Index
Entries in bold are R functions
- 1 parameter “1” as the intercept
- 1:6 generate a sequence 1 to 6
- = = (“double equals”) logical EQUALS
- != logical NOT EQUAL
- for barplot
- influence testing
- with subsets
- / division
- / nesting of explanatory variables
- %% modulo
- & logical AND
- | conditioning (“given”)
- ( ) arguments to functions
- (a,b] from and including a, up to but not
- including b
- * main effects and interaction terms in a model
- * multiplication
- : generate a sequence; e.g. 1:6
- [[ ]] subscripts for lists
- [ ] subscripts
- [a,b) include b but not a
- \\ double backslash in file paths
- ^ for powers and roots
- { } in defining functions
- in for loops
- <- gets operator
- < less than
- > greater than
- 1st Quartile with summary
- 3rd Quartile with summary
- a intercept in linear regression
- a priori contrasts
- abline function for adding straight lines to a
- plots
- after Ancova
- in Anova
- with a linear model as its argument
- abline(h = 3) draw a horizontal line
- abline(lm(y ∼ x)) draw a line with a and b
- estimated from the linear model y ∼ x
- abline(v = 10) draw a vertical line at x =
- absence of evidence
- acceptance null hypothesis
- age effects longitudinal data
- age-at-death data using glm
- aggregation and randomization
- aggregation count data
- AIC Akaike's Information Criterion
- air pollution correlations
- aliasing introduction
- analysis of covariance, see Ancova
- analysis of deviance count data
- proportion data
- analysis of variance, see Anova
- Ancova
- contrasts
- order matters
- subscripts
- with binary response
- with count data
- anova and Anova: anova is an R function for comparing two models, while Anova stands for analysis of variance
- anova analysis of deviance
- Ancova
- comparing models
- function for comparing models
- model simplification
- non-linear regression
- test=“Chi”
- test=“F”
- with contrasts
- Anova essence of
- choice
- introduction
- longhand calculations for one-way
- model formula
- one-way
- Anova table in regression
- one-way Anova
- and non-orthogonal data
- antilogs exp
- ants in trees
- aov function for fitting linear models with categorical explanatory variables
- analysis of variance models
- competition example
- Error for rats example
- factorial experiments
- model for analysis of variance
- multiple error terms using Error
- with contrasts
- appearance of graphs, improvements
- arcsine transformation of percentage data
- arithmetic mean definition
- with summary
- array function creating an array specifying its dimensions
- array
- as.character for labels
- in barplot labels
- as.matrix
- as.numeric
- as.POSIX
- as.vector
- to estimate proportions
- with tapply
- assignment, <- not =
- association, contingency tables
- asymptotic exponential in non-linear regression
- attach a dataframe
- autocorrelation random effects
- average of proportions
- averaging speeds
- axis change tic mark locations
- b slope in linear regression
- b = SSXY/SSX
- barplot factorial experiments
- frequencies
- negative binomial distribution
- table using tapply
- two data sets compared
- with error bars
- with two sets of bars
- Bernoulli distribution n =
- binary response variable
- Ancova
- introduction
- binom.test exact binomial test
- binomial variance/mean ratio
- binomial data introduction
- binomial denominator
- binomial distribution dbinom density
- function
- pbinom probabilities
- qbinom quantiles
- rbinom random numbers
- binomial errors glm
- logit link
- binomial test comparing two proportions with prop.test
- binomial trials Bernoulli distribution
- blank plots use type=“n”
- blocks
- split plot design
- and paired t-test
- bootstrap confidence interval for mean
- hypothesis testing with single samples
- bounded count data
- bounded proportion data
- box and whisker plots, see boxplot
- boxplot function
- garden ozone
- notch = T for hypothesis testing
- c concatenation function
- making a vector
- calculator
- cancer with distance example
- canonical link functions glm
- Cartesian coordinates
- categorical variables in data frames
- use cut to create from continuous
- cbind function to bind columns together
- in Ancova
- making contrasts
- proportion data
- creating the response variable for proportion data
- ceiling function for “the smallest integer greater than”
- censoring introduction
- central, a function for central tendency
- central limit theorem, introduction
- central tendency central function
- introduction
- chance and variation
- character mode for variable
- chi squared comparing two distributions
- test = “Chi”
- distribution pchisq probabilites qchisq quantiles
- chisq.test Pearson's Chi-squared test
- chi-square contingency tables
- choice of model, usually a compromise
- choose combinatorial function in R
- classical tests
- clear the workspace rm(list = ls())
- clumps, selecting a random individual
- coef extract coefficients from a model object
- coefficients Ancova
- Anova
- binary infection
- coef function
- extract, as in model$coef
- factorial experiments
- gam
- glm with Gamma errors
- quadratic regression
- regression
- regression with proportion data
- treatment contrasts
- with contrasts
- cohort effects in longitudinal data
- col = “red” colour in barplot
- column totals in contingency tables
- columns selecting from an array
- selecting using subscripts
- columnwise data entry for matrices
- comparing two means
- comparing two proportions
- comparing two variances
- competition experiment
- concatenation function, c
- confidence intervals as error bars
- introduction
- constant variance glm
- model checking
- contingency tables dangers of aggregation
- introduction
- rather than binary analysis
- continuous variables
- convert to categorical using cut
- in data frames
- using cut to create categorical variables
- contr.treatment treatment contrasts
- contrast coefficients
- contrast conventions compared
- contrast sum of squares example by hand
- contrasts Ancova
- as factor attribute
- Helmert
- introduction
- sum
- treatment
- contrasts = c(“contr.treatment”, “contr.poly”)) options
- controls
- Cook's distance plot in model checking
- cor correlation in R
- paired data
- cor.test scale dependent correlation
- significance of correlation
- correct=F in chisq.test
- corrected sums of squares Ancova
- one-way Anova
- correction factor hierarchical designs
- correlation and paired-sample t-test
- contingency tables
- introduction
- partial
- problems of scale-dependence
- variance of differences
- correlation coefficient r
- correlation of explanatory variables model checking
- multiple regression
- correlation structure, random effects
- count data analysis of deviance
- analysis using contingency tables
- Fisher's Exact Test
- introduction
- negative binomial distribution
- on proportions
- counting, use table
- using sum(d > 0)
- elements of vectors using table function
- counts
- covariance and the variance of a difference
- introduction
- paired samples
- critical value and rejection of the null
- hypothesis
- F-test
- rule of thumb for t = 2
- Student's t
- cross-sectional studies longitudinal data
- cumprod cumulative product function
- current model
- curvature and model simplification
- in regression
- model checking
- multiple regression
- curves on plots, Ancova with Poisson errors
- cut, produce category data from continuous
- d.f., see degrees of freedom
- dangers of contingency tables
- data, fitting models to
- data Ancovacontrasts
- cases
- cells
- clusters
- compensation
- competition
- Daphnia
- deaths
- decay
- f.test.data
- fisher
- flowering
- gardens
- germination
- growth
- hump
- induced
- infection
- isolation
- jaws
- light
- oneway
- ozone
- paired
- pollute
- productivity
- rats
- sexratio
- sheep
- skewdata
- smoothing
- splityield
- streams
- sulphur.dioxide
- t.test.data
- tannin
- two sample
- worms
- yvalues
- data dredging using cor
- data editing
- data exploration
- data frame, introduction
- data summary one sample case
- dataframe create using cbind
- create using read.table
- name the same as variable name
- dates and times in R
- death data introduction
- deer jaws example
- degree of fit r2
- degrees of freedom checking for
- pseudoreplication
- contingency tables
- definition
- factorial experiments
- in a paired t-test
- in an F test of two variances
- in Anova
- in different models
- in nested designs
- in the linear predictor
- model simplification
- number of parameters
- one-way Anova
- spotting pseudoreplication
- deletion tests, steps involved
- density function binomial
- negative binomial
- Normal
- Poisson
- derived variable analysis longitudinal data
- detach a dataframe
- deviations, introduction
- diet supplement example
- diff function generating differences
- differences vs. paired t-test
- differences between means aliasing
- in Anova model formula
- differences between slopes Ancova
- differences between intercepts Ancova
- difftime
- dim dimensions of an object
- dimensions of a matrix
- dimensions of an array
- dimensions of an object x - 1:12; dim(x) <- c(3,4)
- division /
- dnbinom function for probability density of the negative binomial
- dnorm
- plot of
- probability density of the Normal distribution
- dredging through data using cor
- drop elements of an array using negative subscripts
- drop the last element of an array using length
- dt density function of Student's t, plot of
- dummy variables in the Anova model formula
- duration of experiments
- E = R x C/G expected frequencies in contingency tables
- each in repeats
- edges, selecting a random individual
- effect size and power
- factorial experiments
- fixed effects
- one-way Anova
- else with the if function
- empty plots use type = “n”
- equals, logical == (“double equals”)
- Error with aov, introduction
- multiple error terms in aov
- error bars, function for drawing
- least significant difference
- on proportions
- overlap and significance
- error correction
- error structure introduction
- model criticism
- error sum of squares SSE in regression
- error variance contrast sum of squares
- in regression
- error.bars function for plotting
- errors Poisson for count data
- eta the linear predictor
- even numbers, %%2 is zero
- everything varies
- exact binomial test binom.test
- Excel dates in R
- exit a function using stop
- exp antilogs (base e) in R
- predicted value
- with glm and quasipoisson errors
- expectation of the vector product
- expected frequencies E = R x C / G
- Fisher's Exact Test
- negative binomial distribution
- experiment
- experimental design
- explained variation in Anova
- in regression
- explanatory power of different models
- explanatory variables
- continuous regression
- dangers of aggregation
- specifying, see predict
- transformation
- unique values for each binary response
- exponential errors, in survival analysis
- expression, complex text on plots
- extreme value distribution in survival analysis
- extrinsic aliasing
- eye colour, contingency tables
- F as logical False
- F ratio
- in regression
- F-test, comparing two variances
- factor, numerical factor levels
- factor levels Fisher's Exact Test
- generate with gl
- informative
- in model formula
- factorial, Fisher's Exact Test
- factorial designs, introduction
- factorial experiments introduction
- factor-level reduction in model simplification
- factors categorical variables in Anova
- in data frames
- plot
- failure data, introduction
- failures proportion data
- FALSE or F, influence testing
- logical variable
- falsifiable hypotheses
- family = binomial binary response variable
- proportion data
- family = poisson for count data
- famous five; sums, sums of squares and sums of products
- file names
- fill colour for legends
- in barplot legend
- fisher.test Fisher's Exact Test
- with 2 arguments as factor levels
- Fisher's Exact Test, contingency tables
- Fisher's F-Test, see F-test
- fit of different models
- fitted values definition
- proportion data
- fitting models to data
- fixed effects, introduction
- for loops
- drawing error bars
- for plotting residuals
- negative binomial distribution
- residuals in Anova
- with abline and split
- formula, model for Anova
- F-ratio, contrast sum of squares
- one-way Anova
- frequencies count data
- using table
- frequency distributions, introduction
- F-test, introduction
- functions written in R
- error bars
- exit using stop
- for a sign test
- for variance
- leverage
- median
- negative binomial distribution
- gam generalized additive models
- data exploration
- introduction
- library(mgcv)
- with a binary response
- y∼s(x)
- Gamma distribution, variance/mean ratio
- Gamma errors glm
- introduction
- gardenA
- Gaussian distribution in survival analysis
- generalized additive models, see gam
- generalized linear model, see glm
- generate factor levels gl
- geometric mean, definition
- gl generate levels for factors
- glm analysis of deviance
- Ancova with binomial errors
- Ancova with poisson errors
- binary infection
- binary response variable
- cancers example
- Gamma errors
- proportion data
- regression with proportion data
- saturated model with Poisson errors
- gradient, see slope
- graphs, two adjacent, par(mfrow=c(1,2))
- graphs, two by two array, par(mfrow=c(2,2))
- Gregor Mendel effect
- grouping random effects
- h, leverage measure
- hair colour, contingency tables
- harmonic mean
- header = T
- Helmert contrasts Ancova
- example
- heteroscedasticity introduction
- model checking
- multiple regression
- hierarchical designs, correction factor
- hierarchy random effects
- rats example
- hist function for producing histograms
- speed
- values
- with bootstrap
- with skew
- histograms,, see hist
- history(Inf) for list of input commands
- honest significant differences TukeyHSD
- horizontal lines on plot abline(h=3)
- how many samples? plot of variance and sample size
- humped relationships significance testing
- model simplification
- testing for
- testing a binary response model
- hypotheses good and bad
- hypotheses testing
- using chi-square
- with F
- I “as is” in multiple regression
- model formulas
- identity link glm
- Normal errors
- if function
- if with logical subscripts
- incidence functions using logistic regression
- independence
- independence assumption in contingency tables
- independence of errors
- random effects
- index in one-variable plots
- induced defences example
- infection example
- inference with single samples
- influence introduction
- model checking
- one-way Anova
- testing in multiple regression
- informative factor levels, fixed effects
- initial conditions
- input from keyboard using scan()
- insecticide
- interaction, multiple regression
- terms with continuous explanatory variables
- terms model formulae
- terms in multiple regression
- interaction.plot split plot example
- interactions factorial experiments
- selecting variables
- value of tree models
- intercept a
- calculations longhand
- differences between intercepts
- estimate
- maximum likelihood estimate
- treatment contrasts
- intercepts Ancova
- interquartile range
- plots
- intrinsic aliasing
- inverse, and harmonic means
- k of the negative binomial distribution
- key, see , see legend
- kinds of years
- known values in a system of linear equations
- kurtosis definition
- error structure
- function for
- values
- labels changing font size, cex.lab
- for barplot
- least significant difference (LSD) error bars
- introduction
- least-squares estimates of slope and intercept in linear regression
- legend barplot with two sets of bars
- plot function for keys
- length function for determining the length of a vector
- drop the last element of an array
- in a sign test function
- length with tapply
- levels of factors
- levels, generate with gl
- levels introduction
- model simplification
- proportion data
- regression in Ancova
- with contrasts
- “levels gets” comparing two distributions
- factor-level reduction
- with contrasts
- leverage and SSX
- leverage function
- influence testing
- library ctest for classical tests
- mgcv for gam
- nlme for mixed effects models
- survival for survival analysis
- tree for tree models
- linear function
- linear mixed effects model lme
- linear predictor introduction
- logit link
- linear regression example using growth and tannin
- linearizing the logistic
- lines adds lines to a plots (cf. points)
- binary response variable
- drawing error bars
- dt and dnorm
- exponential decay
- for errors with proportion data
- non-linear regression
- ordered x values
- over histograms
- polynomial regression
- showing residuals
- type = “response” for proportion data
- with glm and quasipoisson errors
- with qt
- with subscripts
- link, log for count data
- link function complementary log-log
- logit
- list, in non-linear regression
- lists, subscripts
- liver, rats example
- lm
- lm fit a linear model lm(y∼x)
- Ancova
- in regression
- linear models
- the predict function
- lme linear mixed effects model
- handling pseudoreplication
- locator function for determining coordinates on
- as plot
- with barplot
- loess local regression non-parametric models
- log exponential decay
- log logarithms (base e) in R
- log link for count data
- log odds, logit
- log transformation in multiple regression
- logarithms and variability
- logical subscripts
- logical tests using subscripts
- logical variables, T or F
- in data frames
- logistic model, caveats
- logistic S-shaped model for proportion data
- distribution in survival analysis
- logistic regression, binary response variable
- example
- logit link binomial errors
- definition
- log-linear models for count data
- longitudinal data analysis
- loops in R, see for loops
- LSD least significant difference
- plots
- lty line type (e.g. dotted is lty=2)
- m3 third moment
- m4 fourth moment
- marginal totals in contingency tables
- margins in contingency tables
- matrices, columnwise data entry
- matrix function in R
- with nrow
- matrix multiplication %*%
- maximum. with summary
- max
- maximum likelihood definition
- estimates in linear regression
- estimate of k of the negative binomial
- mean function determining arithmetic mean
- mean, arithmetic
- geometric
- harmonic
- mean age at death with censoring
- mean squared deviation, introduction
- means, tapply for tables
- two-way tables using tapply
- measurement error
- med function for determining medians
- median built-in function
- with summary
- writing a function
- mgcv, binomial
- Michelson's light data
- minimal adequate model
- analysis of deviance
- multiple regression
- minimum, min, with summary
- mixed effects models
- library(nlme)
- mode, the most frequent value
- model for Anova
- contingency tables
- linear regression
- model checking, introduction
- in regression
- model criticism, introduction
- model formula for Anova
- model objects, generic functions
- model selection
- model simplification analysis of deviance
- Ancova
- caveats
- factorial experiments
- factor-level reduction–224
- multiple regression
- non-linear regression
- with contrasts
- model, structure of a linear models using str
- modulo %%
- for barplot
- remainder
- with logical subscripts
- moments of a distribution
- multiple comparisons
- multiple error terms, introduction
- multiple graphs per page, par(mfrow = c(1,2))
- multiple regression, introduction
- difficulties in
- minimal adequate model
- number of parameters
- quadratic terms
- multiplication, *
- n, sample size
- and degrees of freedom
- and power
- and standard error
- names in barplot
- names of variables in a dataframe
- natural experiments
- negative binomial distribution definition
- dnbinom density function
- negative correlation in contingency tables
- negative skew
- negative subscripts to drop elements of an array
- nested Anova, model formulae
- nesting model formulae
- of explanatory variables, %in%
- new line of output using “\n”
- nice numbers in model simplification
- nlme library for mixed effects models
- non-linear mixed effects model
- nls non-linear least squares models
- non-constant variance count data
- model criticism
- proportion data
- non-linear least squares, see nls
- non-linear mixed effects model, see nlme
- non-linear regression introduction
- non-linear terms in model formulae
- use of nls
- non-linearity in regression
- non-Normal errors introduction
- count data
- model checking
- model criticism
- proportion data
- non-orthogonal data observational studies
- order matters
- non-parametric smoothers gam
- pairs
- with a binary response
- Normal and Student's t distributions compared
- Normal calculations using z
- Normal curve, drawing the
- Normal distribution, introduction
- dnorm density function
- pnorm probabilities
- qnorm quantiles
- rnorm random numbers
- Normal errors identity link
- model checking
- Normal q-q plot in model checking
- normality, tests of
- not equal, !=
- notch=T in boxplot for significance testing
- plots for Anova
- with boxplot
- nrow, number of rows in a matrix
- n-shaped humped relationships
- nuisance variables, marginal totals in contingency tables
- null hypotheses
- rejection and critical values
- with F-tests
- null model y ∼ 1
- numbers as factor levels
- numeric, definition of the mode of a variable
- observational data
- observed frequencies in contingency tables
- Occam's Razor
- and choice of test
- contingency tables
- odd numbers, %%2 is one
- odds, p/q, definition
- one-sample t-test
- one-way Anova introduction
- options contrasts = c(“contr.helmert”, “contr.poly”))
- contrasts = c(“contr.sum”, “contr.poly”))
- contrasts = c(“contr.treatment”, “contr.poly”))
- order function
- in sorting dataframes
- with scatter plots
- with subscripts
- order matters Ancova
- non-orthogonal data
- ordering, introduction
- orthogonal contrasts
- orthogonal designs
- Anova tables
- outliers definition
- in box and whisker plots
- new line using “\n”
- overdispersion and transformation of explanatory variables
- no such thing with binary data
- proportion data
- use quasibinomial for proportion data
- use quasipoisson for count data
- over-parameterization in multiple regression
- ozone and lettuce growth in gardens
- Π Greek Pi, meaning the product of
- p number of parameters
- and influence
- in the linear predictor
- estimated parameters in the model
- p values
- compared for t-test and Wilcoxon Rank Sum Test
- paired samples t-test
- pairs mutli-panel scatterplots
- panel.smooth in pairs
- par graphics parameters
- par(mfrow=c(1,1)) single graph per page
- par(mfrow=c(1,2)) two graphs side by side
- par(mfrow=c(2,2)) four plots in a 2×2 array
- parallel lines in Ancova
- parameter estimation in non-linear regression
- parameters 2-parameter model
- in multiple regression
- parsimony
- partial correlation, introduction
- paste to concatenate text
- path analysis
- path name for files
- pch with split
- pch = 35
- solid circle plotting symbols
- with split
- pchisq cumulative probability of chi squared distribution
- Pearson's chi-squared definition
- for comparing two distributions
- Pearson's Product-Moment Correlation
- cor.test
- percentage data and the arcsine transformation
- from counts
- percentiles
- plots
- in box and whisker plots
- with summary
- pf cumulative probability from the F
- distribution
- in F-tests
- in regression
- one-way Anova
- piece-wise regression, with a binary response
- Pivot Table in Excel
- plot 5
- abline for adding straight lines
- adding points to a plot
- binary response variable
- box and whisker
- compensation example
- correlation
- count data
- growth and tannin
- in Anova
- in error checking
- las=1 for vertical axis labels
- multiple using pairs
- multiple using par(mfrow = c(1,2))
- non-linear scatterplot
- proportion data
- regression with proportion data
- scale dependent correlation
- the locator function for determining coordinates
- type = “n” for blank plotting area
- with index
- with split
- plot(model) introduction
- for gam
- and transformation of explanatory variables
- for tree models
- glm with Gamma errors
- model checking
- multiple regression
- one-way Anova
- plot.gam with a binary response
- plots, box and whisker
- pairs for many scatterplots
- for binary response example
- plotting symblols pch in plot
- pnorm probabilities from the Normal
- distribution
- probabilities of z values
- points adding points to a plot (cf. lines)
- with gam plot
- with split
- with subscripts
- Poisson distribution definition
- dpois density function
- rpois random number generator
- poisson errors count data
- glm for count data
- pollution, example of multiple regression
- polygon function for shading complex shapes
- polynomial regression, introduction
- population growth, simulation model
- positive correlation, and paired-sample t-test
- contingency tables
- POSIX
- power, probability of rejecting a false null hypothesis
- functions for estimating sample size
- power.t.test
- powers ^
- p/q, see odds
- predict, function to predict values from a model for specified values of the explanatory variables
- binary response variable
- non-linear regression
- polynomial regression
- type = “response” for proportion data
- with glm and quasipoisson errors
- predicted value, standard error of ^y
- predictions
- probabilities, contingency tables
- probability density, binomial distribution
- Normal
- negative binomial distribution
- Poisson distribution
- products, cumprod function for cumulative products
- prop.test binomial test for comparing two proportions
- proportion, transformation from logit
- proportion data introduction
- analysis of deviance
- Ancova
- binomial errors
- rather than binary analysis
- proportions from tapply with as.vector
- pseudoreplication
- analysis with
- checking degrees of freedom
- removing it
- split plots
- pt cumulative probabilities of Student's t distribution
- garden ozone
- test for skew
- qchisq quantiles of the chi-square distribution
- qf quantiles of the F distribution
- contrast sum of squares
- in regression
- one-way Anova
- qnorm quantiles of the Normal distribution
- qqline introduction
- qqnorm introduction
- in regression
- qt quantiles of the t distribution
- confidence interval for mean
- critical value of Student's t
- quadratic regression. introduction
- multiple regression
- in a binary response model
- model formulae
- quantile function in R
- of the chi-square distribution using qchisq
- of the F distribution usibng qf
- of the Normal distribution using qnorm
- of the t distribution usibng qt
- quartile plots
- with summary
- quasibinomial analysis of deviance
- family for overdispersed proportion data
- quasipoisson analysis of deviance
- family for overdispersed count data
- r correlation coefficient
- in terms of covariance
- in terms of SSXY
- R downloadi
- R language
- r2 as a measure of explanatory power of a model
- definition
- r2 = SSR/SSY
- random effects introduction
- longitudinal data
- uninformative factor levels
- random numbers from the normal distribution
- rnorm
- from the Poisson distribution, rpois
- from the uniform distribution, runif
- randomization in sampling and experimental design
- randomizing variable selection
- range function returning maximum and minimum
- rank function in R
- read.table introduction
- reading data from a file
- reciprocal link with Gamma errors
- reciprocals
- regression introduction
- anova table
- at different factor levels Ancova
- binary response variable
- by eye
- calculations longhand
- choice
- exponential decay
- linear
- logistic
- non-linear
- parameter estimation in non-linear
- piece-wise
- polynomial
- predict in non-linear
- quadratic
- summary in non-linear
- testing for humped relationships
- testing for non-linearity
- rejection critical values
- null hypothesis
- using F-tests
- relative growth rate with percentage data
- removing variables with rm
- rep function for generating repeats
- error bars
- for subject identities
- LSD bars
- repeat function
- text
- repeated measures
- random effects
- repeats, generating repeats, see rep
- replace = T sampling with replacement
- replication 7
- checking with table
- residual deviance in proportion data
- residual errors
- residual plots in model checking
- residuals definition
- extract residuals from a model object
- in Anova
- model checking
- pattern and heteroscedasticity
- response, predict with type = “response”
- response variable and the choice of model
- regression
- types of
- rev with order in sorting dataframes
- rev(sort(y)) sort into reverse order
- rm removing variables from the work space
- rm(list = ls()) clear everything
- rnorm random normally distributed numbers
- roots, ^(fraction)
- in calculating geometric mean
- row names in data frames
- row totals contingency tables
- row.names in read.table
- rows selecting from an array
- selecting using subscripts
- rules of thumb
- parameters in multiple regression p/3
- power 80% requires n > = 16 s2/d2
- t >2 is significant
- runif uniform random numbers
- Σ Greek Sigma, meaning summation
- S language, background
- s(x) smoother in gam
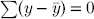 proof
proof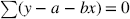 proof
proof- sample, function for sampling at random from a vector
- with replacement, replace = T
- selecting variables
- for shuffling, replace = F
- sample size and degrees of freedom
- sampling with replacement; sample with replace = T
- saturated model
- contingency tables
- saving your work from an R session
- scale location plot, used in model checking
- scale parameter, overdispersion
- scale-dependent correlation
- scan() input from keyboard
- scatter, measuring degree of fit with r2
- scatterplot, graphic for regression
- sd standard deviation function in R
- seed production compensation example
- selecting a random individual
- selecting certain columns of an array
- selecting certain rows of an array
- selection of models, introduction
- self-starting functions in non-linear regression
- seq generate a series
- values for x axis in predict
- sequence generation, see seq
- serial correlation
- random effects
- sex discrimination, test of proportions
- shuffling using sample
- sign test definition
- garden ozone
- significance
- in boxplots using notch = T
- of correlation using cor.test
- overlap of error bars
- significant differences in contingency tables
- simplicity, see Occam's Razor
- simplification, see model simplification
- simulation experiment on the central limit theorem
- single sample tests
- skew definition
- asymmetric confidence intervals
- function for
- in histograms
- negative
- values
- slope b
- calculations longhand
- definition
- differences between slopes
- maximum likelihood estimate
- standard error
- slopes Ancova
- removal in model simplification
- smoothing gam
- model formulae
- panel.smooth in pairs
- sort function for sorting a vector
- rev(sort(y)) for reverse order
- sorting a dataframe
- sorting, introduction
- spaces in variable names or factor levels
- spatial autocorrelation random effects
- spatial correlation and paired t-test
- spatial pseudoreplication
- Spearman's Rank Correlation
- split for species data
- proportion data
- separate on the basis of factor levels
- split-plots Error terms
- introduction
- different plotting symbols
- spreadsheets and data frames
- sqrt square root function in R
- square root function, see sqrt
- SSA explained variation in Anova
- one-way Anova
- shortcut formula
- SSC contrast sum of squares
- SSE error sum of squares
- in Ancova
- in Anova
- in regression
- one-way Anova
- the sum of the squares of the residuals
- S-shaped curve logistic
- SSR Ancova
- in regression
- regression sum of squares
- SSX corrected sum of squares of x
- calculations longhand
- SSXY corrected sum of products
- Ancova
- calculations longhand
- shortcut formula
- SSY total sum of squares defined
- calculations longhand
- in Anova
- null model
- one-way Anova
- SSY = SSR+SSE
- standard deviation, sd function in R
- and skew
- in calculating z
- standard error
- as error bars
- difference between two means
- Helmert contrasts
- mean
- of kurtosis
- of skew
- of slope and intercept in linear regression
- standard normal deviate, see z
- start, initial parameter values in nls
- statistical modelling, introduction
- status with censoring
- step automated model simplification
- str, the structure of an R object
- straight line
- strong inference
- strptime, in R
- Student's t-distribution introduction
- pt probabilities
- qt quantiles
- Student's t-test statistic
- normal errors and constant variance
- subjects, random effects
- subscripts [ ] introduction
- barplot with two sets of bars
- data selection
- factor-level reduction
- for computing subsets of data
- in data frames
- in lists [[ ]]
- in calculations for Anova
- influence testing
- lm for Ancova
- residuals in Anova
- with order
- using the which function
- subset in model checking
- influence testing
- multiple regression
- subsets of data using logical subscripts
- substitute, complex text on plots
- in plot labels
- successes, proportion data
- sulphur dioxide, multiple regression
- sum function for calculating totals
- sum contrasts
- sum of squares introduction
- computation
- contrast sum of squares
- shortcut formula
- summary introduction
- analysis of deviance
- Ancova
- Ancova with poisson errors
- factorial experiments
- glm with Gamma errors
- glm with poisson errors
- in regression
- non-linear regression
- of a vector
- regression with proportion data
- speed
- split plot aov
- with data frames
- with quasipoisson errors
- summary(model)
- gam
- piece-wise regression
- with survreg
- summary.aov
- Ancova
- in regression
- one-way Anova
- summary.lm
- Ancova
- effect sizes in Anova
- factorial experiments
- Helmert contrasts
- in Anova
- two-way Anova
- with contrasts
- sums of squares in hierarchical designs
- suppress axis labelling xaxt = “n”
- survfit plot survivorship curves
- survival analysis introduction
- library(survival)
- survivorship curves, plot(surfit)
- survreg analysis of deviance
- symbols in model formulae
- symbols on plots complex text on plots
- different symbols
- Sys.time
- T logical True
- t distribution, see Student's t distribution
- t.test garden ozone
- one sample
- paired = T
- table, function for counting elements in vectors
- binary response variable
- checking replication
- counting frequencies
- counting values in a vector
- determining frequency distribution
- with cut
- tables of means introduction
- tapply on proportions
- tails of the Normal distribution
- tails of the Normal and Student's t compared
- tapply for tables of means
- for proportions
- function in R
- mean age at death
- mean age at death with censoring
- reducing vector lengths
- table of totals, with sum
- table of variances, with var
- two-way tables of means
- with contrasts
- with count data
- with cut
- with length
- temporal autocorrelation random effects
- temporal pseudoreplication
- test statistic for Student's t
- test = “Chi” contingency table
- test = “F” anova
- tests of hypotheses
- tests of normality
- text(model) for tree models
- theory
- three-way Anova, model formulae
- thresholds in piece-wise regression
- ties, problems in Wilcoxon Rank Sum Test
- tilde ∼ means “is modelled as a function of” in lm or aov
- model formulae
- time and date in R
- time at death
- time series, random effects
- time series
- time-at-death data, introduction
- transformation
- arcsine for percentage data
- count data
- explanatory variables
- from logit to p
- linear models
- logistic
- model criticism
- model formulae
- the linear predictor
- transpose, using concatenate, c
- transpose function for a matrix, t
- treatment contrasts introduction
- treatment totals, contrast sum of squares
- in Anova
- tree models
- advantages of
- data exploration
- ozone example
- trees, selecting a random individual
- Tribolium
- logical variable
- t-test definition
- paired samples
- rule of thumb for t = 9
- TukeyHSD, Tukey's Honest significant differences
- two sample problems
- t-test with paired data
- two-parameter model, linear regression
- two-tailed tests
- Fisher's Exact Test
- two-way Anova, model formulae
- Type I Errors
- Type II Errors
- type = “b” both points and lines
- type = “l” line rather than points in plot
- type = “n” for blank plots
- proportion data
- type = “response”, model output on back-transformed scale
- Ancova with poisson errors
- with binary data
- with proportion data
- unexplained variation
- in Anova
- in regression
- uniform random numbers with runif function
- uninformative factor levels
- rats example
- unlist
- unplanned comparisons, a posteriori contrasts
- unreliability, estimation of
- intercept
- predicted value
- slope
- update in model simplification
- after step
- analysis of deviance
- contingency table
- multiple regression
- using variance to estimate unreliability
- testing hypotheses
- var variance function in R
- var(x,y) function for covariance
- var.test F-test in R
- for garden ozone
- variable names in dataframes
- variance, definition and derivation
- and corrected sums of squares
- and power
- and sample size
- and standard error
- constancy in a glm
- count data
- data on time-at-death
- F-test to compare two variances
- formula
- gamma distribution
- in Anova
- minimizing estimators
- of a difference
- of the binomial distribution
- plot against sample size
- random effects
- sum of squares / degrees of freedom
- var function in R
- VCA, variance components analysis
- variance components analysis
- rats example
- variance constancy model checking
- variance function, random effects
- variance/mean ratio
- aggregation in count data
- examples
- variation
- using logs in graphics
- variety and split
- VCA, see variance components analysis
- vector functions in R
- weak inference
- web address of this book, xii
- proportion data
- Welch Two Sample t-test
- which, R function to find subscripts
- whiskers in box and whisker plots
- wilcox.test Wilcoxon Rank Sum Test
- Wilcoxon Rank Sum Test
- non-normal errors
- worms dataframe
- writing functions in R, see functions
- x, continuous explanatory variable in regression
- xlab labels for the x axis
- in Anova
- y response variable in regression
- y ∼ 1 null model
- y ∼ x-1 removing the intercept
- Yates’ correction Pearson's Chi-squared test
- yaxt = “n” suppress axis labelling
- yield experiment, split plot example
- ylab labels for the y axis
- in Anova
- ylim controlling the scale of the y axis in plots
- in Anova
- z of the Normal distribution
- approximation in Wilcoxon Rank Sum Test
- zero term negative binomial distribution
- Poisson distribution