Figure 3.1 A web-based multiple-choice quiz

Computers are widely used in language classes to help students experience a foreign language and culture. They deliver videos and podcasts, texts and multimedia presentations, and they can host chat rooms and online lessons where learners interact with native speakers. Many students also log on to complete computer-based exercises and tests on the web. Yet, the typical tests and drills with true/false and score feedback are only pale approximations of what a good teacher can provide as feedback, and indeed such systems do not really use the special capabilities of the computer to analyze language in an important way. In this chapter, we discuss how computers can help provide foreign language learners with a richer, more personalized, and more effective learning experience.
You probably don’t remember learning your first language or having anyone teach it to you, yet here you are reading this book. Students learning a second language experience a situation very different from that encountered during first language acquisition. Babies and young children seem to need no instruction in order to pick up their native language, and this process certainly does not require computer skills from any of the participants. This remarkable human capability has been a hot issue in the science and philosophy of language since the very beginning of scholarship. Researchers strongly disagree with each other on how much of the ability to learn a language is innate, and how much simply emerges from experience, and these arguments do not look likely to be conclusively resolved any time soon. It is clear, though, that our innate biological endowment and our ability to learn from a rich social and physical environment both play imporant roles.
However it works, children can learn a language just by using it and being exposed to it in the course of everyday life. At the beginning of their lives, babies can already cry to express displeasure and make other sounds to signify pleasure. They start to play with making sounds soon after, and at about six months typical babies are beginning to use sequences of consonants and vowels such as bababa, a stage referred to as babbling. They then quickly start learning words by their first birthday and can form simple two-word utterances by the time they turn two. Children then make use of more and more of the language structure, so that by the age of three they can already voice and understand sentences of surprising complexity. In the next nine or ten years of childhood, more and more words and complex language structures are acquired, with some structures such as passive sentences being added relatively late, around nine or ten years of age. These typical stages of first language acquisition are essentially the same across all languages and cultures, and they apply, with some individual variation, to almost all children. If a child can hear, has a normal social life, and is otherwise healthy, language acquisition is almost automatic. Because of this, health professionals pay careful attention to language development in assessing the general health and welfare of a young child.
Interestingly, if they grow up in an environment in which more than one language is spoken, children can also acquire several languages at the same time. This is, for example, often the case when one parent speaks one language and the other parent another, or in environments where multiple languages are being spoken, which is the norm in many countries outside the USA and Europe, for instance in Africa or the Indian subcontinent. A child thus can be a native speaker of multiple first languages, acquiring each of them without requiring explicit instruction.
Consider in contrast what it is like to learn a language as an adult, a situation generally referred to as second language acquisition. Even after living in a foreign country for a long time, listening to and talking in a foreign language there, adults do not automatically acquire a second language. In line with that general observation, research since the 1990s has shown that language awareness as an awareness of the forms, functions, and regularities of a given language is important for an adult learner to acquire that language successfully. For example, the use of the articles “the” and “a” in English is quite difficult to learn, especially for foreigners whose native language does not make use of articles, such as Chinese or Russian. Learning the distinction generally requires awareness of classes such as mass nouns, a class of nouns that cannot be counted (e.g., “rice”, which would lead to ungrammatical sentences such as “Please give me three rice”), and of generic uses of nouns (e.g., “lion” in “The lion generally lives in Africa”). In a sense, this is also reflected in the fact that we typically learn foreign languages in school instead of just being able to tune in to a foreign language radio or television station to pick it up – even though such exposure to a foreign language can support foreign language instruction, which gets us back to the starting point of using computers to help learners experience a foreign language and culture.
What are the particular needs of second language learners? We mentioned that they benefit from foreign language instruction to become aware of language forms and regularities, yet the time a student learning a foreign language can spend with an instructor or tutor typically is very limited. As a consequence, work on form and rules is often deemphasized and confined to homework, so that the time with the instructor can be used for discussions, role-playing, and other communicative activities. The downside is that the learner has relatively few opportunities to gain language awareness and receive insightful individual feedback on their writing. Indeed, the British National Student Surveys identified the lack of prompt feedback as an important concern for higher education in general: “students are notably less positive about assessment and feedback on their assignments than about other aspects of their learning experience” (Williams and Kane, 2008).
This situation seems like an excellent opportunity for developing computer-assisted language learning (CALL) tools to provide dedicated, individual feedback on assignments written by the learner. CALL tools can also make users aware of particular aspects of foreign language texts, such as the particular ways in which ideas are expressed, the forms in which specific words need to be used, or the order in which words have to appear. In the following, we discuss how computers are used to support those aspects of a foreign language and take a closer look at the nature of the analyses this requires.
As a starting point, computers can be used to explicitly store the knowledge about words or the grammar of a foreign language necessary to complete a specific exercise. For example, Figure 3.1 shows the first part of a web-based quiz targeting the use of prepositions in English.
Figure 3.1 A web-based multiple-choice quiz
Such multiple-choice exercises found on many language learning websites can work well for practicing or testing specific choices of forms or meanings. The person creating the exercise includes so-called distractors as incorrect choices in addition to the correct answer. Good distractors will generally be of the same class as the correct choice, such as another preposition in the exercise above.
Computers are a good medium for delivering language exercises because they allow immediate feedback and, more generally, because they can respond in a more flexible way than is possible using pencil and paper. In a frame-based CALL system, the answers given to an exercise by a student are matched against a set of correct and incorrect answers that are explicitly specified by an instructor in a so-called frame. In addition to true/false feedback, the frame can include more elaborate feedback for each of the choices. For example, for the option “in” of the first exercise in Figure 3.1, one could specify the feedback: “False. While the preposition ‘in’ can be used for cities, it cannot be used for streets as in this example.”
It is not necessary for multiple-choice exercises to be presented as lists of checkboxes. Some systems instead allow the student to respond by clicking on a hotspot in a graphic; or use pull-down menus listing the choices; or fill-in-the-blank (FIB) texts, where a word in a sentence is erased and the learner must type in the missing word – also referred to as cloze exercises or gap-fill exercises.
In addition to the set of expected answers and the feedback to be provided, such cloze exercises need to provide a fallback case to respond to any unexpected input. For instance, if a learner types “Help me!” in a FIB exercise targeting prepositions, the fallback option may provide the feedback: “You entered ‘Help me!’, which is not a preposition in English. Please enter a preposition.” Such computer responses are also called canned text responses. It is often appropriate for the canned message to incorporate material that is based on what the user said, such as the phrase “Help me!” entered by the user above. This is often a good idea, because it can make the system seem responsive. In the chapter on dialog systems (specifically, Section 6.7) we will see an extended example of how this can be used to create the impression of natural dialog.
It is easy to see that there will be limits to what can be done by explicitly listing all answer choices and the feedback messages to be displayed for them in a language learning exercise. We are about to discuss those limits, and what can be done to overcome them. But first, let us consider what an excellent automated tutor could do in response to learner input, in addition to providing feedback. Like a good teacher, it could provide remedial exercises for students having problems, but allow students doing well on an exercise to move on to more challenging exercises and materials. Indeed, such dynamic sequencing of instruction is found in some present-day frame-based CALL systems.
In their most basic variants, linear CALL systems pose a question as part of an exercise, accept an answer from the student, and then inform the student as to whether or not the answer was correct (as well as any more detailed feedback stored for the choice made). Regardless of the correctness of the answer, linear systems then proceed to the next question.
In branching CALL systems, on the other hand, the sequencing of the exercises depends on what the student does. For example, if for a given exercise the student provides a correct response, the system continues with a slightly harder question; if the student provides an incorrect response, the system next presents a simpler question and might suggest additional reading material explaining the specific issue at hand. The hope is that this flexible sequencing will allow each student to receive instruction that is precisely tailored to their individual needs. This kind of flexible sequencing is also used in computer adaptive testing (CAT).Once again, the choice of items is affected by the previous answers given by the test taker. But this time, the goal is different: if the system can make sure that strong students do not spend time on questions that are much too easy for them, and weak students do not spend time on questions that are much too hard for them, fewer questions will be needed in order to get an accurate assessment of each student’s ability. If you have taken computer-delivered standardized tests, you may have experienced this strategy in action. Once again, this kind of adaptivity is really only feasible if the test is delivered electronically.
A general problem with frame-based CALL systems is that their knowledge is very specific. They do contain the frames, the pre-envisaged correct or incorrect answers that the student might enter, and the feedback that the system should provide for these answers, but they do not contain any generally applicable knowledge of language. This limits their flexibility. Since they do not really analyze language, the best they can do is match the string of characters entered by the student against strings of characters stored as potential answers to the exercise. If the response matches an expected answer, whether right or wrong, the system can trot out the prescribed action. But if the response is unexpected, the system will have to fall back on default responses, many of which are unlikely to be very helpful. If the system could analyze language in a deeper way, it might be able to find a more appropriate response. In the next sections, we will give more detail on what is needed in order to overcome these limitations of frame-based systems.
While CALL systems can successfully handle exercises of the type discussed in the previous section, the fact that traditional CALL systems cannot analyze language means that everything needs to be spelled out explicitly when the teacher designs the exercise – all options for answering it and the feedback the system should provide for each one. For instance, take a basic fill-in-the-blank exercise such as the one in (22).
Possible correct answers include the ones shown in (23), plus many other ways of writing down this date in English.
Combined with the many different ways one could misspell any of these options and the large number of incorrect answers a learner might enter for this blank, even for such a trivial question we obtain a very long list of possible correct and incorrect answers. To enable a CALL system to react to such answers, as part of the exercise one would have to list each of those options explicitly together with the feedback the system should provide for it.
Consider other dates, say “October 10”, “Oct., the 10th”, etc. Clearly, the many different options for writing down dates in English are available for any date you pick. Instead of having to explicitly list every option for every date, what we need is a general way to refer to a given date in all the possible, predictable ways of writing it down in English. In computational linguistics, the related task of identifying dates, addresses, or names of people or companies in a text is referred to as named entity recognition. It has received much attention since recognizing all the different ways to write the same name is, for example, also important for search engines and other information-retrieval applications.
At this point, one may well object that the different ways of writing down dates or names are not particularly interesting language aspects for learners of English. Yet, the need to be able to refer to classes instead of individual strings arises in language much more broadly than just for dates and other named entities. Consider, for example, the fill-in-the-blank exercise in (24), modeled on a German exercise in Trude Heift’s E-Tutor system.
The different options for filling in this blank correctly go far beyond differences in writing things down. For one thing, languages typically offer many words for expressing a given meaning – for instance, for the exercise in (24), the English language includes many words to talk about vehicles. Among the possible correct answers, there are synonyms; that is, words that mean the same (at least in certain contexts), such as “car” and “automobile”. And as we discuss in the context of machine translation in Section 7.5, there are various other lexical semantic relations between words. In our context, another relevant lexical semantic relation is hyponymy; this is the option of picking a more specific term, a so-called hyponym, such as “pick-up”, “SUV”, or “hybrid car” in place of the more general term “car”, the hypernym. Finally, though the people designing exercises generally try to avoid this, there may also be multiple different meanings that make sense for a slot in a given exercise; for instance, in (24) the context would also be compatible with inserting “yacht”, “personal jet”, or even “car radio” – and for each one of these, various semantically related words could be used.
Clearly, specifying all such related words as options in the frame of an FIB exercise would involve a great deal of work – and this is work that would have to be repeated for every new exercise, even though these lexical semantic relations are encoding a general property of the language, not something specific to a given exercise.
The situation is similar when we consider that a single word in a language can show up in different forms. For English, a word such as “bring” has a citation form or lemma“to bring”; this is the canonical form under which it can also be found in a dictionary. In a text, the same word can appear in various forms, such as “bringing”, “brought”, “bring”, or “brings”. The different word forms and their function are investigated in morphology as a subfield of linguistics.
Many languages include an even richer inventory of forms than English. For example, you may know from studying Spanish that verbs surface in complex conjugation patterns. Just looking at the present tense of one of the verbs meaning “to be” in Spanish, one finds the six forms “soy”, “eres”, “es”, “somos”, “sois”, and “son” – and this is only one of over a dozen other tenses and moods. If we want to specify an exercise frame in a CALL system to provide different feedback for different forms, we would have to spell out the many different forms for each exercise – even though this clearly is a general property of the language which we should be able to encode once and for all, instead of having to spell it out for each exercise frame.
For exercises where the learner can enter more than single words, we face an additional problem since, depending on the language, words are combined in different orders and forms to create sentences. This aspect of language is studied in the subfield of syntax, which identifies different word-order possibilities and the forms in which words have to appear in these different patterns (see Section 2.4.1). From our perspective of exploring how difficult it is to specify explicitly all options in the frame of a CALL exercise, the various word-order possibilities result in additional, systematic variation. For example, consider the FIB exercise in (25) targeting phrasal verbs, where both of the orders in (26) are possible.
While for English word order is relatively rigid, for free word-order languages such as the Slavic languages, sentences typically offer a wide range of possible word orders. This is systematic and thus should be expressed by mechanisms capturing language generalizations instead of expanding out all possibilities as part of the frame of a CALL exercise.
So far, we have considered the question of how we can make use of linguistic generalizations to specify compactly the expected correct or incorrect answers, instead of spelling out all forms and word orders by hand in the frame of a given exercise. We still have to specify in the frame what we expect to find in the response, but we can do this more compactly if we can rely on natural language processing (NLP) tools to generate or recognize the wide range of morphological forms and word orders for us. In other words, we can compactly specify the different form options by which language can encode a given meaning, but we still need to provide some specification of the intended answer to ensure that the learner actually provided a meaningful answer to a given exercise.
In ending this discussion, let us note that there are things we can say about the form in general, independent of the exercise. For example, we can refer to parts of speech and require that every sentence should contain a verb; then, we can connect that requirement to feedback reporting when a verb is missing. For such rules, the particular exercise to which they are applied is no longer relevant, apart from the fact that the exercise requires a sentence as the answer. If this idea of using rules sounds familiar, you are right: it is the approach of rule-based techniques to grammar checking that we mentioned in Section 2.4.2; it is used in the grammar and style checkers found in common wordprocessing software today.
Now that we have seen why it is useful to capture generalizations about language instead of hand specifying them for each activity, we need to take a closer look at what is involved in realizing this idea.
If we want to get to generalizations about words, such as the lemmas or parts of speech mentioned in the previous section, as the very first step we need to find the words. In Chapter 1, we saw that text in a computer is encoded on a character-by-character basis. So, a text is simply a very long list of letters. To process such text, as a first step language technology generally needs to identify the individual words, more generally referred to as tokens. This step is referred to as tokenization or word segmentation and a number of different approaches have been proposed for this task. This may surprise you. After all, what is hard about starting a new word whenever there is a space?
The first issue that comes to mind is that the writing systems of many languages do not actually use spaces between the words. For example, in Chinese a word consists of one or more Chinese characters, the so-called zi, and characters are written next to one another without spaces to separate the words. In Section 1.2.3, we saw that in the logographic writing system of Chinese, the characters are generally associated with meanings (as opposed to with sounds, as in alphabetic systems). Differences in segmenting the long string of characters into words thus will directly influence the meaning. Take for example the two character string  . If we segment it as two words of one character each, it means “will hurt”; if we segment it as a single word consisting of two characters, it means “vitals”. Which tokenization is chosen depends on the context – much like the context determines whether an occurrence of the English word “bank” refers to a financial institution or a river bank. Such a segmentation problem, where two or more characters may be combined to form one word or not, is referred to as a covering ambiguity.
. If we segment it as two words of one character each, it means “will hurt”; if we segment it as a single word consisting of two characters, it means “vitals”. Which tokenization is chosen depends on the context – much like the context determines whether an occurrence of the English word “bank” refers to a financial institution or a river bank. Such a segmentation problem, where two or more characters may be combined to form one word or not, is referred to as a covering ambiguity.
Figure 3.2 A potential overlapping ambiguity in Chinese

A second kind of tokenization problem is overlapping ambiguity, which refers to cases where a given character may combine with either the previous or the next word. Lu (2007, p. 72) provides a clear illustration of this ambiguity with the string  . Depending on whether the second to last character
. Depending on whether the second to last character  is part of the last word or the word before that, the meaning of the sentence changes significantly, as illustrated by Figure 3.2 (even though in Chinese only the second segmentation option is a grammatical sentence).
is part of the last word or the word before that, the meaning of the sentence changes significantly, as illustrated by Figure 3.2 (even though in Chinese only the second segmentation option is a grammatical sentence).
You may consider yourself lucky that the writing system used for English makes it so much easier to determine what the words are by simply starting a new word whenever there is a space. But even for English, life is not that simple. After all, “inasmuch as” and “insofar as” would then be split into two tokens and “in spite of” into three – but to process them further or even just to look them up in a dictionary, clearly identifying them as a single token would be most useful! For an even more common case, let us begin with a simple sentence such as (27a), where starting a new token for every word is straightforward.
But then we see (27b) on the lapel sticker of someone in the street – and we do not run away thinking we met a criminal bragging about his first killing! We immediately interpret “flu shot” as a single token, parallel to the occurrence of “salary” in (27c), despite the fact that it contains a space. Naturally, this is very much language dependent, as a compound noun such as “flu shot” is, for instance, written without spaces as “Grippeimpfung” in German. So spaces should presumably be allowed in some English tokens, which immediately raises the question of when exactly a tokenizer should identify words that include spaces and when not.
The opposite problem is posed by strings such as “I’m”, “cannot”, or “gonna”. None of these tokens contains a space, but we know that “I’m” is nothing but a short form, a so-called contraction, of “I am”. Similarly, “gonna” occurs in the same places and is interpreted in the same way as “going to”. And a word such as “dunno” (which might well appear in an English text to be processed, even if some people would rather ignore such forms) seems to be equivalent to “do not know”. So, does it make sense to treat them as one token in the contracted form and as two or three tokens in the form including a space? Clearly, treating the two variants in such a radically different way would complicate all later processing, which would not be necessary if we, for instance, tokenized “I’m” as two tokens “I” and “’m”. This naturally raises the general question of when exactly a tokenizer should split up English strings that do not contain spaces into multiple tokens.
In sum, to tokenize an English text, there are some general strategies, such as starting a new token whenever we encounter a space or punctuation symbol, and there are more specific segmentation cases where tokens can contain spaces and where multiple tokens result from a string lacking spaces. The automatic tokenizers used today thus typically contain long lists of known words and abbreviations, as well as a number of rules identifying common subregularities (these are generally finite-state rules; see Under the Hood 7 for a discussion of finite-state technology).
Once we have identified the tokens, we can turn to obtaining the general classes of words we are looking for, such as the part-of-speech (POS) classes that, for example, make it possible to identify that the sentence a learner entered into a CALL system is lacking a finite verb and to provide the general meta-linguistic feedback message “The sentence you entered is missing a verb”, independent of the particular requirements specific to a given activity.
But what are parts of speech and where does the evidence for them come from? Essentially, parts of speech are labels for classes of words that behave alike. What counts as alike naturally needs to be made more precise, and one essentially finds three types of evidence for it. The first is distribution, by which we refer to the linear order with respect to the other tokens; that is, the slot in which a word appears. For example, in the sequence “John gave him ball.”, the slot between “him” and “ball” is the distributional slot of a determiner such as “the” or “a”.
When designing automatic POS taggers, distributional information is typically collected in the form of statistics about which POS sequences are likely to occur, parallel to the n-gram statistics we saw in the discussion of language models in Under the Hood 2. To be able to observe possible POS sequences, one naturally needs a corpus that is already annotated with POS tags. Such corpora with so-called gold-standard annotation are generally created using significant manual effort to annotate or correct the annotation. To obtain gold-standard corpora of the size needed to train current POS taggers (and supervised machine learning approaches in general – see Chapter 5) thus requires large, long-term projects. Correspondingly, they so far only exist for less than 10% of the roughly 6,000 human languages (which poses a significant challenge to the development of NLP tools for underresourced languages).
The second type of evidence is the one we use every time we look up a word in a dictionary. For some words, lexical stem lookup provides an unambiguous part-of-speech category. For example, “claustrophobic” is only listed as an adjective. Yet, many words are ambiguous and belong to more than one part-of-speech class. For example, the word “can” occurs as an auxiliary in “The baby can walk.”, as a full verb in “I can tuna for a living.”, and as a noun in “Pass me that can of beer, please!” Even a word like “some”, which at first glance one might think unambiguously is a determiner (e.g., some cars), is also found used as an adverb (e.g., The cut bled some. or You need to work on it some.) or pronoun (e.g., Some like it hot.).
Another problem of lexical lookup arises from the fact that there are words that are not in the lexicon. Even if we tried very hard and got the world’s best dictionary resource, there still would be words not listed there, since new words are added to the language all the time. For instance, words such as “googling” or “facebooked” clearly do not occur in texts from the 1980s (see also Section 2.3.1). All automatic POS taggers make use of lexical information. That lexical information typically is collected from the POS-annotated gold-standard corpora in the training phase, which records the distributional information mentioned above.
The third type of evidence for classification of words into parts of speech presents itself when we take a closer look at the form of words, their morphology. Certain markings, such as suffixes added to the end of stems, encode information that is only appropriate for particular parts of speech. For example, -ed is a suffix indicating a past-tense marking of words as, for example, in “walked” or “displayed”. Thus, if we find a word such as “brachiated” in a sentence, even if we know nothing about this word or its context, we can infer based on the -ed suffix that it is likely to be a past-tense verb.
Apart from inflectional suffixes indicating information such as the tense or agreement markers (e.g., the -s found on verbs in the third-person singular), other potential sources of information include derivational affixes , such as -er, which is used to turn verbs into nouns (e.g., walk – walker, catch – catcher, love – lover). In automatic POS taggers, suffix analysis is often included in a fallback step. Whenever a word has not been seen before in the training data, so that no lexical or distributional information is available for that word, suffix analysis is performed to determine the most likely part of speech, for example using handwritten rules. If none of the suffix rules applies, as a last resort POS taggers generally assign the most common option, usually a noun tag.
While distribution and morphology already came up in the discussion of guiding principles for part-of-speech analysis in Section 2.4.1, in the CALL context we are considering in this chapter, a complication arises from the fact that we are dealing with a so-called interlanguage written by students with one native language while they acquire another, foreign language. That complication confirms in an interesting way that indeed we are dealing with three independent sources of evidence which we are using to determine the part-of-speech class of a word. Consider the following two sentences written by Spanish learners of English (from the NOCE corpus, Díaz Negrillo et al., 2010):
In (28a), the word “choiced” distributionally appears in a verbal slot, and morphologically it carries a verbal inflection (-ed), whereas lexically the stem “choice” is a noun (or adjective). And in (28b), the meaning of the sentence is fine, but “during” distributionally is a preposition, which cannot appear in the distributional slot of a conjunction. POS-tagging approaches to learner language thus need to be extended to take into account such potentially mismatching evidence.
Naturally, there are many abstractions and generalizations about language that can be used in concisely characterizing and providing feedback to learner answers in CALL systems. Another typical area in this context is grammar – in a sense that is quite different from boring and dry rule books. It is more related to the regularities you can observe in, say, chemistry, when you ask yourself what happens if you combine two given substances. Certain molecules can combine; others don’t; a particular order is needed for them to be able to combine; and sometimes an additional element, a catalyst, needs to be present for a combination to be possible. Or in music, there are clear generalizations about the way you can combine musical notes in chords or when setting music. For those who like neither chemistry nor music, just think of the good old days when you may well have played with LEGO bricks – and again, only certain forms fit together in a particular order, independent of what it is that you actually want to build. So that is what grammar is about when it comes to using language.
Grammar as studied in the linguistic subfield of syntax captures the same kind of generalizations for language. We already mentioned some of the basic generalizations that syntax makes in Section 2.4.1. These include generalizations about word order. For example, in a typical English sentence, the subject precedes the verb and the object follows it. There also are generalizations about which elements have to appear together; for example, if the verb “devour” occurs in a sentence, it must be accompanied by a particular kind of an object, a noun phrase, to avoid ungrammatical sentences such as “John devoured recently.” Here, the generalization is that a verb can select (or subcategorize) the category of elements that can or must accompany it.
Other generalizations in the area of syntax deal with the forms in which words need to appear to be able to occur together. For example, a subject can only appear together with a verb if they share so-called agreement features, a generalization that is necessary to rule out ungrammatical sentences such as “I walks.” In other situations, when the generalization involves one element telling another what to look like, we typically speak of government. For example, a verb such as “hug” requires its object to occur in the accusative case, to ensure that we get sentences such as “Sarah hugged him” and not sentences where we instead get the nominative form of the pronoun, as in “Sara hugged he.”
We discussed the techniques used for expressing generalizations about the order and form of words in Section 2.4.2 in the context of the chapter on writers’ aids, so we will not repeat them here. Instead, we continue by asking ourselves what happens when we add linguistic analysis in the form of tokenization, part-of-speech tagging, and syntactic parsing and agreement checking to a CALL system. We then obtain a CALL system that is aware of language, in the sense that it can analyze and check some generalizations about language that are independent of a particular exercise.
In such language-aware systems, often referred to as intelligent computer-assisted language learning ( ICALL), one no longer needs to explicitly specify everything in a frame that matches all possible learner answers to the feedback messages to be given in those cases. In ICALL systems, some of the feedback thus is based on a general analysis of language, while other feedback remains based on information explicitly specified in a given exercise – for example, without looking at the exercise materials there is no way to determine the names of the people that a question asks about.
Having discussed various issues that arise in providing feedback with a computer-assisted language learning system, you probably wonder what such systems actually look like. So, in this section, we take a closer look at an intelligent language tutoring system (ILTS) called TAGARELA (Teaching Aid for Grammatical Awareness, Recognition and Enhancement of Linguistic Abilities), an intelligent web-based workbook for beginning learners of Portuguese.
The TAGARELA system offers self-guided activities accompanying teaching. It includes six types of activities: listening comprehension, reading comprehension, picture description, fill-in-the-blank, rephrasing, and vocabulary. It thus is similar to traditional workbook exercises, with the addition of audio. But it provides on-the-spot meta-linguistic feedback on orthographic errors (spelling, spacing, punctuation), syntactic errors (nominal and verbal agreement), and semantic errors (missing or extra concepts, word choice).
Figure 3.3 shows a rephrasing activity, in which the learner is given a sentence and has to rewrite it using the words provided. In this example, the learner forgot to include a verb in the answer they typed into the answer field at the bottom left of the page. The system displays a feedback message pointing out this error at the bottom right of the page. Note that just as discussed at the end of Section 3.3, a sentence missing a verb is an error the system can detect and provide feedback on solely based on knowledge about the language. In TAGARELA, this knowledge about the language is encoded in grammar rules for Portuguese, which are independent of this particular activity.
Figure 3.3 TAGARELA: Feedback on missing verb
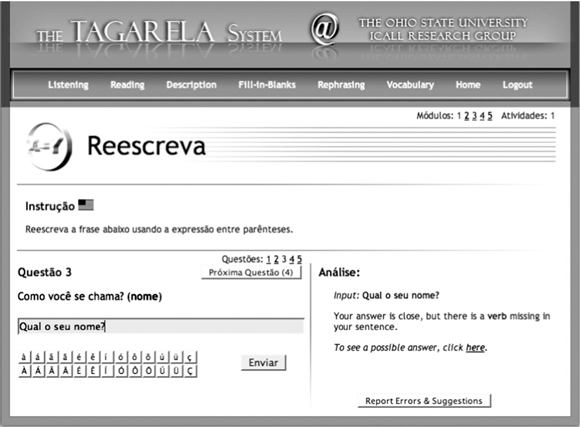
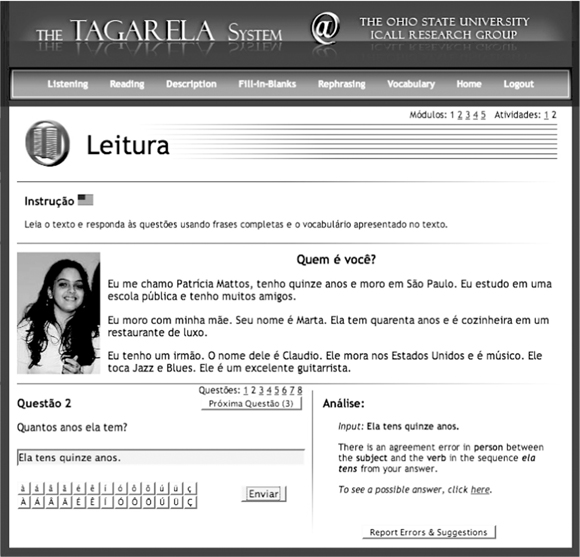
Figure 3.4 shows an example for a reading comprehension question. The feedback provided by TAGARELA for the learner response in this exercise illustrates another general type of error made by language learners, so-called subject–verb agreement errors, where the form of the verb does not agree with its subject.
The feedback in the previous two examples was computed by TAGARELA based on the system’s general NLP capability to analyze language – from identifying tokens, words, lemmas, and parts of speech to syntactic generalizations – without the need for explicit frames spelling out all potential learner answers and the feedback to be provided. Yet, we also mentioned at the end of the previous section that some of the feedback that an ICALL system provides remains based on the specific exercise. An example for such exercise-specific feedback is shown in Figure 3.5, where a text about Brazil introduces the different regions of the country and the learner is asked a reading comprehension question about it.
The learner response states that there are five cities in Brazil, even though the specific question at hand in this exercise was asking about the number of regions in that country. Making use of information specific to this exercise, the system feedback alerts the learner to the fact that the answer is not expected to be about cities but about regions.
Figure 3.4 TAGARELA: Feedback on agreement
Note that even for such feedback based on exercise-specific information, the feedback at the same time also makes use of generalizations detected by the system’s NLP capabilities, by pointing out that the problem is associated with a noun. The system thus recognized the unexpected word “cidade” as belonging to the POS category of noun and used that general information obtained about the learner input in formulating the feedback.
So far, we have mentioned two sources of information that are used by computer-assisted language learning systems. We started with the explicit information in the exercises, in particular the frames that need to be specified for each exercise in a traditional CALL system. The second source of information arises from the computational linguistic analysis in an ICALL system, which is based on the general knowledge about a language and thus is independent of a particular exercise.
Figure 3.5 TAGARELA: Example for exercise-specific feedback

In addition to those two sources of information – the exercise and the language – it can also be important to take into account what we know about the learner. Generally speaking, such learner modeling includes two types of information. On the one hand, there are learner properties that are more or less permanent, such as the gender, native language, or learning style preferences – and it is easy to see that, for example, system feedback for visual learners should be enhanced with more visual cues than for other learner types. On the other hand, there is the dynamic record of learner performance so far, essentially a history recording whether a given learner has successfully used particular words or structures before.
Both types of information about the learner are relevant when providing feedback. For example, a learner’s mother tongue (or first, native language; that is, L1) strongly influences the words and constructions used and the mistakes made when learning a second language – correspondingly, one often reads about positive and negative L1 transfer. An example of negative transfer is the fact that many native speakers of languages such as Chinese or Czech, which do not include articles of the kind found in English, find it very difficult to use the English articles “the” and “a” properly. Correspondingly, a tutoring system should provide feedback on article misuse for learners with such native languages, whereas for other users a missing article may be a minor typo, so that feedback should instead focus on other, more relevant aspects of the learner answer.
Implicit in this last example is the fact that tutoring systems generally try to focus the feedback on the most relevant errors first, since it is known that providing all possible corrections and comments is problematic – just like most students receiving back graded homework will simply stuff it in their bag instead of reading the comments if there are massive red marks all over the place. Learner modeling provides important information for the prioritization of feedback needed to make learners notice the most relevant aspects specific to themselves.
Naturally, L1 transfer does not always cause problems; it can also help a learner in acquiring a new language. An example of positive L1 transfer is the fact that for speakers of Spanish and other Romance languages, many of the English ten-dollar words popular in standardized tests such as the GRE are comparatively easy, since they frequently have Latin roots that survived in many Romance languages.
An important difference between static learner properties such as the mother tongue and the constantly updated history of learner interaction as the second component of learner modeling lies in the way in which the learner information is obtained. Information for the more or less permanent part of a learner model typically stems from a questionnaire asking for information such as gender, mother tongue, time spent abroad, and other languages spoken in the family, as well as from tests providing information on the learner’s general cognitive or more specific language abilities. For the second component of learner modeling, on the other hand, the system needs to draw inferences from the learner’s interaction with the system. Let us take a closer look at what is meant by inferences here and why they are needed.
One could simply record everything the learner enters in exactly the way it is entered. However, all this would help detect is whether the learner has entered a particular answer before, which would allow the system to provide specific feedback for a single, very specific case of minor relevance. To be able to make more use of recording past learner performance, just like in the discussion of analysis and feedback in the first part of the chapter, it is necessary to abstract away from the surface of what the learner entered into the system to the more general linguistic properties and classes of which the learner answer provides evidence. For example, one may want to record whether a learner answer contains a finite verb and whether it showed correct subject–verb agreement. Once we have observed learner answers that include instances of a particular linguistic class or relation, we can infer that the learner has mastered this aspect of the language to be learned and deprioritize feedback on it in the future. Where the tutoring system supports this, learner models may also be used to sequence the teaching material appropriately, for example by guiding learners to additional material on concepts they apparently have not mastered yet.
It is far from trivial to determine when such inferences are valid. Just like in the context of language testing , in the intelligent tutoring context construct under-representation can hinder the recording of a particular ability in a learner model. In other words, the exercises the student is completing need to provide enough evidence of a particular language ability if we want to record and update the record of what the learner can do in the learner model. To ensure valid inferences, it also is not enough only to consider the learner answers themselves. Instead, we also need to include information on the exercise the learner was completing and the strategies learners may employ to succeed in such a task. For example, a particular learner answer may simply have been copied by the learner from the text they were answering a question about, which is known as lifting – and such an answer naturally does not provide good evidence of mastery of the linguistic material it includes. To be able to interpret learner answers in terms of what they allow us to infer about the learner’s abilities, an intelligent tutoring system thus also needs to take into account learner strategies such as lifting or avoidance of structures about which the learner is unsure.
Concluding our exploration of language tutoring systems and the role the analysis of language needs to play within them, the use of NLP in language teaching and in education in general is one of the application areas that is just starting to take off. Following in the footsteps of the first few intelligent language tutoring systems in real-life use today (E-Tutor, Robo-Sensei, TAGARELA), the coming years will bring a much wider range of exercise types with more adaptive feedback and increased use of virtual environments. The first interactive robots used for language teaching are already appearing on the scene. Based on what we discussed in this chapter, it is clear, however, that one aspect will stay the same in all such uses of computers in language learning: for these systems to be able to react to learner input in an intelligent way, going beyond a small number of pre-envisaged frame specifications, it is crucial for the systems to be able to step back from the specific learner answer at hand to more abstract linguistic representations. These representations support system feedback and interaction with a wide range of learner responses. The key to success lies in combining generalizations about language with aspects specific to the given activity and information about the particular learner and their interaction history.
After reading the chapter, you should be able to:
For example, line 124 of the transcript at (http://purl.org/lang-and-comp/childes-ex) shows “I falled down again.” In which sense is this similar to the cases discussed above? Can you find other examples of this pattern? Are there other, related patterns you can see recurring in the transcripts?
To answer this, run a part-of-speech tagger on some learner sentences or entire texts from the CHILDES repository. You can use one of the free online tagging services, such as (http://purl.org/lang-and-comp/claws) or (http://purl.org/lang-and-comp/cogcomp-pos).
What do these part-of-speech taggers do for words used by learners that are not words in native English? Think about the different sources of evidence (distribution, morphology, lexicon). How does the fact that these are sentences written by language learners affect the overall performance of the tagger?
Are there any differences between the exercises offered for learners of English and those for learners of Spanish (e.g., on the pages found by a search for Spanish multiple choice exercises)?
As discussed in the text, L1 transfer is not always a problem for language learners, it can also be helpful. Consider which words a Spanish native speaker would find easy or hard when learning English and give examples.
Further reading
A general overview of the use of NLP in the context of language learning is provided in Meurers (2012). A detailed discussion of ICALL projects, including a historical overview and a characterization of the techniques used, can be found in Heift and Schulze (2007).
Two prominent collections of research articles on intelligent language tutoring systems are Swartz and Yazdani (1992) and Holland, Kaplan, and Sams (1995). Most of the research on learner modeling for intelligent tutoring systems does not deal with learning languages but other subjects, such as mathematics. However, the work of Susan Bull (http://purl.org/lang-and-comp/susan.bull) provides a good overview of the topics and issues discussed in connection with learner modeling for intelligent language tutors. Amaral and Meurers (2008) explain the need to extend learner models of ICALL systems beyond linguistic knowledge.
To get an idea of what intelligent language tutoring systems look like, you can find descriptions of the German E-Tutor system and the exercise types it offers in Heift (2010). More discussion of such systems and how they relate to real-life language teaching can be found in Amaral and Meurers (2011).