Before creating any Data Factory artifacts, such as datasets and pipelines, it is a good idea to set up the code repository for hosting files related to Data Factory:
- Click on the Data Factory dropdown from the top menu:
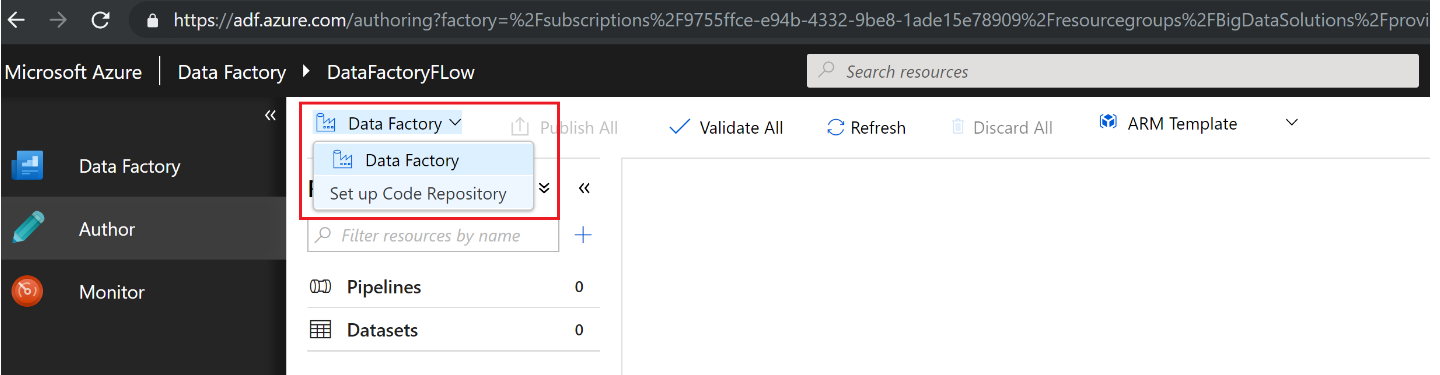
- From the resultant blade, select any one of the repositories that you would like to store Data Factory code files in. In this case, GitHub is selected:
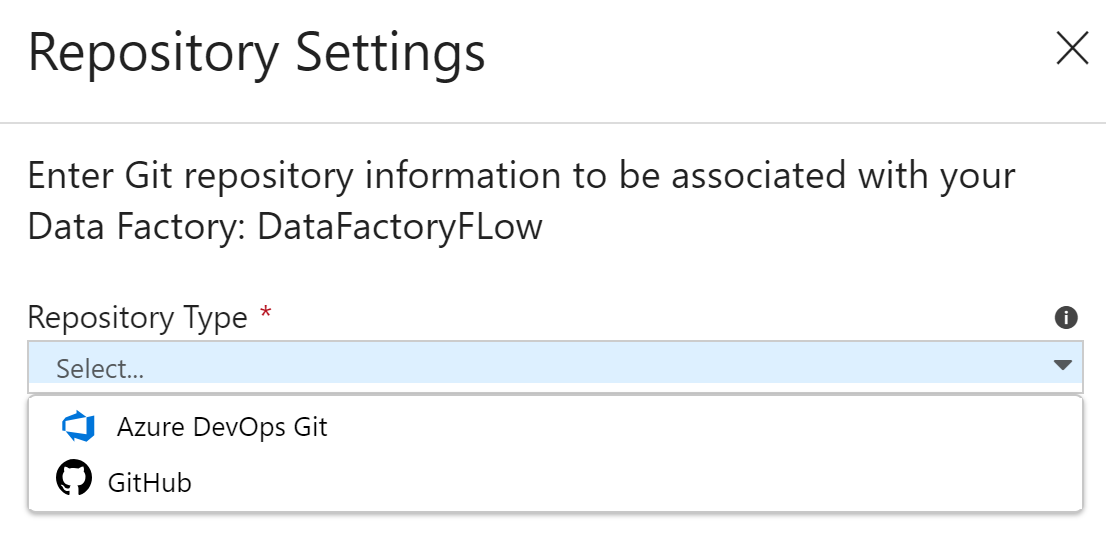
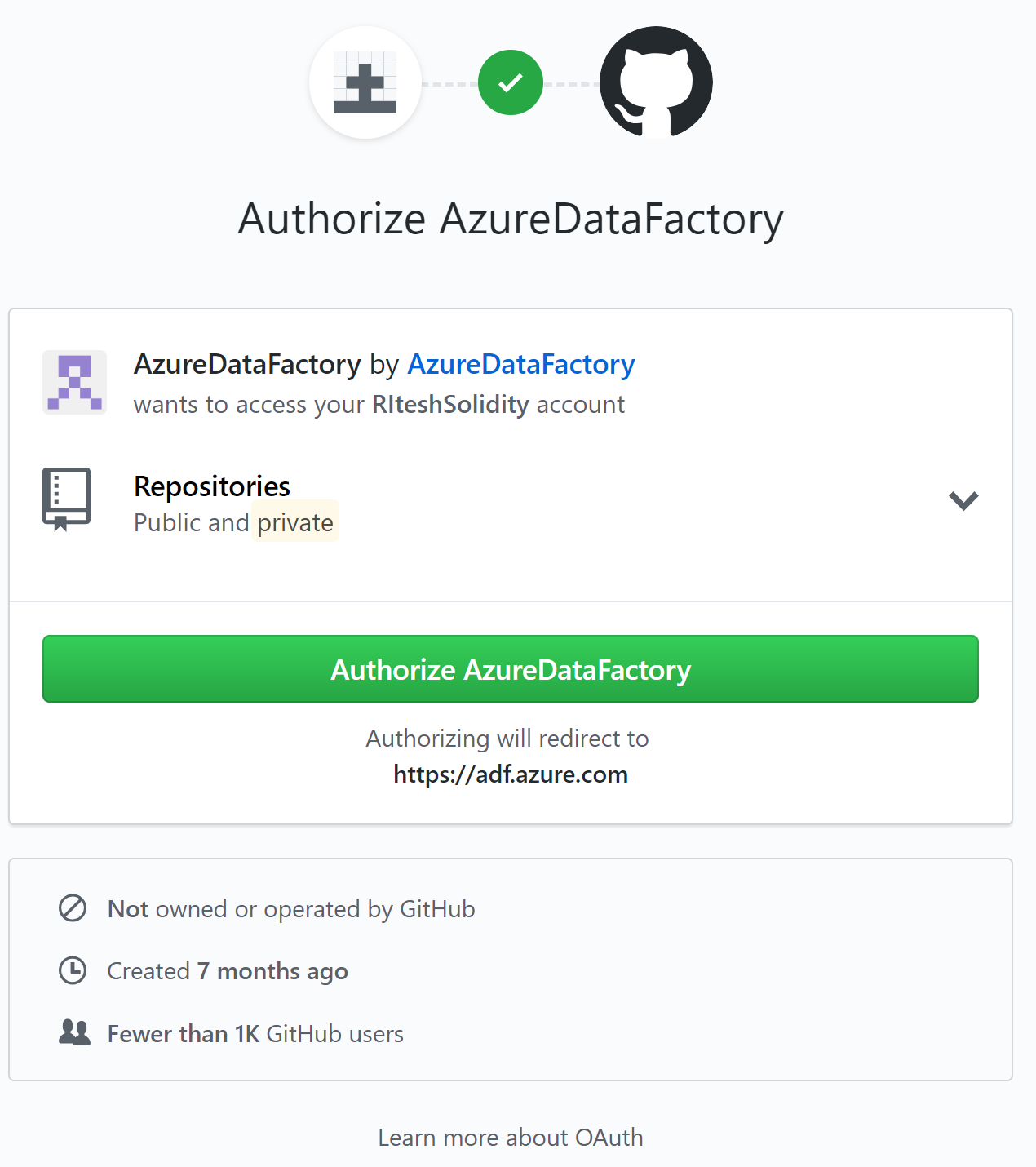
- It will ask for authorization to the GitHub account.
- Log into GitHub with your credentials and provide permissions to the Azure Data Factory service:
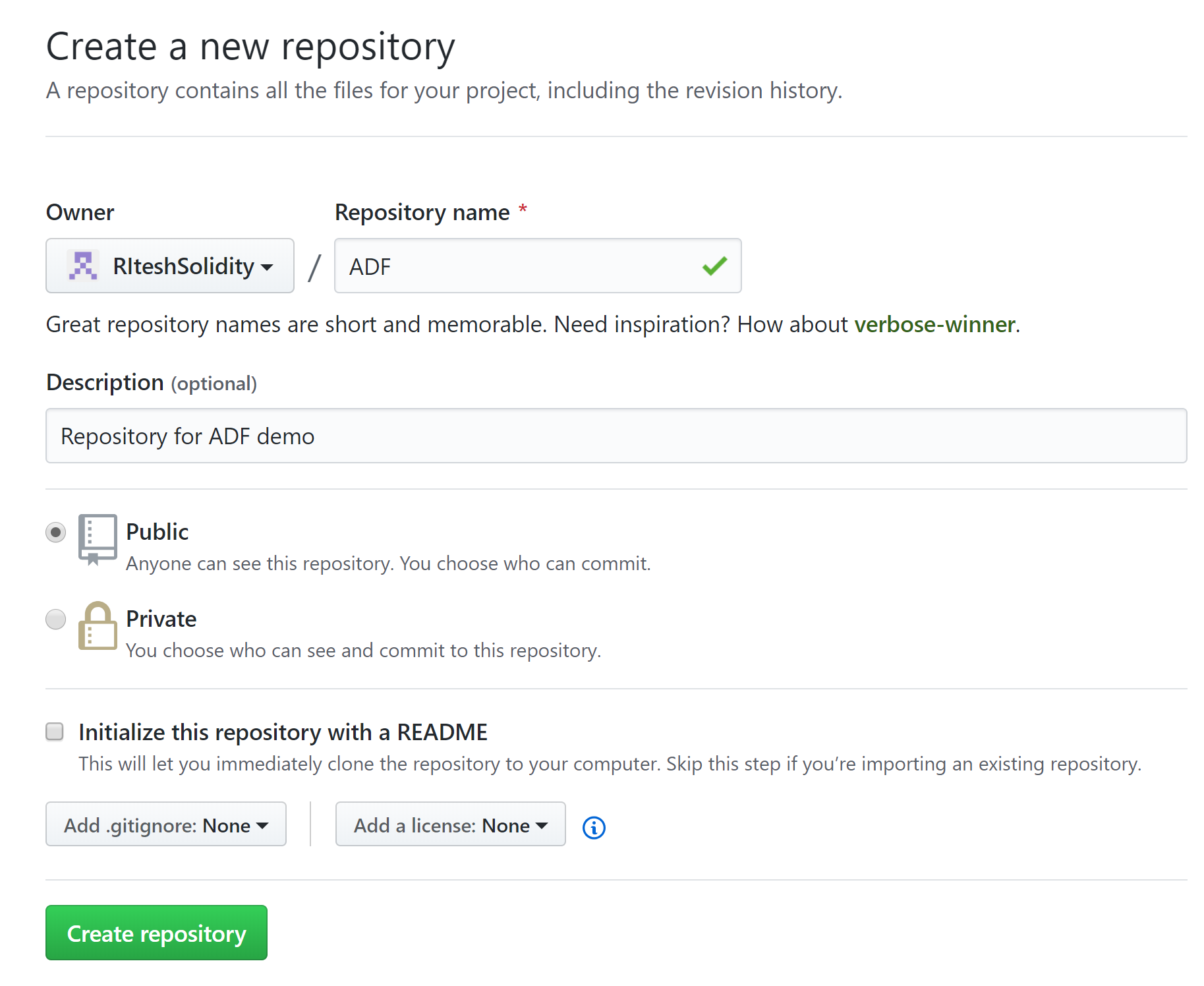
- Create or reuse an existing repository from GitHub. In our case, we are creating a new repository named ADF. If you are creating a new repository, ensure that it is already initialized, otherwise the Data Factory repository setting will complain:
- Now we can move back to the Data Factory pipeline window and ensure that the repository settings are appropriate, including the repository name, collaboration branch, root folder, and branch, which will act as the main branch:
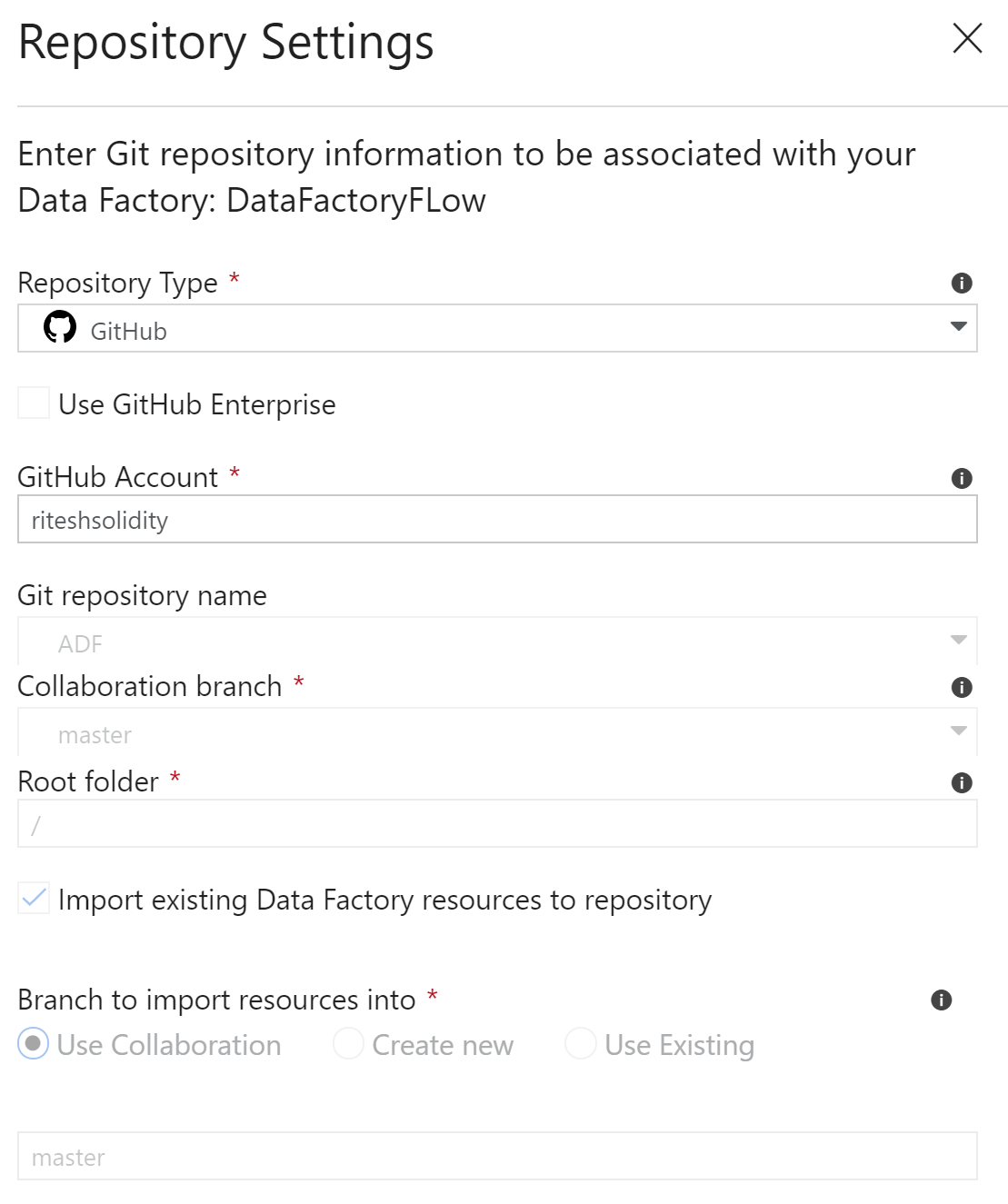
- On the next screen, create a new branch on which developers will be working. In our case, a new development branch is created:
