13
Cell Biology
- 13.1 The Origin of Life
- 13.2 Molecular Biology of the Cell
- 13.3 Structural Cell Biology
- 13.4 Expression of Genes
- Exercises
- References
- Further Reading
This section gives a brief overview of biology and related subjects, such as biochemistry, with a focus on molecular biology, since the latter is most relevant to current systems biology. We will review several basics on biochemistry, and introduce fundamental knowledge of biology. The basics are required for the setup of all models for biological systems, and the meaningful interpretation of simulation results and analysis. For a broader and more detailed introduction to biology, it is recommended to consult books by Alberts et al. [1] and Reece et al. [2].
Biology is the science that deals with living organisms and their interrelationships between each other and their environment in light of their evolutionary origin. Some of the main characteristics of organisms are the following:
- Physiology: All living organisms assimilate nutrients, extract energy from these nutrients, produce substances themselves, and excrete the remains.
- Growth and reproduction: All living organisms grow and reproduce their own species.
- Cellular composition: Cells are the general building blocks of organisms.
Biology is divided into several disciplines, such as physiology, morphology, cytology, ecology, developmental biology, behavioral and evolutionary biology, molecular biology, biochemistry, and classical and molecular genetics. Biology tries to explain characteristics such as the shape and structure of organisms and their change during time, as well as phenomena of their regulatory, individual, or environmental relationships. This section gives a brief overview about this scientific field with a focus on biological molecules, fundamental cellular structures, and molecular biology and genetics.
13.1 The Origin of Life
The earliest development on earth began 4½ billion years ago. Massive volcanism released water (H2O), methane (CH4), ammonia (NH3), hydrogen sulfide (H2S), and molecular hydrogen (H2), which formed a reducing atmosphere and the early ocean. By loss of hydrogen into space and gas reactions, an atmosphere consisting of nitrogen (N2), carbon monoxide (CO), carbon dioxide (CO2), and water (H2O) was formed. The impact of huge amounts of energy (e.g., sunlight with a high portion of ultraviolet (UV) radiation and electric discharges) onto the reducing atmosphere along with the catalytic effect of solid-state surfaces resulted in an enrichment of simple organic molecules such as amino acids, purines, pyrimidines, and monosaccharides in the early ocean. This is called the prebiotic broth hypothesis and is based on the experiments of Miller and Urey [3]. Another possibility is that the first forms of life formed in the deep sea utilizing the energy of hydrothermal vents, well protected from damaging UV radiation and the unstable environment of the surface [4]. Once simple organic molecules were formed in significant amounts, they presumably assembled spontaneously into macromolecules such as proteins and nucleic acids. By formation of molecular aggregates from these colloidally solved macromolecules, the development of simple compartmented reaction pathways for the utilization of energy sources was possible. Besides this, enzymes appeared that permitted specific reactions to take place in ordered sequences at moderate temperatures, and information systems necessary for directed synthesis and reproduction were developed. The appearance of the first primitive cells – the last common ancestors of all past and recent organisms – was the end of the abiotic (chemical) and the beginning of the biotic (biological) evolution. Later, these first primitive cells evolved into the first prokaryotic cells (prokaryotes). About 3½ billion years ago, the reducing atmosphere was very slowly enriched by oxygen (O2) due to the rise of photosynthesis that resulted in an oxidative atmosphere (1.4 billion years ago: 0.2% O2; 0.4 billion years ago: 2% O2; today: about 21% O2).
Prokaryotes (eubacteria and archaebacteria) are mostly characterized by their size and simplistic structure compared with the more evolved eukaryotes. Table 13.1 summarizes several differences between these groups. The evolutionary origin of the eukaryotic cells is explained by the formation of a nucleus and several compartments, and by the inclusion of prokaryotic cells, which is described by the endosymbiont hypothesis. This hypothesis states that cellular organelles, such as mitochondria and chloroplasts, are descendants of specialized cells (e.g., specialization for energy utilization) that have been engulfed by the early eukaryotes.
Table 13.1 Some important differences between prokaryotic and eukaryotic cells.
| Prokaryotes | Eukaryotes | |
| Size | Mostly about 1–10 μm in length | Mostly about 10–100 μm in length |
| Nucleus | Nucleus is missing; chromosomal region is called nucleolus | Nucleus is separated from the cytoplasm by the nuclear envelope |
| Intracellular organization | Normally, no membrane-separated compartments and no supportive intracellular skeletal framework are present in the cells' interior | Distinct compartments are present, for example, nucleus, cytosol with a cytoskeleton, mitochondria, endoplasmic reticulum, Golgi complex, lysosomes, plastids (chloroplasts, leucoplasts) |
| Gene structure | No introns; some polycistronic genes | Introns and exons |
| Cell division | Simple cell division | Mitosis or meiosis |
| Ribosome | Consists of a large 50 S subunit and a small 30 S subunit | Consists of a large 60 S subunit and a small 40 S subunit |
| Reproduction | Parasexual recombination | Sexual recombination |
| Organization | Mostly single cellular | Mostly multicellular, and with cell differentiation |
Prokaryotes and these early eukaryotes are single-celled organisms. Later during evolution, single-celled eukaryotes evolved further into multicellular organisms. Their cells are mostly genetically identical, but differentiate into several specialized cell types during development. Most of these organisms reproduce sexually.
The developmental process that takes place by sexual reproduction starts with a fertilized egg (zygote) that divides several times (the cell division underlying this process is discussed in more detail in Section 13.3). For instance, in the frog Xenopus laevis – which is a vertebrate and belongs to the amphibians – the development starts with the zygote and passes through several developmental phases, that is, morula (64 cells), blastula (10 000 cells), gastrula (30 000 cells), and neurula (80 000 cells), before forming the tadpole (with a million cells 110 h after fertilization) that develops into the adult frog later on. This process is genetically determined and several phases are similar between species that are related close to each other due to their identical evolutionary origin. Figure 13.1 shows a simplified tree of life that illustrates major evolutionary relations.
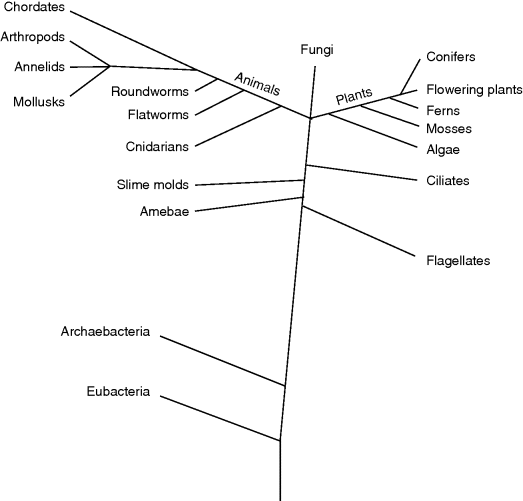
Figure 13.1 The tree of life shows phylogenetic relations between some major groups of organism.
While most places with moderate aerobic conditions were populated by eukaryotes, the prokaryotic archaebacteria in particular have specialized to survive under extreme conditions (e.g., thermophilic bacteria, which propagate at temperatures of 85–105 °C in the black smokers of the deep sea, or the halobacteria, which live in high salt concentrations).
Along with organisms that have their own metabolism, parasitic viruses and viroids that utilize cells for reproduction have developed. Viruses consist of a very small genome surrounded by a protein envelope (capsid); viroids are single-stranded circular RNAs. Due to the absence of metabolism and a cellular structure, these parasites are not regarded as living organisms.
The phenotypical diversity of organisms observed is also displayed in the structure of their hereditary information: the size of this genomic information can vary, as can its organization into different elements, that is, plasmids and chromosomes. Table 13.2 summarizes some data acquired from commonly investigated organisms.
Table 13.2 Genome sizes of different organisms from the prokaryotic and eukaryotic kingdom.
| Organism | Number of chromosomes (haploid genome) | Genome size (base pairs; genes) |
| Mycoplasma genitalium (prokaryote) | 1 circular chromosome | 5.8 × 105 bp; 480 genes |
| Escherichia coli (prokaryote) | 1 circular chromosome | 4.6 × 106 bp; 4290 genes |
| Saccharomyces cerevisiae (budding yeast; eukaryote) | 16 chromosomes | 12.5 × 106 bp; 6186 genes |
| Arabidopsis thaliana (flowering plant; eukaryote) | 5 chromosomes | 100 × 106 bp; ∼25 000 genes |
| Drosophila melanogaster (fruit fly, eukaryote) | 4 chromosomes | 180 × 106 bp; ∼14 000 genes |
| Mus musculus (mouse, eukaryote) | 20 chromosomes | 2.5 × 109 bp; ∼30 000 genes |
| Homo sapiens (human, eukaryote) | 23 chromosomes | 2.9 × 109; ∼30 000 genes |
| Information about further organisms can be found, for example, at http://www.cbs.dtu.dk/services/GenomeAtlas and www.ensembl.org. | ||
13.2 Molecular Biology of the Cell
Cellular structures and processes result from a complex interaction network of biological molecules. The properties of these molecules determine possible interactions. Although many of these molecules are highly complex, most fall into one of the following four classes or contain substructures that belong to one of these: carbohydrates, lipids, proteins, and nucleic acids. Along with these four classes, water is essential for all living systems. Molecules are held together by and interact through chemical bonds and forces of different types: ionic, covalent, and hydrogen bonds, nonpolar associations, and van der Waals forces. The following sections will provide a foundation for the understanding of molecular structures, functions, and interactions by giving a brief introduction to chemical bonds and forces, to the most important classes of biological molecules, and to complex macromolecular structures formed by these molecules.
13.2.1 Chemical Bonds and Forces Important in Biological Molecules
The atomic model introduced by Rutherford and significantly extended by Bohr describes the atom as a positively charged nucleus being surrounded by one or more shells (or, more exactly, energy levels) that are filled with electrons. Most significant for the chemical properties of an atom is the number of electrons in its outermost shell. Atoms tend to fill up their outermost shell to obtain a stable state. The innermost or first shell is filled up by two electrons. The second and further shells are filled up by 2n2 electrons, where n depicts the number of the shell. However, due to reasons of energetic stability, the outermost shell will not contain more than eight electrons. For example, helium, with two electrons in its single shell, or atoms such as neon or argon, with eight electrons in their outermost shells, are essentially chemically inert. Atoms with a number of electrons near to these numbers tend to lose or gain electrons to attain these stable states. For example, sodium (one electron in its outer shell) and chlorine (seven electrons in its outer shell) can both achieve such a stable state by transferring one electron from sodium to chlorine, thus forming the ions Na+ and Cl−. The force holding together the oppositely charged ions in solid state is called the ionic or electrostatic bond (Figure 13.2a). If the number of electrons in the outer shell differs by more than one, atoms tend to share electrons by forming a so-called covalent bond (Figure 13.2b). Atoms held together by covalent bonds are called molecules. If the shared electron pair is equally distributed between the two involved atoms, this bond is called nonpolar (e.g., for the hydrogen molecule). If one atom has a higher attraction to the shared electron pair, it becomes partially negatively charged. Then the other atom in this polar association becomes partially positively charged, as is the case with the water molecule (H2O), where the oxygen attracts the shared electron pairs stronger than the hydrogen atoms do. Thus, OH and NH groups usually form polar regions in which the hydrogen is partially positively charged. A measurement for the affinity of an atom to attract electrons in a covalent bond is given by its electronegativity, which was introduced by Linus Pauling. In addition to single covalent bonds, double and triple bonds also exist. These kinds of bonds are more exactly described by the quantum-mechanical atomic model, in which the electron shells of an atom can be described by one of several differently shaped orbitals that represent the areas where the electrons are located with highest probability (electron clouds). A covalent bond is then described by molecular orbitals, which are derived from atomic orbitals. Furthermore, if single and double bonds are altered in a single molecule or a double bond is in direct vicinity of an atom with a free electron pair, then one electron pair of the double bond and the free electron pair can delocalize across the participating atoms, for example, the three electron pairs in benzol (Figure 13.2b) or the double bond between C and O and the free electron pair of N in a peptide bond (Figure 13.6a). Such electrons are called delocalized π-electrons. For a more detailed description, please consult books about general and inorganic chemistry or introductory books about biochemistry.
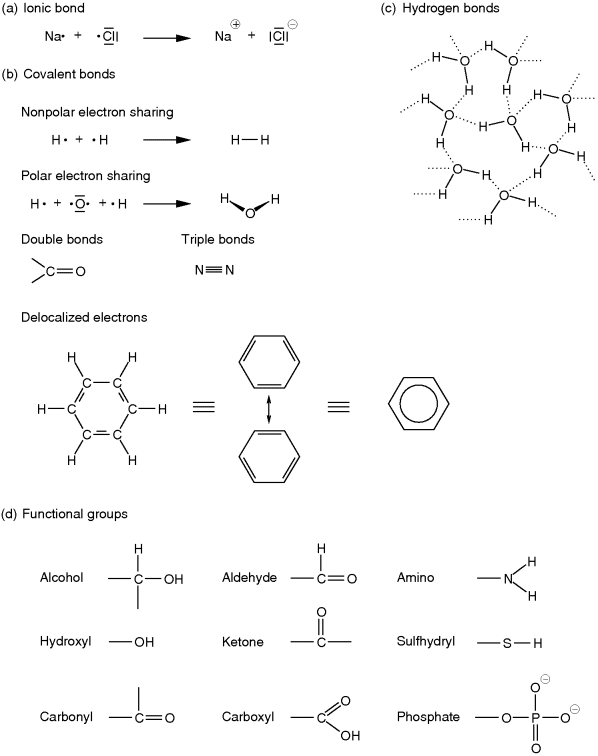
Figure 13.2 Chemical bonds and functional organic groups. Single electrons in the outer shell are visualized by a dot; electron pairs are replaced by a dash. Shared electron pairs are represented by a dash between two atoms. (a) Single charged Na+ and Cl− ions are formed by the transition of the single outermost electron of sodium to chlorine. (b) In a covalent bond, electrons are shared between two atoms. If the shared electron pair is attracted more strongly by one of the participating atoms than by the other, this bond is called a polar bond. Depending on the molecular structure, double and triple bonds can occur as well. Sometimes, binding electron pairs might also be delocalized among several atoms, as is the case in benzol. (c) Unequal electron sharing causes the formation of hydrogen bonds (shown by dotted lines) as found in water. (d) The skeleton of organic molecules essentially consists of carbon atoms bound to each other or to hydrogen. Some of these carbons are bound to or are part of functional groups with special chemical characteristics. Hence, these influence the reactivities and physicochemical properties of the molecule.
Hydrogen atoms with a positive partial charge that are bound to oxygen or nitrogen (as in H2O or NH3) are able to interact with free electron pairs of atoms with a negative partial charge. These attractions are called hydrogen bonds and are relatively weak compared with solid-state ionic bonds or covalent bonds. To break a hydrogen bond, only about 4 kJ mol−1 is required. Therefore, hydrogen bonds separate readily at elevated temperatures, which is often the reason why proteins such as enzymes lose their function during heating. Likewise, the hydrogen bonds that hold together the double strands of nucleic acids (see Section 13.2.3) can be separated at high temperatures. This fact is utilized for several molecular biological methods, for example, polymerase chain reaction (PCR), or for the radioactive labeling of DNA (deoxyribonucleic acid) fragments (see Chapter 14 for more details). Hydrogen bonds also explain why water is liquid at room temperature and boils at 100 °C. Small alcohols, such as methanol or ethanol, are fully soluble in water, due to their hydroxyl group that interacts with the hydrogen bonds of water, whereas larger alcohols, such as hexanol or heptanol, are weakly soluble or insoluble in water due to their longer unpolar carbohydrate tail. As we have seen, polarized functional groups can interact with water, which is why they often are called hydrophilic (or lipophobic), while nonpolar molecules or molecule parts are called hydrophobic (or lipophilic).
Also critical to structures and interactions of biological molecules are the van der Waals forces. The electron clouds surrounding atoms that are held together by covalent bonds are responsible for these forces. Momentary inequalities in the distribution of electrons in any covalent bond, due to chance, can make one end of the covalent bond more negative or positive than the other for a short moment, which results in rapid fluctuations in the charge of the electron cloud. These fluctuations can induce opposite fluctuations in nearby covalent bonds, thus establishing a weak attractive force. The closer the electron clouds, the stronger the attractive force, but if the outermost electron orbitals begin to overlap, the negatively charged electrons strongly repel each other. Thus, van der Waals forces can be either attractive or repulsive. Their binding affinity is, at 0.4 kJ mol−1 in water, even lower than that of hydrogen bonds. The optimal distance for maximum van der Waals forces of an atom is called its van der Waals contact radius. The van der Waals repulsions have an important influence on the possible conformations of a molecule.
13.2.2 Functional Groups in Biological Molecules
As outlined before, one major characteristic of life are physiological processes in which nutrients from the outside are converted by the organism to maintain a thermodynamically open system with features such as development or behavior. These physiological processes are realized on the metabolic level by myriads of reactions in which specific molecules are converted into others. These intra- or intermolecular rearrangements often take place at specific covalent bonds that can more readily be disturbed than others. Such covalent bonds are often formed by certain intramolecular substructures that are called functional groups. Thus, functional groups often serve as reaction centers converting some molecules into others or link some molecular subunits to form larger molecular assemblies, for example, polypeptides or nucleic acids. The functional groups most relevant in biological molecules are hydroxyl, carbonyl, carboxyl, amino, phosphate, and sulfhydryl groups (Figure 13.2d).
Hydroxyl groups (OH) are strongly polar and often enter into reactions that link subunits into larger molecular assemblies in which a water molecule is released. These reactions are called condensations. The reverse reaction, in which a water molecule enters a reaction by which a larger molecule is split into two subunits, is called hydrolysis. The formation of a dipeptide from two amino acids is an example of condensation, and its reverse reaction is the hydrolysis of the dipeptide (Figure 13.6a). If the hydroxyl group is bound to a carbon atom, which in turn is bound to other hydrogen and/or carbon atoms, it is called an alcohol. Alcohols can easily be oxidized to form aldehydes or ketones, which are characterized by their carbonyl group (Figure 13.2d). Aldehydes and ketones are particularly important for carbohydrates (such as sugars) or lipids (such as fats). In aldehydes the carbonyl group occurs at the end of a carbon chain, whereas in ketones it occurs in its interior. A carboxyl group is strongly polar and formed by an alcohol group and an aldehyde group. The hydrogen of the hydroxyl part can easily dissociate as H+ due to the influence of the nearby carbonyl oxygen. In this way, it acts as an organic acid. The carboxyl group (COOH) is the characteristic group of organic acids such as fatty acids and amino acids. Amino acids are further characterized by an amino group. Amino groups (NH2, Figure 13.2d) have a high chemical reactivity and can act as a base in organic molecules. They are, for instance, essential for the linkage of amino acids to form proteins and for the establishment of hydrogen bonds in DNA double strands. Moreover, amino acids carrying NH2 in their residual group often play a crucial role as part of the catalytic domain of enzymes. Another group that has several important roles is the phosphate group (Figure 13.2d). As part of large organic molecules, this group acts as a bridging ligand connecting two building blocks to each other, as is the case in nucleic acids (DNA, RNA; see Section 13.2.3) or phospholipids. Furthermore, the di- and triphosphate forms in conjunction with a nucleoside serve as a universal energy unit in cells, for example, adenosine triphosphate (ATP, Figure 13.7a). Phosphate groups are also involved in the regulation of the activity of enzymes, for example, MAP kinases, which participate in signal transduction. Sulfhydryl groups (Figure 13.2d) are readily oxidized. If two sulfhydryl residues participate in an oxidization, a so-called disulfide bond is created (Figure 13.6d). These linkages often occur between sulfhydryl residues of amino acids that form a protein. Thus, they are responsible for the stable folding of proteins, which is required for their correct functioning.
13.2.3 Major Classes of Biological Molecules
The structural and functional properties of an organism are based on a vast number of diverse biological molecules and their interplay. The physicochemical properties of a molecule are determined through their functional groups. In the following sections, four major classes of biological molecules that are ubiquitously present and are responsible for fundamental structural and functional characteristics of living organisms will be introduced: carbohydrates, lipids, proteins, and nucleic acids.
Carbohydrates
Carbohydrates function as energy storage molecules and furthermore can be found as extracellular structure mediators, for example, in plants. The chemical formula of carbohydrates is mostly Cn(H2O)n. The individual building blocks of all carbohydrates are the monosaccharides, which consist of a chain of three to seven carbon atoms. Depending on the number of carbon atoms, they are categorized as trioses, tetroses, pentoses, hexoses, or heptoses (cf. Figure 13.3a). All monosaccharides can occur in linear form, and with more than four carbons, they exist in equilibrium with a ring form. In the linear form, all carbons of the chain, except for one, carry a hydroxyl group (polyalcohol), which makes the carbohydrates hydrophilic. The remaining carbon carries a carbonyl group, and depending on its position – whether it is an aldehyde or a ketone – it is called an aldose or a ketose. The circular configuration is attained by an intramolecular reaction between the carbonyl group and one of the hydroxyl groups. Such a compound is called a hemiacetal. An example of the ring formation for the six-carbon monosaccharide glucose is given in Figure 13.3b, in which it forms a so-called glucopyranose ring. Depending on the orientation of the hydroxyl group at the 1-carbon, that is, whether it points downward (α-glucose) or upward (β-glucose), two alternate conformations exist. Glucose is one of the most important energy sources for organisms. It is metabolized during glycolysis into ATP and reduction equivalents (e.g., NADH, NADPH, or FADH2).
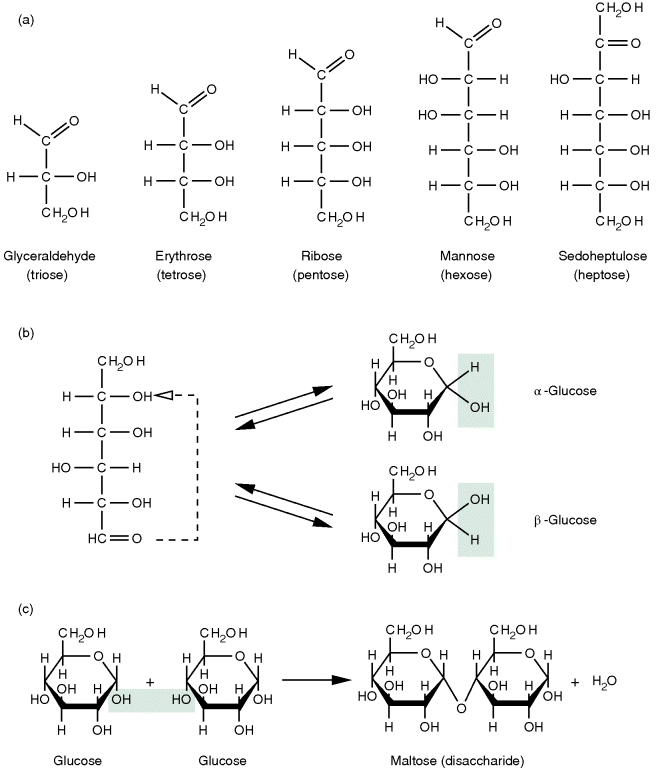
Figure 13.3 Carbohydrates. (a) Some examples of carbohydrates with a backbone of three to seven carbon atoms. (b) Glucose, like other monosaccharides with more than four carbons in their backbone, can form a circular structure, known as hemiacetal, by an intramolecular condensation reaction that can occur in two different conformations. (c) By further condensation reactions, such sugar monomers can form disaccharides or even larger linear or branched molecules called oligomers or polymers depending on the number of monomers involved.
The hydroxyl group at the 1-carbon position of the cyclic hemiacetal can react via a condensation with the hydroxyl group of another monosaccharide. This linkage forms a disaccharide from two monosaccharides (Figure 13.3c). If this happens subsequently for several carbohydrates, polysaccharides that occur as linear chains or branching structures are formed.
Lipids
Lipids are a very diverse and heterogeneous group. Since they are made up mostly of nonpolar groups, lipids can be characterized by their higher solubility in nonpolar solvents, such as acetone. Due to their hydrophobic character, lipids tend to form nonpolar associations or membranes. Eventually, these membranes form cellular hydrophilic compartments. Furthermore, such hydrophobic regions offer a local area for reactions that require a surrounding deprived of water. Three different types of lipids are present in various cells and tissues: neutral lipids, phospholipids, and steroids. Lipids can also be linked covalently to proteins or carbohydrates to form lipoproteins or glycolipids, respectively.
Neutral lipids are generally completely nonpolar and are commonly found as storage fats and oils in cells. They are composed of the alcohol glycerol (an alcohol with three hydroxyl groups), which is covalently bound to fatty acids. A fatty acid is a linear chain of 4–24 or more carbon atoms with attached hydrogens (molecules like this are well known as hydrocarbons) and a carboxyl group at one end (Figure 13.4a). Most frequent are chains with 16 or 18 carbons. Fatty acids can be either saturated or unsaturated (polyunsaturated). Unsaturated fatty acids contain one or more double bonds in their carbon chain and have more fluid character than do saturated ones. Linkage of the fatty acids to glycerol results from a condensation reaction of the carboxyl group with one of the alcohol groups of glycerol; this is called an ester binding. If all three sites of the glycerol bind a fatty acid, it is called a triglyceride, which is the most frequent neutral lipid in living systems. Triglycerides – in form of fats or oils – mostly serve as energy reserves.

Figure 13.4 (a) Fatty acids represent one part of fats and phospholipids. They are either saturated or unsaturated. (b) Triglycerides are formed by condensation reactions of glycerol and three fatty acids. (c) In phospholipids, the third carbon of glycerol is bound to a polar group via a phosphate group (P), which usually is ethanolamine, choline, glycerol, serine, threonine, or inositol. (d) Steroids constitute another major lipid class. They are formed by four condensed carbon rings. Cholesterol, shown here, is important, for example, for membrane fluidity of eukaryotic cells.
Phospholipids are the primary lipids of biological membranes (cf. Section 13.3.1). Their structure is very similar to the neutral lipids. However, the third carbon of glycerol binds a polar residue via a phosphate group instead of a fatty acid. Polar subunits commonly linked to the phosphate group are ethanolamine, choline, glycerol, serine, threonine, or inositol (Figure 13.4c). Due to their polar and apolar parts, phospholipids have dual-solubility properties termed amphipathic or amphiphilic. This property enables phospholipids to form a so-called bilayer in an aqueous environment, which is the fundamental design principle of biological membranes (Figure 13.9a). Polar and nonpolar parts of the amphipathic molecules are ordered side by side in identical orientation and form a one molecule thick layer (monolayer) with a polar and a nonpolar side; the aqueous environment forces the lipophilic sides of two such layers to each other, thus creating the mentioned bilayer.
Steroids are based on a framework of four condensed carbon rings that are modified in various ways (Figure 13.4d). Sterols – the most abundant group of steroids – have a hydroxyl group linked to one end of the ring structure, representing the slightly polar part of the amphiphilic molecule; a nonpolar carbon chain is attached to the opposite end. The steroid cholesterol plays an important part in the plasma membrane of animal cells. Among other things, cholesterol loosens the packing of membrane phospholipids and maintains membrane fluidity at low temperatures. Other steroids act as hormones (substances that regulate biological processes in tissues far away from their own place of production) in animals, and they are, for example, involved in regulatory processes concerning sexual determination or cell growth.
In glycolipids, the lipophilic part is constituted of fatty acids bound to the 1-carbon and 2-carbon of glycerol, as is the case with phospholipids. The 3-carbon is covalently attached to one or more carbohydrate groups that confer an amphiphilic character to the molecule. Glycolipids do occur, for example, in the surface-exposed parts of the plasma membrane bilayer of animal cells that are subject to physical or chemical stress. Furthermore, among several other things, they are responsible for the ABO blood system of humans.
Proteins
Proteins fulfill numerous highly important functions in the cell, only a few of which can be mentioned here. They build up the cytoskeletal framework, which forms the cellular structure and is responsible for cell movements (motility). Proteins are also part of the extracellular supportive framework (extracellular matrix), for example, as collagen in animals. As catalytic enzymes for highly specific biochemical reactions, they rule and control the metabolism of a single cell or whole organism. Furthermore, proteins regulated by transient modifications are relevant for signal transduction, for example, proteins controlling cell division such as cyclin-dependent protein kinases (CDKs). A further highly important function of proteins is their ability to control the transcription and translation of genes as well as the degradation of proteins (see Section 13.4).
Proteins consist of one or more polypeptides. Each polypeptide is composed of covalently linked amino acids; these covalent bonds are called peptide bonds. Such a bond is formed by a condensation reaction between the amino group of one amino acid and the carboxyl group of another (Figure 13.6a). The primary structure of a polypeptide is coded by the genetic information that defines in which order amino acids – chosen from a set of 20 different ones – do appear. Figure 13.5 shows the chemical structures of these amino acids. Common to all amino acids is a central carbon (α-carbon), which carries an amino group (except for proline where this is a ring-forming imino group), a carboxyl group, and a hydrogen. Furthermore, it carries a residual group with different physicochemical properties, due to which the amino acids can be divided into different groups, such as amino acids that carry (i) nonpolar residues that can grant lipophobic characteristics, (ii) uncharged polar residues, (iii) residues containing a carboxyl group, which are negatively charged at physiological pH and thus act as acids, and (iv) residues that are usually positively charged at common pH ranges of living cells and thus show basic characteristics. Due to the combination of possibilities of these amino acids, proteins are very diverse. Usually proteins are assembled from about 50 to 1000 amino acids, but they might be much smaller or larger. Except for glycine, the α-carbon of amino acids binds four different residues and therefore amino acids can occur in two different isoforms that behave like an image and its mirror image. These two forms are called the L-isoform and the D-isoform, of which only the L-isoform is used in naturally occurring proteins. Furthermore, amino acids of proteins are often altered posttranslationally. For instance, proline residues in collagen are modified to hydroxyproline by addition of a hydroxyl group.

Figure 13.5 Amino acids are formed by carbon that is bound to an amino group, a carboxyl group, a hydrogen, and a residual group. Depending on the physicochemical characteristics of the residual group, they can be categorized as (a) nonpolar, (b) uncharged polar, (c) basic, or (d) acidic amino acids.
The primary structure of a protein is given by the sequence of the amino acids linked via peptide bonds. This sequence starts at the N-terminus of the polypeptide and ends at its C-terminus (cf. Figure 13.6a). In the late 1930s, Linus Pauling and Robert Corey elucidated the exact structure of the peptide bond. They found that the hydrogen of the substituted amino group almost always is in opposite position to the oxygen of the carbonyl group, so that both together, with the carbon of the carbonyl group and the nitrogen of the amino group, build a rigid plane. This is due to the fact that the bond between carbon and nitrogen does have a partial double bond character. In contrast to this, both the bonds of the α-carbon with the nitrogen of the substituted amino group and the carbon of the carbonyl group are flexible since they are pure single bonds. The free rotation around these two bonds is limited only by steric interactions of the amino acid residuals. Based on this knowledge, Pauling and Corey proposed two very regular structures: the α-helix and the β-strand. Both are very common in proteins. They are formed by the polypeptide backbone and are supported and stabilized by a specific local amino acid sequence composition. Such regular arrangements are called secondary structures. An α-helix (Figure 13.6b) has a cylindrical helical structure in which the carbonyl oxygen atom of each residue (n) accepts a hydrogen bond from the amide nitrogen four residues further in sequence (n + 4). Amino acids often found in α-helices are Glu, Ala, Leu, Met, Gln, Lys, Arg, and His. In a β-sheet, parallel peptide strands – β-strands that may be widely separated in the linear protein sequence – are linked side by side via hydrogen bonds between hydrogen and oxygen atoms of their backbone (Figure 13.6c). The sequence direction (always read from the amino/N-terminal to the carboxyl/C-terminal of the polypeptide) of pairing β-strands can be either parallel or antiparallel. The residual groups of the amino acids point up and down from the β-sheet. Characteristic amino acids of β-sheets are Val, Ile, Tyr, Cys, Trp, Phe, and Thr. The regular secondary structure elements fold into a compact form that is called the tertiary structure of a protein. Its surface topology enables specific interactions with other molecules. Figure 13.6e shows a model of the three-dimensional structure of the superoxide dismutase (SOD), which detoxifies aggressive superoxide radicals ( ). Sometimes the tertiary structure is stabilized by posttranslational modifications such as disulfide bridges (Figure 13.6d) or metal ions such as calcium (Ca2+) or zinc (Zn2+). Some proteins are fibrous, that is, they form filamentous structures (e.g., the keratin of hair). But most proteins fold into globular, compact shapes. Larger proteins often fold into several independent structural regions: the domains. Domains frequently consist of 50–350 residues and are often capable of folding stably enough to exist on their own. Often proteins are composed of assemblies of more than one polypeptide chain. Such a composition is termed the quaternary structure. The subunits can be either identical or different in sequence and the protein is thus referred to as a homo- or heteromer; for example, a protein composed of four identical subunits such as the lac repressor is called a homotetramer.
). Sometimes the tertiary structure is stabilized by posttranslational modifications such as disulfide bridges (Figure 13.6d) or metal ions such as calcium (Ca2+) or zinc (Zn2+). Some proteins are fibrous, that is, they form filamentous structures (e.g., the keratin of hair). But most proteins fold into globular, compact shapes. Larger proteins often fold into several independent structural regions: the domains. Domains frequently consist of 50–350 residues and are often capable of folding stably enough to exist on their own. Often proteins are composed of assemblies of more than one polypeptide chain. Such a composition is termed the quaternary structure. The subunits can be either identical or different in sequence and the protein is thus referred to as a homo- or heteromer; for example, a protein composed of four identical subunits such as the lac repressor is called a homotetramer.
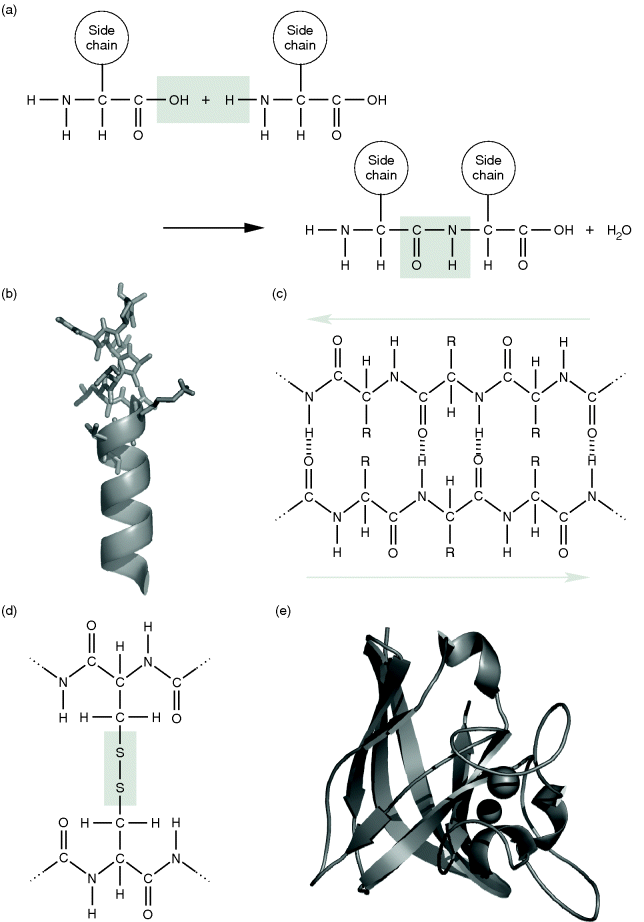
Figure 13.6 (a) Formation of a peptide linkage by a reaction between the carboxyl group of one amino acid and the amino group of the other amino acid . (b) The molecular structure of an α-helix, as shown in the upper part of the image, is often illustrated by a simple helical structure as shown below. (c) An antiparallel β-sheet. (d) A disulfide bridge is formed by oxidation of the SH groups of cysteine residues belonging to either the same or different polypeptides. (e) Three-dimensional illustration of the copper–zinc superoxide dismutase (CuZnSOD) of E. coli (PDB: 1EOS). α-Helices are depicted as helical structures and β-strands illustrated by arrows. The two metal ions are shown as spheres.
Nucleic Acids
Deoxyribonucleic acid (DNA) is present in all living organisms and is the molecule storing the heredity information, that is, the genes. Another molecule, the ribonucleic acid (RNA), takes part in a vast number of processes. Among these, the transfer of the hereditary information leading from DNA to protein synthesis (via transcription and translation; see Section 13.4) is the most important. Both DNA and RNA are nucleic acids. Nucleic acids are polymers built up of covalently bound mononucleotides. A nucleotide consists of three parts: (i) a nitrogen-containing base, (ii) a pentose, and (iii) one or more phosphate groups (Figure 13.7a). Bases are usually pyrimidines such as cytosine (C), thymine (T), or uracil (U), or purines such as adenine (A) or guanine (G) (Figure 13.7b). In RNA, the base is covalently bound to the first carbon (1′-carbon) of the circular pentose ribose. In DNA, it is bound to the 1′-carbon of deoxyribose, a pentose that lacks the hydroxyl group of the 2′-carbon. A unit consisting of these parts – a base and a pentose – is named nucleoside. If it furthermore carries a mono-, di-, or triphosphate, it is called a nucleotide. Nucleotides are named according to their nucleoside, for example, adenosine monophosphate (AMP), adenosine diphosphate (ADP), or adenosine triphosphate (ATP); prepending deoxy to the name (or d in the abbreviation) indicates the deoxy form (e.g., deoxyguanosine triphosphate or dGTP). Nucleotides are not only relevant for nucleic acid construction but also responsible for energy transfer in several metabolic reactions (e.g., ATP and ADP) or play certain roles in signal transduction pathways, such as 3′–5′ cyclic AMP (cAMP), which is synthesized by the adenylate cyclase and is involved, for instance, in the activation of certain protein kinases.
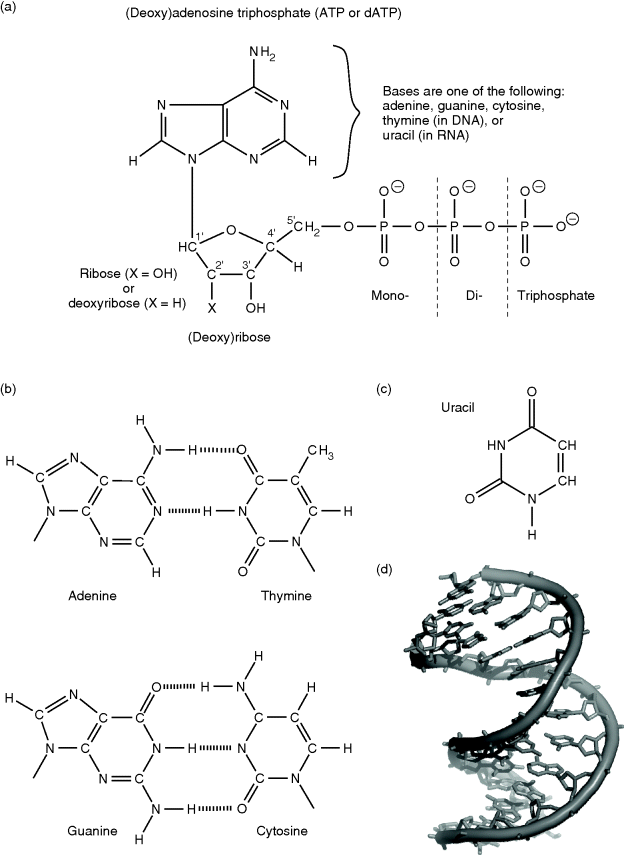
Figure 13.7 (a) Nucleoside phosphates are composed of a ribose or deoxyribose that is linked at its 1′-position to a purine or pyrimidine base. Purines are adenine and guanine, and pyrimidines are thymine, cytosine, or uracil. (b) In DNA, adenine is bound to its complementary base thymine by two hydrogen bonds, and guanine is bound to cytosine by three hydrogen bonds. (c) In RNA, thymine is replaced by uracil. (d) The DNA double helix (PDB: 140D).
In DNA and RNA, the 3′-carbon of a nucleotide is linked to the 5′-carbon of the next nucleotide in sequence via a single phosphate group. These alternating sugar and phosphate groups form the backbone of the nucleic acids. Both DNA and RNA can carry the bases adenine, guanine, and cytosine. In DNA, thymine can also be present, which is replaced by uracil in RNA. The sequence of the different bases has a direction – because of the 5′–3′ linkage of its backbone – and is used in living organisms for the conservation of information. DNA contains millions of nucleotides; for example, a single DNA strand of human chromosome 1 is about 246 million nucleotides long. Each base of the sequence is able to pair with a so-called complementary base by hydrogen bonds. Due to the number and steric arrangement of hydrogen bonds, only two different pairing types are possible (Figure 13.7b): adenine can bind thymine (A–T, with two hydrogen bonds) and guanine can bind cytosine (G–C, with three hydrogen bonds). In RNA, thymine is replaced by uracil. In 1953, Watson and Crick proposed a double strand for the DNA, with an antiparallel orientation of the backbones. Each of the bases of one strand binds to its complementary base on the other strand, and together they form a helical structure (Figure 13.7d). This so-called double helix is the usual conformation of DNA in cells. RNA usually occurs as a single strand. Occasionally, it is paired to a DNA single strand, as during the mRNA synthesis (Section 13.4.1), or complementary bases of the same molecule are bound to each other, for example, as in tRNA.
13.3 Structural Cell Biology
This section gives a general introduction to the structural elements of eukaryotic cells. Fundamental differences between prokaryotic and eukaryotic cells have already been mentioned and are summarized in Table 13.1.
The first microscopic observations of cells were done in the seventeenth century by Robert Hooke and Anton van Leeuwenhoek. The general cell theory was developed in the 1830s by Theodor Schwann and Matthias Schleiden. It states that all living organisms are composed of nucleated cells, which are the functional units of life, and that cells arise only from preexisting cells by a process of division. Today, we know that this is true not only for nucleated eukaryotic cells but also for prokaryotic cells lacking a nucleus. The interior of a cell is surrounded by a membrane that separates it from its external environment. This membrane is called the cell membrane or plasma membrane and it is semipermeable; that is, the traffic of substances across this membrane in either orientation is restricted to some specific molecular species or specifically controlled by proteins of the membrane that handle the transport. Fundamental to eukaryotic cells – in contrast to prokaryotic cells – is their subdivision by intracellular membranes into distinct compartments. Figure 13.8 illustrates the general structure of a eukaryotic cell as found in animals. Generally, one distinguishes between the storage compartment of the DNA, the nucleus, and the remainder of the cell interior that is located in the cytoplasm. The cytoplasm contains further structures that fulfill specific cellular functions and that are surrounded by the cytosol. Among these cytoplasmic organelles are the endoplasmic reticulum (ER), which forms a widely spread intracellular membrane system; the mitochondria, which are the cellular power plants; the Golgi complex; transport vesicles; peroxisomes; and, additionally in plant cells, chloroplasts, which act as sunlight harvesting systems performing photosynthesis, and the vacuole. In the following sections, we will describe the structure and function of biological membranes and the most important cellular compartments that are formed by them.

Figure 13.8 Schematic illustration of an animal cell with its major organelles.
13.3.1 Structure and Function of Biological Membranes
All cells are surrounded by a plasma membrane. It not only separates the cell plasma from its surrounding environment but also acts as a selective filter for nutrients and by-products. By active transport of ions, for which the energy source ATP is usually utilized, a chemical and/or electrical potential can be established across the membrane that is essential, for example, for the function of nerve cells. Furthermore, receptor proteins of the plasma membrane enable the transmission of external signals that enable the cell to react to its environment. As already mentioned, eukaryotes additionally possess an intracellular membrane system acting as a boundary for different essential compartments.
The assembly of a bilayer, which is the fundamental structure of all biological membranes, is described in the section about lipids (Section 13.2.3; cf. also Figure 13.9a). Biological membranes are composed of this molecular bilayer of lipids (mainly phospholipids, but also cholesterol and glycolipids) and membrane proteins that are inserted and held in the membrane by noncovalent forces. Besides integral membrane proteins, proteins can also be attached to the surface of the membrane (peripheral proteins). This model of biological membranes is known as the fluid mosaic model and was introduced by Singer and Nicolson [5] (Figure 13.9b). Furthermore, they proposed a possible asymmetric arrangement of adjoining monolayers caused by different lipid composition and orientation of integral proteins, as well as specific occurrence of peripheral proteins in either of the monolayers. In the plasma membrane, for example, glycolipids always point to the exterior. While an exchange of lipid molecules between the two monolayers – a so-called flip-flop – very rarely occurs by mere chance, lateral movement of lipid molecules takes place frequently. This can also be observed with proteins as long as their movement is not prevented by interaction with other molecules. Lateral movement of lipids depends on the fluidity of the bilayer. The fluidity is strongly enhanced if one of the hydrocarbon chains of the phospholipids is unsaturated and the membrane contains a specific amount of cholesterol.
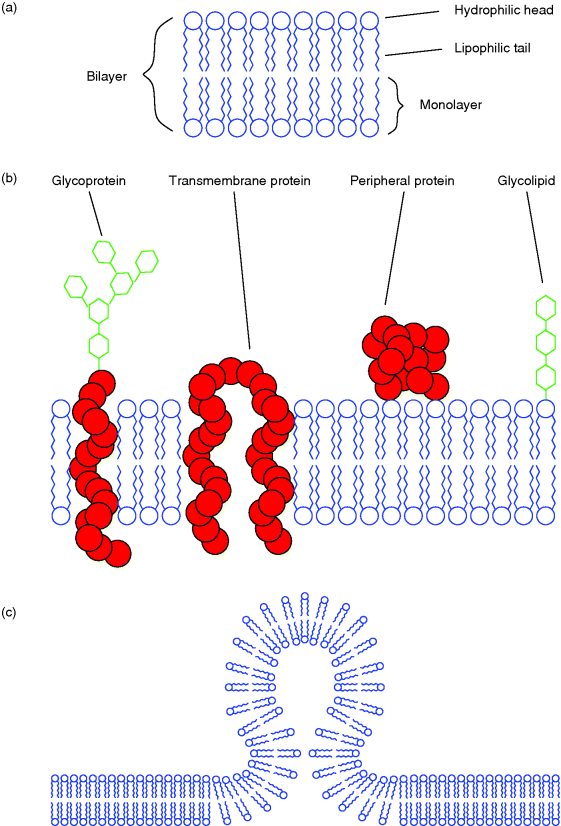
Figure 13.9 (a) In a lipid bilayer, the amphipathic lipids are oriented to both aqueous compartments with their hydrophilic parts. The hydrophobic tails point to the inner membrane space. (b) The fluid mosaic model of a cellular membrane. (c) Formation of a spherical vesicle that is in the process of either pinching off from or fusing with a membrane. Such vesicles are formed during endo- or exocytosis by peripheral proteins inducing the process.
An important feature of biological membranes is their ability to form a cavity that pinches off as a spherical vesicle, and the reverse process in which the membrane of a vesicle fuses with another membrane and becomes a part of it (Figure 13.9c). This property is utilized by eukaryotic cells for vesicular transport between different intracellular compartments and for the exchange of substances with the exterior. The latter process is termed exocytosis when proteins produced by the cell are secreted to the exterior and endocytosis or phagocytosis when extracellular substances are taken up by the cell.
There are two different kinds of exocytosis. The first one is a constitutive secretion: synthesized proteins packed into transport vesicles at the Golgi complex move to the plasma membrane and fuse with it, thereby delivering their payload to the exterior. This happens, for example, with proteins intended for the extracellular matrix. In the second case termed regulated exocytosis, the proteins coming from the Golgi complex via transport vesicles are enriched in secretory vesicles that deliver their content usually due to an external signal recognized by a receptor and further transmitted via second messengers (e.g., Ca2+). This pathway is common, for example, to neurotransmitters secreted by neurons or digestive enzymes produced by acinar cells of the pancreas.
Vesicular transport is important for large molecules such as proteins. For smaller molecules (e.g., ions or glucose), there are alternative mechanisms. In the case of passive transport, the flux takes place along an osmotic or electrochemical concentration gradient and requires no expenditure of cellular energy. Therefore, either the molecules can diffuse through the membrane or, since especially polar and charged substances cannot pass this hydrophobic barrier, transport is mediated selectively by integral transmembrane proteins. Other transmembrane proteins enable an active transport against a concentration gradient that requires cellular energy (e.g., ATP).
Sensing of exterior conditions and communication with other cells are often mediated by receptors of the cell membrane that tackle the signal transmission. Alternatively, mostly hydrophobic substances such as steroid and thyroid hormones can cross the cell membrane directly and interact with receptors in the cell's interior. A general overview of biochemistry of signal transduction is given, for example, by Krauss [6].
Besides the plasma membrane, plant cells are further surrounded by a cell wall with cellulose, a polysaccharide, as main polymer forming the fundamental scaffold. Prokaryotes also often have a cell wall where different monosaccharides act as building blocks for the polymer.
13.3.2 Nucleus
Prokaryotes store their hereditary information – their genome – in a single, circular, double-stranded DNA (located in a subregion of the cell's interior called the nucleoid) and optionally in one or several small, circular DNAs (the plasmids), which code for further genes. The genome of eukaryotes is located in the cell nucleus and forms the chromatin that is embedded into the nuclear matrix and has dense regions (heterochromatin) and less dense regions (euchromatin). The nucleus occupies about 10% of the cellular volume and is surrounded by the nuclear envelope formed by an extension of the ER that creates a double membrane. The nuclear envelope has several protein complexes that form nuclear pores and that are responsible for the traffic between the nucleus and the cytosol. A subregion of the chromatin in which many repeats of genes encoding ribosomal RNAs (rRNAs) are located appears as a roughly spherical body called nucleolus.
The structure of the chromatin usually becomes optically clearer during cell division, when the DNA strands condense into chromosomes, each consisting of two DNA double strands called chromatids. Both chromatids are joined at the centromere. The ends of the chromatids are called telomeres. At the molecular level, the DNA of a chromosome is highly ordered: The double strand is wound around protein complexes, the histones, and each DNA/histone complex is called a nucleosome.
13.3.3 Cytosol
The cytosol fills the space between the organelles of the cytoplasm. It represents about half of the cell volume and contains the cytoskeletal framework. This fibrous network consists of different protein filaments that constitute a general framework and are responsible for the coordination of cytoplasmic movements. These activities are controlled by three major types of protein filaments: the actin filaments (also called microfilaments), the microtubules, and the intermediate filaments.
The long stretched actin filaments, with a diameter of about 5–7 nm, are built up of globular actin proteins. One major task of actin filaments is the generation of motility during muscle contraction. For the generation of movement, actin filaments slide along another filament type called myosin. This ATP-consuming process is driven by a coordinated interaction of these proteins. Together with other proteins involved in the regulation of muscle activity, these filaments form very regular structures in muscle cells. Furthermore, in many animal cells, actin filaments associated with other proteins are often located directly under the plasma membrane in the cell cortex and form a network that enables the cell to change its shape and to move.
Another filament type found in eukaryotes are the microtubules. They consist of heterodimers of the proteins α- and β-tubulin, which form unbranched cylinders of about 25 nm in diameter with a central open channel. These filaments are involved, for example, in rapid motions of flagella and cilia, which are hair-like cell appendages. Flagella are responsible for the movement of, for example, sperm and many single-celled eukaryotic protists. Cilia occur, for instance, on epithelial cells of the human respiratory system. The motion of a cilia or flagella is due to the bending of a complex internal structure called axoneme. Almost all kinds of cilia and eukaryotic flagella have nearly the same characteristic structure of the axoneme. This is called the 9 + 2 structure, because of its appearance: nine doublets that look like two condensed microtubules form a cylinder together with other associated proteins, the center of which contains two further single microtubules. The flexibility of the axoneme is also an ATP-consuming process that is further assisted by the protein dynein.
The third major filament type of the cytoskeleton is the intermediate filament. In contrast to actin filaments and microtubules, which are built of globular proteins, intermediate filaments consist of fibrous proteins. Several subtypes of these filaments are known, for example, keratin filaments in the cytosol of epithelial cells, which make these cells resistant against mechanical influence, or lamin filaments, which are involved in the formation of the nuclear lamina.
Furthermore, the cytosol contains ribosomes responsible for protein synthesis, and is filled with thousands of metabolic enzymes. A central metabolic pathway that is catalyzed by some of these enzymes is the glycolysis. Substrates of this pathway are glucose or some similar six-carbon derivatives of it. These substrates are converted by several reactions into two molecules of the three-carbon compound pyruvate. Each metabolized glucose molecule generates two molecules of ATP, and one NAD+ (the oxidized form of nicotinamide adenine dinucleotide) is reduced to NADH. But via this pathway – which does not involve molecular oxygen – only a small amount of the energy that can be gained through oxidation of glucose is made available. In aerobic organisms, the bulk of ATP is produced from pyruvate in the mitochondria (see the following section).
13.3.4 Mitochondria
Mitochondria have a spherical or elongated shape and are about the size of a bacterium. Their interior is surrounded by two membranes: a highly permeable outer membrane and a selective inner membrane. Therefore, mitochondria have two internal compartments, the intermembrane space and the matrix. The outer membrane is permeable for ions and most of the small molecules due to several transmembrane channel proteins called porins. The inner membrane's surface area is strongly increased by numerous folds and tabular projections into the mitochondrial interior, which are called cristae. Mitochondria are partially autonomous: they possess their own DNA and enzymatic complexes required for protein expression (such as ribosomes and mRNA polymerase). Nevertheless, they depend on the symbiosis with their cell since most genes of mitochondrial proteins left the mitochondrial chromosome during evolution and are encoded by the nuclear DNA today. These mitochondrial proteins are synthesized in the cytoplasm and are then imported into the organelle.
As mentioned above, the bulk of ATP (34 out of 36 molecules per metabolized glucose molecule) is gained in mitochondria; thus, they can be termed the “power plants” of eukaryotic cells. The underlying oxidative process that involves molecular oxygen and yields CO2 and ATP is driven mainly by pyruvate from the glycolysis and fatty acids. Both pyruvate and fatty acids can be converted into acetyl-CoA molecules. Acetyl-CoA has an acetyl group (CH3CO−, a two-carbon group consisting of a methyl group and a carbonyl group) that is covalently liked to coenzyme A (CoA). Cytosolic pyruvate can pass the outer mitochondrial membrane and enter the mitochondrial matrix via a transporter of the inner membrane. Pyruvate is then converted into acetyl-CoA by a huge enzyme complex called pyruvate dehydrogenase. Acetyl-CoA reacts with oxaloacetate and thus enters the citrate cycle, a sequence of several reactions during which two CO2 molecules and energetic reduction equivalents (mainly NADH, but also FADH2) are produced. Finally, oxaloacetate is regenerated and thus the cycle is closed. The electrons delivered by the reduction equivalents are further transferred step by step onto O2, which then reacts together with H+ ions to form water. The huge amount of energy provided by this controlled oxyhydrogen reaction is used subsequently for the transfer of H+ ions out of the mitochondrial matrix, thus establishing a H+ gradient across the inner membrane. The energy provided by this very steep gradient is used by another protein complex of the inner mitochondrial membrane – the ATP synthase – for the production of ATP inside the mitochondrial matrix by a flux of H+ from the intermembrane space back into the matrix. This coupled process of oxidation and phosphorylation is called the oxidative phosphorylation. The complete aerobic oxidation of glucose produces as many as 36 molecules of ATP:
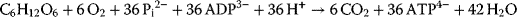
13.3.5 Endoplasmic Reticulum and Golgi Complex
The endoplasmic reticulum is a widely spread cytosolic membrane system that forms tubular structures and flattened sacs. Its continuous and unbroken membrane encloses a lumen that stays in direct contact with the perinuclear space of the nuclear envelope. The ER occurs in two forms: the rough ER and the smooth ER. The rough ER forms mainly flattened sacs and has many ribosomes that are attached to its cytosolic surface; the smooth ER lacks ribosomes and forms mostly tubular structures. Proteins destined for secretion but also intended for the ER itself, the Golgi complex, the lysosomes, or the outer plasma membrane enter the lumen of the ER directly after being synthesized by ribosomes of the rough ER. The total amount of ER membranes of a cell as well as the ratio of smooth and rough ER varies strongly depending on species and cell type. All enzymes required for biosynthesis of membrane lipids, such as phosphatidylcholine, phosphatidylethanolamine, or phosphatidylinositol, are located in the ER membrane, their active centers facing the cytosol. Membrane lipids synthesized by these enzymes are integrated into the cytosolic part of the ER bilayer. Since this would result in an imbalance of lipids in the two layers of the membrane, phospholipid translocators can increase the flip-flop rate for specific membrane lipids; thus, the lipid imbalance can be compensated and the membrane asymmetry concerning specific membrane lipids can be established. Furthermore, the ER can form transport vesicles responsible for the transfer of membrane substance and proteins to the Golgi complex.
The Golgi complex (also called Golgi apparatus), usually located in vicinity of the nucleus, consists of piles of several flat membrane cisternae. ER transport vesicles enter these piles at its cis-side. Substances leave the Golgi complex at the opposite trans-side. Transport between the different cisternae is mediated by Golgi vesicles. Some modifications of proteins by the addition of a specific oligosaccharide happen in the ER, but further glycosylations of various types take place in the lumen of the Golgi complex. Since such modified membrane proteins and lipids point to the organelles' inner space, they will be exposed to the cell's outer space when they are transported to the plasma membrane. The synthesis of complex modifications by several additions of carbohydrates requires a special enzyme for each specific addition. Therefore, these reaction pathways become very complex.
13.3.6 Other Organelles
Eukaryotic cells have further compartments for certain functions. Some of these organelles and their major functions will be mentioned briefly here.
Lysosomes are responsible for the intracellular digestion of macromolecules. These vesicular organelles contain several hydrolyzing enzymes (hydrolases), for example, proteases, nucleases, glycosidases, lipases, phosphatases, and sulfatases. All of them have their optimal activity at pH 5. This pH value is maintained inside the lysosomes via ATP-dependent H+ pumps (for comparison, the pH of the cytosol is about 7.2).
Peroxisomes (also called microbodies) contain enzymes that oxidize organic substances (R) and use therefore molecular oxygen as an electron acceptor. This reaction produces hydrogen peroxide (H2O2).
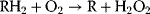
H2O2 is used by peroxidase to further oxidize substances such as phenols, amino acids, formaldehyde, and ethanol, or it is detoxified by catalase (2 H2O2 → 2 H2O + O2).
In contrast to the ER, the Golgi cisternae, lysosomes, peroxisomes, and vesicles, which are surrounded by a single membrane, chloroplasts, as well as mitochondria, have a double membrane of which the inner one is not folded into cristae as in mitochondria. Instead, a chloroplast has a third membrane that is folded several times and forms areas that look like piles of coins. This membrane contains light harvesting complexes and ATP synthases that utilize the energy of the sunlight for the production of cellular energy and reduction equivalents used for the fixation of carbon dioxide (CO2) into sugars, amino acids, fatty acids, or starch. Chloroplasts, as well as mitochondria, have own circular DNA and ribosomes.
13.4 Expression of Genes
Classically, a gene is defined as the information encoded by the sequence of a DNA region that is required for the construction of an enzyme or – more generally – of a protein. We will see that this is a simplified definition, since, for example, mature products of some genes are not proteins but RNAs with specific functions; eukaryotic gene sequences in particular also contain noncoding information. The term gene expression commonly refers to the whole process during which the information of a particular gene is translated into a particular protein. This process involves several steps. First, during transcription (Figure 13.10,  ), the DNA region encoding the gene is transcribed into a complementary messenger RNA (mRNA). In eukaryotic cells, this mRNA is further modified (
), the DNA region encoding the gene is transcribed into a complementary messenger RNA (mRNA). In eukaryotic cells, this mRNA is further modified ( ) inside the nucleus and transferred to the cytosol (
) inside the nucleus and transferred to the cytosol ( ). In the cytosol, the mRNA binds to a ribosome that uses the sequence as a template for the synthesis of a specific polypeptide that can fold into the three-dimensional protein structure (
). In the cytosol, the mRNA binds to a ribosome that uses the sequence as a template for the synthesis of a specific polypeptide that can fold into the three-dimensional protein structure ( ). In prokaryotic cells, the mRNA is not further modified and ribosomes can bind to the nascent mRNA during transcription.
). In prokaryotic cells, the mRNA is not further modified and ribosomes can bind to the nascent mRNA during transcription.
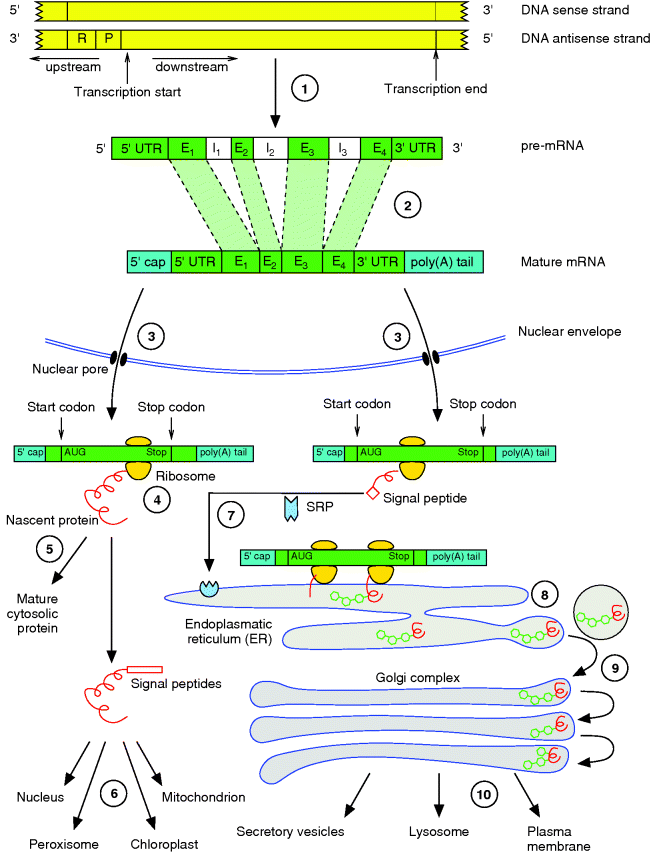
Figure 13.10 Gene expression in eukaryotic cells comprises several steps from the DNA to the mature protein at its final destination. This involves the () transcription of the gene, () splicing and processing of the pre-mRNA, () export of the mature mRNA into the cytosol, () translation of the genetic code into a protein, and ( –
– ) several steps of sorting and modification. More details are given in the text.
) several steps of sorting and modification. More details are given in the text.
In eukaryotic cells, the synthesized proteins can either remain in the cytosol () or, if they have a specific signaling sequence, be synthesized by ribosomes of the rough ER and enter its lumen (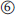 ). However, there are several mechanisms of directing each protein to its final destination. During this sorting, proteins are often modified, for example, by cleavage of signaling peptides or by glycosylations.
). However, there are several mechanisms of directing each protein to its final destination. During this sorting, proteins are often modified, for example, by cleavage of signaling peptides or by glycosylations.
All the genes of a single organism make up its genome. But only a subset of these genes will be expressed at a particular time or in a specific cell type. Some genes fulfill basic functions of the cell and are always required; these are called constitutive or housekeeping genes. Others are expressed only under certain conditions. The amount of a gene product, for example, a protein, depends mainly on its stability and the number of its mRNA templates. The number of the latter depends on the transcription rate, which is influenced by regulatory regions of the gene and transcription factors that control the initialization of transcription. Thus, quantitative changes in gene expression can be monitored by mRNA and protein concentrations (see Chapter 14 on experimental techniques used for this purpose). Rate changes in any production or degradation step of a specific gene product, which might happen in different cell types or developmental stages, can lead to differential gene expression.
The whole procedure of gene expression, protein sorting, and posttranslational modifications is summarized in Figure 13.10 and will be described in more detail in the following sections.
13.4.1 Transcription
The synthesis of an RNA polymer from ATP, GTP, CTP, and UTP employing a DNA region as a template is called transcription. RNA synthesis is catalyzed by the RNA polymerase. In eukaryotic cells, there are different types of this enzyme that are responsible for the synthesis of different RNA types, including mRNA, rRNA, or transfer RNA (tRNA). In prokaryotic cells, all these different RNA types are synthesized by the same polymerase. This enzyme has an affinity to a specific DNA sequence, the promoter, that also indicates the first base to be copied. During initiation of transcription, the RNA polymerase binds to the promoter with a high affinity that is supported by further initiation factors. Complete formation of the initiation complex causes the DNA to unwind in the promoter region. Now the enzyme is ready to add the first RNA nucleoside triphosphate to the template strand of the opened DNA double strand. In the subsequent elongation phase, the RNA polymerase moves along the unwinding DNA and extends the newly developing mRNA continuously with nucleotides complementary to the template strand. During this phase, a moving transient double-stranded RNA–DNA hybrid is established. As the polymerase moves along, the DNA rewinds again just behind it. As RNA synthesis always proceeds in the 5′ → 3′ direction, only one of the DNA chains acts as template, the so-called antisense (−) strand. The other one, the sense (+) strand, has the same sequence as the transcribed RNA, except for the thymine nucleotides that are replaced by uracil nucleotides in RNA. As much as the promoter is responsible for initiation of transcription, the terminator – another specific DNA sequence – is responsible for its termination. For the bacterium Escherichia coli, two different termination mechanisms are described: the Rho-independent and the Rho-dependent termination. In Rho-independent termination, the transcribed terminator region shows two short GC-rich and self-complementary sequences that can bind to each other and thus form a so-called hairpin structure. This motif is followed by a block of uracil residues that bind the complementary adenine residues of the DNA only weakly. Presumably, this RNA structure causes the RNA polymerase to terminate and release the RNA. In Rho-dependent termination, a protein – the Rho factor – can bind the newly synthesized RNA near the terminator and mediate the RNA release. Termination in eukaryotic cells shows both similarities to and differences from the mechanisms found in bacteria.
13.4.2 Processing of the mRNA
In eukaryotic cells, the primary mRNA transcript (precursor mRNA or pre-mRNA) is further processed before being exported into the cytosol and entering translation (Figure 13.10, ). The protein-coding sequence lies internally in the mRNA and is flanked on both sides by nucleotides that are not translated. During processing, a so-called 5′ cap is attached to the flanking 5′ untranslated region (5′ UTR, about 10–200 nucleotides) preceding, or lying upstream of, the coding sequence. This 5′ cap consists of three nucleotides that are further modified. The 3′ untranslated region (3′ UTR) of most mRNAs is also modified after transcription by addition of a series of about 30–200 adenine nucleotides that are known as the poly(A) tail. Furthermore, the pre-mRNA is often much longer than the mature RNA because the coding sequence is often interrupted by one or several intervening sequences called introns, which do not occur in the mature mRNA exported to the cytosol. These intron sequences are removed during processing by a mechanism called splicing. The remaining sequences are called exons. The final coding sequence thus consists of a series of exons joined together. It starts with AUG, which is the first triplet being translated into an amino acid, and it stops with a stop codon (UGA, UAA, or UAG). Via the pores of the nuclear envelope, the mature mRNA is finally exported to the cytoplasm, where the translation process takes place.
13.4.3 Translation
Translation of the genetic information encoded by the mRNA into the amino acid sequence of a polypeptide is done by ribosomes in the cytosol. To encode the 20 different amino acids occurring in polypeptides, at least three bases out of the four possibilities (G, U, T, C) are necessary (43 = 64 > 20). During evolution, a code developed that uses such triplets of exactly three bases, which are called codons, to code the amino acids and signals for start and end of translation. By using three bases for each codon, more than 20 amino acids can be coded, and hence some amino acids are encoded by more than one triplet. The genetic code is shown in Table 13.3. It is highly conserved across almost all prokaryotic and eukaryotic species except for some mitochondria or chloroplasts. For translation of the genetic information, adapter molecules are required. These are the transfer RNAs. They consist of about 80 nucleotides and are folded into a characteristic form similar to an “L”. Each tRNA can recognize a specific codon by a complementary triplet, called an anticodon, and it can also bind the appropriate amino acid. For each specific tRNA, a certain enzyme (aminoacyl tRNA synthetase) attaches the right amino acid to the tRNA's 3′ end. Such a loaded tRNA is called an aminoacyl tRNA.
Table 13.3 The genetic code.
| Position 2 | Position 3 (3′ end) | ||||
| Position 1 (5′ end) | U | C | A | G | |
| U | Phe | Ser | Tyr | Cys | U |
| Phe | Ser | Tyr | Cys | C | |
| Leu | Ser | Stop | Stop | A | |
| Leu | Ser | Stop | Trp | G | |
| C | Leu | Pro | His | Arg | U |
| Leu | Pro | His | Arg | C | |
| Leu | Pro | Gln | Arg | A | |
| Leu | Pro | Gln | Arg | G | |
| A | Ile | Thr | Asn | Ser | U |
| Ile | Thr | Asn | Ser | C | |
| Ile | Thr | Lys | Arg | A | |
| Met | Thr | Lys | Arg | G | |
| G | Val | Ala | Asp | Gly | U |
| Val | Ala | Asp | Gly | C | |
| Val | Ala | Glu | Gly | A | |
| Val | Ala | Glu | Gly | G | |
| Each codon of the genetic code – read in the 5′ → 3′ direction along the mRNA – encodes a specific amino acid or a starting or termination signal of translation. | |||||
During translation (Figure 13.11), the genetic information of the mRNA is read codon by codon in the 5′ → 3′ direction of the mRNA, starting with an AUG codon. AUG codes for methionine, and therefore newly synthesized proteins always begin with this amino acid at their amino terminus. Protein biosynthesis is catalyzed by ribosomes. Both eukaryotic and prokaryotic ribosomes consist of a large and a small subunit, and both subunits are composed of several proteins and rRNAs. In eukaryotic cells, the small ribosomal subunit first associates with an initiation tRNA (Met-tRNAi) and binds the mRNA at its 5′ cap. Once attached, the complex scans along the mRNA until reaching the start AUG codon. In most cases, this is the first AUG codon in the 5′ → 3′ direction. This position indicates the translation start and determines the reading frame. Finally, during initiation the large ribosomal subunit is added to the complex and the ribosome becomes ready for protein synthesis. Each ribosome has three binding sites: one for the mRNA and two for tRNAs. In the beginning, the first tRNA binding site, also called P site, contains the initiation tRNA. The second or A site is free to be occupied by an aminoacyl tRNA that carries an anticodon complementary to the second codon. Once the A site is filled, the amino acid at the P site, which is the methionine, establishes a peptide bond with the amino group of the amino acid at the A site. Now the unloaded tRNA leaves the P site and the ribosome moves one codon further downstream. Thus, the tRNA carrying the dipeptide enters the P site and the A site is open for another aminoacyl tRNA, which is complementary to the third codon in sequence. This cycle is repeated until a stop codon (UAA, UAG, or UGA) is reached. Then the newly synthesized polypeptide detaches from the tRNA and the ribosome releases the mRNA. It is obvious that the addition or alteration of nucleotides of a gene can lead to changes in the reading frame or to the insertion of false amino acids, which might result in malfunctioning proteins. Such changes can happen by mutations, which are random changes of the genomic sequence of an organism that either occur spontaneously or are caused by chemical substances or radiation. A mutation can be either an exchange of a single nucleotide by another or some larger rearrangement. Even the exchange of a single nucleotide by another might severely influence the function of an enzyme, if it occurs, for example, in the sequence coding for its active site.
Figure 13.11 During translation, the genetic information of the mRNA is converted into the corresponding polypeptide. More details are given in the text.
13.4.4 Protein Sorting and Posttranslational Modifications
Cells possess a sorting and distribution system that routes newly synthesized proteins to their intra- or extracellular destination. This is mediated by signal peptides – short sequences of the polypeptide occurring at diverse positions. The sorting begins during translation when the polypeptide is synthesized by either a free ribosome or one that becomes attached to the ER membrane. The latter occurs if the growing polypeptide has a signal sequence at its amino terminus that can be recognized by a specific signal recognition particle (SRP) that routes it to a receptor located in the ER membrane (Figure 13.10, ). Such polypeptides are transferred into the ER lumen, where the signal peptide is cleaved off.
Peptides synthesized in the cytosol (Figure 13.10, ) either remain in the cytosol (), if not possessing a specific signal sequence, or are routed further to a mitochondrion, chloroplast, peroxisome, or the nucleus ( ).
).
The nuclear localization sequence (NLS) is usually located inside the primary sequence of the protein and is not found terminally; thus, it is not cleaved from the protein as happens with many other signal peptides. Similarly, some transmembrane proteins synthesized by ribosomes of the rough ER have internal signal peptides that are required for correct routing to the membrane.
Polypeptides entering the ER after synthesis are usually further modified by glycosylations, where oligosaccharides are bound to specific positions of the newly synthesized proteins ( ). Most proteins entering the ER do not remain in the ER but are transferred via transport vesicles to the Golgi complex (
). Most proteins entering the ER do not remain in the ER but are transferred via transport vesicles to the Golgi complex ( ), where further modifications of the bound oligosaccharides and additional glycosylations take place. If the proteins are not intended to remain in the Golgi complex, they are further transferred into lysosomes or secretory vesicles or they become transmembrane protein complexes of the plasma membrane ().
), where further modifications of the bound oligosaccharides and additional glycosylations take place. If the proteins are not intended to remain in the Golgi complex, they are further transferred into lysosomes or secretory vesicles or they become transmembrane protein complexes of the plasma membrane ().
13.4.5 Regulation of Gene Expression
The human genome presumably contains about 20 000–25 000 protein-coding genes, with an average coding length of about 1400 base pairs (bp) and an average genomic extent of about 30 kb (1 kb = 1000 bp). This would mean that only about 1.5% of the human genome consists of coding sequences and only one-third of the genome would be transcribed in genes [7,8]. Besides coding sequences, also regulatory sequences are known that play important roles in particular through control of replication and transcription. The remaining noncoding genomic DNA that does not yet appear to have any function is often referred to as “junk DNA.”
Since only a small subset of all the genes of an organism must be expressed in a specific cell (e.g., detoxification enzymes produced by liver cells are not expressed in epidermal cells), there must be regulatory mechanisms that repress or specifically induce the expression of genes. This includes mechanisms that control the level of gene expression.
In 1961, François Jacob and Jacques Monod proposed a first model for the regulation of the lac operon, a genetic region of the E. coli genome that codes for three genes required for the utilization of the sugar lactose by this bacterium. These genes are activated only when glucose is missing but lactose, as an alternative carbon source, is present in the medium. The transcription of the lac genes is under the control of a single promoter, which overlaps with a regulatory region lying downstream called operator to which a transcription factor, a repressor, can bind. Jacob and Monod introduced the term operon for such a polycistronic gene. (The term cistron is defined as the functional genetic unit within which two mutations cannot complement. The term is often used synonymous with gene and describes the region of DNA that encodes a single polypeptide [or functional RNA]. Thus, the term polycistronic refers to a DNA region encoding several polypeptides. Polycistronic genes are known only for prokaryotes.)
Besides the negative regulations or repressions mediated by a repressor, positive regulations or activations that are controlled by activators are also known. An activator found in E. coli that is also involved in the catabolism of alternative carbon sources is the catabolite activator protein (CAP). Since the promoter sequence of the lac operon shows only low agreement to the consensus sequence of normal E. coli promoters, the RNA polymerase has only a weak affinity to it. (The consensus sequence of a promoter is a sequence pattern that shows highest sequence similarity to all promoter sequences to which a specific RNA polymerase can bind.) The presence of CAP, which indicates the lack of glucose, enhances the binding affinity of RNA polymerase to the lac promoter and thus supports the initiation of transcription.
The regulation of gene expression in eukaryotic cells is more complicated than in prokaryotic cells. In contrast to the bacterial RNA polymerase that recognizes specific DNA sequences, the eukaryotic enzymes require a protein/DNA complex that is established by general transcription factors. One of these transcription factors (TFIIB) binds the so-called TATA-box – a promoter sequence occurring in most protein-coding genes with the consensus sequence TATAAA. Besides these general transcription factor binding sites, most genes are further regulated by a combination of sequence elements lying in the vicinity of the promoter and enhancer sequence elements located up to 1000 nucleotides or more upstream of the promoter.
Regulation of gene expression not only is carried out by transcriptional control but can also be controlled during processing and export of the mRNA into the cytosol, by the translation rate, by the decay rates of the mRNA and the protein, and by control of the protein activity.
Exercises
- 13.1.What are the different structures and conformations a protein can have and by which properties is the protein conformation defined?
- 13.2.Why is it necessary that the protein sequences are encoded in the DNA by nucleotide triplets and not by nucleotide duplets?
- 13.3.Why are proteins of thermophilic bacteria not rapidly denatured by the high temperatures these organisms are exposed to?
- 13.4.What is the purpose of posttranslational modifications? List six functional groups that are used for posttranslational modifications.
- 13.5.What is the purpose of introns and why do eukaryotes have introns but prokaryotes do not?
- 13.6.What is the benefit of cellular compartments?
- 13.7.Why do most transmembrane proteins have their N-terminus outside and the C-terminus inside?
- 13.8.If a eukaryotic cell has lost all its mitochondria (let's say during mitosis one daughter cell got none), how long does it take to regrow them?
References
- 1. Alberts, B. et al. (2008) Molecular Biology of the Cell, Garland Science.
- 2. Reece, J.B. et al. (2013) Campbell Biology, Pearson.
- 3. Miller, S.L. and Urey, H.C. (1959) Organic compound synthesis on the primitive earth. Science, 130, 245–251.
- 4. Wächtershäuser, G. (1988) Before enzymes and templates: theory of surface metabolism. Microbiol. Rev., 52, 452–484.
- 5. Singer, S.J. and Nicolson, G.L. (1972) The fluid mosaic model of the structure of cell membranes. Science, 175, 720–731.
- 6. Krauss, G. (2003) Biochemistry of Signal Transduction and Regulation, 3rd edn, Wiley-VCH Verlag GmbH, Weinheim.
- 7. Lander, E.S. et al. (2001) Initial sequencing and analysis of the human genome. Nature, 409, 860–921.
- 8. Venter, J.C. et al. (2001) The sequence of the human genome. Science, 291, 1304–1351.
Further Reading
- Alberts, B., Johnson, A., Lewis, J., Morgan, D., Raff, M., Roberts, K., and Walter, P. (2014) Molecular Biology of the Cell, 6th edn, Garland Science.