Chapter 3
From self-service to self-sufficiency
Abstract
This chapter explores the expansion of self-service to self-sufficiency, the changing role of information technology (IT) to enablement technology (ET), and emerging data science education in academia.
Keywords
self-service
self-sufficiency
discovery
enablement
talent
data scientist
visual analyst
enablement technology
“Look up at the stars and not down at your feet. Try to make sense of what you see, and wonder about what makes the universe exist. Be curious.”
—Stephen Hawking
In the previous chapter, we took a look at the foundational change happening in the data industry as organizations begin to include new thinking in data discovery as a fundamental complement alongside traditional BI processes. From an organizational perspective this is an important evolution in the larger way that data-driven organizations are beginning to think about—and approach—how they explore the untapped value hidden within their data to uncover new competitive advantages and insights. But, to realize the full potential of this change, we need to push the conversation a bit further down the rabbit hole. Rather than just looking at how organizations are cultivating a culture of discovery at the strategic top tier, we also need to consider how that shift is trickling down and changing the way various groups of people within the organization are working with data, too. After all, change does not happen in a vacuum of vision statements and good intentions. To realize changes requires the ability to take action—and while machine learning and other artificial intelligence technologies are rapidly reshaping our current perceptions of learning, humans are still our biggest data discoverers. Thus, they need to be empowered—and enabled—to be a part of discovery in a meaningful way.
One of my favorite leading ladies in the BI industry is Jill Dyché—and one of my favorites of Jill’s quotes comes from her latest book, The New IT. In her book Jill eloquent writes, “IT is at a moment where its future is being redefined. And its cultural power is shifting to a new set of gatekeepers (Dyché, 2015, p. 13).” Going forward, Jill describes how IT is forging a new identity through its operations, connections, and innovations. Again, think back to chapter: Separating Leaders From Laggards and how traditional IT departments are recalibrating in the wake of disruption, transformation, and reinvention.
Luckily, I agree with Jill. In a December 2014 piece I wrote, entitled From Self-Service to Self-Sufficiency: How Discovery is Driving the Business Shift, I wrote pointedly about how self-service is being redefined to be less about service and more about sufficiency—thus, self-sufficiency—in terms of mindset, tools, and capabilities. I also wrote about the simultaneous shift of IT from Information Technology to Enablement Technology (or, ET) and how that is affecting the new types of modern data analysts and other data science professionals whose roles are materializing today in order to bridge the gap from self-service to self-sufficiency.
In chapter: Separating Leaders From Laggards, we took an overhead view into how business as usual is changing to become more data- and customer-centric. Likewise, in chapter: Improved Agility and Insights through (Visual) Discovery, we discussed how the data industry itself is changing in the way we think about data. Now, in this chapter, let us take a deeper dive into what self-sufficiency is and what it needs to thrive, as well as the new role of IT and how it is being refitted within the visual discovery culture today.
3.1. From self-service to self-sufficiency
In the past several years, “self-service” has come to be understood as users simply having access to information they need, which is served to them in easily consumable ways for the most basic of slice and dice operations. Today, that definition is being redefined. Now, self-service is less about access and much more about ability: it is a fundamental shift from being able to consume something that has been predefined and provided to be able to develop it—to discover it—yourself.
As a quick aside, it is worth mentioning that self-service is a term that is applied more than generously in the data industry today. Everything is self-service and everyone needs self-service. It is the most versatile accessory you can find anywhere. But, I want to clarify that within our discussions on self-service to self-sufficiency, I am not talking about self-service for IT, developers, or even data scientists. I am talking about self-sufficiency for business users and modern data analysts. Self-service is an enabling term and previously meant for access to “information.” Self-sufficiency is more about access to work with “data” independently without the need for requirements or developers to make it so.
To add a bit of color here, let me begin with a quick story. When I was a little girl, my favorite Disney princess was Ariel from The Little Mermaid. But, as it may surprise you, it was not Ariel herself who was my favorite character in the adaptation of Hans Christian Andersen’s much darker tale. Sure, she was spunky and curious and determined—all qualities that I admire, but it was her curmudgeonly crustacean pal Sebastian the crab that reeled me in (no pun intended). Sebastian was a demanding, get-it-done kind of guy, who did not like to take no for an answer and who had an eye for finding solutions to the biggest problems under the sea. In one scene of the film, Sebastian—who by then had enough of that ditzy seagull and Ariel’s other lovably inept companions—said, with a hint of seduction, if “you want something done, you’ve got to do it yourself.” To bring this to life visually it, see Figure 3.1.

Now, I certainly do not want to implicate today’s self-sufficient analysts as being the crabs of the industry—I am sure that title could be better applied elsewhere. But I do want to recognize the very Sebastian-like independent and Do It Yourself mindset because it is one that is being adopted with fervor across organizations (not to mention society as a whole, with the surplus of DIY television shows and guidebooks and the appearance of crafting sites like Pinterest and Etsy). Now, let us apply this story back to our context. In the data science and analytics world, it is no longer enough to be like Ariel: inquisitive and eager to explore for new discoveries. Now, we are determined to find those answers—to earn those new discoveries, and we want the power and the abilities to do it ourselves. We are Sebastians.
The business user has changed, and that is possibly the most important driver shifting self-service to self-sufficiency. Like the business itself in an era of disruption, transformation, and reinvention, this change in the business user mindset is one of fitness. Users have had to adapt in order to respond to the evolving needs of data-centric cultures. Today’s increasingly sophisticated predictive and operational analytics require users with business knowledge to become partners in discovery, not merely consumers of enterprise approved business information for decision-making. These users have the business context and tribal knowledge that gives them a unique position to contribute to collective learning in the organization and apply their insights into the larger discovery process. Equipped with better tools, users are also earning greater autonomy and compatibility within cutting-edge IT organizations. Where agility was a “codeveloper” before, self-sufficient business users can now do it all: they can connect, integrate, analyze, and visualize data without the central control and management of IT.
Alongside that attitude change has come a buffet of tools designed to support the demand. And, with the advent of increasingly robust technologies, there is no shortage of self-service tools on the market today. More important, these tools—BI and beyond—are good. In fact, they are more than good: these next-generation tools are the catalyst enabling business users to become increasingly more self-sufficient from IT in their data needs—if they so choose. While I will not spend a lot of time going through and comparing the different tools and solutions currently available in the marketplace, it is worth to take a look at a few leading players and the trends among them. See Box 3.1 for more.
Before I move on that last point—“if they choose”—warrants a small disclaimer. Self-sufficiency comes with a caveat. There will always remain those users within the business that simply do not want to be self-sufficient. Some—possibly even a majority—will want to stay dependent. They are not interested in all these new capabilities and are perfectly content to continue having information delivered to them—and that is okay. It is not about forcing 100% of users within an organization to be self-sufficient: it is about enabling those who want to be. Adoption will continue at its own pace that is nurtured and facilitated by how the business supports those early-movers and continues to encourage everyone else to follow suit. Again, this is part of the larger discovery culture change that starts at the top and works its way down throughout all levels of hierarchy in the organization. So, defining data provisioner and consumer roles—and, further, developing a user readiness assessment—is another key part of the access framework, too.
With the new business user credo “take care of thyself” that is reshaping user mindsets and ushering in an era of consumerized BI with a bevy of new self-sufficiency-oriented discovery tools, it should be no surprise that the role of IT is fast changing too. No longer that of command-and-control, IT is increasingly taking on the role of broker and consultant—of enabler. We simply do not need traditional IT anymore, at least not for discovery. Of course, this is not to say that IT itself is going away by any means. It is not. IT will always deserve a fundamental role in data management and continue to be a key player in information security, governance, and other stewardship facets.
Again, just so I am clear and there is no miscommunication, let me phrase this more explicitly. While self-sufficiency is about enabling more business users with more access to more data with more frequency and across more channels, it should not be enacted without putting governance at the forefront of the discovery process. I am not making a case for the Wild Wild West of data here, though I suppose I am suggesting a step out of the comfort zone for many. Governance is, actually, a topic that may now be more charged than ever because of self-sufficiency and discovery. However, we will save governance for discussion in later chapters, where I will take a magnifying glass to how to enable self-sufficient governed data discovery and a brand of governed data visualization, too.
Governance aside, traditional information technology must—and will—soon become enablement technology. And, as IT evolves into a role that is focused on enabling and supporting more information-hungry users, it must respond to the opportunity to educate the business on IT processes and governance.
Ultimately, the shift toward self-sufficiency is closing the gap between business and IT. It is a symbiotic relationship, now more than ever before. As Jill noted, the cultural power of IT is being shifted to a new set of gatekeepers. These gatekeepers are the data owners whose data is being used for discovery and also those self-sufficient business users—the demanding discoverers of new insights.
In the following sections of this chapter we will explore the core discovery capabilities for self-sufficiency as well as the shift of IT to ET and the arising roles in data science in greater detail. But first, let me share just one more story as an example to illustrate how self-sufficiency is changing the way we do BI and discovery.
3.1.1. A lesson from frozen yogurt
I am not afraid to say that the Big Data Culture hinges on self-sufficiency to be successful. I firmly believe that it does. Like discovery, self-sufficiency is a numbers game. The more data available and the more people that are actively enabled to work productively in the discovery process, the more insight potential and, therefore, the more valuable discovery. The less restriction and red tape we put on these self-sufficient users, the more discoveries they can uncover. They may not all be winners, but there will be the few golden nuggets, too.
At the Teradata Big Data Analytics Roadshow held in New York City in December 2013, Bill Franks, the current Chief Analytics Officer of Teradata, noted that changing small things about your policy and culture will achieve huge business impacts. Enabling self-sufficiency is one of these. As a way to explain his position, Bill pointed to yogurt shops and the customized frozen yogurt trend that is sweeping the nation and making the Ye Olde Yogurt Shoppes of the past more or less obsolete. This example has stuck with me ever since I heard it, and I want to share it with you.
To get the most out of this lesson, you have to know that there is a funny trick about learning how to dine with children. For example, over the years I have learned that trying to convince my eight-year old son to go to a fine dining establishment will have him bored to tears before I finish my first glass of wine. Likewise, he is never going to convince me to put anything that is handed to me out of a drive-through window into my mouth. But, the one thing he and I always agree on when we are looking for a tasty treat is our favorite frozen yogurt shop. At Spooners my son and I each grab a paper cup from the counter and take off in different directions. We each get to sample and experiment with different flavor blends by pulling the lever on any one of the dozen or so yogurt spouts lining the wall. We can fill the paper cup until it—or our eyes, at least—are satisfied. Then, we can further customize our creamy treat with sprinklings of candies, fruits, nuts, and other delicious toppings at will. When it is all said and done, we pay by the ounce for our dessert, eat, and enjoy while debating the merits of one froyo interpretation over the other.
Now, compare that experience against the traditional yogurt shop model. In the shops of my youth, I would be taken in and told to select from a menu of flavors that I would then watch the clerk measure into a cup. I had the option to select a topping that—for an additional cost per topping—could be, again, measured out and added to the cup by the clerk behind the counter. Then, we would pay per cup and per topping in a transactional, impersonal manner from a set menu of prices. As a kid, going with my father to get frozen yogurt was still a special treat that we enjoyed doing together, but it was inherently less…creative. In fact, when that particular chain went out of business, I had only ever tried one flavor of yogurt. I simply took what was served to me, and rarely had the opportunity (or the initiative) to think outside of the box.
This anecdote provides a simple, yet accurate allegory about self-sufficiency in our new data-driven culture. In the older model, the yogurt is the data, the clerk is IT, and the customer is the business user steadily requesting data. The old model—where IT prepares the data in a pre-defined way and delivers it to the business user—is self-service and it is traditional BI. I have access to the same basic ingredients—yogurt flavors and toppings—but someone else is measuring it out and giving it to me. All I get to do is consume. How would you feel if you realized you only got to play with one way of interacting with data—ever?
The new way—where IT provides access to the data and allows the user to explore, shape, and consume the data how they need to—is self-sufficiency and its discovery. Not only do I have access to all the ingredients that I need, but I also have the ability to measure my own yogurt, decide my own toppings, and toss in whatever types and amounts of either (or both) that I want to find new patterns and new tastes. Now, I get to customize my discovery experience to my own requirements. It is an endless supply of mix-and-match possibilities using the same basic elements to find new discoveries and insights while expectations and conditions are constantly envolving. That discovery environment gives business users the tools, the environment, and the access they need to shape their own experience in the data. And, that discovery environment (just like the new yogurt shops versus the progressively obsolete ones of the past) requires self-sufficiency to thrive.
3.2. Discovery capabilities for self-sufficiency
As defined in chapter: Improved Agility and Insights Through (Visual) Discovery, discovery is—in a very simplified version—an iterative, revolving process where data is virtualized or modeled and then visualized to see insights into the data. Once new insights have been discovered (or not), discovery continues in an exploratory “lather, rinse, and then repeat” cyclical fashion until new insights are uncovered.
If we think of discovery as a process, then self-sufficiency is the charge—the battery, if you will—that sparks that process from a framework to an action. It is the mechanism that makes discovery “go.”
For a visual example, think of self-sufficiency as a perfect triangle (as depicted in Figure 3.2), with tools, environment, and access each being one of its three points. Like any shape, the triangle requires its three points to retain its form. A failure in any of these three points becomes an Achilles Heel in discovery. If you care to revisit the discussion on friction from the previous chapter, you could expand this idea in terms of slope, and consider that the addition of friction-causing activities in each of these three areas effectively steepens the angle between points, making the climb that much more uphill for the self-sufficient user. The less friction in discovery, the flatter the triangle, and the more enabled the self-sufficient discovery analyst is.
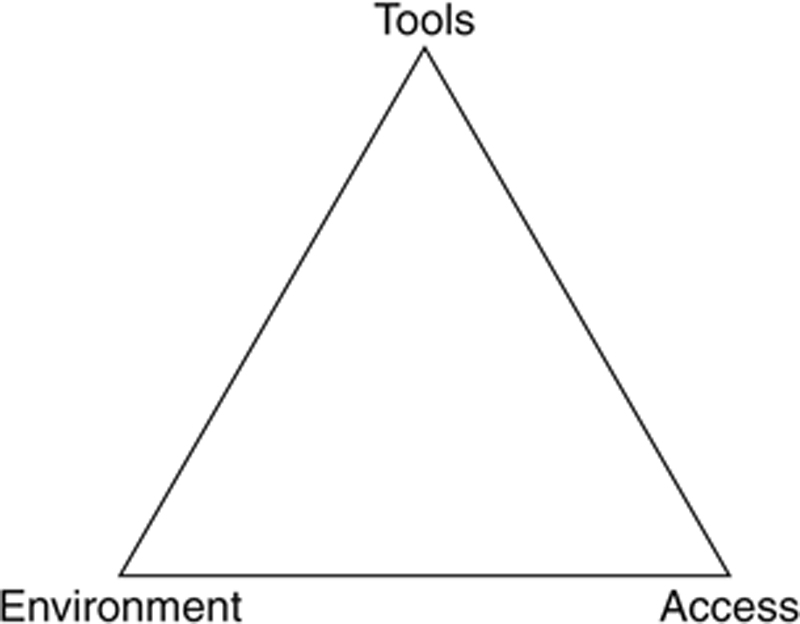
Figure 3.2 Self-Sufficiency Triangle
In the subsequent three sections, we will explore each of these points—tools, environment, and access—in further detail.
3.2.1. Discovery tools
The majority of business users are not ETL programmers. Many of them do not know how to write SQL or use other programming languages, and many of them are lacking any formal data analysis education or skills. Instead of considering this a weakness, consider it an opportunity to design from. Business users need tools that will work within the parameters of their roles, and that will allow them to discover without having to write programming code, or script, etc.—or, otherwise without the need for advanced training beyond their core function within the business. In later chapters, we will talk about the competencies and standards needed to architect governance and provide guardrails to users who lack formal data analysis and discovery training, however the emphasis in this section is simply on the tool capabilities needed to enable self-sufficient user discovery.
Bells and whistles aside, business users hunting self-sufficient discovery tools are looking for two things. First, they need agile, iterative tools that propel them beyond limited self-service capabilities and provide more opportunities to interact with the data. Second, along with best practice design, guided discovery, and other mechanisms to preserve the integrity of the discovery process and insulate the business from risk, these discovery tools also need to be visual, and invite visual discovery and storytelling to foster train of thought thinking and compelling communication of insights. Together, these are two basic criteria that are requisite for self-sufficiency: best-of-breed BI coupled with best-of-breed data visualization. Cumulatively these give users the ability to integrate and abstract data, visualize it, analyze it for insights, share discoveries—and then go back and do it all over again.
Tools are not the end-all-be-all for self-sufficiency. Along with these tools, business users need an environment to work with data—not just a local data set to tinker with offline. Some organizations are building their own environments some are turning to the cloud. Either way, what is needed is a discovery environment that responds to and leverages the capacities of self-sufficient tools.
3.2.2. Discovery environment
In the previous chapter, we discussed sandboxes, and their role in discovery. This type of discovery environment is important because the discovery process has to live within the business: business users are the drivers with the inherent knowledge to detect context (ie, predefinitions) and know what they are looking for. They are also the ones who may not know what they are looking for, but can—and will—know it when they see it. Discovery requires a leap of faith. Think of your discovery environment—whether in the cloud or within an architected sandbox or otherwise—again like that glorious baseball diamond in Field of Dreams: if you build it, they—insights—will come.
This optimistic, forward-looking mentality is a key distinction between BI and discovery. While both focus on deriving value from data, BI and discovery are differentiated in that BI relies on people to tell us what is going on inside the business, while discovery uses the data to gain insights that show us what is happening. These value opportunities typically fall into one of four categories—customer insights, risk avoidance and compliance, business optimization, and/or business innovation—and self-sufficient users are one vehicle to champion discovery in the business.
At the end of the day, providing self-sufficient users with the tools and the environment in which to use them is not just a shift we should do or react to: it is something that we have to. A 2013 IDC and ComputerWorld study found that 10–15% of organizations say that their environment consists of established discovery sandboxes. There is a good reason behind that: if you do not give people a place to innovate, they will find a place—and that place may bring unnecessary (and unknown) risk into the business. After all, “shadow IT” scenarios (a term used to describe IT systems and solutions build and used inside the organization without explicitly organizational approval) persist primarily in those companies where IT does not embrace becoming a discovery enabler for the business (in addition to their data management and governance responsibilities).
3.2.3. Discovery access
Finally, the third point on the self-sufficiency trifecta, is access. Self-sufficient data discovery requires not just tools and technologies, but it also involves creating a culture of exploration and embedding analytics into the fabric of the entire business. Self-sufficient users thrive within a data culture that does not shy away from innovation, or of empowering business users to explore the data. We have to move away from the habitual hoarding of information into little silos or slapping up so much red tape to get access to nonregulated or otherwise protected data that the business user ends up just forgetting it and moving on. It is not an “unleash the firehose” mentality, but we should at least be turning on the sprinklers. Self-sufficient data discovers need more access to more data with more frequency to have as much opportunity to discover new insights as possible.
Having this data discovery environment requires overcoming that long-suffering information barrier and giving business users access to information they need—and want—to explore for new insights. No, it is admittedly not the easiest change to make, but access is a critical ingredient of self-sufficiency and it has to be resolved, governed, and set up responsibly. Whether this access is given via the cloud or the internal environment is irrelevant: self-sufficient users just need the freedom to take their toys and go play.
3.3. (Information) enablement technology
Self-sufficiency is such an important part of the new Big Data Culture because the real value of big data is utilizing it to discover new insights—and uncover new patterns or questions that we do not know already and sometimes do not even know that we are looking for—in the data. Thus, our business users and modern data analysts need self-sufficiency, enabled by discovery capabilities, including tools, environments, and more frequent and open data access, in order to truly maximize the value proposition of data discovery. And, as mentioned already, enabling business users in discovery is part of IT’s new role. In fact, that is IT’s new role: they need to become information enablement technology, not just information technology. IT—or, ET—is (and will continue to be) responsible for helping enable more self-sufficient opportunities for business users to explore and do more so that we discover more and, as a result, gain more actionable insights that bring value back to the business.
More enabled users results in reduced demands on IT to endlessly perform tasks that users can now do for themselves (again, this is the concept of friction and “frictionless” that was introduced in chapter: Improved Agility and Insights Through (Visual) Discovery). When IT takes business requirements there is a big challenge in distinguishing between generalization (for many) and personalization (for one). Self-sufficiency enables personalization and governance guides generalization. Yes, IT’s role is going to change, but within this change comes the perfect opportunity for IT to step up and educate the business on IT processes and governance. The business does not have the background (or interest) in systems and data management—knowledge about the maintenance of systems, about standards and management and service-level agreements, and so on. And, with reduced business user needs, IT has more time to focus on navigating governance, security, and other quagmires that keep popping up for data and platform management—especially in an ecosystem driven by self-sufficiency.
Really, it is a win–win for IT—and there is little need for IT to become defensive or insecure about the reshaping of their role. Instead, ET needs to take the initiative to educate the business on (1) how technology works, (2) what to expect, and (3) how to properly articulate their requirements and needs. Because of IT’s proven capability to standardize and efficientize information, as much as they will become an enabler, they will also take the role of a technology administrator. We will analyze this further in a later chapter on the joining of governance and discovery.
Of course, not everyone in IT will see this as a win–win. For example, if traditional IT now has a new focus, one next question becomes: what will become of all the IT developers in this new era of self-sufficiency? What is going to happen to them? I think many IT folks would be quick to argue that they have plenty of other things to be setting their minds to. But, discovery is not prototyping. IT developers will still productionize; they will find a home, write the code, optimize, and harden designs into processes. They will still develop and build, it is just going to get started a little differently is all— with discovery and governance in addition to (or in lieu of) requirements gathering processes.
As with any change, there was inevitably be doubt, potential reservations, and resistance. However, now is not the time to sling around the Borg mantra “resistance is futile” but instead to work together collaboratively to migrate through those changes as they come. There will be early adopters and there will be late adopters. There will be champions and naysayers. This is to be expected and should be approached with a keen sense of change leadership.
Along with the revised job description of business users and IT, there are also new roles working their way into the organizational charts of companies across virtually every industry vertical. Beyond “new” some of them are even super sexy. And when we think of sexy data science jobs, there is one that immediately pops in our mind. This is the role of the Data Scientist.
3.4. The data scientist: the sexiest of them all
While the original credit for the concept of “sexy statistics” goes to Google’s chief economist Hal Varian (2009) perhaps it all started—the romance and the legends alike—in a HBR article by Tom Davenport and DJ Patil (2012). In the breath of one headline—Data Scientist: The Sexiest Job of the 21st Century—Tom and DJ managed to upgrade the mental image of the geeky math guy from pocket calculators and too-short pants to one of a hipper, cooler guy (or gal) in a t-shirt. Thick-rimmed black glasses somehow came back into style. In fact, those hipster frames somehow became the logo of the data scientist, regardless of whether any actual data scientist has ever worn them or not (I still have not met one that does). For myself, the memory that comes immediately to mind when I think of the data scientist is one event where a respected industry analyst, participating on stage in a dueling keynote with another analyst, put on a pair of black spectacles and pronounced himself a data scientist in front of the audience’s eyes. When I renewed my eyeglasses prescription I even subconsciously chose a pair of the black frames—and statistics have been my nemesis since high school.
But, just like in high school, once we all heard that the data scientists were hot, they got really, really popular—and really, really fast. Suddenly, they were the stuff of dozens of articles, infographics and, on occasion, the beneficiary of a zinger or two about ponytails and hoodies. At Teradata PARTNERS in October 2013, one analyst called them new versions of old quants. They have been firmly denied any of thought-leader Jill Dyché’s affections according to her blog post Why I Wouldn’t Have Sex with a Data Scientist (Dyché, 2013). And, my personal favorite: industry writer Stephen Swoyer labeled them unicorns—fantastical silver-blooded beasts of folklore and impossible to catch. If there was a homecoming king/queen of the data industry in 2012, it would have, without a doubt, been the data scientist.
In the wake of their first appearance, some of the craze surrounding the data scientist has, admittedly, died down a bit—though by no means has it settled into the cozy comfort of urban legend. Just about everyone still has something to say about the data scientist, and for good reason: finding one is hard, retaining them even more difficult. For all their allegorical appeal, to a large degree the data scientist is something of a rare creature. This is partly because the genetic makeup of the data scientist is a hybrid mix of both skillset and mindset. And, that skillset itself is blended—and one that is still difficult to find as educational programs and experience with brand new (and intrinsically fluid) tools and technologies are almost impossible to keep up with (this will be the focus of chapter: The Data Science Education and Leadership Landscape). After all, it is hard to be an expert in something that just appeared on the market 6 months ago—or less.
3.4.1. The blended aptitudes of data scientist, PhD
First, let us talk skillset. One often-disputed characteristic of the data scientist is their educational background. Some say that the data scientist is a PhD statistician or mathematician with business acumen and a knack for communicating technical info. Others believe it is an MBA graduate with tech savvy aptitudes. And, still some say it is both…or neither, or that the data scientist is a myth, or that it is really the everyday analyst that holds the real value. The jury is still out.
Regardless, one question that manages to always bubble to the top is: does the data scientist need a terminal degree—or, to put it another way, should our data unicorns be limited to data scientist, PhD? While I cannot answer that question definitively, I would like to provide at least some kind of practicable advice for you. Here is what a tiny sample of de facto data scientists in my network had to say:
Data Scientist #1—has a PhD in engineering and data management—said that a PhD student with statistical skills is typically a good candidate for a data scientist role—so long as he or she is willing to engage with the business context.
Data Scientist #2—has a PhD in applied mathematics—said that math teaches the ability to abstract problems and dive into data without fear. And, while a business background is important, it does not give a data scientist the skillset to execute a data problem.
Granted the sample size was miniscule and seeing as how both the data scientists above happened to have doctorate degrees (although in different fields), I will gladly admit that their positions on the issue were probably biased. But, that aside, if you look closely we can tweeze two very interesting pieces of insight out of those comments. Does having advanced mathematics education give some a better ability to execute—turning business ideas into solutions that can be delivered to others? Or, perhaps data people simply can more easily understand what the business needs than a businessperson can understand what the data is capable of? I am not suggesting any answers, but it is definitely food for thought.
Either way, competency in mathematics (especially statistics) is unanimously important for a data scientist—perhaps even more so important than having a business background. Yet, there is also a common sentiment that it is (typically) easier to interface with someone who has a business background, as opposed to one highly technical. And that is where we shift to a business-education skillset: clear, effective communication delivered in a simple format that business executives expect—and that lacks mysterious data jargon. Equally as important for the successful data scientist is the ability to translate and engage between both business and IT, and have a firm understanding of the business context in which they operate.
So, business acumen and statistical skills—got it. These two competencies are complementary, even if they are imbalanced. But, maybe a data scientist does not need a degree that says data science any more than they need an MBA. What the data scientist does need is a foundational understanding of these concepts. More important, these unicorns require a third skillset that is a little more intangible: an eagerness to explore and discover within data. Beyond their educational background, the characteristic that really seems to set the data scientist unicorn apart from the data user herd is their personality. This is the other half of the blended aptitude: the mindset to go along with the skillset. A true data scientist possesses a suite of hidden skills, including things like innovative thinking, the readiness to take risks and play with data, and a thirst to explore the unknown—and he looks to see how these skills are embedded within the integrated whole of education and experience.
The best data scientist(s) who you will find out there today are not just the ones with the right skills to do the job, but the ones who think about the job the right way, too. These curious unicorns are the ones who are able to divorce the idea that formal education is simply on the job training and keep their humanity intact. Being a data scientist is not about checking off a list of qualifications and adding buzzwords to a resume. It is about becoming a data scientist—having the eagerness and hunger to dig deep inside data and find value. That is aspiration, and it is an intrinsic characteristic not taught in any program.
Remember: the key to discovery is curiosity. Not just in curiosity-enabling technologies, but more important, in curiosity-driven personalities. This is, ultimately, the demystification of the data scientist. It is not limited to a dissection of their skills, academic pedigree, or depth of business knowledge, but an innate component of their personality type. The discovery culture in the business as it relates to the people, then, is a function of matching personality to possibility.
That said, there are some essentialities to being a good data scientist who are becoming more and more ubiquitous in the data scientist job description. If you are hunting for the perfect data scientist resume, consider the below. They must:
• Be of an analytical and exploratory mindset
• Have a good understanding of how to do data-based (quantitative) research
• Possess statistical skills and be comfortable handling diverse data
• Be clear, effective communicators with the ability to interact across multiple business levels
• Have a thorough understanding of their business context
Ultimately, it is not just about the knowledge the data scientist brings with them. It is about the willingness to keep learning. Regardless of what works for your particular organization or job description, the key is this: hire for capability, not for skill set. The skillset will change; the mindset, however, will not (Box 3.2).
At the end of the day, we have got to get beyond the sex appeal of the data scientist and start thinking of data science more broadly—not as a particular set of technologies or skills, but as those people who have a set of characteristics: curiosity, critical-thinking, and the ability to communicate insights and assumptions. And this does not necessarily mean we have to look outside of our company walls. Those naturally inquisitive people already living and breathing the data within our businesses are every bit as much capable of being the next data scientist, even if they do not have the fancy job title.
One thing is for certain: data scientists come in as many colors as the rainbows that their fantastical counterparts dance upon. But data scientists, no matter how sexy or rare they are, are not the only source of discovery within the organization, especially with the rapid increase of self-sufficient discovery tools allowing everyday business users to explore their own data. The lone data scientist does not scale, and if you define data scientist community as a set of skills, you are missing out on a ton of people who already exist in your organization—and who can contribute a ton of value, too.
3.5. Moving forward
Whether it is supporting the enablement of self-sufficient business users with internal training, support, and opportunities; or harnessing the educational opportunities brought to light by the surplus of powerful and intuitive tools already available to business users; or simply looking to hire and retain the rarest of data scientists, the simple truth is that continuous learning and improvement are the main source of competitive advantage in an era of business disruption and reinvention. And, as the next-generation of knowledge workers and information leaders, millennials are on course to become the most educated generation in American History. In fact, they will have overtaken the majority representation of the workforce by the end of 2015—last year (Pew Research Center, 2010). Building a blended education model that connects research and academia with experienced professionals, and hands-on practicable experiences facilitates a knowledge transfer that will not only empower the individual, but continue to bring value into the next-generation of the organization. Further efforts in this space should include an increased focus on mentorship between incoming and retiring workers to facilitate knowledge transfer, as well as the continued availability of more internship opportunities for incoming graduates.
However, merely educating incoming knowledge workers is not the answer to developing future technology leaders. Likewise, innovation cannot be a reactionary Measure. Reinvention is an intentional and proactive process designed to reimagine leadership potential (Gallagher et al., 2010). This leadership potential dives much further than the internal affairs of IT, academic research, and business acumen: it becomes a process of developing competent data leaders and equipping them with the skills they need to be successful.
The term “leadership” commands a broad umbrella of competencies and capabilities, including leadership styles, models, coaching, and more. But one thing I want to give special consideration to is ethics. Today, leaders are expected to adhere to ethical standards in the way they interact with the business and how the businesses they champion interact with and impact society. This is especially relevant in the world of data, and analysts and researchers in the business intelligence and big data industry have written extensively on the need for ethics in various aspects of the emerging data-centric culture. Whenever technology innovation—such as big data—moves faster than society, business, and people can handle, the question of ethics inevitably comes up. Business ethics have always been an issue, and today this includes the business use of data with known—and unknown—customers and consumers.
As we start to consider the governance, privacy, security, and other ethical quagmires that face the big data democracy that is gaining momentum with every advancement the importance of ethical conduct becomes increasingly more imperative. This will be the lens for how we approach the next chapter.