As a note, this script will be designed to work only in Python 3 and was tested with Python 3.7.1. If you'd like the Python 2 version of the code after working through this section, please see https://github.com/PacktPublishing/Learning-Python-for-Forensics for the prior iteration.
In the first iteration of the script, we use several standard libraries to complete all of the functionality required for the full operation. Like we did in prior scripts, we are implementing argparse, csv, and logging for their usual purposes, which include argument handling, writing CSV reports, and logging program execution. For logging, we define our log handler, logger, on line 43. We have imported the sqlite3 module to handle all database operations. Unlike our next iteration, we will only support SQLite databases through this script. The os module allows us to recursively step through files in a directory and any subdirectories. Finally, the sys module allows us to gather logging information about the system, and the datetime module is used to format timestamps as we encounter them on the system. This script does not require any third-party libraries. We have the following code:
001 """File metadata capture and reporting utility."""
002 import argparse
003 import csv
004 import datetime
005 import logging
006 import os
007 import sqlite3
008 import sys
...
038 __authors__ = ["Chapin Bryce", "Preston Miller"]
039 __date__ = 20181027
040 __description__ = '''This script uses a database to ingest and
041 report meta data information about active entries in
042 directories.'''
043 logger = logging.getLogger(__name__)
Following our import statements, we have our main() function, which takes the following user inputs: custodian name, target input directory or output file, and a path to the database to use. The main() function handles some high-level operations, such as adding and managing custodians, error handling, and logging. It first initializes the database and tables, and then checks whether the custodian is in the database. If it is not, that custodian is added to the database. The function allows us to handle the two possible run options: to recursively ingest the base directory, capturing all subobjects and their metadata, and to read the captured information from the database into a report using our writer functions.
The init_db() function, which is called by main(), creates the database and default tables if they do not exist. The get_or_add_custodian() function, in a similar manner, checks to see whether a custodian exists. If it does, it returns the ID of the custodian, otherwise it creates the custodian table. To ensure that the custodian is in the database, the get_or_add_custodian() function is run again after a new entry is added.
After the database has been created and the custodian table exists, the code checks whether the source is an input directory. If so, it calls ingest_directory() to iterate through the specified directory and scan all subdirectories to collect file-related metadata. Captured metadata is stored in the Files table of the database with a foreign key to the Custodians table to tie each custodian to their file(s). During the collection of metadata, we call the format_timestamp() function to cast our collected timestamps into a standard string format.
If the source is an output file, the write_output() function is called, passing the open database cursor, output file path, and custodian name as arguments. The script then determines whether the custodian has any responsive results in the Files table and passes them to the write_html() or write_csv() function, based on the output file path's extension. If the extension is .html, then the write_html() function is called to create an HTML table using Bootstrap CSS, which displays all of the responsive results for the custodian. Otherwise, if the extension is .csv, then the write_csv() function is called to write the data to a comma-delimited file. If neither of the extensions is supplied in the output file path, then a report is not generated and an error is raised that the file type could not be interpreted:
046 def main(custodian, target, db):
...
081 def init_db(db_path):
...
111 def get_or_add_custodian(conn, custodian):
...
132 def get_custodian(conn, custodian):
...
148 def ingest_directory(conn, target, custodian_id):
...
207 def format_timestamp(timestamp):
...
219 def write_output(conn, target, custodian):
...
254 def write_csv(conn, target, custodian_id):
...
280 def write_html(conn, target, custodian_id, custodian_name):
Now, let's look at the required arguments and the setup for this script. On lines 321 through 339, we build out the argparse command-line interface with the required positional arguments CUSTODIAN and DB_PATH, and the optional arguments --input, --output, and -l:
320 if __name__ == '__main__':
321 parser = argparse.ArgumentParser(
322 description=__description__,
323 epilog='Built by {}. Version {}'.format(
324 ", ".join(__authors__), __date__),
325 formatter_class=argparse.ArgumentDefaultsHelpFormatter
326 )
327 parser.add_argument(
328 'CUSTODIAN', help='Name of custodian collection is of.')
329 parser.add_argument(
330 'DB_PATH', help='File path and name of database to '
331 'create or append metadata to.')
332 parser.add_argument(
333 '--input', help='Base directory to scan.')
334 parser.add_argument(
335 '--output', help='Output file to write to. use `.csv` '
336 'extension for CSV and `.html` for HTML')
337 parser.add_argument(
338 '-l', help='File path and name of log file.')
339 args = parser.parse_args()
On lines 341 through 347, we check that either the --input or --output argument was supplied by the user. We create a variable, arg_source, which is a tuple containing the mode of operation and the corresponding path specified by the argument. If neither of the mode arguments were supplied, an ArgumentError is raised and prompts the user for an input or output. This ensures that the user provides the required arguments when there are one or more options:
341 if args.input:
342 arg_source = ('input', args.input)
343 elif args.output:
344 arg_source = ('output', args.output)
345 else:
346 raise argparse.ArgumentError(
347 'Please specify input or output')
On lines 349 through 368, we can see the log configuration that we used in previous chapters and check for the -l argument, making a path to the log if necessary. We also log the script version and the operating system information on lines 366 through 368:
349 if args.l:
350 if not os.path.exists(args.l):
351 os.makedirs(args.l) # create log directory path
352 log_path = os.path.join(args.l, 'file_lister.log')
353 else:
354 log_path = 'file_lister.log'
355
356 logger.setLevel(logging.DEBUG)
357 msg_fmt = logging.Formatter("%(asctime)-15s %(funcName)-20s"
358 "%(levelname)-8s %(message)s")
359 strhndl = logging.StreamHandler(sys.stdout)
360 strhndl.setFormatter(fmt=msg_fmt)
361 fhndl = logging.FileHandler(log_path, mode='a')
362 fhndl.setFormatter(fmt=msg_fmt)
363 logger.addHandler(strhndl)
364 logger.addHandler(fhndl)
365
366 logger.info('Starting File Lister v.' + str(__date__))
367 logger.debug('System ' + sys.platform)
368 logger.debug('Version ' + sys.version)
With the logging squared away, we can create a dictionary, which defines the arguments passed into the main() function using kwargs. Kwargs, or keyword arguments, provide a means of passing arguments as dictionary key-value pairs, where the keys match the parameter name and are assigned a corresponding value. To pass a dictionary to a function or class as kwargs instead of a value, we must specify two asterisks preceding the dictionary name, as seen on line 373. If we did not use kwargs, we would have needed to pass the args.custodian, arg_source, and args.db_path arguments as individual positional arguments. There is more advanced functionality with kwargs, and examples of this can be found at https://docs.python.org/3.7/faq/programming.html. We have the following code:
370 args_dict = {'custodian': args.CUSTODIAN,
371 'target': arg_source, 'db': args.DB_PATH}
372
373 main(**args_dict)
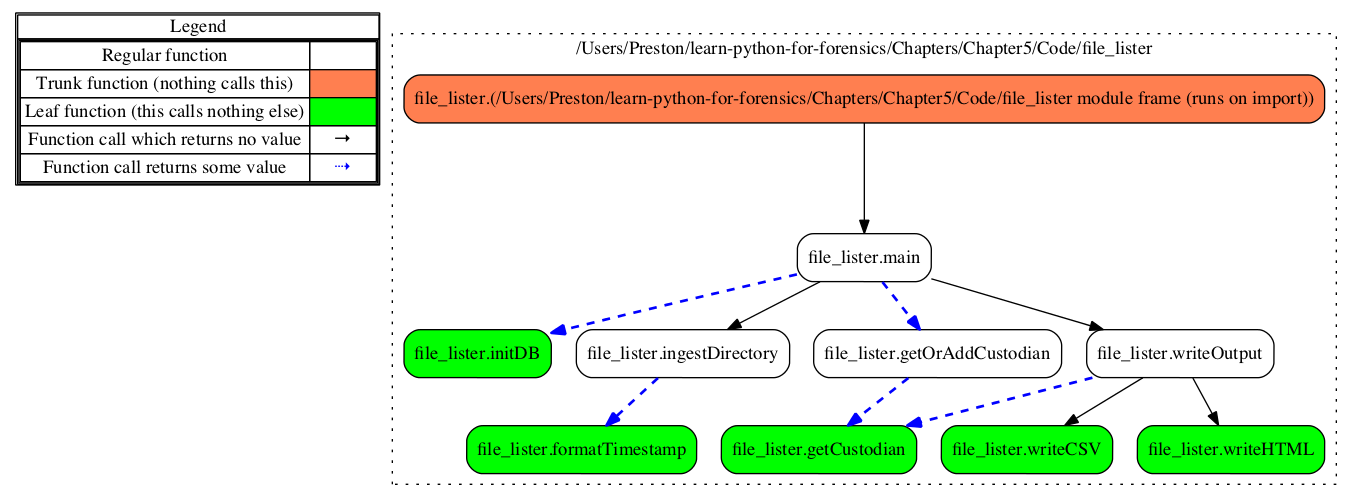
Refer to the following flowchart to understand how each function is linked together: