Each thread requires resources—CPU and memory. It means the number of threads must be controlled, and one way to do it is to create a fixed number of them—a pool. Besides, creating an object incurs an overhead that may be significant for some applications.
In this section, we will look into the Executor interfaces and their implementations provided in the java.util.concurrent package. They encapsulate thread management and minimize the time an application developer spends on writing the code related to threads' life cycles.
There are three Executor interfaces defined in the java.util.concurrent package:
- The base Executor interface: It has only one void execute(Runnable r) method in it.
- The ExecutorService interface: It extends Executor and adds four groups of methods that manage the life cycle of the worker threads and of the executor itself:
- submit() methods that place a Runnable or Callable object in the queue for the execution (Callable allows the worker thread to return a value); return an object of Future interface, which can be used to access the value returned by the Callable, and to manage the status of the worker thread
- invokeAll() methods that place a collection of interface Callable objects in the queue for the execution; return List of Future objects when all the worker threads are complete (there is also an overloaded invokeAll() method with a timeout)
- invokeAny() methods that place a collection of interface Callable objects in the queue for the execution; return one Future object of any of the worker threads, which has completed (there is also an overloaded invokeAny() method with a timeout)
- Methods that manage the worker threads' status and the service itself as follows:
- shutdown(): Prevents new worker threads from being submitted to the service.
- shutdownNow(): Interrupts each worker thread that is not completed. A worker thread should be written so that it checks its own status periodically (using Thread.currentThread().isInterrupted(), for example) and gracefully shuts down on its own; otherwise, it will continue running even after shutdownNow() was called.
- isShutdown(): Checks whether the shutdown of the executor was initiated.
- awaitTermination(long timeout, TimeUnit timeUnit): Waits until all worker threads have completed execution after a shutdown request, or the timeout occurs, or the current thread is interrupted, whichever happens first.
- isTerminated(): Checks whether all the worker threads have completed after the shutdown was initiated. It never returns true unless either shutdown() or shutdownNow() was called first.
- The ScheduledExecutorService interface: It extends ExecutorService and adds methods that allow scheduling of the execution (one-time and periodic one) of the worker threads.
A pool-based implementation of ExecutorService can be created using the java.util.concurrent.ThreadPoolExecutor or java.util.concurrent.ScheduledThreadPoolExecutor class. There is also a java.util.concurrent.Executors factory class that covers most of the practical cases. So, before writing custom code for worker threads' pool creation, we highly recommend looking into using the following factory methods of the java.util.concurrent.Executors class:
- newCachedThreadPool() that creates a thread pool that adds a new thread as needed, unless there is an idle thread created before; threads that have been idle for 60 seconds are removed from the pool
- newSingleThreadExecutor() that creates an ExecutorService (pool) instance that executes worker threads sequentially
- newSingleThreadScheduledExecutor() that creates a single-threaded executor that can be scheduled to run after a given delay, or to execute periodically
- newFixedThreadPool(int nThreads) that creates a thread pool that reuses a fixed number of worker threads; if a new task is submitted when all the worker threads are still executing, it will be placed into the queue until a worker thread is available
- newScheduledThreadPool(int nThreads) that creates a thread pool of a fixed size that can be scheduled to run after a given delay, or to execute periodically
- newWorkStealingThreadPool(int nThreads) that creates a thread pool that uses the work-stealing algorithm used by ForkJoinPool, which is particularly useful in case the worker threads generate other threads, such as in a recursive algorithm; it also adapts to the specified number of CPUs, which you may set higher or lower than the actual CPUs count on your computer
A work-stealing algorithm allows threads that have finished their assigned tasks to help other tasks that are still busy with their assignments. As an example, see the description of Fork/Join implementation in the official Oracle Java documentation (https://docs.oracle.com/javase/tutorial/essential/concurrency/forkjoin.html).
Each of these methods has an overloaded version that allows passing in a ThreadFactory that is used to create a new thread when needed. Let's see how it all works in a code sample. First, we run another version of MyRunnable class:
class MyRunnable implements Runnable {
private String name;
public MyRunnable(String name) {
this.name = name;
}
public void run() {
try {
while (true) {
System.out.println(this.name + " is working...");
TimeUnit.SECONDS.sleep(1);
}
} catch (InterruptedException e) {
System.out.println(this.name + " was interrupted\n" +
this.name + " Thread.currentThread().isInterrupted()="
+ Thread.currentThread().isInterrupted());
}
}
}
We cannot use parameter property anymore to tell the thread to stop executing because the thread life cycle is now going to be controlled by the ExecutorService, and the way it does it is by calling the interrupt() thread method. Also, notice that the thread we created has an infinite loop, so it will never stop executing until forced to (by calling the interrupt() method). Let's write the code that does the following:
- Creates a pool of three threads
- Makes sure the pool does not accept more threads
- Waits for a fixed period of time to let all the threads finish what they do
- Stops (interrupts) the threads that did not finish what they do
- Exits
The following code performs all the actions described in the preceding list:
ExecutorService pool = Executors.newCachedThreadPool();
String[] names = {"One", "Two", "Three"};
for (int i = 0; i < names.length; i++) {
pool.execute(new MyRunnable(names[i]));
}
System.out.println("Before shutdown: isShutdown()=" + pool.isShutdown()
+ ", isTerminated()=" + pool.isTerminated());
pool.shutdown(); // New threads cannot be added to the pool
//pool.execute(new MyRunnable("Four")); //RejectedExecutionException
System.out.println("After shutdown: isShutdown()=" + pool.isShutdown()
+ ", isTerminated()=" + pool.isTerminated());
try {
long timeout = 100;
TimeUnit timeUnit = TimeUnit.MILLISECONDS;
System.out.println("Waiting all threads completion for "
+ timeout + " " + timeUnit + "...");
// Blocks until timeout, or all threads complete execution,
// or the current thread is interrupted, whichever happens first.
boolean isTerminated = pool.awaitTermination(timeout, timeUnit);
System.out.println("isTerminated()=" + isTerminated);
if (!isTerminated) {
System.out.println("Calling shutdownNow()...");
List<Runnable> list = pool.shutdownNow();
System.out.println(list.size() + " threads running");
isTerminated = pool.awaitTermination(timeout, timeUnit);
if (!isTerminated) {
System.out.println("Some threads are still running");
}
System.out.println("Exiting");
}
} catch (InterruptedException ex) {
ex.printStackTrace();
}
The attempt to add another thread to the pool after pool.shutdown() is called generates java.util.concurrent.RejectedExecutionException.
The execution of the preceding code produces the following results:

Notice the Thread.currentThread().isInterrupted()=false message in the preceding screenshot. The thread was interrupted. We know it because the thread got the InterruptedException. Why then does the isInterrupted() method return false? That is because the thread state was cleared immediately after receiving the interrupt message. We mention it now because it is a source of some programmer mistakes. For example, if the main thread watches the MyRunnable thread and calls isInterrupted() on it, the return value is going to be false, which may be misleading after the thread was interrupted.
So, in the case where another thread may be monitoring the MyRunnable thread, the implementation of MyRunnable has to be changed to the following (note how the interrupt() method is called in the catch block):
class MyRunnable implements Runnable {
private String name;
public MyRunnable(String name) {
this.name = name;
}
public void run() {
try {
while (true) {
System.out.println(this.name + " is working...");
TimeUnit.SECONDS.sleep(1);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
System.out.println(this.name + " was interrupted\n" +
this.name + " Thread.currentThread().isInterrupted()="
+ Thread.currentThread().isInterrupted());
}
}
}
Now, if we run this thread using the same ExecutorService pool again, the result will be:
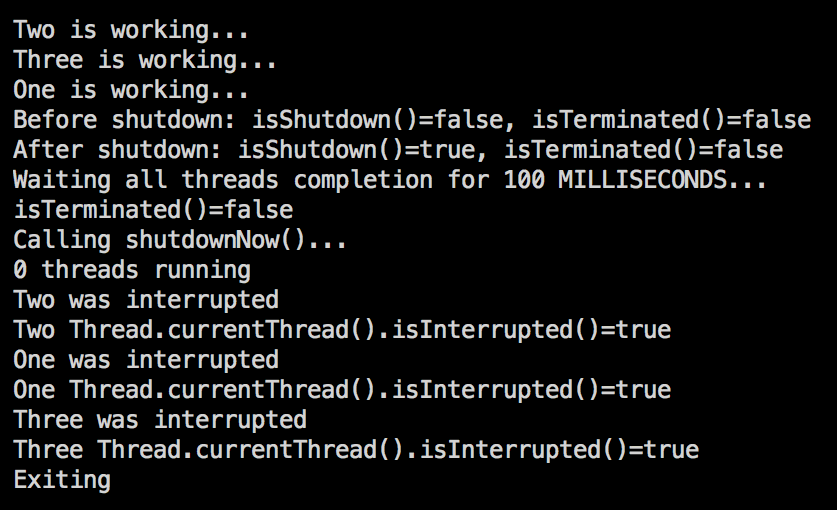
As you can see, now the value returned by the isInterrupted() method is true and corresponds to what has happened. To be fair, in many applications, once the thread is interrupted, its status is not checked again. But setting the correct state is a good practice, especially in those cases where you are not the author of the higher level code that creates the thread.
In our example, we have used a cached thread pool that creates a new thread as needed or, if available, reuses the thread already used, but which completed its job and returned to the pool for a new assignment. We did not worry about too many threads created because our demo application had three worker threads at the most and they were quite short lived.
But, in the case where an application does not have a fixed limit of the worker threads it might need or there is no good way to predict how much memory a thread may take or how long it can execute, setting a ceiling on the worker thread count prevents an unexpected degradation of the application performance, running out of memory, or depletion of any other resources the worker threads use. If the thread behavior is extremely unpredictable, a single thread pool might be the only solution, with an option of using a custom thread pool executor. But in the majority of the cases, a fixed-size thread pool executor is a good practical compromise between the application needs and the code complexity (earlier in this section, we listed all possible pool types created by Executors factory class).
Setting the size of the pool too low may deprive the application of the chance to utilize the available resources effectively. So, before selecting the pool size, it is advisable to spend some time monitoring the application with the goal of identifying the idiosyncrasy of the application behavior. In fact, the cycle deploy-monitor-adjust has to be repeated throughout the application's lifecycle in order to accommodate and take advantage of the changes that happened in the code or the executing environment.
The first characteristic you take into account is the number of CPUs in your system, so the thread pool size can be at least as big as the CPU's count. Then, you can monitor the application and see how much time each thread engages the CPU and how much of the time it uses other resources (such as I/O operations). If the time spent not using the CPU is comparable with the total executing time of the thread, then you can increase the pool size by the following ratio: the time CPU was not used divided by the total executing time. But that is in the case where another resource (disk or database) is not a subject of contention between the threads. If the latter is the case, then you can use that resource instead of the CPU as the delineating factor.
Assuming the worker threads of your application are not too big or too long executing and belong to the mainstream population of the typical working threads that complete their job in a reasonably short period of time, you can increase the pool size by adding the (rounded up) ratio of the desired response time and the time a thread uses CPU or another most contentious resource. This means that, with the same desired response time, the less a thread uses CPU or another concurrently accessed resource, the bigger the pool size should be. If the contentious resource has its own ability to improve concurrent access (like a connection pool in the database), consider utilizing that feature first.
If the required number of threads running at the same time changes at runtime under the different circumstances, you can make the pool size dynamic and create a new pool with a new size (shutting down the old pool after all its threads have completed). The recalculation of the size of a new pool might also be necessary after you add or remove the available resources. You can use Runtime.getRuntime().availableProcessors() to programmatically adjust the pool size based on the current count of the available CPUs, for example.
If none of the ready-to-use thread pool executor implementations that come with the JDK suit the needs of a particular application, before writing the thread managing code from scratch, try to use the java.util.concurrent.ThreadPoolExecutor class first. It has several overloaded constructors.
To give you an idea of its capabilities, here is the constructor with the biggest number of options:
ThreadPoolExecutor (int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
The parameters of the preceding constructor are as follows:
- corePoolSize is the number of threads to keep in the pool, even if they are idle unless the allowCoreThreadTimeOut(boolean value) method is called with true value
- maximumPoolSize is the maximum number of threads to allow in the pool
- keepAliveTime: When the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating
- unit is the time unit for the keepAliveTime argument
- workQueue is the queue to use for holding tasks before they are executed; this queue will hold only the Runnable objects submitted by the execute() method
- threadFactory is the factory to use when the executor creates a new thread
- handler is the handler to use when the execution is blocked because the thread bounds and queue capacities are reached
Each of the previous constructor parameters except the workQueue can also be set via the corresponding setter after the object of the ThreadPoolExecutor class has been created, thus allowing more flexibility and dynamic adjustment of the existing pool characteristics.