Chapter 9
Writing the Disaster Recovery Plan
In This Chapter
![]() Deciding what goes into your DR plan
Deciding what goes into your DR plan
![]() Giving the DR plan structure
Giving the DR plan structure
![]() Managing development of the DR plan
Managing development of the DR plan
![]() Preserving the DR plan
Preserving the DR plan
The job isn’t done until the paperwork’s done.
Nowhere is this pithy saying truer than in disaster recovery planning. The paperwork in DR planning outlines how to jump-start the business when the big one hits. Depending on where your business is located, the big one may be an earthquake, labor strike, hurricane, flood, or a swarm of locusts.
The paperwork for DR planning simply covers the procedures and other documents that business personnel must refer to in order to get things going again after a disaster. The DR planning procedures are especially important because people who aren’t the foremost experts on the systems that support critical business processes may have to read and follow those procedures. Those people have to rebuild critical systems in a short period of time so those systems can support critical processes. And the people performing those processes probably aren’t subject matter experts at the business process level.
The business’s survival depends on the paperwork being right. You don’t get any second chances.
In this chapter, I explain how to actually write down the DR plan.
You just love documentation, right? Thought so.
Determining Plan Contents
Before embarking on the task of actually writing the DR plan, the team needs to agree what the DR plan is. You can describe it something like this:
The disaster recovery plan is the set of documents that describes post-disaster emergency response, damage assessment, and system restart for designated critical business processes.
The devil, as they say, is in the details.
DR plans should contain several key elements that you can use to jumpstart critical systems and processes after a disaster strikes. Most organizations should include the following elements in their DR plan:
 A disaster-declaration procedure
A disaster-declaration procedure
Emergency contact lists and trees
Emergency leadership selection (the predetermined leadership team and also the procedure to quickly assemble a team)
Damage assessment procedures
System recovery and restart procedures
Procedures for the transition to normal operations
Recovery team selection (the pre-selected recovery team, as well as the process for finding others who can help when disaster actually strikes)
I cover these elements in greater detail in the following sections.
Disaster declaration procedure
Disaster recovery procedures commence when somebody says so. And when does someone say so? When a disaster has occurred.
I’m sorry if this sounds silly. Many DR planners get too hung up on how to declare a disaster. Here are a few ideas for how to declare a disaster, one of which may work for you:
Declaration by consensus: You designate a core team of decision makers, probably middle or senior managers, as the DR leadership team. When a disaster occurs, the core team members contact one another and perhaps convene a conference call, if they can. When two or more of the core team members agree that the organization should start the disaster recovery plan, they make that decision. This decision triggers the execution of the DR plan. A typical declaration might go something like this:
1. The event occurs.
2. Two or more DR plan core team members discuss the event by telephone, if possible. They exchange information about what they know of the event and the potential impact on the business.
3. Two or more core team members conclude that the event has sufficient impact on the business to affect business operations.
4. The core team members decide to declare a disaster, which triggers disaster response and recovery actions, including performing emergency communications and action plans that assess damage and begin restoration of services.
You don’t need to make your disaster declaration procedure much more complicated than the preceding steps.

Core team members may or may not be near the business facility when they need to make a direct assessment of the event’s impact. They can make a judgment call and decide based on what they know at the time, or they can choose to gather more information before making a declaration.
Declaration by criteria: Designate core team members as the DR leadership team. When an event occurs, one or more of them reads a short checklist, which might be a series of Yes or No questions. If certain answers, or a minimum number of answers, are Yes, the team declares a disaster, which triggers the DR plan. Here’s how this process might play out in a disaster:
1. A weather-related event occurs that has widespread impact on a city.
2. DR plan core team members begin to contact one another to share information about the situation.
3. Available core team members answer basic questions on their disaster declaration checklists. The core team members decide that the results of the checklist warrant a disaster declaration. If they can’t come to a consensus, either they have to gather more information or just decide one way or the other.
4. The core team declares a disaster and begins to notify other core team members, instructing them to begin working through their DR plan procedures to assess, contain, and begin recovery from the disaster.
Over the years, I’ve heard many people express the same concern: What if an organization declares a disaster unnecessarily? The short answer: Don’t worry about it. If the core team declares a disaster, and they later decide that the situation isn’t so bad, they can just call a halt to the disaster response. For example, if a severe weather event results in widespread utility outages and transportation problems, an organization might initially declare a disaster but later cancel the disaster response effort when it discovers that critical IT systems are only lightly isolated and quickly recoverable, despite feet of snow, inches of water, volcanic ash, or whatever prompted the disaster declaration.
You can make disaster declaration as scientific or unscientific as you need it to be. Don’t make it too complicated, or the core team members may hesitate to declare a disaster if they can’t decide whether they should.
Emergency contact lists and trees
After you declare a disaster, the logical next step in a comprehensive plan is to begin notifying the personnel who are responsible for performing DR-plan-related activities, such as communications, assessment, and recovery. The DR plan core team members who participate in the disaster declaration obviously know first when the organization declares a disaster, and the notifications move out from there to additional disaster response personnel, management, personnel who communicate with suppliers and customers, and so on.
Where will DR planning core team members be when a disaster occurs? The decidedly unscientific method in this section is based on simple probabilities.
A seven-day period contains five workdays, which total 168 hours. Presuming that a core team member has a life, Table 9-1 shows the probability breakdown for employees’ possible activities, giving you an idea of where people may be when the disaster strikes.
| Hours | Percent of Work Week | Activity | |
|---|---|---|---|
| 48 | 28.6 | Sleeping | |
| 48 | 28.6 | Working at place of employment | |
| 40 | 23.8 | Leisure activities at home | |
| 10 | 6.0 | Commuting | |
| 4 | 2.4 | Shopping | |
| 2 | 1.2 | Worship | |
| 16 | 9.5 | Other | |
| 168 | 100.0 | Total |
When a disaster strikes, employees will probably be at home, either sleeping, working, or relaxing. The next most likely place they’ll be is at work itself, followed by commuting, shopping, at worship, and doing something else entirely. Table 9-1 doesn’t factor in weeks of vacation or business travel. If a core team member spends a lot of recreation time away from home (boating, hiking, or whatever), that core team member will more likely be away from home when a disaster strikes.
Given the high probability that a disaster will occur when core team members are away from work, you need to make the information that core team members need both portable and easy to use. You have a lot of choices when it comes to storing emergency contact information, as well as performing other disaster declaration and emergency communications activities. Table 9-2 features these choices.
| Method | Pros | Cons |
|---|---|---|
| Wallet card | Compact, portable, | Can’t hold much information; |
| likely available | not easily updated | |
| Thumb drive | Compact, portable, | Requires a running computer |
| high density | to view | |
| PDA | Compact, portable, | Might not be on-hand when |
| high density | a disaster occurs; must be | |
| partially charged | ||
| Mobile phone | Compact, portable, | Might not function if the |
| high density | network is unreachable | |
| CD-ROM | Compact, portable, | Requires a running |
| high density | computer to view | |
| Laptop hard drive | High capacity | User may not have it on-hand |
| at all times; bulky; short battery | ||
| life; more likely to be damaged | ||
| or left behind | ||
| Private Web site | Centrally available, | Difficult to access in a disaster |
| or file servers | easily updated | situation |
| Microfiche or | Portable, high density | Requires bulky reader and |
| microfilm | possibly electricity | |
| Three-ring binder | Portable, easy to read | User may not have it on-hand |
| at all times; may be damaged or | ||
| left behind |
Many organizations put emergency contact lists on laminated wallet cards. Wallet cards are very portable because they can fit into a wallet or billfold. And staff are more likely to have their wallets or billfolds (and therefore their cards) with them when a disaster event occurs, even if they’re on vacation or away from home. People don’t need electricity or any other technology to read a wallet card.
Consider putting the following items on your emergency-contact wallet cards:
Core team member names: But, of course!
Mobile, home, and office phone numbers: Talking live by phone is the next best thing to being there.
Spouse mobile and office numbers: When you can’t find a core team member, calling his or her spouse may help locate him or her.
E-mail and instant messaging contacts: In a disaster, you never know what infrastructures will be down and what will still be running.
Conference bridge numbers: More than one, preferably, and from different services.
Key business addresses: Just in case core team members need to know.
Hints on disaster declaration procedures: Jog the core team members’ memories.
URL that contains more disaster procedures: Disaster recovery procedures stored online. Hopefully hosted far, far away from your business, in case damage is widespread.
You might need more information than what appears in the preceding list, or you might need less, depending on your disaster recovery and business needs.
Emergency leadership and role selection
When your organization declares a disaster, who’s going to lead the response team?
Actually, I think the question should be, who’s not going to lead it? At the onset of a disaster, core team members each have a number of distinct responsibilities related to their respective departments. Each member will have enough to keep him or her busy when a disaster unfolds. But during a disaster, several decisions must be made, minute by minute and hour by hour.
Your first natural inclination might be to select, from among the core team members, the person who should be the team’s leader before the recovery effort even begins. But, depending on the nature of the disaster and when it occurs, you don’t know which core team members will be active at the onset of the disaster. You could rank-order possible leaders from among core team members, or you could let them figure it out amongst themselves. In disaster situations, one of the core team members will just step out and lead the rest. If your core team comes from company management, several of your core team members have leadership skills and talents. One of them will take the lead, and the others will follow. You don’t need to get scientific about who will lead. In fact, you can probably just let the team members figure it out on their own.
The nature of the disaster may call for around-the-clock response for a few days, or even a long stretch of days or weeks. At least at the beginning of the disaster, the core response team should assign one of its members a duty- officer role, which involves leading the team for a period of several hours. Leaders can trade off, giving members a chance to rest if your organization need 24/7 coverage.
When a disaster response stretches into several days, the response team should set up a more formal leadership and management schedule so all team members know who’s in charge at what times and on what days. But, like a few other matters in disaster response and recovery (such as leadership selection), you probably don’t want to get too rigid in your DR plan. Allow the leadership and response team to make those decisions on the fly. After all, you need to consider many possible scenarios with varying damage and recovery conditions, and you’ll have an unpredictable selection of personnel available to lead, manage, and recover the business.
In addition to the leadership and management roles, you also need a scribe. Somebody needs to write down the discussions, duties, findings, and decisions. Don’t count on remembering these decisions later because it may all be a blur when the disaster response team can finally stand down after a lengthy recovery effort. Instead, record these decisions and other matters on the spot.
At the beginning of the disaster, scribes should operate the old-fashioned way — pen and paper. High tech solutions, such as notebook computers or voice recorders, might very well be impractical, depending on the nature of the disaster.
Damage assessment procedures
The disaster recovery plan needs to include procedures for assessing damage to equipment and facilities. The objective of damage assessment is to identify the state of the IT systems and supporting facilities that are involved in a disaster and to decide whether the systems and supporting facilities are damaged or disabled to the extent that you need IT systems in another location to continue supporting critical business functions.
Damage assessment is both an art and a science. In this section, I don’t tell you how to determine whether a building is safe for occupancy — that’s a role for professional civil and structural engineers. Similarly, I don’t delve into whether a disaster warrants evacuation or if personnel can stay behind to help with assessment and possible recovery or restarts. These matters are important, to be sure, but they’re beyond the scope of this book.
.jpg)
Damage assessment procedures focus on determining what happened to critical IT systems and the related facilities — such as HVAC (Heating, Ventilation, and Air Conditioning), network, utilities, and security perimeter — in a disaster. You also need to figure out whether you can still access or restart IT systems, or whether the business needs to implement its Plan B — the disaster recovery plan.
You don’t need to use complicated damage assessment procedures, but you may find the procedures you do use a bit tedious. The tedium may lie in the number of simple checks you need to perform in order to assess the overall health and availability of systems. Here’s an example to help explain what I mean:
Acme Services (not a real company) is an organization that provides online records management to corporate customers around the world. A natural or man-made disaster has occurred (imagine a hurricane, civil unrest, tsunami, earthquake, flood, or whatever other disaster you’re familiar with), and Acme’s online systems have experienced a temporary interruption.
As specified in Acme’s disaster declaration procedure, the core team members who were able to contact one another determined that the magnitude of the disaster warranted the declaration of an official disaster and the initiation of the disaster recovery plan.
After some delays related to the nature of the disaster (imagine a damaged transportation infrastructure), some emergency response personnel arrived at Acme’s office building. They hesitantly entered the building (which didn’t appear damaged) to find that the building had no electricity or running water. IT systems appeared undamaged. The UPS batteries had been exhausted (it took personnel over an hour to reach the facility), and the backup generator wasn’t running.
Because the Maximum Tolerable Downtime (MTD) for Acme’s critical online processes was set to eight hours, the damage assessment team decides that they need to put the DR plan into full force. Even if they started the generator right away, the health of the IT systems was in question, and customers from around the world were anxious to access Acme’s systems so that they could go about their business.
The preceding example is a little simplistic, but it contains an important judgment call: No people were available to start the generator. If someone had been able to start the generator, the team still would have needed time to assess the health and reach-ability of the critical IT systems. Further, a generator typically has only several hours of fuel, not enough to keep critical systems going until power is restored, which could take several days in a widespread disaster. The team’s decision to invoke the disaster recovery plan was sound.
Assessment procedures are basically just checklists. You need to examine these potentially long lists of items and check either the Running or Not Running box. One or more Not Running checkmarks might mean that you need to use systems in alternate locations, unless you can quickly remedy the Not Running items. Assessment is just that: an examination of what’s running and what’s not. After you assess the items, you need to begin recovery and restart procedures, both of which I cover in the following section.
System recovery and restart procedures
After you develop the disaster declaration and assessment procedures, you need to create the instructions for recovering and restarting vital IT systems. You use these procedures to recover and restart IT systems that support critical business processes as soon as possible.
You likely need to make your system recovery and restart procedures pretty complex and lengthy. They need to include every tiny detail involved in getting systems up and running from various states, including bare metal (servers with no operating system or application software installed on them).
This list illustrates some disaster scenarios for cold sites, warm sites, and hot sites:
Cold site: In a cold-site restart scenario, you may or may not have computers to start with (the typical cold site has no computers). They could be boxed up, or maybe you have to go and buy them. A typical cold-site procedure might resemble these steps:
1. Order systems and network devices from a supplier or manufacturer to replace the systems and devices damaged by the disaster.
2. Retrieve the most recent backup media from wherever you store it.
3. Install network devices and build a server network. Verify connectivity to customers, suppliers, and partners.
4. Install operating systems and applications on new servers.
5. Restore data from backup media.
6. Start the applications and perform functionality tests.
7. Announce the availability of recovered applications to employees, customers, and partners, as needed.
The preceding procedure probably takes place over a period of several days to as long as two weeks.
Warm site: With equipment and servers already on hand, a warm site recovery takes less time and is generally a little less complicated than a cold site recovery. Here’s a typical warm-site procedure:
1. Retrieve the most recent backup media from wherever you store it.
2. Configure network devices. Verify connectivity to customers, suppliers, and partners.
3. Install or update operating systems and applications on new servers.
4. Restore data from backup media.
5. Start the applications and perform functionality tests.
6. Announce the availability of recovered applications to employees, customers, and partners, as needed.
The preceding warm-site procedure is similar to the cold-site procedure, but you have a head start with a warm site over a cold site because you already have computers available.
Hot site: Ready to assume production duties with already-prepared servers within hours or even minutes. Here’s a typical hot-site procedure:
1. Confirm the state of the most recent mirroring or replication activities.
2. Make any required network configuration changes.
3. Switch the state of server cluster nodes and database servers to active.
4. Perform application functionality tests.
5. Announce the availability of recovered applications to employees, customers, and partners, as needed.
Systems at a hot site are very nearly ready to take over operational duties with short notice. The exact procedures for a cutover to hot site servers depends on the technologies you use to bring about the readiness — whether transaction replication, mirroring, clustering, or a combination of these.
I deliberately omitted many details from the procedures in the preceding list. You need to take many additional factors into account when you develop your system recovery procedures:
Communications: Throughout the recovery operation, recovery teams need to be in constant communication with the DR core team, as well as customers, suppliers, partners, and other entities.
Work areas: Establish an area where critical IT workers can work during and after the recovery operation. IT systems in a recovered state might be somewhat more unstable than they were in their original production environments, and they might require more observation, adjusting, and tuning.
Expertise: Make the recovery procedures general enough so that people who are familiar with systems administration duties, but not necessarily your systems, can recover your systems without having to make guesses or assumptions. Step by step means step by step!
Transition to normal operations
After the disaster occurs and you recover critical IT systems at an alternate processing center, recovery activities have restored the original processing and work facilities. When you recover the original processing center, you need to reestablish IT systems there and shut down the alternate site.
The timing of the cutover back to the original processing center (or a permanent replacement facility if the original facility was completely destroyed) depends on many factors, including
Application stability: If applications running in the recovery site are a little unstable, consult the personnel maintaining the applications to determine the best time to transition back to the main processing site.
Business workload: Transition back to the main processing site at a time when workload is low so any users or related systems will better tolerate the actual cutover.
Available staff: Have sufficient staff at both the recovery site and the main processing site to switch processing back to the main site.
Costs: Additional costs associated with operating the recovery site may bring pressure to transition back to the main processing site as soon as possible.
Functional readiness: Operating and supporting critical IT applications at the main processing site must meet some minimum criteria so the applications can function properly after you transition them back to the main site. In other words, are you ready to get back to normal operations?
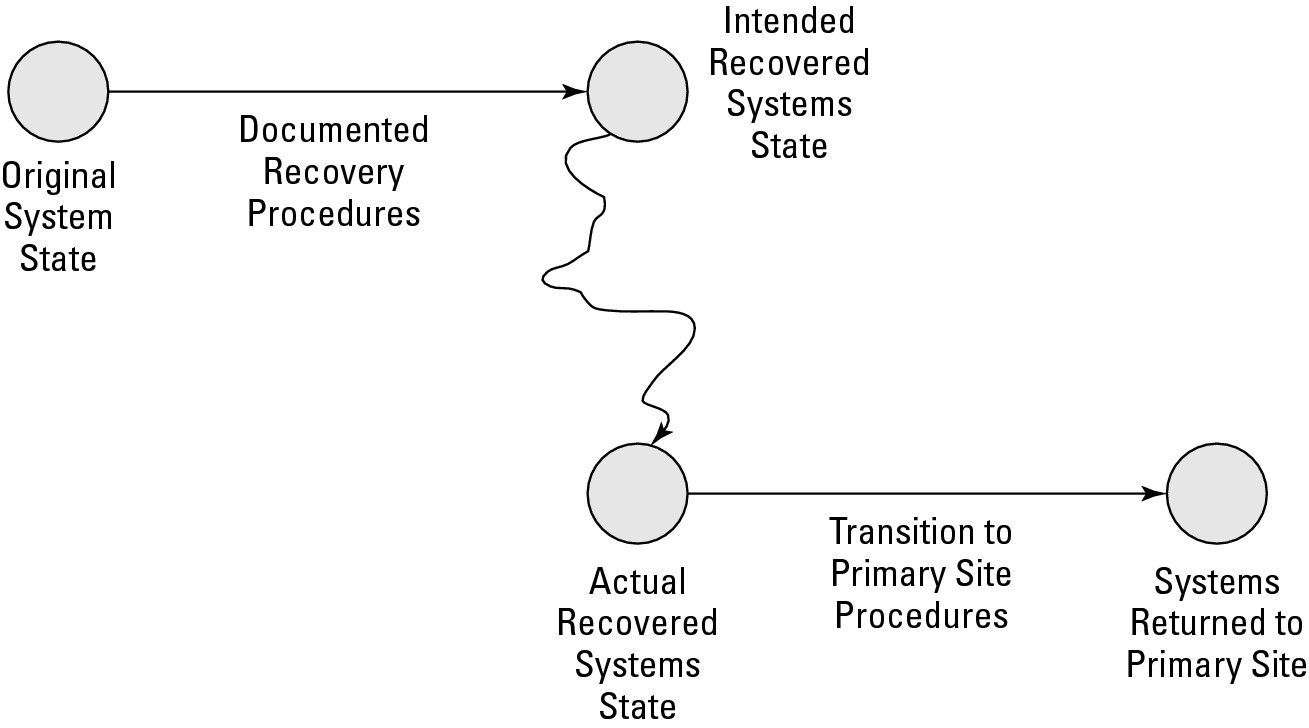
Write down the procedures for transitioning systems back to primary processing sites. These procedures aren’t the same as the recovery procedures. The state and configuration of systems in the alternate processing site probably won’t be precisely the way you planned them. For whatever reasons, you may have had to make some changes during the recovery procedures that resulted in the recovery systems not being configured or architected precisely as you intended. In other words, the starting point for transition back to the main processing sites may not be exactly as the DR planners anticipated. So, the procedures for getting back to the main site won’t exactly fit, either. Figure 9-1 illustrates the fact that transitioning back to the primary site doesn’t necessarily mean transitioning back to the primary state.
|
Figure 9-1: Procedures and states from original to recovered to original. |
|
You need to write procedures that explain how to transition from the temporary DR systems back to systems in the primary processing site. How can you write a procedure to get to the desired end state when you don’t know exactly what the initial state (the recovery systems) will be?
Testing can help with this conundrum. Full testing, including a failover test, forces recovery team members to actually construct application recovery systems and infrastructure, and then transition them back. During those tests, you should uncover most of the variables that may occur in an actual disaster, so the transition-to-normal procedures should very closely resemble reality. I describe the various types of tests in Chapter 10.
Finally, you can incorporate issues you uncover during testing into release notes (a detailed description of systems and procedures) that recovery personnel can read to better understand any issues they may encounter during recovery and transition-to-normal operations.
Recovery team
When the disaster strikes, who can the core team depend on to perform all of the tasks associated with communications, assessment, system recovery, and transition-to-normal operations? Anyone they can find. Remember, you can choose your recovery team in advance, but a disaster can render some of those team members unavailable for various reasons.
Seriously, depending on the type of disaster, many of the normal operational staff many be unavailable for a variety of reasons, including
Family and home come first: When a regional disaster occurs, workers with families and homes attend to those needs before thinking of work. When workers have things under control on the home front, then they can turn their attention to the workplace and their work responsibilities.
Transportation issues: Regional disasters can disrupt transportation systems, making it difficult for workers to travel to work locations.
Disrupted communications: Workers can often perform many recovery tasks over the wire, through VPN (Virtual Private Network, for remote access) connections from their residences to business networks. But a widespread disaster can disrupt communications, making such work difficult or impossible to perform.
Evacuations: Often, civil authorities order mass evacuations that prevent workers from being able to travel to work locations. Sometimes, evacuations work in reverse, preventing workers from leaving work to travel home, which introduces a whole other set of challenges.
Injury, illness, and death: Regional disasters are often, by their nature, violent, which can lead to injuries, disease, and fatalities.
Structuring the Plan
The preceding sections in this chapter discuss the contents of a disaster recovery plan in the very pragmatic sense — the sections and words that you put into the DR plan documents. In all but the smallest organizations, several people write sections of the plan, and many more people are involved in document review. In the following sections, I describe some of the approaches and methods that you can use to assemble a disaster recovery plan.
Enterprise-level structure
This section looks at some ways that an organization can slice and dice its DR plans. You might adopt one of these approaches or tailor one to fit your business needs.
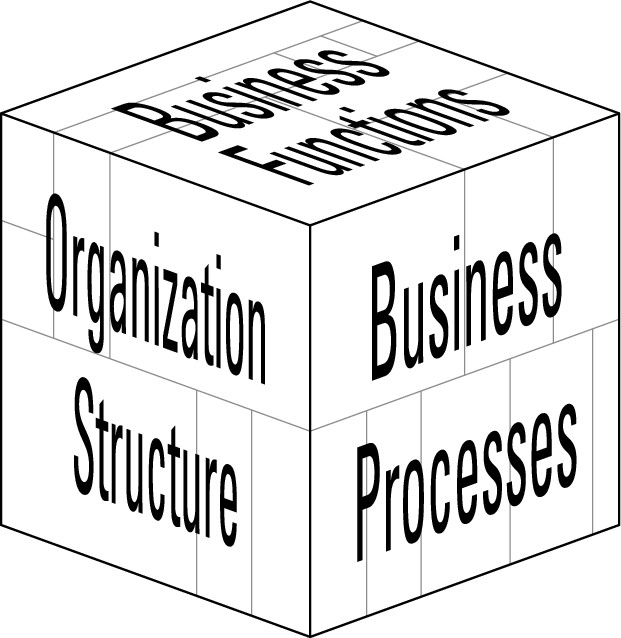
Multi-unit organizations doing large DR plans have to figure out how to write these plans for critical processes and applications that span departments or business units. Should DR plans align with applications, or should they align with the business units? It’s difficult to say; your DR development team needs to weigh the options and decide. Figure 9-2 shows an application versus business-unit point of view.
|
Figure 9-2: DR plans align with business functions, or they align to the organization. |
|
Here are some considerations that can help you understand how to approach this big-picture issue:
Geography: Disasters, for the most part, strike a geographic region, regardless of the organizational or political structures of the organizations located in those regions. Writing DR plans that take care of business in the regions hit by disasters may make the most sense for your organization. In a large company, DR plans need to reference business units and functions that are located in other locations, particularly when those units and functions are on the critical path for business processes affected by a disaster.
Organization structure: Different segments of a large organization may push forward on DR planning at different rates. One segment’s lack of progress shouldn’t impede another segment. Think of this type of situation as a DR plan for each cog in the organizational wheel. If you do things in your organization business unit by business unit, you may want to build the DR plan in pieces, asynchronously.
Business function: The point of disaster recovery planning is to recover and restore critical business functions as quickly as possible, regardless of the geographical or political makeup of the organization. With this purpose in mind, DR plans should address whole business processes, regardless of where specific functions are located.
The preceding list of considerations is somewhat idealistic. Although idealism doesn’t factor much into real-world business, consider these points of view when you try to figure out how your organization needs to structure its DR planning.
Document-level structure
Like any formal project in which important business information appears in documents, consider setting up some structure within individual disaster-recovery documents. Yes, I’m talking document templates. Your templates may include the following:
Standard document and file naming: Make the names of different documents (what appears on the title page), as well as those documents’ file names (the name of the document in a computer), consistent.
Standard headers and footers: Include the document name at the top of each page (header) and information such as Company Confidential, page number, date, and version number at the bottom of each page (footer).
Title page: Create a formal title page that includes all the document metadata, including title (but, of course!), version, date, and so on.
Table of contents: A table of contents helps the reader quickly find sections in the document. Larger documents may also need an index, list of figures, and list of tables.
Copyright and other legalese: Helps protect the organization’s intellectual property.
Modification history: Helps you keep track of the changes made from one version to the next, as well as who made those changes and when.
Document
version: Call me picky, but it helps.
Standard headings and paragraphs: A consistent appearance makes the DR documents easier to read and work with. You might even consider doing nested section numbering (such as Section 1, 1.1, 1.1.1, and so on) if you have a really big DR plan.
Depending on the maturity of document management in your organization, the template structure in the preceding list might be too heavy, too lightweight, or just right — just like in the timeless story, “The Three Bears.”
Managing Plan Development
Unless you have just one person writing your organization’s DR plan, you need to establish some process and procedure for this effort so the pieces of the plan come together smoothly without getting tangled. You need formal document management, including these kinds of activities and capabilities:
Formal document templates: I discuss templates in detail in the preceding section.
Version control: Keep track of document versions manually, perhaps by putting the version number of each document in that document’s name. You can also use a formal document management product that performs functions such as document check-out, check-in, and version management. You can find several good document management products available today, and maybe your organization has one already.
Document review: Establish a formal document review procedure in which a document’s author circulates each document to specific reviewers who can make edits and comments. Some document management products manage document review.
This book covers just the high-level basics of document management so you can better organize the development of DR plan documents if you have several people writing those documents and more people reviewing them.
Preserving the Plan
When you have completely written, reviewed, corrected, revised, and examined the plan, you need to protect that plan from harm and loss. In other words, you need to make the DR plan itself disaster-proof! What good is a good DR plan if it’s trapped inside inoperable systems that were damaged or destroyed in a disaster?
You need to preserve your DR plan, along with a lot of supporting information, against loss, just in case a significant disaster occurs. Think worst-case scenario, whatever that might be in your part of the world. Here are some methods you can use to preserve your DR plan, just in case the unthinkable happens:
Three-ring binders: Often, the low-tech way is best. Binders don’t need power cords or power supplies. Make binders for each core team member, as well as other key personnel. Make a set for work and another set for home. One downside is the difficulty in keeping them all current. I didn’t say DR planning was easy!
CD-ROM or USB keys: These devices are compact and lightweight, and they have a lot of capacity. On the downside, you need a working computer to access them.
Internet-accessible servers: These servers are a good idea, as long as you locate at least some of them far away from the main business centers so a regional disaster won’t affect them. A possible downside is that you need Internet connectivity to access these servers.
Off-site storage: Chances are, most organizations use off-site media storage for backup media safe-keeping. Often, these off-site storage firms also store paper records in addition to electronic records, so why not have them store your DR plans?
Taking the Next Steps
After you write your DR plan, are you done? Hardly. You have many tasks still ahead.
You need to test your DR plans to be sure that they’ll actually work in a real disaster. DR-plan testing is covered in Chapter 10.
After you finalize and bless your DR plan, are the underlying software and data architecture, business processes, and supporting IT systems going to stop changing? No way! Disaster recovery plans need to be kept up-to-date, which I cover in Chapter 11.