The heart and soul of any enterprise system is its database. It is the biggest asset of the system on any given day. It is also the most vulnerable part of the whole system in such an exercise. No wonder database architects can sound mean and intruding whenever you ask them to make even the smallest change. Their domain is defined by database tables and stored procedures.
The health of their domain is judged by the referential integrity and the time it takes to perform various transactions. I don't hold them guilty for overdoing it anymore. They have a reason for this—their past experiences. It's time to change that. Let me tell you, this won't be easy, as we will have to utilize a completely different approach to handle data integrity once we embark on this path.
You might think that the easiest approach is to divide the whole database in one go, but this is not the case. It can lead us to the situation we have been trying to avoid all along. Let's look at how to go about doing this in a more efficient manner.
As you move along, picking up pieces after the module dependency analysis, identify the database structures that are being used to interact with the database. There are two steps that you need to perform here. First, check whether you can isolate the database structures in your code to be broken down, and align this with the newly defined vertical boundaries. Second, identify what it would take to break down the underlying database structure as well.
Don't worry yet if breaking down the underlying data structure seems difficult. If it appears that it is involving other modules that you haven't started to move to microservices, it is a good sign. Don't let the database changes define the modules that you would pick and migrate to microservice-style architecture. Keep it the other way round. This ensures that when a database change is picked up, the code that depends on the change is already ready to absorb the change.
This ensures that you don't pick up the battle of data integrity while you are already occupied with modifying the code that would rely on this part of the database. Nevertheless, such database structures should draw your attention so that the modules that depend on them are picked next. This will allow you to easily complete the move to microservices for all the associated modules in one go. Refer to the following diagram:
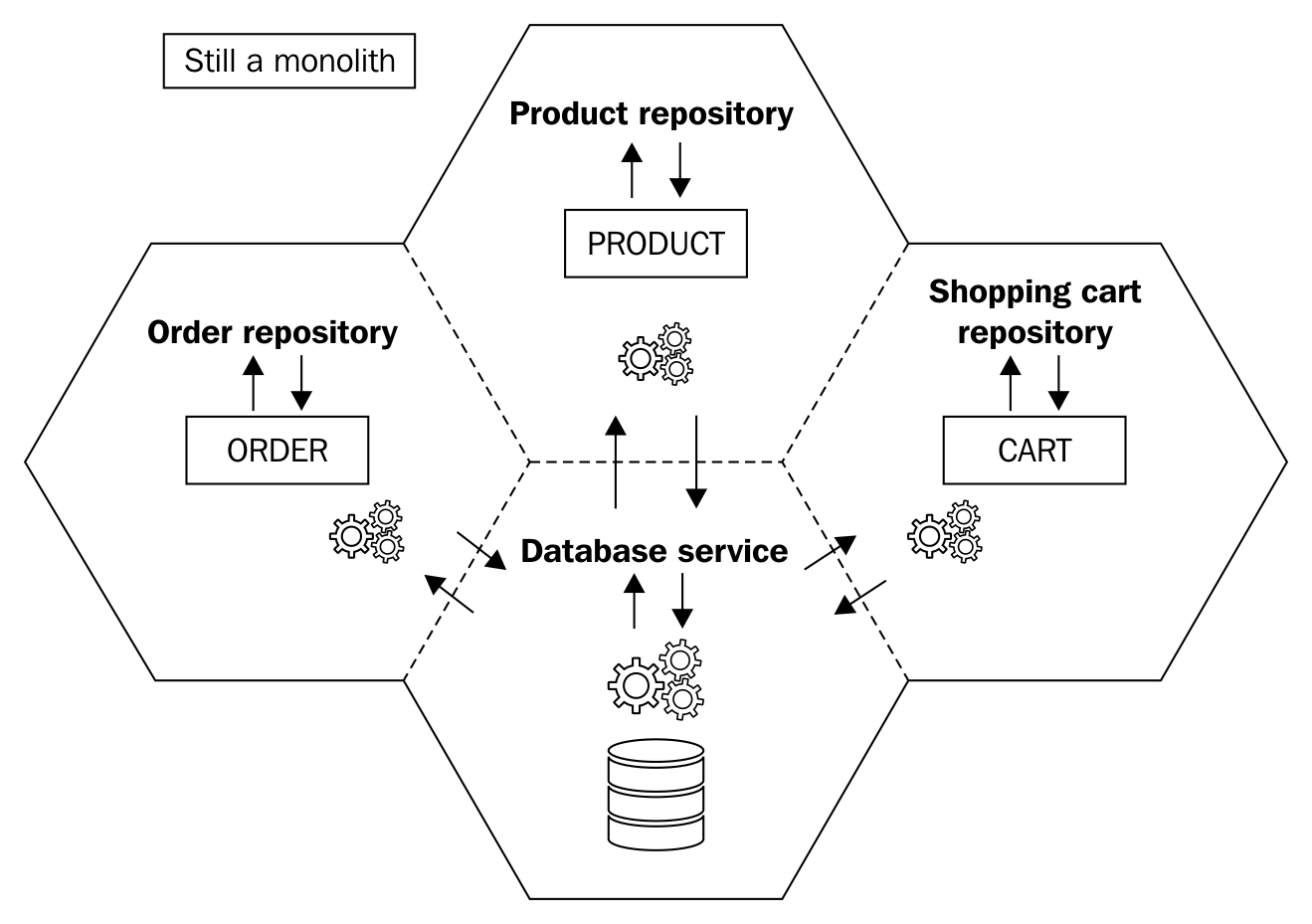
Here, we have not broken the database yet. Instead, we have simply separated our database access part into layers as part of the first step.
What we have simply done is map the code data structure the database, and they no longer depend on each other. Let's see how this step would work out when we remove foreign key relationships.
If we can transition the code structures being used to access the database along with the database structure, we will save time. This approach might differ from system to system and can be affected by our personal bias. If your database structure changes seem to be impacting modules that are yet to be marked for transition, move on for now.
Another important point to understand here is what kind of changes are acceptable when you break down this database table or merge it with another partial structure? The most important thing is not to shy away from breaking those foreign key relationships apart. This might sound like a big difference from our traditional approach to maintaining data integrity. However, removing your foreign key relationships is the most fundamental challenge when restructuring your database to suit the microservice architecture. Remember that a microservice is meant to be independent of other services. If there are foreign key relationships with other parts of the system, it makes it dependent on the services owning that part of the database. Refer to the following diagram:
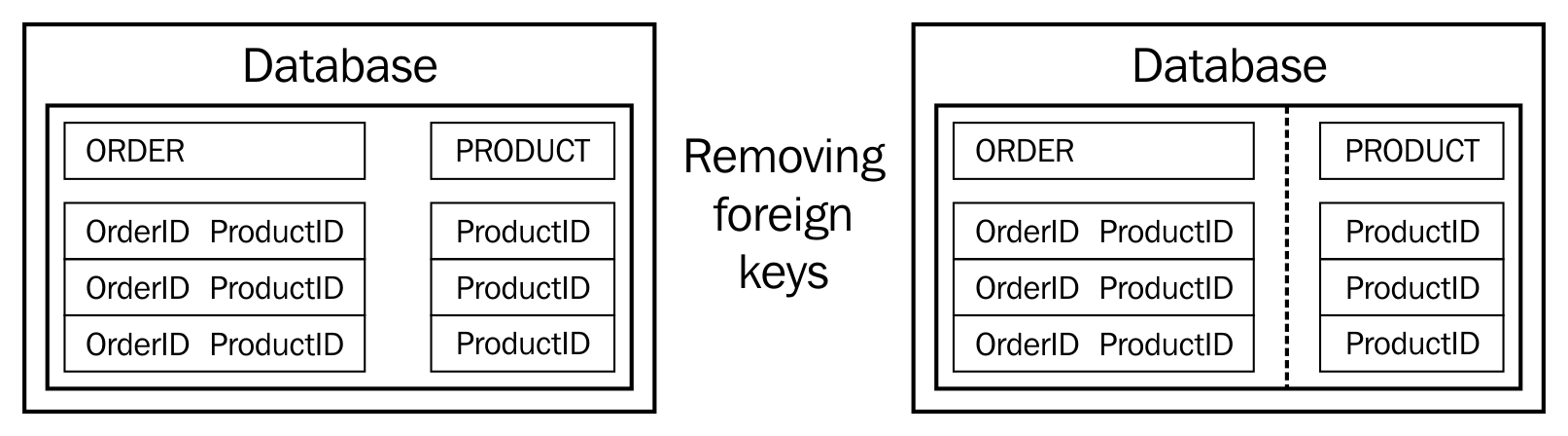
As part of step two, we have kept the foreign key fields in the database tables but have removed the foreign key constraint. So the ORDER table is still holding information about ProductID, but the foreign key relation is broken now. Refer to the following diagram:

This is what our microservice-style architecture would finally look like. The central database would be moved away in favor of each service having their own database. So, separating the data structures in the code and removing foreign key relationships is our preparation to finally make the change. The connected boundaries of microservices in the preceding figure signify the interservice communication.
With the two steps performed, your code is now ready to split ORDER and PRODUCT into separate services, with each having their own database.
If all of the discussion here has left you bewildered about all those transactions that have been safely performed up to now, you are not alone. This outcome of the challenge with the transactions is not a small one by any means, and deserves focused attention. We'll talk about this in detail a bit later. Before that, there is another part that becomes a no man's land in the database. It is master data or static data, as some may call it.