Chapter 2
Why is big data special?
Big data didn’t just happen—it was closely linked to the development of computer technology. The rapid rate of growth in computing power and storage led to progressively more data being collected, and, regardless of who first coined the term, ‘big data’ was initially all about size. Yet it is not possible to define big data exclusively in terms of how many Pb, or even Eb, are being generated and stored. However, a useful means for talking about the ‘big data’ resulting from the data explosion is provided by the term ‘small data’—although it is not widely used by statisticians. Big datasets are certainly large and complex, but in order for us to reach a definition, we need first to understand ‘small data’ and its role in statistical analysis.
Big data versus small data
In 1919, Ronald Fisher, now widely recognized as the founder of modern statistics as an academically rigorous discipline, arrived at Rothamsted Agricultural Experimental Station in the UK to work on analysing crop data. Data has been collected from the Classical Field Experiments conducted at Rothamsted since the 1840s, including both their work on winter wheat and spring barley and meteorological data from the field station. Fisher started the Broadbalk project which examined the effects of different fertilizers on wheat, a project still running today.
Recognizing the mess the data was in, Fisher famously referred to his initial work there as ‘raking over the muck heap’. However, by meticulously studying the experimental results that had been carefully recorded in leather-bound note books he was able to make sense of the data. Working under the constraints of his time, before today’s computing technology, Fisher was assisted only by a mechanical calculator as he, nonetheless successfully, performed calculations on seventy years of accumulated data. This calculator, known as the Millionaire, which relied for power on a tedious hand-cranking procedure, was innovative in its day, since it was the first commercially available calculator that could be used to perform multiplication. Fisher’s work was computationally intensive and the Millionaire played a crucial role in enabling him to perform the many required calculations that any modern computer would complete within seconds.
Although Fisher collated and analysed a lot of data it would not be considered a large amount today, and it would certainly not be considered ‘big data’. The crux of Fisher’s work was the use of precisely defined and carefully controlled experiments, designed to produce highly structured, unbiased sample data. This was essential since the statistical methods then available could only be applied to structured data. Indeed, these invaluable techniques still provide the cornerstone for the analysis of small, structured sets of data. However, those techniques are not applicable to the very large amounts of data we can now access with so many different digital sources available to us.
Big data defined
In the digital age we are no longer entirely dependent on samples, since we can often collect all the data we need on entire populations. But the size of these increasingly large sets of data cannot alone provide a definition for the term ‘big data’—we must include complexity in any definition. Instead of carefully constructed samples of ‘small data’ we are now dealing with huge amounts of data that has not been collected with any specific questions in mind and is often unstructured. In order to characterize the key features that make data big and move towards a definition of the term, Doug Laney, writing in 2001, proposed using the three ‘v’s: volume, variety, and velocity. By looking at each of these in turn we can get a better idea of what the term ‘big data’ means.
Volume
‘Volume’ refers to the amount of electronic data that is now collected and stored, which is growing at an ever-increasing rate. Big data is big, but how big? It would be easy just to set a specific size as denoting ‘big’ in this context, but what was considered ‘big’ ten years ago is no longer big by today’s standards. Data acquisition is growing at such a rate that any chosen limit would inevitably soon become outdated. In 2012, IBM and the University of Oxford reported the findings of their Big Data Work Survey. In this international survey of 1,144 professionals working in ninety-five different countries, over half judged datasets of between 1 Tb and 1 Pb to be big, while about a third of respondents fell in the ‘don’t know’ category. The survey asked respondents to choose either one or two defining characteristics of big data from a choice of eight; only 10 per cent voted for ‘large volumes of data’ with the top choice being ‘a greater scope of information’, which attracted 18 per cent. Another reason why there can be no definitive limit based solely on size is because other factors, like storage and the type of data being collected, change over time and affect our perception of volume. Of course, some datasets are very big indeed, including, for example, those obtained by the Large Hadron Collider at CERN, the world’s premier particle accelerator, which has been operating since 2008. Even after extracting only 1 per cent of the total data generated, scientists still have 25 Pb to process annually. Generally, we can say the volume criterion is met if the dataset is such that we cannot collect, store, and analyse it using traditional computing and statistical methods. Sensor data, such as that generated by the Large Hadron Collider, is just one variety of big data, so let’s consider some of the others.
Variety
Though you may often see the terms ‘Internet’ and ‘World Wide Web’ used interchangeably, they are actually very different. The Internet is a network of networks, consisting of computers, computer networks, local area networks (LANs), satellites, and cellphones and other electronic devices, all linked together and able to send bundles of data to one another, which they do using an IP (Internet protocol) address. The World Wide Web (www, or Web), described by its inventor, T. J. Berners-Lee, as ‘a global information system’, exploited Internet access so that all those with a computer and a connection could communicate with other users through such media as email, instant messaging, social networking, and texting. Subscribers to an ISP (Internet services provider) can connect to the Internet and so access the Web and many other services.
Once we are connected to the Web, we have access to a chaotic collection of data, from sources both reliable and suspect, prone to repetition and error. This is a long way from the clean and precise data demanded by traditional statistics. Although the data collected from the Web can be structured, unstructured, or semi-structured resulting in significant variety (e.g. unstructured word-processed documents or posts found on social networking sites; and semi-structured spreadsheets), most of the big data derived from the Web is unstructured. Twitter users, for example, publish approximately 500 million 140-character messages, or tweets, per day worldwide. These short messages are valuable commercially and are often analysed according to whether the sentiment expressed is positive, negative, or neutral. This new area of sentiment analysis requires specially developed techniques and is something we can do effectively only by using big data analytics. Although a great variety of data is collected by hospitals, the military, and many commercial enterprises for a number of purposes, ultimately it can all be classified as structured, unstructured, or semi-structured.
Velocity
Data is now streaming continuously from sources such as the Web, smartphones, and sensors. Velocity is necessarily connected with volume: the faster data is generated, the more there is. For example, the messages on social media that now ‘go viral’ are transmitted in such a way as to have a snowball effect: I post something on social media, my friends look at it, and each shares it with their friends, and so on. Very quickly these messages make their way around the world.
Velocity also refers to the speed at which data is electronically processed. For example, sensor data, such as that being generated by an autonomous car, is necessarily generated in real-time. If the car is to work reliably, the data, sent wirelessly to a central location, must be analysed very quickly so that the necessary instructions can be sent back to the car in a timely fashion.
Variability may be considered as an additional dimension of the velocity concept, referring to the changing rates in flow of data, such as the considerable increase in data flow during peak times. This is significant because computer systems are more prone to failure at these times.
Veracity
As well as the original three ‘v’s suggested by Laney, we may add ‘veracity’ as a fourth. Veracity refers to the quality of the data being collected. Data that is accurate and reliable has been the hallmark of statistical analysis in the past century. Fisher, and others, strived to devise methods encapsulating these two concepts, but the data generated in the digital age is often unstructured, and often collected without experimental design or, indeed, any concept of what questions might be of interest. And yet we seek to gain information from this mish-mash. Take, for example, the data generated by social networks. This data is by its very nature imprecise, uncertain, and often the information posted is simply not true. So how can we trust the data to yield meaningful results? Volume can help in overcoming these problems—as we saw in Chapter 1, when Thucydides described the Plataean forces engaging the greatest possible number of soldiers counting bricks in order to be more likely to get (close to) the correct height of the wall they wished to scale. However, we need to be more cautious, as we know from statistical theory, greater volume can lead to the opposite result, in that, given sufficient data, we can find any number of spurious correlations.
Visualization and other ‘v’s
‘V’ has become the letter of choice, with competing definitions adding or substituting such terms as ‘vulnerability’ and ‘viability’ to Laney’s original three—the most important perhaps of these additions being ‘value’ and ‘visualization’. Value generally refers to the quality of the results derived from big data analysis. It has also been used to describe the selling by commercial enterprises of data to firms who then process it using their own analytics, and so it is a term often referred to in the data business world.
Visualization is not a characterizing feature of big data, but it is important in the presentation and communication of analytic results. The familiar static pie charts and bar graphs that help us to understand small datasets have been further developed to aid in the visual interpretation of big data, but these are limited in their applicability. Infographics, for example, provide a more complex presentation but are static. Since big data is constantly being added to, the best visualizations are interactive for the user and updated regularly by the originator. For example, when we use GPS for planning a car journey, we are accessing a highly interactive graphic, based on satellite data, to track our position.
Taken together, the four main characteristics of big data—volume, variety, velocity, and veracity—present a considerable challenge in data management. The advantages we expect to gain from meeting this challenge and the questions we hope to answer with big data can be understood through data mining.
Big data mining
‘Data is the new oil’, a phrase that is common currency among leaders in industry, commerce, and politics, is usually attributed to Clive Humby in 2006, the originator of Tesco’s customer loyalty card. It’s a catchy phrase and suggests that data, like oil, is extremely valuable but must first be processed before that value can be realized. The phrase is primarily used as a marketing ploy by data analytics providers hoping to sell their products by convincing companies that big data is the future. It may well be, but the metaphor only holds so far. Once you strike oil you have a marketable commodity. Not so with big data; unless you have the right data you can produce nothing of value. Ownership is an issue; privacy is an issue; and, unlike oil, data appears not to be a finite resource. However, continuing loosely with the industrial metaphor, mining big data is the task of extracting useful and valuable information from massive datasets.
Using data mining and machine learning methods and algorithms, it is possible not only to detect unusual patterns or anomalies in data, but also to predict them. In order to acquire this kind of knowledge from big datasets, either supervised or unsupervised machine learning techniques may be used. Supervised machine learning can be thought of as roughly comparable to learning from example in humans. Using training data, where correct examples are labelled, a computer program develops a rule or algorithm for classifying new examples. This algorithm is checked using the test data. In contrast, unsupervised learning algorithms use unlabelled input data and no target is given; they are designed to explore data and discover hidden patterns.
As an example let’s look at credit card fraud detection, and see how each method is used.
Credit card fraud detection
A lot of effort goes into detecting and preventing credit card fraud. If you have been unfortunate enough to receive a phone call from your credit card fraud detection office, you may be wondering how the decision was reached that the recently made purchase on your card had a good chance of being fraudulent. Given the huge number of credit card transactions it is no longer feasible to have humans checking transactions using traditional data analysis techniques, and so big data analytics are increasingly becoming necessary. Understandably, financial institutions are unwilling to share details of their fraud detection methods since doing so would give cyber criminals the information they need to develop ways round it. However, the broad brush strokes present an interesting picture.
There are several possible scenarios but we can look at personal banking and consider the case in which a credit card has been stolen and used in conjunction with other stolen information, such as the card PIN (personal identification number). In this case, the card might show a sudden increase in expenditure—a fraud that is easily detected by the card issuing agency. More often, a fraudster will first use a stolen card for a ‘test transaction’ in which something inexpensive is purchased. If this does not raise any alarms, then a bigger amount is taken. Such transactions may or may not be fraudulent—maybe a cardholder bought something outside of their usual purchasing pattern, or maybe they actually just spent a lot that month. So how do we detect which transactions are fraudulent? Let’s look first at an unsupervised technique, called clustering, and how it might be used in this situation.
Clustering
Based on artificial intelligence algorithms, clustering methods can be used to detect anomalies in customer purchasing behaviour. We are looking for patterns in transaction data and want to detect anything unusual or suspicious which may or may not be fraudulent.
A credit card company gathers lots of data and uses it to form profiles showing the purchasing behaviour of their customers. Clusters of profiles with similar properties are then identified electronically using an iterative (i.e. repeating a process to generate a result) computer program. For example, a cluster may be defined on accounts with a typical spending range or location, a customer’s upper spending limit, or on the kind of items purchased, each resulting in a separate cluster.
When data is collected by a credit card provider it does not carry any label indicating whether the transactions are genuine or fraudulent. Our task is to use this data as input and, using a suitable algorithm, accurately categorize transactions. To do this, we will need to find similar groups, or clusters, within the input data. So, for example, we might group data according to the amount spent, the location where the transaction took place, the kind of purchase made, or the age of the card holder. When a new transaction is made, the cluster identification is computed for that transaction and if it is different from the existing cluster identification for that customer, it is treated as suspicious. Even if it falls within the usual cluster, if it is sufficiently far from the centre of the cluster it may still arouse suspicion.
For example, say an 83-year-old grandmother living in Pasadena purchases a flashy sports car; if this does not cluster with her usual purchasing behaviour of, say, groceries and visits to the hairdresser, it would be considered anomalous. Anything out of the ordinary, like this purchase, is considered worthy of further investigation, usually starting by contacting the card owner. In Figure 1 we see a very simple example of a cluster diagram representing this situation.
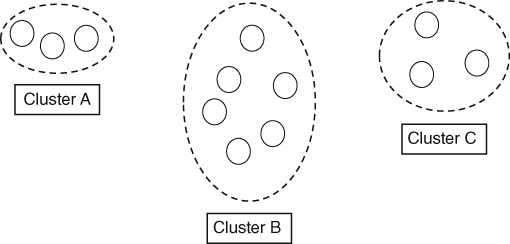
1. A cluster diagram.
Cluster B shows the grandmother’s usual monthly expenditure clustered with other people who have a similar monthly expenditure. Now, in some circumstances, for example when taking her annual vacation, the grandmother’s expenditure for the month increases, perhaps grouping her with those in Cluster C, which is not too far distant from Cluster B and so not drastically dissimilar. Even so, since it is in a different cluster, it would be checked as suspicious account activity, but the purchase of the flashy sports car on her account puts her expenditure into Cluster A, which is very distant from her usual cluster and so is highly unlikely to reflect a legitimate purchase.
In contrast to this situation, if we already have a set of examples where we know fraud has occurred, instead of clustering algorithms we can use classification methods, which provide another data mining technique used for fraud detection.
Classification
Classification, a supervised learning technique, requires prior knowledge of the groups involved. We start with a dataset in which each observation is already correctly labelled or classified. This is divided into a training set, which enables us to build a classification model of the data, and a test set, which is used to check that the model is a good one. We can then use this model to classify new observations as they arise.
To illustrate classification, we will build a small decision tree for detecting credit card fraud.
To build our decision tree, let us suppose that credit card transaction data has been collected and transactions classified as genuine or fraudulent based on our historical knowledge are provided, as shown in Figure 2.
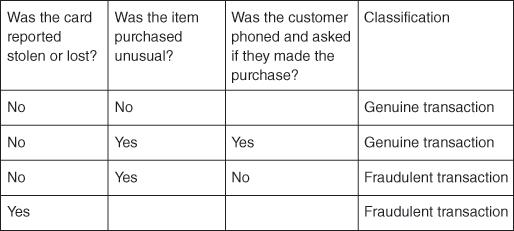
2. Fraud dataset with known classifications.
Using this data, we can build the decision tree shown in Figure 3, which will allow the computer to classify new transactions entering the system. We wish to arrive at one of the two possible transaction classifications, genuine or fraudulent, by asking a series of questions.
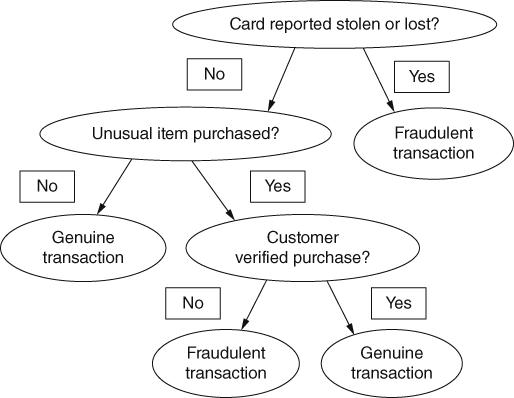
3. Decision tree for transactions.
By starting at the top of the tree in Figure 3, we have a series of test questions which will enable us to classify a new transaction.
For example, if Mr Smith’s account shows that he has reported his credit card as lost or stolen, then any attempt to use it is deemed fraudulent. If the card has not been reported lost or stolen, then the system will check to see if an unusual item or an item costing an unusual amount for this customer has been purchased. If not, then the transaction is seen as nothing out of the ordinary and labelled as genuine. On the other hand, if the item is unusual then a phone call to Mr Smith will be triggered. If he confirms that he did make the purchase, then it is deemed genuine; if not, fraudulent.
Having arrived at an informal definition of big data, and considered the kinds of questions that can be answered by mining big data, let us now turn to the problems of data storage.