In a mission-critical application, each application service has to run in multiple replicas. Depending on the load, that can be as few as two to three instances and as many as dozens, hundreds, or thousands of instances. At any given time, we want to have a clear majority of all service instances running. So, if we have three replicas, we want to have at least two of them up and running all the time. If we have 100 replicas, we can content ourselves with a minimum of, say 90 replicas, that need to be available. We can then define a batch size of replicas that we may take down to upgrade. In the first case, the batch size would be 1 and in the second case, it would be 10.
When we take replicas down, Docker Swarm will automatically take those instances out of the load balancing pool and all traffic will be load balanced across the remaining active instances. Those remaining instances will thus experience a slight increase in traffic. In the following diagram, prior to the start of the rolling update, if Task A3 wanted to access Service B, it could have been load balanced to any of the three tasks of service B by SwarmKit. Once the rolling update had started, SwarmKit took down Task B1 for updates. Automatically, this task is then taken out of the pool of targets. So, if Task A3 now requests to connect to Service B, the load balancing will only select from the remaining tasks B2 and B3. Thus, those two tasks might experience a higher load temporarily:

The stopped instances are then replaced by an equivalent number of new instances of the new version of the application service. Once the new instances are up and running, we can have the swarm observe them for a given period of time and make sure they’re healthy. If all is good, then we can continue by taking down the next batch of instances and replacing them with instances of the new version. This process is repeated until all instances of the application service are replaced.
In the the following diagram, we see that Task B1 of Service B has been updated to version 2. The container of Task B1 got a new IP address assigned, and it got deployed to another worker node with free resources:

It is important to understand that when a task of a service is updated, it, in most cases, gets deployed to a different worker node than the one it used to live on. But that should be fine as long as the corresponding service is stateless. If we have a stateful service that is location or node aware and we'd like to update it, then we have to adjust our approach, but this is outside of the scope of this book.
Now, let’s look into how we can actually instruct the swarm to perform a rolling update of an application service. When we declare a service in a stack file, we can define multiple options that are relevant in this context. Let’s look at a snippet of a typical stack file:
version: "3.5"
services:
web:
image: nginx:alpine
deploy:
replicas: 10
update_config:
parallelism: 2
delay: 10s
...
In this snippet, we see a section, update_config, with the properties parallelism and delay. Parallelism defines the batch size of how many replicas are going to be updated at a time during a rolling update. Delay defines how long Docker Swarm is going to wait between the update of individual batches. In the preceding case, we have 10 replicas that are updated in two instances at a time and, between each successful update, Docker Swarm waits for 10 seconds.
Let’s test such a rolling update. We navigate to subfolder ch11 of our labs folder and use the file stack.yaml to create a web service configured for a rolling update. The service uses the Alpine-based Nginx image with version 1.12-alpine. We will then later update the service to a newer version 1.13-alpine.
We will deploy this service to our swarm that we created locally in VirtualBox. First, we make sure we have our Terminal window configured to access one of the master nodes of our cluster. We can take the leader node-1:
$ eval $(docker-machine env node-1)
Now, we can deploy the service using the stack file:
$ docker stack deploy -c stack.yaml web
The output of the preceding command looks like this:

Once the service is deployed, we can monitor it using the following command:
$ watch docker stack ps web
And we will see the following output:

The previous command will continuously update the output and provide us with a good overview on what’s happening during the rolling update.
Now, we need to open a second Terminal and also configure it for remote access to a manager node of our swarm. Once we have done that, we can execute the docker command that will update the image of the web service of the stack also called web:
$ docker service update --image nginx:1.13-alpine web_web
The preceding command leads to the following output, indicating the progress of the rolling update:
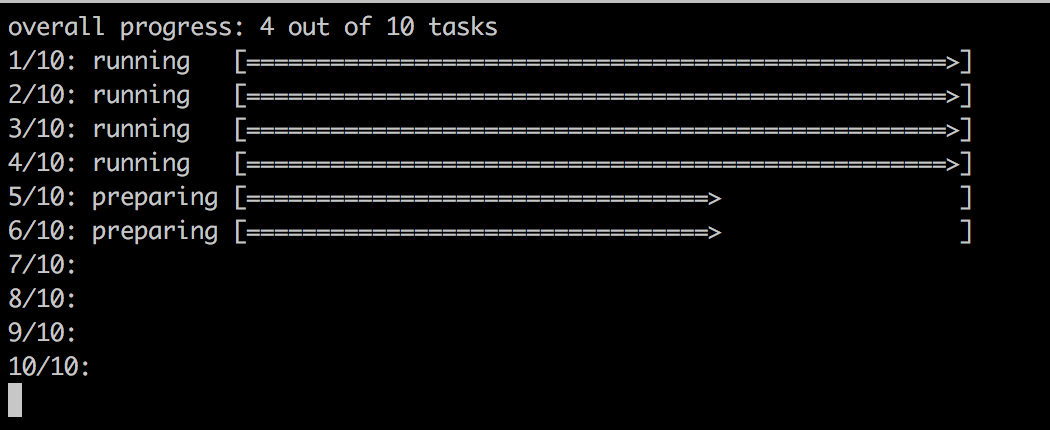
The output indicates that the first two batches with each two tasks have been successful and that the third batch is preparing.
In the first terminal window, where we're watching the stack, we should now see how Docker Swarm updates the service batch by batch with an interval of 10 seconds. After the first batch, it should look like the following screenshot:

In the preceding screenshot, we can see that the first batch of the two tasks, 8 and 9, has been updated. Docker Swarm is waiting for 10 seconds to proceed with the next batch.
Once all the tasks are updated, the output of our watch docker stack ps web command looks similar to the following screenshot:

Please note that SwarmKit does not immediately remove the containers of the previous versions of the tasks from the corresponding nodes. This makes sense as we might want to, for example, retrieve the logs from those containers for debugging purposes, or we might want to retrieve their metadata using docker container inspect. SwarmKit keeps the four latest terminated task instances around before it purges older ones to not clog the system with unused resources.
Once we're done, we can tear down the stack using the following command:
$ docker stack rm web
Although using stack files to define and deploy applications is the recommended best practice, we can also define the update behavior in a service create statement. If we just want to deploy a single service, this might be the preferred way. Let's look at such a create command:
$ docker service create --name web \
--replicas 10 \
--update-parallelism 2 \
--update-delay 10s \
nginx:alpine
This command defines the same desired state as the preceding stack file. We want the service to run with 10 replicas and we want a rolling update to happen in batches of 2 tasks at a time, with a 10 second interval between consecutive batches.