The first iteration of our script focuses on performing the task at hand with a standard module, sqlite3, in a more manual fashion. This entails writing out each SQL statement and executing them as if you were working with the database itself. Although this is not a very Pythonic manner of handling a database, it demonstrates the methods that are used to interact with a database with Python. Our second iteration employs two third-party libraries: peewee and jinja2.
Peewee is an object-relational mapper (ORM), which is a term that's used to describe a software suite that uses objects to handle database operations. In short, this ORM allows the developer to call functions and define classes in Python that are interpreted as database commands. This layer of abstraction helps to standardize database calls and allows for multiple database backends to be easily interchanged. Peewee is a light ORM, as it is a single Python file that supports PostgreSQL, MySQL, and SQLite3 database connections. If we needed to switch our second script from SQLite3 to PostgreSQL, it would only require that we modify a few lines of code; our first script would require more attention to handle this same conversion. This being said, our first version does not require any dependencies beyond the standard Python installation for SQLite3 support, an attractive feature for tools that are designed to be portable and flexible while in the field.
Our file_lister.py script is a per-custodian metadata collection and reporting script. This is important in incident response or the discovery phase of an investigation, as it stores information about active files on a system or in a specified directory by custodian name. A custodian assignment system allows for multiple machines, directory paths, or network shares to be indexed and categorized by a single custodian name, regardless of whether the custodian is a user, machine, or device. To implement this system, we need to prompt the user for the custodian name, the path of the database to use, and the input or output information.
By allowing the examiner to add multiple custodians or paths into the same database, they can append to the files that have been found for a single custodian or add in as many custodians as they please. This is helpful in collections as the investigator can preserve as few or as many paths as they need, as we all know how unexpected devices show up once we are in the field. In addition, we can use the same script to create file listing reports, regardless of the number of collected files or custodians, as long as the custodian has at least one collected file.
In our design state, we don't only take into account our script but also the database and the relational model we will use. In our case, we are handling two separate items: custodians and files. These both make for good tables, as they are separate entries that share a common relation. In our scenario, a file has a custodian and a custodian may have one or more files; therefore, we will want to create a foreign key, relating files to a specific custodian. A foreign key is a reference to a primary key in another table. The primary key and the foreign key references are usually a unique value or an index that links the data together.
The following diagram represents the relational model for our database. We have two tables, custodians and files, and a one-to-many relationship between them. As defined earlier, this one-to-many relationship will allow us to assign many files to a single custodian. Using this relationship, we can ensure that our script will properly assign information in a structured and easy-to-manage manner:
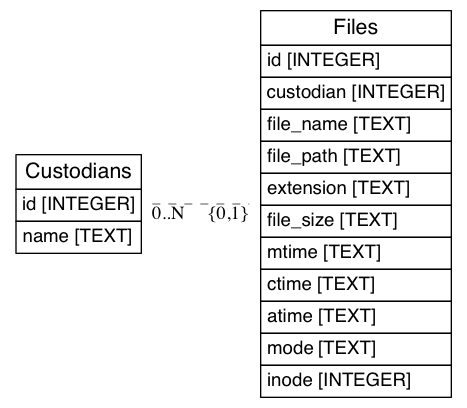
In this relational model, for example, we could have a custodian named JPriest who owns files located in a folder named APB/. Under this root folder, there are 40,000 files spread among 300 subdirectories, and we need to assign each of those 40,000 files to JPriest. Because custodian names may be long or complex, we want to assign JPriest an identifier, such as the integer 5, and write that to each row of the data being stored in the Files table. By doing this, we accomplish three things:
- We are saving space as we are storing only one character (5) instead of seven (JPriest) in each of the 40,000 rows
- We are maintaining a link between the JPriest user and their files
- If we ever needed to rename JPriest, we could change one row in our Custodians table and therefore update the custodian's name for all associated rows