Chapter 6
Big data, big business
In the 1920s, J. Lyons and Co., a British catering firm famous for their ‘Corner House’ cafés, employed a young Cambridge University mathematician, John Simmons, to do statistical work. In 1947, Raymond Thompson and Oliver Standingford, both of whom had been recruited by Simmons, were sent on a fact-finding visit to the USA. It was on this visit that they first became aware of electronic computers and their potential for executing routine calculations. Simmons, impressed by their findings, sought to persuade Lyons to acquire a computer.
Collaboration with Maurice Wilkes, who was then engaged in building the Electronic Delay Storage Automatic Computer (EDSAC) at the University of Cambridge, resulted in the Lyons Electronic Office. This computer ran on punched cards and was first used by Lyons in 1951 for basic accounting tasks, such as adding up columns of figures. By 1954, Lyons had formed its own computer business and was building the LEO II, followed by the LEO III. Although the first office computers were being installed as early as the 1950s, given their use of valves (6,000 in the case of the LEO I) and magnetic tape, and their very small amount of RAM, these early machines were unreliable and their applications were limited. The original Lyons Electronic Office became widely referred to as the first business computer, paving the way for modern e-commerce and, after several mergers, finally became part of the newly formed International Computers Limited (ICL) in 1968.
e-Commerce
The LEO machines and the massive mainframe computers that followed were suitable only for the number-crunching tasks involved in such tasks as accounting and auditing. Workers who had traditionally spent their days tallying columns of figures now spent their time producing punched cards instead, a task no less tedious while requiring the same high degree of accuracy.
Since the use of computers became feasible for commercial enterprises, there has been interest in how they can be used to improve efficiency, cut costs, and generate profits. The development of the transistor and its use in commercially available computers resulted in ever-smaller machines, and in the early 1970s the first personal computers were being introduced. However, it was not until 1981, when International Business Machines (IBM) launched the IBM-PC on the market, with the use of floppy disks for data storage, that the idea really took off for business. The word-processing and spreadsheet capabilities of succeeding generations of PCs were largely responsible for relieving much of the drudgery of routine office work.
The technology that facilitated electronic data storage on floppy disks soon led to the idea that in future, businesses could be run effectively without the use of paper. In 1975 an article in the American magazine BusinessWeek speculated that the almost paper-free office would be a reality by 1990. The suggestion was that by eliminating or significantly reducing the use of paper, an office would become more efficient and costs would be reduced. Paper use in offices declined for a while in the 1980s when much of the paperwork that used to be found in filing cabinets was transferred to computers, but it then rose to an all-time high in 2007, with photocopies accounting for the majority of the increase. Since 2007, paper use has been gradually declining, thanks largely to the increased use of mobile smart devices and facilities such as the electronic signature.
Although the optimistic aspiration of the early digital age to make an office paperless has yet to be fulfilled, the office environment has been revolutionized by email, word-processing, and electronic spreadsheets. But it was the widespread adoption of the Internet that made e-commerce a practical proposition.
Online shopping is perhaps the most familiar example. As customers, we enjoy the convenience of shopping at home and avoiding time-consuming queues. The disadvantages to the customer are few but, depending on the type of transaction, the lack of contact with a store employee may inhibit the use of online purchasing. Increasingly, these problems are being overcome by online customer advice facilities such as ‘instant chat’, online reviews, and star rankings, a huge choice of goods and services together with generous return policies. As well as buying and paying for goods, we can now pay our bills, do our banking, buy airline tickets, and access a host of other services all online.
eBay works rather differently and is worth mentioning because of the huge amounts of data it generates. With transactions being made through sales and auction bids, eBay generates approximately 50 Tb of data a day, collected from every search, sale, and bid made on their website by a claimed 160 million active users in 190 countries. Using this data and the appropriate analytics they have now implemented recommender systems similar to those of Netflix, discussed later in this chapter.
Social networking sites provide businesses with instant feedback on everything from hotels and vacations to clothes, computers, and yoghurt. By using this information, businesses can see what works, how well it works, and what gives rise to complaints, while fixing problems before they get out of control. Even more valuable is the ability to predict what customers want to buy based on previous sales or website activity. Social networking sites such as Facebook and Twitter collect massive amounts of unstructured data that businesses can benefit from commercially given the appropriate analytics. Travel websites, such as TripAdvisor, also share information with third parties.
Pay-per-click advertising
Professionals are now increasingly acknowledging that appropriate use of big data can provide useful information and generate new customers through improved merchandising and use of better targeted advertising. Whenever we use the Web we are almost inevitably aware of online advertising and we may even post free advertisements ourselves on various bidding sites such as eBay.
One of the most popular kinds of advertising follows the pay-per-click model, which is a system by which relevant advertisements pop up when you are doing an online search. If a business wants their advertisement to be displayed in connection with a particular search term, they place a bid with the service provider on a keyword associated with that search term. They also declare a daily maximum budget. The adverts are displayed in order according to a system based in part on which advertiser has bid the highest for that term.
If you click on their advertisement, the advertiser then must pay the service provider what they bid. Businesses only pay when an interested party clicks on their advertisement, so these adverts must be a good match for the search term to make it more likely that a Web surfer will click on them. Sophisticated algorithms ensure that for the service provider, for example Google or Yahoo, revenue is maximized. The best known implementation of pay-per-click advertising is Google’s Adwords. When we search on Google the advertisements that automatically appear on the side of the screen are generated by Adwords. The downside is that clicks can be expensive, and there is also a limit on the number of characters you are allowed to use so that your advertisement will not take up too much space.
Click fraud is also a problem. For example, a rival company may click on your advertisement repeatedly in order to use up your daily budget. Or a malicious computer program, called a clickbot, may be used to generate clicks. The victim of this kind of fraud is the advertiser, since the service provider gets paid and no customers are involved. However, since it is in the best interests of providers to ensure security and so protect a lucrative business, considerable research effort is being made to counteract fraud. Probably the simplest method is to keep track of how many clicks are needed on average to generate a purchase. If this suddenly increases or if there are a large number of clicks and virtually no purchases then fraudulent clicking seems likely.
In contrast to pay-per-click arrangements, targeted advertising is based explicitly on each person’s online activity record. To see how this works, we’ll start by looking more closely at cookies, which I mentioned briefly in Chapter 1.
Cookies
This term first appeared in 1979 when the operating system UNIX ran a program called Fortune Cookie, which delivered random quotes to the users generated from a large database. Cookies come in several forms, all of which originate externally and are used to keep a record of some activity on a website and/or computer. When you visit a website, a message consisting of a small file that is stored on your computer is sent by a Web server to your browser. This message is one example of a cookie, but there are many other kinds, such as those used for user-authentication purposes and those used for third-party tracking.
Targeted advertising
Every click you make on the Internet is being collected and used for targeted advertising.
This user data is sent to third-party advertising networks and stored on your computer as a cookie. When you click on other sites supported by this network, advertisements for products you looked at previously will be displayed on your screen. Using Lightbeam, a free add-on to Mozilla Firefox, you can keep track of which companies are collecting your Internet activity data.
Recommender systems
Recommender systems provide a filtering mechanism by which information is provided to users based on their interests. Other types of recommender systems, not based on the users’ interests, show what other customers are looking at in real-time and often these will appear as ‘trending’. Netflix, Amazon, and Facebook are examples of businesses that use these systems.
A popular method for deciding what products to recommend to a customer is collaborative filtering. Generally speaking, the algorithm uses data collected on individual customers from their previous purchases and searches, and compares this to a large database of what other customers liked and disliked in order to make suitable recommendations for further purchasing. However, a simple comparison does not generally produce good results. Consider the following example.
Suppose an online bookstore sells a cookery book to a customer. It would be easy to subsequently recommend all cookery books, but this is unlikely to be successful in securing further purchases. There are far too many of them, and the customer already knows he or she likes cookery books. What is needed is a way of reducing the number of books to those that the customer might actually buy. Let’s look at three customers, Smith, Jones, and Brown, together with their book purchases (Figure 19).
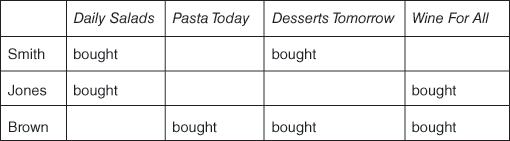
19. Books bought by Smith, Jones, and Brown.
The question for the recommender system is which book should be recommended to Smith and which recommended to Jones. We want to know if Smith is more likely to buy Pasta Today or Wine for All.
To do this we need to use a statistic that is often used for comparing sets and is called the Jaccard index. This is defined as the number of items the two sets have in common divided by the total number of distinct items in the two sets. The index measures the similarity between the two sets as the proportion they have in common. The Jaccard distance, defined as one minus the Jaccard index, measures the dissimilarity between them.
Looking again at Figure 19, we see that Smith and Jones have one book purchase in common, Daily Salads. Between them they have purchased three distinct books, Daily Salads, Desserts Tomorrow, and Wine for All. This gives them a Jaccard index of 1/3 and a Jaccard distance of 2/3. Figure 20 shows the calculation for all the possible pairs of customers.
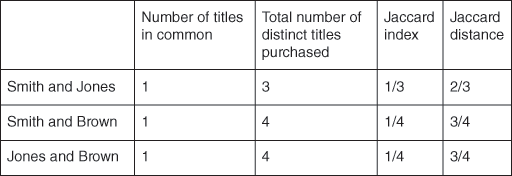
20. Jaccard index and distance.
Smith and Jones have a higher Jaccard index, or similarity score, than Smith and Brown. This means that Smith and Jones are closer in their purchasing habits—so we recommend Wine for All to Smith. What should we recommend to Jones? Smith and Jones have a higher Jaccard index than Jones and Brown, so we recommend Desserts Tomorrow to Jones.
Now suppose that customers rate purchases on a five-star system. To make use of this information we need to find other customers who gave the same rating to particular books and see what else they bought as well as considering their purchasing history. The star ratings for each purchase are given in Figure 21.
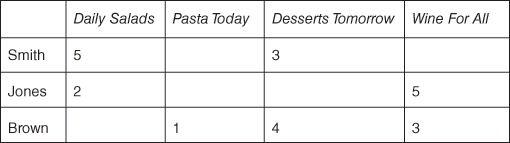
21. Star ratings for purchases.
In this example a different calculation, called the cosine similarity measure, which takes the star ratings into account, is described. For this calculation, the information given in the Star Ratings table is represented as vectors. The length or magnitude of the vectors is normalized to 1 and plays no further part in the calculations. The direction of the vectors is used as a way of finding how similar the two vectors are and so who has the best star rating. Based on the theory of vector spaces, a value for the cosine similarity between the two vectors is found. The calculation is rather different to the familiar trigonometry method, but the basic properties still hold with cosines taking values between 0 and 1. For example, if we find that the cosine similarity between two vectors, each representing a person’s star ratings, is 1 then the angle between them is 0 since cosine (0) = 1, and so they must coincide and we can conclude that they have identical tastes. The higher the value of the cosine similarity the greater the similarity in taste.
If you want to see the mathematical details, there are references in the Further reading section at the end of this VSI. What is interesting from our perspective is that the cosine similarity between Smith and Jones works out to be 0.350, and between Smith and Brown it is 0.404. This is a reversal of the previous result, indicating that Smith and Brown have tastes closer than those of Smith and Jones. Informally, this can be interpreted as Smith and Brown being closer in their opinion of Desserts Tomorrow than Smith and Jones were in their opinion of Daily Salads.
Netflix and Amazon, which we will look at in the next section, both use collaborative filtering algorithms.
Amazon
In 1994, Jeff Bezos founded Cadabra, but soon changed the name to Amazon and in 1995 Amazon.com was launched. Originally an online book store, it is now an international e-commerce company with over 304 million customers worldwide. It produces and sells a diverse range from electronic devices to books and even fresh food items such as yoghurt, milk, and eggs through Amazon Fresh. It is also a leading big data company, with Amazon Web Services providing Cloud-based big data solutions for business, using developments based on Hadoop.
Amazon collected data on what books were bought, what books a customer looked at but did not buy, how long they spent searching, how long they spent looking at a particular book, and whether or not the books they saved were translated into purchases. From this they could determine how much a customer spent on books monthly or annually, and determine whether they were regular customers. In the early days, the data Amazon collected was analysed using standard statistical techniques. Samples were taken of a person and, based on the similarities found, Amazon would offer customers more of the same. Taking this a step further, in 2001 researchers at Amazon applied for and were granted a patent on a technique called item-to-item collaborative filtering. This method finds similar items, not similar customers.
Amazon collects vast amounts of data including addresses, payment information, and details of everything an individual has ever looked at or bought from them. Amazon uses its data in order to encourage the customer to spend more money with them by trying to do as much of the customer’s market research as possible. In the case of books, for example, Amazon needs to provide not only a huge selection but to focus recommendations on the individual customer. If you subscribe to Amazon Prime, they also track your movie watching and reading habits. Many customers use smartphones with GPS capability, allowing Amazon to collect data showing time and location. This substantial amount of data is used to construct customer profiles allowing similar individuals and their recommendations to be matched.
Since 2013, Amazon has been selling customer metadata to advertisers in order to promote their Web services operation, resulting in huge growth. For Amazon Web Services, their Cloud computing platform, security is paramount and multi-faceted. Passwords, key-pairs, and digital signatures are just a few of the security techniques in place to ensure that clients’ accounts are available only to those with the correct authorization.
Amazon’s own data is similarly multi-protected and encrypted, using the AES (Advanced Encryption Standard) algorithm, for storage in dedicated data centres around the world, and Secure Socket Layer (SSL), the industry standard, is used for establishing a secure connection between two machines, such as a link between your home computer and Amazon.com.
Amazon is pioneering anticipatory shipping based on big data analytics. The idea is to use big data to anticipate what a customer will order. Initially the idea is to ship a product to a delivery hub before an order actually materializes. As a simple extension, a product can be shipped with a delighted customer receiving a free surprise package. Given Amazon’s returns policy, this is not a bad idea. It is anticipated that most customers will keep the items they do order since they are based on their personal preferences, found by using big data analytics. Amazon’s 2014 patent on anticipatory shipping also states that goodwill can be bought by sending a promotional gift. Goodwill, increased sales through targeted marketing, and reduced delivery times all make this what Amazon believes to be a worthwhile venture. Amazon also filed for a patent on autonomous flying drone delivery, called Prime Air. In September 2016, the US Federal Aviation Administration relaxed the rules for flying drones by commercial organizations, allowing them, in certain highly controlled situations, to fly beyond the line of sight of the operator. This could be the first stepping stone in Amazon’s quest to deliver packages within thirty minutes of an order being placed, perhaps leading to a drone delivery of milk after your smart refrigerator sensor has indicated that you are running out.
Amazon Go, located in Seattle, is a convenience food store and is the first of its kind with no checkout required. As of December 2016 it was only open to Amazon employees and plans for it to be available to the general public in January 2017 have been postponed. At present, the only technical details available are from the patent submitted two years ago, which describes a system eliminating the need to go through an item-by-item checkout. Instead, the details of a customer’s actual cart are automatically added to their virtual cart as they shop. Payment is made electronically as they leave the store through a transition area, as long as they have an Amazon account and a smartphone with the Amazon Go app. The Go system is based on a series of sensors, a great many of them, used to identify when an item is taken from or returned to a shelf.
This will generate a huge amount of commercially useful data for Amazon. Clearly, since every shopping action made between entering and leaving the store is logged, Amazon will be able to use this data to make recommendations for your next visit in a way similar to their online recommendation system. However, there may well be issues about how much we value our privacy, especially given aspects such as the possibility mentioned in the patent application of using facial recognition systems to identify customers.
Netflix
Another Silicon Valley company, Netflix, started in 1997 as a postal DVD rental company. You took out a DVD and added another to your queue, and they would then be sent out in turn. Rather usefully, you had the ability to prioritize your queue. This service is still available and still lucrative, though it appears to be gradually winding down. Now an international, Internet streaming, media provider with approximately seventy-five million subscribers across 190 different countries, in 2015 Netflix successfully expanded into providing its own original programmes.
Netflix collects and uses huge amounts of data to improve customer service, such as offering recommendations to individual customers while endeavouring to provide reliable streaming of its movies. Recommendation is at the heart of the Netflix business model and most of its business is driven by the data-based recommendations it is able to offer customers. Netflix now tracks what you watch, what you browse, what you search for, and the day and time you do all these things. It also records whether you are using an iPad, TV, or something else.
In 2006, Netflix announced a crowdsourcing competition aimed at improving their recommender systems. They were offering a $1 million prize for a collaborative filtering algorithm that would improve by 10 per cent the prediction accuracy of user movie ratings. Netflix provided the training data, over 100 million items, for this machine learning and data mining competition—and no other sources could be used. Netflix offered an interim prize (the Progress Prize) worth $50,000, which was won by the Korbell team in 2007 for solving a related but somewhat easier problem. Easier is a relative term here, since their solution combined 107 different algorithms to come up with two final algorithms, which, with ongoing development, are still being used by Netflix. These algorithms were gauged to cope with 100 million ratings as opposed to the five billion that the full prize algorithm would have had to be able to manage. The full prize was eventually awarded in 2009 to the BellKor’s Pragmatic Chaos team whose algorithm represented a 10.06 per cent improvement over the existing one. Netflix never fully implemented the winning algorithm, primarily because by this time their business model had changed to the now-familiar one of media streaming.
Once Netflix expanded their business model from a postal service to providing movies by streaming, they were able to gather a lot more information on their customers’ preferences and viewing habits, which in turn enabled them to provide improved recommendations. However, in a departure from the digital modality, Netflix employs part-time taggers, a total of about forty people worldwide who watch movies and tag the content, labelling them as, for example, ‘science fiction’ or ‘comedy’. This is how films get categorized—using human judgement and not a computer algorithm initially; that comes later.
Netflix uses a wide range of recommender algorithms that together make up a recommender system. All these algorithms act on the aggregated big data collected by the company. Content-based filtering, for example, analyses the data reported by the ‘taggers’ and finds similar movies and TV programmes according to criteria such as genre and actor. Collaborative filtering monitors such things as your viewing and search habits. Recommendations are based on what viewers with similar profiles watched. This was less successful when a user account has more than one user, typically several members of a family, with inevitably different tastes and viewing habits. In order to overcome this problem, Netflix created the option of multiple profiles within each account.
On-demand Internet TV is another area of growth for Netflix and the use of big data analytics will become increasingly important as they continue to develop their activities. As well as collecting search data and star ratings, Netflix can now keep records on how often users pause or fast forward, and whether or not they finish watching each programme they start. They also monitor how, when, and where they watched the programme, and a host of other variables too numerous to mention. Using big data analytics we are told that they are now even able to predict quite accurately whether a customer will cancel their subscription.
Data science
‘Data scientist’ is the generic title given to those who work in the field of big data. The McKinsey Report of 2012 highlighted the lack of data scientists in the USA alone, estimating that by 2018 the shortage would reach 190,000. The trend is apparent worldwide and even with government initiatives promoting data science skills training, the gap between available and required expertise seems to be widening. Data science is becoming a popular study option in universities but graduates so far have been unable to meet the demands of commerce and industry, where positions in data science offer high salaries to experienced applicants. Big data for commercial enterprises is concerned with profit, and disillusionment will set in quickly if an over-burdened data analyst with insufficient experience fails to deliver the expected positive results. All too often, firms are asking for a one-size-fits-all model of data scientist who is expected to be competent in everything from statistical analysis to data storage and data security.
Data security is of crucial importance to any firm and big data creates its own security issues. In 2016, the Netflix Prize 2 initiative was cancelled because of data security concerns. Other recent data hacks include Adobe in 2013, eBay and JP Morgan Chase Bank in 2014, Anthem (a US health insurance company) and Carphone Warehouse in 2015, MySpace in 2016, and LinkedIn—a 2012 hack not discovered until 2016. This is a small sample; many more companies have been hacked or suffered other types of security breaches leading to the unauthorized dissemination of sensitive data. In Chapter 7, we will look at some of the big data security breaches in depth.