Our framework takes some input directory, recursively indexes all of its files, runs a series of plugins to identify forensic artifacts, and then writes a series of reports into a specified output directory. The idea is that the examiner could mount a .E01 or .dd file using a tool such as FTK Imager and then run the framework against the mounted directory.
The layout of a framework is an important first step in achieving a simplistic design. We recommend placing writers and plugins in appropriately labeled subdirectories under the framework controller. Our framework is laid out in the following manner:
|-- framework.py
|-- requirements.txt
|-- plugins
|-- __init__.py
|-- exif.py
|-- id3.py
|-- office.py
|-- pst_indexer.py
|-- setupapi.py
|-- userassist.py
|-- wal_crawler.py
|-- helper
|-- __init__.py
|-- utility.py
|-- usb_lookup.py
|-- writers
|-- __init__.py
|-- csv_writer.py
|-- xlsx_writer.py
|-- kml_writer.py
Our framework.py script contains the main logic of our framework-handling the input and output values for all of our plugins. The requirements.txt file contains one third-party module on each line used by the framework. In this format, we can use this file with pip to install all of the listed modules. pip will attempts to install the latest version of the module unless a version is specified immediately following the module name and two equal to signs (that is, colorama==0.4.1). We can install third-party modules from our requirements.txt file using the following code:
pip install -r requirements.txt
The plugins and writers are stored in their own respective directories with an __init__.py file to ensure that Python can find the directory. Within the plugins directory are seven initial plugins our framework will support. The plugins we'll include are as follows:
- The EXIF, ID3, and Office embedded metadata parsers from Chapter 8, The Media Age
- The PST parser from Chapter 11, Parsing Outlook PST Containers
- The Setupapi parser from Chapter 3, Parsing Text Files
- The UserAssist parser from Chapter 6, Extracting Artifacts from Binary Files
- The WAL file parser from Chapter 12, Recovering Transient Database Records
There's also a helper directory containing some helper scripts that are required by some of the plugins. There are currently three supported output formats for our framework: CSV, XLSX, and KML. Only the exif plugin will make use of kml_writer to create a Google Earth map with plotted EXIF GPS data, as we saw in Chapter 8, The Media Age.
Now that we understand the how, why, and layout of our framework, let's dig into some code. On lines 2 through 11, we import the modules we plan to use. Note that this is only the list of modules that are required in this immediate script. It doesn't include the dependencies required by the various plugins. Plugin-specific imports are made in their respective scripts.
Most of these imports should look familiar from the previous chapters, with the exception of the new additions of colorama and pyfiglet. On lines 7 and 8, we import our plugins and writers subdirectories, which contain the scripts for our plugins and writers. The colorama.init() call on line 13 is a prerequisite that allows us to print colored text to the Windows Command Prompt:
002 from __future__ import print_function
003 import os
004 import sys
005 import logging
006 import argparse
007 import plugins
008 import writers
009 import colorama
010 from datetime import datetime
011 from pyfiglet import Figlet
012
013 colorama.init()
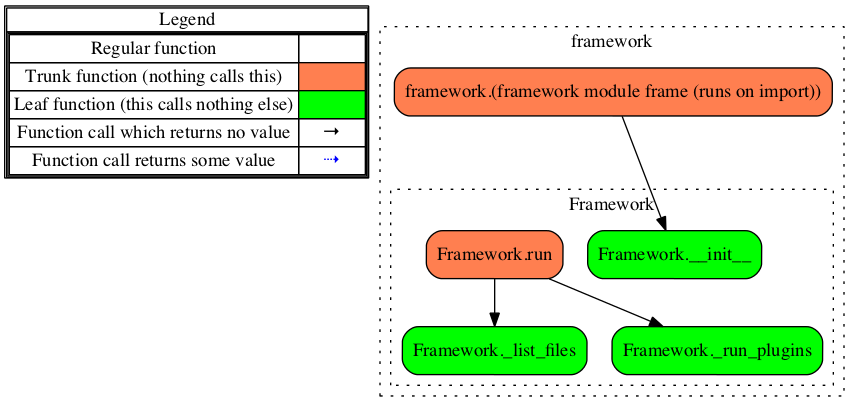
On line 49, we define our Framework class. This class will contain a variety of methods, all of which handle the initialization and execution of the framework. The run() method acts as our typical main function and calls the _list_files() and _run_plugins() methods. The _list_files() method walks through files in the user-supplied directory and, based upon the name or extension, adds the file to a plugin-specific processing list. Then, the _run_plugins() method takes these lists and executes each plugin, stores the results, and calls the appropriate writer:
049 class Framework(object):
...
051 def __init__():
...
061 def run():
...
074 def _list_files():
...
115 def _run_plugins():
Within the Framework class are two subclasses: Plugin and Writer. The Plugin class is responsible for actually running the plugin, logging when it completes, and sending data to be written. The run() method repeatedly executes each function for every file in the plugin's processing list. It appends the returned data to a list, mapped to the key in a dictionary. This dictionary also stores the desired field names for the spreadsheet. The write() method creates the plugin specific output directory and, based on the type of output specified, makes appropriate calls to the Writer class:
207 class Plugin(object):
...
209 def __init__():
...
215 def run():
...
236 def write():
The Writer class is the simplest class of the three. Its run() method simply executes the desired writers with the correct input:
258 class Writer(object):
...
260 def __init__():
...
271 def run():
As with all of our scripts, we use argparse to handle command-line switches. On lines 285 and 287, we create two positional arguments for our input and output directories. The two optional arguments on lines 288 and 290 specify XLSX output and the desired log path, respectively:
279 if __name__ == '__main__':
280
281 parser = argparse.ArgumentParser(description=__description__,
282 epilog='Developed by ' +
283 __author__ + ' on ' +
284 __date__)
285 parser.add_argument('INPUT_DIR',
286 help='Base directory to process.')
287 parser.add_argument('OUTPUT_DIR', help='Output directory.')
288 parser.add_argument('-x', help='Excel output (Default CSV)',
289 action='store_true')
290 parser.add_argument('-l',
291 help='File path and name of log file.')
292 args = parser.parse_args()
We can see our first use of the colorama library on line 297. If the supplied input and output directories are files, we print a red error message to the console. For the rest of our framework, we use error messages displayed in red text and success messages in green:
294 if(os.path.isfile(args.INPUT_DIR) or
295 os.path.isfile(args.OUTPUT_DIR)):
296 msg = 'Input and Output arguments must be directories.'
297 print(colorama.Fore.RED + '[-]', msg)
298 sys.exit(1)
On line 300, we check whether the optional directory path was supplied for the log file. If so, we create these directories (if they don't exist), and store the filename for the log in the log_path variable:
300 if args.l:
301 if not os.path.exists(args.l):
302 os.makedirs(args.l) # create log directory path
303 log_path = os.path.join(args.l, 'framework.log')
304 else:
305 log_path = 'framework.log'
On lines 307 and 309, we create our Framework object and then call its run() method. We pass the following arguments into the Framework constructor to instantiate the object: INPUT_DIR, OUTPUT_DIR, log_path, and excel. In the next section, we inspect the Framework class in greater detail:
307 framework = Framework(args.INPUT_DIR, args.OUTPUT_DIR,
308 log_path, excel=args.x)
309 framework.run()
The following flow chart highlights how the different methods in the framework.py script interact. Keep in mind that this flow chart only shows interactions within the immediate script and doesn't account for the various plugin, writer, and utility scripts: