Chapter 4
Navigating ethics in the big data democracy
Abstract
This chapter explores many new and emerging questions that we are only just beginning to consider regarding, how we can (or should) approach navigating ethics in the big data democracy, including with data visualization as a tool for communicating information.
Keywords
data democracy
data ethics
ethics
morality
big data
leadership
“Ethics is knowing the difference between what you have a right to do and what is right to do.”
—Potter Stewart
4.1. Introduction
This chapter begins, ironically as ethics could (and does, often) easily provide enough fodder for a book on its own, with one of the simplest introductions in this book.
With the arrival of big data, companies have a huge opportunity to capitalize on—or even exploit—information for business value in new ways. By this point in our discussions (as well as your general understanding of the data industry), this should not come as a bombshell of new insight. It should be more of an accepted truth. We have more data, with more diversity, from more sources, and with more people contributing to the pool of information available than ever before. We have more ways to work with this data, too, and more motivation to use it in novel ways to disrupt industries and transform our businesses. However, we still have to figure out how to do this—both in the operational sense (through technologies, architectures, analytical models, and so on) as well as philosophically. Many of these are new and emerging questions that we are only just beginning to consider. I like to refer to these as a new generation of ethical quagmires—how we can (or should) approach navigating ethics in the big data democracy.
Ethics is one of those conversations that has the tendency to either get people fired up or to do the exact opposite—bore them to death. I happen to be among the former. In fact, discussions regarding big data ethics are actually some of my favorite discussions to have, and those that generally get the most animated when I have the opportunity to engage in them with live audiences. Often these bleed over into more in-depth conversations on peripheral (and just as important) topics, such as governance, privacy, best practices, and so on, and how we can combat ethical ambiguities by anticipating them in our system designs. However, for this chapter we will stick to ethics and the morality of the collection and use of big data, how these affect our data-driven decisions, and how we communicate these with data visualization. Primarily, we will explore these through personal applications of potentially sticky ethical data situations, case studies, and by engaging in real-life, thought-provoking exercises.
4.2. Aftershocks of the big data revolution
Like so many things top-of-mind in the data industry, this conversation begins with focusing, again, on big data. In chapter: Seperating Leaders From Laggards, we paid homage to big data as the Incredible Hulk of BI, though it has been little more than an undercurrent in the previous few chapters without any concentration. This was intentional, as I have reserved the big data conversation for now. Definitions offer good starting points, so let us begin there.
Big data is a term used to describe the massive data sets (and related analytical techniques) that are too large and too complex to rely on traditional data storage, analysis, and visualization technologies. It is shaped partly by ultra-fast global IT connections, the development and deployment of business-related data standards, electronic data interchange formats, and the adoption of business database and information systems that have facilitated the creation and disbursement of data (Hsinchun et al., 2012). Contributing to this, the willingness of consumers to directly share information about themselves and their preferences through web services and social media has further enhanced the volume and variety of complex unstructured and customer sentiment data available for interpretation and use (Nunan and Di Domenico, 2013). The widespread and robust amount of data generated has led to an increased reliance upon data by the business, and big data strategies are now a critical component of business objectives as organizations seek to maximize the value of information.
To capture this surplus of ever-generating information, the advent of new technologies—such as cloud storage and new database types—has made collecting, storing, and analyzing big data increasingly more cost-efficient and manageable for the business. This has been accomplished in part by what is commonly referred to as Moore’s Law: the steady continuance of technology capacity—that is, computing hardware—to double every two years, complemented by simultaneously improving efficiency and cost reduction of hardware (Ramana, 2013). For the business and its bottom line, this is good: the need to garner and exploit insights from collected information is a foundation of most business strategies, providing a key-in-lock mechanism to reach established business metrics and quantify strategy efforts. We now have more technology to truly make use of our data in ways we never could before.
It would be fair to say that “big data” has been the linguistic power couple of the data industry for the past decade or so. This is for good reason. It was not too long ago that large volumes of information were available only to the selected few able to afford the expensive IT infrastructure to collect, store, manage, and analyze it. These were the big budget companies with seemingly bottomless pockets, or the Internet companies that built empires on collecting and interpreting data—those with the Big Budgets to invest in Big Iron. But now, with new technologies and through the realized effects of Moore’s law as described earlier, along with the consumerization of BI and analytics tools, this big data is increasingly available to everyone—and without having to dig deep into budgets or employ robust IT departments. This is especially important for small (and newer) businesses that need access to data to survive and thrive. Widespread access to data is empowering these organizations to easily and affordably access, collect, and analyze data to create new opportunities within their markets and customers. This is the quiet momentum of “data democratization” that has emerged in the wake of the big data revolution. Through the emergence of web-based data collection and analysis and richer self-service technologies, this data democracy is enabling fast access to actionable insights. As a result, organizations, from the massive to the miniscule, are racing to get a handle on their big data.
Race they should. Big data equals more information and information, as we all know, is power. Access and insight into data drives innovation and competition. Likewise, it is the ability to index and integrate information to improve performance and create opportunity. It is the grease that oils the gears that spur innovators to innovate, creators to develop, and marketers to market—what GoodData CEO Roman Stanek aptly termed “the oil of this century.” More important, individual consumers are becoming the new market research companies—and they are ready to capitalize on their data. There is a greater emphasis on mobile engagement and a mainstream willingness to share data online, including behavioral data. Users themselves are generating a huge chunk of all the new data that we are using in our advanced analytic efforts today. In practice, this is where that visual imperative becomes so worthwhile: sometimes the best—or only—way to truly make sense of this big data is via the power of data visualization. We have to literally see it to understand it.
However, the continued proliferation of big data does not simply offer promise and opportunity. It has also raised concerns over privacy, security, and the guiding principles surrounding the collection, storage, aggregation, distribution, and use of sensitive information. While big data presents a convergence of technological and strategic capabilities that provide significant potential for data-driven organizations to squeeze the value out of information, it also brings the potential to use this data unethically. Because of this, one of the most pressing concerns in the development of future information leaders is the focus on developing ethical competencies to engage in an increasingly data-dependent business environment. And it brings top-of-mind unique questions on how users contribute to and participate in the big data democracy, too.
One of the most salient themes in these concerns relates to the nature of knowledge and its connection with power. Along with the “Power of Knowing” comes the obligation to use this knowledge responsibly. While laws will set the legal parameters that govern data use, ethics establish the fundamental principles of “right and wrong” critical to the appropriate use of data in the technology age—especially for the Internet of Things. Unfortunately, though the concept of ethics is important, it rarely receives much attention until someone does something perceived as “unethical.” The black and white guidelines of laws and regulations typically appear in hindsight—until we know something is “wrong” to do (or, until we do something that has what are generally agreed to be widespread negative consequences), it is unlikely that such rules will appear.
Therein lies the rub: now that we have the chance to get our hands on all kinds of new and exciting data, what can we do with it? And more important, what should we do with it? While ethics in big data is bound to get more complicated as data-dependency, data democracy, and technologies advance, if we do not institute ethics cultures, education, and policies now it will only become more difficult down the road.
Big data exists in an environment of duality, with one side the potential and opportunity embedded in the untapped value of information and insights learned in analytical discovery processes, and the other a mixed bag of concerns for privacy, quality, and the appropriate use of information, and its impact on society-at-large. Data-driven companies must proactively implement a culture of ethics that will set precedents in how it approaches the appropriate use of, responsibility for, and repercussions for data’s use by leaders who rely on data to make decisions and take action within their organizations. Providing future technology leaders with a foundation in ethical responsibility and accountability will support the emergence and nurturing of complementary leadership competencies in emotional and cultural intelligence; transformational and adaptive leadership; and critical thinking and decision-making. We will discuss this leadership aspect in greater detail toward the end of this chapter, but first let us talk through a few key areas that may have an especially big ethical footprint.
4.3. Big data’s personal impact
One of the most effective ways to make a philosophical conversation about ethics impactful is to make it personal. In this, big data ethics are no different. Big data opens up opportunities to use customer and consumer information in new ways, many of which pose the potential for exploitation. However, it would be a mistake to think that all this data is stuff that is being collected about us. As mentioned earlier, much of this is data that we are generating about ourselves. Through our digital activities, people are one of the biggest contributors to the ever-deepening pool of big data, and we are generating an avalanche every minute of every day. Don’t believe me? Let us quickly review some of the data on big data.
Take a look at the infographic (Figure 4.1), which was presented by Domo in 2012. As you can gather from its title, the infographic was intended to illustrate how much data is generated by people every minute of every day. And, it does what an infographic is designed to do: it allows us to see some immediate takeaways into very big numbers. For example, we can see that for every minute of the day in 2012, we pinged Google with over two million search queries. We collectively sent about 204,166,667 emails. We spent a lot of time building and sharing content, with hundreds of new websites and blog posts per minute. We were also starting to really get into the groove of social media: 3,600 photos on Instagram per minute; 100,000 tweets, and so on.

Figure 4.1 Data Never Sleeps, Infographic by Domo
The problem with this data—as is so often the problem with data these days—is that the 2012 infographic very quickly became outdated. Thus, Domo updated its infographic in 2014 (Figure 4.2). More than just an update on our digital activities, in the mere space of two years we can already spot some major trends in how we are behaving digitally.

Figure 4.2 Data Never Sleeps 2.0, Infographic by Domo
Between 2012 and 2014, we started to send slightly fewer emails (a small decrease from 204,166,667 emails to only 204,000,000). We apparently got a lot more curious—twice as much in fact: our Google searches doubled from 2 million a minute to 4 million. We also spent less time building content online and more time sharing content and details about our lives and our opinions. Tweets per minute nearly tripled and Facebook, Pinterest, Tinder, and other social platforms all leap frogged. Take a look at Instagram, which grew from 3,600 new photos a minute in 2012 to 216,000 new photos in 2014—that is an increase of 6,000%. Flipping between these two visuals suddenly that 2012 infographic just seems…so 2012. I am willing to bet that when Domo produces an even more updated infographic (which I hope they do), 2014 is going to look pretty historical already, too.
We have been busy generating a massive amount of data—all that digital activity—about ourselves, on top of all the other data that is coming in from everywhere else, like sensors and wearables, or our sales transactions at the super market. And it is safe to assume that all that data is not just languishing in some ignored data warehouse somewhere (though some probably is until we can figure out how to use it). How is all that data about us being used? And, beyond just the sum of the data points, what does it say about us—the users?
This was the question I asked a room full of attendees in a recent session at the 2015 TDWI Boston Analytic Experience conference, where we enjoyed a lively, open dialog about the emerging technological, commercial, and moral issues surrounding big data. In that session, we focused on five key areas in which big data may impact the lives of people without their immediate knowledge, from protecting their social relationships to preserving individual privacy in a public world. Let us explore those briefly now.
4.3.1. Social graphs
Social graphs are our network of interconnected relationships online—from our LinkedIn professional networks to our personal Facebook networks, and everything in-between. To truly appreciate the complexity and connectedness of social graphs, we have to first quantify how many people are on social networks.
Of the near 3 billion people on the Internet (some numbers say this number is 2.4 billion, others put it closer to 2.95 billion), 74% are active social media users. In January 2014, the Pew Research Center released its Internet Project Omnibus Survey. This survey and its takeaway percentages is outlined above in Figure 4.3. What is interesting about this data is how surprisingly even all of the percentages are. For example, there is no significant gender gap amount social media users, with 72% of men and 76% of women engaged. The same type of spread appears through levels of education and income. The only statistically significant differences are in age range demographics, but these come with a few caveats. First, there was no data collected on users under the age of 18. Likewise, a noticeable lag in use evidences in the over-50 age demographic, but there are a wide number of environmental factors that influence this segment, too (including mortality rates, familiarity with technology, and other health and medical concerns that limit Internet access).

Figure 4.3 Survey Data on Who Uses Social Networking Sites, Presented by the Pew Research Center’s Internet Project January Omnibus Survey
Without getting lost in the weeds on the various segments described, we can assert simply that, as a general rule of thumb, most people are online. It is pretty much an equal opportunity platform that truly encourages people of all ages, backgrounds, and demographics to connect, making true on its longtime promise. However, we need to be able to put this in a more personal context. One way to really be able to recognize just how complex and interconnected your social network is to visualize it. Take a look at Figure 4.4. This is an example of a social graph. Using Socilab—a free online tool—I visualized the first 500 of my personal LinkedIn connections. From a personal perspective, what I find interesting is what I can infer about my relationships via these connections. I can make certain assumptions about the denser portions of my network and assume that these gray areas are my friends, colleagues, peers, and associates in the greater business intelligence industry. Likewise, I would guess that similar clusters might be various academic networks that I am heavily involved with. What is even more curious is interpreting the disconnect outliers at the outer ring of my network. Who are those people, and why are not they connected to at least one other person? I am usually fairly discriminatory on whom I connect with and would not expect to see so many disconnected “connections.” Do you see the same patterns in your social graphs? What do these connections say about me, and what does it say about them?

Figure 4.4 This Social Graph was Created via the Free app at Socilab.com
It visualizes the first 500 of my personal LinkedIn connections
It visualizes the first 500 of my personal LinkedIn connections
Looking at your social graph is a fun personal exercise, but in the scope of big data ethics it is important to remember that you are not the only one looking at your network. For example, Facebook is somewhat infamous for its Graph Search, a semantic search engine introduced in March 2013. This feature combined the big data acquired from its billion-strong user base and external data (including that from Microsoft Bing) into a search engine to provide user-specific search results (eg, it could show you which restaurants in London your friends have visited). Graph Search was met with a whirlwind of privacy issues (including its share of hoaxes, like one that announced that the app made private Facebook content visible to strangers) and after being made public to users in July 2013, Facebook changed its graph search features, dropped its partnership with Bing, and eliminated most search patterns by the end of 2014. However, while Facebook’s Graph Search did not exactly take off, other companies working with social graphs as a part of marketing research, are. One example is Boulder, CO-based startup Spotright, which has developed a patent-pending social graph platform—GraphMassive™—that maps billions of consumer relationships and interests across social media with individual-level offline data (ie, demographics). Using data and relationships provided from analyzing your personal social networks, social graphs can be a tool for marketers and data-driven companies to amp up their efforts in targeting marketing and segmentation. How do you feel about that?
4.3.2. Data ownership and data memory
Data ownership refers to who owns—or should own the legal right to and complete control over data. Data memory compounds data ownership by looking at the length of time data can be stored or recalled. These are often addressed as two distinct categories, but for the sake of brevity I will combine them here.
In the scope of data ownership and memory, what is perhaps most interesting is the juxtaposition between who we—as consumers—think should have ownership and access to data versus who actually does. Figure 4.5 on the next page is a data visualization of the 2013, J.D. Power and Associates Consumer Privacy Research Study. Notice how noticeably different ideas our ideas are about who we think should access data—from our friends and families to the government—and how even our own ideas about this change across different devices and activities.
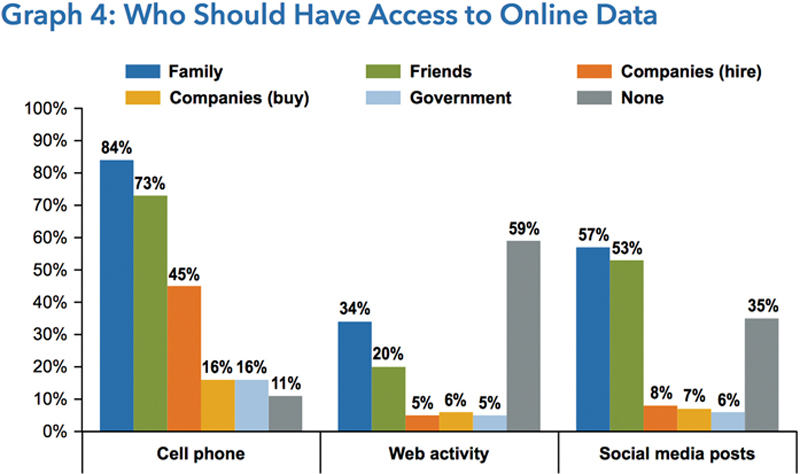
Figure 4.5 Results of the 2013 J.D. Power and Associates Consumer Privacy Research Study
It would appear that for our cell phone data—texts, pictures, or maybe even game app data—we are basically okay with our family members having access to all that data. However, we do not want that same group of people to look into our web browsing history. In fact, we do not really want anyone to access our web activity data, especially not the government. I suspect that we are okay with companies we work for (hire), having more access to our cell phone data because so many of us use company-provided or BYOD programs at work. Other than that, we really do not want companies—whether those we work for or buy from—to have access to our data.
It is worth mentioning, too, that data that is private now may be public later. Facebook—this time its Timeline—is again a perfect example for this scenario. With changing privacy settings, what is posted as a private post to be shared with only friends, family, or a defined group, could very likely be changed to a public, globally-shared post at some point in the future. It is up to the user to continuously stay abreast of privacy policy changes, as well as new platform updates that can alter the way their data is openly viewed by the public. This brings up many questions regarding the longevity of data and the statute of limitations on how long the data you generate can be used for—or against—you.
4.3.3. Passive data collection
Passive data collection is one that has the potential to go from really cool wearable devices (the focus of a later chapter) to really creepy Big Brother behavior—and really fast. In a nutshell, we can articulate this concept as data that is being collected without the express consent of the user at the time of collection. This includes everything from mob-mentality—or, opt in once and “fugget about it”—passive data collection (such as data that is collected via an app that has a one time opt-in clause at installation) to the other end of the continuum, where data is collected without the person being aware that it is even being collected, never mind what it is being used for. In the latter we could group things like security footage or traffic cameras.
As a personal example to give this some shape, my family recently moved across country. My son and I drove a total of 1600 miles, stopping at gas stations, convenience stores, restaurants, and hotels. Using my in-dash GPS for navigation, we crossed nearly ten state lines, drove on half a dozen toll roads. I cannot even begin to guess how much data this trip truly generated, who has access to it, or how it is being used. I would like to believe that it is being used for altruistic purposes, like to assist in traffic management optimization efforts or to measure the performance of my vehicle, but in the end I just do not know. Do you?
4.3.4. Privacy in a public world
Each of the brief sections above—and many more—roll up under one larger ethical umbrella: privacy in a public world. It begs the question, how much privacy do we have when almost everything is public? Privacy itself is a bit of a paradox, as the concept of privacy is often cultural or based on geography (eg, Europeans have different perceptions of—and rules around—privacy than the United States), it changes over time, and is largely subjective. It is an understatement to say that digital activity is pervasive. It has become a way of life. Companies are taking to social media to communicate directly with customers. We are being forced to rely on apps and our devices in every day interactions—like urgent travel update notifications (delays/cancellations), confirming doctors’ appointments, or even refilling prescriptions. With so many things “going online,” if we choose not to engage with technologies in certain ways—that is, if we are not on Facebook or if we buy a car without a GPS—are we on our way to being excluded from everyday social interaction? For example, without the digital services offered by a smartphone app for local traffic, we are often excluded from seeing real-time traffic updates, which can make our work commute or other travel needs suffer, if we are unable to see potential roadblocks in our path. What about every day social needs hosted through Facebook group or event pages that make having a profile a requirement? How connected is too connected?
4.4. Exercise: ethical data scenarios
Ethics is deceptively simple in the abstract. When given a choice between two actions, most of us can quickly identify—on the surface—the difference between one that is “right” and one that is “wrong,” however, most matters are not that black and white. Ethics exist on a continuum of shades of gray. So, let us have some fun and try out an exercise. In the next few sections, I will present you a few potential (and very realistic) ethical scenarios. I invite you to play along in this experiment, and consider how you might respond in the following situations. Would you feel differently if you were on the opposite side of the table in any of these—if your role changed from the head of analytics to the consumer demographic in question? Why, or why not?
4.4.1. Scenario one
Imagine you are the head of analytics at a major insurance provider. Your CDO asks you to create a social media presence to connect with customers’ (and their networks’) publically shared data. So, you do. Your CDO then asks you to mine social activities of customers to identify those who engage in extreme sports. Is it ethical to use this kind of customer data to adjust policy rates?
Considering this scenario from the consumer perspective: You are a Facebook user and “like” your insurance company online. Recently, you uploaded pictures to your page of you and some of your friends base jumping off of Royal Gorge Bridge, 956 feet in the air of Canon City, Colorado. By liking your insurance company’s page, you are helping them to build a deeper view of the customer (you) as well giving them permission to engage with you on the platform. By tagging your friends, you are also inadvertently sharing insights into your social network—some of which may or may not also be customers. They see your pictures and upgrade your risk category.
But what if you tried base jumping once, hated it, and vow never to do it again? The pictures are a one off, bucket list thing and not an indicator of your every day behavior (or is it—maybe it is a prediction of what you might try later). Is that one experience enough to change your risk category? Should you have to worry about what you post on your personal Facebook page in fear that you might be subject to negative consequences by an agency that is supposed to help you? And, what about base jumping customers who are not on Facebook? They do not get the policy increase simply because they are not engaged in social media? That certainty does not seem right. So, if your online connection with the insurance company penalizing me, maybe you should not “like” them and they need to rethink their engagement model?
4.4.2. Scenario two
You are the head of analytics at a major retailer. You are asked to create a mobile app to engage customers in the store with promotional offers, coupons, etc. Your company also wants to sell its app data to its partners for targeted advertizing and cross-selling opportunities. How would you feel about exchanging customer behavioral data with third parties for the opportunity to gain better insight?
Again, here is a context to consider: I am your customer, in your store, using your app. Thanks to the location sensors in the app, your system notices that I am hovering around in the formalwear section and pushes me a coupon for 20% off on any formalwear purchase. I use the coupon, so you can be reasonably sure that I bought some type of fancy new attire. I might need shoes to go with it, and your partner shoe company is located in the storefront next to you. Is it okay for you to give them my data so they can send me offers, too?
This one is a little more complicated than the previous. Many customers might actually be quite happy if this happened: it saves them money on things they likely want or need, it is prompt and timely, and it is easy to ignore if they do not need it. When I have shared this example, eight out of ten people seem agreeable to it. However, there are still those who think it infringes on their privacy and will bring up the big data “creep factor” at being stalked while shopping. Sure, using the app is voluntary, but if—like many stores—the only coupons available are on the app, it makes it hard not to use it. Again, it is almost a privacy tax not to use the app (and thus not have access to the money-saving coupon). Is this a situation where, as Mr Spock so famously said, the needs of the many outweigh the needs of the few? Is there a way to keep both the majority and the minority happy shoppers, or is that small percent worth losing?
4.4.3. Scenario three
You are the head of analytics at a social networking site. Your CDO wants to allow researchers access to user-generated data in order to alter the user experience to conduct experiments on user sentiment and behavior. Is it ethical to manipulate user emotions even if it is for academic or medical research?
This scenario never fails to elicit some kind of immediate, visceral response from an audience (I think it is that word “manipulate”). No one seems to be fond of the idea of turning over data to researchers and letting them play with it, especially when we do not know it is happening and there is the real possibility that they are literally toying with our emotions. But, with things like cyber bullying constantly making headlines, what if these researchers do find an insight on how teenage suicides can be linked to what they see on social media and this discovery can save lives? Does it make a difference if we know the end goal of the research or not—the idea of informed consent? What about if we know that it is going on versus finding out about it later?
4.5. Data ethics in the news
If this last scenario presented in the earlier section sounds strangely familiar to you, it is probably because it is not hypothetical. In fact, something very similar happened in 2014. Moreover, these kind of sticky ethical data circumstances creep to the top of tech news very often. This section will look briefly to a sample of situations of companies not-so-ethical use of big data that have made big headlines.
4.5.1. Facebook
The fact that we can pick on Facebook so much as an example of all things good and bad about the most data-centric companies is a testament to just how much Facebook is pushing the envelope when it comes to operationalizing its customers’ data. As of the second quarter of 2015, Facebook had 1.49 billion active users worldwide. To put that in perspective, consider that the population of China—the entire country—is just shy of that number at an estimated 1.39 million (as of July 2014 by Worldometers). (If you are inclined, there is an interesting static timeline visualization that shows the increase of active Facebook users from 2008–15 at http://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-worldwide/.)
With that amount of people contributing data with every click and scroll, one can only imagine just how much data Facebook really has. And, just like its user community, we can see a similar growth curve in the amount of infrastructure Facebook needs to manage all of that data. Exact details are proprietary and this is not the place for a technical discussion on how all of this data is managed, but reports from 2014 quantify the amount of data Facebook stores as some 300 PB in addition to a daily intake of about 600 TB (Cohen, 2014). (It also boasts a staff of over thirty data scientists—see research.facebook.com/datascience.)
Facebook is a hub for market (and other types) of research. In summer 2014, researchers associated with Facebook, Cornell, and the University of California-San Francisco participated in a social media-based emotion experiment (Waldman, 2014). The paper, which was published in the Proceedings of the National Academy of Sciences, revealed that the researchers intentionally manipulated the Facebook news feeds of nearly 700,000 of its users in order to study “emotional contagion through social networks” (Kramer et al., 2014). For the study, researchers tested the affect on user’s emotions by either reducing the number of positive or negative posts that were visible on users’ news feeds. This experiment raised a number of red flags, including whether university’s or Facebook financed the survey. Here is the nutshell version of the research design: certain elements were hidden from 689,003 peoples’ news feed (about 0.04% of users, or 1 in 2,500) over the course of seven days in 2012. The experiment hid a “small percentage” of emotional words from peoples’ news feeds, without their knowledge, to test what affect that had on the statuses (including likes, commenting, or status sharing) that they posted or reacted to. The expectation was that news feeds did not affect users’ mood and were simply social content hovering on the Internet. Contrary to this expectation, the researchers instead found that peoples’ emotions were significantly affected by their news feeds. This phenomenon is what the researchers dubbed as “emotional contagion, or the ability for emotions to be contagious and spread virally through social content” (Arthur, 2014).
The most significant criticism of the emotion study is that it did not conform to the principles expressed in the widely regarded cornerstone document on human research ethics, the Declaration of Helsinki, which mandates that human subjects be adequately informed of, among other things, the potential risks of the study and any discomfort it may entail. This is the premise of informed consent. Because it affected users’ moods (both positively and negatively), this “unethical experiment” harmed participants, and it forms the basis of widespread malcontent of the study. However, one of the researchers noted in a lengthy defense (which was published on Facebook) that the primary purpose of this study was altruistic. Kramer wrote, “The reason we did this research is because we care about the emotional impact of Facebook and the people that use our product” (Kramer, 2014).
The end result of the Facebook emotion study is that we learned that social media exposure does affect people’s moods. We can now use this information to avoid or address certain issues, perhaps such as cyber bullying or other social problems. While that is the result, the question still remains: does this benefit overshadow the fact that a percentage of Facebook users were unknowingly subjected to emotional experiments?
4.5.2. Target
As the name behind one of the biggest urban legends in predictive analytics history, retailer Target is widely believed to have predicted the pregnancy of a 16-year old girl before even her father knew—which was a big surprise when coupons for baby wares arrived in the family’s mailbox.
The legend began when a conspicuously titled story—How Companies Learn Your Secrets—by Charles Duhigg went live in a February 2012 New York Times article, followed by many similar titles that reported on the same topic. The story was largely theoretical, and detailed the work of statistician Andrew Pole (and Target’s Guest Marketing Analytics team), who did indeed design a pregnancy prediction model (starting with the information and behavioral data of women enrolled in Target’s baby registry). Pole’s work, by the way, was not too terribly different than research from the 1980s by a team of researchers led by a UCLA professor, who undertook a study of people’s most mundane shopping habits to predict major, albeit predictable changes that might impact purchasing behavior. All in all, simply understanding how habits work makes them easier to control—and predict. Nevertheless, as Pole crawled through the data, he was able to identify a few dozen products that when analyzed together, gave him the ability to assign a shopper a “pregnancy prediction” score, along with the ability to estimate a delivery date by taking buying trends and timelines into consideration. These analytics were not aimed at predicting when pregnancy would occur and proactively try to secure consumer loyalty with personalized offers, but on sending relevant offers to customers during specific stages of pregnancy.
Then, as many may recall, there was the story of the dad that reportedly walked into Target armed with a mailer of baby coupons and upset that his daughter had received them. He later recounted and—somewhat abashedly (per quotes printed from here to Mars)—admitted that he had not been aware of all things happening under his roof and his daughter was indeed pregnant. After this incident, according to Duhigg’s article, Target went quiet and no further communication was contributed to his article—in fact, from reading his article you would get the idea that Duhigg was forcibly silenced by Target’s cold-shoulder. The trail went cold, but the public spotlight only grew brighter—due in part to a second article, Kashmir Hill’s How Target Figured Out A Teen Girl Was Pregnant Before Her Father Did (2012), which was published on the same day as Duhigg’s but in short-form. Hill’s article cut through the fat of the longer New York Times cover piece with some carefully tweezed quotes that left readers with one clear message that went viral: Target is watching you.
What was not made clear in the original article is that this was not a piece of investigative journalism. It simply reported on work presented by Pole himself in 2010 at the Predictive Analytics World Conference (PAWCon) entitled “How Target Gets the Most out of Its Guest Data to Improve Marketing ROI” (which is still available and free to view online at www.pawcon.com/Target).
So, did Target really predict that teenager’s pregnancy and take advantage of the opportunity to send targeted marketing offers to a soon-to-be teen mom? As Eric Siegel (founder of PAWCon) wrote in his book, Predictive Analytics: The Power to Predict Who Will Click, Buy, Like, or Die (2013), this probably is not how it actually happened. This is for two reasons, according to Siegel. One it took an implication and made it fact, and two, Target “knows” consumers value privacy and thus might not enjoy being marketed to on such a private matter, and the retailor actively camouflages such product placements among other nonbaby-related products.
Thus, we are left with two different questions—can Target predict a customer’s pregnant, and did it do so (and will it continue to so/do it again)? The ethical implications of either question are likely as fundamentally different as the questions themselves.
4.5.3. Ashley madison
One of the most recent data hacks you may be familiar with is that of online adultery site, Ashley Madison. With the tagline of “Life is Short, Have an Affair,” Ashley Madison had amassed a user base of over 37 million users worldwide (including about one million from the UK). In July 2015, a hacking group calling themselves The Impact Team hacked Ashley’s Madison database, stealing the personal and private details of those using the website and threatened to release the data to the public if the website was not taken down. As evidence of its threat, 40 MB of data was initially released, which included internal files and documents from the parent company, Canada’s Avid Life Media (ALM) (Kharpal, 2015). The motivation for The Impact Team’s hack was ideological in nature: the group said they targeted the ALM and its subsidiary sites because they do not agree with the morality of the service (one statement from The Impact Team referred to the site(s) as prostitution/human trafficking for rich men to pay for sex (McCormick, 2015)), as well as the fact that it is supposedly littered with thousands of fake female profiles which prey on other users.
In August 2015, after Ashley Madison’s website owners, ALM (which also runs sister sites Cougar Life and Established Men, both of which are designed for users to arrange sexual encounters), refused to shut down operations, just under 10 Gb of data was released, including the names, email addresses, passwords, and bank details of accounts of users associated with the site (Tidy, 2016). The data dumped online, which by all accounts by investigators and data experts looks completely legitimate, includes some interesting names and affiliations. Personal data—including the names and, in some instances, credit card information, of approximately 10,000 email addresses that appear to be associated with government (including political party members) and military accounts (Williams, 2015) were also included in the data dump. The site users themselves were caught in the crossfire, and when Ashley Madison ultimately refused to shut down the site, the hackers made good on their threat to dump the 9.7 GB of stolen data if the site was not shut down as demanded. However, they dumped it in a place were the average person would not find it: the “dark web,” which is only accessible through the Tor network (Dark Reading Staff, 2015).
Some call the act by The Impact Team “hactivism,” the art of gaining unauthorized access (or “hacking”) into a computer system for a politically or socially motivated personal goal. Others say that it is simply one of criminality. There are those, like Ashley Madison CEO Noel Biderman, who has been quoted as saying that “cheating is like the secret glue that keeps millions of marriages together” in order to justify hi-tech infidelity (Kharpal, 2015). Still, morality issues aside, the data hack is an illegal act against the individual members of AshleyMadison.com as well as against personal privacy and freedom to engage in lawful online activities. What do you think?
4.6. The data visualization hippocratic oath
Before we move forward into assessing the type of leadership competencies needed in an ethically-aware big data culture, it is worth a quick aside to realign the conversation thus far to data visualization and the visual data culture which is the heart of this text. One of the most potent applications of ethics to data visualization is through data journalism. Armed not only with more data but also with data visualization, data journalists wield an incredible amount of power into how to mislead with numbers. There have been numerous examples of “good data viz gone wrong” by news organizations that have unintentionally—or perhaps intentionally—produced faulty data visualizations (The New York Times has been criticized for this in a number of occasions). We will discuss data journalism more in a later chapter on visual data storytelling, but a brief mention here provides the perfect opportunity to briefly make a meaningful connection of ethics to data visualization.
Many in the data visualization industry have suggested—even demanded—the need for a sort-of data visualization Hippocratic Oath to guide data journalists and other types of business users generating data visualizations. This oath is intended to go beyond things like data visualization best practices to offer a simple and succinct essence of responsible visualization. While there is no officially recognized (or sworn) Hippocratic Oath for data visualization, at VisWeek 2011 Jason Moore of the Air Force Research Lab suggested an oath that has since been accepted by many, echoed on the blogs of data visualization galleries, practitioners, and even a few vendors and creative services.
Moore’s Oath is written simply as thus:
“I shall not use visualization to intentionally hide or confuse the truth which it is intended to portray. I will respect the great power visualization has in garnering wisdom and misleading the informed. I accept this responsibility willfully and without reservation, and promise to defend this oath against all enemies, both domestic and foreign.”
Taking Moore’s Oath one step further, I would like to add the following: I will engender the continuation of best practices and awareness of design principles in data visualization, and I will view visualizations first from the perspective of the receiver than of the creator.
The latter plays an important part in the newly formed Data Visualization Competency Center™ that I introduced at Radiant Advisors in 2015. However, this cursory mention of ethics and data visualization accomplished, let us put a pin in this topic for now and continue to narrow our focus on ethics and data leadership.
4.7. Ethics requires leadership
Coming from a background in leadership studies, I could not resist the urge to spend time talking about leadership in the context of ethics. One of my favorite quotes from the literature on leadership comes from New York Times best-selling business and management author John Kotter and is readily applicable to our current state of disruption and innovation in the data industry. In A Sense of Urgency (2008), Kotter writes that creating a sense of urgency is the “first step in a series of actions” critical to avoiding stagnation and achieving success in a rapidly changing world. To achieve this sense of urgency, leaders must commit to identifying and resolving issues that create obstacles to success. They must foster change initiatives, celebrate short-term wins that open pathways to larger goals, and they must make changes stick by incorporating them into the organizational structure, processes, and culture (Kotter, 2008). This statement resonates profoundly when applied to the ethical quagmires faced by big data. We must first and foremost embrace a sense of urgency in developing future technology leaders by fostering growth in critical leadership competencies needed for a strong foundation of ethical leadership in a dynamic data economy.
This ethical foundation begins with perspective. Developing leaders must be aware of their ethical responsibilities not only to their organization, but also to the people inside the organization, those it impacts, and society as a whole. However, an organizational structure itself (including the requisite policies and codes of ethics) does not guarantee ethical behavior unless the leadership actively demands that those policies are followed and values demonstrated.
Therefore, ethical leaders must have the courage to take action when the organizational acts unethically, even if it damages profits or has an otherwise unfavorable result on the business. As part of what Freeman and Stewart (2006) defined as a “living conversation” of ethics within an organization, just as important as the ability for leaders to take action against organizational objectives or actions perceived as unethical are mechanisms for leaders—and others within the organization—to voice concerns or “push back” too. These processes, which can be anonymous to avoid any perceived barriers or retaliation responses, are critical to avoiding the likelihood of values becoming stale or overlooked. Additionally, having this living conversation about ethics and behaviors throughout all levels of the organization provides a measure of accountability and transparency (Freeman and Stewart, 2006), reinforcing the organizational culture of ethical responsibility.
Continuous research is devoted to the study of big data and ethical implications—including the creation of best practices and incorporating mechanisms for feedback—however preparing future technology leaders to speak as advocates in the ongoing conversation on ethics, and the potential ethical issues surrounding big data is a vital component of educating emerging leaders. This begins first with the fostering and refinement of emotional intelligence as well as cultural intelligence and diversity appreciation. We will quickly review these next.
4.7.1. Emotional intelligence
Seminal research by researchers Peter Salovey and John Mayer (1990) posited that, as humans, we have developed an emotional system that helps us to communicate problems. They coined this system “emotional intelligence” (commonly referred to as EQ). EQ is defined as the ability to monitor one’s feelings and those of others, and to use that information to guide thinking and action (Salovey & Mayer, 1990). Later evangelists built upon Salovey and Mayer’s original work, and “[added] in components such as zeal, persistence, and social skills” (Caruso et al., 2002, p. 307). It is now considered part of the set of multiple intelligence, and proselytized by management guru Daniel Goleman (2011) who noted that IQ and technical skills are “threshold capabilities” and that true leadership edge comes from knowledge and acceptance of emotional intelligence.
4.7.2. Cultural competence and diversity in data
Diversity has an especially important impact on the assemblage, storage, and usage of big data for several reasons that extend beyond an appreciation and awareness. A primary reason is because the data itself is nearly as diverse as the mechanisms for collecting, generating, and analyzing it. There is a wide disparity in data types and origins, and the discovery capabilities of recognizing and adapting to data anomalies by many types of data users within an organization (Jonker, 2011). The commercial value of big data likewise requires a diverse application. Because much of the growth in data is due to the sharing of information directly by consumers there are implications as to the ownership of data and respecting privacy in a public environment (Nunan and Di Domenico, 2013). There is also a wide array of attitudes toward the data that is shared, and this is dependent on the social culture of where the data originates and the expectations of what data can—and should—be used for, how long it should be retained, etc.
Emerging technology leaders should be instructed in the responsiveness to a multicultural vision that assesses the cultural competence and empathy of leaders in order to help them thrive in diverse business environments. In fact, it is worth a mention that legislation for data collection, use, retention, and so forth vary worldwide as well. Thus, a widespread understanding and insight into different cultures, motivations, and norms will provide leaders with the skills to make ethical decisions when dealing with the realities, opportunities, and challenges of working in diversity and also provide them with insight into the behaviors and expectations of outside cultures (Cortes & Wilkinson, 2009).
4.7.3. Adaptive leadership as an applied approach
With the rapid rate of change, complexity, and uncertainty in the business intelligence industry, adaptive, transformational leadership is paramount to driving organizational success. The ability for organizations to mobilize and thrive in new business environments is critical, and the solutions to these challenges reside in the collective intelligence of leaders (Heifetz & Laurie, 2011). Adaptive leadership—an approach to command based on situation and factors like mission, strategy, etc.—is a trait requisite of successful leaders, however it is somewhat counterintuitive because leaders must be able to see a context for change or create one rather than respond to a need. Adaptive leadership is about leading change that enables the organization to thrive. It is the practice of mobilization, and it occurs through experimentation and requires diversity (Heifetz, Linsky, & Grashow, 2009).
Because adaptive and transformational leadership—wherein a leader is charged with identifying needed change and creating a vision to guide the change through inspiration—is individually considerate and provides followers with support, mentorship, and guidance (Bass & Riggio, 2006), it is tied to the construct of emotional intelligence. This connection between transformational leadership and emotional intelligence has been supported by several empirical studies that report a positive correlation between the two, with analysis indicating that both emotional intelligence and transformational leadership are emotion-laden constructs (Lindebaum & Cartwright, 2010). That said, the principal difference between these two theories is that emotional intelligence is applied primarily to the leader, while adaptive leadership is applied primarily to the organization. Adaptive leadership requires that a leader embrace a learning strategy to address challenges that are adaptive, or for which there are no known solutions and which require a shift in thinking (Granger & Hanover, 2012). This, in turn, denotes a need for emotional intelligence in the capacity to be self-aware and self-managing (Goleman, 2005). A transformational leader must shift perspectives in order to adapt to changes that are happening, and leverage emotional intelligence skills to motivate and inspire others to engage when confronting a challenge, adjusting values, changing perceptions, and nurturing new habits—or, behaving ethically (Heifetz & Laurie, 2011).
4.7.4. Finally, critical thinking competence
Leaders who exhibit strategic decision-making analyze ideas in a nonsuperficial way to discover logical connections for reasoning and effective judgment (Patterson, 2011). This is particularly relevant in the era of big data, as organizations must work to harness data and uncover insights and business value within that can then be implemented into business use and part of the organizational fabric.
Remember, no two leaders are the same (Bennis and Townsend, 2005). Nevertheless, developing future technology leaders, knowledge workers, and—yes—big data experts from a foundation of ethics will contribute to how we collectively approach constructing an ethical framework for leadership behavior in an increasingly murky culture of data overload.
And, while specific practices to prepare future leaders will vary for any given industry, the inclusion of a blended education model of technical and leadership skills alongside the provision of prescriptive, applicable, and practicable experiences are paramount. Leadership is an ongoing process: learning and growth happen perpetually, and sharing these cumulative experiences provide educators with the input needed to prepare ethical, next-generation leaders—regardless of industry. This will be our focus in the next chapter.
4.8. Closing thoughts
A few years ago, I wrote a book review on Big Data: A Revolution That Will Transform How We Live, Work, and Think by Viktor Mayer-Schönberger and Kenneth Culkier (2013). During that review, I had the opportunity to interview Mayer-Schönberger, and in one of our exchanges, he wrote something that has stuck with me over the years (and a quote which I included in the original review). Speaking of his book, Viktor wrote, “[We] try to understand the (human) dimension between input and output. Not through the jargon-laden sociology of big data, but through what we believe is the flesh and blood of big data as it is done right now.” As a closing thought, I would like to propose that it is our human traits of creativity, intuition, and intellectual ambition that should be fostered in the brave new world of big data. That the inevitable ”messiness“ of big data can be directly correlated to the inherent ”messiness” of being human. Most important, that the evolution of big data as a resource and tool is a function of the distinctly human capacities of instinct, accident, and error, which manifest, even if unpredictably, in greatness. And, in that greatness is progress. That progress is the intrinsic value of big data, and what makes it so compelling—but it comes at a price.
Ultimately, no one expects ethics to ever become a simple, black and white issue, and nor should it, really. However, as data and innovative technologies becomes increasingly more and more an embedded part of our every day lives, we must pay attention to the circle of interrelated ethical quagmires that we face and approach them carefully, or—as Jaron Lanier (2011) writes in his book You Are Not a Gadget, we should approach these as if they were a part of nature rather than from an externalized perspective.