Figure 6.1 A sample dialog from the Let’s Go system ( http://www.speech.cs.cmu.edu/letsgo/example.html)

I’m sorry, Dave. I’m afraid I can’t do that.
[Hal 9000, in Stanley Kubrick’s 1968 film 2001: A Space Odyssey]
In the film 2001, Hal is a computer that can use and understand human language as well as we can. He knows how to say things that, while not strictly true, are effective in communicating with Dave the astronaut. The problem in the movie is that Hal becomes so intelligent that “he” starts disobeying Dave’s commands.
In this case, Dave has just requested that Hal open the pod bay doors, and Hal says that he cannot. Both Hal and Dave know that Hal can really open the pod bay doors if he wants to, but they also both understand that he is choosing not to. Hal is being “polite” by using a phrase that disguises the conflict between what Dave wants and what Hal wants.
The reason this conversation works (even if opening the pod bay doors does not) is that Hal and Dave both understand a great deal about the hows and whys of dialog, as speakers and as listeners. From the speaker’s perspective, the important organizing ideas are:
We shall see that practical dialog systems are based on these organizing principles.
From the other perspective, the listener’s role is to make sense of what is being said by the speaker. The listener must:
In order to do this, the listener has to reason about the speaker’s intent on the basis of the observed evidence. Competent listeners know about the conventions of dialog and use that knowledge to make inferences about what the other person must be thinking and intending. A first step toward building a computer that can do the same is to develop precise descriptions of how this process actually works in human–human dialog. In this chapter, we outline some of the concepts that dialog researchers use to describe dialogs and indicate how computers can use them. The key ideas are speech acts, dialog moves, and conversational maxims, all of which will be discussed.
Neither the listener’s perspective nor the speaker’s is the whole story. Communicating is a collaborative event, so the speaker and hearer must interact in ways where each understands the other. Between them, the speaker and the listener must manage the following processes, in real time:
Human beings are skilled in this activity long before they enter preschool. We are so accustomed to this process that we hardly notice it. One of the first consequences of trying to involve a computer in dialog is that the difficulties become more evident. If you take nothing else from this chapter, try to remember to be impressed every time you see two or more people talking without getting confused or frustrated. This is a major accomplishment, and almost everyone does it ridiculously well.
In the film, Hal has clearly acquired the ability to participate fully in natural-seeming dialogs. Stanley Kubrick and Arthur C. Clarke, the writers of 2001, seems to have imagined that Hal learned this in a human-like way, since toward the end of the film there is a scene in which Hal regresses to “childhood” as his memory banks are gradually shut down. It is not yet possible to design computer systems that have Hal’s abilities (he turned out to have language skills beyond those of most humans), but it is possible to design systems that engage in reasonably natural dialog with their human users. Many modern dialog systems are trained by exposure to successful and unsuccessful dialogs, and do learn from experience, but the way in which they do this is quite different from the way a human child learns. (For a general introduction to what it might mean for a computer to learn, see Chapter 5 on classifying documents.) It is not practical to build systems that rely on learning for all their knowledge, so system designers always build in substantial knowledge of how dialog works. Most of this chapter is a description of this knowledge and how it is used in systems.
One of the main reasons for using language is in order to collaborate with others on getting things done. If people, or other agents with some notion of intelligence, such as an artificial intelligence (AI) system, have everything they need, or can get it without asking for help, they have no pressing reason to speak. But, more often, people and computer systems need to work with others in order to achieve their goals. Dave the astronaut wants the pod bay doors opened and cannot immediately do this without Hal’s help, so he requests Hal’s collaboration. Hal turns out not to want to cooperate, but rather than saying this outright, he falls in with the standard conventions of human dialog and talks as if he basically wants to cooperate but is somehow prevented from doing so.
Dialog is full of rules and conventions that have evolved over the years in order to make communication run smoothly. For example, a question is usually followed by an answer; a request is often made indirectly because outright demands feel rude; and a refusal is often heavily disguised so as to soften the impact of the unexpected and unwelcome response.
Rules and conventions are easiest to notice when they break down. The American comedian Demetri Martin tells the following joke (near the end of the video at http://purl.org/lang-and-comp/identity):
I went to a clothes store and the woman there got really annoyed because she asked what size I was and I said, “Actual! This ain’t a trick, baby, what you see is what you get.”
She took me to the changing room and said, “If you need anything, I’m Jill” and I thought to myself, “Whoa, I’ve never met a woman before … with a conditional identity. What if I don’t need anything? Who are you?” “If you don’t need anything, I’m Mike.”
Good humor does not need explaining, but what has happened is that Martin has found a way of deliberately misinterpreting what the shop assistant said. Where is the misunderstanding? Everyone knows that the assistant must mean something like: “If you need anything, do call my name, which is Jill.” We can fill in the details because we understand why the assistant is speaking, and we use that understanding to fill in the interpretation. What Demetri Martin noticed is that literal meaning fits better with the wildly incongruous situation in which Jill has “a conditional identity”.
If computers are supposed to participate in natural dialog with humans, they should be just as flexible as humans, or they should control the dialog so that this flexibility is not needed. One way to do this is to work in a limited domain, such as airline booking, where the system can keep tight control of the dialog, reducing the user to the bit-part role of providing strictly limited information as and when required. If a task can be reduced to simple form filling, and the user is prepared to play along, then this can be an efficient way of getting the job done. We do learn to work with these systems as they are, and to adjust to their abilities, but it is still very different from dealing with a real person.
Figure 6.1 gives an example of what present-day dialog systems can do. The point of the system is to help callers with bus timetables. The system utterances are marked with S and the user responses with U. If you have access to a computer that can play sound, you should go to the URL mentioned in the caption and listen carefully to the dialog. It might be useful to listen a second time after reading the next few paragraphs.
To begin the conversation, the system signals its willingness and ability to serve.
S: Thank you for calling the CMU Let’s Go! Bus Information System. This conversation will be recorded for research purposes. If you do not want to be recorded, please hang up now. What can I do for you?
The first system utterance is simple canned text designed to ensure that the user has given informed consent to participation in a research study. In addition, it mentions the name and purpose of the system, so that people can hang up if that was not what they were expecting.
When the system says “What can I do for you?” part of the point of the polite question is to signal that the user now has the floor and should make a request for information. Having the floor is a useful idea that dialog analysts have borrowed from parliamentary procedure. When you have the floor, you have the opportunity, and sometimes the obligation, to contribute something to the dialog.
Figure 6.1 A sample dialog from the Let’s Go system ( http://www.speech.cs.cmu.edu/letsgo/example.html)
U: I would like to go to the airport tomorrow morning.
The user’s first utterance announces the wish to go to the airport. Notice that this is not a direct request for bus information, but rather a statement about a desire that the caller has. Section 6.5 goes into detail on why conversations are often indirect. She does not need to say “I need some bus information.”, because this is built in to the participants’ understanding of the context in which the conversation is happening. In other words, this reflects the fact that the system and the user both understand the why of this conversation.
U: I would like to go to the airport tomorrow morning.
S: To the airport. When do you want to arrive?
The next system utterance includes two things. The first is a confirmation that the system has correctly understood the destination to be the airport. The second part of the system response is a question about the caller’s plan. Something quite subtle must be going on here, because nobody has mentioned a plan yet. Specifically, the system has assumed that the caller intends to make a bus journey to the airport, and it is therefore trying to help her out by finding a suitable bus. Notice that the caller has not said that she is planning to travel to the airport, only that she wants to do so. In context, it is a completely reasonable assumption that she does indeed have such a plan, and it is also an entirely reasonable thing for a cooperative dialog system to adopt the goal of providing the caller with the information she needs in order to execute that plan. Therefore, the system asks when the caller wants to arrive at the airport.
S: To the airport. When do you want to arrive?
U: I’d like to arrive at 10:30.
S: Arriving at around 10:30 AM. Where do you want to leave from?
U: I’d like to leave from Carnegie Mellon.
The caller provides the information. The system confirms its understanding of her intended arrival time, cleverly augmenting the caller’s 10:30 to 10:30 a.m. This acts as an implicit confirmation of the system’s assumption that it did correctly recognize the word “morning” earlier on. Notice that it would be much less smooth for the system to ask explicitly: “Do you mean 10:30 a.m. or 10:30 p.m.?” Then the system prompts the user by asking for another necessary detail. The user provides Carnegie-Mellon as the departure point.
The system now has the information it needs to look up a bus, and it does so. It has collected all the preconditions for doing its database lookup, and can move ahead without further help from the user.
U: I’d like to leave from Carnegie Mellon.
S: From Carnegie Mellon. There is a 28X leaving Forbes Avenue at Morewood at 9:20 AM. It will arrive at Greater Pittsburgh Airport at Departure Stops at 10:15 AM.
The next utterance confirms Carnegie-Mellon, then provides detail about a particular bus leaving at a particular time and arriving at Greater Pittsburgh Airport. The system gives the full name of the destination, which is perhaps more than a lay person would, but probably exactly what an experienced travel agent would do.
The reason the system gives more information than is strictly needed is in order to avoid misunderstanding. If the caller had really intended to travel to some other airport near Pittsburgh, now would be the time she would find out that the system was not understanding the phrase “the airport” in the same way as she was. In fact, when, earlier in the conversation, the caller used “the”, she was relying on an assumption about what the system knows. In a city where there were multiple well-known airports, the system would have needed to request clarification with some utterance like: “Hang on, which airport did you mean?” Clarification requests are among the dialog moves covered in Section 6.5.
In fact, there actually are several different airports near Pittsburgh, but only one that has generally accessible flights open to the public, so the system would be justified in assuming that this is the one the caller means. Temporary ambiguity is OK, so long as the system and the caller finish up with a common understanding of what was meant. The system’s strategy of explicitly confirming the full name of the destination is a good means to this end.
S: From Carnegie Mellon. There is a 28X leaving Forbes Avenue at Morewood at 9:20 AM. It will arrive at Greater Pittsburgh Airport at Departure Stops at 10:15 AM.
U: When’s the next bus?
S: …
U: Thank you very much.
The system has finished its current task, but the conversation is not over. It would be over if the caller said “OK” now. But instead she asks: “When’s the next bus?” The system does extremely well with this, correctly understanding that the caller is asking for a bus with the same departure and arrival points, but a later departure time. Even though her question could be seen as idle chit-chat, the system understands it as a request for a completely new plan. Notice that this bus does not exactly meet the caller’s declared goal of arriving by 10:30. It looks as if the programmers built a certain amount of tolerance into the planning, because many callers are relaxed enough not to worry about five minutes one way or the other.
The rest of the conversation is a new plan for the return journey. Things work as before, then the whole interaction terminates with the caller’s formulaic “Thank you very much”, and the system can safely hang up.
A running thread in the Let’s Go dialog is that the system and the caller are making assumptions about beliefs, desires, and intentions, that these assumptions are silently tracked by the participants, and that this allows the conversation to be concise and efficient. Because the system and the caller both understand the goals of the dialog, there is no need for the conversation to mention these goals explicitly. The participants come to the conversation with a set of expectations that frame the dialog and allow it to proceed smoothly.
There is much more to this idea of framing expectations than meets the eye. A useful analogy is to think of dialog as resembling a game of basketball. Games have rules, and when the players agree to participate, they also agree to be subject to the rules that control the game, rules that are designed to make the game enjoyable to play. The rules are designed to frame the game and set up expectations for how things will proceed; they are conventions rather than strict rules. A basketball game without any fouls would be a major surprise, and players who joined the game looking for an opportunity to exercise their physical skill and courage might actually be disappointed if this happened. In high-stakes settings, there is a referee, part of whose job is to apply appropriate sanctions for rule violations. In a neighborhood pick-up game, the rules will be enforced (or not) according to a tacit understanding between the players. In a mixed-ability or mixed-age group, there might be a general understanding that older and heavier players should be gentle with younger and lighter players (or not). In chess, which is a different kind of game from basketball, the rules are usually adhered to relatively strictly, but there are still gray areas: a player would never expect to be allowed to take back a move in a tournament, but might easily ask to do so in an after-dinner game with a friend. Chess is also different from basketball in that there is a strict rotation of moves: first white plays, while black waits, and then it is black’s turn while white waits.
In the same way, dialog has conventions and rules. Discomfort can and does arise if the participants do not “play fair” in the game of dialog. For example, the caller would be quite right to be annoyed if she later found out that there is a perfectly good bus from Forbes Avenue to the airport, leaving at 9:55 and arriving at 10:20. Even though this is not the answer to “When’s the next bus?”, she is still entitled to expect that a well-informed and cooperative travel helper would offer it to her if it existed, because it is a better way of meeting her declared goal than the one that she was offered. So, she infers that no such bus exists. In so doing, she is relying on a deeper assumption, which is that the system understands and is playing by a generally accepted rule of dialog: one that can be stated as “Be cooperative.” As in the other games, the ways the rules of dialog are applied depend on the situation. In law courts, the rules are tight, rather artificial, and managed by the judge, who plays the role, among others, of referee. Decision-making meetings often follow Robert’s Rules of Order (http://www.robertsrules.com), which are again very formal. However, in everyday conversation, the rules and conventions are less obvious, partly because we are so used to them. Computers, of course, begin with no knowledge or understanding of the conventions of dialog. If we want them to participate in conversation, and we are not satisfied by an inflexible form-filling approach, we are going have to study dialog, understand the implicit conventions, and draw these out into a form that can be used in computer programs. This is what we outline next.
We have just mentioned the idea of treating dialog as a game. Before this concept became established, the standard view was that language existed primarily in order to allow the speaker to generate and use accurate descriptions of the world. Many of the people who studied language were mathematicians, logicians, or philosophers of science, for whom the central preoccupation is how to establish whether or not something is true, so this is really not surprising.
In the 1950s and 1960s, an alternative view arose: language was instead seen as a tool for getting things done, especially getting things done in collaboration with others. This approach turns out to be extremely suitable for use in dialog systems. In this perspective, dialog is treated as a kind of cooperative game, and the things people say become moves in that game. This matches the needs of dialog systems, because dialog systems are usually goal driven.
We will investigate various properties of dialog, all of which help us see dialog as similar to a game. Researchers in this area talk about dialog moves, speech acts, and conversational maxims. These are useful concepts, and worth knowing about, whether you are interested in computer systems or not. We discuss each in turn.
What kinds of things happen in a dialog? One way to answer this question is by viewing dialog as a series of moves, like in a game. As in chess, what you can do at a given point in the dialog depends on what has gone before; a range of dialog moves are available. Typically, the core of the matter is that the participants exchange information.
We can break down dialog moves into three basic kinds:
These examples should be enough to give you an idea of the kind of give-and-take that can go on in conversation, and of the way in which previous moves can influence the choices that are reasonable as next moves. There is a lot of current research on dialog, and we are still short of a final consensus on what the repertoire of dialog moves should be, but the simplified version above is based on a comparative review of several frameworks, and is probably a good basis for extension and exploration. In general, this type of categorization is useful for determining a dialog system’s next move.
A different kind of characterization of dialog is in terms of speech acts, which emphasize different aspects of utterances. To understand the history of speech acts, it helps to know that philosophers have often thought of sentences in terms of truth: the words in a sentence are combined in order to form a true or false statement. Part of the reason speech acts were developed was a philosophical concern with what is going on when people say things that are difficult to characterize in terms of truth, such as “I promise to pay you five hundred dollars.” or “I pronounce you man and wife.” The intuition is that these performative utterances are actions in their own right, and it does not make sense to describe them as true or false. Speech act theorists note that a promise is an act that immediately incurs an obligation (typically, the obligation is simply to deliver on the promise). They also note that saying “I pronounce you man and wife.” does not automatically result in a change in the legal status of the people addressed, but that it can have that effect when it is uttered by an officiant who has the appropriate legal and social status.
At a more mundane level, speech acts matter because they help us to understand what is really going on when people say, for example: “Could you pass the salt?” This utterance always has the syntactic form of a question, but in many contexts the speech act that it implements is obviously a polite request. There is a great deal of subtlety in what the speech act corresponding to an utterance can be, but what matters for practical dialog systems is the ability to recognize that utterances may not be exactly what they seem and to be aware of a few standard patterns, such as the use of questions to stand for commands, the use of objectively unnecessary, informative statements to stand for requests (e.g., using “You are blocking my view.” rather than “Get out of my eyeline.”), and so on. A customer service dialog system would probably do well to be able to recognize most of the patterns that people use to implement the speech act of complaining, for example.
Common speech acts include informing, reminding, inviting, complaining, refusing, accepting, requesting, and commanding. In artificial intelligence, we often describe actions in terms of their preconditions and their effects. Forexample, in order for bank robbers to pack their loot into a getaway van (an effect), they need to satisfy a range of preconditions, such as ensuring that the doors of the getaway van are open, the van has been backed up to the doors of the vault, both the loot and the loaders are available and in the right place, and so on. In order for the effect of the van doors being opened, the preconditions for that will in turn need to be satisfied: better not forget the key to the van doors! If they fail to satisfy a crucial precondition at any stage, or fail to sequence the operations properly, the whole operation will fail. It is useless to have the key to the van doors if the person carrying them is locked inside the van and cannot open the doors from the inside. And you have to worry about preconditions that may not have figured in your planning, such as the van turning out not to be empty or, worse, to be full of police. However, if you do it right, representing actions in terms of preconditions and effects can allow artificial intelligence software to work out solutions to problems that call for planning of sequences of actions.
This kind of reasoning can work with speech acts as well as physical acts. You can represent the speech act of informing in terms of its preconditions and effects. A precondition of informing someone that a concert is on Friday is actually to know that the concert is on Friday, and the effect is that the other person also knows that. A second precondition, at least if we want a fully fledged act of informing, is that the other person did not previously know when the concert was. If they did, we would probably want to say that the speech act was in fact reminding rather than informing. Once you have a set of speech acts, along with a carefully worked-out understanding of their preconditions and effects, you can begin to piece together sequences of speech acts (and indeed other acts) that result in particular desirable effects in the world.
In stating “If you need anything, I’m Jill.”, Demetri Martin’s shop assistant was helping him out by offering a piece of information (her name) that is a precondition for an action that he might reasonably want to execute: namely, calling her if he wanted further advice. But Martin insists on reinterpreting Jill’s remark as a free-floating act of information giving, forcing his audience to notice the weird alternative meaning that he had in mind.
In order to function in dialog, automated systems often use a level of explicit representation in which speech acts are represented in terms of preconditions and effects. Logically, this need not be the case. Indeed, most of you have been effortlessly navigating your way through dialogs without thinking much about preconditions and effects, so it might one day be possible to build systems that do things in the same way. For now, speech acts are useful because they give us a way of connecting choices about what to say with the real-world results that we would like our dialogs to achieve.
The philosopher H. Paul Grice had another take on dialog, similar to but not exactly the same as the speech act idea. He noticed that there are patterns in conversation that can be explained if we think about dialog conventions and pay attention to what happens when these conventions are apparently violated. One of Grice’s main interests was the phenomenon of nonliteral language, which he hoped to explain.
Typically, people who engage in conversation obey what Grice (1975) referred to as the four maxims (or rules) of conversation. All of them are based on the cooperative principle: this is the assumption that speakers are trying to contribute to the purposes of the conversation. This is a safe working assumption, because if the speakers are not trying to do this, the conversation is more or less certain to go wrong. So, listeners can use the cooperative principle to infer what a speaker is really getting at, or to fill in details that were left out.
The first Gricean maxim is called Quantity. Quantity asserts that speakers will be exactly as informative as required for the purposes of the current conversational exchange. You should not be less informative than the situation requires. Thus, when someone replies to “How many blackboard erasers do you have?” with the answer “Two.”, the conversation partner knows that it means exactly two. If the person had three erasers, that is the more cooperative answer and should have been provided. If you have three, it is not a lie to say that you have two, but it is less informative than you could have been. As far as you know, your interlocutor might actually have a need for three erasers, in which case saying “two” is seriously uncooperative.
A second aspect of Quantity is that you should not be more informative than the situation requires. If you pass someone you know slightly on the way to class and they ask “How’s it going?” the answer “It’s complicated. Yesterday I was sick and stayed home all day, which was bad, but I did manage to do some scrapbooking …” is probably more than they were looking for. This is a violation of the maxim of Quantity, because the usual response would be conventional and largely content free. For midwestern Americans, who are taught to be positive, the expected reponse might be “Great, how about you?”; or for the British, whose culture encourages them to express stoicism in the face of life’s irritations, it could be “Oh, you know, mustn’t grumble.” By providing a nonexpected response, one that violates the maxim of quantity, you would be inviting an escalation of the seriousness of the exchange. This is a perfectly reasonable social move, and might get you an invitation to go to coffee, but it is a disruption in the flow of the dialog. Grice’s observation is that when the maxim of Quantity is violated, the hearer can and does interpret this as a signal that something unusual is happening.
The second maxim, similar to Quantity, is Quality. This states that people typically make statements that they know to be true and that the hearer can accept that they have evidence for. When someone says “Everyone is counting on you to get the contract.” and I reply “Yes, thanks, that really helps take the pressure off.”, I am saying something that seems very unlikely to be true. This is a violation of Quality, since the knowledge that people are counting on me will, if anything, increase the pressure for success. The violation is supposed to lead the hearer to infer that I am not actually thanking them for being supportive, but instead chiding them for being insensitively pushy.
A third Gricean maxim is Relevance. Contributions are expected to be relevant to the conversation. If it looks as though they are not, maybe the hearer is supposed to be doing some inference. Thus, if you ask “Does Clara have a boyfriend?” and I reply “Well, I never see her around on Friday or Saturday nights any more.”, I am not exactly saying “yes”. However, by making a remark that initially appears to be irrelevant, I am inviting you to infer that she does have an ongoing relationship, since this is a probable cause – perhaps, in my mind, the only plausible cause – for Clara not being available to hang out with me.
The final Gricean maxim that we will cover is called Manner. It says that contributions are expected to avoid obscurity, to avoid ambiguity, to be appropriately brief (that is, to avoid rambling on when they do not have to), and to be presented in a clear and orderly way. Violations of Manner trigger inference in much the same way as the other three maxims we have presented.
For example, if someone says “It is possible that the weather will be rainy.”, this is a simple and direct statement, and most hearers take it to mean that there is a reasonably high probability that it will rain. If, however, someone instead says “It is not impossible that the weather will be rainy.”, the hearer notes the (minor) violation of the maxim of Manner (the double negation is more complicated than the positive form) and infers that the speaker is warning against a rather more remote possibility of rain. In the same way, if someone is asked “Did you hear Doctor Brew’s keynote address?” and the response is the verbose and obscure “Well, he came to the podium, moved his lips, exercised his larynx, and a series of words came out.”, the questioner will infer from the violation of Manner (because the answer is much more obscure, verbose, and weird than the more obvious response of just saying “yes”) that something nonstandard is intended, and will conclude that the speaker’s true intent is to indicate, indirectly, a general dissatisfaction with the keynote.
Grice’s maxims are all about inference. The examples given above are flashy ones in which the role of inference is made very obvious. Computer systems definitely need to use inference in order to keep track of what is going on in natural dialogs, and the need arises even in ordinary conversations. For practical purposes, speech acts and dialog moves cover most of what is needed, largely because real dialog systems currently get deployed in settings such as airline booking and traffic advice. In human–human dialogs, we typically notice the Gricean maxims when they are violated, and trigger the inference that a secondary meaning is intended. This happens because we know that the dialog partner is smart enough to avoid violations, so can assume that any violations are intentional.
We can see this even at an early age. One of the authors encountered a very early deployment of smart dialog tactics when a small child produced the following utterance: “I want something that is crunchy.” The purpose of this vague request was not immediately evident until it was clarified to: “I want something that is crunchy and (points in direction of cookie jar) over there.” We think that the child had noticed that direct requests for cookies were less successful than interactions in which the parent was the first to mention them, hence chose to start with an utterance that was intentionally obscure. This worked, once the parent had stopped laughing.
In human–computer dialogs, by contrast, since we cannot assume that the computer is clever enough to avoid unintentional violations, it is safer to assume that everything the computer says is intended to be taken at face value. If dialog systems ever get as good at managing dialog as Hal was in 2001, we will need to revise this view, but for the moment it is correct. In the same way, until we have strong reason to believe otherwise, when we speak to a computer-based dialog system, it is probably safe to assume that it will be taking what we say at face value and not searching for hidden meanings.
Since real-world dialog systems are not as flexible as human speakers, and we still want them to perform well, it is useful to know the vocabulary that system designers use to describe the intended purpose of a particular system. This is helpful for establishing feasibility, setting realistic expectations for quality, and making plans for how much effort will be needed. When we try to make a precise description of the scenario under which the system is expected to perform well, we are carrying out an activity called task analysis. It is also an important part of task analysis to be clear about the scenarios under which the system is not required to perform well. This helps guard against over-engineering, which is what happens when a system is more elaborate than is really necessary. Looking back at Figure 6.1, Let’s Go can be described as a mixed-initiative, task-oriented dialog system working in the limited domain of bus timetable advice. But what does this mean?
Dialog systems can be system-initiative, user-initiative, or mixed-initiative systems. These categories are about the extent to which the system or the user takes charge and guides the conversation in a particular direction. As users, we would prefer mixed-initiative systems, in which both conversational participants can take the lead as needed, because that is what we are used to from people. As we will see in the next section, Eliza was an early dialog system that is a user-initiative system.
Let’s Go is a mixed-initiative system because both participants (caller and system) take initiative. The caller takes control at the beginning of the interaction, then again by asking for a later bus, and finally when requesting the return journey. Otherwise, the system keeps control, and carefully prompts the user to provide particular pieces of information. Many telephone-based systems keep an even tighter rein on the conversation than Let’s Go does; it would not have been surprising, for example, if the system had explicitly asked “Is that OK?” immediately after telling the user about each bus departure, thereby taking more of the initiative.
Dialog systems can be designed to work with the user in carrying out a task or can fulfill some other purpose such as selling a product, telling a story, or making the user laugh. Most research systems are explicitly task oriented. This is helpful, because it allows the system to make sane assumptions about what the user’s goals are and then to focus the dialog on these assumed goals, as Let’s Go did. Within the general frame of task-oriented systems, there is room for more and less ambitious tasks, requiring greater or lesser flexibility on the part of the system. Less ambitious would be a system designed to obtain a 10-digit phone number with area code; more ambitious a system that engages the user in conversation about a wide range of possible entertainment options, with the aim of recommending one that the user will like.
It is also helpful for the system designer to know ahead of time that the user is trying to carry out a particular task, such as getting travel information, because it can then make task-specific assumptions about what the user knows, wants, and believes. The set-up of Let’s Go assumes that the user is trying to travel somewhere by bus and needs timetable information in order to do so. Dialog scientists call this a limited domain. Nobody really expects Let’s Go to be any good at general conversation or to be able to give investment advice; that is not its role.
Limited-domain settings can be contrasted with general settings, in which less can safely be assumed about user goals. Hal the computer definitely has general-purpose dialog skills that operate across many possible domains, using general knowledge and extremely sophisticated reasoning. This is well beyond current technology.
Let’s Go is a good example of a modern dialog system very useful for modeling human conversation and fulfilling a task. But it is also too complicated to be explained fully in this textbook. We want you to have the full picture on what is involved in making a simple working system, so we are going to go back in time and look at a very early dialog system, called Eliza. You can find several versions of Eliza by searching around online. The original Eliza was made in 1966 and was the first well-known program of its kind. Joseph Weizenbaum, Eliza’s creator, only wanted to show that simple principles could produce a reasonably good dialog participant. But the idea caught the imagination of researchers in artificial intelligence, and Eliza became very famous.
Eliza is a simple limited-domain dialog system; such systems are often referred to as chatbots or chatterbots. It is based on a script that allows it to pretend to be a Rogerian nondirective psychotherapist. Weizenbaum chose the therapeutic setting because it is one of the few situations in which a conversational participant can get away without specific knowledge of what is being discussed. The primary role of the nondirective therapist is simply to keep the conversation going, allowing the patient to talk out his or her concerns. Eliza takes on this role, and turns out to be able to handle it well. Figure 6.2 shows part of a dialog that Eliza might have with a familiar mythological figure. The transcript of this dialog is in Figure 6.3.
It is tremendously important to the success of Eliza that it is emulating a “nondirective” psychotherapist. This is what allows the program to be so simple, because a nondirective therapist can usually get away with simply reflecting back things that the patient has said. A proper Freudian psychotherapist would need to have a more complex way of responding to King Oedipus and would need to provide a little more depth in the responses.
Basically, the Eliza program only reacts to what the user says (i.e., it is user-initiative). It watches for keywords such as “father” and “mother”, and churns out items from a set of preplanned responses. Some of the things that it says, such as “Tell me more about your family.”, are planned out in every detail and never changed. Others are a little more flexible: the system memorizes what the user says, changes it a little, and reflects some of the material back. Thus, it says “Why do you tell me that you were adopted by your stepfather now?” because the user has said “I was adopted by my stepfather.” By reflecting back some of the material, it is increasing the chance that its contributions will conform to the Gricean maxim of providing relevant comments.
In this case, the words “I” and “my” have been converted into “you” and “your” (as well as “was” becoming “were”). While the placement of the word “now” is a little odd, this response works well. Later on, the system says “Perhaps I already know you were giving I your life history.”, which is not quite right, because the routine that switches the personal pronouns made a small mistake. It would have been fine if the system had said “Perhaps I already know you were giving me your life history.” In general, using the correct pronouns and understanding what the user is referring to with their pronouns (e.g., “I want help, and I want it now”) is a challenge even today.
By carefully observing the behavior of the system, and making up new sentences that probe its capabilities, it is possible to find out much more about what the program must be doing. It clearly knows some words, has a store of templates for semirelevant responses, and remembers some of the things that the user says to it. The final response –“Does that have anything to do with the fact that your father is king of thebes?” – could easily be mistaken for psychological insight, but, as you will see if you read the Under the Hood section on Eliza, this is far from the case.
Figure 6.2 Screenshot of an ELIZA implementation ( http://chayden.net/eliza/Eliza.html)
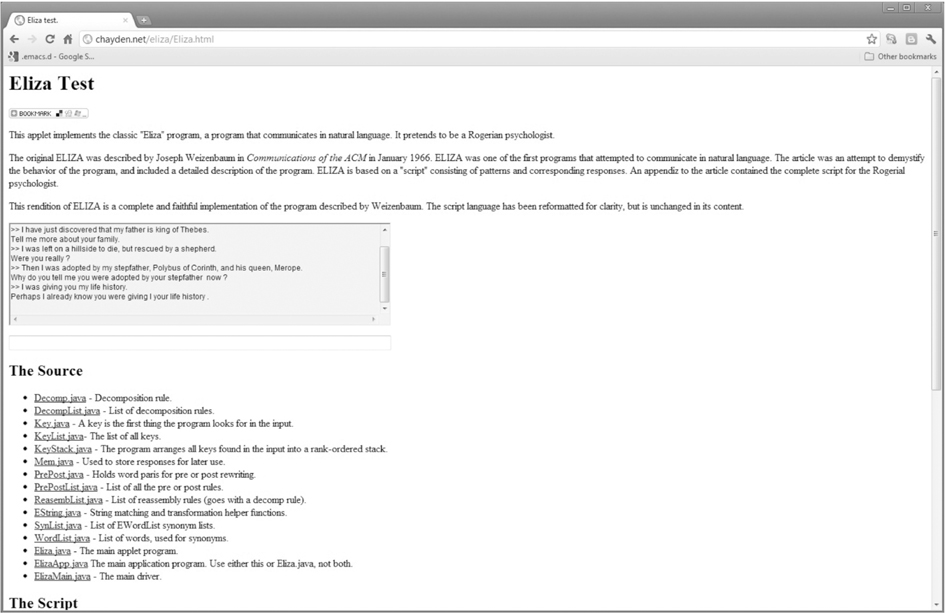
Figure 6.3 Transcript of Eliza’s dialog with a figure from mythology

Part of the reason conversations with Eliza sometimes appear to succeed is that its conversational partners are very tolerant and adaptable. This is not surprising, because everyday dialog with a human partner also calls for flexibility and an ability to smooth over potential confusions. It is perfectly possible for human dialog partners to carry on a conversation in a noisy environment where almost every word is liable to be misheard, and the same kind of ability to keep going in the face of error operates at the level of meaning. When we talk with a human being, we are continually making sensible guesses and assumptions in order to fill in the details we need. This allows us to follow the conversation and chip in with our own contributions. It is natural to treat Eliza in the same way, generating the guesses and assumptions that are needed in order to make the conversation make sense. Eliza’s conversation partner ends up actively working to maintain the illusion that this is a genuine conversation. Since Eliza has no real understanding, it will sooner or later say spectacularly unlikely and inappropriate things, and the illusion will shatter, but this can take a surprisingly long time if circumstances are favorable.
There is at least one well-attested account of a human being being misled by an Eliza-like program. Figure 6.4 is a story told to the Stanford Humanities Review by Daniel Bobrow, who is one of the pioneers of artificial intelligence. (Some historical pointers: PDP-1 was an early type of computer; LISP is a programming language; Weizenbaum was the creator of Eliza; teletype was a typewriter used to type messages over a communication channel; and being snotty, we hope, is obvious.)
Eliza is important for two reasons. First, it works reasonably well using simple means, and this can be useful if your application calls for a straightforward but limited way of creating the illusion of an intelligent being at the other end of the wire. Secondly, it draws attention to the fact that human beings are tolerant dialog partners, who are prepared to cut their interlocutors a great deal of slack for the sake of keeping the conversation going. Guesses and assumptions are just a built-in part of the process. This is obvious once you notice it, and really has nothing to do with computers, but it is something that everyone should remember. For example, eyewitness testimonies can be flawed because the witness cannot always tell the difference between the details they actually saw and the ones they used their common sense and world knowledge to fill in. In the same way, it is sometimes hard to tell the difference between what your conversation partner actually said and what you filled in using common sense, world knowledge, and awareness of dialog conventions. If you want to be more certain, record the conversation.
Figure 6.4 VP’s dialog with Eliza, told by Daniel Bobrow

Eliza produces its output in written form, on the screen. This is not what we usually do as humans, although we can. For us it is more natural to produce the dialog in spoken form. Programs for text-to-speech synthesis are available for most modern computers (see Section 1.4.5) and can, for example, play back the text of a document. It would be quite easy to make Eliza speak by hooking into this software.
Unfortunately, this may not be enough because, in dialog, the speakers must do more than speak the right words; they must also speak them in the right way, with appropriate emphasis and intonation. We know this already: the scripts of plays often have stage directions, and even when they do not, actors are expected to perform the words in a way that is expressive of the underlying intentions of the characters. The only way they can do this is to understand those intentions, and to imagine how a person with those intentions would speak the words.
In practice, what this means is that the core dialog system needs to produce more than just the words themselves, and pass them along to the speech synthesizer. There are standard markup languages called SSML and voice XML, both of which aim to do for speech what HTML does for well-laid-out text on the web (see Under the Hood 6 in Chapter 4). The idea is that instead of saying where you want paragraphs, line breaks, bold fonts, and so on, as you would with HTML, you instead provide tags that specify emphasis, timing, and pitch at a more or less detailed level. This field is in its infancy; more work is needed on finding good ways to describe the ebb and flow of expressive spoken language, and then yet further research will be needed to make the connections between the top-level plans and the ways in which they ought to be expressed in dialog.
For now, dialog systems are probably going to sound flatter and more robotic than their human counterparts. This may in fact be helpful in managing expectations, because a very natural sound might draw users into unreasonable expectations about what the system is really able to do.
If we want to make dialog systems better, we have to devise methods for making sure that we can measure their performance and work out which features of the systems contribute to success.
In principle, we know exactly how to evaluate the performance of a dialog system. Suppose that its job is to help customers make airline bookings. All that we have to do is to monitor the conversations it has, measuring how often it succeeds in booking a flight for the customer, how often the customer hangs up in frustration, and perhaps even the number of times it lures a gullible customer into paying extra money for a first-class seat. This is exactly what well-organized businesses do with human customer service representatives. (In call centers, the somewhat questionable activity of guiding customers to high-profit additional items is called upselling, and it is exceptionally important in determining your commission.) Unfortunately, this style of evaluation will not work until the system is good enough to be worth deploying in the first place, so it is not useful for the initial development. Until the system is good enough, users will simply be unable to interact with it in any useful way. In particular, until the system is minimally capable of holding up its own end of the conversation, users will be unable to have a dialog with it at all, and no progress will be made in improving it.
In response to this conundrum, researchers have developed two approaches. Both approaches temporarily give up on the idea of human–computer dialog, but try to collect information that will be useful in shaping the design of the final system. The first of these approaches replaces human–computer dialog with a carefully disguised human–human dialog. As far as the user is concerned, the system seems like a computer, but actually, behind the scenes, it is being driven by a human being who takes on the role of the computer. This approach is called the Wizard of Oz simulation, because, like the Wizard of Oz in the movie, it relies on using a trick to maintain the illusion of magic.
The second approach replaces the human–computer dialog with a computer–computer dialog. Here there are two computer systems. The main system is a straightforward dialog system, one that tries to be flexible and efficient in the ways we have discussed earlier in the chapter. In addition, there is a second computer system that is designed to take on the role of the user. This is similar to an idea that has been used by chess computers in which the system learns by playing a large number of simulated games against itself. In just the same way, two linked dialog systems can rapidly simulate a large number of dialogs and work out which strategies will work best in achieving the goals of the system. Of course, this only works if the simulated dialogs are sufficiently similar to what the system will encounter with real, live users.
A third approach to evaluation is to give up on the idea of doing fully general dialog systems, and to focus instead on dialogs that take place in well-understood and highly structured domains. One such domain is teaching. Teaching, especially individual or small-group teaching, can definitely be seen as a dialog, but it is one where the roles are very we ll defined and formal. The teacher is trying to get the student to think in particular ways and may also be trying to evaluate the student’s level of knowledge. Typically, the teacher asks carefully targeted questions, then pays attention to the student’s answers, looking for evidence that the student is thinking in the expected ways, or that particular expected misconceptions have arisen. This kind of tutorial dialog is highly structured and has attracted a lot of research, both from people who want to automate it and from those who want to help human teachers develop effective ways of getting ideas across.
Dialog crosses the boundary between language and action. In order to play well with others in dialog, computers need not only to use language well, but also to understand the mental and social worlds of their interlocutors. Current dialog systems work well when the designers manage to arrange for a situation in which the system can get away with limited linguistic and social skills, and poorly when the situation calls for real flexibility. Realistically, the near future is likely to bring continued clever exploitations of the niches in which limited dialog skills are enough, along with improvements in surface features such as vocabulary choice and the naturalness of spoken responses. Major improvements in flexibility and responsiveness will only come, however, if researchers are able to crack some of the very hard problems of giving computers common sense and the ability to reason effectively with everyday knowledge.
Your working assumption should probably be that any impressive-seeming dialog system is probably more limited than it seems. Our guess is that a careful and systematic effort to probe such a system will reveal the limitations, just as it did with Eliza. Alan Turing, a British mathematician and early computer scientist, turned this idea around. Imagine that you find yourself in a (written medium) chat conversation, with a partner who, unknown to you, is actually a computer, and that the conversation is so natural that you really cannot be sure whether or not you are dealing with a machine. If a machine can do that, says Turing, perhaps we ought to agree that it has met all the important criteria for intelligence. This idea struck a chord among philosophers and many others, and contributed much to the development of the academic field of artificial intelligence. Turing’s successors called his imaginary experiment the Turing Test.
The Loebner Prize is a competition for chatbots, where the set-up is essentially Turing’s, and the designer of a successful program could win a large monetary prize. It has been suggested that any winning program ought to be allowed to keep the money, and make its own decisions about how to spend it, since it would, by definition, be intelligent enough to do so. This is a joke, because a special-purpose system designed to carry on a good dialog would not necessarily have any claim to general intelligence. However, for practical dialog needs, there is nothing wrong with a well-judged special-purpose system. It is certainly realistic to hope that there will be limited-domain dialog systems that are appropriately responsive, sound good, work well in their niche, and offer an improvement in terms of consistency and cost-effectiveness over what could be done before they existed.
After reading the chapter, you should be able to:
Further reading
H.L. Austin’s book How to do things with words (Austin, 1975) is an excellent introduction to the idea that dialog can be thought of in terms of speech acts. This book sparked a series of major contributions to the philosophy of language, including H. Paul Grice’s Studies in the Way of Words (Grice, 1989), which includes detailed discussion of the conversational maxims discussed in this chapter.
In the world of technology and computer-supported cooperative work. Terry Winograd and Fernando Flores develop the idea of “tools for conversation” in their book Understanding Computers and Cognition: A New Foundation for Design (Winograd and Flores, 1987). This is a remarkable and thought-provoking book that does not fit into any known academic discipline, but is full of interesting and potentially very useful ideas. Their framework for thinking about conversation has found its way, in simplified form, into widely used software for email and calendaring.
Turing (1950) introduces the idea of the Turing Test and, despite being over 60 years old, is still fresh and challenging today, as well as beautifully written and full of sly humor.
Jurafsky and Martin (2009) is a good review of modern dialog systems. In Jurafsky and Martin (2000), the corresponding chapter is 19, but the one from the second edition is a complete rewrite and has a great deal of extra material. The quote from 2001 at the head of this chapter is also used by Jurafsky and Martin, as a general illustration of what computers might be able to do with speech and language. Weizenbaum, the creator of Eliza (Weizenbaum, 1983), was sufficiently shocked by the sensation caused by Eliza to write Computer Power and Human Reason: From Judgment to Calculation (Weizenbaum, 1976). A set of dialogs between Eliza and other human and computer entities, including the interaction with the anonymous VP of BBN, can be found at http://www.stanford.edu/group/SHR/4-2/text/dialogues.html.
The dialog moves discussed are simplified versions of those discussed in a review paper by Staffan Larsson (Larsson, 1998).