CHAPTER 5
Prototyping
Once the project has been defined and the data has been acquired and curated, it is time to start creating a prototype of the solution. The prototype will serve as a preliminary model of the solution and enable the project stakeholders to provide early feedback and course corrections as needed. Additionally, building a prototype forces a reality check on the project as a whole, since the prototype will necessarily be a vertical piece of functionality, testing that most elements of the technology stack work together.
Assuming your user stories had an initial prioritization set during the project planning step, your prototype should implement the top few user stories. In this way, you will start to see business value as soon as the initial prototype is complete. Note that the combination of user stories you tackle during this phase should leverage most of the technical components of your planned system. For instance, if using training data from a particular data source will be critical to your system's success, you should ensure that at least one of your user stories selected for the prototype step requires that data.
Is There an Existing Solution?
Before you spend resources going down the path of building an AI solution, the first question you should ask yourself is “Can my problems be solved by an existing solution?” For instance, if a business wants to have a simple automated chat capability for their customers, an all-in-one solution likely exists that can be purchased outright or licensed on a monthly basis. Some configuration is always involved (e.g., what specific questions are my customers likely to ask?), but this solution could be dramatically cheaper and ready more quickly than building a solution from scratch. There are a few ways to look for existing systems.
The first method to find out if a complete solution is available on the market is to search the Internet for your problem. Chances are, if you have a problem that needs solving, other people will have the same problem. For instance, a search for “automated chatbots products” returns an overwhelming number of chatbot product comparisons and product reviews. Problems that affect a large number of people tend to attract those with an entrepreneurial spirit who will come up with a solution to such a problem. In doing so, they may start building their own businesses and try to grow themselves. Part of this process for them will involve advertising and promoting themselves online, so given the right search terms, it is certainly possible to find online solutions for most common problems.
Another avenue for finding existing all-in-one solutions is by speaking with other businesses that have a similar capability to what you are looking to build. If you find that you are a customer of another business with automated chat technology, reach out to that company and see which path they took to provide that capability. Did they purchase a solution or build their own using open-source technologies? What previous approaches did they try that failed? What other “gotchas” and useful tips did they glean? Assuming your business is not a direct competitor, most people tend to be helpful, especially when it comes to explorations of new technologies. As you travel further along your journey toward AI adoption, you can just as easily become an ally to them and reciprocate with your own lessons learned down the road.
The added benefit of directly reaching out to a fellow business is that you tend to avoid the marketing spin that surrounds the “Google” research approach. Instead, you speak to a real user of the technology and hear their unbiased experiences with the initial setup and continued use of the product. Even insights into what the vendor is like to work with can be valuable. If a vendor has the greatest technology in the world but is unresponsive to customer support requests, you may ultimately decide that it is not worth using that technology at all or decide to hold off while you look for a suitable alternative with better support options.
The final way to learn if there is an existing solution to your problem is attending industry conferences. Especially if your problem seems like it might be only somewhat common, AI conferences that target business audiences could be a good place to research solutions. Conferences bring together both AI experts as well as business leaders who are staying abreast of what solutions are available. Given the fact that these people attend conferences, they are likely to also be well connected and able to introduce you to people who have faced similar challenges and created workable solutions.
Employing vs. Contracting Talent
If no existing solution is available, you need to ask yourself at the start of the prototyping phase, “Do I have an engineering team who can successfully build this AI solution?” This will include data scientists, developers, machine learning experts, and so on. Chances are, if you are a small to medium-sized business whose core competency is not technology, the answer to this will be “no.” Even for large companies that have been sticking with traditional technologies, this answer can often be “no.” If this is the case, you need to make a decision: “Do I build the team I need, or do I find one that is already assembled and contract with them for the job or jobs I will need done?” If you anticipate a clear end date to the work you need, or if you required the engineering team to build only your one AI system, it may make sense to outsource the job to a preexisting firm. They will be able to move more quickly with their existing experience and help you avoid any beginner pitfalls.
Finding a Firm
Finding a contracting firm that you can trust to deliver your AI system is similar to finding an employee in some ways. For example, you will want to see examples of their previous work that implements capabilities similar to the ones you want in your AI system. Most firms should be able to provide case study documents for similar projects. Asking to see these systems with a live demonstration is also a good way to continue the conversation and do some due diligence. Drill down and ask if the system they built is still in use today, and if not, ask why. Additionally, ask if they are still performing work for that same client today. It can be a good sign if their clients want to continue working with them on their future projects.
You will also want to ensure that the firm you are considering is able to quantify the impact of the systems they build. Look for metrics in the case studies the firm provides. Nothing speaks like real numbers. For instance, the claim that “Our AI system led to a 30 percent reduction of human-addressed support tickets” is a good indication that their AI system made a difference and they delivered on their stated value.
With a firm, you are paying for their expertise in a domain, such as AI. Therefore you will also want to ensure the firm is seen as an expert in that space by doing more than just their client work. For instance, ask if they are active in the AI community by presenting at conferences, writing articles, or perhaps doing their own AI research. Their participation is a positive signal, and the materials they have created can be reviewed to give you a more detailed look at their expertise.
Finally, you can get firsthand opinions by asking the firm for references from their previous clients. Be sure to ask the references not only about the firm's technical ability to deliver but also how they are to work with on a personal level. Most projects will last a few months if not longer. The firm you are considering may generate amazing results, but if they are unresponsive and a pain to work with, the personal toll will outweigh the benefits.
The Hybrid Approach
While the information in this section has been presented in a way that covers outsourcing your entire AI solution, this does not have to be an all-or-nothing proposition. Instead, let's imagine your team has experience with four of the five technologies you plan to use but lacks, say, an engineer with user experience (UX) skills related to natural language interfaces. Although hiring a dedicated person to fulfill this role is an option, it is typical, especially in smaller companies, to not have sufficient work to keep such a person utilized 100 percent of the time. Instead, this role might best be fulfilled via a contracted resource.
You will likely pay more per hour than you would with this resource on staff, but you will more than make up the difference by paying only for the time you are using. Additionally, this individual will have more expertise than, say, a developer who fills in as a natural language UX designer when needed. This added experience will pay off since they will use their expertise to be more time efficient and produce a higher-quality end product.
In the scenario where you are contracting out a particular skill to one single person, it may make sense to find the individual yourself and contract with them directly instead of using a firm. Yes, it will be more work to find and vet an individual contractor, but individuals will have lower overhead than a natural language UX designer who is part of a firm. Sites such as Upwork1 or Freelancer.com,2 can connect you with individual contractors from around the globe. Although these resources will be cheaper, they can be hit or miss, and you might have to go through a few until you find the right person for the job. These are the trade-offs you must considered when staffing your project.
Scrum Overview
To stay flexible during the prototype's development, we recommend using the Scrum framework from Agile to scope and plan your development activities. To assist you with this, the next two sections will focus on clarifying terms under this framework. To read even more about the Scrum framework, you can refer to the Scrum document, maintained by experts Ken Schwaber and Jeff Sutherland.3
Under Scrum, the team is divided into three major roles:
Product Owner
The product owner is the business end of the Scrum team. They sign off on demos and ensure that development is carrying on according to established timelines. It is the job of the product owner to prioritize the user stories in the backlog and plan the focus of each sprint.
Scrum Master
The scrum master is the person responsible for the development team staying on task and not getting distracted. It is their job to ensure that the development team receives the critical inputs necessary to do their jobs perfectly. It also part of the duties of the scrum master to ensure that Scrum and Agile are being followed and are well understood by the various stakeholders involved.
Development Team
The development team is a cross-disciplinary team, typically with no more than 10 members, whose responsibility is to deliver the releases and demos. The team is cross-functional and developers should be able to do the work of another as much as is possible. The development team clears the product backlog and is responsible for ensuring that the solution is delivered as per their established timelines.
The Scrum process also consists of three distinct parts:
Sprint Planning
In Scrum, development is done in periods of between two weeks and a month, depending on the development team and schedule. Each period is called a sprint. At the start of each sprint, the team discusses and sets goals for the sprint. Goals should be set in a way that ensures that there will be a new working “piece” of the system available at the end of the sprint. Usually the goals are selected user stories that identify a piece of functionality. Depending on the size and complexity of the user story and team, multiple user stories can be accomplished during a sprint. As development progresses, bug fixes for previously developed code will also be included in sprint planning.
Daily Stand-ups
Daily stand-ups are daily meetings no longer than 15 minutes that allow each development team member to talk about their progress and their plan for the day. This meeting needs to be strictly time-capped. Typically each developer responds to the same three questions: “What did I do yesterday?,” “What do I plan to do today?,” and “Do I have any blockers?” The daily stand-up is run by the scrum master, who is also tasked with helping to resolve any blockers identified by the developers that they themselves are not able to resolve.
Sprint Review
At the end of each sprint, there needs to be a sprint review. This review should discuss what user stories were able to be completed and which ones were deferred. The current working demo of the system should be shown to the product owner and other stakeholders to gather feedback. This feedback will be used to adjust course for the next sprint. The review also needs to consider what went wrong and what went right during the sprint's development. We will discuss feedback further in the next section.
It is pertinent to note here that Agile and Scrum are frameworks and meant to be flexible. You do not have to follow the entire process as is. You can pick and choose what is applicable to your project and team. The objective is to keep development focused on implementing user stories that provide real value, not to create an inflexible bureaucratic process.
User Story Prioritization
As development work on the prototype continues, it is possible that user story prioritizations need to be adjusted. It is the product owner's responsibility to ensure that the project roadmap is clear and prioritized. This is essential to get right; otherwise, the demos at the end of the sprint might only include low-value features or, worse, features that do not solve a current problem. The product owner's key responsibility is to ensure that such a prioritization is logical and can realistically be achieved.
Every demo produced at the end of a sprint should be a working piece of the entire system. The solution should be iteratively grown and implemented. A demo that does not allow for full functionality cannot be tested and will have to be rejected or accepted purely based on its code, which can lead to erroneous decisions and extend the project deadline. As an example, if the customer password change form is developed before the customer database and procedures for hashing and storing passwords is coded, it will lead to an untestable demo.
To prioritize correctly, adopt a combination approach of value points and story points. The value points will be generated by the product owner based on empathy maps and the product owner's understanding of the users' wants and needs. The story points, on the other hand, should be assigned by the development team, assessing the difficulty and/or labor hours necessary for each user story.
In the first step, value analysis of each user story must be performed, with ranks given based on the value derived from them. “Value” here can be defined as the benefit the user will receive from using the demo generated by the user story, weighed against the labor hours needed to code it. The value points are abstract points and can follow any consistent method of scoring, such as one based on the Fibonacci Sequence (1, 2, 3, 5, 8, 13).
Using a modified Delphi technique can help the product owner to correctly estimate the effort required by involving the Scrum team in the process. The Scrum team can assign story points to each user story, and stories for which disagreement arises can be discussed. Differing opinions will be discussed and points reassigned until there is agreement among the team. The process for assigning story points should involve sizing each user story iteratively before awarding any points. Points can be any arbitrary number system, like the Fibonacci sequence used traditionally in Scrum, or T-shirt sizing like S, M, L, and XL, and so forth.
Using the story points and their value scores, the product manager should sort each story. The stories that maximize user value along with matching complexity in story points should be taken up first. Using this approach to project planning will ensure that you are protected against the pitfall of doing the easy, low-value tasks first and leaving the hard tasks to never get completed.
The Development Feedback Loop
As we mentioned before, one of the primary ways to prevent large issues from occurring in a project is to identify and correct errors as soon as possible. In this way, good code will not be written based on an incorrect foundation. Assuming you are using an Agile methodology while developing the prototype, at the end of each sprint you should have new functionality. This functionality can then be verified to ensure that it fulfills, or is on track to fulfill, the identified user stories. If the functionality does not work or, more likely, works but performs a different function than the use case requires, stakeholders need to speak up. Development can then adjust its course immediately, saving hours or days of work down the line. This feedback can be used to adjust any part of the AI pipeline, as can be seen in Figure 5.1.
One of the best ways to turn feedback loops into a standardized process is through the aforementioned sprint reviews. Reviews happen at the end of each sprint and include the developers along with the stakeholders. During the review, a demo is typically conducted showcasing the newly implemented features for that sprint. This opens a dialogue between stakeholders and developers, which helps build alignment and is crucial to the project's success as a whole. Without a regular dialogue, development could be left working in isolation and first showing their progress to stakeholders after three months have passed. At that point, a stakeholder might want major changes (causing major delays), either because of an initial misunderstanding or because external requirements have since changed.
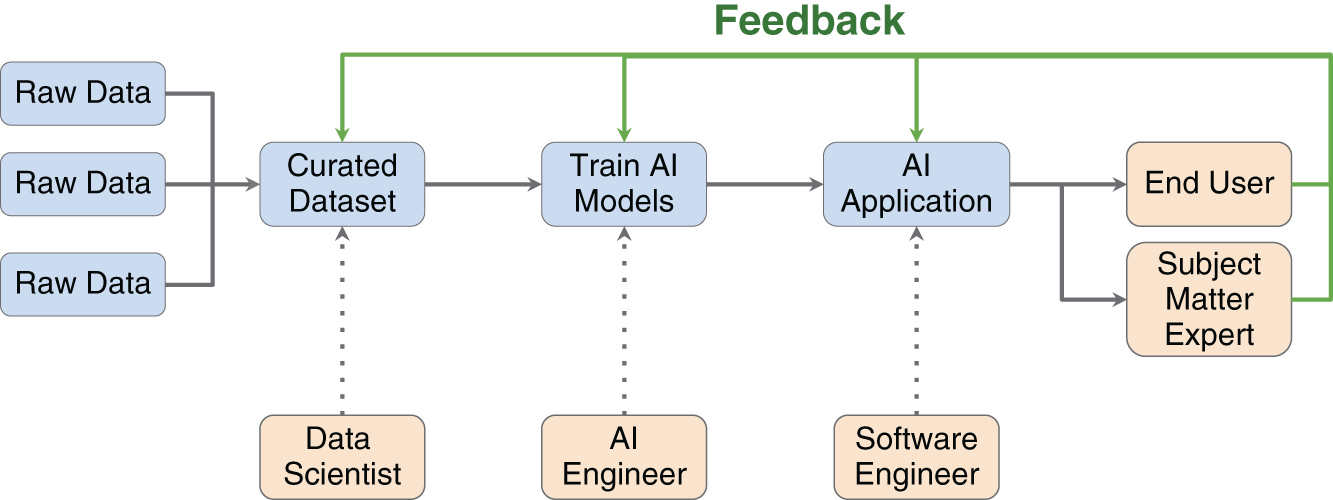
FIGURE 5.1 The Stages and Roles Involved with Feedback
Reviews are valuable only if all parties regularly attend. This is typically not a problem for the development team since it is part of their process, but stakeholders can be another story. They tend to be in positions that require their attention to be divided among many competing priorities. Project managers must impress upon each stakeholder the value of not only regularly attending reviews, but also being engaged and vocal with their feedback. They are a stakeholder for a reason, and their success depends in part on the project's success.
During implementation of the prototype, you will also learn and receive feedback that can be codified as lessons learned. For instance, certain capabilities of your selected technologies might not work exactly as advertised. Maybe one of your architectural decisions, when implemented, turned out to be extremely slow and changes had to be made to make it more performant. Documenting this knowledge will be valuable not only for making future decisions on this project, but also when working on future projects.
Designing the Prototype
Assuming there is no existing solution and you are committed to developing your solution in-house, the first step to building a prototype is to define your system's architecture. This begins with the logical components of your system along with the selected technologies that will be providing those capabilities. Note that a single instance of a technology can serve multiple logical roles. For instance, if you need a place to host AI model for Part A of your logical design and another AI host for Part B, you could potentially use a single deployed instance of AI hosting technology such as TensorFlow Serving4 to fulfill both.
Logical architectures tend to be defined using a logical architecture diagram. The logical architecture diagram shows all the conceptual parts of a system and is helpful to determine which kinds of technology you will need to select. An example of a logical architecture diagram is shown in Figure 5.2.

FIGURE 5.2 A Logical Architecture for a Support Chatbot
Technology Selection
With a logical architecture diagram in place, it is now time to start researching which technologies will fulfill the requirements. One approach is to create a spreadsheet of all the capabilities required in the prototype, as noted by your logical diagram. Along the other axis of the spreadsheet, list all the technologies that fulfill one or more of those capabilities. Other factors can be included in the spreadsheet as well, such as price or features, since they may also influence the technology selection. Table 5.1 shows an example of such a table.
After this matrix has been completed and you've selected the best technology for the roles, it is time to make a physical architecture diagram (see Figure 5.3 for an example). This physical architecture diagram resembles the logical architecture diagram; however, it will include the technologies you are proposing to use. This will continue to help development and stakeholders visualize the solution and pinpoint any issues ahead of time. Fixing a problem now instead of, say, during production will be dramatically cheaper. This concept is called error cost escalation, and it is applicable in a number of industries but especially so in software engineering. As we have mentioned before, if development continues to build on top of a mistake, all that work will need to be redone once the mistake is identified. This is also one of the primary benefits of software development and, in a way, the reason we are building this prototype.
| Technology name | Role | Price |
| Dialogflow | Conversation API | Cost per query |
| Watson Assistant | Conversation API | Cost per query |
| Microsoft Bot Framework | Conversation API | Cost per query |
| React | App front-end | Open source |
| Django | App backend | Open source |
| ExpressJS | App backend | Open source |
| MySQL | Relational database | Open source |
| Oracle | Relational database | Yearly license fee |
| PostgreSQL | Relational database | Open source |

FIGURE 5.3 A Physical Architecture for a Support Chatbot
One of the other considerations when choosing technologies is “How well do the selected technologies interact with one another?” In some systems, all technologies interact solely with your application code. In this case, evaluating the integration points between components is less important. However, in a scenario such as a database needing to communicate with another system via a message bus, having a supported integration between those two technologies will make life much easier. In this way, you can avoid having to write and maintain custom integration services.
When making technology selections, it is important to lean on other colleagues in the field. You probably know others in your industry who have experience using the very technologies you have identified in your technology spreadsheet. Some might have had good experiences and recommend a particular technology, but more important are the ones with bad experiences. Although bad technologies might improve with time (especially if the bad experiences were a few years back), you could potentially save yourself from a lot of future pain by getting the details. Lastly, if you select a technology with which your colleagues have experience, you can ask them for help during implementation. If you end up selecting the same technology, you can reciprocate and provide your experiences back to them, which will help both of you.
Another large decision point when building a system is what programming language you will use to build your application. The controversy over which language is best causes many “holy wars” in the industry. From a practical sense, there are two primary determinants for selecting a programming language. The first is the primary language of your development team. Given that they have likely worked on projects together, using the programming language they are already comfortable with will likely have large gains in productivity. Language syntax, built-in library functions, and development tooling will already be familiar to them.
The second determinant when selecting a programming language is whether the language has the software libraries to fulfill your requirements. For instance, most of the current machine learning technologies are primarily available in the Python programming language. Therefore, selecting Python for an AI project may make the most sense. You might find that libraries support multiple programming languages, but keep in mind that the support for alternative programming languages will likely be less. That is in terms of the library's stability (i.e., more software bugs) and in finding help and documentation in online forums. For instance, TensorFlow, which is a neural network technology open sourced by Google, is primarily used in the Python programming language. Although they have support for the Java programming language, the TensorFlow website states that “The TensorFlow Java API is not covered by the TensorFlow API stability guarantees.”
Alternatively, it is possible to use multiple programming languages for a single system. This is ideally suited for a microservices architecture, where pieces of the system are implemented as separate units and are integrated through a language-independent method such as a representational state transfer (REST) API. For instance, let's say your engineering team is strong in JavaScript but the machine learning library that ideally meets your requirements is available only with Python. In this scenario, a machine learning service could be written in Python and called via a REST API from your primary application code, which is written in JavaScript. In this way, the majority of your development team will not need to learn Python just to take advantage of an ideal machine learning library.
When selecting a technology, also consider the requirements for the other user stories you have identified. Although you will not be implementing them during the prototype phase, it is good to avoid using a technology that you know will not support all your other user stories. With this little bit of planning, you can avoid having to replace parts of your technology stack during the production step.
Cloud APIs and Microservices
Traditionally, when developers wanted to add a capability to their application, they would download a code library. Developers would do this for each capability needed. For example, if a programmer needs to manipulate and analyze training data, they could use Python's pandas library. Libraries like these, however, are programming language specific and typically do not include much (if any) data. This delivery model is fairly limiting, especially for capabilities that are powered by large collections of data.
By contrast, data-powered capabilities are now being delivered through web-based APIs. Instead of downloading a library, a developer makes the appropriate API call and a response is returned. This allows all the requisite data for powering the API to be managed by the API and abstracts the complexity of the implementation completely. Most companies with machine learning technology make their solutions available through API offerings. Here are a few of the larger companies in this space:
- IBM's Watson Services6 (see Figure 5.4 for their catalog of AI services)
- Google's Cloud Machine Learning Engine7
- Amazon's Machine Learning on Amazon Web Services (AWS)8
- Microsoft's Machine Learning on Azure9
REST APIs, as mentioned earlier, also have the added benefit of being programming language agnostic. If a developer writes a Python application, they can simply include Python's HTTP library and call a REST API. Similarly, for a NodeJS application, a developer can include the NodeJS HTTP library and make the same REST API call. This enables developers to select the language of their choice without needing to match the language of the library they want to use. For instance, a lot of mid-2000s machine learning programs were implemented in Java, simply because the Java-ML library was the most mature at the time. With the cloud-based API model, libraries are decoupled from programming languages and are easily accessible to all.

FIGURE 5.4 Sample Catalog of AI Cloud Services from IBM
Internal APIs
Integrating with cloud APIs does not have to be just with third-party vendors. Integrations with your organization's existing back-end systems will also be necessary. For instance, if a user has not received their package in the mail, they might ask your chatbot about its current status. The response to this question is not a simple static answer but rather requires querying a separate shipping system to determine the package's status. The result is then used to craft a natural language response for the user. This is a simple example, but it is possible that some user questions could require responses from multiple systems, including the results of running AI models.
In order for the chatbot to be able to interact with these backend systems, there needs to be an established communication channel. Unlike humans, who typically use a web browser to interact with systems, chatbots require an API to interact with another system. Therefore, it is important to validate that all needed back-end systems already have an API available and that they expose all necessary data. If they do not, you will have to add the creation of the API to your development roadmap for the system that needs to be accessed programmatically. Although this might be straightforward if the back-end system also happens to be created by your team, it can be more difficult if it was created by another team in your organization or a third-party vendor. In this case, you will need to convince them that it is worth the time and resources to add an API to an existing system that has not yet needed to have an API. Explaining that adding an API will enable more integrations with their system, thus making it more valuable, might be enough for them. Additional cost sharing might also make sense, given the funding situations of the different teams.
On a positive note, most systems built today include an API because of the prevalence of automation and open standards. You can typically find out if a system has the required APIs by looking at their documentation. If APIs exist, the documentation will specify the formats and methods for how to call the APIs.
Pitfalls
Here are some pitfalls you may encounter during prototyping.
Pitfall 1: Spending Too Much Time Planning
Although the majority of this chapter dealt with how to break down the prototype requirements and select technologies, it is important not to dwell too much on designing and planning your solution. Given that you will be using an Agile approach and starting a feedback loop as soon as possible, design changes can happen quickly. The start of the project is the point when you necessarily have the least amount of information known. Therefore, it only makes sense to start sooner than later, gaining knowledge by implementing and updating your design as you go. In the end, you will be able to create value more quickly using this approach.
Pitfall 2: Trying to Prototype Too Much
Another frequent pitfall that developers run into during the prototyping phase is setting themselves up for failure by trying to implement too much. A prototype should be limited in scope, provide real value, and be realistically feasible. There will be plenty of time to build large, complex, even moonshot systems once the prototype has been built. However, the prototype is your time to demonstrate value and prove to the stakeholders that AI systems are worth the investment. A prototype that takes too long or that is too ambitious and fails will hurt your organization's chances of ever transforming into an AI-integrated business.
Continuing the chatbot example, it is important to include only a few types of chat interactions during the prototyping phase. For instance, if you are building a chatbot for a movie theater chain, perhaps the prototype version would only handle the ticket purchasing flow. Concepts such as refunds or concessions should be deferred until the production phase. In this way, the prototype can demonstrate the concept and value of purchasing tickets with the understanding that the other interactions can be added later with further investment.
Pitfall 3: The Wrong Tool for the Job
The other common problem is correctly identifying a problem but then assuming it can be solved with the technology du jour. During the technology selection process, you have to ensure that currently popular technologies do not cloud your judgment. Otherwise, at best you will have a needlessly more complex solution. At worst, you will need to replace a core technology midway through development. If your problem requires a hammer, it does not matter how awesome and new that shovel is, it is not the right tool for the job.
With regard to AI, this frequently happens with the misapplication of neural networks. Although it is true that neural networks can solve a large class of problems, it is not the right solution for every problem. For example, naïve Bayes can be a better approach when you do not have a large amount of data. Additionally, if you are in an industry that has to be able to explain its results, neural networks (especially large ones) are notorious for being opaque. They might be accurate given the training data, but because the features it learned are a complex combination of the inputs it is impossible to give a coherent reason why it made the decision it did.
Action Checklist
- ___ Select which of the top user stories are feasible and will be implemented as your prototype.
- ___ Determine if there is an available solution on the market that can be used to save time and resources.
- ___ Decide if you have the necessary talent in your organization or if you need to supplement by contracting resources.
- ___ Design the prototype and use the technology selection process to determine how to build the prototype.
- ___ Use Agile methodologies to iteratively build the prototype with regular stakeholder feedback.