35
SELECTING THE DEPENDENT
VARIABLE IN ELECTORAL
STUDIES: CHOICE OR
PREFERENCE?
One of the central questions in electoral research concerns the understanding of individual behavior that, in the aggregate, produces election outcomes. This chapter focuses on that aspect of this behavior that involves electoral support for parties or candidates, while only cursorily touching upon the electoral participation aspect. The apparent simplicity of the notion of party support does not encourage conceptual reflection on the phenomenon under study, which can be referred to in terms of either choice (between parties or candidates) or preference. These two terms are very frequently treated as synonyms. Yet, there are good reasons to keep them conceptually distinct, and doing so has practical consequences for the way they are studied.
In Downs’ (1957) seminal theory of the electoral interactions between electoral entrepreneurs and voters, he conceptualizes choice as resulting from a comparison of preferences (which he refers to as “utilities”). He postulates that voters have preferences for each of the options from which, under most electoral systems, they can choose only one; implying that the process that results in choice consists of two stages. In a first stage, individuals assess their preference for each choice-option; the process that generates these preferences can be summarized in a preference function (sometimes also referred to as a utility function). In the second stage, a decision rule determines the choice on the basis of these preferences (this is usually seen as selecting the option that has the highest preference). It has to be emphasized that Downsian utilities refer to variables whose values can range from low to high, which is somewhat different from ordinary parlance where the term “preference” is often synonymous with “preferred,” referring only to high values on such a variable (“my preference is for the Liberals”). In spite of the fact that Downs’ contribution has been of immense influence on electoral studies over a considerable period of time, this conceptual distinction between preferences and choice, and the practical implications of that distinction, has been widely overlooked. This is evident from the content of election surveys, which invariably include questions about electoral choice, but not always (actually, quite often not) about electoral preferences.
Elections constrain the expression of voters’ electoral preferences. Most electoral systems allow only a single option to be chosen. Systems that allow the ranking of parties, such as the alternative vote (AV) or the single transferable vote (STV), impose other constraints – for example, by preventing more than one party from being ranked first (respectively, second etc.) in preference order on the ballot. Because of such constraints, choice reflects only a single aspect of the underlying preferences, namely which of the preferences was highest. Choice does thus not reflect other aspects of the underlying preferences, such as the strength of preference for the chosen option (ranging from “least-repugnant” to “best-that-can-be”), or how much better the chosen option is compared to other ones (ranging from “no-noticeable-difference” to a “wide chasm”). The only inference about preferences that can therefore be made from choices is the relative preference of one of the options (the one that is chosen) versus all other ones. These limitations have long been recognized by scholars such as Converse (1974: 742–743), Sartori (1976: 338–339) and Powell (2000: 160), who all emphasize that the constrained character of the ballot (and of survey questions about choice) do not provide a suitable basis for the observation and analysis of citizens’ preferences regarding the options from which they can choose.
To overcome these limitations, so-called “non-ipsative” measures of electoral preferences have been developed which are increasingly more often included in election survey studies. The term “ipsative” refers to constraints imposed on the expression of preferences, such as “choose only one,” that generate dependencies in the observed preferences for the various options (under the “choose only one” constraint, the observation that party A is chosen implies that all other parties are not chosen). Choices thus tell us little about the underlying “non-ipsative” preferences. To avoid unnecessary jargon, such non-ipsative preferences for parties will be referred to in this chapter as multiple party preferences. Survey questions about multiple party preferences ask respondents to report the strength of their preference for each (or for the most important) of the parties available. There are various ways in which these strengths of preferences can be solicited. The simplest form is by way of a dichotomy between “preferred” and “non-preferred” parties, as in a “pick any that apply” task. More nuances of strength can be expressed when some kind of rating scale is employed (e.g., when asking for scores between 0, which reflects not preferred at all, and 10, which reflects very strongly preferred).1 Since the 1990s, such measures have spawned a variety of innovations in the study of support for political parties along with related phenomena of electoral participation, electoral competition and the comparative analyses of elections and electoral behavior.
Varieties of multiple party preferences
Multiple party preference data are available in many contemporary election studies, and exist predominantly in a few “flavors” which differ regarding what it is about parties that is preferred to a greater or lesser degree. The oldest is the so-called “feeling thermometer” used in the American National Election Studies (ANES). Respondents are requested to indicate on a scale from 0 to 100 how “warm or favorable” (respectively, how “cold or unfavorable”) they feel for each of the parties about which they are being questioned, with the midpoint (50) as a neutral point (“no feeling at all”). This is a long-running question in the ANES, and has also been included in election surveys in other countries, although more rarely as a long-running question. A second form in which multiple party preferences are asked is the so-called “likes-dislikes” question that has become a recurring element in the data collected as part of the Comparative Study of Electoral Systems (CSES) and therefore also of all national election studies in which the CSES is incorporated. This question asks respondents to indicate (usually on a scale of 0 to 10) how strongly they “like” or “dislike” each of the parties for which the question is asked. The third popular form in which multiple preferences are asked was first introduced in 1982 in the Dutch Parliamentary Election Study (DPES) where it has been a recurring question ever since. This question has been included in a growing number of national election studies as well as in the European Parliament Election Studies (EES) where it has become one of the core questions asked in all studies since 1989. This question, which has become known as the “propensity to vote” question (PTV), asks respondents to indicate (usually on a scale from 0 to 10) “how likely it is that you will ever vote for” each of the parties for which the question is asked. A more recent way of eliciting multiple party preferences derives from the so-called “consideration set” approaches that focus not on all parties on offer, but only those that voters “consider” to vote for (cf. Wilson 2008; Oskarson et al. 2016). Some surveys contain questions about parties respondents consider voting for (which is a straightforward and dichotomous “pick any that applies” task for respondents). As yet the development and validation of such questions is still in its infancy.2
The main difference between these various existing kinds of multiple preference measures lies in what the respondents are asked to express. The feeling thermometer and likes-dislikes questions most clearly seem to focus on affect, while the PTV and “which parties do you consider” questions focus more directly on electoral preferences of the kind conceptualized by Downs (1957). Some surveys have asked two, or even three, of these kinds of questions to the same respondents, which makes it possible to compare responses in terms of the extent to which they match actual party choice. After all, in Downs’ view, the party yielding the highest preference should be the one chosen, which implies that a relatively simple test of construct validity consists of assessing the extent to which respondents’ choices accord with their highest preferences. Such comparisons (based on Dutch, Irish and British national election study data) yield the following conclusions. The proportion of respondents who choose the party to which they give the highest preference is highest for the PTV questions, somewhat lower for the likesdislikes and much lower for the feeling thermometer. For the PTVs, this concordance between most-preferred party and party voted for is generally far in excess of 80 percent, often even in excess of 90 percent.3 In terms of construct validity, this means that feeling “warm” or “cold” is evidently something else than electoral preference, although as an indicator of affect it may well be one of the drivers thereof. These, and other validating analyses, indicate PTVs as the most valid indicators for Downsian electoral preferences, with likes-dislikes as a somewhat weaker but acceptable alternative (Tillie 1995; van der Eijk et al. 2006; van der Eijk and Marsh 2011).
Choice or preferences: when to focus on which?
Analysts interested in electoral support for parties sometimes have a decision to make about the kind of variable on which to focus: choice, or multiple preferences. If datasets include, for the political systems and elections that they are interested in, information on multiple preferences as well as choice, which of these should they focus on, and why? The answer to this question is mainly dependent on the research problem that they want to address and, to some extent, also on the kind of political system that they study.
The substantive questions that analysts may want to pursue with respect to parties’ electoral support can be distinguished into party-specific questions on the one hand, and systemic or generic questions on the other hand. Party-specific questions focus on the factors and conditions that drive electoral choice for a given party, such as “what is the association between religious affiliation and voting for the CDU/CSU” (in Germany), or “does the working class still support the Labour Party” (in Britain), or “to what extent do Democrats depend on the support of Latinos” (in the USA)? Such questions are not only of interest to political analysts, but also to journalists, politicians and interested citizens. The second kind of question, which we refer to here as “generic,” focuses on the structure of the process that underlies choices. Such questions are of the kind “what drives party choices in general: religion, class or ethnicity?” Or, “what is more important for party choice in general: party characteristics or leader characteristics?” Or, “under which conditions do issues of the day trump long-term ideological orientations?” In such research questions, we refer to “a party,” a generic entity, rather than to “Party A,” a specific party.
These different kinds of research interests – party-specific and generic questions – generally require different analytical strategies, and possibly different kinds of data, except in the specific (and exceptional) context of elections in which only two parties or candidates compete. In an election between only two contenders, both kinds of questions can be answered by a single binary logistic regression of electoral choice on attitudes, orientations and group membership of voters. This is because any given factor that benefits one of the parties harms the other party to the same degree. But in a multi-party context this does not hold. A multinomial logit analysis will in principle address party-specific questions via party-specific coefficients of contrasts between each party and a reference party. But the plethora of coefficients generated by such analyses will not provide a straightforward answer to generic research questions. This is because a factor that benefits one of the parties may at the same time benefit some of the other parties as well, while hurting yet other ones, and not all of this can be expressed in a single coefficient. One common approach to deal with this problem is by applying some kind of discrete-choice modeling, amongst which conditional logit analysis is probably the most popular variety. This approach has a number of advantages. Owing to the “long” or “stacked” data format used in such analyses it becomes possible to incorporate party characteristics (e.g., party size) as variables explaining party preferences, which is not possible in multinomial logistic analysis (cf. Alvarez and Nagler 1998). On the other hand, it is difficult in conditional logit analysis to incorporate respondent characteristics that for the same respondent do obviously not vary across parties. This leads often to hybrids of conditional logit and multinomial logistic models, which become increasingly more cumbersome as the number of choice options increases and which still contain (in their multinomial parts) party-specific coefficients that defy unequivocal expression of their importance in the choice process. An additional problem of conditional logit is the presence of unobserved heterogeneity, as parties are only distinguished in terms of “chosen” (category 1, assigned to only one party) and “not chosen” (category 0, assigned to all other parties), with the “0” category plausibly being heterogeneous in terms of electoral preference. It is particularly here – when addressing generic research questions in multi-party contexts – that multiple party preferences become a useful approach (as elaborated below).
If one has available empirical information about multiple preferences as well as about electoral choice, and one studies a multi-party context, then one should consider focusing on multiple preferences when interested in generic questions. Party-specific questions can then generally be well addressed by focusing on electoral choice, although even there multiple preferences may add relevant detail. In a two-party context, generic and party-specific questions can both be largely addressed by a focus on electoral choice, although here, too, analyses of multiple preferences may add useful detail.4
Analyzing multiple party preferences
Multiple preference questions provide a separate variable for each of the parties for which the question is asked. These can be used in at least two different ways when studying the bases of electoral support: separately (which addresses party-specific questions) or jointly (which addresses generic questions).
Analyzing multiple preferences separately – for each, or for some, or conceivably for only one of the parties for which they have been asked – is particularly useful for addressing partyspecific, descriptive and politically relevant questions about the electoral relationships between various individual characteristics (including group memberships) and political parties. In particular, these preference variables provide detail that cannot be obtained from traditional kinds of analyses that describe from which groups the various parties obtain votes. By tracing the strength of support for a party in a variety of segments of the population (defined by their demographic, socio-economic, residential or media-usage characteristics, or by their ideological orientations or involvement with particular issues), these analyses can depict differences in intensity of preferences for various parties. Such analyses can also usefully illuminate the competitive structure of party support, by identifying groups where a political party may gain additional votes (because that party is highly favored even if not actually voted for), or where the votes it gets are under threat of defection to other parties (for which support is almost as great even if not realized in terms of votes). Such information is of obvious relevance for the market segmentation and resource allocation strategies that are part of modern election campaigning. Moreover, multiple preferences also help alleviate the common problem of small numbers of observations that analysts of the electoral basis of small parties encounter. In a well-designed sample of (say) 1000 respondents, only some 50 respondents will have chosen or intend to choose a party that obtains, for example, 5 percent of the vote. Such small numbers severely limit how detailed the analysis can be of the support base of small parties. When using multiple preferences, however, all respondents in the sample are asked to express their electoral preference for the party in question, thus providing a much larger basis for analysis. Moreover, because the responses contain more variance (ranging from no preference to very strong preferences), they also provide a more productive basis for exploring correlates and possible drivers of electoral preferences. These advantages are even greater because when respondents provide multiple preferences they are not hindered by indecision about choice between several parties (which often leads to “don’t know” responses to a choice question), or by non-voting (which leads to an “inapplicable” coding for a choice question). Although largest for small parties, these advantages also apply to larger ones.5 Given these advantages, it is little wonder that multiple preferences are increasingly used for the analysis of electoral support of individual parties, both by practitioners involved in the running and management of campaigns and by academic analysts (cf. van der Brug et al. 2000, 2009; Mellon and Evans 2016; Vezzoni and Mancosu 2016).
Yet, party-specific analyses have clear limitations when trying to answer more general questions about the overall importance of factors driving electoral preferences and choice, irrespective of whether they are based on choices or on multiple preferences. Does class outweigh religion in determining party support? Do leader evaluations become more important over time? Is left/right ideology less important in newly established democracies? Party-specific analyses of support or choice cannot answer such questions as they yield a different result for each party. This problem becomes even more pressing when one realizes that coefficients from separate regression analyses of multiple preferences for different parties are incomparable because of distributional differences. How important are, for example, ideological orientations for voters’ electoral preferences? When analyzing multiple preferences separately, the answer to this question will be clear, but different for each party. Consider, for example, the correlation between multiple preferences for parties on the one hand and respondents’ left/right positions on the other. For a right-wing party, the relationship is likely to be strongly positive (being right-wing resulting in stronger preferences for a right-wing party). For a left-wing party, the relationship is likely to be strongly negative, while the relationship might appear to be close to zero for a centrist party (only because the relationship is non-linear). To solve this problem, a form of analysis is required that considers the multiple preferences for all parties jointly. Such a procedure is also required to avoid another problem inherent in analyzing electoral preferences separately for each of the parties: the omission of explanatory variables that only vary between parties, but that are constant for each party separately.6 Party size or parties’ government/opposition status are such factors which are often hypothesized to matter in voters’ preferences, but which cannot be assessed on the basis of separate, party-specific analyses.
Analyzing electoral preferences for all parties jointly can be done by shifting the unit of analysis from the respondent to the response: a respondent’s stated preference for a particular party (this yields a “long” or “stacked” data structure in which every respondent is represented by as many records as there are parties for which preferences have been asked). This is analogous to how conditional logit analysis structures data, with the party voted for coded “1” and all other parties coded “0.” The main difference is that with conditional logit analysis this variable is constrained (only one preference is non-zero) and dichotomous. Multiple preferences such as likes-dislikes and PTVs are empirically much richer and more informative, reflecting more gradations both in absolute levels of preference and in the degree to which one party may be preferred to other ones.7 The stacked structure of the data requires that many explanatory variables have to be defined in terms of relationships between the individual and party in question; thus, in order to assess the importance of left/right ideology in a stacked data arrangement, the relevant variable is not respondents’ left/right position (as it would be in a “wide” data arrangement where each of the multiple preferences is a separate variable) but instead the left/right distance between the respondent and each of the parties in question. For some kinds of variables, this is relatively easy to do (at least if the necessary data are available), but for other variables, such as demographics or attitudes, the relationship or “affinity” between respondents and parties has to be constructed in the form of synthetic variables (De Sio and Franklin 2011). Procedures to accomplish this exist8 and, when applied, provide the possibility to analyze all multiple preferences jointly as a single, generic variable (i.e., preference for a party). This in turn allows explanatory analyses of this generic variable that can incorporate the following different kinds of explanatory variables:
• Individual-specific variables, which are characteristics of respondents. The values of these variables vary between individuals for each party, but not between parties for each individual. Examples include demographics, attitudes, etc. Coefficients for these variables reflect the effect of voter characteristics on preferences for all parties;
• Party-specific variables, which are characteristics of parties. The values of these variables vary between parties for each individual, but not between individuals for each party. Examples are parties’ size, government status, etc. Coefficients for these variables reflect the effect on preferences of party characteristics that are the same for all respondents;
• Individual-party affinities, which are characteristics of respondent-party dyads. The values of these variables vary between parties for each individual, and also between individuals for each party. Examples are distances in ideological or issue dimensions or sympathy scores for the leaders of parties, but also synthetic affinities that express how attractive each of the parties is for a respondent given their demographic characteristics, attitudes, etc. (see note 8). Coefficients for these variables reflect the effect on preferences of party-respondent distance or affinity;
• Interactions between these kinds of variables.
Preference scores for multiple parties can, when structured in the stacked form, thus be analyzed in the following general form:
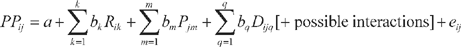 |
[1] |
where PP represents party preferences, one for each combination of respondents (i ) and parties ( j), Rik represents respondents’ scores on k different individual characteristics; Pjm represents parties’ scores on each of m different party characteristics; and Dijq represents the scores of all i × j respondent–party dyads on q different dyadic characteristics.9 This approach is a straightforward application of Przeworski and Teune’s (1970) recommendation to climb the ladder of abstraction by replacing specific (non-comparable) phenomena by more general (and hence more comparable) ones, and to replace proper names by theoretically relevant characteristics.
Use of multiple preferences in comparative research
Analyses of multiple party preferences in the generic form described above do not lead to conclusions about specific parties, but instead to conclusions about party preferences in general, and the factors that generate higher or lower preferences. This is of particular interest for comparative electoral studies because this generic perspective on party preferences provides a solution to the endemic problems caused by the fact that party systems are qualitatively different in different countries (and sometimes also at different moments in a single country). Traditionally, comparisons between political systems of choices or preferences for political parties have resorted to one of several solutions to this problem, none of which was quite satisfactory. One solution consists of replacing parties by party families which are supposed to be more comparable across countries than are the individual parties.10 This poses additional problems, such as what typology of party families to use; and how to classify parties in such a typology (particularly parties that do not easily fit within any of the families, such as, for example, Sinn Féin in Ireland). A second traditional approach to the incomparability of party systems is to distinguish the parties on the basis of some dichotomy: government versus opposition, or left versus right, or working class vs. others,11 and so forth. In this approach, too, the assumption is that the dichotomous distinction is more comparable between political systems than the separate parties are. This approach often creates the same problem of where to place particular parties, and almost always creates a problem of unobserved heterogeneity in one or even in both of the categories distinguished. A third way that has traditionally been used to deal with the incomparability of party systems consists of characterizing parties by their location on a single dimension (for instance, left/right) that is supposed to be of dominant importance in all countries to be compared. This solution reduces the problem of arbitrary classification, but makes the implausible assumption that other characteristics of parties are irrelevant for voters’ preferences.12
The generic perspective on party preferences discussed above solves these problems. It does not ask who is, or is not, attracted to a particular party, or to the parties of a particular party family, or to, for example, left parties, but instead it asks “what makes a party attractive to a citizen?” and it answers that question in a form (reflected in the equation at the end of the previous section) that is equally applicable to all parties and all citizens in all political systems under consideration. Survey data containing multiple preferences from different political systems can thus be pooled in a single analysis in which respondents’ preferences for political parties (in stacked form) constitute the dependent variable and with the same kinds of variables distinguished in equation 1 as independents.13 Such a data structure is obviously hierarchical in character, necessitating a multi-level analysis with responses (to the party preference questions) as level 1 units, respondents as level 2 units, parties cross-classified as a different set of level 2 units, and political systems as level 3 units.
Some of the first wide-ranging applications of this approach are Oppenhuis (1995) and van der Eijk and Franklin (1996), which both used 1989 and 1994 European Parliament Election Study data.
Additional analytical uses of multiple party preferences
Multiple party preferences are powerful instruments in the analysis of electoral support for political parties. However, they are also important as the empirical basis for other phenomena in the realm of electoral research, most notably electoral participation and electoral competition and the quality of electoral supply. Without going into great detail, this section summarizes these kinds of uses.
Multiple party preferences and electoral participation
It should come as no surprise that preferences for parties are highly predictive of whether or not citizens go to the polls. If none of the parties on offer engenders enthusiasm (as expressed in responses to multiple preference questions), there is little reward in voting. For a respondent to vote, at least one party should be sufficiently highly preferred.14 What is “sufficiently high” cannot be determined on the basis of first principles, but has to be assessed empirically, and may differ for different kinds of respondents and different contexts. Irrespective of the kind of preference scores used, levels of turnout increase monotonically with the magnitude of the highest preference score. Yet the relationship is distinctly not linear. Drop-off of turnout rates occurs particularly when (on a PTV scale from 0 to 10) the highest preference drops below 7, while values below 5 correspond to almost total abstention. Interestingly, multiple preferences allow detailed assessment of the importance of two often hypothesized conditions of non-voting: alienation and indifference, particularly in multi-party systems.15 Analyses based on CSES data (using the likes-dislikes measure of preferences) demonstrate that alienation is a very potent force driving electoral abstentions, while effects of indifference are much weaker (Falk Pedersen, Dassonneville and Hooghe 2014; Aarts and Wessels 2005).
Multiple party preferences, electoral competition and the quality of electoral supply
Survey questions about multiple party preferences provide a basis for measuring and analyzing party competition or the quality of the electoral supply side, by deriving from these multiple preferences a variety of other measures pertaining to individuals, parties, sets of parties and of entire party systems.
For individual respondents, their responses to multiple preference questions can be used to operationalize alienation from the party system and indifference toward the choices on offer, as noted above in the discussion of electoral participation. Another measure that can be derived from preferences for different parties is the magnitude of the difference (the “gap”) between highest and next highest preference. For some respondents, the two most preferred parties are tied (making the gap zero), for some it is small, and for others it is large®. This measure has been found to be strongly related to party-switching: those with a small gap have a much higher likelihood of switching than those with a larger gap. This measure is therefore particularly useful for managers of political campaigns who aim to identify those who are subject to intense electoral competition and who may therefore easily change their actual choice within a relatively short period such as, for example, during an election campaign.16 In academic usage the likely switchers are of particular interest in counterfactual analyses, focusing on how election outcomes would change if certain conditions were to be different (cf. van der Brug et al. 2007: 137–169).
At the level of political parties the set of multiple preference scores can be used to derive plausible estimates of the vote share that they maximally could obtain, and thus also of the complementary share of the electorate that, for all practical purposes, is beyond their reach. Such potential vote shares are unrealistic in the sense that they can only be obtained if, simultaneously, all relevant conditions favor the party in question and at the same time undermine its competitors. They are nevertheless important for political practitioners as evidence-based criteria of what is and what is not possible regarding electoral performance under given competitive circumstances.17 A party’s potential vote share is often considerably larger than its actual or predicted magnitude because of electoral competition, which manifests itself in the overlap of these potential vote shares across multiple parties. These overlaps are generated by respondents who have relatively high preferences for several parties at the same time. Such multiple high preferences (i.e., small “gaps” between preferences for the most preferred parties) are in European countries extremely common.18 The extent of overlap between parties’ potential vote shares can easily be calculated and reflects the effective electoral competition between them.19 These competitive relationships can be assessed for a party vis-à-vis any other party (or set of other parties), or for groups of parties vis-à-vis each other (e.g., the “left” parties versus the “right” parties), and all of these can easily be visualized in Venn-like diagrams. Further refinements consist of distinguishing for each party the competitive risks (potential vote switching away from the party in question by those who do or intend to vote for it) and the competitive opportunities (vote switching toward a party by those who do or intend to vote for another party). These various kinds of competitive relationships can be further specified by identifying the demographic or attitudinal profiles of the groups involved. From an academic perspective, analyses such as these are particularly important to analyze the factors underlying changing patterns of electoral competition and their consequences for electoral outcomes. Van der Eijk and Elkink (2017), for example, identify how generational replacement and cohort effects contributed to the dramatic Irish parliamentary election outcome of 2011 in which the incumbent Fianna Fáil lost almost 60 percent of its vote share.20
At yet a higher level of aggregation, entire political systems or party systems can be characterized in terms of degree and structure of electoral competition, by using various kinds of aggregations of the individual- or party-level characteristics discussed above. Alienation from the party system can be defined at the individual level, but aggregation leads to the measurement of party systems in terms of the degree of alienation that they engender among its citizens, or (when perceived from the opposite perspective) the quality of electoral supply. It then becomes a contextual variable that itself can be used as the phenomenon to be explained (what explains variations in alienation between countries?) or as an independent variable (what are the consequences of such variations between countries?).
Concluding remarks
Empirical data on multiple party preferences, in addition to data on electoral choice, provide large and important benefits to analysts of elections, electoral behavior and electoral competition. One of the most important of these is the possibility to model the relationships between voters and parties very flexibly in a generic way. For the study of multi-party systems, multiple preferences are indispensable to address such questions, while even for two-party systems they will provide useful added insights. As discussed, the advantages over more traditional discrete choice models include a reduced reliance on (sometimes heroic) assumptions,21 the avoidance of unaccounted-for heterogeneity, and the straightforward possibility of pooling data from multiple political systems (with their qualitatively different party systems) in a single model. The advantages of multiple preference questions for party-specific and descriptive research interests include the enormous increase in the number of relevant observations which allow more detailed comparisons between subgroups such as cohorts than would be possible if only information on choice would be available. Moreover, empirical information on preferences is more detailed than the coarse black-and-white of choice distinctions. Both aspects provide more statistical power than any analysis based on choice. The advantages of multiple preference questions for the study of electoral competition lie not only in the detail of relevant information, but particularly in the possibility they provide for comparing the competitive situations in which different parties find themselves at the point in time at which the questions are asked.
Moreover, multiple preferences yield, much more than choice, relevant information for non-academic stakeholders in electoral research: parties, politicians, campaign managers and interested citizens.
These advantages come, of course, at the price of a greater pressure on questionnaire space than if one were to only ask about choice. Yet, in all instances where questions about multiple preferences were included in surveys, the investment has paid off handsomely. If, therefore, one overarching and compelling conclusion can be drawn from this chapter, it is that surveys about electoral behavior and support for parties should include questions about multiple party preferences.
Compared to analyses of survey data about choice, which now rely on accumulated experience of some 50 to 75 years (depending on the country one looks at), experiences with analyses of multiple preferences are still relatively limited. For many countries, the inclusion of such questions in election surveys is a recent departure or one that has not yet occurred. But the analysis of multiple preferences is certainly not in its infancy, and it can be expected that the passage of time will propel important innovations with respect to data collection, statistical and analytical procedures, and theoretical insights. In the next edition of this handbook, this chapter should reflect such progress.
Notes
1 Much more refined is magnitude estimation of strength of preferences, which yields interval-level measurement, and which is useful to calibrate the ordinal information obtained from rating scales (for an example, see Tillie 1995).
2 The consideration set approach does not necessarily require dedicated survey questions and can be based on the other multiple preference questions discussed above (cf. Bochsler and Sciarini 2010).
3 The Irish National Election Study (INES) of 2002 is the only large-scale study in which these three kinds of multiple measures were all included. The concordance between multiple preferences and choice was 87 percent for PTV, 83 percent for likes-dislikes and 65 percent for the thermometer question (cf. Van der Eijk and Marsh 2011). The same rank order of performance has been found in largescale studies that incorporated two of these three kinds of questions.
4 In two-party contests multiple preferences allow more incisive analyses of electoral participation and of electoral competition, as described later in this chapter.
5 In many multi-party systems, a vote share of some 30 percent is sufficient to make a party one of the “large” ones. Depending upon registration procedures this may represent a considerably smaller segment of the voting-age population, as illustrated by the British Conservative Party, which polled almost 37 percent of the votes in 2015 but was supported by only 24 percent of the voting-age population. As a consequence, numbers of respondents having voted for a “large” party in a representative sample may be disappointingly limited.
6 These same issues are equally problematic when analyzing choices in a multinomial logistic analysis.
7 Moreover, multiple preferences avoid the problem of unobserved heterogeneity in conditional logit analysis that was already mentioned earlier and which generally leads to biased estimates; this advantage is mostly lost, however, when only focusing on the most strongly preferred parties, as is done in the consideration set approach, as that approach restricts the variance of the dependent variable.
8 Several approaches to the construction of such synthetic affinity variables exist. One is the so-called “y-hat” procedure (cf. van der Eijk and Franklin 1996: Chapter 20; van der Eijk et al. 2006); another procedure is based on the application of Joint Correspondence Analysis (cf. Franklin and Weber 2014). Yet another, widely used by sociologists, compares individual characteristics with the average for all supporters of each given party, producing a “quasi-distance” measure that is comparable across parties.
9 As the data structure is clustered, a multi-level specification of this model is necessary if the residuals display significant intra-class correlation; for examples, see Franklin and Renko (2013).
10 Examples of the reduction of party systems to a set of party families include Marks et al. (2002), Ennser (2012) and Knutsen (2013).
11 Reducing a party system to a dichotomy is commonplace in much of the literature on economic voting, using the distinction between government and opposition parties (cf. Andersen 1995; Lewis-Beck and Paldam 2000); for a critique of this approach, see van der Brug et al. (2007: 9–15). Such a reduction on the basis of a different dichotomy was also used by Franklin et al. (1992, 2009), who use a binary distinction between “left” and “right” parties. Yet another binary distinction underlies wellknown indices of class-voting (cf. Alford 1962), and many analyses of particular kinds of parties, such as extreme right parties (cf. van der Brug et al. 2000).
12 Examples of the reduction of party systems to a single dimension include Dalton (2008), and, in dichotomized form, Franklin et al. (1992, 2009).
13 Obviously, for these situations, equation 1 has to be extended, at least in principle, with a class of independent variables pertaining to the political system and, possibly, interactions thereof in order to take account of any system-specific deviations from a common pattern of effects.
14 This implies the need in many analyses of a new variable created as the maximum of the responses to the party preference questions.
15 Alienation would be reflected inversely in the magnitude of the highest preference, and indifference would be reflected in ties between preference scores for different parties.
16 Respondents who claim to be “undecided” are not, as is often thought, necessarily tied in their party preferences. If we ask undecided voters about their preferences for different parties, we often find many of them with a party that is well ahead of all others in terms of preferences. “Undecided” then indicates that the respondent has not yet focused on the decision that they need to make.
17 The following episode illustrates this. In the mid-1980s, Dutch opinion polls showed that one of the political parties in the country would lose virtually all of its parliamentary seats at the next election. This led to a grassroots appeal for its leader to be replaced by a charismatic predecessor. Before taking action, the latter wanted to know whether there was any realistic hope of success. An analysis of multiple preferences revealed that the party’s realistic potential electorate was far from negligible, which persuaded the former leader to again take charge of the party, and within weeks the party had regained in the polls its former strength (a situation that continued until the next parliamentary election). This was only possible because for many voters their preferences for this party were high, but just shy of being their first (highest) preference. The change of leadership increased their preference for the party by just a little, but sufficiently for it to become their highest preference.
18 Kroh et al. (2007) estimate that in 1999 more than 40 percent of citizens across the EU countries have a gap of no more than 1 (on a PTV-scale of 0–10) between their two most preferred parties.
19 Competition is here conceptualized in terms of openness on the demand side, referred to by Bartolini (2002) as availability. This emphasizes not the outcome of competition, but the range of counterfactual outcomes that can ensue from it, a perspective also emphasized by Elkins (1974).
20 These authors also provide a set of formal equations for the definition of these, and yet other, such relationships.
21 This is elaborated in more detail in van der Eijk et al. (2006).
References
Aarts, K. and Wessels, B. (2005) “Electoral Turnout,” in Thomassen, J. (ed.) The European Voter: A Comparative Study of Modern Democracies, Oxford: Oxford University Press: 64–83.
Alford, R. (1962) “A Suggested Index of the Association of Social Class and Voting,” Public Opinion Quarterly, vol. 26, no.3, Fall, 417–425.
Alvarez, R. M. and Nagler, J. (1998) “When Politics and Models Collide: Estimating Models of Multiparty Elections,” American Journal of Political Science, vol. 42, no. 1, January, 55–96.
Andersen, C. (1995) Blaming the Government: Citizens and the Economy in Five European Democracies, Armonk: M. E. Sharpe.
Bartolini, S. (2002) “Electoral and Party Competition: Analytical Dimensions and Empirical Problems,” in Gunther, R., Montero, J. R. and Linz, J. (eds.) Political Parties – Old Concepts and New Challenges, Oxford, Oxford University Press: 84–110.
Bochsler, D. and Sciarini, P. (2010) “So Close but So Far: Voting Propensity and Party Choice for Left-Wing Parties,” Swiss Political Science Review, vol. 16, no. 3, Autumn, 373–402.
Brug, W. van der, Eijk, C. van der and Franklin, M. (2007) The Economy and the Vote – Economic Conditions and Elections in Fifteen Countries, Cambridge: Cambridge University Press.
Brug, W. van der, Fennema, M. and Tillie, J. (2000) “Anti-Immigrant Parties in Europe: Ideological or Protest Vote?,” European Journal of Political Research, vol. 37, no. 1, January, 77–102.
Brug, W. van der, Hobolt, S. and de Vreese, C. (2009) “Religion and Party Choice in Europe,” West European Politics, vol. 32, no. 6, November, 1266–1283.
Converse, P. E. (1974) “Some Priority Variables in Comparative Electoral Research,” in Rose, R. (ed.) Electoral Behavior: A Comparative Handbook, New York: The Free Press: 727–745.
Dalton, R. J. (2008) “The Quantity and the Quality of Party Systems: Party System Polarization, Its Measurement, and Its Consequences,” Comparative Political Studies, vol. 41, no. 7, February, 899–920.
De Sio, L. and Franklin, M. (2011) “Generic Variable Analysis: Climbing the Ladder of Generality with Social Science Data,” Paper presented at the 2011 European Conference on Comparative Electoral Research, Sofia, December 1–3.
Downs, A. (1957) An Economic Theory of Democracy, New York: Harper and Row.
Eijk, C. van der, Brug, W. van der, Kroh, M. and Franklin, M. (2006) “Rethinking the Dependent Variable in Voting Behaviour – On the Measurement and Analysis of Electoral Utilities,” Electoral Studies, vol. 25, no. 3, September, 424–447.
Eijk, C. van der and Elkink, J. A. (2017) “How Generational Replacement Undermined the Electoral Resilience of Fianna Fáil,” in Marsh, M., Farrell, D. M. and McElroy, G. (eds.) A Conservative Revolution? Electoral Change in 21st Century Ireland, Oxford: Oxford University Press: 102–122.
Eijk, C. van der and Franklin, M. (eds.) (1996) Choosing Europe? The European Electorate and National Politics in the Face of Union, Ann Arbor: The University of Michigan Press.
Eijk, C. van der and Marsh, M. (2011) “Comparing Non-Ipsative Measures of Party Support,” Paper presented at the 2011 European Conference on Comparative Electoral Research, Sofia, December 1–3.
Elkins, D. E. (1974) “The Measurement of Party Competition,” American Political Science Review, vol. 68, no. 2, June, 682–700.
Ennser, L. (2012) “The Homogeneity of West European Party Families: The Radical Right in Comparative Perspective,” Party Politics, vol. 18, no. 2, February, 151–171.
Falk Pedersen, E., Dassonneville, R. and Hooghe, M. (2014) “The Effect of Alienation and Indifference Toward the Party System on Voter Turnout, A Comparative Analysis,” Paper presented at the 2014 Belgian-Dutch Political Science Conference, Maastricht, June 12–13.
Franklin, M. and Renko, M. (2013) “Studying Party Choice,” in Bruter, M. and Lodge, M. (eds.) Political Science Research Methods in Action, Basingstoke: Palgrave Macmillan: 93–118.
Franklin, M. and Weber, T. (2014) A Structuring Theory of Electoral Politics, Unpublished Manuscript, available online: www.trincoll.edu/~MarkFranklin/Structuring_UBC_w_appendix.pdf.
Franklin, M., Mackie, T. and Valen, H. (eds.) (1992) Electoral Change: Responses to Evolving Social and Attitudinal Structures in Western Countries, New York: Cambridge University Press.
Franklin, M., Mackie, T. and Valen, H. (eds.) (2009) Electoral Change: Responses to Evolving Social and Attitudinal Structures in Western Countries, Colchester: ECPR Press.
Knutsen, O. (2013) “Party Choice,” in Keil, S. I. and Gabriel, O. W. (eds.) Society and Democracy in Europe, London: Routledge, 244–269.
Kroh, M., van der Brug, W. and van der Eijk, C. (2007) “Prospects for Electoral Change,” in van der Brug and van der Eijk (eds.) European Elections and Domestic Politics – Lessons from the Past and Scenarios for the Future, Notre Dame: University of Notre Dame Press: 236–253.
Lewis-Beck, M. and Paldam, M. (2000) “Economic Voting: An Introduction,” Electoral Studies, vol. 19, no. 2–3, June, 113–122.
Marks, G., Wilson, C. J. and Ray, L. (2002) “National Political Parties and European Integration,” American Journal of Political Science, vol. 46, no. 3, July, 585–594.
Mellon, J. and Evans, G. (2016) “Class, Electoral Geography and the Future of UKIP: Labour’s Secret Weapon?,” Parliamentary Affairs, vol. 69, no. 2, April, 492–498.
Oppenhuis, E. V. (1995) Voting Behavior in Europe: A Comparative Analysis of Electoral Participation and Party Choice, Amsterdam: Het Spinhuis.
Oskarson, M., Oscarsson, H. and Boije, E. (2016) “Consideration and Choice: Analyzing Party Choice in the Swedish European Election 2014,” Scandinavian Political Studies, vol. 39, no. 3, September, 242–263.
Powell, G. B. (2000) Elections as Instruments of Democracy, New Haven: Yale University Press.
Przeworski, A. and Teune, H. (1970) The Logic of Comparative Social Inquiry, New York: Wiley-Interscience.
Sartori, G. (1976) Parties and Party Systems: A Framework for Analysis, Cambridge: Cambridge University Press.
Tillie, J. (1995) Party Utility and Voting Behavior, Amsterdam, Het Spinhuis.
Vezzoni, C. and Mancosu, M. (2016) “Diffusion Processes and Discussion Networks: An Analysis of the Propensity to Vote for the 5 Star Movement in the 2013 Italian Election,” Journal of Elections, Public Opinion and Parties, vol. 26, no. 1, February, 1–21.
Wilson, C. J. (2008) “Consideration Sets and Political Choices: A Heterogeneous Model of Vote Choice and Sub-National Party Strength,” Political Behavior, vol. 30, no. 2, June, 161–183.