Figure 7.1 Some overconfident translations into English

This chapter is about technology for automatic translation from one human language to another. This is an area where the gap between (science) fiction and (science) reality is especially large. In Star Trek, the crew uses a Universal Translator that provides instantaneous speech-to-speech translation for almost all alien languages. Sometimes there is a short pause while the Universal Translator adapts to a particularly challenging language, and very occasionally the system proves ineffective, but most of the time everything simply works. In The Hitchhiker’s Guide to the Galaxy, Douglas Adams’ affectionate parody of the conventions of science fiction, the same effect is achieved when Arthur Dent puts a Babel Fish in his ear. In Matt Groening’s Futurama (another parody), one of the characters invents a Universal Translator that translates everything into French (in Futurama, nobody speaks French any more, and almost everyone knows standard English anyway, so this device, while impressive, has no practical value whatsoever). In the real world however, instantaneous general-purpose speech-to-speech translation is still a far-off research goal, so this chapter will focus on simpler uses of translation.
Before discussing uses of translation, it is useful to define the concept and introduce some terms. Translation is the process of moving text or speech from one human language to another, while preserving the intended message. We will be returning to the question of what exactly is meant by preserving the intended message throughout the chapter. For the moment, please accept the idea at its intuitive face value. We call the language that the translation starts from the source language and the language that it ends up in the target language. We say that two words, one from the source language, one from the target language, are translation equivalents if they convey the same meaning in context. The same idea applies to pairs of phrases and sentences.
Figure 7.1 Some overconfident translations into English
Figure 7.1 contains some examples of difficulties that can arise if you are not careful to check whether a translation is saying the right thing. If you are ever asked to put up a sign in a language that you do not fully understand, remember these examples, and get the content checked.
It is unclear what happened with the first one. Perhaps the source text was about some kind of special ice-cream, and the adjective that described the ice-cream was mistranslated. Or perhaps the word “fat” was omitted, and the translation should have been “no-fat ice cream”. The second one is presumably trying to describe a doctor who specializes in women’s and other diseases, but the possessive marker is omitted, making the sentence into an unnecessary suggestion that women are a kind of disease. The third one happens because the sense of “have children” as “give birth” was not salient in the mind of the person who created the sign. The fourth one is just a poor word choice: “valuables” is the word that the translator was searching for, and “values” is unintentionally funny. The French word “valeurs” means “values” and the French phrase “valeurs familiales” is used in much the same way as “family values” is in English. Of course, this kind of ambiguity can also happen when English native speakers write notices in a hurry and do not check them carefully.
The last three are a little different, because they are failures of the process of translation. Presumably Wikipedia was used to find an article about some foodstuff, but the amateur translator mistook the name of the website for the name of the foodstuff. We have a great deal of sympathy for the translator here, because “Wikipedia” does feel like a good name for a foodstuff, possibly some kind of seafood with legs. For the dining hall, the graphic artist must have thought that the string “Translate server error” actually was the translation.
We chose the examples in Figure 7.1 because we hope that they are funny. But in other settings, translation errors can have serious consequences. This happened when a young male patient was brought into a Florida hospital’s emergency room in a coma. His mother and girlfriend, speaking in Spanish, talked to the non-Spanish-speaking emergency room staff. They used the word “intoxicado”, which can mean several things, including “nauseous”. Because the emergency room staff were not professional interpreters, they thought that “intoxicado” must mean the same as the English “intoxicated” and treated him on the assumption that he was under the influence of drugs or alcohol. The patient was eventually diagnosed with a brain aneurysm and became quadriplegic. This case is famous, because it led to a lawsuit and drew attention to the principle that hospitals, courts, and other institutions that work with the public should plan for the needs of a multilingual population and provide the necessary translation and interpretation services. This is an issue of basic fairness, public safety, and perhaps also civil rights.
In web search and information retrieval, the user can be thought of as having an information need (Section 4.3.1). In the same way, a potential user of translation technology can be thought of as having a translation need. If you have taken comparative literature classes at high school or college, you will have encountered translations into English of foreign-language poetry and novels. A publisher who wants to make a new English version of a novel by José Saramago has a translation need. This need is far beyond the capabilities of any present-day automatic system, because for this purpose, a good translation needs to be a literary work in its own right. As well as getting across the content, it must capture the “feel” of the original writing. The only way to do this is to employ a human translator who has excellent literary skills in both English and Portuguese. Because there are so many English-speaking readers in the world, and the author is a Nobel prize winner, the publisher can expect a good return on investment in expert help. Nobody would expect a machine-generated translation to be good enough for this purpose, although it would be cheap.
Another quite demanding translation need is that of a scholar needing to understand an academic paper written in a foreign language. Here, the scholar does not care much about the “feel” of the article, but will want to be sure about the arguments that are being made, the conclusions that are being drawn, and the evidence that is being used to support these conclusions. To do this well, even if the paper is in your native language, you need to have some training in the relevant academic field or fields. Academic papers are designed to be read by informed experts, so if the paper is on linguistics, what you are looking for is a translator who is expert enough in linguistics to be able to understand and accurately translate the arguments in the text. A translator who is a specialist in translating business documents will almost certainly struggle to make a useful translation of a linguistics paper. We should not expect a machine translation system to be any better at meeting this specialized need.
In Chapters 2 and 4, we described technology that supports the everyday scholarly activities of information gathering and writing. Each one of you already knows much about these activities. The role of the computer is to help out with the aspects of the process that it does well, and to keep out of the way when the human writer knows better. Translation is a little different, because it is usually done by trained experts rather than the general public. Professional translators sometimes worry that machines are going to take over their role, or that free web-based services will lead to big changes in the market for their skills. These worries are reasonable, since all knowledge workers will need to adapt as technology changes, but the reality is that professional translators are still going to be required in future. Unless you have had an internship with a translation company, you probably do not know as much about the market for translation as you do about the activities of writing and information gathering. In this chapter, as well as explaining some of the technology, we will go into detail about the business needs for translation and the changes that are resulting from the easy availability of free online translation.
From this perspective, literary translations are interesting to think about when we are trying to understand the process of translation, but are not the first place to look for practically important uses of translation technology. For that, we need to focus on more everyday translation needs. For example, if you are considering buying a new mobile phone, but the model you want is not yet available in your country, you may want to read customer reviews from another market, perhaps ones written in a language you do not know well.
This is a translation need, but literary quality is no longer a relevant criterion. You want to know about battery life, quality of the input devices, usability of the built-in software, and so on. (See Chapter 5 on classifying documents for other ways in which computers can assist in this.) If there are points in the review that you can understand, errors may not matter. The German text says that the phone is a little slimmer (schmaler) than the iPhone, and the English version is “The Magic is smaller, and therefore slightly better in the hand”. A human translator might write this as “The Magic is slimmer and therefore more pleasant to handle”, but the rather literal automatic translation serves the purpose perfectly well, even though, strictly speaking, it is inaccurate. Free web-based translation (specifically, Google Translate, in July 2009) is quite adequate for this translation need.
A third type of translation need turns up in large multinational organizations such as electronics companies. For them, there is often a legal requirement that the instruction manuals and other documentation be available in the native language of the user. Here, accuracy obviously matters, but fine points of literary style are not important. Indeed, if there is a choice between elegant literary phrasing and an uglier version using simple and direct language, the latter is preferable. For this translation need, there is an especially good choice of translation technology, called example-based translation. This relies on the fact that most of the sentences in an instruction manual are either the same as or very similar to sentences found somewhere in a collection of previously translated manuals. Electronics companies keep copies of all the manuals that they produce, as well as the translations. The software that does this is called a translation memory. The first step is for the human translator to use the search capability of the translation memory to find relevant sentences that have already been translated. These previously translated sentences can be used as a basis for the translation of the new sentence. For example, suppose that the sentence to be translated into German is:
and we have the following example sentences already translated:
Then it should not be too hard to piece together the underlined fragments to get:
The simplest way of doing this is to write a program that uses search technology to find the best matching sentences, leaving to a human the task of working out how to put the fragments together. Alternatively, a fairly simple program could get most of the way. There would need to be a special routine to make sure that the name of the product “FX380B” was transferred appropriately, but the rest is pretty straightforward. The output should be checked by a human being, to make sure that the legal requirement for adequate documentation has been met. Once again, the standards that apply depend on the nature of the documentation need. The documentation for a medical x-ray machine that is going to be used by a multilingual staff, and that could hurt people if it is used incorrectly, needs to be excellent in all the relevant languages. The translations of the documentation for a mobile phone are not so safety-critical, so it may be acceptable to be a little less careful.
The important lesson of this section is that the translation technology that is used should depend on the details of the translation need, not just on some abstract notion of what counts as a good translation.
For fun, let us return to the idea of translating Shakespeare. Figures 7.2, 7.3, 7.4, and 7.5 contain a range of versions of Shakespeare’s Sonnet 29. One is the original Shakespeare, one a brilliant translation into German by the twentieth-century poet Stefan George. Then there are two machine translations from English to German, and a back-translation by Google Translate of George’s German into English.
Figure 7.2 Shakespeare’s Sonnet 29 in the original

Figure 7.3 Shakespeare’s Sonnet 29 as translated by Stefan George

Figure 7.4 Google’s translation of Sonnet 29

Figure 7.5 Google’s translation of Stefan George’s version

When translating poetry, it is important to do more than just get the meaning across: you have to also aim for a similar overall impression. Stefan George’s translation is almost line for line, and uses the same rhyme scheme as Shakespeare. “Deaf heaven” in Shakespeare’s third line finishes up as “tauben himmel” in George’s fourth, and the “rich in hope” in Shakespeare’s fifth becomes “von hoffnung voll” in George’s sixth. The crunchy contrast of “with what I most enjoy contented least” turns into the alliterative “Dess mindest froh was meist mich freuen soll”.
German and English are quite closely related – words like “king” and “König” or “earth” and “Erde” come from the same original source and mean the same. Linguists call these corresponding words cognates. Cognates sometimes make it possible to work out which lines go with which even if you don’t speak German well enough to read the text in detail.
Figures 7.4 and 7.5 show what happens with automatic translation. In Google’s German, the word “beweep” has defeated the system, and simply been transferred over unchanged. Also, the fourth line translates the English word “curse” as a noun “Fluch” when it should be a verb. Because the verb is missing from the German, the translation engine has a hard time finding an acceptable way of fitting in the material that should have been attached to it, and the result is very messy.
In Google’s English (which is a back-translation of George’s good German), there are lots of good word-for-word translations. But “los” ( = “fate”) has been “translated” in the same way that “beweep” was: the system has given up. The term “human-looking” is not quite right for “Menschenblick”: Shakespeare had “men’s eyes”, and “human view” is probably what a modern writer would produce. Also, the “For” in “For the deaf sky hopeless cry” should be “To”, thus rendering the final line as “To the deaf sky hopelessly cry”.
Overall, the conclusion regarding poetical translation has to be a qualified negative. Current systems are designed for quite a different translation need. Certainly, the output is not good poetry, or indeed particularly convincing English, but there might be circumstances in which knowing what the poem is about has some usefulness. For example, it comes through clearly that Shakespeare’s sensitive protagonist is not having an especially good time. And, more seriously, a human translator might be able to use the machine-translated output as a starting point for revisions.
Figure 7.6 shows a diagram that explains one of the main tradeoffs in designing translation systems. At the bottom corners of the triangle in Figure 7.6 are the source and target languages. The captions in the body of the triangle indicate possible relationships between source and target language. If we are lucky, the words and concepts in the target language will match those in the source language, and direct word-for-word translation will just about work. In that case, there is no need to design a complex system, or to use linguistically sophisticated representations.
Figure 7.6 The translation triangle
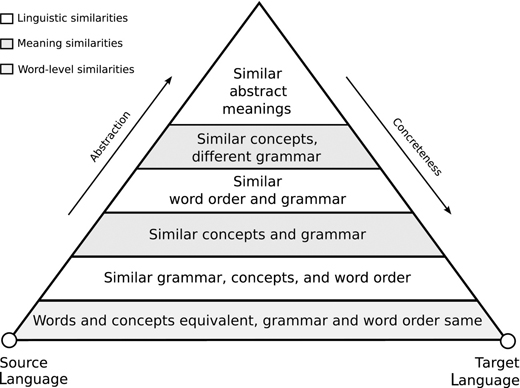
The example-based translation that we discussed in Section 7.2.2 is a method that works directly with the words of the sentence, not analyzing them in any deep way. The translation triangle illustrates the fact that if you work at the level of words, source and target languages are quite far apart. For some uses, such as example-based methods for highly stereotyped and repetitious texts, such direct approaches to translation work well enough, but broadly speaking they are insufficient for more general tasks.
The labels on the body of the triangle represent various different kinds of similarities and differences that might turn up in translation. There can be differences in the linguistic rules used by the two languages and also differences in the way in which the languages map concepts onto words. If you are prepared to do work to produce abstract representations that reconcile these differences, you can make translation easier. The captions are placed according to our judgment of how easy it would be for an MT system to create them, with the ones that would take more work nearer the top.
The arrow labeled Abstraction points in the direction of increasing abstraction, as well as increasing distance from the specifics of the source and target languages. The higher you go, the fewer the differences between source and target languages, and the easier the task of converting the source language representation into the target language representation. This is represented by the fact that the sides of the triangle get closer as we go up. The corresponding arrow, labeled Concreteness, points in the direction of increasing concreteness (therefore, also, in the direction of decreasing abstraction).
However, although translation itself gets easier as the representation becomes more abstract, the task of moving from the words of the source language to a more abstract representation gets harder as the representation becomes more abstract, as does the task of moving from the abstract representation of the target language back down to the words of the target language. This is represented by the fact that the distance between the representations and the bottom of the triangle grows larger as we go up. Unless the consumers of your translations are highly sophisticated linguists, it will not do to give them abstract representations: they need words.
At the apex of the translation triangle we would have a so-called interlingua. At this point there would be no difference between the source and target language representations. If you could do full linguistic analysis and get all the way to a common language-neutral meaning, there would be no translation work to do.
Thus, an interlingua is a representation that can be reached by analyzing the source language, and that can then be used, unchanged, to generate the equivalent sentence in the target language. If this could be achieved, it would have the tremendous advantage that in order to add a new language (e.g., Hungarian) to our translation system we would only need to build a Hungarian-to-interlingua module and an interlingua-to-Hungarian module. Once that was done, we could translate to or from Hungarian into or out of any of the other languages in the system.
The fundamental problem with this approach is that the interlingua is an ideal rather than a reality. Despite great efforts, nobody has ever managed to design or a build a suitable interlingua. Worse, it has turned out to be very difficult to build fully adequate solutions for the step that analyzes the source words and produces the interlingua. A useful partial solution for this task, which is known as parsing, is described in detail in Section 2.4.1. Finally, the remaining step, the one that generates the target language words from the interlingua, is also a difficult research topic on which much effort and ink has been spent. In summary, the interlingua idea is useful because it clarifies what would need to be done in order to build an excellent MT system based on solid linguistic principles. This is helpful as a focus for research, but it does not offer a ready-made solution.
Figure 7.7 English phrase structure rules for John goes on the roller coaster
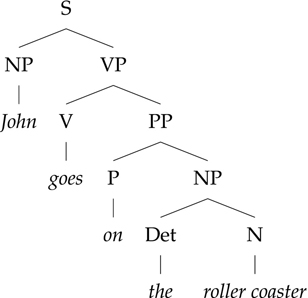
So, while an interlingua-based system would be good in theory, we probably cannot have one any time soon. For practical purposes, it is often best to be somewhat less idealistic, and build systems that do simple things well. Sometimes a direct approach will work well, because the given languages express things in similar ways.
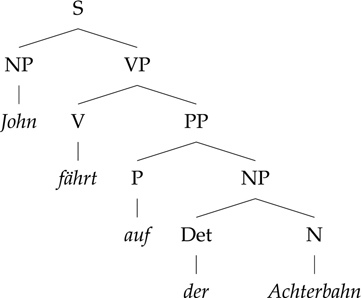
Figures 7.7 and 7.8 give an example of two sentences for which everything is parallel, so the direct approach would work well. If you know German, you will realize that the only really tricky aspect of this pair of sentences is getting the right feminine dative ending on the article “der” that translates “the”. For the record, the German is actually a little less ambiguous than the English: the German unambiguously says that John is riding on the roller coaster, not going onto the roller coaster, but the English allows either situation. In translating, you often have to make an educated guess about what was meant in order to translate correctly. An automatic system has to do the same, by whatever means it can.
In practice, many systems fall in the middle ground between the direct method and interlinguas, doing some linguistic analysis in order to move a little way up the translation triangle. The result of this is a language-specific transfer representation for the source language sentence. Then the system designer writes transfer rules to move the language-specific source language representation into a language-specific target language representation. Finally, a third module moves from the language-specific target language representation to an actual target language sentence. Systems that use this design are called transfer systems. The advantage of this approach is that the transfer representations can be designed in such a way that the transfer rules are reasonably easy to write and test; certainly easier than the kind of rules you have to write in order to switch around the word order in a direct approach to the translation between English and German. The disadvantage is that if you have N languages you have to write N(N − 1) sets of rules, one for each pair of languages and direction of translation.
Figure 7.8 German phrase structure rules for John fährt auf der Achterbahn
The main requirement that we can realistically expect from machine translation is that the translation process preserves meaning. That is, we want a person who speaks only the target language to be able to read the translation with an accurate understanding of what the source language original was saying. Before we can tell whether a translation is good, we will need to have a clear way of talking precisely about the meanings we are aiming to preserve. Therefore, before studying the details of translation, we will need to introduce some ideas from the linguistic subfield of semantics, which is the study of the part of human language grammar that is used to construct meanings (see also Section 3.3 for a discussion of semantic relations in the context of language tutoring systems).
Notice that we are no longer asking for the translated text to preserve aspects of the message other than meaning. The style of the translation could be very different from the style of the original. So long as the meaning is preserved, we will call the result a success.
In our discussion of grammar checking (Section 2.4.1), we saw that it is helpful to break up English sentences into smaller components, and give these components names like noun phrase and verb phrase. These components may in turn be broken down into subcomponents, with the whole process bottoming out either in words or in a unit slightly smaller than the word that is called the morpheme. The same kind of process happens in semantics and we thus need to study two aspects. The first is lexical semantics, which is the study of the meanings of words and the relationships between these meanings. Lexical semantics includes the study of synonym (words that mean the same thing), antonyms (words that are opposites), and word senses (the subdivisions of meaning that a particular word can have). This matters for translation, because lexical semantics gives you the tools to understand some of the ways in which elements can change as you move from one language to another.
The other part of semantics explains how a sentence like “Roger outplayed Andy” means something quite different from “Andy outplayed Roger”. The words are the same, but the way they are arranged differs, and this affects the meaning. But “Roger outplayed Andy” means much the same as “Andy was outplayed by Roger”. Here the words differ, but the meaning somehow comes out almost identical. The part of semantics that studies this is called compositional semantics.
The reason that this term (compositional) is used is that the meaning of a whole expression is composed of the meanings of its component parts. Thus, the meaning of the phrase “triangular hat box” is constructed (one way or another) from the meanings of the individual words “triangular”, “hat”, and “box”. It could mean a triangular box for hats, a box (shape unspecified) for triangular hats, or even a triangular box made out of hats, but each one of these meanings can be built out of the meanings of the smaller parts. Researchers in compositional semantics begin with the assumption that there is some kind of kind of mechanism for assembling the word meanings into a sentence meaning and spend their research efforts on experiments and theories designed to shed light on the way this mechanism works. Different languages typically assemble meanings in similar ways, but the fine details of the process differ from language to language, so an automatic translator has to smooth over the differences somehow.
For example, in German, when you want to say that you like skiing, you use an adverb (gern) to express the idea of liking:
There are two aspects to notice about this translation:
The meaning comes across, and in each language it is easy to see how the meaning of the whole is related to the meaning of the parts, but the details differ.
Some phrases are not like this at all. Both German and English have idiomatic phrases for dying, but the usual English one is “kick the bucket” and the German one is “ins Gras beissen”, which is literally “to bite into the grass”. The German idiom is rather like the English “bites the dust”, and a tolerant reader can probably accept that the meaning is somehow related to the meaning of the component parts, but the English idiomatic meaning has no obvious connection with buckets or kicking, so linguists label this kind of phrase non-compositional. To understand “kick the bucket” you just have to learn the special idiomatic meaning for the phrase. As a bonus, once you have done that, the slang-term “bucket list” becomes more comprehensible as a way of talking about the list of things you want to do before you die. Later in the chapter, we will see a technology called phrase-based machine translation. This technology learns from data and would probably be able to get the translation right for many idiomatic phrases.
George W. Bush is reputed to have said: “The trouble with the French is that they don’t have a word for entrepreneur”. This is an example of a common type of claim made by journalists and others. But, of course, “entrepreneur” is a French word, listed in the dictionary, and means just about the same as it does in English. Claims like this are not really about the meanings of the words, but rather about cultural attitudes. If President Bush did actually say what was reported, people would have understood him as meaning something like: “The French people do not value the Anglo-Saxon concept of risk-taking and the charismatic business leader as much as they should”. When people say “<languageX> doesn’t have a word for <conceptY>”, they want their readers to assume that if the people who speak <languageX> really cared about <conceptY>, there would be a word for it. So if you want to assert that a culture does not care about a concept, you can say that there is no word for it. It is not important whether there really is a word or not: your intent will be understood. This is a good rhetorical trick, and a mark of someone who is a sensitive and effective language user, but it should not be mistaken for a scientific claim.
Vocabularies do differ from language to language, and even from dialect to dialect. One of the authors (who speaks British English) grew up using the word “pavements” to describe what the other two (speakers of standard American English) call “sidewalks”, and also prefers the terms “chips” and “crisps” to describe what the other two call “fries” and “chips”, respectively. These are actually easy cases because the words really are one-for-one substitutes. Trickier are words that could mean the same but carry extra senses, such as “fag”, which is an offensive term for a gay male in the USA, but (usually) a common slang term for a cigarette in Britain. In elite British private schools, “fagging” is also a highly specialized term for a kind of institutionalized but (hopefully) nonsexual hazing in which younger boys are required to, for example, shine the shoes of older boys. This one can be a source of real misunderstanding for Americans who are unaware of the specialized British meaning.
In school, you may have been exposed to the concepts of synonyms and antonyms. Words like “tall” and “short”, “deep” and “shallow”, “good” and “bad”, “big” and “small” are called antonyms because they have opposite meanings. Words that have the same meaning are called synonyms. Examples of very similar words include pairs like “eat” and “devour” or “eat” and “consume”, “drink” and “beverage”, “hoover” and “vacuum”. As linguists, we actually doubt that there are any true synonyms, because there is no good reason for a language to have two words that mean exactly the same thing, so even words that are very similar in meaning will not be exactly equivalent. Nevertheless, the idea of synonyms is still useful.
Cross-linguistically, it also makes sense to talk about synonyms, but when you look carefully at the details it turns out that word meanings are subtle. The French word “chien” really does mean the same as the English word “dog”, but there is no single French word corresponding to all occurrences of the English word “know”. You should use “connaître” if you mean “to know someone” and “savoir” if you mean “to know something”. Translators have to choose, and so does a machine translation system. Sometimes, as below, you have to choose two different translations in the same sentence.
The right way to think about the relationships between words in different languages is to note when they are translation equivalents. That is, we try to notice that a particular French word corresponds, in context, to a particular English word.
This idea of translation equivalence is helpful, because it leads to a simple automatic method that a computer can use to learn something about translation. Called the bag-of-words method, this is based on the use of parallel corpora. As an example, we use the English and German versions of a Shakespeare sonnet that we discussed in Section 7.3. This text is not typical of real translation tasks, but makes a good example for showing off the technology.
The main idea is to make connections between the pairs of sentences that translate each other, then use these connections to establish connections between the words that translate each other. Figure 7.9 is a diagram of the alignment between the first four sentences of Shakespeare’s original and the first four lines of the German translation. Because this is a sonnet, and is organized into lines, it is natural to align the individual lines. In ordinary prose texts you would instead break the text up into sentences and align the sentences, producing a so-called sentence alignment.
Figure 7.9 Correspondence between the two versions

Figure 7.10 Word alignment for the first line

Once you have the sentence alignment, you can begin to build word alignments. Look carefully at Figure 7.10. Notice that the word “menschenblick” is associated with two words, and that the word “ich” is not associated with any word, because the line we are matching does not have the word “I” anywhere in it. It is useful to make sure that every word is connected to something, which we can do by introducing a special null word that has no other purpose than to provide a hook for the words that would otherwise not be connected. This is shown in Figure 7.11.
Figure 7.11 Revised word alignment for the first line

Once we have the word alignment, we have collected some evidence about the way in which individual German words can go with corresponding English words. We are saying that “wenn” is a possible translation of “When”, that “in disgrace” could be translated by “verbannt”, that “men’s eyes” could go with “menschenblick”, and so on. Notice that these are not supposed to be the only answers. In another poem “menschenblick” could easily turn out out to be translated by “human view”, “verbannt” could go with “banned”, and “wenn” could turn out to correspond to “if”. But in Sonnet 29, the correspondences are as shown in the diagram.
In order to automate the idea of word alignment, we rely on the fact that it is fairly easy to identify corresponding sentences in a parallel corpus. Then, to get started, we just count the number of times each word pair occurs in corresponding sentences. If we try this for a little fragment of Hansard (the official record of Canadian parliamentary debates), which is conveniently published in French and English, we can find out that the French word “gouvernement” lines up with the frequent English words in the second column in Table 7.1.
Table 7.1 Word alignment of gouvernement in Hansard
| French | English | Count |
| Gouvernement | the | 335 |
| Gouvernement | to | 160 |
| Gouvernement | government | 128 |
| Gouvernement | of | 123 |
| Gouvernement | and | 81 |
| Gouvernement | that | 77 |
| Gouvernement | in | 73 |
| Gouvernement | is | 60 |
| Gouvernement | a | 50 |
| Gouvernement | it | 46 |
Likewise, the English word “government” lines up with the frequent French words in the first column of Table 7.2.
Table 7.2 Word alignment of government in Hansard
| French | English | Count |
| De | government | 195 |
| Le | government | 189 |
| Gouvernement | government | 128 |
| Que | government | 91 |
| ? | government | 86 |
| La | government | 80 |
| Les | government | 79 |
| Et | government | 74 |
| Des | government | 69 |
| En | government | 46 |
We have left out the infrequently paired words in both lists, because we are expecting many accidental matches. But we are also expecting that word pairs that truly are translations will occur together more often than we would expect by chance. Unfortunately, as you see, most of the frequent pairs are also unsurprising, as the word for government is lining up with a common word of the other language, such as “the”. However, one pair is high up in both lists:
Gouvernement government 128
Table 7.3 Selected word-pair statistics in a small aligned corpus
This gives us a clue that these words probably do translate as each other. You can do the same with phrases. You can use the word-pair statistics about: “Président”, “Speaker”, and “Mr” to work out, just by counting, that “Monsieur le Président” and “Mr Speaker” are probably translation equivalents. Here is the data that you need to decide this:
… | ||
Président | Mr | 135 |
Président | Speaker | 132 |
… | ||
Monsieur | Mr | 129 |
… | ||
Monsieur | Speaker | 127 |
… |
Because these numbers are all roughly the same, you can tell that this set of words are tightly linked to each other.
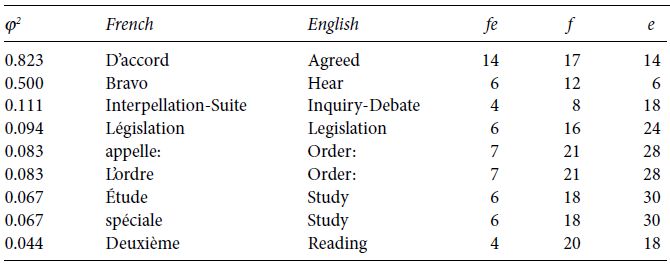
The tables we are showing are based on 1,923 sentences, but in a full system we would process many thousands, hundreds of thousands, or millions of sentences, so the tables would be correspondingly bigger. To make further progress on this, we need to automate a little more, because it is hard work poring over lists of word pairs looking for the interesting patterns.
The way to deal with this is to do statistics on the word pairs. Table 7.3 contains some of the higher-scoring pairs from a single file of the Canadian Hansard. Now, instead of calculating the number of times the word pair occurs together, we also collect other counts. The first column of the table is a statistical score called ϕ2 (phi- squared) which is a measure of how closely related the words seem to be. The second column is the French word, the third the English word, and the fourth through seventh are, respectively:
In reality, the table would be much bigger and based on more words, but you can already see that good word pairings are beginning to appear. The point of this table is to motivate you to believe that statistical calculations about word pairings have some value.
Many of the tools of statistical machine translation were first developed at IBM Research in the 1980s. This work completely changed the nature of academic research in machine translation, made it much more practical to develop web services such as Google Translate, and will probably be recognized as the most important work in machine translation for several decades. IBM made five models of the translation process. The first and simplest one, called IBM Model 1, is explained here.
Taking the task of translating from English to French, Model 1 is based on the idea that in each aligned sentence each English word chooses a French word to align to. Initially, the model has no basis for choosing a particular French word, so it aligns all pairs equally.
Figure 7.12 Part of an initial alignment

Figure 7.12 shows part of the initial alignment between two sentences. The point of making such alignments is as a step along the road toward making a so-called translation model; we are not doing translation yet, just working with the aligned sentences in order to produce a mathematical model, which will later be used by the translation software to translate new sentences. Notice that we add a special NULL word, to cover the possibility that an English word has no French equivalent. We make an alignment like this for each of the sentences in the corpus, and count the number of times that each word pair occurs. After that, words that occur together frequently will have larger counts than words that occur infrequently. This is what we saw in the previous section. Now we use those counts to form a new alignment that drops some of the weaker edges from the original figure.
An idealized version of what might happen in this process is shown in Figure 7.13. The connections between the first part and the second part of the sentence have been broken, reflecting the fact that there are two distinct phrases.
Figure 7.13 Part of a second-stage alignment

The details of what really happens depend on the statistics that are collected over the whole corpus. The hope is that “années” will occur more in sentences aligned with ones having the word “years” than it does with ones aligned with “change”, thereby providing more weight for the “années”–”years” link.
Once we have created a new alignment for each sentence in the parallel corpus, dropping some edges that do not correspond to likely translation pairs, we have a new and more focused set of counts that can be used to form a third series of alignments, as shown in Figure 7.14.
Figure 7.14 Part of a third-stage alignment

The principle here is to use the statistics over a whole corpus to thin out the alignments such that the right words finish up aligned. We are going to create a model that represents the probabilities of many of the ways in which words can combine to form a translation. To do this, we use the information contained in the bilingual corpus of aligned sentences.
Since the model is just a representation of what has been learned by processing a set of aligned sentences, you may wonder why we bother with the whole elaborate apparatus of alignments, model building, and probabilities. Could we not simply memorize all the sentence pairs? That would allow us to achieve a perfect translation of the sentences in the bilingual corpus, but it is not really good enough, because we want a solution that generalizes to new sentences that we have never seen before. To do this, we need a way of assigning probabilities to sentence pairs that we have not previously seen. This is exactly what the translation model provides.
When we come to translate new sentences, we will choose a translation by using the probabilities provided by the translation model to piece together a good collection of words as equivalents for the French. Model 1 provides a translation model. We will soon see how to combine this translation model with a language model. This is order to make sure that the translation output not only matches the French, but also works as a fluent sentence in English.
IBM Model 1 is clearly too simple (else why would the IBMers have made Models 2, 3, 4, and 5?) Specifically, Model 1 has the following problems:
Models 2, 3, 4, and 5 introduce different ways of building alignments, ones that are carefully tuned to avoid the deficiencies of Model 1. For a long time, systems based around variants of Models 3, 4, and 5 were state of the art, but lately a new and related idea of phrase-based translation has gained ground. This will be discussed later.
Figure 7.15 The noisy channel model

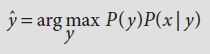
 is therefore the system’s best guess at what the original message must have been. The message model is expressed as P(y), which is the probability that the writer will have intended a particular word y. This is what tells us “Dsvid” is unlikely and “Dscis” very unlikely. P(x|y) is the channel model, and tells us that the s for a substitution is likely. Obviously, all bets are off if you do have friends called “Dsvid” and “Dscis”, or if the writer was using a nonstandard keyboard.
is therefore the system’s best guess at what the original message must have been. The message model is expressed as P(y), which is the probability that the writer will have intended a particular word y. This is what tells us “Dsvid” is unlikely and “Dscis” very unlikely. P(x|y) is the channel model, and tells us that the s for a substitution is likely. Obviously, all bets are off if you do have friends called “Dsvid” and “Dscis”, or if the writer was using a nonstandard keyboard.Table 7.4 Word pairs in French and English

In this section, we discuss the practicalities of using (or not using) automatic translation in a real-world commercial setting. This discussion is not concerned with difficult literary translations, or with the complexities of the technology, but with what the technology lets you do.
A system built for Environment Canada was used from 1981 to 2001 to translate government weather reports into French, as Canadian law requires. A typical report is shown in Figure 7.16.
This is a very structured text, as shown in Figure 7.17, but it is not really written in conventional English at all. The main part of each “sentence” is a weather condition such as “CLOUDY WITH A FEW SHOWERS”, “CLEARING”, “SNOW”, or “WINDS”. These do not correspond to any standard linguistic categories: the main part can be an adjective, a verb in the -ing form, a noun, and probably other things.
To translate into French, the METEO system relies on a detailed understanding of the conventions about what weather reports say and how they say them, and on a special grammar, largely separate from traditional grammars of English, which explains which words are used to mean what and in what combinations. This is called a sublanguage. The translation of the dateline is completely straightforward, since it simply consists of the date plugged into a standard template. Similarly, place names are easy to translate: they are the same in the English and French version. The body text does change, but the sentences are highly telegraphic, and mostly very similar from day to day.
Figure 7.16 A typical Canadian weather report

Figure 7.17 The parts of Canadian weather report

Finally, METEO benefits from two facts about the way it is used. First, it is replacing a task that is so crushingly boring for junior translators that they were not able, even with the best will in the world, to do it consistently well. Secondly, by law, METEO’s output had to be checked by a human before it was sent out, so occasional mistakes were acceptable provided that they were obvious to the human checker. METEO was used until 2001, when a controversial government contracting process caused it to be replaced by a competitor’s system. By that time, it had translated over a million words of weather reports.
The European Union (EU) is a group of European countries that cooperate on trade policy and many other aspects of government. It was founded by 6 countries in 1957, has expanded to include 25 countries, and now has 23 official languages. There is a rule that official documents may be sent to the EU in any of the 23 languages and that the reply will come back in the same language. Regulations need to be translated into all the official languages. In practice, European institutions tend to use English, French, and German for internal communications, but anything that comes in front of the public has to be fully multilingual.
One way of meeting this need is to hire 23 × 22 = 506 teams of good translators, one for each pair of source language and target language. You might think that 253 would suffice, because someone who speaks two languages well can translate in either direction. This idea has been tested and found to be wrong, however, because a translator who is good at translating English into French will usually be a native speaker of French, and should not be used to translate from French into English. It is harder to write well in a foreign language than to understand it. Translators are expensive, and government documents long and boring, so the cost of maintaining the language infrastructure of the EU is conservatively estimated at hundreds of millions of euros. In practice, it makes little sense to employ highly trained teams to cover every one of the possibilities. While there will often be a need to translate from English into German, it is unusual to have a specific need to translate a document originally drafted in Maltese into Lithuanian. Nevertheless, the EU needs a plan to cover this case as well. In practice, the solution it adopts is to use English, French, and German as bridge languages, and to translate between uncommon language pairs by first translating into and then out of one of the bridge languages. With careful quality control by the senior translators, this achieves adequate results.
Because of the extent of its translation needs, the EU has been a major sponsor of research and development in translation technology. This includes fully automatic machine translation, but also covers machine-aided human translation. The idea is that it may be more efficient to provide technology that allows a human translator to do a better and faster job than to strive for systems that can do the job without human help. Despite substantial progress in machine translation, nobody is ready to hand over the job of translating crucial legislative documents to a machine, so, at least for the EU, there will probably always be a human in the loop. Since the EU was early in the game, it makes heavy use of highly-tuned transfer systems, with transfer rules written and tested against real legislative documents. Over time, it may begin to make more use of statistical translation systems, especially if future research is able to find good methods for tuning these systems to do well on the very particular workloads of the EU. For the moment, the EU, with its cadre of good translators, is likely to stick with transfer methods. By contrast, Google, with statisticians aplenty, computational power to burn, and access to virtually limitless training data, seems likely to continue pushing the frontiers of statistical methods. For the casual consumer of machine translation, this diversity of approaches can only be good.
Translators entering the professional market will need to become experts on how to use translation memories, electronic dictionaries, and other computer-based tools. They may rely on automatic translation to provide first drafts of their work but will probably need to create the final drafts themselves thus the need for expert human judgment will certainly not disappear. In part, this is because users of commercial translation need documents on which they can rely, so they want a responsible human being to vouch for the accuracy and appropriateness of the final result. Specialist commercial translators will certainly continue to be in demand for the foreseeable future; there is no need to worry about the risk of being replaced by a computer. As in most other workplaces, you have to be comfortable using technology, and you should expect to have to keep learning new things as the technology changes and offers you new ways of doing your job more efficiently.
The range of languages for which free web-based translation is available will continue to grow, in large part because the statistical techniques that are used are very general and do not require programmers to have detailed knowledge of the languages with which they are working. In principle, given a parallel corpus, a reasonable system can be created very rapidly. A possible example of this was seen in June 2009, when Google responded to a political crisis in Iran by rolling out a data-driven translation system for Persian. It appears that this system was created in response to an immediate need due to the fact that the quality of the English translations from Persian did not match up to the results from Google’s system for Arabic, a system which used essentially the same technology but had been tuned and tested over a much longer period.
Improvements in the quality of web-based translation are also likely. We think this will happen for three reasons: first, the amount of training data available will continue to increase as the web grows; secondly, the translation providers will devote effort to tuning and tweaking the systems to exploit opportunities offered by the different languages (notice that for this aspect of the work, having programmers with detailed knowledge of the source and target languages really would be useful after all); and thirdly, it seems likely that advances in statistical translation technology will feed from the research world into commercial systems. There will be a continuing need for linguists and engineers who understand how to incorporate linguistic insights into efficient statistical models.
Literary and historical translators could be unaffected by all of this, although some of them will probably benefit from tools for digital scholarship such as those offered by the Perseus Project. These allow scholars to compare different versions of a text, follow cross-references, seek out previous works that might have inspired the current work, and so on. For example, a scholar working on a Roman cookbook might want to check up on all uses of the word “callosiores” in cooking-related Latin, to see how often it seems to mean “harder” and how often it means “al dente.”
Many potential users want to use automatic translation as a tool for gathering a broader range of information than they otherwise could. Marketers who already do the kind of opinion mining mentioned in Chapter 5 will also want to collect opinions from their non-English-speaking customers. This is much the same as what we did to decode the German cellphone review.
After reading the chapter, you should be able to:
T . . . . . 0 . . . . . N . . . . . R . . . . . U .
. R . . . P . S . . . O . C . . . E . S . . . F . N
. . A . S . . . I . I . . . I . H . . . A . E . . .
. . . N . . . . . T . . . . . P . . . . . R . . . .
T . . . O . . . N . . . R . . . U . . . R . . . P.
. S . 0 . C . E . S . F . N . A . S . I . I . I . H
. . A . . . E . . . N . . . T . . . P . . . R . . .
Further reading
There is a large and growing literature on translation and machine translation. We provide a few pointers into this literature.
Chapter 25 of Jurafsky and Martin’s textbook (Jurafsky and Martin, 2009) covers modern machine translation in depth. Phillipp Koehn (Koehn, 2008) has written a comprehensive technical introduction to statistical machine translation.
An older but more general introduction to machine translation is provided by John Hutchins and Harry Somers (Hutchins and Somers, 1992). Language Files (Mihaliček and Wilson, 2011) has a full chapter on machine translation.
Doug Arnold and his colleagues have made a good introductory textbook available for free on the internet: http://purl.org/lang-and-comp/mtbook.
The cautionary tale about “intoxicado” is from Harsham (1984).
There have been a few attempts to make machine translation systems more capable of translating poetry. In Genzel, Uszkoreit, and Och (2010), the authors describe a system that aims to produce translations with appropriate meter and rhyme. This is an impressive technical achievement, but does not address the bigger problem of how to produce translations that have the beauty and precision of good human-created poetic translations.
The Perseus project (Crane, 2009) presents beautiful web versions of literary texts, including 13 million words of Latin and 10 million words of Ancient Greek. These include commentary, translations, and all kinds of support for multilingual scholarship.