It is safe to say that one of the most powerful supervised deep learning models is convolutional neural networks (abbreviated as CNN or ConvNet). CNN is a class of deep learning networks, mostly applied to image data. However, CNN structures can be used in a variety of real-world problems including, but not limited to, image recognition, natural language processing, video analysis, anomaly detection, drug discovery, health risk assessment, recommender systems, and time-series forecasting.
CNNs achieve a high level of accuracy by assembling complex patterns using the more basic patterns found in the training data. For instance, from lines to an eyebrow, from two eyebrows to a human face, and then to a full human figure, CNNs can correctly detect humans in an image by using mere lines. To assemble these patterns, CNNs require a small amount of data preparation since their algorithm automatically performs these operations. This characteristic of CNNs offers an advantage compared to the other models used for image processing.
Today, the overall architecture of the CNNs is already streamlined. The final part of CNNs is very similar to feedforward neural networks (RegularNets, multilayer perceptron), where there are fully connected layers of neurons with weights and biases. Just like in feedforward neural networks, there is a loss function (e.g., crossentropy, MSE), a number of activation functions, and an optimizer (e.g., SGD, Adam optimizer) in CNNs. Additionally, though, in CNNs, there are also Convolutional layers, Pooling layers, and Flatten layers.
In the next section, we will take a look at why using CNN for image processing is such a good idea.
I will usually refer to image data to exemplify the CNN concepts. But, please note that these examples are still relevant for different types of data such as audio waves or stock prices.
Why Convolutional Neural Networks?
The main architectural characteristic of feedforward neural networks is the intralayer connectedness of all the neurons. For example, when we have grayscale images with 28 x 28 pixels, we end up having 784 (28 x 28 x 1) neurons in a layer that seems manageable. However, most images have way more pixels, and they are not in grayscale. Therefore, when we have a set of color images in 4K ultra HD, we end up with 26,542,080 (4096 x 2160 x 3) different neurons in the input layer that are connected to the neurons in the next layer, which is not manageable. Therefore, we can say that feedforward neural networks are not scalable for image classification. However, especially when it comes to images, there seems to be little correlation or relation between two individual pixels unless they are close to each other. This important discovery led to the idea of Convolutional layers and Pooling layers found in every CNN architecture.
CNN Architecture
Usually, in a CNN architecture, there are several convolutional layers and pooling layers at the beginning, which are mainly used to simplify the image data complexity and reduce their sizes. In addition, they are very useful to extract complex patterns from the basic patterns observed in images. After using several convolutional and pooling layers (supported with activation functions), we reshape our data from two-dimensional or three-dimensional arrays into a one-dimensional array with a Flatten layer. After the flatten layer, a set of fully connected layers take the flattened one-dimensional array as input and complete the classification or regression task. Let’s take a look at these layers individually.
Layers in a CNN
We are capable of using many different layers in a convolutional neural network. However, convolutional, pooling, and fully connected layers are the most important ones. Therefore, let’s quickly cover these layers before we implement them in our case studies.
Convolutional Layers
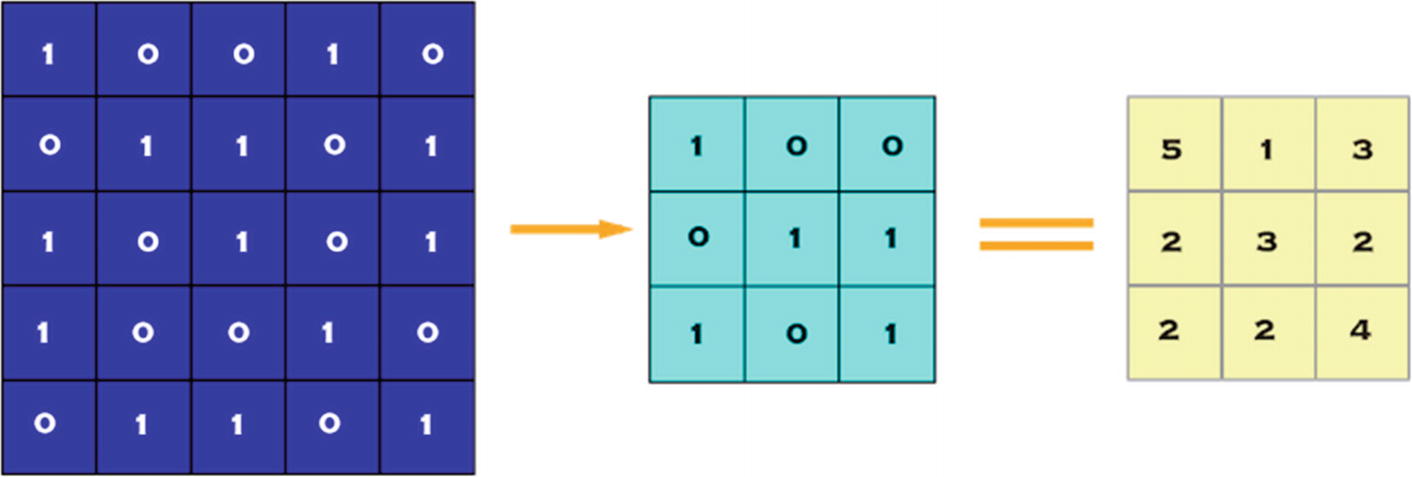
Convolution of 5 x 5 Pixel Image with 3 x 3 Pixel Filter (Stride = 1 x 1 pixel)
Filtering
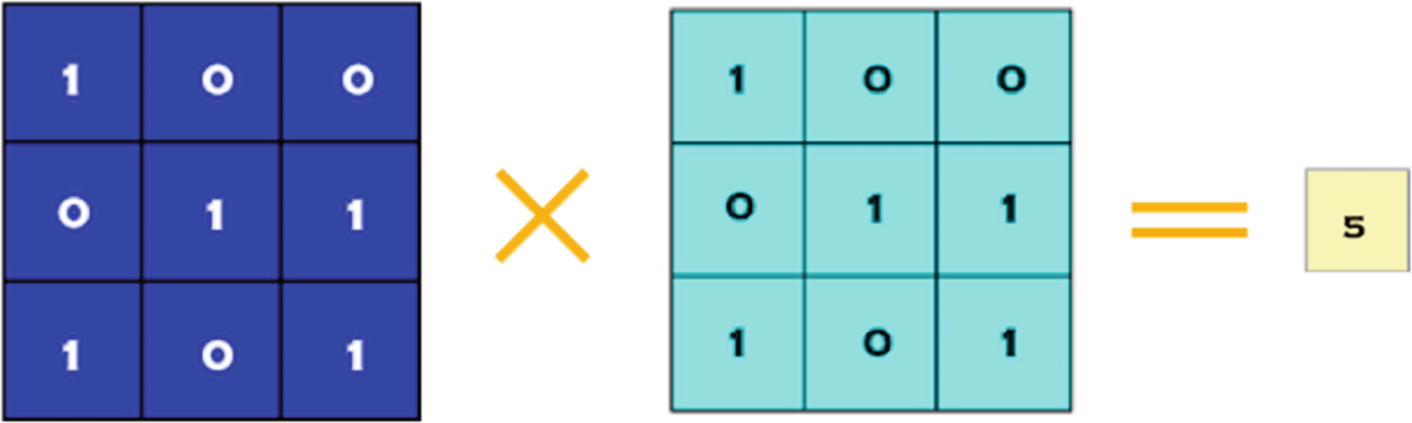
The Very First Filtering Operation for the Convolution Shown in Figure 7-1
The Table of Calculations for Figure 7-2
Rows | Calculations | Result |
|---|---|---|
1st row | (1x0) + (0x0) + (0x0) + | |
2nd row | (0x0) + (1x1) + (1x1) + | = 5 |
3rd row | (1x1) + (0x0) + (1x1) |
Using a too large filter would reduce the complexity more, but also cause the loss of important patterns. Therefore, we should set an optimal filter size to keep the patterns and adequately reduce the complexity of our data.
Strides
If we select a 1 x 1 pixel stride, we end up shifting the filter 9 times to process all the data.
If we select a 2 x 2 pixel stride, we can process the entire 5 x 5 pixel image in 4 filter operations.
Using a large stride value would decrease the number of filter calculations. A large stride value would significantly reduce the complexity of the model, yet we might lose some of the patterns along the process. Therefore, we should always set an optimal stride value – not too large, not too small.
Pooling Layer
When constructing CNNs, it is almost standard practice to insert pooling layers after each convolutional layer to reduce the spatial size of the representation to reduce the parameter counts, which reduces the computational complexity. In addition, pooling layers also help with the overfitting problem.

Max Pooling by 2 x 2
In pooling layers , after setting a pooling size of N x N pixels, we divide the image data into N x N pixel portions to choose the maximum, average, or sum value of these divided portions.
For the example in Figure 7-3, we split our 4 x 4 pixel image into 2 x 2 pixel portions, which gives us 4 portions in total. Since we are using max pooling, we select the maximum value inside these portions and create a reduced image that still contains the patterns in the original image data.
Selecting an optimal value for N x N is also crucial to keep the patterns in the data while achieving an adequate level of complexity reduction.
A Set of Fully Connected Layers
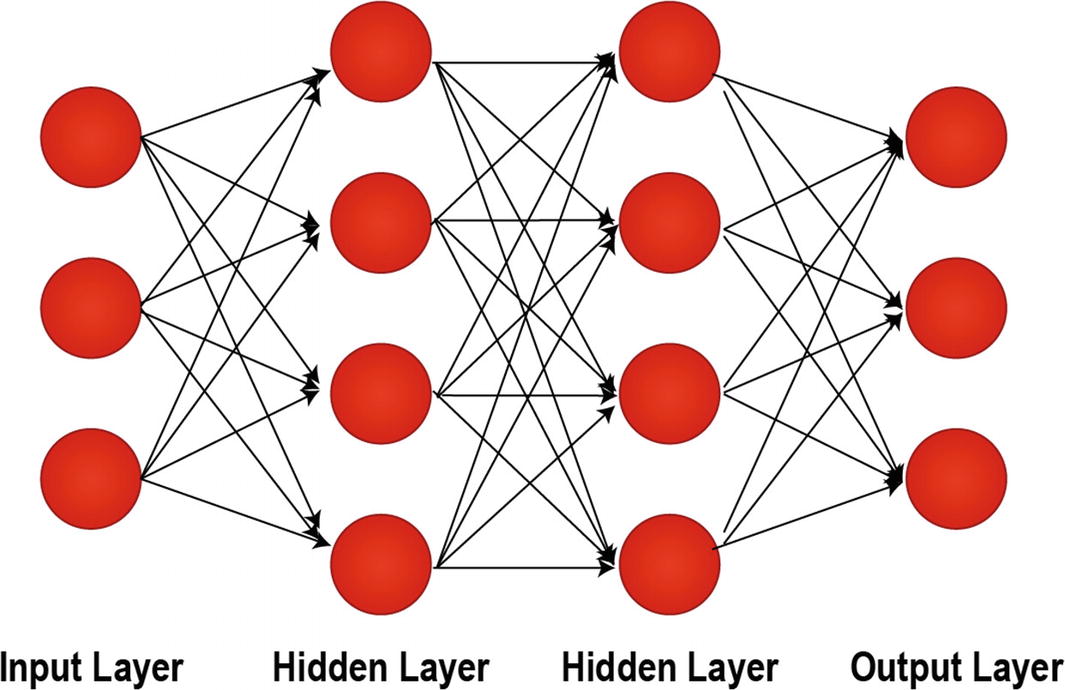
A Fully Connected Layer with Two Hidden Layers
A Full CNN Model
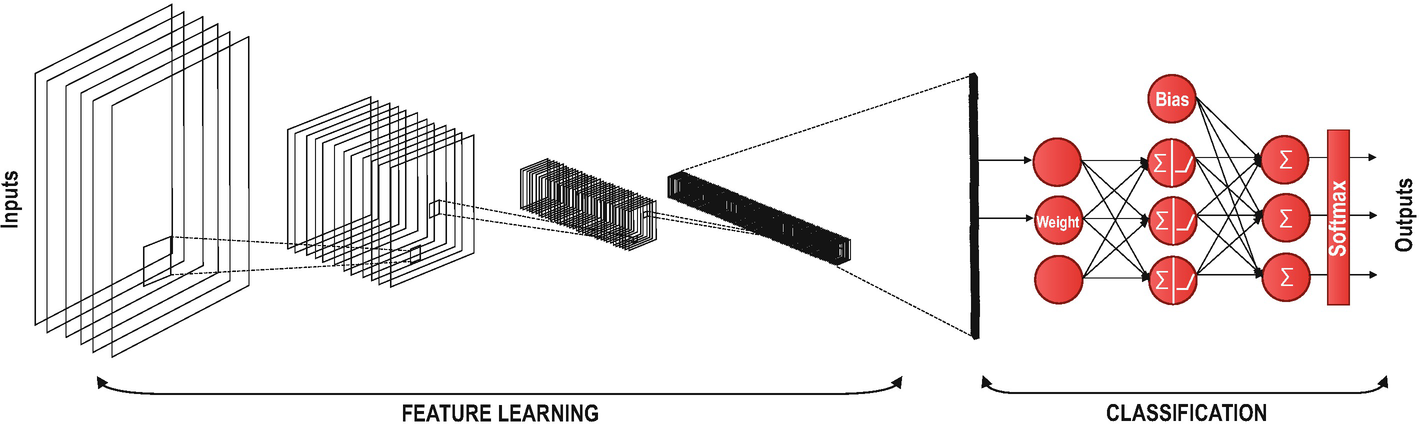
A Convolutional Neural Network Example
While the feature learning phase is performed with the help of convolution and pooling layers, classification is performed with the set of fully connected layers.
Case Study | Image Classification with MNIST
Now that we covered the basics of convolutional neural networks, we can build a CNN for image classification. For this case study, we use the most cliché dataset used for image classification: MNIST dataset, which stands for Modified National Institute of Standards and Technology database. It is an extensive database of handwritten digits that is commonly used for training various image processing systems.
Downloading the MNIST Data
A Visualization of the Sample Image and Its Label
The output we get is (60000, 28, 28, 1). As you might have guessed, 60000 represents the number of images in the training dataset; (28, 28) represents the size of the image, 28 x 28 pixels; and 1 shows that our images are not colored.
Reshaping and Normalizing the Images
Building the Convolutional Neural Network
We build our model by using high-level Keras Sequential API to simplify the development process. I would like to mention that there are other high-level TensorFlow APIs such as Estimators, Keras Functional API, and another Keras Sequential API method, which helps us create neural networks with high-level knowledge. These different options may lead to confusion since they all vary in their implementation structure. Therefore, if you see entirely different codes for the same neural network, although they all use TensorFlow, this is why.
We may experiment with any number for the first Dense layer; however, the final Dense layer must have 10 neurons since we have 10 number classes (0, 1, 2, …, 9). You may always experiment with kernel size, pool size, activation functions, dropout rate, and the number of neurons in the first Dense layer to get a better result.
Compiling and Fitting the Model

Epoch Stats for Our CNN Training on MNIST Dataset
You can experiment with the optimizer, loss function, metrics, and epochs. However, even though Adam optimizer, categorical crossentropy, and accuracy are the appropriate metrics, feel free to experiment.
Epoch number might seem a bit small. However, you can easily reach to 98–99% test accuracy. Since the MNIST dataset does not require substantial computing power, you may also experiment with the epoch number.
Evaluating the Model

Evaluation Results for Our MNIST-Trained CNN Model with 98.5% Accuracy
We achieved 98.5% accuracy with such a basic model. To be frank, in most image classification cases (e.g., for autonomous cars), we cannot even tolerate a 0.1% error. As an analogy, a 0.1% error can easily mean 1 accident in 1000 cases if we build an autonomous driving system. However, for our very first model, we can say that this result is outstanding.
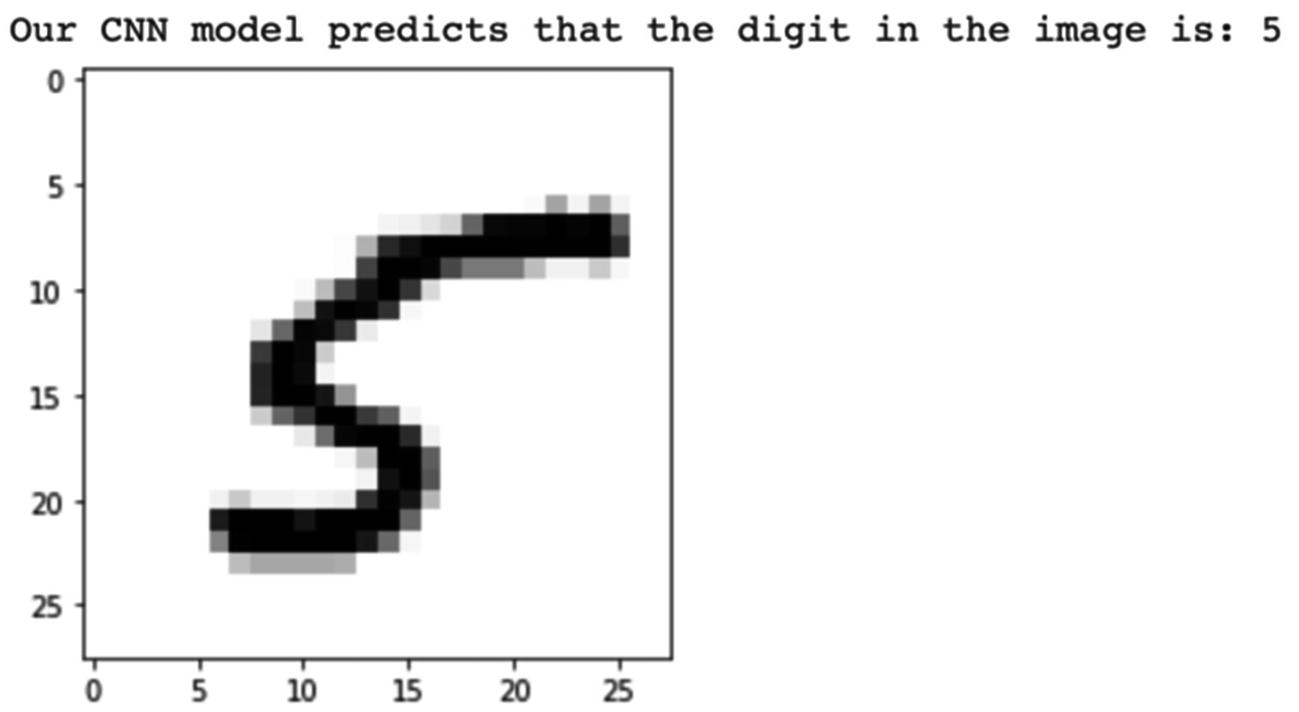
Our Model Correctly Classifies This Image as the Digit 5 (Five)
Please note that since we shuffle our dataset, you may see a different image for index 1000. But your model still predicts the digit with around 98% accuracy.
Although the image does not have good handwriting of the digit 5 (five), our model was able to classify it correctly.
Saving the Trained Model
With the SavedModel, you can rebuild the trained CNN and use it to create different apps such as a digit-classifier game or an image-to-number converter!
There are two types of saving options – the new and fancy “SavedModel” and the old “H5” format. If you would like to learn more about the differences between these formats, please take a look at the Save and Load section of the TensorFlow Guide:
Conclusion
Convolutional neural networks are very important and useful neural network models used mainly in image processing and classification. You can detect and classify objects in images, which may be used in many different fields such as anomaly detection in manufacturing, autonomous driving in transportation, and stock management in retail. CNNs are also useful to process audio and video as well as financial data. Therefore, the types of applications that take advantage of CNNs are even broader than the ones mentioned earlier.
CNNs consist of convolutional and pooling layers for feature learning and a set of fully connected layers for prediction and classification. CNNs reduce the complexity of the data, something that feedforward neural networks are not solely capable of.
In the next section, we will cover another essential neural network architecture: recurrent neural networks (RNNs), which are particularly useful for sequence data such as audio, video, text, and time-series data.