As a library within the OS-Interface, SQLite will have many functions implemented through a program called tclsqlite.c. Many technologies and reserved words are used in different languages, but here we have used C language. The core functions are to be found in main.c, legacy.c, and vmbeapi.c. There is also a source code file in C for the TCL language, to avoid any confusion; the prefix of sqlite3 is used at the beginning of the SQLite library.
The Tokenizer code base is found within tokenize.c. Its task is to look at the strings that are passed to it and partition or separate them into tokens, which are then passed to the parser. The tokenize.c file is included in the code with an include statement and is located in the sqlite/src/tokenize.c directory area.
The Parser code base is found within parse.y. The Lemon LALR(1) parser generator is the parser for SQLite; it takes the concept of tokens and assigns them a meaning. To keep within the low-sized footprint of RDBMS, only one C file is used for the parse generator.
The Code Generator is then used to create SQL statements from the outputted tokens of the parser. It will produce some virtual machine code that will carry out the work of SQL statements. Several files, such as attach.c, build.c, delete.c, select.c, and update.c, will handle the SQL statements and syntax.
Virtual machines execute the code that is generated from the Code Generator. It has in-built storage, where each instruction may have up to three additional operands as a part of each code. The source file is called vdbe.c, which is a part of the SQLite database library. Built in is also a computing engine that has been specially created to integrate with the database system.
There are two header files for virtual machines. The header files that interface a link between the SQLite libraries are vdbe.h and vdbeaux.c, which have utilities used by other modules. The vdbeapi.c file also connects to virtual machines with sqlite3_bind and other related interfaces. C language routines are called from SQL functions to reference them to the header files. For example, functions such as count() are defined in func.c, and date functions are located in date.c.
B-tree is a type of table implementation used in SQLite, and the C source file is btree.c. The btree.h header file defines the interface of the B-tree system. There is a different B-tree setup for every table and index held within the same file. There is a header portion within btree.c, which will have details of B-tree in a large comment field.
Pager or Page Cache using B-tree will ask for data in a fixed size format. The default size is 1024 bytes, but it can be between 512 and 65536 bytes. Commit and Rollback operations, coupled with the caching, reading, and writing of the data, are handled by Page Cache or Pager. Data locking mechanisms are also handled by Page Cache. The C file called page.c is implemented to handle requests within the SQLite library and the header file is pager.h.
The OS Interface C file is defined in os.h. It addresses how SQLite can be used on different operating systems, and it becomes transparent and portable to the user, thus becoming a valuable solution for any developer. An abstract layer to handle Win32 and POSIX compliant systems is also kept in place. Different operating systems have their own C file. For example, os_win.c is for Windows, os_unix.c is for Unix; both are coupled with their own os_win.h and os_unix.h header files.
Util.c is the C file that will handle memory allocation and string comparisons. The Utf.c C file will hold Unicode conversion subroutines.
For more information on the architecture of SQLite, see Figure 2:
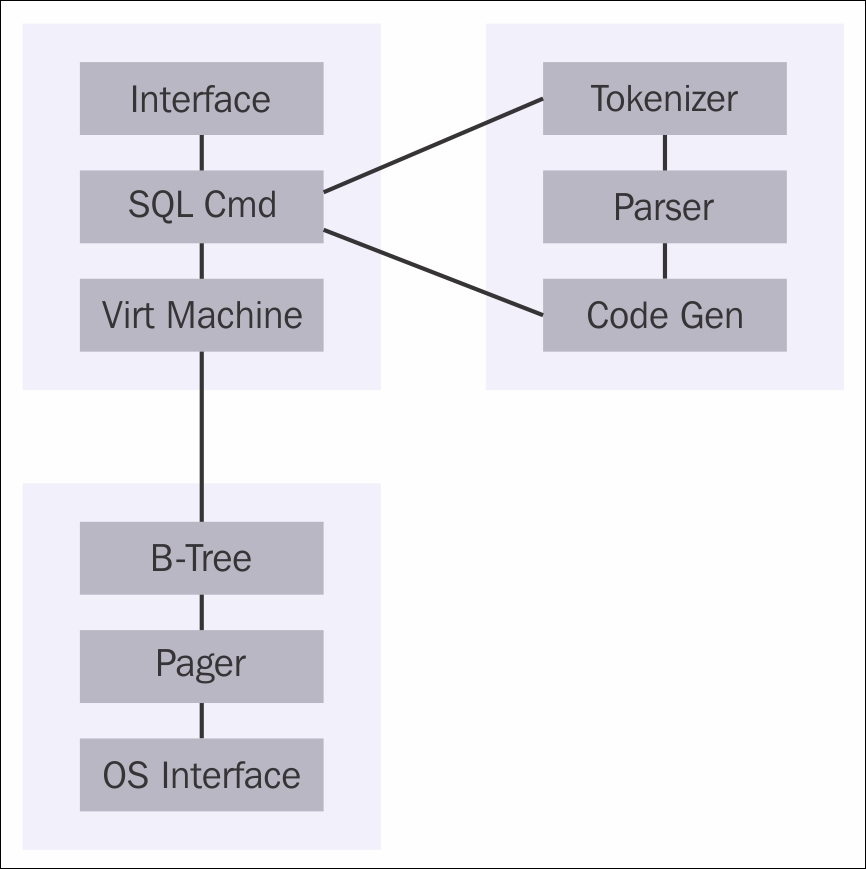
Figure 2: Architecture diagram of SQLite
The Utf.c C file will hold the Unicode data, sort it within the SQL engine, and use the engine as a mechanism for computing data. Since the memory of the device is limited and the database size has the same constraints, the developer has to think outside the box to use these techniques.
These types of memory and resource management formed a part of the approach when the overlay techniques were used in the past and the disk and memory was limited:
SELECT parameter1, STTDEV(parameter2)
FROM Table1 Group by parameter1
HAVING parameter1 > MAX(parameter3)