Figure 2.1 Excerpt of a nonpositional bigram array

A few years ago, the following email was heavily circulated around the internet:
Aoccdrnig to a rscheearch at Cmabrigde Uinervtisy, it deosn’t mttaer in waht oredr the ltteers in a wrod are, the olny iprmoetnt tihng is taht the frist and lsat ltteer be at the rghit pclae. The rset can be a toatl mses and you can sitll raed it wouthit porbelm. Tihs is bcuseae the huamn mnid deos not raed ervey lteter by istlef, but the wrod as a wlohe.
The text is surprisingly readable, even though the claims made in the message are not entirely true. Various people pointed out, for example, that in general it is not enough to get the first and last letters right (see, e.g., http://purl.org/lang-and-comp/cmabridge), so the example text is well chosen. Nonetheless, the message does make you wonder whether correct spelling is just an unnecessary torture invented by middle school teachers. If people can understand badly spelled text just as well as correctly spelled text, why should anyone bother to get the spelling right?
There are a number of reasons why standard spelling is useful and important. Consider, for instance, the spelling of family names: for this, spelling is not standardized, so you will encounter variation. You are asked to call someone called “Vladimir Zygmunt”, so you look him up in the telephone book. But alas, no such entry appears under Z. So you turn to look for alternative spellings and under S you discover “Siegmund.” Among the many entries, you cannot find a “Vladimir”, though. Browsing through the different first names you come across the alternative spelling “Wladimir” and finally find the entry you were looking for under “Wladimir Siegmund”. Without an agreed standard spelling for English words, similar detective work would be necessary every time we want to look up a word in a dictionary or thesaurus. A word such as “itinerary” might, for example, be found under I, but without standard spelling it might also be listed as “etinerary” under E, or as “aitinerary” under A. Standard spelling makes it possible to find a word in a single, predictable place.
Standard spelling also makes it easier to provide a single text that is accessible to a wide range of readers. People of different social or regional backgrounds speaking different dialects can still read and write a common language by using the same spelling conventions. The word that a northern speaker of American English pronounces as [pεn] (so with a vowel as in bet) might sound more like [pIn] (a vowel as in bit) when in the mouth of a southern speaker. Since both agree that the standard spelling of this word is “pen”, it becomes possible to write texts in a general way, independent of the particular pronunciations used in a given region or by a specific social group.
Related to the last point, in the USA today being able to use standard spelling is an expected consequence of being well educated. This was not the case in England in the age of Shakespeare. But today, anyone wanting to make a good impression in formal social interactions such as in job applications had better be prepared to spell words correctly. Of course, the spelling conventions that are suitable for informal settings such as text messages are quite different from those of formal letters: consider “CU L8R” (see you later), “ROTFL” (rolling on the floor laughing), “AFAIK” (as far as I know).
Finally, standard spelling is also important for computer software that deals with written text. Optical character recognition (OCR) software, for instance, can use knowledge about standard spelling to recognize scanned words even for hardly legible input. It can piece together the letters that it cannot read by noticing that they are next to letters that it can read, and using knowledge of spelling to fill in the gaps.
In sum, whether you hate being forced to use English spelling or whether you enjoy it, it looks like standard spelling is here to stay. Luckily, for those of us who can never remember how to spell “Massachusetts” or “onomatopoeia”, or who consistently confuse “they’re” and “there”, technological support exists in the form of spell checkers, grammar checkers, and style checkers. For consistency, the name for the tool that checks spelling should perhaps have been “spelling checker”, but the term spell checker is the one most people use, so we will follow common practice. Until and unless there is a need for a tool that checks spells, no ambiguity will arise.
These tools, often referred to collectively as writers’ aids, are supposed to help; ideally, they enable writers to focus on the content of the document without worrying so much about the forms. We start our exploration of language technology applications in this book with writers’ aids because we assume they are familiar to everybody, and they also provide a nice platform for introducing many linguistic concepts that you will see recur in the rest of the book.
In order to detect and correct spelling errors effectively, we have to know what errors to look for, and so must know what kind of misspelled and ungrammatical input to expect. This is common in natural language processing (NLP): we may have an intuitive sense of the problem – in this case, spelling errors – but the first step in developing technology is to understand the examples or data to be covered and the concepts that are relevant for capturing the properties we see exemplified by the data.
The so-called nonword errors are errors resulting in words that do not exist in a language, for example when the article “the” is erroneously written as the nonword “hte”. One can characterize such errors in two ways. On the one hand, we can ask why this error happened, trying to determine the cause of the error. On the other hand, we can describe how the word that was written differs from the target word; that is, the word the writer intended but did not write down correctly.
Looking first at the error cause, nonword errors are usually caused either by mistakes in typing or by spelling confusions. Typographical errors (typos) are errors where the person probably knew how to spell the word correctly, but mistyped it. Spelling confusions occur when the person lacks or misremembers the necessary knowledge. A writer might, for example, never have seen the word “onomatopoeia” or might remember that “scissors” has something odd about it, but not be able to recall the details. For the record, “scissors” has at least three odd features: the use of sc to make the [s] sound is unusual, as is the use of ss to spell a [z] sound, as is the use of or for the suffix that is more often written er. In English, when you know how to say a word, you may still be a long way from knowing how to spell it correctly.
Spelling confusions based on sound are obviously a major problem; not only do we spell based on analogy with other words, but we often use typical sound-to-letter correspondences when a word is unknown. Thus, spellers may leave out silent letters (nave for knave), may replace a letter with a similar-sounding one (s for c in deside in place of decide), or may forget nuances of a rule (recieve: i before e except after c). This is not the same across all languages, however. In some languages, such as Finnish and Korean but not English, if you know how to say a word, you will be able to make a very good guess about how to spell it. We say that languages like this have a transparent writing system. In these languages, we do not expect to see very many errors caused by confusions about the sound-to-letter correspondence.
Errors can happen for other reasons, such as a particular keyboard layout that causes certain typos to be more likely than others. Yet, while one can hypothesize a wide range of such underlying error causes, it is difficult to obtain definitive evidence. After all, we are not generally around to observe a person’s fingers or to notice that an error was caused by a cat walking on the keys. As a result, the analysis of spelling errors and the development of spell checking technology has primarily focused on a second method for classifying errors. Instead of trying to identify the underlying cause of the error, we try to describe the way in which the misspelled word differs from the target word that the writer was aiming for. There is an obvious problem with this approach if the reader cannot tell what the intended target was, but this turns out to be rare, at least given enough context.
Research on spelling errors distinguishes four classes of target modification errors on the basis of the surface form of the misspelled word and the likely target word:
You may feel that this way of describing errors is quite mechanical. We agree that the underlying causes described a few paragraphs ago are more interesting for understanding why errors arise. But we will see both in the following discussion and when we introduce techniques for automatically identifying and correcting errors in Section 2.3.2 that viewing errors in terms of target modification is a very useful perspective in practice.
Classifying errors in terms of target modification allows us to identify the most common kinds of insertions, deletions, substitutions, and transpositions that people make. By looking at long lists of examples of actual errors, it then also becomes possible to infer some likely error causes. When finding many substitutions of one specific letter for another, the mistyped letter is often right next to the correct one on a common keyboard layout. For example, one finds many examples where the letter s has been mistyped for the letter a, which is related to the fact that the a and s keys are next to another on a typical English QWERTY keyboard. We can, of course, also turn this correspondence around and use the information about keyboard proximity to calculate the likelihood of particular substitutions and other error types occurring. This will be useful when we look at ranking candidates for spelling correction in Section 2.3.2 .
Looking at where such errors arise, we can distinguish single-error misspellings, in which a word contains one error, from multi-error misspellings, where a single word contains multiple instances of errors. Research has found upwards of 80% of misspellings to be single-error misspellings, and “most misspellings tend to be within two characters in length of the correct spelling” (Kukich, 1992). The two observations naturally are connected: both insertion and deletion errors only change the length of a word by one character, whereas substitution and transposition errors keep the length the same.
The insight that writers primarily make single-error misspellings within two characters in length of the correct spelling means that spell checkers can focus on a much smaller set of possible corrections and therefore can be relatively efficient. A related observation further narrowing down the search for possible corrections is that the first character in a word is rarely the source of the misspelling, so that the misspelled word and the correct spelling usually have the same first letter.
Note that these trends are based on data from good writers of native speaker English, so will not be fully applicable to other populations, such as nonnative speakers or people with dyslexia. Because traditional spell checkers are built on the assumption that the writers are native speakers, they are not good at correcting nonnative errors. Fortunately, it can sometimes help to know that we are dealing with nonnative speakers: there are specific types of spelling errors that are characteristic of people learning English as a foreign language. For example, it is common to use an English word that looks like a word from their native language. An example of such so-called false friends or lexical transfer would be the common use of “become” in place of “get” by German-speaking learners of English – an error that arises since the German word “bekommen” means “get” in English. Chapter 3 discusses the use of computers in foreign language teaching and learning in more detail.
Typos are not caused by confusions or missing knowledge, but by mistakes in the execution of the writing process. These include misspellings caused by overuse, underuse, or misuse of the space bar. Splits are errors caused by hitting the space bar in the middle of a word, turning a single word into two words, such as “quintuplets” becoming “quin tuplets”. This is overuse of the space bar. Although determining where a word starts and where it ends, so-called tokenization, is a tricky issue for languages other than English (and even sometimes in English), most spell checkers assume that the string that needs to be checked is contained between two spaces. (See Section 3.4 for more on tokenization.) Thus, split errors are often difficult to correct, because the checker cannot tell that the adjacent strings are intended as part of the same word. On the other hand, run-ons are errors that are caused by underuse of the space bar between two words, turning two separate words into one, such as “space bar” becoming “spacebar”. Finally, there can be errors where the space between words is present, but not in the correct place, as can happen if you write “atoll way” instead of “a tollway”. This is going to be especially hard to correct if, as here, the results of the mistake turn out to be real words.
real-word error
We just introduced the idea that errors can result in real words, making them more difficult to detect. Normally, when the result of an error is a nonword, an automated system can detect the error by trying to look up the word in a dictionary: if the word is not found, it may very well be the result of a spelling error. But this will not work for errors that result in real words, because the results will probably be listed in the dictionary. Human readers can often detect that something is wrong by inspecting the surrounding context of the word. There are three different kinds of real-word errors, each involving an appeal to context, but differing in the extent and nature of that appeal. As the appeal to context becomes more elaborate, the task of detecting the error becomes progressively more difficult.
First, there are local syntactic errors. Generally speaking, syntactic errors are errors in how words are put together in a sentence: different parts of speech are in the wrong places in a sentence or the wrong grammatical forms are used. Local syntactic errors are errors where the syntactic violation is detectable by looking within one or two words in the sentence. In sentence (3), for example, a possessive pronoun (their) is in the place where a noun phrase (there) should be, and this can be determined by the presence of the verb “was” that immediately follows it.
In order to make explicit that this is an example of an ungrammatical sentence, we mark it with an asterisk (*). This is a common convention in linguistics – and also alerts editors and typesetters to the fact that the error in the example is intended, rather than something to be corrected for publication.
The second kind of real-word error we need to discuss here are long-distance syntactic errors, which are more difficult because they involve syntactic violations spread out over many more words. In sentence (4), for instance, there is a problem with subject–verb agreement, but it is spread out over five words.
Finally, there are semantic errors. These are errors in meaning: the sentence structure is grammatical, but the problem is that the sentence does not mean what was intended. In (5), “brook” is a singular noun – just like the presumably intended “book” – but it does not make sense in this context.
It is not always easy to decide whether an error is a spelling error or an error in grammar. Example (4), for instance, could be thought of as a real-word spelling error in which the typist simply omitted the s of gets, or it could be thought of as a problem with subject–verb agreement, which is a grammatical error. Without knowing what is going on in the mind of the reader, it is hard to know which explanation is better. In example (3), on the other hand, it seems obvious that the writer was trying to produce There, so it is safe to classify this as a real-word spelling error.
Having explored the types of errors, we can now look at how to detect and correct spelling errors automatically. In general, we could design either an interactive spell checker or an automatic spelling corrector. Interactive spell checkers try to detect errors as the user types, possibly suggesting corrections, and users can determine for themselves the value of the corrections presented. Automatic spelling correctors, on the other hand, run on a whole document at once, detecting the errors and automatically correcting them without user assistance. Such correctors are never 100% accurate, so they are less desirable for the task of assisting in writing a document. When the “correction” that the system chooses is the wrong one, it will stay in the document unless the user notices and undoes the change. Note that many existing spell checkers actually make auto-corrections – which can sometimes lead to inadvertent and undesirable corrections.
Most of us are familiar with interactive spell checkers, and they will be the focus of our discussion here. Spelling correction involves the following three tasks, in increasing order of difficulty. First, there is nonword error detection, the task of finding strings in a text that are not words. For some purposes, simply detecting a misspelling is enough for the writer, who can then fix it by hand. Sometimes, however, we require the second task, isolated-word error correction. As the name implies, the goal of this task is to correct errors or suggest corrections, but without taking the surrounding context into account. For example, a corrector could correct “hte” to “the”. Because it does not look at context, however, such a checker could not change “there” when it is used incorrectly in place of “their”. For these errors, we need context-dependent word correction, the task of correcting errors based on the surrounding context. For instance, “too” used as a numeral will be corrected to “two” when it is surrounded by a determiner and a plural noun (e.g., the too computers).
The simplest way to detect nonwords is to have a dictionary, or spelling list; if the word is not in the dictionary, it is a misspelling. While this is a good idea in general, there are several issues to consider in constructing a dictionary and looking words up in the dictionary.
First, one must realize that a dictionary is inherently incomplete, due to the productivity of language. New words are continually entering the language, such as “d’oh”, while at the same time, old words are leaving. For example, in Shakespeare’s time, “spleet” (“split”) was a word and thus correctly spelled, while today it is not. Foreign words, differently hyphenated words, words derived from other words, and proper nouns continually bring new words to a language. A dictionary can never be exhaustive.
Even if we could include every word, however – including all proper nouns – it is not clear that this would be desirable. Including the proper last name “Carr” may result in not finding the misspelling in “The Great American Carr Show”. A writer does not use every possible word in existence, and no two writers use exactly the same set of words. Should each person then have their own private dictionary?
The answer is both yes and no. For the majority of writers, we can narrow down a dictionary by considering only words that are “common”. Rare words are likely to become confused with actual misspellings, and so they should not be included. For example, “teg” is a word (“a sheep in its second year”), but most English writers do not know or use this word. So, if it is found in a document, it is probably a misspelled form of, for instance, “tag” or “beg”. The few writers who do intend to use “teg” will probably not mind if the spell checker flags it.
We can also focus on specific populations of users by utilizing separate dictionaries for particular domains. For the average user, “memoize” is a misspelling of “memorize”, but for computer scientists it is a technical term. We can take this to the level of the individual user, too. Many spell checkers allow users to update their own personal dictionaries, by adding words or spelling rules. The free checker Hunspell (http://hunspell.sourceforge.net/), for instance, allows users easily to change the dictionary they use.
Turning to the internal parts of a dictionary, a general issue for dictionary construction is whether or not to include inflected words as separate entries. For example, should “car” and “cars” be stored separately? Or should “car” be stored as a single entry, indicating its part of speech (noun) and that it is regular; that is, it takes the standard -s plural ending?
The choice is one of efficiency and where to allocate the work. If they are separate entries, then the lookup mechanism is straightforward, but there is an increase in the number of words. If inflected words are not stored as separate entries, on the other hand, then there are far fewer lexical entries, but we have to strip the affixes (prefixes and suffixes) from the words before looking them up. Furthermore, one has to handle exceptions to affix rules in some systematic way, possibly by separate entries for “ox” and “oxen”, for instance. And we have to prevent overgeneralizations of affix rules: there must be a special note on “ox” that it is irregular, so that “oxs” or “oxes” will not be accepted as correct spellings.
When dealing with thousands of words, looking up those words becomes nontrivial; each word has to be stored somewhere in computer memory, and finding where the word is takes time. Thus, an efficient storage and lookup technique is also needed – just as efficient storage is needed for webpages (see Search engine indexing in Section 4.3.4). Words could be stored alphabetically, and each word encountered could be searched for, but the words in English are not evenly distributed over the entire alphabet: for instance, the number of words that start with x is much smaller than the number of those that start with s. Computer scientists study and develop various ways to distribute word entries evenly in memory, in order to, for example, more quickly find words in the middle of the s section.
What might be surprising is that, to some extent, words can be determined to be misspelled without using an explicit dictionary. One technique uses n-gram analysis. A character n- gram, in this context, refers to a string of n characters in a row; for instance, thi is a 3-gram (or trigram). Note that thi is a possible trigram of English (this), whereas pkt is not. Thus, one can store all possible n-grams for a certain n and a given language in order to determine whether each new string encountered has only valid n-grams. The set of valid (or likely) n-grams can be collected from a long piece of text, assuming that it has few or no misspellings.
N-gram analysis is more popular for correcting the output of optical character recognition (OCR) than for detecting writers’ errors. This is due to the fact that OCR errors are more likely to result in invalid character sequences. Still, the technique is useful to examine, because it shows us how to detect spelling errors using very little knowledge or computational resources.
Specifically, one can use 2-grams (bigrams) and store them in a table. This can be done with positional information included or not. A nonpositional bigram array is an array, or table, of all possible and impossible bigrams in a language, regardless of the bigram’s position in a word, as shown in Figure 2.1.
Figure 2.1 Excerpt of a nonpositional bigram array
A positional bigram array, on the other hand, is an array of possible and impossible bigrams for a particular position in a word, such as a word ending. Figure 2.2 illustrates this, with 1 indicating possible and 0 impossible.
Figure 2.2 Excerpt of a positional bigram array (word ending)
Thus, kl is a possible bigram in English (e.g., knuckles), so it is in the nonpositional array (Figure 2.1), but it is not a valid word ending and so is not in the positional bigram array for word endings.
To detect errors, the spell checker first breaks the input word into bigrams and labels them with their positions. Then it looks up the bigrams in the nonpositional array for the given language. If any of the bigrams is missing from the array, it knows that the word has been misspelled. If all the bigrams were present, it goes on to check the positional bigram arrays. If it finds all the bigrams in the correct positions, the word is probably good. But if any of the checks fail, that means that one of the bigrams is out of place, so the input form is probably an error.
Taking nonword errors that have been detected, isolated-word spelling correction attempts to correct a misspelled word in isolation; that is, irrespective of surrounding words. Notice that one cannot expect 100% correctness from isolated-word spelling correctors. When humans were given the same task – correcting nonwords without knowing the context – their accuracy was around 74%.
In general, there are three main steps for a spell checker to go through in correcting errors: (i) error detection (described above); (ii) generation of candidate corrections; and (iii) ranking of candidate corrections. Isolated-word spelling correction deals with effective generation and ranking of candidate corrections. Such a task is useful in interactive spelling correctors, where a human makes the ultimate decision, because the higher up in the list the correct spelling is, the more quickly the user can approve the correction.
Rule-based techniques generate candidate corrections by means of written rules, which encode transformations from a misspelling to a correct spelling. For example, a rule will look for the misspelling “hte” and generate “the” as a potential correction, or perhaps the only possible correction. Such rules can be highly effective, especially for high-frequency errors like “hte”, where the intended word is clear. There are two downsides to rule-based generation of candidates, however.
The first is that someone has to write the rules, and they may not capture all the spelling errors humans might make. There have been advances in computational linguistics allowing for automatic derivation of rules, but a second problem remains: the rules are often very narrow and specific, such as the “hte” rule mentioned, which covers only one single misspelling of “the”. A separate rule has to be written for “teh” and, as mentioned, generally only high-frequency errors are covered.
A second technique for generating candidates is actually an old method that was developed for working with variant names in US census data. Similarity-key techniques store words (correct spellings) with similar properties in the same bucket. That is, words with similar spellings or similar sounds and of about the same length are put together into one slot. When a misspelling is encountered, the similarity key for it is automatically calculated, and the bucket of similar but correctly spelled words is retrieved.
For example, in the SOUNDEX system, one of several well-known similarity-key systems, the word “nub” would be assigned the code N1: an N for the first letter, a 0 (zero) (which is later eliminated) for the vowel, and a 1 for a bilabial (b, p, f, v). The words “nob”, “nap”, and so on will also be in this bucket. If we encounter the misspelling “nup”, we retrieve bucket N1 – which contains “nub”, “nob”, “nap”, and other words – as our set of potential corrections.
Once the list of candidate corrections is generated, we want to rank these candidates to see which is the best. Again, we will look at two basic ideas.
Methods that use probabilities give us a mathematically precise way of indicating which corrections we want a checker to choose. But where do the probabilities come from? If we could directly measure the probability that one word will be typed when another is intended, and do this for every possible pair of words, we could use the probabilities as a way of ranking candidates. Unfortunately, because there are so many possible words, and a correspondingly large number of probabilities, this approach is not practical. It would take too long and use too much computer memory. Fortunately, it turns out that there is an effective approximate approach based on character-level transition probabilities and character-level confusion probabilities of individual characters. The idea is to use character-level statistics to build an adequate approximation to the word-level confusion statistics that we would ideally like but cannot obtain.
Transition probabilities represent the probability of one character following another; for instance, the probability of q being followed by u in English is essentially 100%. Transition probabilities are used to model how likely it is that a character has been inserted or deleted. Confusion probabilities, on the other hand, represent the probability of one character being substituted for another; for example, using the standard English QWERTY keyboard, the chance of an m being typed for an n is higher than a q being typed for an n because m and n are nearby on the keyboard (and are similar phonetically). Starting with the misspelling, we use probabilities of insertions, deletions, substitutions, and transpositions to find the correct spelling in our candidate set with the highest probability (see the discussion on distance measurements below). We refer to this as the correction that maximizes the probability; that is, it is the most likely correction given the misspelling. We will take a close look at the mathematics behind this in Under the Hood 11.
Similarly, to rank candidate corrections, we can assign each a distance value telling how far off it is from the misspelling. A specific instance of this is called edit distance, which measures how many operations – insertions, deletions, substitutions, and (sometimes) transpositions – it would take to convert a misspelling into the correct spelling. (Transpositions are often not used in calculating edit distance and instead are treated as two substitutions.) The candidate with the minimum edit distance is the top-ranked one, where by minimum edit distance – often referred to as Levenshtein distance – we mean the minimum number of operations it would take to convert one word into another. For example, for the misspelling “obe”, the word “oboe” has a distance score of one (insertion of o), while “hobo” has a score of two (insertion of h, deletion of e), so “oboe” is the better choice.
Of course, a word like “robe” also has a distance score of one, so to give a ranking with no ties, we need to add more information. This is where we can combine the edit distance method with the probabilistic method mentioned above. Instead of giving a value of one for each operation, we can use probabilities to determine which operations are more likely. For example, a greater edit distance would be given to substituting q for n than would be given to substituting m for n.
The minimum edit distance problem is technically challenging. The problem is this: there are many different sequences of edit operations that change a misspelling into a word. For instance, it is possible, although strange, to derive “oboe” from “obe” by deleting o, changing b to o, inserting b, and finally inserting o, taking four steps. Worse, there are hundreds of sequences that do this in five steps: one is to start by deleting o, then change b to o, then insert b, then insert a, and finally change a to o. It is pretty obvious that the a was a pointless diversion, but not immediately obvious how to fix this systematically.
Both human beings and computers can solve this problem, but they do so in different ways. Human beings can often use intuition to seek out and follow a single promising possibility. They can even solve a harder version of the problem in which all the intermediate stages are real words. Computers do not have intuition, so it works better for them to pursue multiple alternatives simultaneously. Fortunately, they are very good at the bookkeeping required for systematically working through a range of possibilities. The technique that makes this efficient is called dynamic programming, which is explained in detail in Under the Hood 3.
Figure 2.3 The basic set-up of a minimum edit distance graph
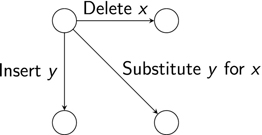
Figure 2.4 An initial directed graph relating “fry” and “fyre
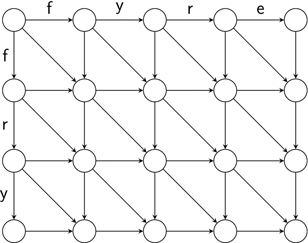
Figure 2.5 The directed graph, topologically ordered
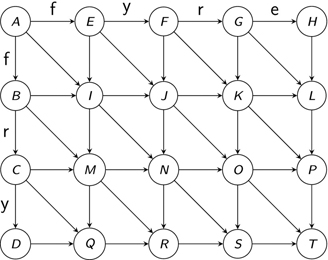
Figure 2.6 The directed graph with costs
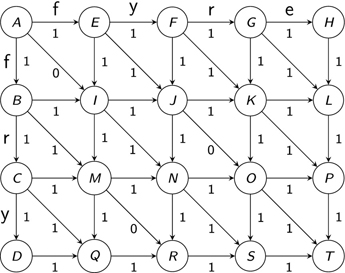
Figure 2.7 Calculating the cost into node I

The problem of context-dependent word correction is that of detecting and correcting errors that result in existing words, the real-word errors we first mentioned in Section 2.2.2. For example, the use of “There” in “There house is nice” is wrong, but it is still a word. The problem is not the word itself, but the particular way in which it is used. We say that the word does not fit the context.
This kind of spelling correction is closely related to grammar checking. Consider “The teams was successful”: here there is a grammatical error, because the subject “teams” is plural while the verb “was” is singular. Again, the words used are wrong in context. Without looking further, we cannot be sure whether the writer intended “The teams were successful” or “The team was successful”, but we know that something is wrong with the sentence.
In the first case of the misspelled “there”, we know that the word “there” is not a possessive, yet this is the function it has in the sentence. In order to know that this is a misspelling, we have to do some grammatical analysis, and some reasoning about what the writer probably intended. Indeed, it could be that the writer actually meant to say either “Their house is nice” or “The house there is nice”. To detect, classify, and correct these issues we will need to do some guessing, and we want this guessing to be well informed and based on evidence. Thus, we will treat context-dependent word correction and grammar correction together here. Both are important, as 30–40% of spelling errors made by writers result in real words.
Before we investigate how to correct grammar errors, we have to ask ourselves what we mean by grammar. Traditionally, linguists have focused on descriptive grammar, which refers to a set of rules for how speakers of a language form well-formed sentences. For our purposes, this is a good start, and we will return to different definitions of grammar in Section 2.5.
Basing our discussion in this section on Mihaliček and Wilson (2011), we define grammar in terms of rules, but when we talk about the rules of a language, what do we mean by that? To explain this, we need to introduce syntax, the study of how grammatical sentences are formed from smaller units, typically words. Some of these concepts will also resurface when analyzing learner language in Section 3.4.3.
Sentences in human language are organized on two axes. These are linear order and hierarchical structure. The idea of linear order is that languages can vary word order so as to convey different meanings. Thus, in English “John loves Mary” is not the same as “Mary loves John”. Not all languages use linear order in exactly the same way: for example, in Czech, Russian, and German the presence of richer word endings makes it possible to vary word order slightly more freely than we can in English. In linguistics, the study of word endings and other changes in word forms is called morphology. Nevertheless, linear order is a guiding principle for organizing words into meaningful sentences, and every human language uses it to some extent.
The other guiding principle for sentence organization is hierarchical structure, or what is called constituency. Words are organized into groupings, and intuitively, these groupings are the meaningful units of a sentence. Take the sentence in (6), for example. It seems like “most of the ducks” forms a unit, and this intuition is backed up by the fact that we can replace it with other, similar phrases, like “people who have won the Super Bowl”.
(6) Most of the ducks play extremely fun games.
When we break a sentence down further, we find that these meaningful groupings, or phrases, can be nested inside larger phrases of the same or different type: for example, “extremely fun” is a part of “extremely fun games”. When we put all those phrases together, it is useful to view them as a syntactic tree, as we see in 2.8.
While this tree captures the intuition that words group into phrases, more can be done with the labels on the tree nodes. It is not helpful to use uninformative names such as a, b, and so forth. What linguists do is to add categorical information, to tell us something about the kinds of phrases there are. For example, “most of the ducks” and “extremely fun games” are the same type of phrase, and “of the ducks” is something else entirely, in that substituting it for one of the other two expressions does not result in a grammatical sentence.
Figure 2.8 A labeled tree
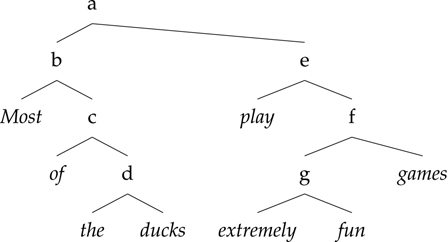
If you go further in the study of syntax, you will encounter sharp debates about specific aspects relating to how words and phrases really work. What we are presenting here is the basic terminology and ideas that all linguists use, especially those linguists who primarily use syntax (as opposed to researching it), as many computational linguists do.
Thus, we examine word and phrase categories. Since phrases are built from words, we start with word categories: lexical categories are simply word classes, or parts of speech. The main ones are verbs (run, believe, consider), nouns (duck, government, basketball), adjectives (bad, potential, brown), adverbs (heavily, well, later), prepositions (on, at, into), articles (a, the, this, some), and conjunctions (and, or, since).
We can use two main criteria to tell what a word’s part of speech is. The first criterion is the word’s distribution: where it typically appears in a sentence. For instance, nouns like “mouse” can appear after articles, like “some” or “the”, while a verb like “eat” cannot. The second criterion is the word’s morphology, the kinds of prefix/suffix a word can have. For example, verbs like “walk” can take an “-ed” ending to mark them as past tense; a noun like “mouse” cannot. Words that share a similar distribution and a similar morphology are put into the same lexical category. Linguists use categories that are finer grained than the familiar parts of speech, but they still talk about nouns, verbs, adjectives, and so on, and mean roughly the same as an educated nonlinguist does. (These concepts are discussed more fully in Section 3.4.2, in the context of learner language, where such evidence can diverge.)
Moving from lexical categories to phrasal categories, we can also look at distribution. For the sentence in (7), we can replace the phrase “most of the ducks” with “a bear”; “Barack Obama”; “many a dog”; or “people who have won the Super Bowl”. All of these phrases contain nouns as their key component, so we call them noun phrases, abbreviated as NP.
(7) Most of the ducks swam a lap.
Figure 2.9 A tree with linguistically meaningful labels
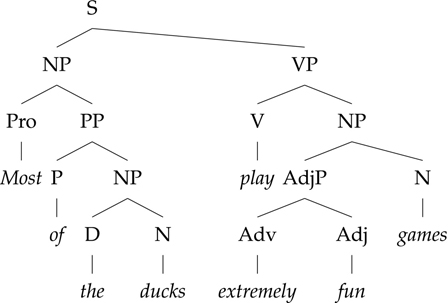
Being able to replace a phrase with another is a test of replaceability, and it is one of several different constituency tests to determine which sequences of words make up constituents. At any rate, if we give each phrasal category a name and an abbreviation, we can now draw a more complete tree, as shown in Figure 2.9.
The trees we draw are systematic. For example, a determiner (D) and a noun (N) often make up an NP, while a verb (V) and adverb (Adv) on their own can never make up an NP. We use phrase structure rules to capture these commonalities and to describe a language. Phrase structure rules (PSRs) give us ways to build larger constituents from smaller ones. For instance, the top subtree in Figure 2.9 corresponds to the rule S → NP VP. This rule indicates both hierarchy and linear order. The hierarchy aspect is that a sentence (S) constituent is composed of a noun phrase (NP) and a verb phrase (VP). The linear order is indicated by the order of mention of the labels on the left-hand side: the NP must precede the VP. In the tree, we can also see structures for prepositional phrases (PP) and adjective phrases (AdjP).
Every tree node in a syntax tree is built out of a corresponding phrase structure rule. The left-hand side of the rule corresponds to the parent, and the labels on the right-hand side of the rule correspond to the subtrees nested below the parent.
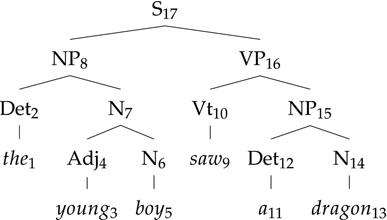
Syntax trees and phrase structure rules are really two sides of the same coin. You can build a syntax tree by piecing together a set of phrase structure rules, and you can also go the other way, reading off the phrase structure rules that are used in a particular syntax tree. For instance, if we have the rule set in Figure 2.10, we can give an analysis to “the young boy saw a dragon”. The analysis is shown in Figure 2.11.
A grammar, then, is simply a collection of such rules. Grammars with rules of the form shown here are referred to as context-free grammars. A grammar that accurately describes a language is able to model all and only those sentences that actually appear in the language. It is very useful to try to build such grammars for human languages, but the complexity of human language makes it unlikely that anyone will ever manage to build a complete grammar for the whole of a human language. Instead, we build grammar fragments. These are simplified working models of a human language. Like other working models, they can serve several purposes. In this book, grammar fragments are important because they may be built into spelling and grammar checkers. For other linguists, they may be just as important as a tool for checking out scientific ideas about how human language works in general. If an idea works in a grammar fragment, maybe that idea reflects what is really going on in the mind of a human speaker. To prove that, detailed experimental or theoretical work would be needed, but a grammar fragment is a good start in the same way that a balsa-wood model in a flotation tank is a good start on the design of an oil tanker. In this book, when we talk about a model, it is always a mathematical or computational model: an abstract system designed to capture key aspects of how we believe language to work.
Figure 2.10 An English grammar fragment, including rules for words
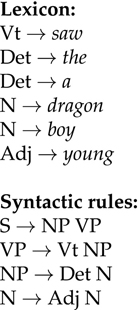
Figure 2.11 Analyzing “the young boy saw a dragon” using the given grammar fragment

So far we have relied on intuition to introduce the idea of phrase structure rules. We are now ready to do the formal mathematics. These rules have to follow a particular structure. Each rule must have a left-hand side (LHS), which is a single nonterminal element, and nonterminals are defined as (phrasal and lexical) categories. So, NP is an acceptable LHS, while “John” is not. Secondly, each rule must have a right-hand side (RHS), which is a mixture of nonterminal and terminal elements, where terminal elements are defined as actual words (terminal because they are the final nodes in a tree). So, “Det Noun” or “Noun and Noun” are acceptable RHSs.
You may be wondering why we call this a context-free grammar. The answer has to do with the fact that each rule is designed to be independent of the others. These rules can be used wherever the category on their LHS occurs. Rules cannot be further restricted to apply only in some places and not others. So, for example, you cannot have a rule specifying that PP → P NP is applicable only when there is a verb phrase (VP) above the PP. The real reason for this is complexity: by having simple rules that apply everywhere, you get the ability to reason modularly about what is going on. (For more information on this topic, see Under the Hood 4.)
A grammar composed of these rules has several properties that are useful for modeling natural language. First, the grammar is generative; it is a schematic strategy that characterizes a set of sentences completely. Secondly, as mentioned, the rules license hierarchical structure. Thirdly, and crucially for natural languages, the rules allow for potential structural ambiguity, where a sentence can have more than one analysis. This is clearly needed when we examine sentences like (8), which can have multiple meanings. In this case, “more” can either group with “intelligent” (9a) or can modify “leaders” (9b).
Finally, the rules are recursive: recursion is the property that allows for a rule to be used in building up its own substructures. In example (10), for instance, NP is reapplied within itself, thus allowing for phrases such as [NP [NP [NP the dog] on the porch ] at my feet ].
Most linguists believe that recursion is an important defining property of human language. For this reason, experiments that aim to tease out the similarities and differences between human and animal communication often focus on recursion.
Using these phrase structure, or context-free, rules, we want to get a computer to parse a sentence; that is, to assign a structure to a given sentence. Some parsers are bottom-up, which means that they build a tree by starting with the words at the bottom and working up to the top. Other parsing techniques are top-down; that is, they build a tree by starting at the top (e.g., S → NP VP) and working down.
Figure 2.12 Trace of a top-down parse
Figure 2.13 Trace of a bottom-up parse
To give a rough idea of how a parser works, let’s start with the rules found in Figure 2.10 and attempt to parse “the young boy saw a dragon”.
A top-down parse starts with the S category – since the goal is to have a sentence (S) when the parse is done – and expands that to NP VP. The next step is to try expanding the NP, in this case into Det N, as that is the only possibility in this grammar. A trace of the order of rules can be seen in Figure 2.12. If there are multiple possible NP rules, the parser can consider them one at a time and then backtrack if a particular NP expansion does not work out.
Instead of starting with the goal of S, the bottom-up way of parsing starts with the very first word, in this case “the”, and builds the tree upwards. Based on the lexicon, Det is the only category that fits for “the”, so this is added to the tree next. On its own, Det cannot form any higher category, so the next word (young) is considered, which is an adjective (Adj). This continues upwards, as seen in Figure 2.13.
This is only a brief sketch of how parsing proceeds to analyze a sentence given a grammar. In general, there are many parsing techniques; pointers are provided in the Further reading section at the end of the chapter.
With a syntactic model of language, what we have is a model of grammatical language. Therefore, we can use a parser to find where the grammar breaks down. When a parser fails to parse a sentence, we have an indication that something is grammatically wrong with the sentence. Here we are more concerned with identifying that there is a grammatical error, such that a native speaker could figure out exactly what the problem is. In the context of language tutoring systems (LTSs), discussed in Chapter 3, additionally the nature of the error needs to be specifically pointed out to the learner.
There are a variety of general approaches for dealing with ill-formed input, and here we will discuss relaxation-based techniques. Relaxation-based techniques for detecting grammar errors relax the parsing process to allow errors. The parser is altered in some way to accept input that it would normally reject as erroneous. This might involve relaxing the parsing procedure so that what would normally result in a parsing failure is allowed to continue building a parse tree, noting where in the parsing the relaxation took place. Alternatively, one might write grammar rules that predict types of failures (i.e., mal-rules); for example, a rule might be expressly written to allow a first-person singular subject to combine with a third-person singular verb, indicating the construction as erroneous.
Although this way of writing grammars can be highly effective, it is not without problems. First, grammars have to be written by hand by trained experts. Both the training and the grammar writing can be time-consuming and intellectually demanding. Even the simple context-free formalisms developed so far are subtle enough to call for sustained thought and careful reasoning, since the consequences of writing a particular rule may be wide-ranging and subtle. This is even more challenging when we consider that the rules we saw in Section 2.4.1 were a simplification of what grammar writers usually do. In practice, grammars are usually augmented with linguistic features to encode properties such as agreement. S → NP VP, for example, becomes S[PER x, NUM y] → NP[PER x, NUM y] VP[PER x, NUM y], where PER and NUM stand for “person” and “number”, and x and y are variables, where every occurrence of the same variable is assumed to represent the same value. This is good because it reduces the number of very similar rules that have to be written, but potentially bad because the extra power increases the risk that the grammar writer will get confused and make a mistake. On the other hand, if you are a particularly patient, orderly, and careful thinker, you may find that you are good at writing grammars, in which case you might have a future doing so.
Secondly, there are grammatical constructions that are rarely used, and we have to decide whether to include these rules in our grammar. For instance, should we have rules to cover “the more, the merrier”, where no verb is used? Finally, as with dictionaries, grammars are likely to be incomplete. Not only are there new words to deal with, but people also continue to create novel expressions and turns of phrase. So if you do find work as a grammar writer, you will probably find that you have taken on a long-term obligation to maintain the grammar as new words and phrases appear.
Grammar-based techniques attempt to detect all errors in a text. However, since grammars are a fair amount of work and since people are more concerned about eradicating the most common errors, we can save time by focusing on only a subset of errors without using a full grammar.
A very simple technique for detecting and correcting grammatical errors is simply to write rules that spot an error pattern and alter it. For example, a rule could match the pattern of “some” or “certain” followed by “extend”, and change “extend” into “extent”. Even a small set of such error pattern rules can be used to build a grammar corrector that can work as well as some commercial software. The disadvantage, again, is that the rules have to be handwritten, and they will be necessarily incomplete, as people make new errors (and new kinds of errors) all the time.
Note that these rules are typically regular expressions (see Section 4.4), which means that we are no longer capturing all of language completely. To learn more about this, see Under the Hood 4. Likewise, the next technique also does not attempt to model language completely.
Complementing the rule-based techniques described in the previous sections, statistical techniques can be used to detect and correct words in context, be it real-word spelling errors or grammatical errors. One such technique is to use n-grams of words to tell us what are likely and unlikely sequences of words. By n-gram we mean sequences of elements: in the context of spell checking in Section 2.3.1, we used sequences of characters, but here we use sequences of words. A simple statistical bigram grammar corrector would use the probability of one word following another to determine whether an error has been made. For example, “conducted be” is not a likely word bigram in English, but “conducted by” is. We will base our discussion here on Wilcox-O’Hearn, Hirst, and Budanitsky (2006).
Real-word spelling correctors that use n-grams typically use trigrams of words. Before we get to how trigrams are employed let us look at the overall scheme: (i) For each word in a sentence (real-word or misspelling), a set of candidate corrections, or spelling variants, is obtained. (ii) A set of candidate corrections for the sentence is obtained by changing exactly one word in the original sentence to a spelling variant. (iii) The sentence with the highest probability is selected. This probability calculation is where trigrams are used, as will be discussed in a moment.
Let’s walk through an example, given in (16).
(i) We first find all candidates for each word, typically real words that are one operation away. For “came”, this will be “come”, “lame”, “cane”, etc.; for “form”, we will have “from”, “dorm”, etc. (ii) Taking these candidates, we generate candidate sentences, as in (17), by changing one and only one word. (iii) Finally, we find the sentence from this set with the highest probability.
The probabilities are obtained by breaking the sentence down into trigrams and then multiplying the probabilities of each trigram. For the ultimately correct sentence, we will multiply the probabilities in (18), which correspond to the trigrams “John came from”, “came from the”, and “from the house”, in addition to including START and END tags to model the likelihood of particular words starting or ending a sentence.
To get these probabilities, we have to go through a corpus and count up how often different trigrams occur. A major problem with such techniques is that it is hard to estimate the probabilities of all possible trigrams from a corpus, given that language is infinite. This is an issue of data sparsity: no matter how much data we use, there will always be something we have never seen before. Data sparsity is a core problem in much of statistical natural language processing, where the behavior is guided by the data one has seen. Learning from a larger corpus can help alleviate the problem, although it does not completely solve it. However, this presents another issue: the number of observed trigrams will be large (e.g., 20 million), so the data structures used need to be efficient. With a large corpus and efficient data structures in place, the method is intuitive, easy to implement, and effective at suggesting error corrections.
N-gram techniques for grammar checking are a form of machine learning, where a computer learns in what contexts a word might be misspelled. Machine learning involves a computer program learning from data such that it can apply what it learns to a new task (see more in Chapter 5 on document classification). Another, similar set-up is to view the context-dependent spelling correction task as a word disambiguation task: we want to find which of a set of words is the correct word in a given context. We base much of the following discussion on Golding and Roth (1999).
Instead of using sets of candidates based only on spelling differences, these techniques use confusion sets consisting of words that are potentially confounded with one another in any relevant property. For example, a set could contain the words “there”, “they’re”, and “their”, and the task of the system is to figure out which of the words was meant in a given context. The advantage of such confusion sets is that the words do not have to be similar looking: “amount” and “number”, for instance, can make up a set of words that are commonly confused. The disadvantage of these confusion sets is that someone has to define them in advance.
The task for the machine, then, is to learn which member of a confusion set is the most appropriate in a particular context. To do this, we break down the surrounding context into different features. Common kinds of features are context words and collocations. Context words capture a broad semantic context because they are simply words within a certain distance of the word in question. For example, it is useful for the spelling corrector to know whether “cloudy” appears within the surrounding ten words if the confusion set we are dealing with is composed of “whether” and “weather”. Collocations, on the other hand, capture a very local context – essentially n-gram information. With the same set of “whether” and “weather”, for instance, a collocation might be the word in question followed by “to” and a subsequent verb (e.g., whether to run).
We will not discuss the actual machine learning mechanisms here, but the idea is that the computer learns which contextual features tend to go with which member of the confusion set. When a new text is encountered with a member of the confusion set, the machine checks to see whether that word is the best one from the set in this context.
Many real-word errors result in a word that does not seem to fit the meaning of the rest of the sentence or paragraph. We refer to this as being semantically inappropriate. For instance in example (19) given by Hirst and Budanitsky (2005), the word “hole” does not fit very well with “sincere.”
The word “hope”, on the other hand, fits rather well with surrounding words like “sincere”. This leads to a two-step procedure for identifying semantically inappropriate words:
For this to work, we then require two things: a way to identify words that are semantically unrelated to their surroundings, and a way to obtain a set of candidates for correction. We already discussed in Section 2.3.2 how to obtain candidate corrections, so we just have to define semantic relatedness between words; that is, how far apart they are. In other words, we want to know which words are likely to appear in the same topic; relevant here are synonyms (e.g., couch and sofa), antonyms (e.g., good and bad), and any sort of meaningful relationship (e.g., penguin and Antarctica) (see also Sections 3.3 and 7.6).
One way to define semantic relatedness is to use a semantic hierarchy, such as WordNet (http://wordnet.princeton.edu/). A semantic hierarchy defines relationships between words, such as: a “hatchback” is a type of “car”, which is a type of “vehicle”. For English, at least, WordNet is an impressive resource that lays out the relationships between many different words and concepts (and more information on it can be found in the Further reading). Roughly speaking, we can use the distance between two words in WordNet to tell us how semantically related they are: “hatchback” and “boat” are somewhat related, in that both are “vehicles”, but “hatchback” and “terrier” are not particularly related, as the only commonality is that they are “physical objects”.
As a side note, the techniques we have been discussing are very similar to techniques used for a related task, that of word sense disambiguation (WSD). In that task, a system takes a semantically ambiguous word like “bank” and attempts to determine which sense the word has in a given context (e.g., a financial institution vs. the sloped land next to a river). Hierarchies like WordNet are useful for defining the senses.
On May 23, 2007, Erik Gunther of Yahoo! listed the 20 top search misspellings from its search logs, with the corrected versions listed in parentheses. Note that, except for “Tattoo” and “Genealogy”, these are all proper names. Furthermore, many of the people were relatively unknown before 2006. 1. Wallmart (Wal-Mart) 2. Rachel Ray (Rachael Ray) 3. Amtrack (Amtrak) 4. Hillary Duff (Hilary Duff) 5. Katherine McPhee (Katharine McPhee) 6. Britany Spears (Britney Spears) 7. Geneology (Genealogy) 8. Jaime Pressley (Jaime Pressly) 9. Volkswagon (Volkswagen) 10. Wikepedia (Wikipedia) 11. William Sonoma (Williams-Sonoma) 12. Tatoo (Tattoo) 13. Travelosity (Travelocity) 14. Elliot Yamin (Elliott Yamin) 15. Kiera Knightley (Keira Knightley) 16. Kelly Pickler (Kellie Pickler) 17. Brittney Spears (Britney Spears) 18. Avril Lavinge (Avril Lavigne) 19. Rianna (Rihanna) 20. Jordan Sparks (Jordin Sparks) |
Figure 2.14 Iteratively transforming a query

Earlier, when we discussed the question of what grammar is, we said that we were interested in descriptive grammar: how the language is actually used. For many writing purposes, however, we are also interested in prescriptivism: how one is supposed to use a language. For example, many of us were instructed never to end a sentence with a preposition. When writing a paper or any formal document, many people want to have these rules in place. When writing a less formal document, these rules may not be followed.
Thus, we distinguish style checkers from grammar checkers. Style checkers can check for violations of a particular style, such as that prescribed by MLA standards. The constructions may still be English, but are simply unacceptable for the purposes of the current document. For example, one might want to have a style checker find singular uses of “data”, such as “the data is”, if the style dictates that it should be plural.
In terms of technology, style checkers work as grammar checkers do; they just identify different constructions. For instance, style checkers might flag the use of too many passive constructions, which are usually disliked in “clear” writing, or they might disallow split infinitives (e.g., to boldly go). As with grammar checkers, style checkers might only examine a small window of context; often, a passive construction with many words between the “be” verb and the passive participle will go undetected as a passive (e.g., was very readily and quickly detected).
After reading the chapter, you should be able to:
After reading the Under the Hood sections, you should be able to:
Further reading
For a good (if slightly dated) overview of spell checking techniques, see Kukich (1992), which has a similar structure to this chapter and presents many of the facts on which we relied (e.g., human agreement rates for isolated-word spelling correction). Mitton (1996) is a somewhat more recent book that provides a good overview of both the types of errors people make and how to correct them. For those who are more computationally inclined, the LingPipe software suite contains a tutorial of spelling correction (Alias-i, 2009), including relating spell checking to the noisy channel model and walking through some programming code that corrects web queries (http://purl.org/lang-and-comp/lingpipe).
We relied on many references for this chapter. To see more about storing probabilities, see Kernighan, Church, and Gale (1990); for more on types of errors, Damerau (1964) provides some early analysis. Mangu and Brill (1997) discuss automatically deriving spelling rules. The SOUNDEX system was developed in Odell and Russell (1918) (note that this was almost a century ago!). Wing and Baddeley (1980) provide evidence of the percentage of real-word spelling errors.
For more information on what grammar is, one can consult any introductory linguistics textbook, such as Mihaliček and Wilson (2011). If you are interested in parsing techniques, you can consult chapters 12–14 of Jurafsky and Martin (2009), which also contains pointers to more advanced works.
A very readable description of formal language theory and complexity can be found in Chapter 16 of Jurafsky and Martin (2009). A comprehensive formal treatment of the topic can be found in Hopcroft, Motwani, and Ullman (2007).
While many of the papers on techniques for correcting words in context are somewhat challenging to read, given the amount of computer science background they assume, Wilcox-O’Hearn, Hirst, and Budanitsky (2006) has a great deal of useful discussion about n-gram grammar correctors, as well as the general task of context-sensitive spell checking, that many readers will find understandable and enlightening. If desired, one can also check out earlier papers such as Mays, Damarau, and Mercer (1991) and Verberne (2002). Likewise, the introduction of Hirst and Budanitsky (2005) provides a good overview of the challenges facing such correctors. Leacock et al. (2010) provide a very readable introduction to the task of grammatical error detection, focusing on its uses for ESL learners, but also presenting, for instance, some discussion of how the Microsoft Word grammar checker works.
For rule-based grammar checking, Naber (2003) originally used 56 rules to achieve good performance. This later developed into the open source software Language Tool (www.languagetool.org/).
If you want to explore word sense disambiguation, there is a wealth of papers and resources, such as those associated with the SemEval workshops (http://www.cs.york.ac.uk/semeval/). A survey paper aimed at a general audience is McCarthy (2009). WordNet is more fully described in Fellbaum (1998) and can be freely found at http://wordnet.princeton.edu/.
More on machine learning techniques can be found in Golding and Roth (1999), Mangu and Brill (1997), and Jones and Martin (1997); note, however, that these papers require some formal or computer science background to read.