Chapter 10
Testing the Recovery Plan
In This Chapter
![]() Diving into DR plan testing
Diving into DR plan testing
![]() Conducting paper tests, walkthroughs, simulations, parallel tests, and cutover tests
Conducting paper tests, walkthroughs, simulations, parallel tests, and cutover tests
![]() Deciding how often to perform tests
Deciding how often to perform tests
And you thought you were done when you finished writing your plan! You’ve only just begun.
Testing a DR plan is the only way to know if it’s any good. In this chapter, I describe the different types of testing that you can use, from simple paper tests to full-on cutover testing.
And, even after you finish testing, you aren’t done with the plan. But, as with a good murder mystery, I shouldn’t spoil the ending by giving it away (no, the butler didn’t do it).
Testing the DR Plan
Disaster recovery plans aren’t much good if they don’t work. And if they don’t work, you pretty much waste the time devoted to their development.
Decision makers in businesses, especially executives, like certainty. They want to have confidence that things will go as planned. And although no one plans a disaster, execs want to know that the recovery effort after a disaster will work.
The survival of the business may depend on it.
To see if your DR plan will work, you can always take it to a fortune teller, but I wouldn’t put much stock in that. Why not just try it?
Why test a DR plan?
Disaster recovery plans contain lists of procedures and other information that an emergency response team follows when a natural or man-made disaster occurs. The purpose of the plan is to recover the IT systems and infrastructure that support business processes critical to the organization’s survival. Because disasters don’t occur very often, you seldom can clearly tell whether those DR plans will actually work. And given the nature of disasters, if your DR plan fails, the organization may not survive the disaster.
Testing is a natural part of the lifecycle for many technology development efforts today: software, processes, and — yes — disaster recovery planning. Figure 10-1 depicts the DR plan lifecycle.
|
Figure 10-1: The DR plan lifecycle. |
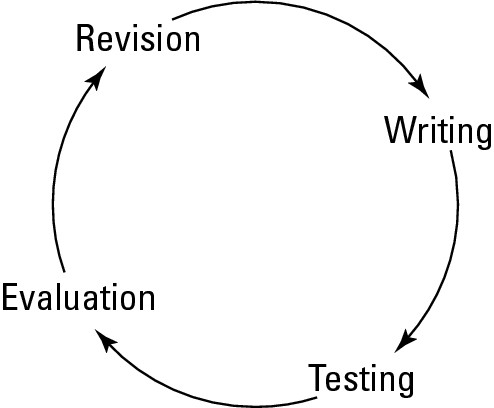
|
When you test the DR plan, note any discrepancies, and then pass the plan back to the people who wrote each section so they can update it. This process improves the quality and accuracy of the DR plan, which increases the likelihood that the organization will actually survive a disaster if one occurs.
Another great benefit of DR plans and their tests is the likelihood that, by undertaking them, you can improve the organization’s everyday processes and systems. When teams closely scrutinize processes and figure out how they can protect and recover those processes, often the team members discover opportunities for improvement. Sometimes the question, “How can we recover this system?” gives people the opportunity to answer the question, “How can we improve the existing system?” Be open to those opportunities because they’ll come, sometimes in droves.
The types of testing that I discuss in this chapter are
 Paper tests
Paper tests
Walkthrough tests
Simulations
Parallel tests
Cutover tests
These tests range from the simple review of DR procedure documents to simulations to running through procedures as if you’re experiencing the real thing.
Developing a test strategy
DR testing in all its forms takes considerable effort and time. To make the best possible use of staff and other resources, map out a test strategy well in advance of any scheduled tests.
Structure DR testing in the same way you structure other complicated undertakings, such as software development and associated testing. Just follow these steps:
1. Determine how frequently you should perform each type of test.
2. Test individual components.
3. Perform wider tests of combined components.
4. Test the entire plan.
When you perform DR testing as outlined in the preceding list, you can identify many errors during individual tests and correct those errors before you do more comprehensive tests. This process saves time by preventing little errors from interrupting comprehensive tests that involve a lot of people.
Virtually every enterprise that builds actual products performs testing as outlined in the preceding list. Businesses have found this test methodology to be the most effective way to ensure success in a reasonable timeframe. Figure 10-2 shows the flow of DR testing.
|
Figure 10-2: This chart shows the evolution of DR plan testing. |
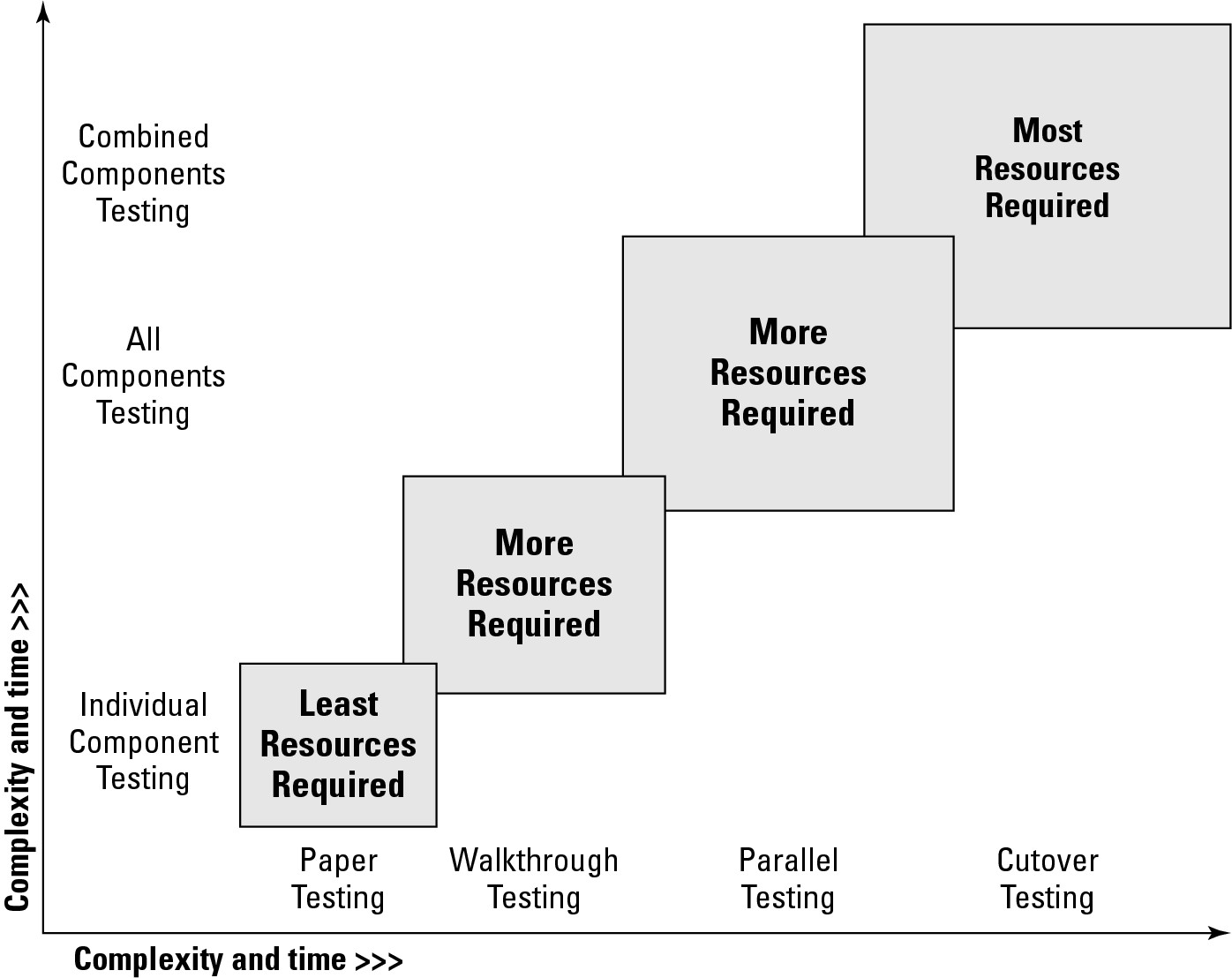
|
Developing and following test procedures
You’re probably anxious to get to testing, but you should know some procedures that are vital for every type of test. Follow these basic steps for every DR test:
1. Determine what you want to test and the type of testing you need to do.
Create a detailed list that includes every step of the disaster response procedure so you can be sure to test each step and record the results.
2. Define and document explicit goals and objectives for each test.
Also determine success criteria.
3. Determine who will perform the test.
4. Schedule the test.
Confirm that the assigned person(s) are available at that time.
5. Make sure the assigned person(s) perform the test and record the test results.
6. If any part of the test was unsuccessful, you must correct the DR procedures and reschedule the test.
The preceding steps give you the minimum that you must do. If your organization does less for its DR plan testing, you risk a recovery effort failing when it matters most, which can jeopardize the future of the organization.
Conducting Paper Tests
A paper test is usually the first type of test that you perform for a recovery procedure. A paper test is a review of disaster recovery procedures and other response documentation, such as contact lists. In a paper test, individual staff members review these documents on their own. Ask them to make annotations or comments so you can verify the accuracy of a DR procedure, prior to performing tests that are more labor-intensive and complex.
The procedure for performing a paper test is fairly simple. Just follow these steps:
1. Assign staff members to perform the test.
The staff members you choose should range from subject matter experts to near-novices. You never know who might be carrying out the procedure in a real disaster!
2. Have these assigned people carefully review the recovery procedure.
They should read the procedure with a critical eye to verifying the facts, as well as making sure the documents are clearly written.
3. Have the assigned people note, step-by-step, which items are correct and which ones need changing.
They need to note errors that are factual in nature (for instance, the misspelling of a command) and procedural in nature (for example, a missing step). Also, ask for suggestions on how you can improve the procedure. The assignees may use any internal or external reference materials they need to confirm the accuracy and appropriateness of the test procedure.
4. Get the test results in writing, including the details that the tester notes in Step 3.
5. Collect these results from all test subjects.
6. Give the results to the project manager or the person who owns the procedure (probably the same person who wrote that procedure) so he or she can revise and retest the procedure.
The people who perform these tests should do so alone and at their own pace. You have opportunities in walkthrough tests (which I talk about in the following section) to have groups of people review procedures together.
After all the reviewers complete paper testing, and you make all revisions and carry out retests, you can advance the procedure to further testing, such as
Paper tests in which you combine the procedure with others: For example, you can combine a procedure for restarting a server with other procedures related to starting all the servers associated with an application.
Walkthrough testing: See the following section for details.
Conduct paper tests periodically to make sure that they remain accurate over time. I discuss the long-term schedule for DR plan testing in the section “Establishing Test Frequency,” later in this chapter.
Conducting Walkthrough Tests
A walkthrough test is similar to a paper test — it’s a review of a written recovery procedure document. But you perform the walkthrough test with a group of experts, rather than a single expert working alone.
A walkthrough test takes place after you complete paper testing. Paper testing eliminates many of the errors in the procedure, so the group reviews a much higher quality procedure in walkthrough testing. You make the walkthrough a more valuable activity if you remove most of the errors before it takes place. A recovery procedure that’s rife with errors makes a walkthrough test a waste of everyone’s time, slowing down the group and making the test less effective.
In a walkthrough test, the test participants discuss each step in the procedure. In this group setting, participants talk their way through each step and decide whether that step is properly worded, and they consider what happens in each step. The ensuing discussion provides opportunities to find errors, as well as opportunities to make improvements.
Walkthrough test participants
Who should participate in the walkthrough test? You need several parties:
Facilitator: Someone with established facilitation and people skills who has no vested interest in the outcome of the walkthrough. The facilitator needs, um, facilitation skills — keeping the participants on track, making sure the pace of the discussion is appropriate, and so on.
Scribe: This person needs to take good notes throughout the walkthrough. These notes include things that went well and things that didn’t go so well throughout the walkthrough.
Business process owners: The people in the company who perform the business process that the walkthrough focuses on. They’re usually familiar with the workings of supporting applications, but they have a point of view that’s quite different from IT developers and operations.
Recovery team members: Staff members whom you select to perform actual recovery operations if and when a disaster occurs.
Subject matter experts: Staff members or outsiders who have expertise in the processes or technologies related to the test.
Auditors: In a regulated or audited organization, auditors can provide valuable insight. The security and audit requirements for a business process and its supporting application(s) aren’t relaxed during a disaster!
Senior management: They provide invaluable big-picture insight when they observe and participate in the walkthrough. Often, they know about business matters that others might miss during a walkthrough.
Walkthrough test procedure
Follow these steps to perform a walkthrough test:
1. Identify the people you want to participate in the walkthrough.
2. Identify potential locations for the walkthrough.
You need a large and comfortable meeting room that can easily accommodate all the participants, as well as space for setting up and eating any meals the group requires.
3. Estimate the length of time required for the walkthrough.
You usually need an entire day.
4. Assign a facilitator and a scribe for the walkthrough.
I can’t overstate the importance of a scribe; when comments, issues, and proposed changes to the DR plan arise, the scribe writes these down so the plan can be updated later. Other people in the room may be too caught up in the discussion to write down all of the issues.
5. Schedule the walkthrough.
Be sure that you allocate enough time for the test — half a day or more. Arrange to provide one or more meals so people don’t have to interrupt the walkthrough by leaving to eat.
6. Distribute the procedure to the walkthrough participants in advance.
7. Conduct the walkthrough (or let the facilitator lead the walkthrough).
During the walkthrough, the most important task — which the scribe performs — is to record the results of the test: What went well, what didn’t go well, and what changes you need to make in the procedure to ensure its success. You most importantly need to discover dependencies — meaning when a step in a procedure depends on an external item — and record the details and issues regarding those dependencies.
8. Prepare the written results and feedback, and pass them to the owner/creator of the procedure.
The owner/creator of the procedure should make any needed revisions to the procedure.
Scenarios
The test facilitator — and possibly other walkthrough test participants — needs to select one or more scenarios as the subject of the walkthrough. Choose the scenarios from among the types of disasters that can actually occur in the organization’s region. Possible scenarios include
Severe storm: A severe storm could be a tornado, hurricane, cyclone, ice storm, windstorm, or other storm that causes widespread transportation and utility outages.
Earthquake, volcano, landslide, or avalanche: Consider any of these scenarios if they’re likely to occur in your region.
Flood or tsunami: If your business is located in an area where these events may occur, you can use them as a walkthrough test scenario.
Utility outage: Human error or a natural event can cause a power or communication outage lasting several days.
Pandemic: A widespread illness can result in high rates of absenteeism and government-mandated quarantines.
Man-caused event: Can include civil unrest, strikes, acts of terrorism, or war.
Other disruptions: Consider including scenarios such as building evacuations, corruption of a critical database, failure of a critical server, a large-scale network outage, and so on. One or more participants may have experienced one of these events, which can help make the walkthrough more realistic and expose more issues.
Describe the scenario you choose in detail at the beginning of the walkthrough. Whoever reveals the scenario should describe its location, as well as what impact the event has on the region. Include a description of damage to the facility and which staff members are or aren’t available to help.
Using a real-life scenario puts a face on the walkthrough and makes it more real. It may be easier to imagine a more realistic and likely scenario that can get the adrenalin flowing. The participants have a greater sense of urgency and concern because their own imaginations help them see the impact of a real disaster and how an organization has to make a best effort to recover critical business processes with few available resources.
Walkthrough results
At the end of the walkthrough, the facilitator should lead a discussion. He or she should solicit from the participants examples of what went well and what didn’t. Of course, the scribe should have written down these items as they occurred, but in recounting the event, the participants can think about how well the walkthrough went and how they could improve it.

You may or may not need to re-perform the walkthrough. If the first walkthrough didn’t go well (which could happen for a variety of reasons), perhaps you need to repeat the walkthrough after you update the procedures and any supporting materials. If the first walkthrough resulted in only minor revisions, you may not need to repeat it.
Properly record the results and details of all walkthroughs so you know the status of each walkthrough and can note and record any required changes.
Debriefing
The team may want to conduct a debriefing session that takes place one or more days after the walkthrough. The purpose of a debriefing is to discuss the results of the walkthrough, after the participants have had some time to analyze the results and perform any needed post-walkthrough research or number crunching. The debriefing should include the facilitator, scribe, management, and any senior managers or executive sponsors.
Depending on the size and complexity of the walkthrough itself, a debrief- ing may range from very informal to highly structured. The debriefing needs a clear purpose and may range from extended discussions about procedures, results, and problems you ran into during the test to strategizing/ brainstorming.
Next steps
After you perform walkthroughs for all procedures in the DR plan and correct all errors and discrepancies, the DR plan team can consider doing parallel testing, in which response teams actually perform the recovery procedures to see how well they work. I cover parallel testing in the section “Conducting Parallel Testing,” later in this chapter. Also, consider simulation testing, which I talk about in the following section.
You need to conduct walkthrough tests now and again. I cover test frequency in the section “Establishing Test Frequency,” later in this chapter.
Conducting Simulation Testing
A simulation is more than a walkthrough (which I discuss in the section “Conducting Walkthrough Tests,” earlier in this chapter), but it shares many characteristics with a walkthrough. A simulation is basically an on-location walkthrough test with props. Here are some relevant facts about simulations:
A simulation’s setting is a credible and likely disaster scenario.
Simulation participants are recovery team members.
The simulation takes place in a designated emergency operations center or a location resembling one.
A simulation usually takes an entire day — maybe even two or three days.
A well-orchestrated simulation usually takes weeks or months to plan.
Probably the most important characteristic of a simulation is that it’s highly choreographed. Script the disaster scenario to take place over a period of several hours. For instance, in a simulation that begins at 8:30 a.m., the moderator issues a number of verbal and written statements at predetermined times, such as the following:
8:30 a.m.: Announcement of a nearby earthquake (tsunami, tornado, ice storm, and so on) with a description of the immediately known damage.
8:35 a.m.: Announcement of early reports of damage to roads, the regional airport, and broadcast facilities.
8:45 a.m.: Announcement that a ruptured natural gas pipeline is burning, forcing mass evacuations and disrupting businesses and transportation systems.
9:00 a.m.: Announcements of specific public utility outages, transportation disruptions, and telecommunications outages.
As the disaster response team hears these announcements, they spring into action, declaring a disaster and mobilizing resources. Design further announcements to constrain their abilities and give them the feeling that these events are actually occurring.
A simulation test is primarily a test of personnel — how they’ll respond and take charge during a real disaster. A simulation reveals the characteristics of leadership, communication, cooperation, and creative thinking among the disaster response team. The information you get from a disaster scenario simulation can provide tremendous insight into the ways in which members of the response team will conduct themselves during a real disaster.
Similar to a walkthrough test, a simulation test should have a scribe and a facilitator, and it should include a post-simulation debriefing in which participants and senior management can discuss the simulation and its results.
Conducting Parallel Testing
The disaster recovery plan paper and walkthrough testing that I discuss earlier in this chapter takes place in the minds of the participants. Team members discuss many details, but they don’t actually do anything. Paper and walkthrough testing exercise the imaginations of the subject matter experts who play various roles in the organization and in the DR planning teams.
With parallel testing, disaster response personnel actually perform the steps in their response procedures. When the procedures say build a server, the personnel build a server. When the procedures say start the applications, the personnel start the applications.
In short, parallel testing finds out if the disaster recovery plans actually work. Well, almost.
In a parallel test, the personnel who are actually delivering services to customers continue doing so. IT systems that support those services continue to run. Customers who do business with the organization don’t see any difference because you make no real changes to the systems that support the services they use, but the disaster response personnel perform DR procedures as though a disaster had actually occurred.
Parallel testing considerations
Parallel testing is quite different than paper testing and walkthroughs. In a parallel test, bits actually flow through recovery systems, so you can get a more reliable idea whether the DR plan will work in an actual disaster. You need to take a number of considerations into account before performing a parallel test:
Do no harm to infrastructure. Don’t interrupt or interfere with existing networks, systems, databases, and applications in a parallel test. Existing systems still perform actual business and support existing business processes that must continue.
Do no harm to staff. Similarly, a parallel test may involve additional employees working in the presence of staff members who are carrying out their regular duties. Recovery test personnel must not interfere with the real staff members.
Acquiring replacement equipment. In some DR plans, you use systems that the organization already owns as recovery systems. In others, the organization must purchase recovery systems. For purposes of parallel testing, you may need to alter the plans somewhat so those purchases don’t actually happen. A viable alternative would be to lease the systems that you need for the duration of the parallel test.
Side-by-side transactions. Depending on the nature of the business process and IT systems you’re parallel testing, you may be able to run some, or all, of the actual business transactions through both the actual systems and the parallel test systems. The DR project team needs to decide what criteria to use when determining which transactions to run on the DR systems.
Actual load or simulated load. The nature of the business might require that you perform only a small portion of transactions to validate the test. But for the test to be valid, the recovery system may need to take a full workload, even if you run only dummy data through it. Testing may also require both types of tests (small numbers of real transactions, plus a full workload test) to validate the correct operation of the systems.
External interfaces. Make the parallel test as much like the real production system it’s mimicking as you can. But you need to simulate some parts of the test so you can avoid certain undesirable events. For example, if an application sends transactions to a bank or payment processor for payment, you might want to avoid having the test system also transmit those transactions, or else your organization incurs twice the number and amount of payments. You may also need to apply this principle to other internal applications.
Make the test as real as possible. Despite all of the limitations I mention in this list, the point of the parallel test is to determine if your DR plan will work during a disaster. Consequently, leave the DR test personnel alone to figure out the hard stuff. The procedures won’t be perfect, and you should constrain the test personnel somewhat — and somehow — so they can’t cheat by overcoming obstacles more easily than they would be able to during an actual disaster.
Even with seemingly adequate precautions, things can go wrong with parallel testing, which can interfere with ongoing business processes. But you can get considerable benefits from parallel testing: Real-world experience in building and starting recovery systems and running them through their paces to see if they can support critical processes in a real disaster.
Although parallel testing is considerably more valuable than walkthrough testing for validating plans, parallel testing falls short of actually supporting critical business processes. Another activity, however, can erase all doubt as to whether recovery systems can do the job — cutover testing. I discuss cutover testing in the section “Conducting Cutover Testing,” later in this chapter.
Next steps
After you successfully complete a parallel test, you should have a very clear idea of how your response team and IT systems will respond in a real disaster. The parallel test should provide you with information that you can use to further improve recovery procedures.
You may want to carry out one or more simulations (see the section “Conducting Simulation Testing,” earlier in this chapter) so you can better understand how personnel will respond in a real scenario. And if you’re ready to climb higher into the rarified air of cutover testing, proceed boldly to but plan thoroughly for this most comprehensive and challenging form of disaster recovery testing, which I cover in the following section.
Conducting Cutover Testing
Parallel testing, which I talk about in the preceding sections, gives you an opportunity to actually build recovery systems to find out if they can perform the type of activities you need to support critical business functions. But parallel testing stops short of actually supporting those processes. If you absolutely must know whether your recovery systems can support actual business workload, consider performing a cutover test.
In a cutover test, the recovery team builds and readies recovery systems that can support critical business functions. A cutover test is the real thing. If the recovery systems don’t work, the business processes they support will really be interrupted. That could be a real disaster!
Cutover testing is deadly serious business. It is, without a doubt, the DR test with the highest amount of risk. A cutover test is kind of like a heart- lung bypass during open-heart surgery — the consequences of failure are tremendous! However, the rewards are equally great: The positive outcome of a cutover test gives the organization a high degree of confidence that the DR plan can assure the continued operation of critical business processes if a real disaster strikes. Walkthrough and parallel tests can’t provide the same level of assurance.
You can usually perform a cutover test more easily than a parallel test for a number of reasons:
No more simulations: In a cutover test, you don’t need to take special care to stop certain things from happening, such as double transactions to external systems. Managing these possible missteps is a tricky issue in parallel testing, but it’s practically a no-brainer in cutover tests.
No more double work: In a parallel test, you need to perform some operations on both primary and recovery systems to validate and reconcile the proper operation of the recovery system. In a cutover test, you have only one system performing transactions.
Less human interference: Some operations in a parallel test may require certain staff to perform their procedures differently for the sake of the parallel test. In a cutover test, staff procedures are probably more like their day-to-day routine than what they do during a parallel test.
Performing a cutover test is like jumping out of an airplane and betting that the parachute (or the reserve ’chute) will work perfectly. Jumping out of a perfectly good airplane can be pretty unnerving, and it can make you question whether you did the right thing. One thing is certain, however — after you begin, you’re committed!
.jpg)
Don’t let testing create a disaster
Typical cutover testing involves disconnecting or shutting down primary systems and transferring operations to recovery systems. This task isn’t risk-free, and a number of things can go wrong:
Inability to start recovery systems: Despite practice, the DR team might run into an unexpected problem and be unable to get recovery systems running. If you’ve already shut down or disconnected primary systems, you could experience an outage of greater-than-expected duration.
Inability to start applications on recovery systems: If the DR team can’t get applications running on recovery systems, more downtime could result.
Inability to retain transaction data on recovery systems: Cleanly transferring transactions from system to system can be very complicated in large, complex, or distributed applications. You may find maintaining transaction integrity, particularly during cutovers, really tricky.
Any of these scenarios can result in unplanned downtime. Depending on the nature of the organization, this unplanned downtime may be crippling. Perform thorough paper, walkthrough, and parallel testing — and examine the test results deeply and carefully — before you begin any cutover test.
Cutover test procedure
In a cutover test, you turn off (or disconnect) production systems and start up the recovery systems, right? Well, maybe. Although you do need to perform full end-to-end testing, you may want to give yourself some accommodations so your testing doesn’t actually interrupt running business processes.
Suppose that a DR plan establishes a two-hour RTO (Recovery Time Objective), which means you need to have recovery systems up and running in less than two hours. Parallel tests may show that you can get those systems up and running in 90 minutes. But do you really want to interrupt running business processes for that long? Remember, this is a parallel test, not a real disaster. Even for the sake of end-to-end DR testing, you may not want to incur that much actual downtime. What you do in your cutover test depends on the type of business you’re in and how much downtime executive management is willing to endure for the sake of a test.
Assuming you don’t want to take a full hit on downtime during a test, follow these steps to perform a cutover test:
1. Develop the entire cutover test plan and circulate it for review to a wide audience of stakeholders and experts.
Include validation criteria that you can use later to determine whether each step of the test was successful.
2. Brief the entire test team prior to the test so you can address any remaining concerns.
3. Begin the test. Notify the team members that the test has begun and that you need them to begin building and/or preparing recovery systems.
You may or may not take main production applications offline, depending on whether executive management is willing to tolerate an actual outage.
4. After the team has prepared and readied the recovery systems, configure those systems to assume full production workload.
5. Carefully observe the recovery systems, now actually supporting critical business processes, to ensure that they’re performing all functions properly.
Also observe interfaces to other systems (whether internal or external) to make sure those interfaces are also operating properly.
6. Carry out any specific test scripts or plans that you developed for the test.
7. After you carry out all desired functions and tests on the recovery systems, revert production workload back to the primary systems.
Note: You must work out a plan for transferring transactions back to primary systems so you can do the switch back smoothly. Primary systems need to have full knowledge of transactions that the recovery systems perform, as though the primary systems had actually performed those transactions.
8. After the primary systems resume all duties, carefully examine the recovery systems to ensure that they were in fact performing their functions correctly.
Personnel participating in the parallel test, as well as all staff members affected by the test, must report any unexpected results to the testing team immediately.
9. The test team and test organizers need to fully document the procedure, issues, and results of the test.
Compare test results with the validation criteria you develop in Step 1 to determine whether each step of the test was successful.
10. Circulate the test report to a wide audience of stakeholders and other personnel.
11. Debrief the test team to provide them an opportunity to discuss the test and its results.
Valuable insights, when you document and act on them, can further improve the quality of the DR plan and increase its effectiveness.
Cutover testing considerations
You need to address several issues long before you conduct a cutover test. Some of these issues include
Practice first: Test virtually all the tasks associated with building and recovering an application prior to the cutover test. Before the test begins, personnel should become familiar with the procedures that they’ll carry out.
Workload: Recovery systems must be able to handle the entire workload. Don’t necessarily expect recovery systems to perform at the same level as primary systems, however. Depending on the nature of the systems you’re testing, you may need to perform volume testing and/or stress testing to be sure that the recovery systems (and all of the supporting infrastructure) can support workloads as expected.
Reach-ability: Customers, users, suppliers, and other parties must know how to reach your systems during a cutover test. Ideally, they’d access your recovery systems in the same way they normally do, but the nature of the applications you’re testing may influence this access.
Notification and communications: Certainly, some staff know that you’re performing the cutover test. But do you tell everyone in the organization that the test will occur or is occurring? I don’t have easy answers for this question — the DR planning team needs to talk it out with senior managers or executives present.
Transaction integrity: The recovery system needs to cleanly record the transactions — or whatever the applications perform. At the end of the test, transfer those records back to the primary system. The method and timeframe for transferring work done on recovery systems back to primary systems depends on the nature of the applications and the processes they support.
Transaction source: Your application should know on which systems it performed transactions. That way, if something goes awry later, after a cutover test, you can figure out which system (primary or recovery) performed a certain transaction.
Controls, regulations, audits, and security: If your organization is bound by any regulations or audits that impose requirements on your systems and applications, the systems must conform to those requirements at all times. You can’t relax or set aside controls during any DR test. Auditors and regulators aren’t likely to be compassionate on account of some omission during a DR test. Make all regulatory, audit, and security requirements and controls a part of the DR plan from the very start.
If cutover testing is starting to sound scary, that’s good! This type of DR testing is very serious and should invoke fear because the risks of failure are great. The rewards for success are even greater, however, so you should figure out how to turn your fear into positive energy and proceed with intention.
Planning Parallel and Cutover Tests
Performing a parallel or cutover test requires a great deal of planning and also a planner or project manager. If you don’t believe me, have a knowledgeable person begin to write down all the tasks that you must perform before the actual test takes place, all the tasks associated with the test itself, and finally all the tasks that you must perform after you complete the test.
You need a project plan for several reasons:
You need to do many tasks. Unlike walkthroughs, you have to do a lot of things to get ready for a parallel or cutover test.
Many tasks depend on other tasks. You can’t load the data until you install the database, and you can’t install the database until you install the operating system, and you can’t install the operating system until you have a computer to install it on. So, on and on it goes — many tasks depend on many others.
All tasks require people. You can very easily build a project plan until you have to assign people to the tasks in that plan. Most project managers find that they have too few people for the job, which makes the job take a lot longer than originally expected.
People are busy with other things. Staff members also have other responsibilities; the project planner can find out how much time each task takes and when people will be available to carry those tasks out.
The project plan is the schedule. A thoroughly developed project plan serves as the de facto project schedule. The project plan contains a list of tasks, when those tasks are supposed to occur, and who’s supposed to perform them. After you identify all the tasks, dependencies, and resources, the project plan begins to become real. When you plug in start dates, the dates for important milestones begin to have credibility with the planning team and executives.
You need to identify and resolve conflicts. Some of the milestones are going to conflict with other events that occur in the organization. You need to identify and consider significant events, such as heavy business periods (retailers before holidays, for example) and fiscal month-, quarter-, and year-ends, so the cutover or parallel test can avoid the significant events in the business’s overall calendar.
You need a way to measure progress. After you complete the project plan and start the project, marking the completion of important milestones gives you a good measure of progress.
The plan can help identify costs. Although plans are task-oriented, analysis of each task can give you information about hard costs (actual dollars spent) and soft costs (such as extra time needed to perform tasks) associated with each task. Costs that you can easily figure out include hardware and software purchases; more difficult ones include consultants and contractors, facilities rental, and so on.
A solid plan helps to shape expectations. Senior management will certainly ask basic questions about the test — how long, how much, and who will do it. A well-developed plan can help you answer those questions with confidence.
Clustering and replication technologies and cutover tests
Environments that use clustering and replication technologies to establish recovery systems usually can more easily perform cutover tests than organizations that have systems that use manual cutover procedures. In local and geo-clusters, the recovery systems are already running and, if you manage them properly, already have the current application software and system configuration.
In such environments, you can perform a cutover test nearly as simply as executing a command on the recovery system’s cluster program that says, “Make me the active server in the cluster.” Execute that command and voilà, the passive recovery system now becomes the active system in the cluster, processing real transactions, or whatever the application does to pass the time.
But if only it were that easy. Clustering and replication work closely together, and they must, so applications can properly perform and record all transactions, particularly those transactions that start on one system and end on another. If this book focused on clustering, transaction processing, and replication, I’d have entire chapters on each of the topics that I mention in this paragraph. Someone in your organization must fully understand clustering and replication, together with the intimate workings of the applications that run on these technologies, so all your applications can work properly when the active server in a cluster ceases to function in a cutover test or in a real disaster.
Next steps
In disaster recovery planning, it’s not over, even after it’s over! After a successful cutover test, an organization knows that it has the right stuff to weather a real disaster. Make sure that you document all the notes, results, and reports of the cutover test, debrief participants and management, and put the next cutover test on the calendar.
If you focus your DR testing on technology, you might want to try a simulation (discussed in the section “Conducting Simulation Testing,” earlier in this chapter) to help you understand the human dynamic that plays out during a disaster and has such a powerful influence on the success (or failure) of a response team.
Establishing Test Frequency
After you complete your testing, you can just send everyone back to their regular jobs, right? Well, yes — but not forever. Remember this constant of business processes and IT systems: They’re always changing! The test plans that worked last month might not work next month. Changes in processes and IT systems have a direct impact on recovery procedures. Does that mean you need to perform DR testing monthly? Well, not necessarily, but in some cases, maybe.
The following factors may increase or decrease how often you need to test:
Cost: The more a test costs, the less often you probably want to perform that test.
Risk: The risk of recovery failure in an actual disaster increases test frequency so you can be sure that recovery operations will actually succeed.
Frequency of change: In a business environment in which processes and/or systems change frequently, you need to perform testing more frequently to keep up with these changes.
Training: More testing makes recovery personnel more familiar with recovery procedures, making a smooth and successful recovery more likely.
Customer or partner demands: Customers or partners may want (within the context of a contract or not) more frequent testing so they can be sure that the organization will survive a disaster and not disrupt other organizations, preventing “your disaster becoming my disaster.”
Regulation: Regulation may define test frequency in some industries or locations in which laws or regulations require certain types of tests at a minimum frequency, regardless of cost.
For most organizations, the following testing schedule will suffice:
Paper tests: As often as procedures change
Walkthroughs: Quarterly
Parallel tests: Annually
Cutover tests: Annually or biennially
Paper test frequency
Keeping DR procedures current is a chore, there’s no doubt about it. But the further that recovery procedures diverge from the systems and processes they support, the higher the risk that recovery procedures won’t work.
Wait — this isn’t just a sales pitch about maintaining recovery plans: It’s also a pitch about testing frequently.
You need to perform paper tests as frequently as the recovery procedures change. But that statement’s not really true, nor is it sufficient. You need to review paper tests regularly — at least quarterly and maybe more often. The periodic review of a recovery procedure serves two purposes: First, it helps operations staff remain familiar with recovery plans by keeping them aware of recovery procedures on the systems or processes they work every day. Second, review of a recovery procedure may uncover the need for a recovery procedure update.
Here’s an example of a procedure review triggering an update of that procedure: An IT operations staff member reads through a recovery procedure that discusses restoring data from tape backup. The staff member recalls that the backup program was upgraded last month and that some of the user interface (UI) elements have changed. If someone who’s a little less familiar with the backup system became responsible for recovering backup data in a real disaster, he or she might find the change in the backup program’s UI confusing, leading to errors and delaying system recovery and restart. Not good. So, the staff member’s review of the recovery procedure, and his realization that it needs a change, triggers upgrades to that recovery procedure.
You should not, however, routinely identify changes by using procedure reviews. At the same time, make sure all personnel associated with DR planning, training, and operations are alert to these types of little discrepancies that can require minor adjustments.
The correct way to update procedures, by the way, is to make reviewing and changing recovery procedures a part of the normal procedure for making changes to business processes and IT systems. I cover the task of keeping DR plans current in Chapter 11.
To keep people fresh and thinking about DR, review procedures monthly. If, however, you have so very many procedures that reading a department’s entire recovery procedure would be too time consuming, review a different portion of the entire procedure each month. You can then test different parts of the procedure library every month — so it might take two, three, or even six months to get through the entire library.
Walkthrough test frequency
When you perform paper tests, you’re tying up one person at a time. With walkthrough tests, you’re corralling a lot of people at the same time, or so you hope.
As I describe in the section “Conducting Walkthrough Tests,” earlier in this chapter, walkthrough tests are community events. Group discussions with experts helps to uncover issues that paper tests may have missed.
Given the rate of change in business processes and IT systems, you should perform walkthroughs quarterly. You don’t have to organize a full caucus with all the stakeholders from up and down the protocol stack every three months. If systems haven’t undergone significant changes since the last walkthrough, you may need only a smaller group to participate in the walkthrough. On the other hand, if you have many new hands on deck, you may need to hold a larger event to at least get the new people familiarized with your DR plan, in general, and the recovery procedures associated with the processes and systems they work with every day, in particular.
If you need some specific ideas for organizing walkthroughs, start with the following and adapt them to your specific needs:
First walkthrough — the big event: After you first develop the DR plan for a given process or application, you need a large audience of participants to talk through every step and nuance of the recovery procedure so you can make sure that the procedure is complete and accurate.
Next two or three quarters — smaller events: As long as you don’t make any major changes in systems or processes, you may need only a small core team of participants to determine whether the recovery procedure is still sufficient and identify little changes that you may need to make.
New staff members: All new staff members, regardless of their place in the process or system ecosystem (whether they’re likely to be on a disaster recovery team), need to participate in the next walkthrough. Senior staff need to indoctrinate newer staff members on details and insights that may fall between the lines in a disaster recovery procedure.
Changes to processes or systems: If the organization has made significant changes to systems or processes, more people need to participate in the next quarterly walkthrough — all those who designed changes, implemented changes, and perform processes or operate systems under the new changes.
Major upgrade or system replacement: If you’ve overhauled a process, or upgraded or replaced an IT system, a full-on walkthrough is called for. Depending on the impact and scope of the change, you may want to wait for the next quarterly walkthrough, or perhaps you need to conduct a walkthrough before you finish the upgrade or replacement (or shortly after you do). The precise schedule for a walkthrough test in an environment with major changes depends on many factors, especially risk. In other words, can the organization afford to put in a new system and then wait to do its first DR walkthrough, or is DR important enough to do the walkthrough before the new system or process goes live?
Tuning the frequency: If your environment is nearly static and you have few major changes and low staff turnover, you could stretch out your walkthrough schedule, perhaps to twice per year. On the other hand, if you work in a high-risk environment (for example, ICU patient telemetry or a building fire control system), you should conduct walkthroughs more frequently than my suggested quarterly schedule. Frequent system or process changes, as well as higher staff turnover, also favor testing more often.
Parallel test frequency
Although parallel tests aren’t quite the real thing, they do give you an opportunity to walk the walk and see if the recovery system has what it takes to do real work. Parallel tests are tricky and require a lot of coordination, but if you never do them, it’s difficult to know whether your recovery systems will even work in a real disaster.
Difficult as it sounds, an organization has to step up and perform parallel tests, even if it doesn’t perform them often. How often you conduct these parallel tests depends on many factors:
Level of effort: You may want to bring in a lot of employees for a parallel test. After all, it’s probably a rare event, and you want as many people as possible to partake in the activity so they can learn from it. But such testing begins to add up when you figure what other activities your test participants don’t get done because of their involvement in the test.
Cost: Performing a parallel test might require some hard dollars for recovery systems (if your plans call for purchasing recovery systems), consultants (for their expertise or their two hands), and other incidentals.
Risk: You have to look at risk from two perspectives — the risk of doing the test (and what could possibly go wrong) and the risk of not doing the test. You need an experienced risk analyst to figure out the risks. The answer won’t be a clean “Yes” or “No.” Instead, your analyst should give you an answer more like, “Here are the things that could go wrong, and here’s what you can do to reduce the risk somewhat.”
Regulation: Ever the trump card, regulations in some industries and locales require real DR tests, regardless of cost, risk, and effort.
If you still aren’t sure how often to perform parallel tests (or whether you should perform them at all), try doing your parallel test one or two times per year. Adjust this frequency up or down, depending on factors that only people in your organization can know.
Cutover test frequency
Cutover tests aren’t wholly unlike parallel tests: They require the involvement of many staff members and managers, can disrupt business, and have risks associated with them. Cutover tests are decidedly riskier than parallel tests because of their disruptive nature — recovery systems get in the middle of critical business processes and support those processes (or try, anyway).
Depending on your processes, your architecture, and the type of business you’re in, you may need to do only parallel tests and never do cutover tests. But, probably, you do need to do cutover tests to make yourself more confident in your DR plans.
The arguments for doing cutover tests more, or less, frequently are the same as for parallel tests (which I talk about in the preceding section). It all depends on effort, cost, risk, and regulation. Say you can do a cutover test every one to two years. Working with the results from that test, you can then assess the risks associated with your applications and what you use them for. If your application keeps heart-lung machines and patient telemetry running, you might run parallel tests every month (or even more frequently than that!). However, if the applications do something nowhere near life- critical or even business-critical, a lower frequency of testing may suffice.