Laying the Groundwork
Abstract
Although the cloud is a group of services, not technologies, the rapid growth it has experienced would not have been possible without the right technologies. Many different technologies go into making the cloud happen. In this chapter, we review some of these technologies and the role they have played in making the cloud viable.
Keywords
virtualization; utility; distributed; authentication; federated; SOAP; REST; identity; IdP; provider; HTML; JBOSS; JSON; Ruby; Java; JavaScript; ACS; factor; PHP; ASP; public; private
Chapter Points
Introduction
The cloud is about services, but there are a number of technology components that come together to make it possible. These technologies and technology advances are responsible for the rapid growth of the cloud and the availability of cloud applications.
We won’t get into too much depth in discussing the technologies, but it’s important that you have a general understanding of them. When you have to make decisions about which cloud providers and cloud products you want to consume, it’s beneficial if you can distinguish between these technologies and what they offer.
Authentication
Authentication is the process of verifying that users are who they say they are. Before you can access resources on most systems, you have to first authenticate yourself. Anytime sensitive information is involved or anytime auditing needs to be performed, you have to make sure the person performing an action is who they say they are. If you don’t, you can’t really trust that person or the information they provide. Many different methods can be used to authenticate someone or something. It’s important that you pick the right authentication method for a given situation.
Authentication is an important part of any environment. The cloud is no exception. In fact, in some aspects, authentication is even more important in a public cloud environment than in a traditional environment. Authentication is the primary method for restricting access to applications and data. Since public cloud applications are available via the Web, they can theoretically be accessed by anyone. For this reason, service providers need to ensure that they take the appropriate precautions to protect applications and user data. This process begins with ensuring that the appropriate authentication methods are in place.
Similarly, when you evaluate cloud providers, you need to ensure that they have the appropriate authentication measures in place. The information is this section will help you make that determination. We start by going over some general background information on authentication and authorization; then we move on to identity providers and federated authentication.
Identification vs. Verification
When you look at the issue of authentication, you can break it down into two components: identification and verification. Identification is the process of you stating who you are. This statement could be in the form of a username, an email address, or some other method that identifies you. Basically, you are saying, “I am drountree” or “I am derrick@gmail.com,” and “I want access to the resources that are available to me.”
But how does the system know that you really are drountree? The system can’t just give access to anyone who claims to be drountree. This is where verification comes in. Verification is the process that a system goes through to check that you are indeed who you say you are. This is what most people think of when they think of authentication. They don’t realize that the first part of the process is that you first have to make a statement about who you are. Verification can be performed in many ways. You supply a password or a personal information number (PIN) or use some type of biometric identifier.
Think about it this way: You know that when you attempt to authenticate to a system and you enter your username and password, the system will check to see if the combination is right. You must have entered the correct password that corresponds to the username you entered. If one or the other is wrong, the authentication attempt fails. The system will first check to see that the username you entered is a valid username. If it isn’t, then an error message will immediately be returned. If is the username is valid, then system checks the password. A correct combination of the username and password is needed for successful authentication.
Authorization
After users have been authenticated, authorization begins. Authorization is the process of specifying what a user is allowed to do. Authorization is not just about systems and system access. Authorization is any right or ability a user has anywhere.
Every organization should have a security policy that specifies who is allowed to access which resources and what they are allowed to do with these resources. Authorization policies can be affected by anything from privacy concerns to regulatory compliance. It’s important that the systems you have in place are able to enforce the authorization policy of your organization; this includes public cloud-based systems.
Advanced Authentication Methods
In securing your data applications, simple username and password authentication may not be sufficient. You should take extra care in situations where the identity of the person making a request may be especially questioned, such as external requests to internal systems. Public cloud systems can also present a heightened risk. Since your public cloud applications and data are freely available over the Internet, you might want to look to a provider that offers advanced authentication methods to secure them. Let’s look at two commonly used methods: multifactor authentication and risk-based authentication.
Multifactor authentication
One method for ensuring proper authentication security is the use of multifactor authentication. Multifactor authentication gets its name from the use of multiple authentication factors. You can think of a factor as a category of authentication. There are three authentication factors that can be used: something you know, something you have, and something you are. Something you know would be a password, a birthday, or some other personal information. Something you have would be a one-time use token, a smartcard, or some other artifact that you might have in your physical possession. Something you are would be your biometric identity, like a fingerprint or a speech pattern. In order for something be considered multifactor authentication, it must make use of at least two of the three factors mentioned. For example, when a user attempts to authenticate, he or she may have to enter both their password and a one-time use token code.
Multifactor authentication is being offered by an increasing number of service providers, especially those that store sensitive data. Often this advanced functionality is not advertised prominently by cloud providers. So, if you feel that multifactor authentication is necessary in your deployment, you should ask the provider about it.
Risk-based authentication
Risk-based authentication has just started to gain popularity. Risk-based authentication actually came about because of the increased risk facing public applications and Web sites. Risk-based authentication uses a risk profile to determine whether the authentication request could be suspect. Each authentication attempt is given a risk score. If the risk score exceeds a certain value, the Web site or service provider can request additional information before allowing access. This additional information could be in the form of security questions or an additional authentication factor.
A risk is calculated based on user and system characteristics. The site will create a profile for each user based on information such as usual login time, system used to access the site, or access method. When a user attempts to access the site and their current usage characteristics do not match their profile, their current risk score would reflect the variation.
Risk-based authentication has become very popular for banking and financial sites. But, like multifactor authentication, risk-based authentication may not be advertised, so you should ask the cloud provider if they can supply it.
Identity Providers
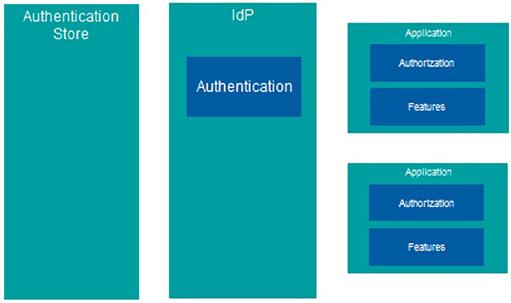
In the authentication arena, there is a particular service provider called an identity provider. An identity provider, or IdP, is an entity that holds identity information. You can have an IdP set up internally, or you can use a service provider. Users, also called entities, authenticate against the IdP’s credential store. The IdP then allows access to the user’s identity information. It’s important to note that an IdP does more than just authenticate a user. It holds the user’s identity information. Upon authentication, this information can be sent to whomever needs it. Generally, this will be a service provider, also referred to as the relying party. This is because the service providers rely on the IdP for authentication and identity information.
Credential Store
The credential store, sometimes called the user store or the authentication store, is where the actual user credentials are stored. Two main types of authentication stores are being used with IdPs today: databases and directory stores. In general, with databases, credentials are stored in proprietary tables created by the user management application. One of the reasons databases are often chosen as credential stores is because a majority of developers have experience coding against a database, so it’s relatively easy for them to write code to authenticate users. Directory stores include Lightweight Directory Access Protocol (LDAP) stores and Active Directory (AD) implementations. LDAP provides a simple standards-based approach to accessing information from the credential store. Active Directory is Microsoft’s domain-based approach to LDAP. Using an AD credential store generally requires that you use proprietary access methods. Many cloud service providers are now offering the option to use your internal credential store instead of their third-party store. This way, users don’t have to remember multiple sets of credentials.
To help you understand the concept a little better, refer to Figures 2.1 and 2.2. Figure 2.1 shows a traditional authentication architecture where the applications interface directly with the authentication store. Figure 2.2 shows how it works with an IdP. The applications interface with the IdP, and the IdP interfaces with the credential store.

Public IdPs
Identity providers can be public or private. The use of public IdPs is steadily increasing. Instead of creating internal IdPs, many organizations have decided to use an IdP service provider. Using an external IdP can save you a lot time and money when it comes user management. There are several public IdPs available for use. We’ll cover a few of the most popular.
OpenID
We’ll start with OpenID. OpenID is not an identity in and of itself; it is a standard for doing authentication. It provides an open framework that providers can use to ensure interoperability of their solutions. OpenID is a technology that allows you to implement an environment where authentication is abstracted from authorization. With OpenID, authentication can be decoupled from an application or other resource. You can use a central entity, such as an IdP, to perform authentication for multiple Websites and resources. As long as the IdP adheres to the OpenID standard and the service provider supports it, the interoperability will work properly.

OpenID provides several key benefits. First, service providers do not have to worry about maintaining authentication capabilities. They do not have to build authentication support into their services or applications. They also do not have to worry about maintaining credential stores or doing user management. Password resets and things of that nature that quickly drive up support costs are eliminated.
Second, with OpenID, the service provider does not care what method was used to authenticate the user. This allows you to select an authentication scheme that meets your organization’s needs without having to worry about whether or not it will work with your applications. You can also feel free to change your authentication scheme when you deem it necessary. It can be a change within the same IdP, or you can choose a new IdP. As long as the IdP supports OpenID, your application will not care that the authentication mechanism has changed. If you did choose a new IdP, you will have to set up a new trust between the application or service and the IdP, but it will not affect authorization within the application or service. This type of flexibility can be a big advantage in today’s ever-changing landscape.
Google based its IdP on the OpenID standard. It conforms to OpenID 2.0. The Google IdP also supports the following extensions: OpenID Attribute Exchange 1.0, OpenID User Interface 1.0, OpenID + OAuth Hybrid Protocol, and Provider Authentication Policy Extension (PAPE). When you use your Google account to log onto sites like YouTube, you are actually using the Google IdP.
Facebook is rapidly growing in popularity as an identity provider. Facebook currently uses OAuth 2.0 to provide authentication and authorization. Facebook offers several APIs and software development kits (SDKs) that aid you in integrating Facebook login with your application. You can use client-side JavaScript, native device calls (iOS, Android, etc.), or server-side execution. Go to www.facebook.com/developers to get more information on using the Facebook identity provider.
Microsoft Account
Microsoft’s identity provider, Microsoft account, was previously known as Windows Live. It’s the default IdP used on all Microsoft-related Websites. It is also the default IdP for Microsoft Access Control Services (ACS), Microsoft’s federated identity provider service, which we discuss next.
Federated Identity
Federated identity is a secure way for disparate systems to get access to your identity information. Your information may only exist in one system. But, with federated identity, other systems can also have access this information. The key to federated identity is trust. The system that holds your information and the system that is requesting your information must trust each other. To make sure your information is being transmitted to a trusted place, the system that holds the information must trust the system that is requesting the information. The system requesting the information has to trust the sender to ensure they are getting accurate and trustworthy information.
Basically, an application is trusting another entity, namely an IdP, when that entity says who a particular user is. The application does not itself perform any actions to verify the user’s identity. It simply believes what the IdP says. Before an application will believe an IdP, a trust relationship must be established. The application must be configured with the address of the IdP that it will be trusting. The IdP must be configured with the address of the application. In most cases, some type of keys will be exchanged between the two entities to actually establish the relationship. These keys are used by the entities to identify themselves with the other entities.
Microsoft Access Control Services
You can choose to go with an externally hosted issuer like Microsoft Access Control Service (ACS). ACS is a Windows Azure cloud-based Web service used for identity and access management. ACS can be used to provide authentication and authorization functionality for Web applications and services. This way, those functions don’t have to be built directly into the code for the application or service. A key benefit of ACS is that because it is a cloud-based instance, no installation is required. You still have to configure the instance for your environment, but nothing needs to be installed.
ACS is very extensible. It complies with a large number of environments and protocols. This allows you to easily integrate ACS into your environment. ACS supports industry-standard protocols such as OAuth, OpenID, WS-Federation, and WS-Trust. ACS also supports multiple token formats. It supports SAML 1.2, SAML 2.0, JWT, and SWT formats. ACS supports development using a variety of Web platforms. You can use .NET, PHP, Java, Python, and a host of others.
ACS includes a host of functionalities that are critical for most federated identity environments. ACS allows you to implement only the functionality you need for your implementation. ACS provides the following functionality: authentication, authorization, federation, security token flow and transformation, trust management, administration, and automation.
Computing Concepts
A couple of key computing concepts come into play when you’re talking about cloud implementations. These concepts help establish many people’s philosophy of cloud implementations.
Utility Computing
The concept of utility computing has been around for a very long time, but it’s just now being put into practice. Utility computing is the practice of treating computing resources like a metered service, as we do for electricity and water. A utility company only charges you for the electricity or water you use. It’s the same in utility computing. The service provider only charges you for the computing resources you use.
This concept of pay-as-you-go computing is at the center of the public cloud methodology. There are resources available to you, but you should only pay for what you use. Often there is also a monthly fee associated with having the resources available, but the bulk of the cost is based on your actual usage.
Commodity Servers
The concept of commodity servers involves using general, nonspecialized servers to complete a task. Instead of using different servers for different tasks, you use the same servers for all tasks. Generally, commodity servers are lower-cost systems. Instead of putting many tasks on one powerful server, you can spread the task over a larger number of less powerful servers. This practice is also referred to as scaling out instead of scaling up.
Cloud providers often use commodity servers for building out their virtualization infrastructure. This is what Amazon did for its cloud implementation. In fact, Amazon has been so successful that other providers have since tried to copy this model.
Hardware Virtualization
When many people think about the cloud, they automatically think virtualization. But in fact virtualization is not required in building a cloud environment. If you think back to the characteristics of a cloud environment, none of them specially mentions virtualization as a requirement.
Although it’s not required, virtualization is used in a majority of cloud implementations. This is because virtualization can increase your ability to deliver the characteristics required in a cloud environment. For example, it can be much cheaper to increase capacity by adding a new virtual machine than it would be to provide this increase using physical systems.
Hardware virtualization is the most common and most well known type of virtualization. Hardware virtualization is used to generate a simulated physical system on top of an actual physical system. In most cases there are multiple simulated physical systems. This is how hardware virtualization is used to create system density and increase system utilization. You can have multiple virtual systems, called virtual machines, running on a single physical system. These virtual systems will share use of the physical resources. So, when one virtual system is not using a physical system’s resources, the resources may be used by another physical system. In a nonvirtualized environment, system resources may be sitting idle a large portion of the time. You’ve paid for the system but are not using it to its full potential.
Hypervisors
Hardware virtualization is implemented through the use of hypervisors. Hypervisors do offer some network and storage virtualization, but robust features are added by other products. For this section, we are concerned with hardware virtualization. We cover some of the more common hypervisors used in cloud environments today. Depending on what service you will be consuming, the hypervisor may be very important in your decision. You need to make sure the hypervisor supports the features you need in your implementation.
Hypervisor Basics
The hypervisor is what actually provides the virtualization capabilities. The hypervisor acts as an intermediary between the physical system, also called the host, and the virtualized system, also called the guest. Different hypervisors require different components be installed on the host system to provide virtualization. Furthermore, different hypervisors provide different options for guest operating systems.
Hypervisor Types
There are two types of hypervisor: Type-1 and Type-2. Hypervisors are categorized based on where they sit in the stack.
Type-1 hypervisors generally sit directly on top of the bare-bones hardware. Type-1 hypervisors act as their own operating systems. This allows them to make more efficient use of physical system resources. Because of this efficiency, most cloud environments are built using Type-1 hypervisors.
Type-2 hypervisors generally sit on top of another operating system. The operating system controls access to the physical hardware. The hypervisor acts as a control system between the host operating system and the guest operating system. One of the big advantages of Type-2 hypervisors is that you can generally install them on your regular desktop system. You don’t need to have a separate system for installing the hypervisor.
Xen Hypervisor
There are two versions of the Xen hypervisor: the open-source version of Xen and the commercial version offered by Citrix, called XenServer. For this book, we will be talking about XenServer.

XenServer is a type-1 hypervisor; basically it is a customized version of Linux that is installed on your server hardware. A XenServer implementation consists of two main components: the XenServer hypervisor, which is installed on a bare-metal system, and the XenCenter management console, which is installed on a Windows system.
Hyper-V
Hyper-V is a type-1 hypervisor. Many people are often fooled by it. Hyper-V is enabled after the Windows operating system is installed, and Hyper-v-based virtual machines are accessed through the Windows operation system. But the fact is, when you enable Hyper-v, it inserts itself between the hardware and the operating system. As a matter of fact, the operating system you see is essentially a virtual machine running on the Hyper-v platform.
vSphere
VMWare offers a type-1 hypervisor call vSphere. VMWare vSphere is widely used within organizations to provide a virtualization infrastructure and private cloud functionality. But it’s use in public cloud infrastructures has been somewhat hindered because of its proprietary nature.

KVM
The Kernel-based Virtual Machine, more commonly known as KVM, is an open-source Linux kernel-based hypervisor. KVM uses a loadable kernable module named kvm.ko and a platform-specific model, either kvm-intel.ko or kvm-amd.ko. KVM supports a wide variety of Windows and Linux operating systems for the guest operating system (OS).

Web Development Technologies
Web applications are accessed via the Internet, typically using a Web browser. Web applications generally don’t require any other client installations. This is one of the things that make them particularly attractive in cloud-based scenarios. They can be accessed from anywhere and in many cases from any device, as long as the device has a suitable Web browser.
More and more independent software vendors (ISVs) are offering Web-based versions of their applications. In fact, Web apps are becoming the de facto standard for offering applications. Several standards and technologies go into making Web applications a viable solution. We cover a few of them here.
In addition, it’s very important to consider Web application technologies in assessing PaaS platforms. Since you will be using the PaaS platform to develop applications, it’s important that you ensure that the PaaS platform you choose supports the technologies that you plan to use to implement your applications.
HTML
HyperText Markup Language (HTML) has been a Web standard for a very long time. In fact, HTML is the number-one standard for creating Web pages. All Web browsers know and understand how to interpret HTML pages. HTML uses tags to format and add structure to Web pages. The number of tags and amount of functionality available in HTML continues to expand. In fact, the newest version HTML 5 has again made HTML a choice Web programming language.
Adobe Flash
Adobe Flash is a programming language used mainly for creating vector graphics and animation. Flash is probably one of the most common languages used on the Internet for applications that need animation.
Flash isn’t as popular as it once was due to concerns over stability and security. Because of these issues, some systems do not support Flash natively. Developers have been looking for alternatives that can provide the same functionality. HTML 5 is one of the technologies that many see as a potential replacement for Flash.

SOAP
SOAP, the Simple Object Access Protocol, is a protocol for exchanging data between Web services. SOAP messages use XML Information Set for their formatting. SOAP relies on other protocols for its negotiation and transmission. The two most common application layer protocols SOAP uses are HTTP and SMTP. The three characteristics of SOAP that make it an attractive protocol are its neutrality, its independence, and its extensibility.
REST
REST, or Representational State Transfer, is actually an application architecture. REST breaks down application interactions into servers and client. The client is the entity making the request, and the server is the entity servicing the request.
REST defines six constraints on application implementations:
■ Client/server model. There must be a strict separation of concerns between clients and servers.
■ Stateless. Applications must not rely on state information when interfacing with clients.
■ Cacheable. The content received by clients must be cacheable.
■ Layered system. Clients cannot tell whether or not they are directly connected to servers; therefore intermediaries can be used when needed.
■ Code on demand. Servers can send executable code to clients.
■ Uniform interface. A standard interface is used between clients and servers.
Java
Java is an object-oriented programming language. Java applications are designed to run on any platform. Java code is interpreted to an intermediate language called Java bytecode. This bytecode is then run by the Java Virtual Machine (JVM). As long as a system has the correct version of the JVM running, the Java application should be able to run.
JavaScript
JavaScript (JS) is a lightweight, object-oriented programming language. All current Web browser versions understand JavaScript. Sometimes you will see that for security reasons, the execution of client-side JavaScript has been disabled. JavaScript was initially used as mainly a client-side language, but nowadays it is used increasingly for both client- and server-side programming. Because of the wide compatibility of JavaScript, it is used in a large number of Web site and Web application implementations.

ASP.NET
ASP.NET is a server-side Web development language developed by Microsoft. It allows a developer to build dynamic pages called Web forms. This means that the content on the page can change based on certain characteristics or requirements. ASP.NET is built on top of Microsoft’s Common Language Runtime (CLR). The CLR does just-in-time compilation of applications written using any programming language based on Microsoft’s .NET Framework.

PHP
PHP is a server-side scripting and programming language. PHP used to stand for Personal Home Page; now it stands for PHP: Hypertext Preprocessor. Many server-side programming languages require a Web page to call a separate file, but PHP code can be embedded directly in a Web page.

Ruby on Rails
Ruby on Rails, also called Ruby, is an open-source development framework that can be used to create templates, develop applications, and query databases. Ruby uses the Model-View-Controller, or M-V-C, architecture. A model maps to a table in a database. A View is an ERB file that is converted to HTML at runtime. A Controller is the component that responds to external requests.

JBOSS
JavaBeans Open Source Software Application Server (JBOSS) is an open-source application server. It is used to implement the Java Platform, Enterprise Edition (JSEE). JBOSS is written in Java, which means it can be run on systems that support Java applications.

JSON
JavaScript Object Notation (JSON) is an open standard used to represent arrays and data structures. JSON is largely used to transmit data between a server and a Web application. As the name indicates, JSON is derived from JavaScript, but it’s important to note that even though it’s derived from JavaScript, JSON is language independent. This is one of the characteristics of JSON that makes it attractive to developers.

Summary
In some cases, you will need only minimal understanding of the technologies behind the cloud. In others, you will need a much greater understanding. It’s important that you understand which technologies are in play when you’re making decisions about cloud providers. If you need to integrate with a cloud implementation, it’s vital that you understand with which technologies you are integrating. These could be authentication technologies, computing technologies, virtualization technologies, or Web development technologies.