, if significant, would always be followed by an investigation of a specific difference, for example, between intervention and control (
df. This overall test for any differences is very non-specific and, if significant, would always be followed by an investigation of a specific difference, for example, between intervention and control ( ) conditions comparing the baseline to a specific time point (
) conditions comparing the baseline to a specific time point ( ). Then the F-statistic has 1 and
). Then the F-statistic has 1 and  df. The square root of an F-statistic with 1,
df. The square root of an F-statistic with 1,  df is distributed as a t-statistic based on
df is distributed as a t-statistic based on  .
.
For the nested cross-section line 5 is dropped and its  df fall down to line 1 to make the error
df fall down to line 1 to make the error  . The form of this df term is
. The form of this df term is  in every cell, and is another indicator that in the nested cross-section, member is nested in the time × unit cell, that is, the member observation occurs only in a specific time in a specific unit. The repeat correlation for the units is
in every cell, and is another indicator that in the nested cross-section, member is nested in the time × unit cell, that is, the member observation occurs only in a specific time in a specific unit. The repeat correlation for the units is  . In the nested cohort, the within member repeat correlation is
. In the nested cohort, the within member repeat correlation is  . In the nested cross-section we would be comparing 4 means instead of the 2 just as in Equation (4) but with
. In the nested cross-section we would be comparing 4 means instead of the 2 just as in Equation (4) but with  ; however, member-level covariates may be introduced to form adjusted means and reducing the member-level residual variance by a factor
; however, member-level covariates may be introduced to form adjusted means and reducing the member-level residual variance by a factor  . The
. The  still includes a unit repeat correlation as long as the repeat design returns to the same units.
still includes a unit repeat correlation as long as the repeat design returns to the same units.
Let us duplicate using the VCR, the calculation using the ICC of the detectable difference given in Wagenaar et al. (1994, pp. 97–98). Note that  in their notation is the total variance, which we symbolize as
in their notation is the total variance, which we symbolize as  , although previously we have omitted the subscript w (for within). The design calls for 200 persons per community. For 30-day alcohol use the within-person variance estimate is
, although previously we have omitted the subscript w (for within). The design calls for 200 persons per community. For 30-day alcohol use the within-person variance estimate is  , which must be divided by (1 – ICC) to produce the total variance; the CMCA paper did not quite get this right. The
, which must be divided by (1 – ICC) to produce the total variance; the CMCA paper did not quite get this right. The  implies
implies  ;
;  while the
while the  . Calculations will differ in having
. Calculations will differ in having  versus
versus  under the square-root sign. However, these quantities are numerically equivalent so the detectable difference calculated using VCR or ICC will be the same. Also note that the assumption is being made that the between-unit component of variance will have the same 50% variance reduction from the use of baseline drinking, age, and gender as covariates. The VCR formulation keeps the components separated and allows separate fractions for variance reduction of the within-unit and the between-unit components of variance.
under the square-root sign. However, these quantities are numerically equivalent so the detectable difference calculated using VCR or ICC will be the same. Also note that the assumption is being made that the between-unit component of variance will have the same 50% variance reduction from the use of baseline drinking, age, and gender as covariates. The VCR formulation keeps the components separated and allows separate fractions for variance reduction of the within-unit and the between-unit components of variance.
The ANOVA model based on Table 11.2 makes a strong assumption. It assumes that each unit is expected to respond equally to the intervention or lack of it. With only two time points one cannot separate variability of unit-response from inherent variability of units—the difference and the response “slope” are measured by the same subtraction. If the number of occasions is 3 or more, then a more realistic model relaxing this assumption is that each unit has its own response-slope, but the average response slopes differ between the intervention and control conditions (Murray et al. 1998). This is the random coefficients model.
The random coefficients (RC) model. When the design calls for more than two time points and interest lies in response to time on a parametric rather than a categorical scale, a more robust model making weaker assumptions than the ANOVA model is possible, and preferred. The random coefficients (RC) model assumes that the units in a condition have trajectories that exhibit random variation around the mean trajectory in that condition, whereas in the ANOVA model it is assumed that each unit in a condition has a common trajectory. For a comparison of the models by simulation see Murray et al. (1998); for practical applications see Brown and Prescott (1999) and Twisk (2003); for theory see Longford (1993). Many other references would be possible, especially in the educational sphere, for example, Bryk and Raudenbush (1992) and Raudenbush and Bryk (2002). Estimates of components of variance for slopes are not as yet available in the literature; for two outcomes in a single context see Murray, Feldman, and McGovern (2000).
The impact on power from a limited number of units. Whether in the ANOVA or the RC model for analyzing a GRT with  time points, the degrees of freedom of the test statistic are governed by the number of units per condition (
time points, the degrees of freedom of the test statistic are governed by the number of units per condition ( ), in the ANOVA model
), in the ANOVA model  or in the RC model
or in the RC model  , indexing the precision with which the variability between the units is assessed. As a consequence, a design with few units has double penalties—the means per condition are less precise because being divided by a smaller g and the rejection region is wider because the precision for estimating the standard error of the intervention effect is less. There is good reason to reread Cornfield's statement quoted at the head of this chapter. We have already examined how power and detectable difference depend on the choices of the number of units (
, indexing the precision with which the variability between the units is assessed. As a consequence, a design with few units has double penalties—the means per condition are less precise because being divided by a smaller g and the rejection region is wider because the precision for estimating the standard error of the intervention effect is less. There is good reason to reread Cornfield's statement quoted at the head of this chapter. We have already examined how power and detectable difference depend on the choices of the number of units ( ) per condition and on the number of members (
) per condition and on the number of members ( ). What is the impact of the degrees of freedom on the term (
). What is the impact of the degrees of freedom on the term ( ) and consequently on the increased value of detectable D? Assuming typical values for Type I error at 5% (two-sided) and power at 85%, Table 11.3 shows the value required for
) and consequently on the increased value of detectable D? Assuming typical values for Type I error at 5% (two-sided) and power at 85%, Table 11.3 shows the value required for  in power formulas and the percent increase (penalty) in the separation between the null and alternative hypotheses. Having 6 units per condition (
in power formulas and the percent increase (penalty) in the separation between the null and alternative hypotheses. Having 6 units per condition ( ) may be sustainable, but the penalty increases rapidly if fewer units per condition are in the design. The comparison is against the Gaussian distribution (equivalent to df = infinity).
) may be sustainable, but the penalty increases rapidly if fewer units per condition are in the design. The comparison is against the Gaussian distribution (equivalent to df = infinity).
TABLE 11.3 IMPACT ON THE FACTOR (t1−a/2 + tpower) IN POWER CALCULATIONS AS A FUNCTION OF df AVAILABLE
| t-dist df | t1−a/2 | Tpower | t1−a/2 + tpower | Penalty |
| Gaussian | 1.96 | 1.04 | 3.00 | – |
| 100 | 1.98 | 1.04 | 3.03 | 1% |
| 50 | 2.01 | 1.05 | 3.06 | 2% |
| 20 | 2.09 | 1.06 | 3.15 | 5% |
| 16 | 2.12 | 1.07 | 3.19 | 6% |
| 10 | 2.23 | 1.09 | 3.32 | 11% |
| 6 | 2.45 | 1.13 | 3.58 | 20% |
| 4 | 2.78 | 1.19 | 3.97 | 32% |
| 2 | 4.30 | 1.39 | 5.69 | 90% |
Type I error = a = 5% (two-sided) and Power = 85%.
Permutation distributions and significance tests. How reliable are the distributional assumptions underlying the model-based analyses typified by the ANOVA and RC models? Fisher (1935) introduced the randomization approach to testing, which he considered to be the gold standard; indeed, Fisher has said that ANOVA is good only so far as its results approximate those of the randomization test. Application of the permutation test to randomized community trials especially belongs to Gail and colleagues (1992, 1996). Under the null hypothesis, the designation of a unit as intervention or control is irrelevant, so arbitrary reassignment of half the units into “intervention” and the other half into “control” status generates an equally possible (under  ) experimental result. All possible reassignment permutations are enumerated and the corresponding experimental results generated. These theoretically equi-possible results (under
) experimental result. All possible reassignment permutations are enumerated and the corresponding experimental results generated. These theoretically equi-possible results (under  ) constitute the distribution against which the actual observed result is assessed. If the observed result lies far in the tail, it has a low probability of being observed under
) constitute the distribution against which the actual observed result is assessed. If the observed result lies far in the tail, it has a low probability of being observed under  , raising suspicion against
, raising suspicion against  —a true significance test. Given that community trials typically have small numbers of units, the permutation or randomization test procedure may have appeal. It is possible to adjust the unit statistic, commonly the mean, for covariates before permuting (Murray et al. 2005). An entry to the extensive literature may be gained from Braun and Feng (2001), Berger (2000), Ludbrook (1998), Ludbrook and Dudley (1994), Good (1994), Edgington (1995), and Manley (1997). Power calculations for the permutation test are difficult and may best be done using simulation methods (Brookmeyer and Chen 1998).
—a true significance test. Given that community trials typically have small numbers of units, the permutation or randomization test procedure may have appeal. It is possible to adjust the unit statistic, commonly the mean, for covariates before permuting (Murray et al. 2005). An entry to the extensive literature may be gained from Braun and Feng (2001), Berger (2000), Ludbrook (1998), Ludbrook and Dudley (1994), Good (1994), Edgington (1995), and Manley (1997). Power calculations for the permutation test are difficult and may best be done using simulation methods (Brookmeyer and Chen 1998).
Power calculations require compromises. Power and sample size calculations have quite a few parameters to be set or to be estimated. Usually straightforward are the Type I error rate (5% two-sided) and the power (80% or 85%). Less standard are the detectable difference, and in GRTs the combination of members (whether cross-sectional or cohort) and the number of units. Add in estimated ICCs, estimated reductions in variance achievable by covariate adjustment, and how any multiple comparisons are handled (in the case of more than one primary outcome), and the mix is to say the least “interesting.” How all these parameters are juggled to make a cogent package is the art of grant-writing; the scenarios presented need to be meaningful, realistic, and almost invariably a reasonable compromise showing that according to good estimates the study is neither too powerful nor too weak—both a waste of resources.
Some studies try to boost power by resorting to a one-sided test, which indeed does require less separation between the null and alternative hypotheses for a given power. Unless a solid argument can be made that the intervention can in no way have a deleterious (if unexpected) outcome, such a strategy is suspect. Further, in a well-designed study with adequate power little is gained by using a one-sided test. A study with an adequate 16 units ( ) and 85% power using a two-tailed 5% test to detect a realistic outcome, in other words, a good study, would push the power up to 91% at the cost of the assumption underlying the use of the one-sided test. On the other hand, a weak study having 8 units (
) and 85% power using a two-tailed 5% test to detect a realistic outcome, in other words, a good study, would push the power up to 91% at the cost of the assumption underlying the use of the one-sided test. On the other hand, a weak study having 8 units ( ) with power 70% under the two-sided 5% test would increase the power to about 83% if the switch was made to a one-sided test. Good study designs gain little from using a one-sided test; invoking a one-sided test is indicative of a weak study struggling to increase power at the expense of a strong assumption that ignores the possibility of unintended consequences.
) with power 70% under the two-sided 5% test would increase the power to about 83% if the switch was made to a one-sided test. Good study designs gain little from using a one-sided test; invoking a one-sided test is indicative of a weak study struggling to increase power at the expense of a strong assumption that ignores the possibility of unintended consequences.
Thus the statistician and the principal investigator need to work together in an iterative pattern to arrive at a reasonable place “in the ball park.” Specification of the expected intervention effect, that is, the detectable difference, is the province of the principal investigator. In TAAG with its six centers, the principal investigators at each site were polled for what they would expect as a likely intervention effect—indeed, for those exposed to two years of intervention and a different amount for those girls exposed to only the second year of intervention. Finally, a consensus compromise was achieved and those values in the TAAG power calculations. Other areas of discussion between the researchers and the statistician involve the variability and correlation of the outcome measures including which survey instrument(s) will be used, which measure(s) is (are) primary, and general ideas about the budget constraint making certain scenarios unrealistic. Finally, the study design comes together into a cogent whole which is in the ballpark from all perspectives. That is why it is a game, involving compromise and diplomacy.
Power is calculated on a statistical model and we need always to keep in mind the dictum of G.E.P. Box (1979), “All models are wrong, but some are useful.” Albert Einstein said “Models should be simple, but not too simple.” The hypotheses to be tested in a group randomized trial in social epidemiology are relatively simple, so the methods used for power can be relatively simple.
Finally, power is calculated based on the assumption that the intervention achieves such an effect. An exaggerated estimate of the likely magnitude of the effect achievable by the intervention by an overly optimistic researcher will lead to optimistic power estimates. Power needs to be calculated for realistic detectable differences, neither too small to be worthwhile substantively nor too big to be “pie in the sky.” Cohen's effect size helps to keep magnitudes of detectable differences in perspective. Ultimately, the experiment relies on a strong, well-applied intervention.
Implementation of Randomized Community Trials
Earlier we saw that design of GRTs is complicated. Implementation of design is complicated also. An experiment starts as a germ in the head of the PI based on some theoretical model of how things work and ends with inferences based on the observed results. In between attention must be given to many details and solutions found to many difficulties that arise. Experts in subject matter, in statistics, in public relations, in management, in planning and coordination, in intervention, and in evaluation each have parts to play. Attention must be given to areas such as:
- Deciding on a “frame” of units
- Deciding primary and secondary outcome measures
- Dealing with Institutional Review Boards, both local and in the communities
- Securing agreement to randomization—from units, from members(?)
- Getting the units interested and motivated
- Agreement from units to participate, even if randomized to control status
- Data for matching or stratification in the design
- Baseline before randomization and extended baseline for maturational history
- Actual randomization
- Implementation of the intervention
- Measuring fidelity to intervention program
- Process measures.
Some idea can be gained of the nitty-gritty difficulties of actually setting up a community randomized trial from the report by Watson et al. (2004). Not often does the readership of the scientific journals become acquainted with the picky details of implementing a cluster randomized trial. More on the statistical aspects but again laying out some of the items that call for attention are to be found in the reports from, for example, TPOP (Forster and Wolfson 1998) or Allina Medical Systems (Roski et al. 2003).
Summary
Why do GRTs? The arguments against GRTs are strong—they are expensive, difficult to implement, fraught with problems along the way, tend to be weak in power, and some of the audience question what the GRT means for individual behavior or health.
So, why do GRTs? The T (trial) and the R (randomization) of GRT are crucial for inference, whether group randomized or not, so the question simplifies to “Why use groups?” From the theoretic perspective, when interest focuses on contextual effects, the GRT is the most feasible way to manipulate contexts by having the control groups act as surrogates for the (unobservable) counterfactual experience. Second, from the practical perspective, the only way to implement a truly contextual intervention is by acting on whole groups. Sometimes an individually directed intervention may be implemented as a GRT to avoid contamination between control and intervention participants, but in this case it is well worth asking the question “Can the intervention be crossed with the units in which the experiment will be carried out?” For example, a doctor in a clinic may be blinded to the status of a patient and unknowingly prescribe an active drug or placebo to the patient. This would be unlikely to pass IRB review, but at least it is a conceivable design! Study TEAM (Hennrikus et al. 2005) did indeed have four hospitals, but both intervention and control participants occurred in each hospital, so that intervention was crossed with hospital. In that case, because intervention is not nested in the hospital, the analyst has the option of considering hospital as a fixed or as a random effect. The contrast of intervention effect with control effect effectively removes the “bump” associated with any realized hospital component of variance. However, a true contextual intervention must apply to the whole unit, and hence must be a group randomized trial. Be warned that not all collaborators, nor all reviewers, will understand that a contextual study is not just an individual-level intervention applied in a group.
Social epidemiology is concerned with contextual effects. In lieu of observational studies, which are inherently weak inferentially (Oakes, 2004a, 2004b), the GRT offers the inferential benefits of the RCT (randomized clinical trial) to researchers concerned with the impact of social contexts on health of people in communities.
References
- Alker, H.R., Jr. (1969) A typology of ecological fallacies, in Social Ecology (eds M. Doggan and S. Rokkan), MIT Press, Cambridge, MA, pp. 69–81.
- Berger, V.W. (2000) Pros and cons of permutation tests in clinical trials. Statistics in Medicine, 19, 1319–1328.
- Blackburn, H. (2004) It Isn't Always Fun…, privately published by Library of Congress.
- Box, G.E.P. (1979) Robustness in the strategy of scientific model building, in Robustness in Statistics (eds R.L. Launer and G.N. Wilkinson), Academic Press, New York, p. 201.
- Braun, T. and Feng, Z. (2001) Optimal permutation tests for the analysis of group randomized trials. Journal of the American Statistical Association, 96 (456), 1424–1432.
- Brookmeyer, R. and Chen, Y.-Q. (1998) Person-time analysis of paired community intervention trials when the number of communities is small. Statistics in Medicine, 17 (18), 2121–2132.
- Brown, H. and Prescott, R. (1999) Applied Mixed Models in Medicine, John Wiley & Sons, Inc., New York.
- Bryk, A.S. and Raudenbush, S.W. (1992) Hierarchical Linear Models: Applications and Data Analysis Methods, 1st edn, Sage Publications, Newbury Park.
- Carleton, R.A., Lasater, T.M., Assaf, A.R., Feldman, H.A., McKinlay, S., and the Pawtucket Heart Health Program Writing Group (1995) The Pawtucket Heart Health Program: community changes in cardiovascular risk factors and projected disease risk. American Journal of Public Health, 85 (6), 777–785.
- Cohen, J. (1988) Statistical Power Analysis for the Behavioral Sciences, 2nd edn, Lawrence Erlbaum, Hillsdale, NJ.
- Cohen, J. (1992) A primer on power. Psychological Bulletin, 112 (1), 155–159.
- Cook, T.D. and Campbell, D.T. (1979) Quasi-experimentation: Design and Analysis Issues for Field Settings, Houghton Mifflin Company, Boston, MA.
- Corbeil, R.R. and Searle, S.R. (1976) Restricted maximum likelihood (REML) estimation of variance components in the mixed model. Technometrics, 18, 31–38.
- Cornfield, J. (1978) Randomization by group: a formal analysis. American Journal of Epidemiology, 108 (2), 100–102.
- Diehr, P., Martin, D.C., Koepsell, T., and Cheadle, A. (1995a) Breaking the matches in a paired t-test for community interventions when the number of pairs is small. Statistics in Medicine, 14, 1491–1504.
- Diehr, P., Martin, D.C., Koepsell, T. (1995b) Optimal survey design for community intervention evaluations: cohort or cross-sectional? Journal of Clinical Epidemiology, 48 (12), 1461–1472.
- Donner, A. (1982) An empirical study of cluster randomization. International Journal of Epidemiology, 11 (3), 283.
- Donner, A. (1985) A regression approach to the analysis of data arising from cluster randomization. International Journal of Epidemiology, 14 (2), 322–326.
- Donner, A., Birkett, N., and Buck, C. (1981) Randomizaton by cluster: sample size requirements and analysis. American Journal of Epidemiology, 114 (6), 906–914.
- Donner, A., Brown, K.S., and Brasher, P. (1990) A methodological review of non-therapeutic intervention trials employing cluster randomization, 1979-–1989. International Journal of Epidemiology, 19, 795–800.
- Donner, A. and Klar, N. (2000) Design and Analysis of Cluster Randomization Trials in Health Research, Arnold, London.
- Donner, A. and Koval, J.J. (1982) Design considerations in the estimation of intraclass correlation. Annals of Human Genetics, 46, 271–277.
- Edgington, E.S. (1995) Randomization Tests, 3rd edn, Marcel Dekker, Inc., New York.
- Farquhar, J.W. (1978) The community-based model of life style intervention trials. American Journal of Epidemiology, 108 (2), 103–111.
- Farquhar, J.W., Fortman, S.P., Maccoby, N., et al. (1985) The Stanford Five-City Project: design and methods. American Journal of Epidemiology, 122, 323–334.
- Farquhar, J.W., McCoby, N., Wood, P.D., et al. (1977) Community education for cardiovascular health. Lancet, 1, 1192–1195.
- Feldman, H.A. and McKinlay, S.M. (1994) Cohort versus cross-sectional design in large field trials: precision, sample size, and a unifying model. Statistics in Medicine, 13, 61–78.
- Fisher, R.A. (1935) The Design of Experiments, Oliver and Boyd, Edinburgh; reprinted 1971, 8th edn, Hafner Publishing Company, Inc., New York; reissued 1990 in Statistical Methods, Experimental Design, and Scientific Inference, Oxford University Press, Oxford.
- Forster, J.L. and Wolfson, M. (1998) Youth access to tobacco: policies and politics. Annual Review Public Health, 19, 203–235.
- Frost, W.H. (1937) How much control of tuberculosis? American Journal of Public Health, 27, 759–766.
- Gail, M.H., Pechacek, T., and Corle, D. (1992) Aspects of statistical design for the community intervention trial for smoking cessation (COMMIT). Controlled Clinical Trials, 13, 6–21.
- Gail, M.H., Mark, S.D., Carroll, R.J., et al. (1996) On design considerations and randomization-based inference for community intervention trials. Statistics in Medicine, 15, 1069–1092.
- Goldstein, H. (1987) Multilevel Models in Educational and Social Research, Oxford University Press, New York.
- Good, P.I. (1994) Permutation Tests. A Practical Guide to Resampling Methods for Testing Hypotheses, Springer-Verlag, Inc., New York.
- Hannan, P.J., Murray, D.M., Jacobs, D.R., Jr, and McGovern, P.G. (1994) Parameters to aid in the design and analysis of community trials: intraclass correlations from the Minnesota Heart Health Program. Epidemiology, 5, 88–95.
- Hennrikus, D.J., Lando, H.A., McCarty, M.C., et al. (2005) The TEAM Project: the effectiveness of smoking cessation intervention with hospital patients. Preventive Medicine, 40, 249–258.
- Hopkins, K.D. (1976) A simplified method for determining expected mean squares and error terms in the analysis of variance. Journal of Experimental Education, 45 (2), 13–18.
- Hopkins, K.D. (1982) The unit of analysis: group means versus individual observations American Education Research Journal, 19 (1), 5–18.
- Jacobs, D.R., Luepker, R.V., Mittelmark, M., et al. (1986) Community-wide prevention strategies: evaluation design of the Minnesota Heart Health Program. Journal of Chronic Diseases, 39 (10), 775–788.
- Jeffery, R.W., Forster, J.L., French, S.A., et al. (1993) The Healthy Worker Project: a worksite intervention for weight control and smoking cessation. American Journal of Public Health, 83 (3), 395–401.
- Keys, A., Blackburn, H.W., Van Buchem, F.S.P., et al. (1967) Epidemiological studies related to coronary heart disease: characteristics of men aged 40–59 in seven countries. Acta Medicine of Scandinavia, 460 (Suppl. 180), 1–392.
- Kish, L. (1965) Survey Sampling, JohnWiley & Sons, Inc., New York.
- Koepsell, T.D., Diehr, P.H., Cheadle, A., and Kristal, A. (1995) Invited commentary: Symposium on Community Intervention Trials. American Journal of Epidemiology, 142 (6), 594–599.
- Krieger, N. (1992) Overcoming the absence of socioeconomic data in medical records: validation and application of a census-based methodology. American Journal of Public Health, 82, 703–710.
- Krieger, N. (1994) Epidemiology and the web of causation: has anyone seen the spider? Society of Science and Medicine, 39 (7), 887–903.
- Laird, N.M. and Ware, J.H. (1982) Random-effects models for longitudinal data. Biometrics, 38, 963–974.
- Longford, N.T. (1993) Random Coefficients Models, Oxford University Press, New York.
- Ludbrook, J. (1994) Special Article: advantages of permutation (randomization) tests in clinical and experimental pharmacology and physiology. Clinical and Experimental Pharmacology and Physiology, 21, 673–686.
- Ludbrook, J. and Dudley, H. (1998) Why permutation tests are superior to t and F tests in biomedical research. The American Statistician, 52, 127–132.
- Manly, B.F.J. (1997) Randomization, Bootstrap and Monte Carlo Methods in Biology, 2nd edn, Chapman & Hall, London.
- Martin, D.C., Diehr, P., Perrin, E.B., and Koepsell, T. (1993) The effect of matching on the power of randomized community intervention studies. Statistics in Medicine, 12, 329–338.
- McCullagh, P. and Nelder, J.A. (1983) Generalized Linear Models, 1st edn, Chapman & Hall, New York.
- McKinlay, S.M. (1994) Cost-efficient designs of cluster unit trials Preventive Medicine, 23, 606–611.
- Mood, A. McF. (1950) Introduction to the Theory of Statistics, McGraw-Hill Book Company, Inc,, New York, Section 7.5, pp. 133–136.
- Murray, D.M. (1998) Design and Analysis of Group Randomized Trials, Oxford University Press, New York.
- Murray, D.M., Feldman, H.A., McGovern, P.G. (2000) Components of variance in a group-randomized trial analyzed via a random-coefficients model: the REACT Trial. Statistical Methods in Medical Research, 9, 117–133.
- Murray, D.M. and Hannan, P.J. (1990) Planning for the appropriate analysis in school-based drug-use prevention studies. Journal of Consulting and Clinical Psychology, 58 (4), 458–468.
- Murray, D.M., Hannan, P.J., Wolfinger, R.D., et al. (1998) Analysis of data from group-randomized trials with repeat observations on the same groups. Statistics in Medicine, 17, 1581–1600.
- Murray, D.M., Hannan, P.J., Varnell, S.P., et al. (2006). A comparison of permutation and mixed-model regression methods for the analysis of simulated data in the context of a group-randomized trial. Statistics in Medicine, 25 (3), 375–388.
- Murray, D.M. and Short, B. (1995) Intraclass correlation among measures related to alcohol use by young adults: estimates, correlates and applications in intervention studies. Journal of Studies on Alcohol, 56 (6), 681–694.
- Murray, D.M., Varnell, S.P., and Blitstein, J.L. (2004) Design and analysis of group-randomized trials: a review of recent methodological developments American Journal of Public Health, 94 (3), 423–432.
- Oakes, J.M. (2004a) The (mis)estimation of neighborhood effects: causal inference in a practicable social epidemiology. Social Science and Medicine, 58, 1929–1952 (with discussion).
- Oakes, J.M. (2004b) Causal inference and the relevance of social epidemiology. Social Science and Medicine, 58, 1969–1971.
- Proschan, M.A. (1996) On the distribution of the unpaired t-statistic with paired data. Statistics in Medicine, 15, 1059–1063.
- Puska, P., Salonen, J.T., Nissenen, A., et al. (1983) Change in risk factors for coronary heart disease during 10 years of community intervention programme (North Karelia Project). British Medical Journal Clinical Research Edition, 287 (6408), 1840–1844.
- Raudenbush, S.W. (1997) Statistical analysis and optimal design in cluster randomized trials. Psychological Methods, 2 (2),173–185.
- Raudenbush, S.W. and Bryk, A.S. (2002) Hierarchical Linear Models: Applications and Data Analysis Methods, 2nd edn, Sage Publications, Thousand Oaks, CA.
- Robinson, W.S. (1950) Ecological correlations and the behavior of individuals. American Sociology Reviews, 15, 351–357.
- Roski, J., Jeddeloh, R., An, L., et al. (2003) The impact of financial incentives and a patient registry on health quality: targeting smoking cessation clinical practice patterns and patient outcomes. Preventive Medicine, 36, 291–299.
- Senn, S. (2004) Added values: controversies concerning randomization and additivity in clinical trials. Statistics in Medicine, 23 (24), 3729–3753.
- Simpson, J.M., Klar, N., and Donner, A. (1995) Accounting for cluster randomization: a review of primary prevention trials, 1990 through 1993. American Journal of Epidemiology, 85 (10), 1378–1383.
- Singer, J.D. (1998) Using SAS PROC MIXED to fit multilevel models, hierarchical models, and individual growth curves. Journal of Educational and Behavioral Statistics, 24 (4), 322–354.
- Snow, J. (1849) On the Mode of Communication of Cholera, vol. 8, London; 2nd edn 1955. Accessed at: http://www.csiss.org/classics/content/8.
- Snow, J. (1936) Snow on Cholera—A Reprint of Two Papers, The Commonwealth Fund, New York, pp. 1–175.
- Sorenson, G., Emmons, K., Hunt, M.K., and Johnston, D. (1998) Implications of the results of community intervention trials Annual Review of Public Health, 19, 379–416.
- Twisk, J.W.R. (2003) Applied Longitudinal Data Analysis in Epidemiology: A Practical Guide, Cambridge University Press, New York.
- Varnell, S.P., Murray, D.M., Janega, J.B., and Blitstein, J.L. (2004) Design and analysis of group-randomized trials: a review of recent practices. American Journal of Public Health, 94 (3), 393–399.
- Wagenaar, A.C., Murray, D.M., Wolfson, M., et al. (1994) Communities mobilizing for change on alcohol: design of a randomized community trial. Journal of Community Psychology, CSAP Special Issue, 79–101.
- Watson, L., Small, R., Brown, S., Dawson, W., and Lumley, J. (2004) Mounting a community-randomized trial: sample size, matching, selection and randomization issues in PRISM. Controlled Clinical Trials, 25 (3), 235–250.
- Wedderburn, R.W.M. (1974) Quasilikelihood functions, generalized linear models and the Gauss–Newton method. Biometrika, 61, 439–447.
- Wedderburn, R.W.M. (1976) On the existence and uniqueness of the maximum likelihood estimates for certain generalized linear models. Biometrika, 63, 27–32.
- WHO Expert Committee (1982) Prevention of coronary heart disease, Technical Report Series 678, World Health Organization, Geneva.
- Williams, P.T., Fortmann, S.P., Farquhar, J.W., et al. (1981) A comparison of statistical methods for evaluating risk factor changes in community-based studies: an example from the Stanford Three-Community Study. Journal of Chronic Diseases, 34 (11), 565–571.
- Winer, B.J. (1971) Statistical Principles in Experimental Design, 2nd edn, McGraw-Hill Book Company, New York, pp. 371–375.
- Zucker, D.M. (1990) An analysis of variance pitfall: the fixed effects analysis in a nested design. Educational and Psychological Measurement, 50, 731–738.
- Zucker, D.M., Lakatos, E., Webber, L.S., et al. (1995) Statistical design of the Child and Adolescent Trial for Cardiovascular Health (CATCH): implication of cluster randomization. Controlled Clinical Trials, 16, 96–118.