You looked at using the Axon framework to implement different scenarios of the CQRS pattern in the previous chapter. In this chapter, you will be revisiting Axon for more scenarios in the microservices context, including executing long-running computational processing. To do that effectively, let’s start the discussion with a few basics, including transactions. A transaction in its simple form is a change or exchange of values between entities. The parties involved can be a single entity or more than one entity. When the party involved is a single entity, typically the transaction is a local transaction. If more than one party is involved, the transaction can be classified as either a local transaction or a distributed transaction, depending on the nature and location of the entities involved.
A transaction may involve a single step or multiple steps. Whether a single step or multiple steps, a transaction is a single unit of work that embodies these individual steps. For the successful completion of a transaction, each of the involved individual steps should succeed. If any of the individual steps fail, the transaction should undo any of the effects of the other steps it has already done within that transaction.
With this preface, you will look into the details of transactions, especially distributed transactions. I will only touch base on the essentials of transactions; I’ll spend more time on the practical implication aspects, especially in the context of microservices. Detailing out transactions to any more depth would require its own complete book, so this coverage will be limited to discussions around microservices and few practical tools you can use to build reliable microservices.
The indeterministic characteristics of computer networks
Transaction aspects in general
Distributed transactions vs. local transactions
ACID vs. BASE transactions
A complete example demonstrating distributed transactions using multiple resource managers
The Two Generals Paradox
In computer networking (particularly with regard to the Transmission Control Protocol), literature shows that TCP can’t guarantee (complete) state consistency between endpoints. This is illustrated by the Two Generals Paradox (also known as the Two Generals Problem or the Two Armies Problem or the Coordinated Attack Problem), which is a thought experiment illustrating the pitfalls and connected design challenges while attempting to coordinate an action by communicating over an unreliable link.
The Two Generals Paradox is unsolvable in the face of arbitrary communication failures; however, the same problem provides a base for realistic expectations for any distributed consistency protocols. So to understand the problem, you need to understand the associated indeterminism involved, which will provide a perfect analogy to learn more about transactions.
Illustrating the Two Generals Paradox

Illustrating the Two Generals Paradox
The two generals have agreed that they will attack; however, they have yet to agree upon a time for attack. The attack will only succeed if both armies attack the city at the same time; the lone attacker army will die trying. So the generals must communicate with each other to decide on a time to attack and agree to jointly attack at that time; each general must also know that the other general knows that they have jointly agreed to the attack plan. An acknowledgement of message receipt can be lost as easily as the original message itself, thus a potentially infinite series of messages are required to come to (near) consensus. Both generals will always be left wondering whether their last messenger got through.
Solution Approaches
Computer networks are the spine of distributed systems; however, the reliability of any network has to be examined. Distributed systems are required to address scalability and flexibility of software systems, so a network is a necessary evil. Schemes should accept the uncertainty of the networks and not attempt to eliminate it; rather, they should mitigate it to an acceptable degree.
The first general can send 50 messengers, anticipating that the probability of all 50 being captured is low. This general will have fixed the time of attack to include enough time for all or a few or many of those 50 messengers to reach the other general. He will then attack at the communicated time no matter what, and the second general will also attack if any of the messages are received.
A second approach is where the first general sends a stream of messages and the second general sends acknowledgments to each received message, with each general’s comfort increasing with the number of messages received.
In a third approach, the first general can put a marking on each message saying it is message 1 of n, 2 of n, 3 of n, etc. Here the second general can estimate how reliable the channel is and send an appropriate number of messages back to ensure a high probability of at least one message being received. If the network is highly reliable, then one message will suffice and additional messages won’t help; if not, the last message is as likely to get lost as the first one.
Microservices as Generals
When you have split the state of a monolith that has been “living happily thereafter, together” to the state of “living happily ever after, separated,” you have split the army from one general into multiple generals. Each microservice has their own general or is a general by itself, and more than one general may be required to coordinate any useful functionality. By adopting polyglot, each microservice will have its own resource, whether it’s a database or file storage. The network is the only way these microservices can coordinate and communicate. The effect of changes made to resources cross-microservices has to be made consistent. This consistency depends on which schema or protocol you choose to coordinate and communicate the commands to make changes and the acknowledgements, which act as the agreement to effect that change between microservices.
TCP/IP, the Valley Between the Generals
The Internet Protocol (IP) is not reliable. It may be delayed or dropped or duplicate data can come or data can come in order not as per the original intention. The Transmission Control Protocol adds a more reliable layer over IP. TCP can retransmit missing packets, eliminate duplicates, and assemble packets in the order in which the sender intended to transmit. However, while TCP can hide packet loss, duplication, or reordering, it may not be able to remove delays in the network, since they are packet switched. Traditional fixed-line telephone networks are extremely reliable, and delayed audio frames and dropped calls are very rare. This is because a fixed, guaranteed amount of bandwidth is allocated for your call in the network, along the entire route between the two callers; this is referred to as circuit switched. However, data center networks and the Internet are not circuit switched. Their backbone, the Ethernet and IP, are packet switched protocols, which suffer from queueing, which can cause unbounded delays in the network.
Each microservice has its own memory space for computation and resources for persistence and storage, and one microservice cannot access another microservice’s memory or resource (except by making requests to the other microservice over the network, through an exposed API). The Internet and most internal networks in data centers (often Ethernet) have the characteristics explained above, and these networks become the only way microservices can coordinate and communicate. In this kind of network, one microservice can send a message to another microservice, but the network gives no guarantees as to when it will arrive or whether it will arrive at all. If you send a request and expect a response, many things could go wrong in between.
The sending microservice can’t even tell whether the request or message was delivered. The next best option is for the recipient microservice to send a response message, which may also in turn be lost or delayed. These issues are indistinguishable in an asynchronous network. When one microservice sends a request to another microservice and doesn’t receive a response, it is impossible to tell why. The typical way of handling such issues is by using timeouts: after some time you give up waiting and assume that the response is never going to arrive. However, if and when a timeout occurs, you still don’t know whether the remote microservice got your request or not, and if the request is still queued somewhere, there is a chance that it may still be delivered to the recipient microservice, even if the sender microservice has given up on the previous request and might have resent the request, in which case a duplicate request will get fired. Advanced solutions to this problem are addressed in the reference.1
Transactions
Transactions help you control how access is given to the same data set, whether it is for read or write purposes. Data in a changing state might be inconsistent, hence other reads and writes should have to wait while the state transitions from “changing” to either “committed” or “rolled back.” You will look at the details related to transactions now.
Hardware Instruction Sets at the Core of Transactions
For transactions at a single database node, atomicity is implemented at the storage level. When a transaction commits, the database makes the transaction’s writes durable (typically in a write-ahead log2) and subsequently appends a commit record to the log on disk. So, the controller of the disk drive handling that write takes a crucial role in asserting that the write has happened.
A transaction once committed cannot be undone. You cannot change your mind and retroactively undo a transaction after it has been committed. This is because, once data has been committed, it may become visible to other transactions and thus other transactions may have already started relying on that data.
The ACID in the Transaction
Atomicity : The outcome of a transaction, if it’s a commit, is that all of the transaction’s writes are made durable as a single unit of work. If it’s an abort, then all of the transaction’s writes are rolled back (i.e., undone or discarded) as a single unit of work. If you go back to the previous section where I described that it’s the single controller of one particular disk drive that sits in the core and takes the commit or rollback decision, you need to appreciate that whether it’s the write of a single word3 or multiple words (depending on 32-bit or 64-bit), it’s the support available from the hardware level that helps you club them together as the write of a single unit of work.
Consistency : This property guarantees that a transaction will leave the data in a consistent state, irrespective of whether the transaction is committed or rolled back. To understand what this “consistent state” means, it refers to the adherence of the constraints or rules of the database. It is common to model business rule constraints in terms of database integrity constraints. So, maintaining consistency is a dual effort by both a resource manager and the application. While the application ensures consistency in terms of keys, referential integrity, and so on, the transaction manager ensures that the transaction is atomic, isolated, and durable. For example, if your transaction is to assign the last seat on the flight to one of two travelers who are concurrently booking for that same flight, the transaction will be consistent if one seat is removed from the inventory of free seats and assigned to one and only one of the travelers and at the same time show that the same seat is not assigned or assignable any more to the other traveler trying booking concurrently.
Isolation : The isolation property guarantees that the changes ongoing in a transaction will not affect the data accessed by another transaction. This isolation can be controlled to finer levels, and “Transaction Isolation Mechanisms" section describes them.
Durability : This property requires that when a transaction is committed, any changes the transaction makes to the data must be recorded permanently. When a transaction commits, the database makes the transaction’s writes durable (typically in a write-ahead log) and subsequently appends a commit record to the log on disk. If the database crashes in the middle of this process, the transaction can be recovered from the log when the database restarts. In cases where the commit record is already written to disk before the crash, the transaction is considered committed. If not, any writes from that transaction are rolled back. So the moment at which the disk finishes writing the commit record is the single deciding point to commit; before that moment, it is still possible to abort (due to a crash), but after that moment, the transaction is committed (even if the database crashes just afterwards). So, it is the controller of the disk drive handling the write that makes the commit atomic. Having said that, if an error or crash happens during the process, the above logs can be used to rebuild or recreate the data changes .
Transaction Models
Flat transactions: In a flat transaction, when one of the steps fails, the entire transaction is rolled back. In a flat transaction, the transaction completes each of its steps before going on to the next one. Each step accesses corresponding resources sequentially. When the transaction uses locks, it can only wait for one object at a time.
Nested transactions: In a nested transaction, atomic transactions are embedded in other transactions. The top-level transaction can open subtransactions, and each subtransaction can open further subtransactions, and this nesting can continue. The effect of an individual embedded transaction will not affect the parent transaction. When a parent aborts, all of its subtransactions are aborted. However, when a subtransaction aborts, the parent can decide whether to abort or not. In a nested transaction, a subtransaction can be another nested transaction or a flat transaction.
Chained transactions: In a chained transaction, each transaction relies on the result and resources of the previous transaction. A chained transaction is also called a serial transaction. Here the distinguishing feature is that when a transaction commits, its resources, like cursors, are retained and are available for the next transaction in the chain. So, transactions inside the chain can see the result of the previous commit within the chain; however, transactions outside of the chain cannot see or alter the data being affected by transactions within the chain. If one of the transactions should fail, only that one will be rolled back and the previously committed transactions will not.
Saga: Sagas are similar to nested transactions; however, each of the transactions has a corresponding compensating transaction. If any of the transactions in a saga fail, the compensating transactions for each transaction that was successfully run previously will be invoked.
Transaction Attributes in EJB vs. Spring
PROPAGATION_REQUIRED (REQUIRED in EJB): Supports a current transaction; creates a new one if none exist.
PROPAGATION_REQUIRES_NEW (REQUIRES_NEW in EJB): Creates a new transaction; suspends the current transaction if one exists.
PROPAGATION_NOT_SUPPORTED (NOT_SUPPORTED in EJB): Executes non-transactionally; suspends the current transaction if one exists.
PROPAGATION_SUPPORTS (SUPPORTS in EJB): Supports a current transaction; executes non-transactionally if none exist.
PROPAGATION_MANDATORY (MANDATORY in EJB): Supports a current transaction; throws an exception if none exist.
PROPAGATION_NEVER (NEVER in EJB): Executes non-transactionally; throws an exception if a transaction exists.
PROPAGATION_NESTED (No equivalent in EJB): Executes within a nested transaction if a current transaction exists, or else behave like PROPAGATION_REQUIRED. There is no analogous feature in EJB. Actual creation of a nested transaction will only work on specific transaction managers. Out of the box, this only applies to the JDBC DataSourceTransactionManager when working on a JDBC 3.0 driver. Some JTA providers might support nested transactions as well.
Transaction Isolation Mechanisms
Locking: Locking controls access to a transaction to a particular data set. Read locks are non-exclusive and allow multiple transactions to read data concurrently. However, write locks are exclusive locks and only a single transaction is allowed to update data.
Serialization: When multiple transactions happen concurrently, serialization is a mechanism to guarantee that the effects are as if they are executing sequentially, not concurrently. Locking is a means of enforcing serialization.
Transaction Isolation Levels
TRANSACTION_NONE: Indicates that transactions are not supported.
TRANSACTION_READ_COMMITTED: Indicates that dirty reads are prevented; non-repeatable reads and phantom4 reads can occur.
TRANSACTION_READ_UNCOMMITTED: Indicates that dirty reads, non-repeatable reads, and phantom reads can occur. This level allows a row changed by one transaction to be read by another transaction before any changes in that row have been committed (a dirty read). If any of the changes are rolled back, the second transaction will have retrieved an invalid row.
TRANSACTION_REPEATABLE_READ: Indicates that dirty reads and non-repeatable reads are prevented; phantom reads can occur.
TRANSACTION_SERIALIZABLE: Indicates that dirty reads, non-repeatable reads, and phantom reads are prevented. This level prohibits the situation where one transaction reads all rows that satisfy a WHERE condition, a second transaction inserts a row that satisfies that WHERE condition, and the first transaction rereads for the same condition, retrieving the additional phantom row in the second read.
The level of relaxation or the strictness of enforcement of the serialization and locks are determined by the type of concurrency the application is willing to tolerate with respect to staleness of data. The next section will explain this concept.
Transaction Concurrency
Dirty read: Dirty reads happen when a transaction reads data that has been written by another transaction but has not yet been committed by the other transaction.
Non-repeatable read: If a transaction reads data, and if it gets a different result if it rereads the same data within the same transaction, it is a non-repeatable read.
Phantom read: When a single transaction reads against the same data set more than once, a phantom read happens when another transaction slips in and inserts additional data.
Transaction Isolation Control Methods
Optimistic locking: Optimistic locking takes a pragmatic approach and encourages clients to be “optimistic” that data will not change while they are using it and allows them to access same data concurrently. If for any reason the transaction on behalf of any particular client wants to update, the update is committed if and only if the data that was originally provided to the client is the same as the current data in the database. This approach is less ideal for hot-spot data because the comparison will fail often.
Pessimistic locking: Pessimistic locking may use semaphore5 or any of the transaction mechanisms previously discussed. For every read, you need a read lock, and for every write, you need a write lock. Read locks are not exclusive whereas write locks are. A typical read lock may be obtained when you query similar to
SELECT ∗ FROM QUOTES_TABLE WHERE QUOTES_ID=5 FOR UPDATE;
Both locks will be released only when the usage of data is completed. A read lock can be given to a transaction on request, provided no other transaction holds the write lock. For a transaction to update, it requires a write lock, and during the duration that transaction holds the write lock, other transactions are allowed to read the data if and only if they don’t require a read lock. Moreover, if a transaction holds a write, it will not allow another transaction to read its changing data until those changes have been committed.
Enterprise Transaction Categories
Transactions have different connotations depending on the context in which we use them. It can be in the context of multiple operations within a monolith system, or in the context of multiple monoliths or multiple microservices, or in the context of multiple enterprises with common (or conflicting) interests. You will briefly look at the different transaction categories in this context.
ACID Transactions

Distributed ACID transactions with multiple resources
BASE = ACID in Slices
ACID is the only style that can guarantee data consistency. However, if a distributed system uses ACID transactions, everything has to happen in lockstep mode, everywhere. This requires all components to be available and it also increases the lock times on the data. BASE is an architectural style that relaxes these requirements, simply by cutting the (overall, ideal) ACID transaction into smaller pieces, each of them still ACID in themselves.
Messaging is used to make changes ripple through the system, where each change is ideally processed by an ACID transaction. The messages are asynchronous rather than synchronous, meaning that there is a delay between the first and last ACID transaction in a BASE system.
This is why this style exhibits “eventual consistency:” one has to wait for all messages to ripple through the system and be applied where appropriate. The “Eventual Consistency of Microservices” section in Chapter 11 discussed this in detail.
I’ll now introduce BASE in various incremental steps, by cutting more and more into the ACID transaction scope.
BASE Transactions

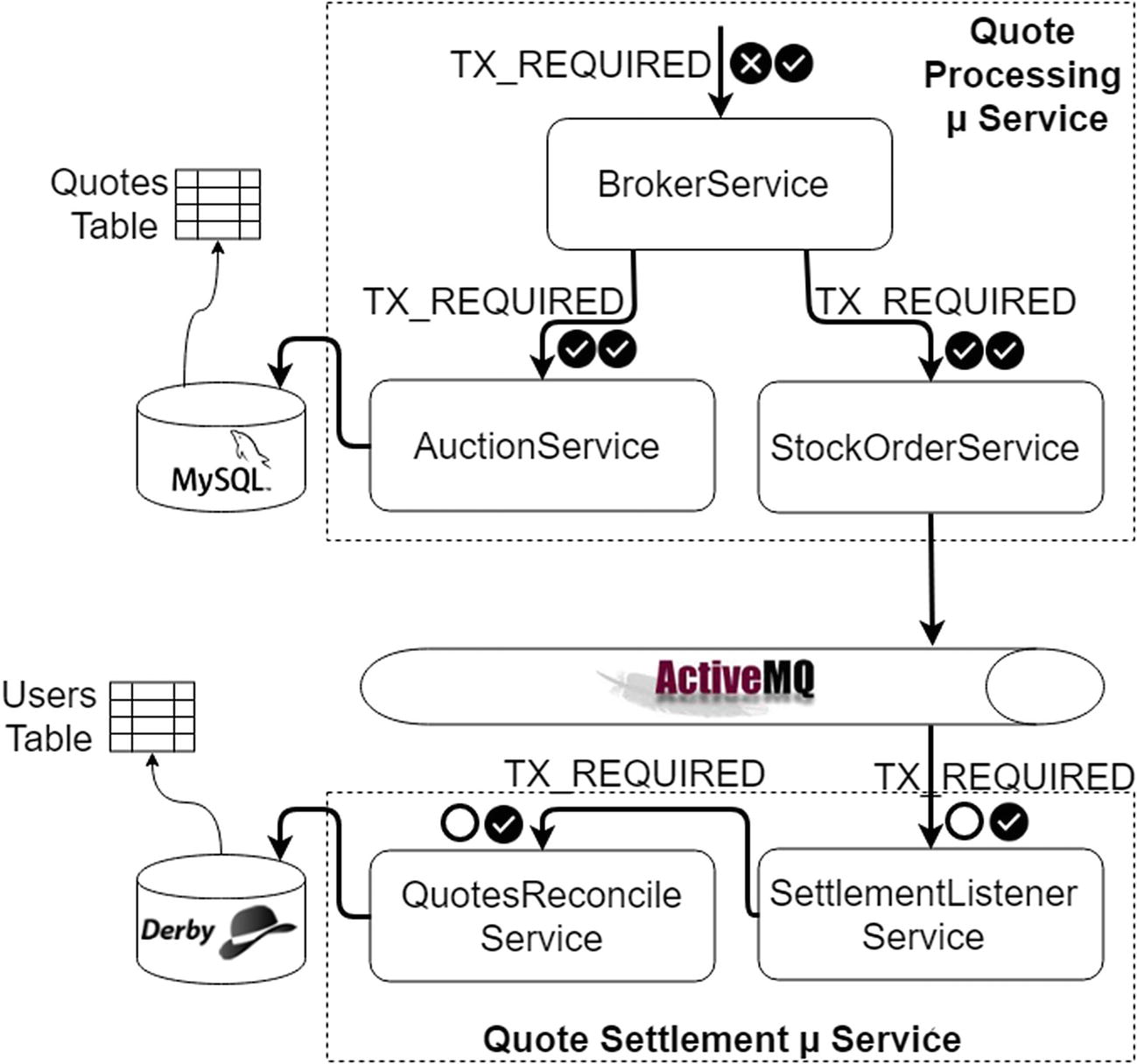
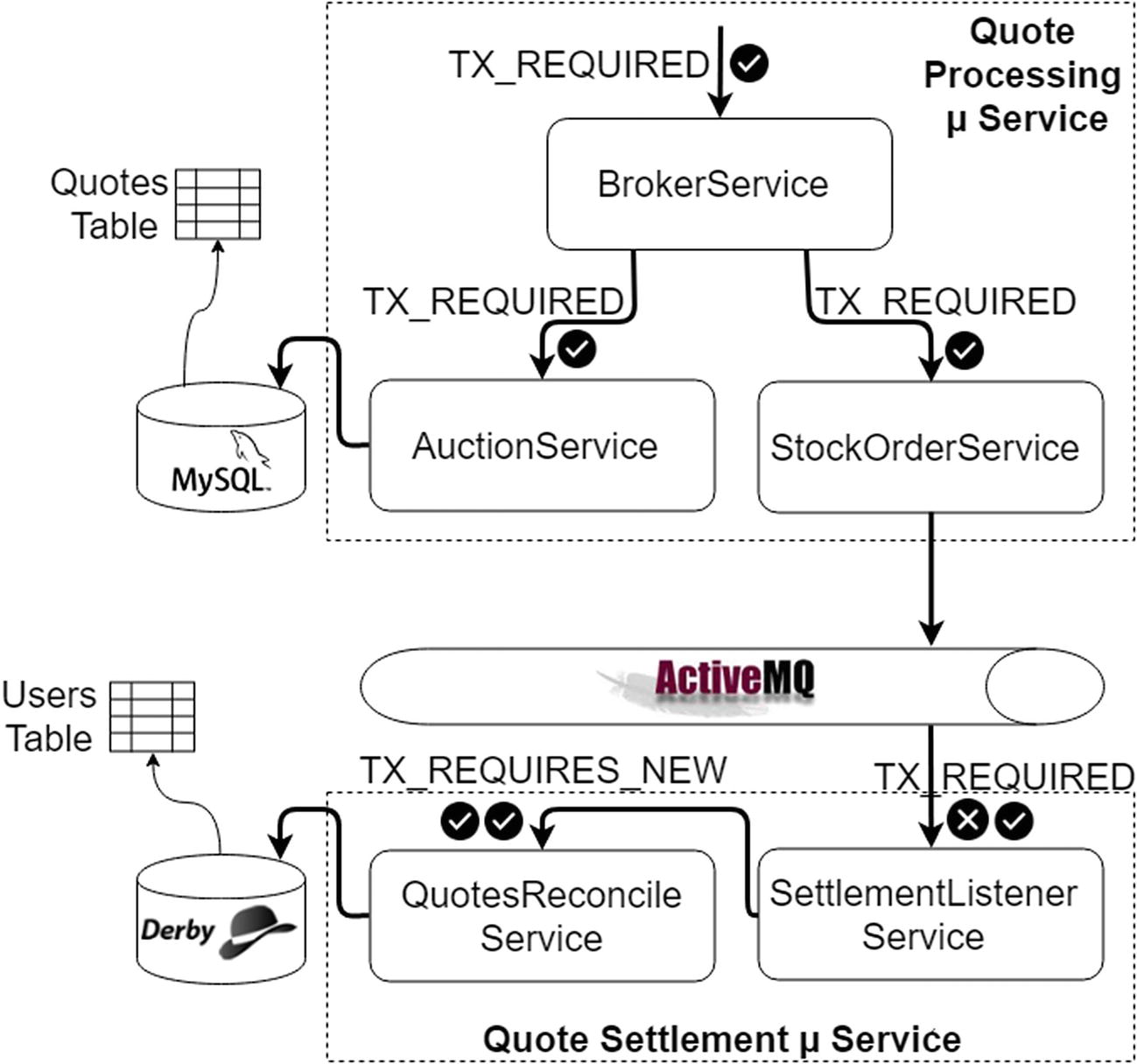
BASE architecture where each microservice still has ACID guarantees by means of XA transactions
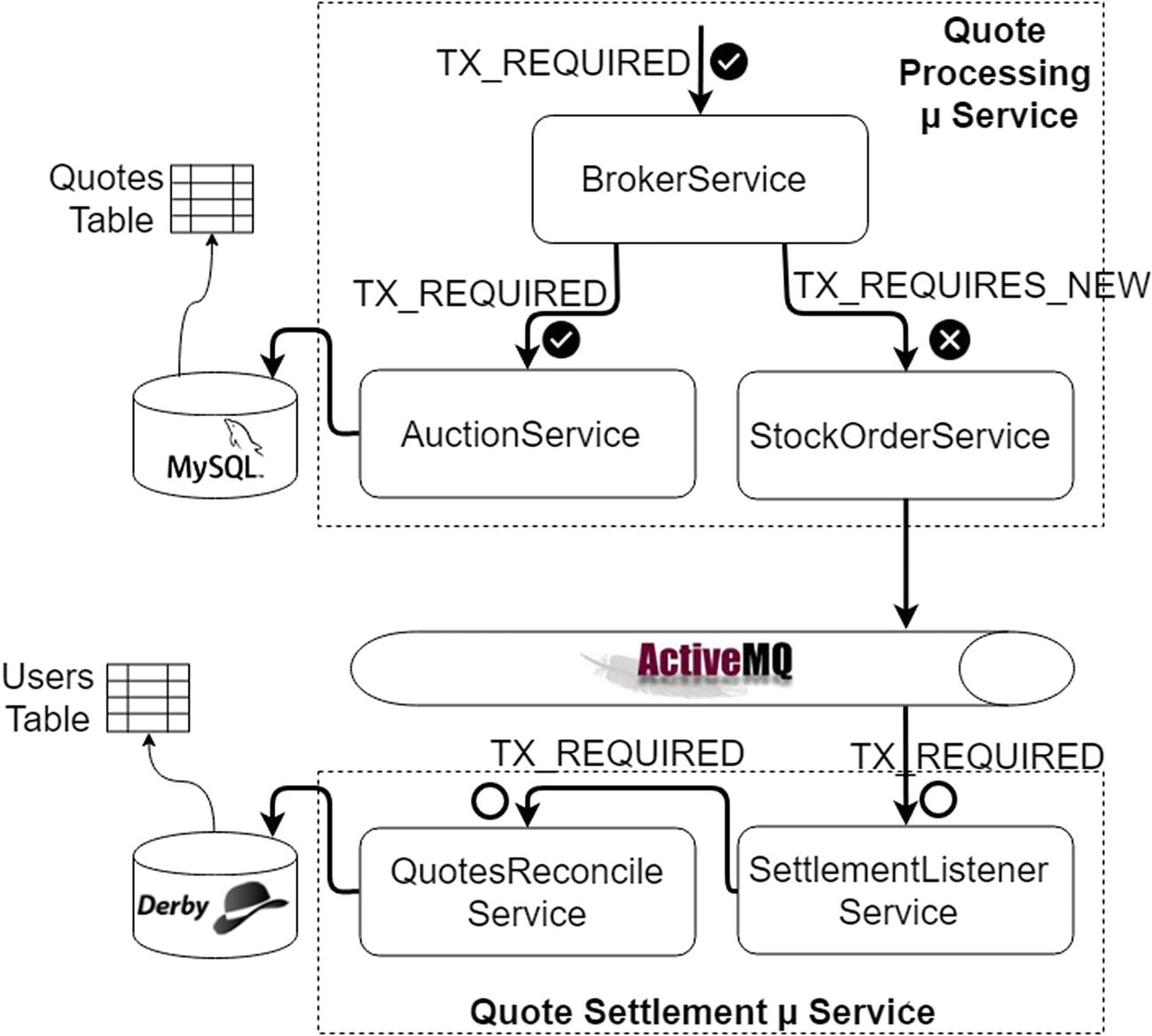
This is the architecture of a microservice ecosystem in BASE style that sends or receives messages in ACID style. You will look at the functionality of each microservice in a later section (the “Design the Example Scenario” subsection under the “Distributed Transaction Example” section); however, pay attention to the technical components depicted here for the time being. It is BASE because via ActiveMQ you don’t know or care where the messages go to or come from; all that the quote processing and quote settlement see between them is the queues (whereas a classical ACID architecture would create one big ACID transaction for quote settlement and quote processing). You use JTA/XA to ensure that messages are processed exactly once, since you don’t want to lose messages (or get duplicates). Messages that are received from the queue are guaranteed to make it to the database, even with intermediate crashes. Messages that are sent are guaranteed to have their domain object status updated in the database, even with intermediate crashes.
For systems that require strong guarantees on data consistency, this is a good solution. In other systems, strong data consistency is not that vital and you can relax things even more–by using an even finer scope of ACID transactions in your BASE architecture.
When you transition to microservices, you want to avoid system-wide distributed transactions. However, your actual data is distributed more compared to the scenario of the monolith, so the need for distributed transactions is very real. And it is in this context we are talking about eventual consistency in place of instantaneous consistency. The “Eventual Consistency of Microservices” section in Chapter 11 covered this in detail.
Relaxed BASE Transactions
In some cases, you don’t care a lot about message loss or duplicates, and the scope of your ACID transactions can be limited to single resource managers, like purely local transactions only. This offers more performance but it has a cost: whereas so far the BASE system had eventual consistency, this architecture no longer guarantees that by default.
As will be shown in the next chapter, to get some level of consistency, a lot more work has to be done by the application developers; in some cases, eventual consistency may even be impossible, notably in the case of message loss.
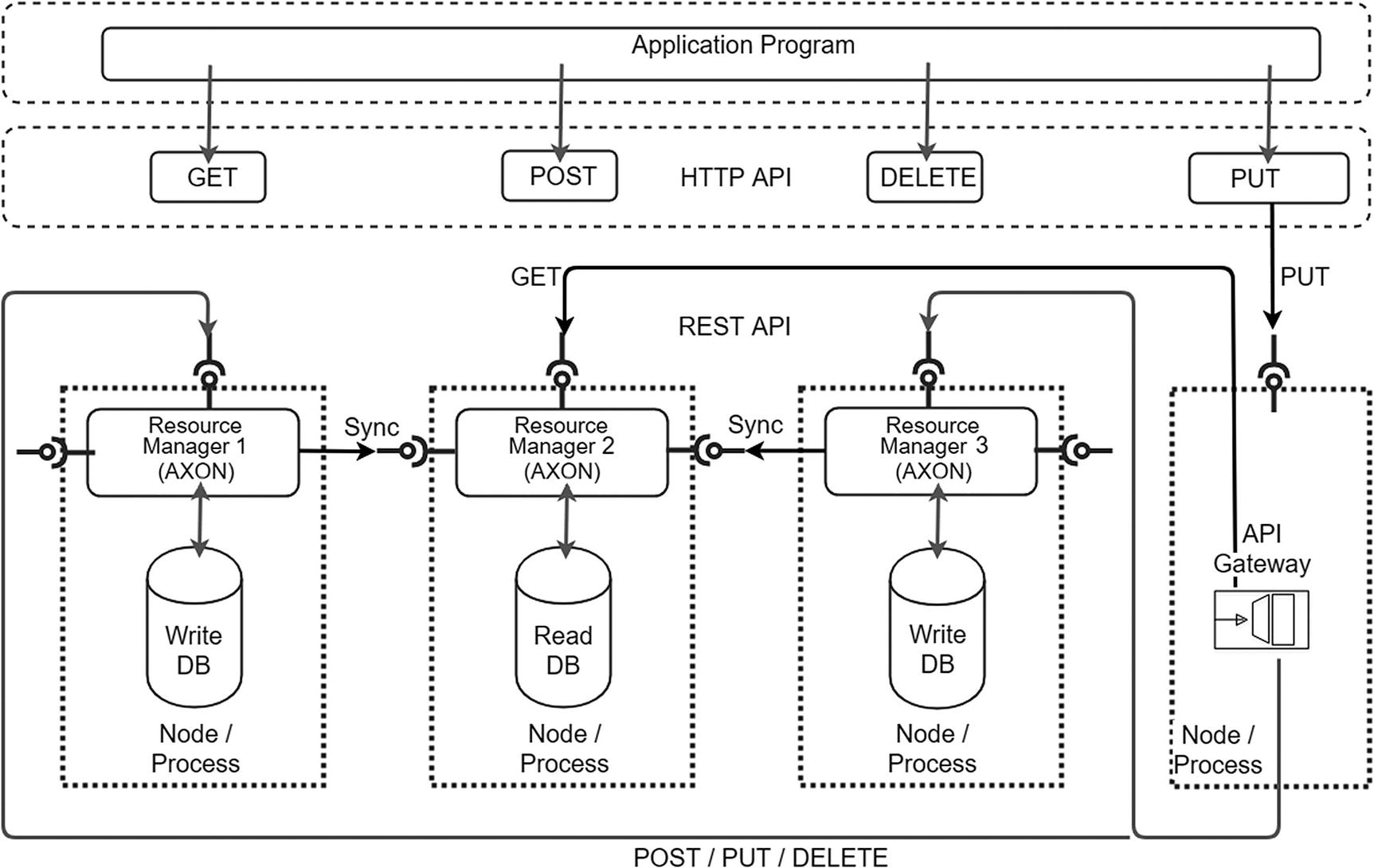
Distributed, relaxed BASE transactions with multiple resources
Microservice resources are distributed across nodes. You want to avoid distributed transactions since locking of resources across nodes will impede system scalability. Further, you are OK for eventual consistency but you don’t mind if you can’t achieve it perfectly. If so, Figure 13-4 illustrates how to follow the relaxed BASE model. Applications interact either directly with one or more of the involved resource managers, or, more typically, through some load balancer or gateway that distributes incoming requests to a pool of resource managers with symmetrical responsibilities and capabilities. Requests are served by one or more resource managers, and changes are propagated to one or more other resource managers subsequently. The number of resource managers involved depends on the sharding model (covered in Chapter 11’s “The Scale Cube” section) and the system configuration chosen, ranging from a single node (single replica) to a quorum of nodes to, theoretically, all replicas of a given data record.
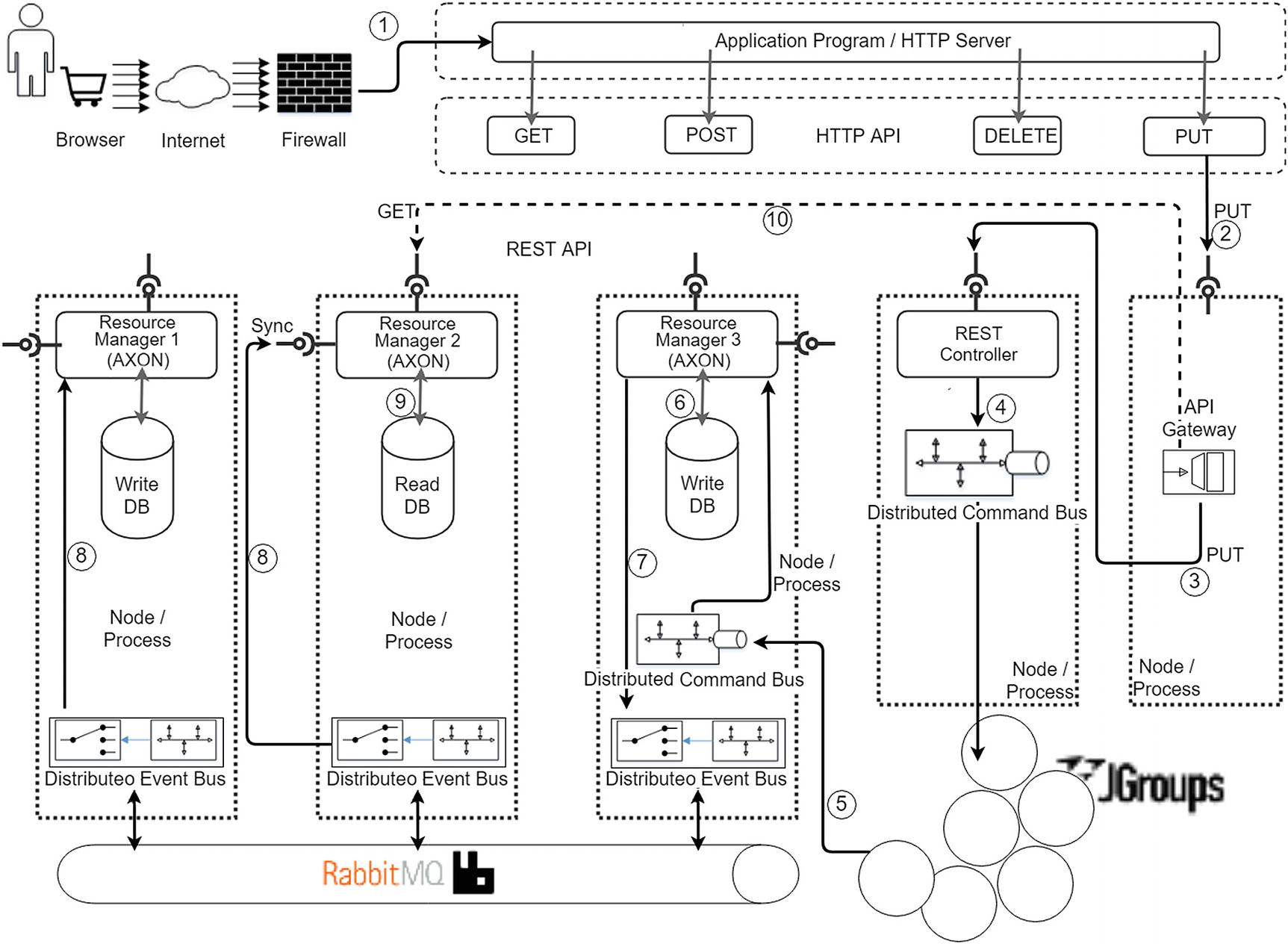
Axon components to support BASE transactions
- 1.
The request is routed to the API gateway.
- 2.
The API gateway routes this request to the first point of contact of the request to the Axon application, which is the (front) REST Controller.
- 3.
The REST Controller, after unpacking the request, interprets it as a request for an entity change and creates a command, following the CQRS pattern. This command is send to the distributed command bus, starting a local transaction.
- 4.
The distributed command bus transports this command to the node containing the respective command handler (Resource Manager 3).
- 5.
The command handler effects the write to the entity with the help of the repository in the Write DB.
- 6.
The above repository change also triggers an event (the “Design the Example Scenario” section under the “Command and Event Handling in Same JVM” section in Chapter 12 provides detailed narration) and this event is sent to the clustered event bus.
- 7.
In Figure 13-5, you can see that the two different event handlers (Resource Manager 1 and Resource Manager 2) are interested in the previous event, and they may also do whatever state changes they dictate.
- 8.
You can see that Resource Manager 2 is in effect synchronizing itself (the Read DB) of any interesting changes in the system.
- 9.
Any subsequent query (HTTP GET) also sees these changes. Eventually, everyone see the changes.
ACID vs. BASE
Such a comparison is like comparing apples and oranges: they are not intended to replace each other, and both are equally good (or bad) at serving their own purpose. This is an easily said statement; however, no CTO-level discussion can end with that straight explanation. Having said that, understanding this distinction is key in “mastering microservices.” If you understand this difference, the main intention of this book is met!
BASE transactions are the base for microservices architecture where we want to stay away from ACID transactions. However, they serve different purposes. There is not much point in debating one over the other, since both solve orthogonal concerns–the reason why the CAP theorem is significant. But then, do you want to completely put aside ACID transactions? It’s like asking whether you as the captain of your fighter jet should have direct control of the seat ejection button or are you comfortable even if you don’t have direct reach to it but you are (almost) sure that your co-pilot will activate it for you at your command? In the former case, you are very sure that you can escape instantaneously, at your own will, when a sudden need arises. In the latter case, you are almost sure that you will still be able to escape; however, there is a percentage of skepticism as to whether the escape will be instantaneous or delayed either due to your co-pilot taking time to execute your command or in the unfortunate event that your co-pilot is not in a position to move his own muscles to act! To restate, the former is synonymous to an ACID transaction, which is relatively more deterministic, whereas the latter is synonymous to a BASE transaction, which (may) eventually happen.
We still need ACID, if not all the time.
Let’s now come to BASE. If you still use ACID at the right level (as in Figure 13-3), then things are easy. On the other hand, an even more relaxed BASE approach is not going to ease your life; in fact, relaxed BASE is going to give you far more complexities than ACID.
Having said that, one way to understand and appreciate the complexities involved in BASE transactions is to understand ACID transactions themselves, so you will do that in the following sections.
Distributed Transactions Revisited
Before you look into concrete examples, you need to understand a few concepts that will set the context for the examples you will explore.
Local Transactions
If you take a typical resource manager, typically that single resource will be confined to a single host or node (even though that may not be the case mandatorily). Operations confined to such a single resource are local transactions and they affect only one transactional resource. Within a single node, there are less (or for practical considerations, nil) nondeterministic operations, hence a command sent to a single node must be considered deterministic, and in case of any catastrophes, there are local recovery mechanisms. These resources have their own transactional APIs, and the notion of a transaction is often exhibited as the concept of a session, which can encapsulate a unit of work with demarcating APIs to tell the resource when the buffered work should be committed to the underlying resource. Thus, from a developer perspective, you do not manage with transactions in a local transaction, but with just “connections.”
A Local Transaction Sample
In Listing 13-1, both the statements will be committed together or rolled back together. However, it is a local transaction, not a distributed transaction.
Distributed Transactions
Typically for the scenario of a distributed transaction to exist, it must span at least two resource managers. Databases, message queues, transaction processing (TP) monitors like IBM’s CICS, BEA’s Tuxedo, SAP Java Connector, and Siebel Systems are common transactional resources, and often, if the transactions has to be distributed, it has to span a couple of such resources. A distributed transaction can be seen as an atomic operation that must be synchronized (or provide ACID properties) among multiple participating resources that are distributed among different physical locations.
JOTM: JOTM is an open source transaction manager implemented in Java. It supports several transaction models and specifications providing transaction support for clients using a wide range of middleware platforms (J2EE, CORBA, Web Services, OSGi).
Narayana: Narayana, formerly known as JBossTS and Arjuna Transaction Service, comes with a very robust implementation that supports both the JTA and JTS APIs. It supports three extended transaction models: nested top-level transactions, nested transactions, and a compensation-based model based on sagas. Further, it also supports web service and RESTful transactions. There is a need for manual integration with the Spring framework, but it provides out-of-the-box integration with Spring Boot.
Atomikos TransactionsEssentials: Atomikos TransactionsEssentials is a production quality implementation that also supports recovery and some exotic features beyond the JTA API. It provides out-of-the-box Spring integration and support for pooled connections for both database and JMS resources.
Bitronix JTA: Bitronix claims to support transaction recovery as well as or even better than some of the commercial products. Bitronix also provides connection pooling and session pooling out of the box.
Distributed Transactions in Java
Coordination of transactions spanning multiple resources are specified by the X/Open standards by opengroup. Java supports X/Open standards by providing two interfaces: JTA (Java Transaction API) and JTS (Java Transaction Service) . As shown in Figure 13-2, JTA is used by application developers to communicate to transaction managers. Since resources can be provided by multiple vendors following different platforms and programming languages, if all of these resources must be coordinated, they have to agree again to the X/Open standards. Here, JTS, which follows CORBA OTS (Object Transaction Service) , provides the required interoperability between different transaction managers sitting with distributed resources.
I have discussed the “distributed nature” in distributed transactions. The two-phase commit protocol is used for coordination of transactions across multiple resource managers.
Distributed Transaction Example Using MySQL, ActiveMQ, Derby, and Atomikos
The easiest way to do away with many data consistency problems, especially when multiple resource managers are involved, is to use XA or distributed transactions even in BASE, as in Figure 13-3. However, if you want to transition to even more relaxed BASE microservices, the design mechanisms have to be more fault tolerant since your XA transaction managers are absent, and they would have done all the hard work. You will walk through the major consistency concern scenarios with the help of an example. Again, I could have demonstrated the concern scenarios straight without using distributed transactions in the example; however, I will take the reverse route and use XA transactions to illustrate the perfect scenario and simulate the various fault conditions by cutting down the ACID scope even more since it is rather easy for you, the reader, to comprehend aspects in this manner. XA transactions allow us to do that by “abusing” the transaction attributes to make the transaction scope smaller than it would normally be. This means that I can reuse the same code to illustrate the anomalies of relaxed BASE incrementally.
The Example Scenario
- 1.
New quotes for stock transactions can be pushed to the Broker Web microservice. New quotes get inserted into a Quotes table, which is in a MySQL DB, with a status of “New.”
- 2.
The Quotes processor task is a quartz scheduled task and it polls the Quotes table in the MySQL DB for any new quotes with a status of “New.”
- 3.
When a new quote with a status of “New” is found, it invokes the processNewQuote method of the broker service, always with a transaction, passing the unique identifier for the new quote into the Quotes table.
- 4.
The broker service makes use of the other transactional services, the auction service and the stock order service, and the execution of both has to be atomic.
- 5.
The auction service confirms the quote received by changing the status of the quote to “Confirmed” within a transaction.
- 6.
The stock order service creates a JMS message out of the information contained in the new quote and is sent to an ActiveMQ queue for settlement of the quote, again within the above (5) transaction.
- 7.
The settlement listener service is listening on the ActiveMQ queue for any new confirmed quote. All confirmed quotes on reaching the ActiveMQ queue are picked up by onMessage of the settlement listener service, within a transaction.
- 8.
The settlement listener service invokes the quotes reconcile service for reconciliation of the quote, again within the above (7) transaction.
- 9.
The quotes reconcile service needs to reconcile the value of the stock traded to the respective user account of the seller and the buyer, within the above (7) transaction.
- 10.
The Broker Web microservice and the Settlement Web microservice are just utilities that provide a dashboard view of the operational data on both the Quotes table as well as the User table to provide live views.
Having seen the high-level business of the example scenario, let’s now pay attention to other infrastructural aspects in the architecture. The Quote Processing microservice has to do atomic operations across two resources, MySQL and ActiveMQ. You need a distributed transaction manager here. Similarly, the Quote Settlement microservice must also do atomic operations across two resources, Derby and ActiveMQ. You need a distributed transaction manager here also.
Code the Example Scenario
The complete code required to demonstrate the distributed transaction example is in folder ch13\ch13-01. There are four microservices to be coded. You will look into them one by one.
Microservice 1: Quote Processing (Broker-MySQL-ActiveMQ)
Maven Dependencies for the Distributed Transactions Example Using MySQL and ActiveMQ (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\pom.xml)
These library dependencies will be clearer when you look at the configuration in detail. Before you do that, let’s inspect the main components in the architecture.
Scheduled Task for Processing New Quotes (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\main\java\com\acme\ecom\schedule\QuotesProcessorTask.java)
Broker Service Coordinating New Quote Processing (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\main\java\com\acme\ecom\service\BrokerServiceImpl.java)
You auto-configure the references to the auction service and the stock order service within the broker service. You have two references of each of these services; this is just a hack to arrange the fixtures for the various test scenarios you are going to validate. To make it clear, you have two references of auction service with the names auctionServiceRequired_TX and auctionServiceRequiresNew_TX. As the name implies, the write methods in auctionServiceRequired_TX get executed in a PROPAGATION_REQUIRED context whereas those in auctionServiceRequiresNew_TX get executed in a PROPAGATION_REQUIRES_NEW context. The rest of the code checks the incoming parameter where you have piggy-backed an indicator (an integer value) to identify which test scenario (test case) you are executing. The general strategy is to use PROPAGATION_REQUIRED if you want to propagate transactions between parent and child services and to use PROPAGATION_REQUIRES_NEW wherever you explicitly generate error conditions so that the error is confined to the context of that respective service method alone, that too in a controlled manner (by using try-catch) and the rest of the execution flow can happen; again, this is to facilitate the fixture for the demonstration purposes.
You need to be aware that, in a real production scenario, you do not want the arrangement of the test scenarios; so if you want atomic operations across services, you just configure everything using PROPAGATION_REQUIRED, the (testCase == 1) scenario alone.
There is another utility method called flipFlop() 6 defined in the broker service. This method flip-flops the simulation of error creation during an operation between two consecutive executions, so if you have simulated an error in one execution of the method, the next execution of the same method will not simulate the error. In this way, if you have executed a test case to validate for an error scenario in one pass, you will also be able to see how the invariants will be if the same flow is executed without that error scenario. This is useful if you want to see if the message consumptions fails between the first pass so that when an attempt to reconsume happens, it will happen without failure in the next pass; in that manner, it is easy for you to test and visualize the results. Leave this here for the time being; it will be clearer when you execute the tests.
Auction Service Confirming New Quotes into MySQL DB (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\main\java\com\acme\ecom\service\AuctionServiceImpl.java)
The auction service changes the status of a new quote to “Confirmed.”
Stock Order Service Sending Messages to ActiveMQ Against Confirmed Quotes (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\main\java\com\acme\ecom\messaging\StockOrderServiceImpl.java)
A Quote Entity (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\main\java\com\acme\ecom\model\quote\Quote.java)
Spring Wiring for Distributed Transactions Example Using MySQL, ActiveMQ, and Atomikos (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\main\resources\spring-sender-mysql.xml)
You touched on local transactions in the “Distributed Transactions Revisited” section earlier and Spring’s PlatformTransactionManager supports local transactions in JDBC, JMS, AMQP, Hibernate, JPA, JDO, and many others usage scenarios. When you want to use XA transactions, org.springframework.transaction.jta.JtaTransactionManager can be used. JtaTransactionManager is a PlatformTransactionManager implementation for JTA, delegating to a back-end JTA provider. This is typically used to delegate to a Java EE server’s transaction coordinator like Oracle WebLogicJtaTransactionManager or IBM WebSphereUowTransactionManager , but may also be configured with a local JTA provider that is embedded within the application like Atomikos. Embedded transaction managers give you the freedom of not using a full-fledged app server; you still get much of the XA transaction support similar to what you get from an app server in your standalone JVM applications.
AuctionService.confirmQuote()
StockOrderService.sendOrderMessage()
BrokerService.processNewQuote()
- AuctionService.confirmQuote()
<prop key="confirm*">PROPAGATION_REQUIRED</prop>
- StockOrderService.sendOrderMessage()
<prop key="sendOrderMessage*">PROPAGATION_REQUIRED</prop>
- BrokerService.processNewQuote()
<prop key="process*">PROPAGATION_REQUIRED</prop>
Further, the recommended way to indicate to the Spring Framework’s transaction infrastructure that a transaction’s work is to be rolled back is to throw an exception from code that is currently executing in the context of a transaction. The Spring Framework’s transaction infrastructure code will catch any unhandled exception as it bubbles up the call stack and will mark the transaction for rollback.
That’s all you want to do to wire the business components. Now, if there is an error within any of the above three methods, it will roll back the state changes affected by all three business methods in the underlying resource managers taking part in the XA transaction.
Spring Wiring for XA JMS Resources for the Distributed Transactions Example ActiveMQ Atomikos (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\main\resources\spring-sender-mysql.xml)
The JmsTemplate used by StockOrderService uses com.atomikos.jms.AtomikosConnectionFactoryBean, which is the Atomikos’s JMS 1.1 connection factory for JTA-enabled JMS operations. You can use an instance of this class to make JMS participate in JTA transactions without having to issue the low-level XA calls yourself. You set whether local transactions are desired by using the localTransactionMode property , which defaults to false. With local transactions, no XA enlist will be done; rather, the application should perform session-level JMS commits or rollbacks instead. Note that this feature also requires support from your JMS provider, ActiveMQ in your case. The xaConnectionFactory property is the basic connection factory that encapsulates the plumbing for connecting to the ActiveMQ broker. In your case, the bean is an instance of ActiveMQXAConnectionFactory type, which is a special connection factory class that you must use when you want to connect to the ActiveMQ broker with support for XA transactions.
Spring Wiring for XA JDBC Resources for the Distributed Transactions Example Using MySQL and Atomikos (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\main\resources\spring-sender-mysql.xml)
You can use an instance of the com.atomikos.jdbc. AtomikosDataSourceBean class if you want to use Atomikos JTA-enabled connection pooling. You need to construct an instance and set the required properties, and the resulting bean will automatically register with the transaction service and take part in active transactions. All SQL done over connections received from this class will participate in JTA transactions. Starting with Connector/J 5.0.0, the javax.sql.XADataSource interface is implemented using the com.mysql.jdbc.jdbc2.optional.MysqlXADataSource class , which supports XA distributed transactions when used in combination with MySQL server version 5.0 and later. You set an instance of MysqlXADataSource as the xaDataSource property for the AtomikosDataSourceBean class.
Next, the LocalContainerEntityManagerFactoryBean is Spring’s FactoryBean that creates a JPA EntityManagerFactory, which can then be passed to JPA-based DAOs via dependency injection. Starting with Spring 3.1, the persistence.xml is no longer necessary and LocalContainerEntityManagerFactoryBean supports a packagesToScan property where the packages to scan for @Entity classes can be specified.
Resolving JTA UserTransaction and TransactionManager (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\main\java\com\acme\ecom\AtomikosJtaPlatform.java)
Having looked at the overall configurations, let’s also look into more details of the infrastructure configurations with reference to Listing 13-9 and Listing 13-10.
You need to set the dataSource property of LocalContainerEntityManagerFactoryBean to a JDBC DataSource that the JPA persistence provider is supposed to use for accessing the database. The DataSource passed in here will be used as a nonJtaDataSource on the PersistenceUnitInfo passed to the PersistenceProvider. Note that this variant typically works for JTA transaction management as well; if it does not, consider using the explicit property jtaDataSource instead. You use the AtomikosDataSourceBean explained previously to set this property.
Next, you need a service provider interface implementation that allows you to plug in vendor-specific behavior into Spring’s EntityManagerFactory creators. HibernateJpaVendorAdapter is an implementation for Hibernate EntityManager. It supports the detection of annotated packages along with other things. The JPA module of Spring Data contains a custom namespace, <jpa:repositories, that allows the defining of repository beans. It also contains certain features and element attributes that are special to JPA. Generally, the JPA repositories can be set up using the repositories element. In this example, Spring is instructed to scan com.acme.ecom.repository.quote and all its subpackages for interfaces extending Repository or one of its subinterfaces. For each interface found, the infrastructure registers the persistence technology-specific FactoryBean to create the appropriate proxies to handle invocations of the query methods. Each bean is registered under a bean name that is derived from the interface name, so your interface of QuoteRepository would be registered under quoteRepository. The entity-manager-factory-ref will help to explicitly wire the EntityManagerFactory to be used with the repositories being detected by the repositories element. This property is usually used if multiple EntityManagerFactory beans are used within the application. If not explicitly configured, Spring will automatically look up the single EntityManagerFactory configured in the ApplicationContext.
This completes the configuration of both XA resources. Next, you must configure the XA transaction manager.
You need org.springframework.transaction.jta. JtaTransactionManager , which is an implementation of PlatformTransactionManager. You need to provide implementations of javax.transaction. TransactionManager and javax.transaction.UserTransaction to create a JtaTransactionManager.
The javax.transaction.UserTransaction interface provides the application the ability to control transaction boundaries programmatically. This interface may be used by Java client programs or Enterprise Java Beans. The UserTransaction.begin() method starts a global transaction and associates the transaction with the calling thread. The transaction-to-thread association is managed transparently by the transaction manager. Thus the UserTransaction is the user-facing API.
com.atomikos.icatch.jta. UserTransactionManager is a straightforward, zero-setup implementation of javax.transaction.TransactionManager. Standalone Java applications can use an instance of this class to get a handle to the transaction manager and automatically start up or recover the transaction service on first use. com.atomikos.icatch.jta. UserTransactionImp is the javax.transaction.UserTransaction implementation from Atomikos which you can use for standalone Java applications. This class again automatically starts up and recovers the transaction service on first use.
org.springframework.transaction.jta.JtaTransactionManager is a PlatformTransactionManager implementation for JTA, delegating to back-end JTA providers. It is typically used to delegate to a Java EE server’s transaction coordinator, but in your case, you have configured with Atomikos JTA provider, which is embedded within the application.
Microservice 2: Broker-Web

The Broker Web console
Microservice 3: Quote Settlement (Settlement-ActiveMQ-Derby)
Maven Dependency for the Derby Client (ch13\ch13-01\XA-TX-Distributed\Settlement-ActiveMQ-Derby\pom.xml)
My intention with using a Derby database in place of MySQL is just to make you, the reader, comfortable using XA transactions with an additional XA-compliant resource, a Derby database, so that as a subsequent exercise you have all the tools to try for yourself XA transactions across two XA-compliant databases within a single XA transactions. But you will not attempt that exercise in this text, since it is outside the scope of our discussion.
Transacted Message Listener Orchestrating Message Consumtion and Quotes Settlement (ch13\ch13-01\XA-TX-Distributed\Settlement-ActiveMQ-Derby\src\main\java\com\acme\ecom\messaging\SettlementListener.java)
Quotes Reconcile Service Doing Settlement Reconciliation (ch13\ch13-01\XA-TX-Distributed\Settlement-ActiveMQ-Derby\src\main\java\com\acme\ecom\service\QuotesReconcileServiceImpl.java)
User Entity (ch13\ch13-01\XA-TX-Distributed\Settlement-ActiveMQ-Derby\src\main\java\com\acme\ecom\model\user\User.java)
Spring Wiring for the Distributed Transactions Example Using Derby, ActiveMQ, and Atomikos (ch13\ch13-01\XA-TX-Distributed\Settlement-ActiveMQ-Derby\src\main\resources\spring-listener-derbyl.xml)
I have already explained all of the configurations above except that of DefaultMessageListenerContainer. DefaultMessageListenerContainer is a message listener container variant that uses plain JMS client APIs, specifically a loop of MessageConsumer.receive() calls that also allow for transactional reception of messages when registered with an XA transaction manager. This is designed to work in a native JMS environment as well as in a Java EE environment. You first set your standard JMS message listener, which is the settlement listener, so that messages can be picked up by the SettlementListener.onMessage().
Microservice 4: Settlement-Web

The Settlement Web console
Main Test Class at the Quote Processor End (ch13\ch13-01\XA-TX-Distributed\Broker-MySQL-ActiveMQ\src\test\java\com\acme\ecom\test\BrokerServiceTest.java)
Another Test Class at the Quote Settlement End (ch13\ch13-01\XA-TX-Distributed\Settlement-ActiveMQ-Derby\src\test\java\com\acme\ecom\test\SettlementListenerServiceTest.java)
Build and Test the Example’s Happy Flow
As the first step, you need to bring up the ActiveMQ server. You may want to refer to Appendix F to get started with ActiveMQ.
The ActiveMQ Queue Configuration (D:\Applns\apache\ActiveMQ\apache-activemq-5.13.3\conf\activemq.xml)
Note
You are using the ij tool from a base location different from your Derby installation, assuming that your database is in a location different from that of the Derby installation, which is a best practice. For further details on how to create a new database, refer to Appendix G.
This completes the infrastructure required to build and run the example.
Next, there are four microservices to build and get running. You will do this one by one.
Microservice 1: Quote Processing Microservice
Microservice 2: Broker Web Microservice
This will bring up the Broker Web Spring Boot Server in port 8080.
You can use a browser (preferably Chrome) and point to the following URL to keep monitoring the processing of all new incoming quotes: http://localhost:8080/.
Microservice 3: Quote Settlement Microservice
Microservice 4: Settlement Web Microservice
This will bring up the Settlement Web Spring Boot Server in port 8080.
You can use a browser (preferably Chrome) and point to the following URL to keep monitoring the running account status of the users and how the account balance changes as each new incoming quote is settled: http://localhost:8081/.

Test cases
In the truest sense, there are only three test cases that validate the example and they are the first, second, and the seventh test cases. All other test cases invalidate the example either by simulating various failure conditions or by adjusting the transaction semantics applied to service methods. I do that to make you understand possible error scenarios that can occur in a distributed transactions environment.
In this section, you will look at the first test case, which demonstrates strict ACID compliant transaction in the end-to-end flow. This means either all of the state changes in the resources will be approved or all of them will be rolled back. The rest of the test cases will be executed in the subsequent sections one by one.
Create test users

Test user console

Create a new quote

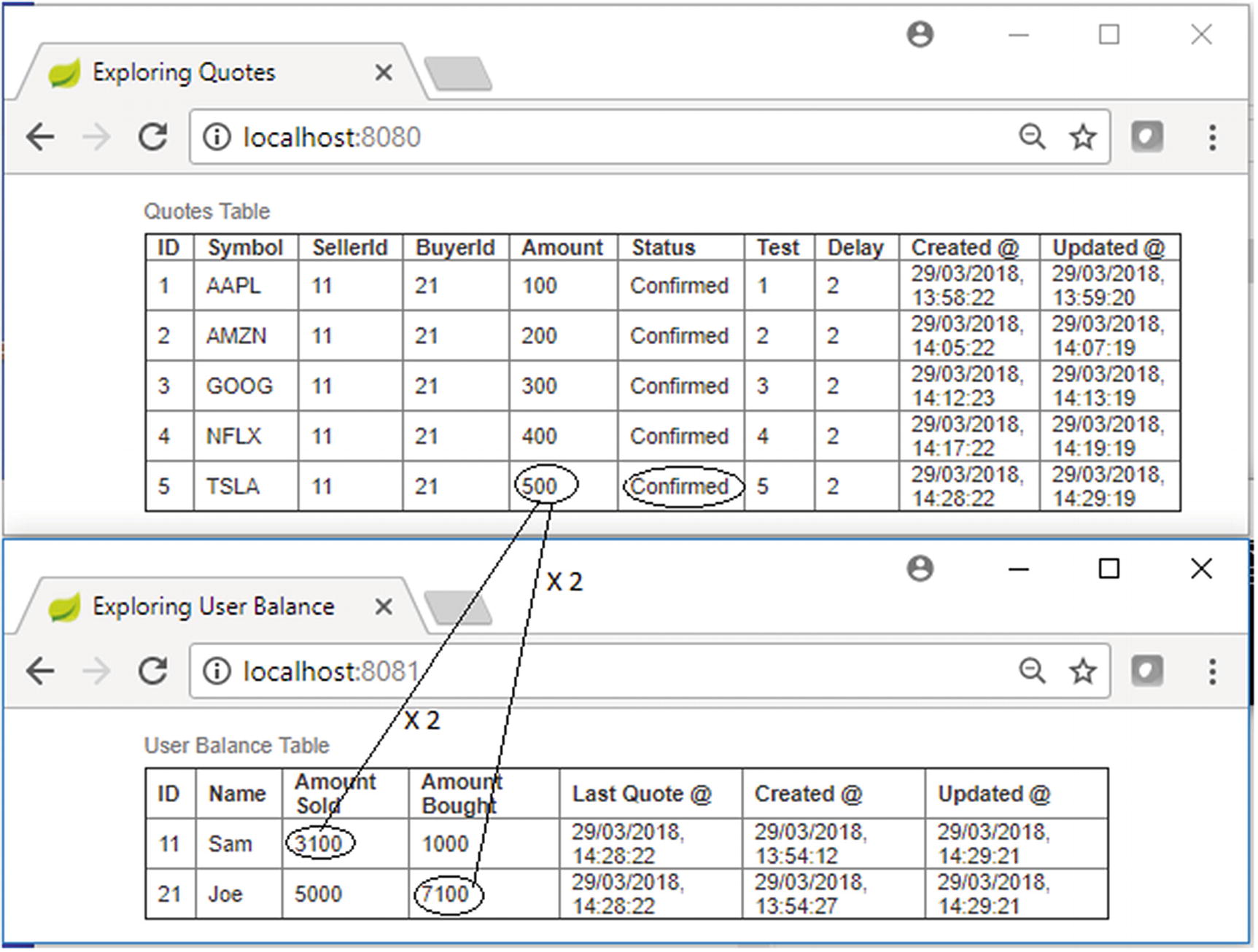
A new quote arrived for Test Case 1

Test Case 1 console
You should also note another aspect in Figure 13-13, which will be relevant in Test Case 8, in the “Test the Message Received Out of Order Scenario” section later. The latest quote creation time in the upstream system gets updated as the Last Quote Time for users whenever the respective user account gets updated.

Test Case 1 transaction semantics
As shown in Figure 13-14, you applied TX_REQUIRED transaction semantics to all service methods. This means either all of the state changes in the resources will be made or all of them will be rolled back. In the current test case, you have not simulated any errors or failure conditions, hence all of the transactions succeeded.
In subsequent test cases you are going to simulate error conditions to better understand possible failure conditions in enterprise scenarios. A thorough understanding of all of these possible failure conditions will arm you with better insight, which is very much required when you design for “true microservices,” where you want to stay away from distributed transactions!
Test the Transaction Rollback Scenario
Test Case 2 transaction semantics
As shown in Figure 13-15, TX_REQUIRED transaction semantics have been applied to all service methods. This means either all of the state changes in the resources will be made or all of them will be rolled back.
In the first pass of execution when the Quotes Processor Task picks up the new quote for processing, you simulate an error within the broker service. This is marked by an X sign in Figure 13-15. So, even though the corresponding transactions in the auction service and stock order service were ready to commit, as shown by the ✓ sign, they will be rolled back since both of them were called within the context of the parent transaction of the broker service where you simulate the error. This is shown in the Quote Processing microservice’s console in Figure 13-16.

Test Case 2 processing first pass

New quote arrived for Test Case 2
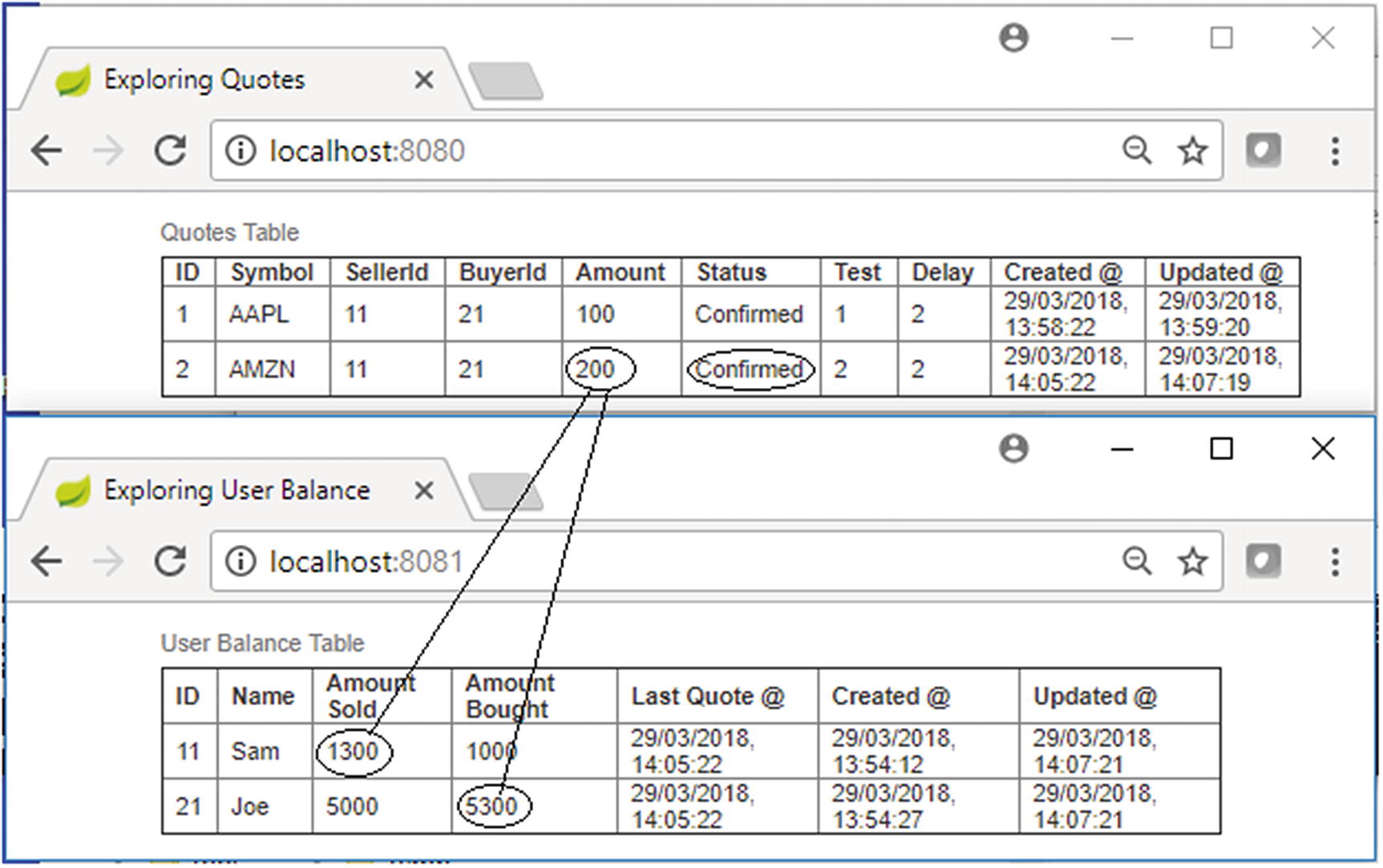
Test Case 2 console
Caution
As a reader, if you follow the execution of tests mentioned in this chapter exactly, it is easy for you to visualize the effects and understand based on the explanation and screenshots provided here. So you are strongly advised to follow exactly as directed. Further, this setup automatically makes the first pass fail and the second pass succeed for few of the test cases. This mechanism is designed in that manner to make intervention from the reader at a minimum during the test execution. However, the test fixtures will work only if you execute tests cases with a single test client (Postman Browser client). So do not (monkey) test the example with concurrent test clients. Later, when you are comfortable executing the tests as described and can follow the explanations provided, then you may start tweaking the code and test fixtures to test further scenarios of your own.
Simulating Relaxed Base Anomalies
So far you implemented a BASE system with a reasonable degree of ACID transactions so you are sure that eventual consistency is preserved. Now, let’s abuse the transaction attributes to artificially “cut down” the scope of ACID transactions even more, which brings you into the following relaxed BASE situations.
Test the Lost Message Scenario
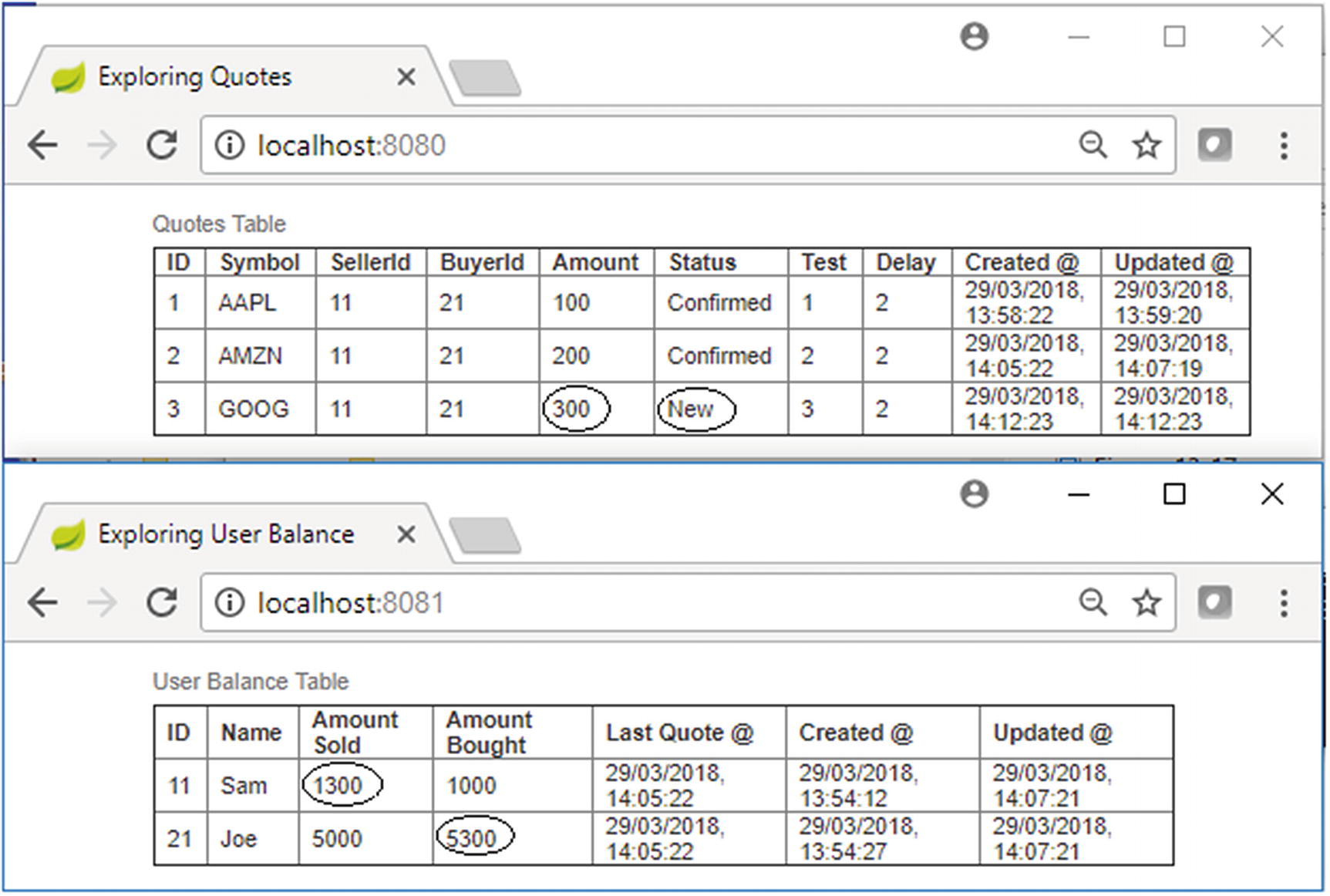
Test Case 3 console at first
Test Case 3 transaction semantics

Test Case 3 console at completion
Test the Duplicate Message Sent Scenario
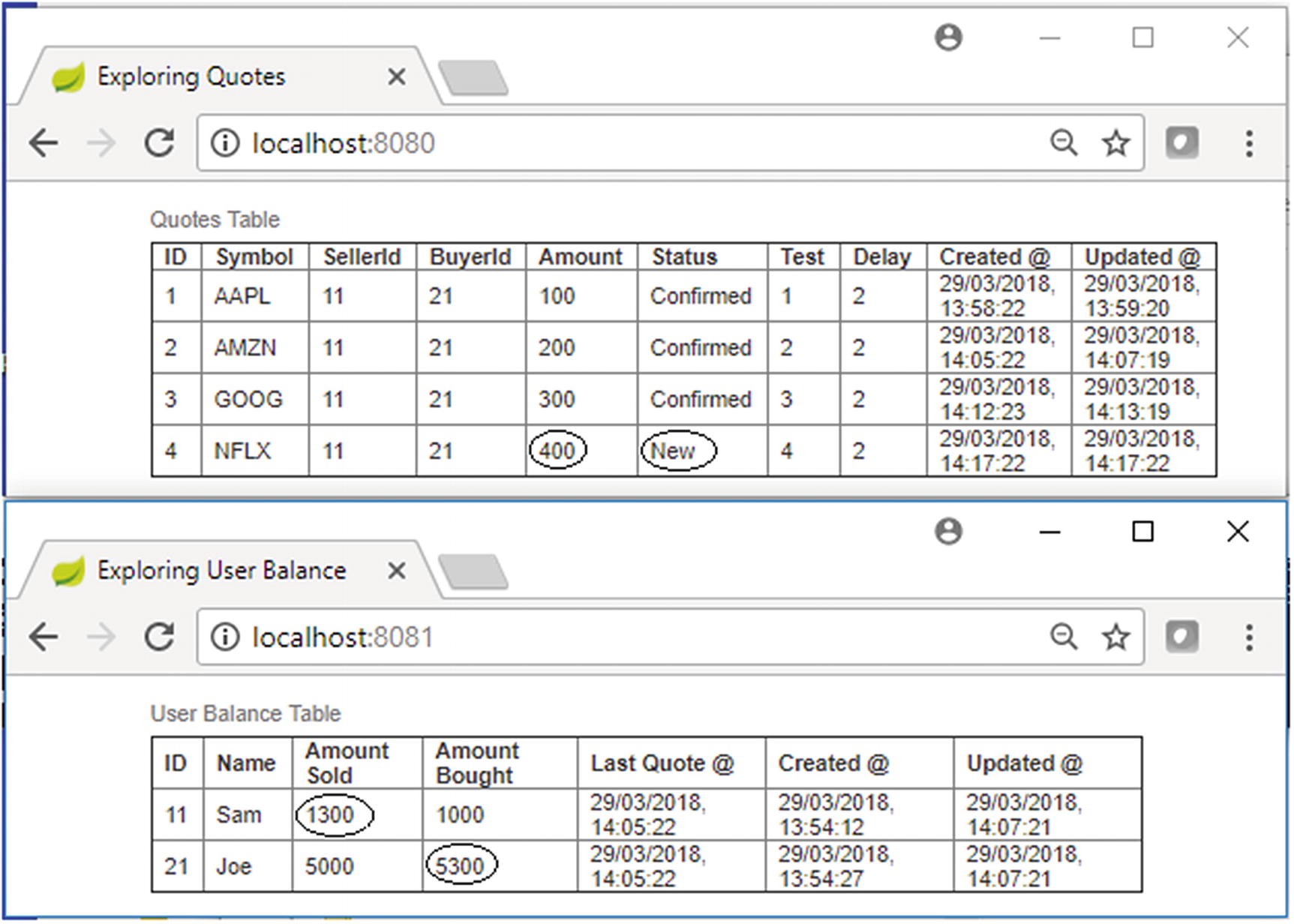
Test Case 4 console, initially

Test Case 4 transaction semantics
Here, the Quotes Processor Task picks up the new quote for processing. You simulate an error within the auction service. This is marked by an X sign in Figure 13-23. The peer transaction in the stock order service has to succeed, so it’s marked with a ✓ sign. The parent transaction in the broker service also needs to succeed. This means the error in the auction service shouldn’t affect the parent transaction in the broker service or the peer transaction in the stock order service, so you put TX_REQUIRES_NEW semantics for the auction service. The net effect is that the status of the quote marked as “Confirmed” will be rolled back; however, the new quote message to ActiveMQ will succeed.

Test Case 4 console, intermediate view
Alarmingly enough, you can see that the quote settlement happened and the quote amount of 400 gets added to the respective running balances of the buyer and seller, as shown in Figure 13-24; however, in the upstream systems, the quote is yet not marked as “Confirmed.” This is because the auction service, which marked the quote as “Confirmed,” got rolled back!
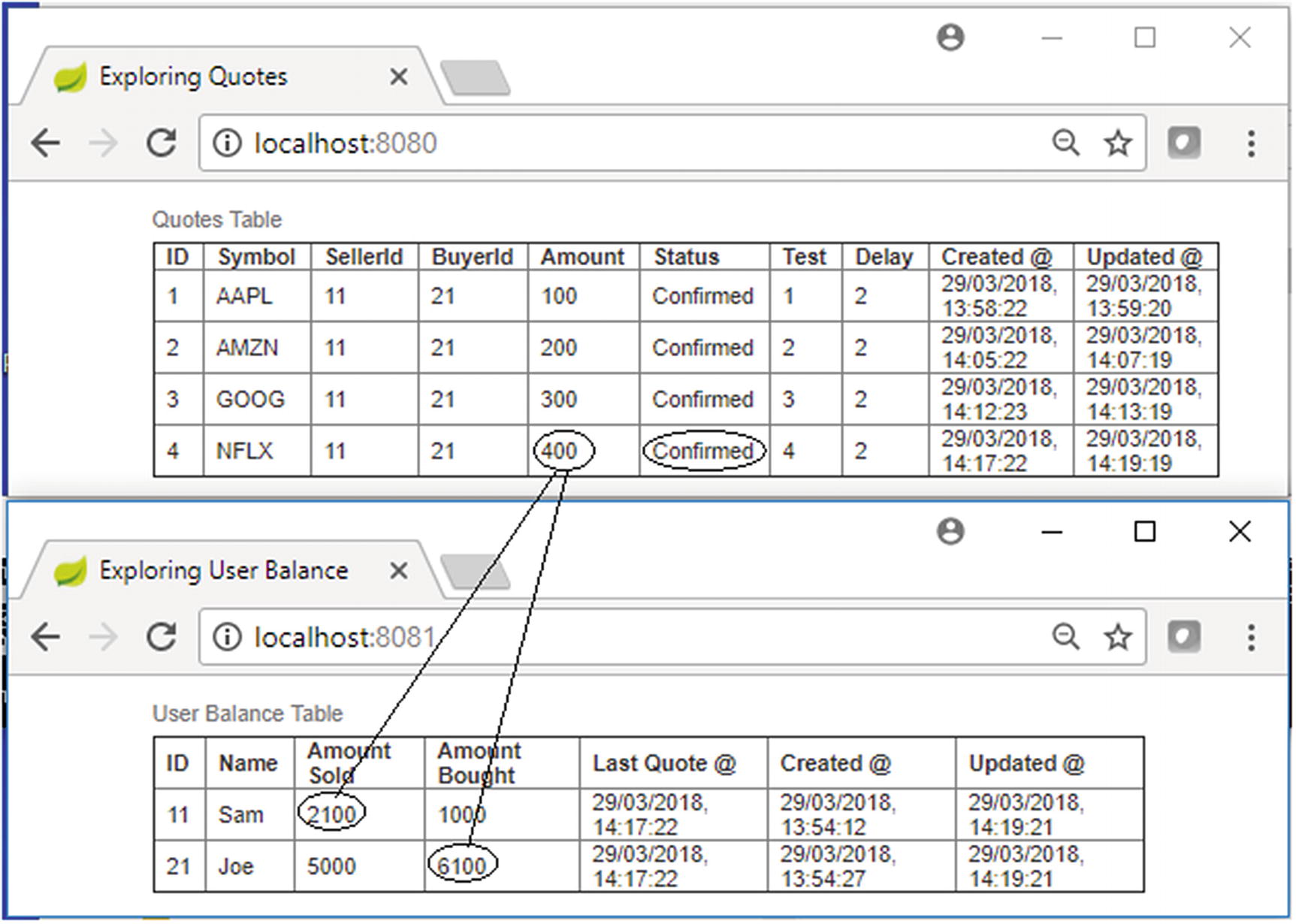
Test Case 4 console at completion
This is not intended. The duplicate message caused the duplicate settlement of the quote!
Test the Duplicate Message Consumption Scenario
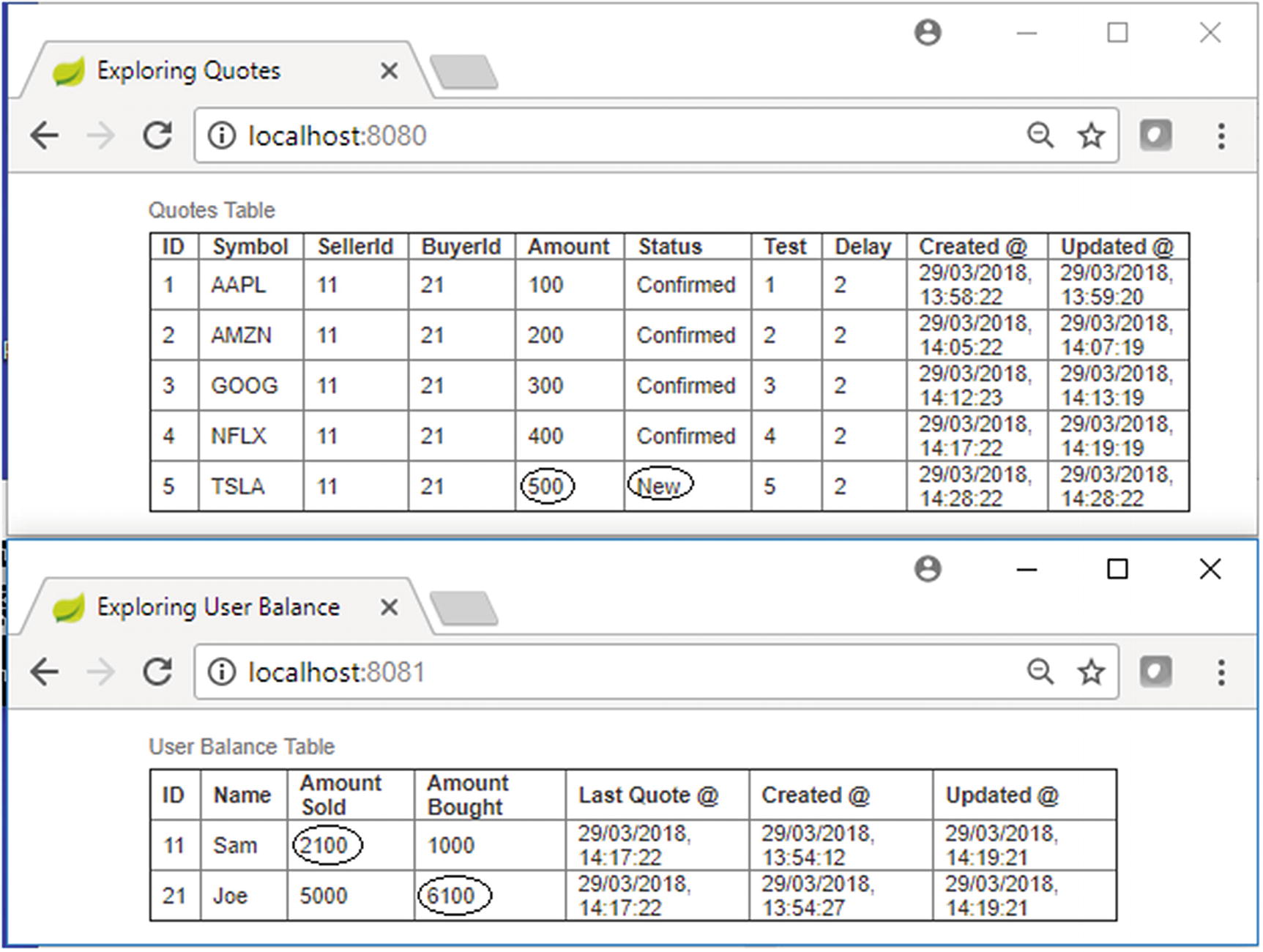
Test Case 5 console, initially
Test Case 5 transaction semantics
Here, there are no errors simulated in any upstream processing, so the quote status will change from “New” to “Confirmed,” and since the new quote message delivery to ActiveMQ is also successful, the Quote Settlement microservice will receive the quote message for settlement. The settlement listener service will receive the message and subsequently invoke the quote reconcile service for settlement. Settlement happens during which the running balances of the buyer and seller are updated. However, once the control comes back from the quote reconcile service, an error is simulated, as shown in Figure 13-27 by the X sign in the first pass for the settlement listener service.
The settlement done by the quote reconcile service is done within a TX_REQUIRES_NEW transaction context, so the error happens at the enclosing or the parent transaction (the transaction of the settlement listener service) will not have any effect on the transaction of the quote reconcile service, so the effect of the settlement is committed.
Even though the settlement listener service has read the message from ActiveMQ, the message listener method, which is in a TX_REQUIRED transaction context, will not commit the message read from ActiveMQ. Hence for ActiveMQ, the message delivery didn’t succeed, so it will try to deliver the message again.
Test Case 5 transaction semantics
Test the Message Consumed, Processing Failure Scenario

Test Case 6 console, initially
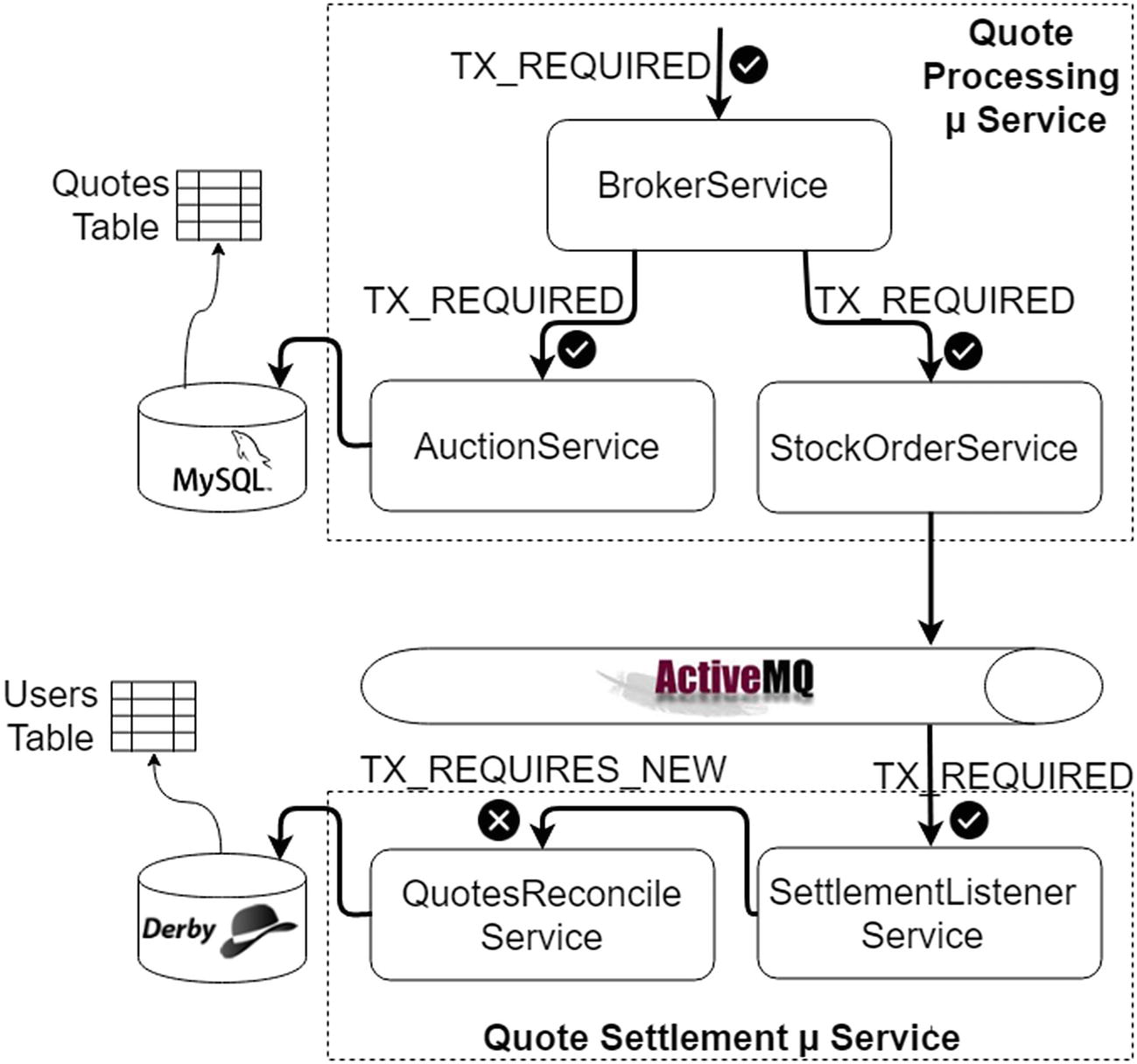
Test Case 6 transaction semantics
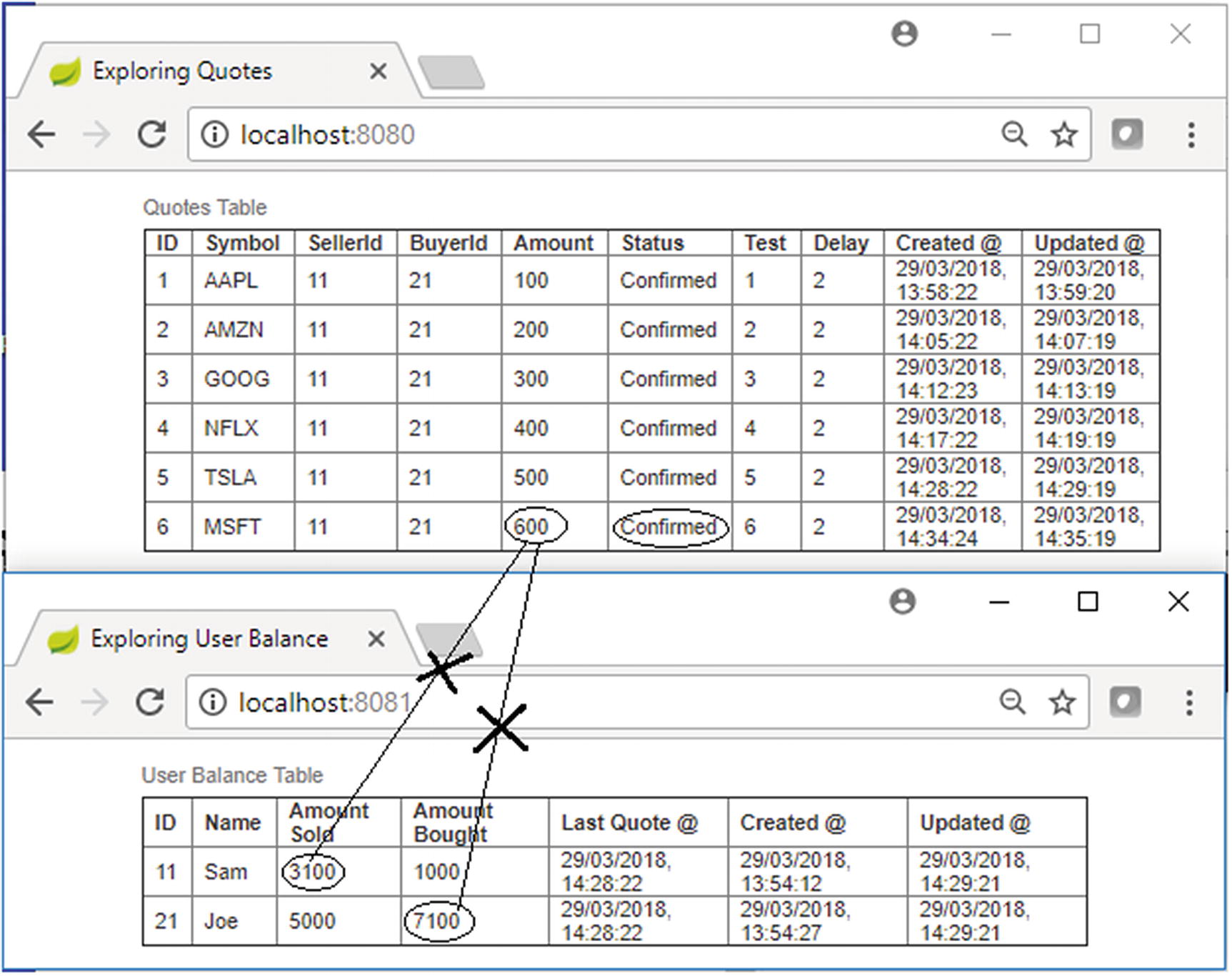
Test Case 6 console, complete
Test the Message Redelivery Scenario
JMS offers no ordering guarantees regarding message delivery, so messages sent first can arrive after messages sent at a later time. This holds regardless of whether you use XA transactions or not.

Test Case 7 console, initially

Test Case 7 transaction semantics
In this case too there are no errors simulated in any upstream processing, hence the quote status will change from “New” to “Confirmed” and since the new quote message delivery to ActiveMQ is also successful, the Quote Settlement microservice will receive the quote message for settlement. The settlement listener service will receive the message and subsequently invoke the quote reconcile service for settlement. Settlement happens, during which it attempts to update the running balances of the buyer and seller. However, during the first pass, an error is simulated within the quote reconcile service transaction, as shown in Figure 13-33 by the X sign. Further, once the control comes back from the quote reconcile service, another error is simulated within the settlement listener service, as shown in Figure 13-33 by the X sign in the first pass by the settlement listener service.

Test Case 7 console, complete
Common Messaging Pitfalls
In this section, I will demonstrate few common messaging pitfalls which can occur in distributed scenarios if you have not designed the system carefully.
Test the Message Received Out of Order Scenario
Testing for this scenario is slightly tricky since you need to coordinate the timing of each action as per the test fixtures. I will explain based on the configuration for my test fixtures, and they should work for you too if you have not done any changes to the example configurations.
You need to send a new quote for upstream processing but you want to delay the processing for a little. While this quote is waiting for the delay to be over, you also want to fire one more new quote for upstream processing, which will get processed nearly straight through without any delay. As a result, the quote created later has to reach the downstream system for further processing first, followed by the quote created initially. In this manner, you need to simulate messages arriving out of order at the downstream system.
Before you start firing requests for this test case, read the rest of this section completely once to understand the preparations you need to make mentally so as to fire new quotes as per instructions. Then come back to this point of the explanation again, read it again, and continue the actual test.

Test Case 8 transaction semantics
As shown in Figure 13-35, you don’t simulate any error scenarios; instead, you simulate only messages reaching out of order.

Test Case 8 console, creating the first quote
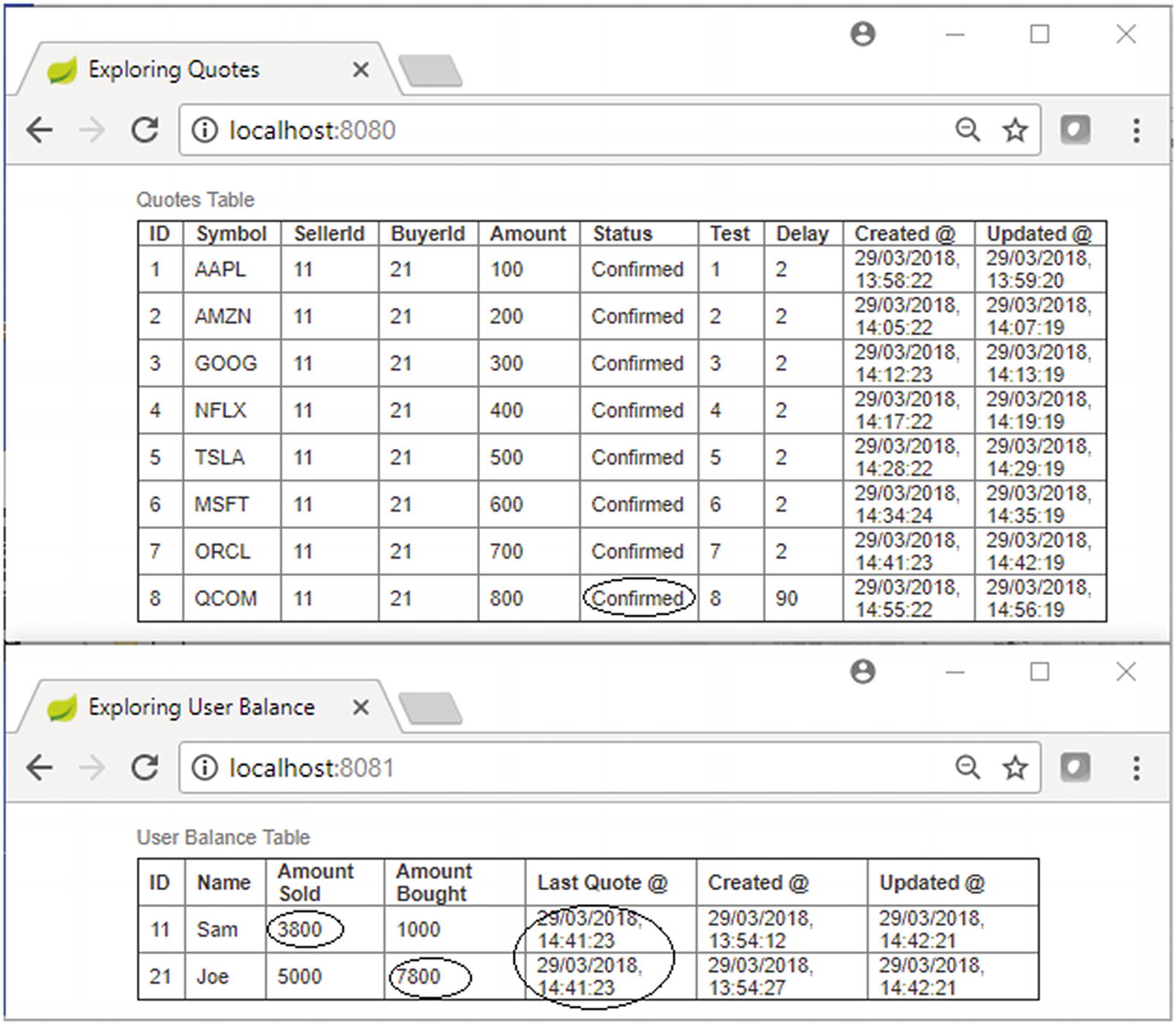
Test Case 8 console, showing the delay
This 90 seconds has a significance because the next time-out of the Quote Processor Task will happen in the next 60 seconds, and during that time-out it shouldn’t fetch this quote because it is already in a processing state (the quote status is not “New”).

Test Case 8 console, creating a second quote
When the Quote Processor Task times out next, it will fetch this second new quote alone. This is because even though the first quote is still under process in the upstream system, the status of the quote has already been updated to “Confirmed,” as shown in Figure 13-38. This is shown by marking the transaction of the Auction Service as TX_REQUIRES_NEW, as is evident in Figure 13-35 (another hack for demonstration purposes).

Test Case 8 console, second quote settled first

Test Case 8 console, first quote settled in second place
In the “Build and Test the Example’s Happy Flow" section earlier, you read that the latest quote creation time in the upstream system gets updated as the last quote time whenever the user account gets updated. Going by this logic, Quote ID 9 in Figure 13-40 is the latest quote created, so the creation timestamp of that quote should be the last quote time for the users. However, since Quote ID 8 and Quote ID 9 reached the downstream systems out of order, this sanity of data attribute rule went wrong!
Summary
Transactions are the bread and butter for the dynamics of any enterprise-class application. Local transactions are good; however, distributed transactions across partitioned domains are not among the good guys. When you shift from a monolith-based architecture to a microservices-based architecture, you still need transactions; however, you are better off with BASE transactions in place of ACID transactions for domains across partitions and keep ACID or XA compliant transactions within partitions or domains. In this chapter, you saw many error scenarios possible in distributed enterprise systems, and you also saw how such error scenarios could be avoided had you been using ACID transactions. When you shift from monolith- to microservices-based architecture, there is no reduction in the above error scenarios; instead, there is a magnitude of increase in such error scenarios since the degree of distribution of microservices-based architectures are increased manyfold. In the next chapter, you will see techniques you can use in architecting distributed systems to safeguard against such error scenarios, so continue happy reading!