Chapter 5
Planning User Recovery
In This Chapter
![]() Making sure end-user workstations keep working
Making sure end-user workstations keep working
![]() Keeping end users communicating
Keeping end users communicating
People are an essential part of all critical business processes. Even highly-automated business processes would soon break down without human involvement, guidance, and intervention.
Recovering users means recovering their workstations and their ability to communicate with people inside and outside of their organization. You have to analyze a lot of details to understand the role of end users’ workstations and communications needs in critical business processes.
In this chapter, I discuss various aspects of recovering user workstations, including
 Web terminals (primarily used just as a Web browser)
Web terminals (primarily used just as a Web browser)
Client-side applications and tools
Access to centrally located information
In this chapter, I also discuss recovering users’ communication needs, including
Voice communications
E-mail
Fax and instant messaging (IM)
Recovering these capabilities requires recovery plans that quickly restore users’ ability to perform their tasks and support critical business processes. This chapter focuses on identifying important issues. When you know these issues, you can help develop the appropriate recovery activities.
In the event that the facilities where your employees work are also damaged in a disaster, those facilities also require recovery efforts. You can read about activities related to recovering facilities and work centers in Chapter 6.
Managing and Recovering End-User Computing
People play a vital role in the operation of business processes. Increasingly, the people portion of business processes involves the use of desktop or notebook computers. End-user computing varies widely, depending on the tasks that each employee performs during his or her workday. Some examples include
Using e-mail to send and receive notifications from applications and other users
Accessing company Web-based applications
Accessing external Web-based applications
Accessing client/server applications
Accessing and working with documents on file servers
Accessing and working with documents on the workstation
For some of the functions in the preceding list, the user’s workstation is little more than a terminal. For other functions, the workstation acts as a local processing and/or data resource.
Most users use both the terminal aspects and the local processing aspects of their workstations, but both functions aren’t necessarily critical for all people, processes, or tasks.

Because employees may use workstations in many different ways, managing and recovering those workstations involves a wide variety of approaches. The following sections discuss these different approaches for managing and recovering workstations, as though they were separate environments:
As terminals
As a means to access centralized information
As application clients
As local computers
Regardless of which of the functions in the preceding list are in play, you also need to figure out how to manage and recover workstation operating systems.
I’m not pretending that employees use end-user workstations exclusively as terminals, or application clients, or local computing resources. Most users utilize their workstations for a combination of tasks. I look at each of these uses separately in the following sections, effectively dissecting users’ work patterns.
Workstations as Web terminals
From a disaster recovery point of view, the easiest function to recover on end-user workstations is their use as terminals — especially if those terminal functions use native components, such as Web browser software. But even in this simple case, several factors require consideration:
Plug-ins
Mashups
Web browser configurations
The following sections discuss these factors.
Application plug-ins
Just because you access one or more of your critical applications via Web browsers doesn’t mean your DR planning efforts are going to be issue-free. When you’re mapping out all the moving parts and pieces of an end-to-end application environment, you need to identify all Web browser plug-ins that your Web applications require to operate properly.
Some examples of Web applications include, but are certainly not limited to, the following:
Adobe Acrobat: To read PDF files
Apple Quicktime: To play video and audio clips
Adobe Flash: To display Web pages’ rich Flash content
Shockwave: To display Web pages’ Shockwave content
Windows Media Player and other media players: To play video and audio clips
Document viewers: To view documents, spreadsheets, presentations, project plans, technical drawings, and so on
Java Virtual Machine (JVM): To run Java applets
Custom plug-ins: Developed by your organization or a third party
If your critical Web application(s) use plug-ins, take a closer look at those plug-ins. Some of the issues related to plug-ins and other browser add-ons that may need attention are
Installation and update: Where do your required plug-ins come from — are they hosted by your application server or a third party, or do they come from external sources?
Configuration: Do any of your plug-ins require configuration, and do those configurations have default or non-default settings?
Management: Do the plug-ins require central management via IT infrastructure management tools or by the end users themselves?
Access control: Do the plug-ins require access to other resources, such as files on the end-user workstation or elsewhere in the environment?
You usually need to dissect your end-user workstations to answer the questions in the preceding list and identify other issues that may make the difference between easily recovered end-user workstations and those that just won’t work despite a lot of troubleshooting.
Managing mashups
Some Web-based applications have code that brings in content and functions from a lot of different applications at the same time. Mashups use APIs (Application Programming Interfaces — ways of getting at information from within another program) from various Web sites, blending code from these different sources to create the result seen in the browser window. Here are examples of some visually interesting mashups:
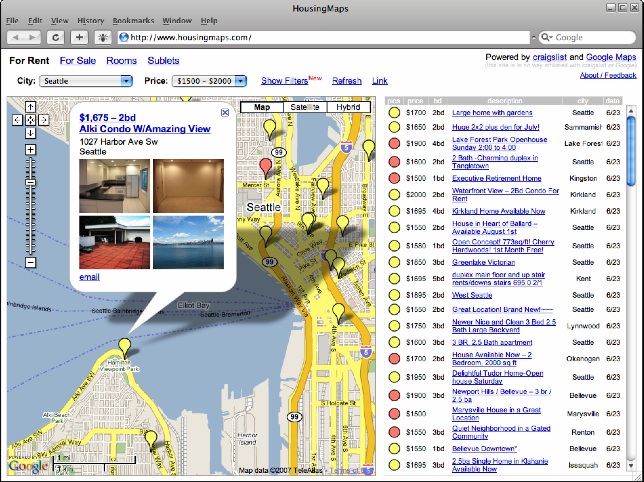
HousingMaps.com: A mashup of Craigslist classified ads and Google Maps. HousingMaps.com shows individual classified ads against a Google Maps backdrop, allowing the user to choose items by their visual location. Clicking a pin brings up an Ajax window with the address and thumbnails. You can see HousingMaps.com in Figure 5-1.
Chicagocrime.org: This mashup shows reported crimes of various types against street maps of the city of Chicago.
In some critical environments, such as the sites in the preceding list, mashups aren’t small potatoes — they’re necessary elements of an application.
Applications that don’t have well-documented specifications make you do some sleuthing to discover mashups. You can start by talking with the application’s Web developers. Then, you have to do some analysis to determine whether any of the mashups you found are critical to the user experience or are merely nice-to-have features.
|
Figure 5-1: A mashup that combines Craigslist and Google Maps. |
|
Recovery notes for workstations as Web terminals
In this section, I discuss specific recovery efforts that an organization might take in order to get workstations as Web terminals up and running as quickly as possible during and after a disaster.
Many of the concepts in the following list are proactive in nature — they’re things you need to do far in advance before a disaster occurs:
Use standard configurations for Web terminal workstations. Developing and sticking to standard configurations has many business benefits, including recoverability. Ensure that standard configurations include all necessary plug-ins, document viewers, network configurations, authentication settings, and other items necessary for the workstations’ proper function.
Use imaging technology for standard configurations. Using standard images permits your IT department to quickly build (meaning install and configure the operating system, applications, and tools for) replacement workstations.
Build workstation images for a variety of hardware configurations. Having these images increases the likelihood that IT staff will be able to build workstations by using not only the hardware that your organization uses on a regular basis, but also other hardware that you use less often.
Consider using a thin-client workstation model for production use, as well as for recovery purposes. Thin-client technology, such as Citrix, permits workstations to act as terminals, even when the workstation uses programs such as Word and Excel, which are actually run on a central server rather than locally on the workstation. A thin-client environment greatly simplifies centralized management and configuration of client-side software.
Back up workstation imaging systems so that you can quickly rebuild them in a disaster. These backups facilitate the rapid recovery of end-user workstations.
Also consider the workstation operating system recovery issues discussed in the section “Managing and recovering workstation operating systems,” later in this chapter.
Workstation access to centralized information
I would argue that a sensible organization promotes (if not requires) that documents, spreadsheets, and other files are stored centrally on servers, rather than solely on user workstations.
Workstations that function as Web terminals, distributed application clients, and standalone computing platforms also need access to centralized information, often in similar ways and requiring some common features and services to do so.
The types of server access workstations require include to
File and print servers
Web servers
Application servers
I explore these types of access in more detail in the following sections.
Accessing file and print servers
File servers store information for workgroups, departments, and organizations, often organizing the information into hierarchies of folders. IT departments often set up one or more drive letter mappings, in which they map a PC-like drive letter, such as M:, to a file server name, such as \\server2\depts\legal. Linux and Mac systems use different mechanisms than Windows, but the effect is the same.
Print servers operate similarly, except that they facilitate access to network- or direct-attached printers, plotters, and other output devices.
Here are the primary issues related to file and print server access:
Mapping: Whether through Windows drive mapping, shortcuts and links, Samba, or NFS (Network File System), end-user workstations require some configuration information so they can find the server.
Authentication: Users need to authenticate to the network, or to servers directly, in order to access files and printers.
Access controls: File and print servers use access controls that determine which users can access directories, files, and printers.
Directory service: Applications need domain name service (DNS) or Windows Internet Name Service (WINS) so user workstations can locate systems on the corporate network, such as application servers, file servers, and print servers, as well as systems on the Internet.
Accessing Web servers
Web servers facilitate access to both static content and information in applications. Web-server access issues include
Authentication: Users often need to be authenticated to networks and/or applications in order to access content on Web servers.
Access controls: Web servers use access controls to determine which users and groups are permitted to access specific information in the Web server.
Directory service: Workstations need domain name service (DNS) so they can locate Web servers on the network.
Accessing application servers
Application servers run software programs that are a part of a business application. Client/server and distributed application environments also have separate application components installed on end-user workstations. This client/side software needs to be able to communicate with application servers.
Issues related to application server access include
Authentication: Applications need to know who’s requesting access. Usually, the client-side component collects user credentials and passes them to the application, which then must consult an internal database or a network-based authentication service to validate the user.
Directory service: Workstations need domain name service (DNS) so end-user workstations can find servers and other resources on the network.
Recovery notes for workstation access to central information
When end-user workstations need to access various types of information on the network, file servers, Web servers, and application servers manage this access. Consider these tips for preparation and recovery:
Properly configure DNS and/or WINS so end-user workstations can find these servers on the network.
Include a network authentication service so users can identify themselves to servers and other resources.
Make the entire set of access control permissions within servers easily recoverable and transferable to replacement servers so the same access controls protect information in a recovery environment.
Regularly back up servers — or replicate data to off-site servers — so you can recover data in the event of a disaster.
Set up a replacement network that has different IP (Internet Protocol) address numbering and different logical and physical architecture so you can transfer the entire set of workstation-server interaction if you need to.
Consider bandwidth-intensive interactions between servers and workstations for optimization. In a recovery environment, servers and workstations may be separated by considerable distance and/or slow networks.
Workstations as application clients
Client/server computing revolutionized computing in the early 1990s by freeing up valuable resources on central computers and moving UI (user interface) logic out to end-user workstations that had relatively ample computing power. Many organizations implemented client/server applications, and many of those applications are still in use today.
One of the issues that was often overlooked in client/server computing was the burden of managing client-side software and related configurations. Network-based workstation management software was still in its infancy, but even in today’s more advanced management platforms, managing client/side software is still a major chore for IT shops. So, naturally, you need to make the whole matter of client-side software management a part of your DR plans if you have any client/server software.
Often, client/server software has multiple client-side components, including
Base software: Software installed on application servers
Client-side application business logic: Software installed on workstations
Configuration data: Settings that determine how base software and client-side software communicate with each other
Patches: Fixes and updates made to the base software and client-side software since initial installation
When I use the term client/server in this book, I mostly refer to distributed, two-tier, three-tier, or multi-tier applications with some of the pieces running on your end-user workstations.
The following sections delve into the management and recovery of these components in greater detail.
Client/server base software
Some client/server environments use a standard client-side software package installation, plus separate programs or scripts for each business application.
A number of questions and issues about client/server base software arise:
Installation: Can you make the base software a part of the workstation image? Can you automatically install it over the network? To install the software, does a human need to enter a license code or configuration data?
Availability: Is the version you’re using still generally available?
Release/installation media: Do you have portable release or installation media for the software?
Compatibility with newer operating systems: Does the base software work with newer versions of Windows and other operating systems?
The questions in the preceding list indicate that you’re dealing with old software. Client/server environments aren’t in this season, and they haven’t been for quite a while. The main question you need to ask about your client/server software is, “Could I rebuild the client side of my client/server environment if I had to rebuild it from scratch?” The preceding list should help you find the answer.
Client-side business logic
Client/server applications have some of the application code running on the server and some running on the client. On the client side, the software is installed and updated in some manner. You can use some of the following mechanisms to get client-side software onto the workstation:
Written (and, optionally, compiled) by a developer and installed through an updating mechanism within the client/server environment
Written by a developer and installed through a separate updating mechanism, such as Microsoft SMS (Systems Management Server)
Written by a developer and installed manually by IT personnel, either in person or through an Internet (or intranet) connection
The preceding list isn’t all-inclusive, but it can jog your memory about the possible means by which client-side software in a client/server environment finds its way to the clients — your end-user workstations. You can find information in the manuals that came with the base software — hopefully, someone has saved those manuals!
Client-side configuration data
Depending on which client/server environment you’re using, your end-user workstations may have another dimension to consider — configuration settings in the workstation’s client/server software. Configuration settings may be separate from the client-side code itself. Centralized management tools may manage those settings, or you may have to make any adjustments manually on each workstation.
Here are some of the possible configuration settings:
Server name
Port number to use when communicating with the server
Authentication settings
Behavior settings, such as initial views
Usability settings, such as colors and fonts
Some of these settings are critical to the basic function of the application, but others are more for the user’s convenience and preferences. All of the settings in the preceding list, except for usability settings, may govern whether the application functions.
.jpg)
Client-side patches
Your client/server environment may use patches to get software, application, or configuration updates out to client systems. If your environment uses patches, it may have its own patching mechanism, or it may use a centralized mechanism, such as Microsoft SMS (Systems Management Server), or a third-party tool, such as Blade Logic.
Consider the following client software patching issues:
Does the client/server environment use patching at the application level?
Can you use a management view to determine which clients have which patches installed?
Is the historical record of patching well documented?
The answers to the questions in the preceding list can tell you how to make updates to client-side software, as well as determine what patches are on your client workstations today. I discuss patching in more detail in the section “Managing and recovering workstation operating systems,” later in this chapter.
Recovery notes for workstations as application clients
The following list gives you some specific preparation and recovery actions that you can take to get end-user workstations that have client/server software back on the air:
To the greatest extent reasonably possible, use standard configurations for client/server workstations. Standard configurations also help reduce support costs. Ensure that standard configurations include all necessary components, from base software to application code and configuration, and whatever OS settings are required to support the software.
Use imaging technology and tools that can help you quickly build replacement client/server workstations. Test your images in a variety of workstation types: In a disaster scenario, you may have to build workstations on hardware platforms that you don’t routinely work with.
Consider a thin-client environment, with client/server software installed on servers, reducing workstations to smart terminals. Thin-client technology, such as Citrix, enables the organization to centralize client-side software installation, configuration, and maintenance.
Back up workstation imaging systems. If you can recover those imaging systems in a disaster, you can use them to build new client/server workstations, as needed.
The section “Managing and recovering workstation operating systems,” later in this chapter, explains how to recover the base operating system on end-user workstations.
Workstations as local computers
Many workers in an organization use their workstations to compose and manage documents, spreadsheets, presentations, technical drawings, and project plans. Workstations may have additional software tools for application development and testing, data analysis and modeling, graphical modeling, statistical analysis, and who knows what else.
Often, users store the data (the actual files or databases that they create and use) locally on the workstation, especially when the workstation is a laptop.
The management and recovery of workstations as local computers have three important aspects:
Programs: The application programs that you use to create and manage documents and data.
Data: The data that users create and work with on their workstations.
Procedure: Documents about the use of local programs, in terms of its support of critical business processes.
The three classes of information in the preceding list differ greatly in terms of management and recovery. When you determine that workstations fall in the critical path of business processes, both programs and data are vital, but you manage them in different ways.
Workstation software
A successful disaster recovery effort needs to manage the local software for workstations on the critical path of business processes. Consider these factors as you build your DR plans:
Installation: What method do you use to install programs into the local workstations? Are the programs part of a standard workstation image, or do you install them by using an install image on a server? Did the end user purchase the software directly? How do end users or the IT department manage activation keys? What installation options are chosen? (Now you know why IT departments are averse to a lot of non-standard tools on workstations!)
Configuration: Are configuration settings centrally managed, or does each end user control them? If more than one end user performs similar tasks, do they all use identical configurations?
Versioning: Does IT control which versions of software tools get installed and maintained on workstations? Do workstations have the latest versions or some older versions? Can these older versions be installed on newly-built workstations? Will the vendor provide license keys for the older versions that you still use?
Patches: Do the programs on end-user workstations have patches installed? Are those patches configured to check for and install updates? Do the end-user workstations need access to release media in order to install patches? Do patches alter the behavior of the software, potentially altering the business process (or other systems)? Do you maintain any central management or recordkeeping related to patches?
Configuration: Document settings associated with the correct operation of the program, rather than the look-and-feel preferences (although those preferences are important, too, because they help make end-user procedures more consistently match the actual appearance that the workstation software imparts).
The issues in the preceding list should get you thinking about your own environment. You may have more issues to consider as you develop your DR plan.
Business data on workstations
When I encounter a situation in which an employee’s workstation is, in fact, on the critical path for a critical business process, the first question I usually ask is, “Why?”
Warnings go off in my head when I hear about an employee’s workstation in any process’s critical path. Here are my main concerns:
High integrity storage: IT can’t (and shouldn’t) guarantee the integrity of storage on end-user workstations. Hard drives fail — it’s a fact of life. You should store business information on systems with commercial-grade storage — maybe RAID (Redundant Array of Independent Disks), mirroring, or another option.
Backups: Regularly back up business information, especially when that information is associated with critical business processes. Typically, IT backs up IT servers but rarely backs up end-user workstations.
Management: IT servers are generally better managed than end-user workstations. IT servers are more likely to have correct configuration and protection, patches, and so on. IT has absolute control over its servers, both in terms of physical access and everything about configuration and use.
Environment: End-user workstations are subjected to abuse: Users drop them, subject them to extreme temperatures, and spill coffee on them. IT servers, on the other hand, are housed in facilities with controlled temperature and humidity, and they don’t get knocked around nearly as much as a user’s laptop.
Power: Cleaner power protects IT servers. An Uninterruptible Power Supply (UPS), line conditioners, or generators can assure the servers’ power is never interrupted.
Physical access: Businesses usually put IT servers in locked rooms with controlled and limited access. End-user laptops, on the other hand, are out in the open and frequently stolen.
Availability: All of the factors in this list make data on IT systems far more available to all users when they need it, when compared to data on an employee’s laptop, wherever it might be at a given moment.
Keeping critical business information on end-user workstations involves a lot more risk than centrally storing and managing that same information on IT servers. Still, you may have situations in which end users must process data locally, with very sound business reasons for doing so. Here are a few examples of such practices:
Field-based operations: Field workers in many industries (including, but certainly not limited to, workers in insurance claims, building inspection, law enforcement, and disaster relief) must collect information in the field by using computer-based data entry. Even in situations in which workstations are equipped to connect to the Internet, those workstations often can’t get a strong enough signal, so the user has to work offline.
Work in-transit: Many workers travel extensively, and they often have to work on contracts, presentations, strategies, and so on while they travel. A laptop computer on a trans-oceanic flight is a boon to productivity.
Document management: Workers in most any business department are responsible for creating policy documents, legal contracts, procedures, and so on. If workers want to make changes to these kinds of files, they should check out those documents from a server to their workstations, make the appropriate changes, update the server. Editing documents — especially large ones — over the network can be difficult because of the slow response time you experience over a network versus accessing the document stored on the local hard drive.
Businesses can have many legitimate activities that require workstations with their own standalone software tools and business information storage. You may or may not be the one to make judgment calls about the legitimacy of this or that use of standalone workstations.
Using workstations as standalone computers, including using local tools and locally stored business data, is more complicated in many ways than other workstations uses. The issues related to managing business information stored on user workstations include
Availability: Whether users can access the data when they need it, not only from the workstation it resides on, but from other workstations. Because of availability issues, don’t store critical business information on a lone workstation — instead, locate it on a centralized server so that users can access it from anywhere.
Capacity: Workstations are fickle beasts, and their users are unpredictable. If a user fills up his or her workstation with other information, whether business-related or not, how can he or she perform important tasks with what little resources remain?
Confidentiality: You need to protect business information from unauthorized disclosure. Control and log who accesses business data on the workstation by using mechanisms such as file or whole-disk encryption, access controls (user IDs and passwords, and possibly also a biometric, smart-card, or other two-factor authentication), and access logging (in which the computer tracks who accesses the data).
Integrity: Put controls in place to ensure that business information on the laptop isn’t changed by anything other than officially permitted means. Permit only specific users and programs to access and make changes to the data.
You can manage most of these issues more easily on IT servers, but if a workstation is really on the critical path for business processes, you need to address these issues to protect the integrity of the process.
Procedures for using workstations
When business processes include tasks that employees carry out on workstations, you need to establish written procedures for those tasks and for other steps in the process that take place on other workstations and servers. Give all tasks in a business process equal formality, regardless of whether they take place on a formal IT server platform or a user’s workstation.
Gap in PC procedure causes corporate crisis
Some years back, while I was working as a consultant, a colleague in another organization came to me for help. In this international organization and U.S. public company, the finance department couldn’t close its quarterly financial books in time to meet an S.E.C. (U.S. Securities and Exchange Commission) filing deadline.
The finance department had missed the deadline by several days, and the matter had become a corporate crisis that reached the CEO and the boardroom.
The cause? An overseas subsidiary couldn’t close its books. The reason? One of the steps that the overseas subsidiary took to complete its month and quarter-end financials was a procedure in which a financial report was downloaded to a PC’s spreadsheet program, where a spreadsheet macro performed some calculations that the subsidiary used in its financial results.
This time, the subsidiary ran into a problem: The macro had become corrupted and wouldn’t run.
The contractor who created the macro was nowhere to be found. No one in the finance department knew what the macro did or how it worked. That macro was an undocumented step in this critical business process; the original software was gone, and nothing about it was documented.
Avoid this kind of a scenario in your organization by formally documenting and controlling all software that you use to process business information.
Recovery notes for workstations as local computers
Using workstations as local computing platforms has some operational risks. Nonetheless, it’s advantageous and necessary in many circumstances.
Follow these preparation and recovery steps to successfully recover work station-based functionality in the event of a disaster:
Use formal change and configuration management capabilities while managing software tool installations and configurations on critical workstations.
Ensure that formal process, procedure, and task documentation for business processes includes all of the steps that are performed on workstations.
Such documentation should cover not only procedural steps, but also the workstation and software tool versions and configurations required to support the tasks.
Take steps to ensure that business information on workstations is easy to recover.
You may need to regularly back up data, or you may need to know how to recover lost data by repeating steps used to obtain information from its external source(s). In fact, you may need to do both, depending on the details surrounding the workstation procedures.
Make sure that you have sufficient controls in place on end-user workstations to prevent unauthorized access to business information on the workstation and the tools used to create and/or manage that information.
Consider both preventive controls and detective controls, depending on implementation details and associated risks. Talk with your internal or external auditors if you’re unsure of the role of controls and risks in your organization.
Be sure that workstation operators understand the procedures associated with processing workstation-based information, as well as general security procedures and precautions.
Use imaging procedures or tools that can manage the entire workstation footprint, as well as quickly build or rebuild workstations.
Imaging and workstation build procedures need to cover all aspects of operating system and tool installations and configurations.
Make sure that workstation imaging and provisioning procedures include software licensing and activation steps.
Also, be sure that you can recover business information onto newly built workstations in disaster scenarios.
Consider recovering critical workstation functions in a Citrix-like environment, in which you can house tools and data on IT-managed servers.
Also, consider the workstation operating system recovery issues discussed in the following section.
Workstation operating systems
Operating systems power workstations. Whether Windows, Linux, Mac OS, or something else, operating systems are at the heart of end-user workstations, no matter whether they’re used as intelligent Web terminals, distributed computing clients, local computing platforms, or all of the above. Rather than repeat all the OS-centric issues in each of the sections in this chapter, I discuss them in this section.
This list includes the major facets of workstation operating systems that require attention for recovery purposes:
Hardware platform
Operating system version, configuration, and patch levels
Network connectivity
Authentication
Authentication resets during a disaster
Security
In the following sections, I discuss all the elements in the preceding list.
Hardware platforms for workstations
In the context of disaster recovery planning, knowing and tracking hardware platforms for end-user workstations is a critical activity. You need workstations in some capacity during and after disasters so you can recover and operate critical processes.
Each hardware platform has its own workstation image — the files, directories, and configurations that are installed on that workstation. Often, when a workstation manufacturer updates the hardware, even within a specific model line, the changes require that you update the image to accommodate differences in the hardware. IT departments can end up managing dozens of images at any one time, not to mention the archive of images they need to retain for all of the older workstations still in use.
Recovery of end-user workstations can take on a life of its own in a disaster scenario. In a situation in which business offices have suffered significant destruction, recovery teams may need to build entirely new workstations from the ground up so that essential personnel can get back to the business of recovering and operating critical business processes. But what if you can’t get your hands on the standard make and model of workstation hardware? Time-critical processes demand that you build workstations, often the backbone of computing, on whatever hardware platform you can get — very likely, you have to work with a different brand entirely. You may find your inventory of ready-to-run images useless because those images probably won’t work on the replacement workstations.
Recovering mobile platforms
Mobile computing platforms, such as PDAs and smart phones, are becoming more commonplace, and they may increasingly become critical platforms. In fact, during a disaster, they might be the only way to get some things done.
The principles of planning for the recovery of mobile platforms are the same as for end-user workstations — but the technologies and the dependencies are a little different.
In your DR planning, you might need to develop recovery or alternative plans for mobile devices, or mobile devices might be viable alternatives to thicker platforms, such as laptops.
The security mechanisms for protecting information on mobile devices is less mature than what you find on laptops. You may need to conduct a risk analysis to understand the risks associated with storing corporate information on mobile platforms.
Operating system version, configuration, and patches for workstations
Managing operating systems (OSs) on a small number of servers is a lot of work. But managing OSs on larger numbers of end-user workstations presents many special challenges that you must meet if you want the organization’s DR strategy to succeed. End-user workstations are in the equation of nearly every business process and business application — they’re the windows (no pun intended) into applications and data. Without them, businesses are blind, deaf, and dumb.
Managing operating systems has its own set of issues, including these concerns:
Supported versions: Knowing what OS versions are in common use, and which user workstations they’re on at any one time, may be a key component to your DR plan. The ability to recover end-user functions may depend on which versions of operating systems you’re using so you can get critical users up and running in a disaster scenario as soon as possible.
Operating system patches and updates: Know what OS patches and updates are supported and working on user workstations. Depending on your environment, you may need to know which updates and patches are supported, or you might need to go the extra step and actually figure out which specific patches and updates are present on each critical user’s workstation. Your application and tools requirements dictate how much detail you need to know.
Operating system configuration: Modern OSs have more knobs and dials than the Space Shuttle, but you can use only a finite number of known, supported combinations on those OSs. You need to know the configurations for many scenarios, supporting every type of connectivity, every tool and application, and every type of user.
End-user capabilities: Knowing what each end user can do on a workstation is an important element in DR planning. If your end users are local administrators on your workstations, you’ll have a more difficult time managing workstation configurations because end users can make many changes on their own.
Supporting business applications and functions: Know the required OS version, patch level, and configurations for each tool and application that runs on the workstation. You can either document those configurations now or figure them out in a disaster scenario when you’re frantically trying to get a workstation functioning correctly while the executives are tapping their fingers nervously.
The devil’s in the details, and the OS is probably the biggest bucket of details you have to consider and accommodate.
Network connectivity for workstation operating systems
You need to understand the methods of network connectivity in use in your organization, regardless of a workstation’s function. Web browsers and applications must be able to communicate with systems inside the business and possibly in the external world.
I discuss several connectivity scenarios in this section, and I may address issues related to your specific environment. Understanding these cases can help you better understand your own environment:
Network access control: Do your target applications limit access tospecific IP addresses or IP ranges? If so, you may need to reconfigure them so your recovered workstations can still connect, even if they’re connected to new, temporary networks.
Remote Access/VPN (Virtual Private Network): Are your applications and servers accessible via any existing remote access or VPN service? If not, you may have extremely limited recovery options because you may need to temporarily locate recovered users away from your server environment.
Access to multiple servers: Do your applications require concurrent access to multiple application servers? I discuss this concept in the “Managing mashups” section, earlier in this chapter.
The connectivity issues in this section all relate to your applications. Your business probably uses workstations as devices to access business applications, and some of those applications are at the heart of many business processes. If you can’t get to the applications (or file servers or whatever resources are critical to the support of business processes), do your workstations have any value?
Authentication for workstation operating systems
Users have to provide credentials to log on to enterprise resources — or do they? Authentication occurs in several different ways, from the very simple to complex and esoteric. You should explore some of these authentication elements:
User ID and password: Easy enough, in most cases.
Biometric: Usually requires extra hardware, such as fingerprint scanners. If employees log in to applications that require biometric authentication, how will that work in a disaster scenario?
Smart card: Similar to the biometric problem, smart-card authentication requires hardware that most workstations don’t have.
One-time password: Often, one-time passwords take the form of tokens and similar devices. Although users may still have their tokens in a disaster scenario, the token-authentication infrastructure may not still be operating.
Single identity and single sign-on: Some Web-based applications depend on centralized services to manage authentication. I cover this authentication process fully in Chapter 8.
Authentication resets during a disaster
Users need an authentication reset if they forget their passwords, fat-finger their logins and lock themselves out, or lose their smart cards and security tokens. With this in mind, you might consider the following methods for managing resets:
Passwords via e-mail: Often, applications can e-mail the existing password, a new temporary password, or a new permanent password to a user who has lost his or her password. For this password assistance to work, the user has to have access to e-mail.
Passwords via live support: In many cases, users can call a manned support desk to get their passwords reset. Of course, you need to have a manned helpdesk available in a disaster situation for this approach to work.
For additional information on authentication, check out Chapter 8.
Workstation operating system security
Security is the thread that’s woven into most IT fabrics these days. I mention security in several places in this chapter, but these security issues deserve their own list:
Security configuration: Security configurations in every layer of the workstation stack — from BIOS passwords (hardware passwords required to boot the computer) to application authentication, and many places in between — enable recovery if you properly configure them or stop recovery dead in its tracks if you don’t.
Encryption keys: You can use encryption in many places, including file encryption, e-mail message encryption, session (communications) encryption, encryption of data such as credit cards and passwords, and encryption of entire workstation hard drives. When you work to recover processing capabilities, you often need to recover the original encryption keys to facilitate the continuation of processes. Often, you can’t simply create new encryption keys because the new keys don’t allow access to data that you encrypted with the old, pre-disaster keys.
Digital certificates: You use certificates (which are closely akin to encryption keys) for encryption, digital signatures, and authentication. And like encryption keys, you often can’t simply create new certificates to access data stored under old certificates.
Security is often an enabler when you design it from the beginning into an application environment. This is evident in effectively designed authentication and data protection mechanisms, as I discuss in this section. But when you omit key components of security from your DR plans, security can be the thing that prevents recovery.
Recovery notes for workstation operating systems
You need to plan for workstation operating system (OS) recovery, regardless of whether your business uses those workstations as Web terminals, clients in distributed environments, or standalone computing platforms. Follow these preparation and recovery steps to recover workstation operating systems:
1. Install an OS.
This broad category covers licensing, installation media, activation, and imaging for workstations. If you have an older version of an OS, be sure that you’ll still be able to activate it well into the future. A disaster isn’t the time to discover that the OS vendor can no longer activate an OS platform that you need to recover a critical business function!
2. Configure your OS.
Whether you have centralized workstation OS management or you configure OS components manually, you need to identify and document all the salient points of workstation configuration so you can configure workstations to support critical business functions.
3. Patch and update your OS.
Know what versions of OS patches and updates workstations need to support applications, network access, and other functions.
4. Set up authentication and access control.
Make sure you can support both local and network-based authentication so users can access the resources they need to continue critical functions. You may also need to include any configuration or hardware necessary to support two-factor authentication.
5. Set up networking and remote access.
Recovered workstations must be able to access resources across networks, including new, temporary networks that you may need to set up in a disaster. You may need to change server- or network-side configurations to permit new methods of access.
6. Set up security.
You may need encryption keys, digital certificates, and other security settings to facilitate access or proper processing.
The items in the preceding steps are broad, high-level preparation needs. You may also need to identify and attend to a lot of details to make sure you have the greatest level of preparedness when disaster strikes. Also, you may need to follow additional steps for your specific organization and business needs.
Managing and Recovering End-User Communications
Although end-user computing is definitely an important aspect of employee support of business processes, communications are arguably even more important. Even in peacetime (meaning when you don’t anticipate a disaster), communications are a vital ingredient in everyday business. Employees routinely rely on one or more of the following elements in support of business processes:
Voice communications or voice mail
E-mail
Fax
Instant messaging
I discuss these elements in the following sections.
Voice communications
Organizations equip their workers with voice communications in a wide variety of ways, including but not limited to
Simple direct-dial telephone service
Telephone company-based PBXs (Private Branch eXchanges, formerly known as Centrex — a fancy word for a telephone system), in which the local telephone company manages direct-dial extensions for a business.
Analog or digital PBXs connected to analog or digital office extensions
IP-based PBXs connected to digital or IP-based phones, or connected to IP-based softphones via wired or wireless networks
Your organization may have more advanced voice communications capabilities, including
Voice communications integrated into contact-center management systems
Inbound 1-800 service, possibly with inbound load balancing and capacity management services that route incoming calls to one or more contact centers
Managed or predictive outbound dialing systems integrated with contact-center management systems
Integration with wireless carriers, either through extension trunking (a way of connecting branch offices to main offices, for instance) or on-premise wireless base stations
Voice mail connected to e-mail gateways
The preceding lists should drive home the point that your voice telecommunications capabilities, in and of themselves, may warrant extensive DR projects! These projects can get especially complicated because you may have extensive types and levels of integration between enterprise applications, telecommunications, and the telephone companies themselves. The complexity of these systems requires detailed planning that’s beyond the scope of this book.
I could devote an entire book to DR for voice communications alone. Here are preparation and recovery tips to ensure rapid recovery of voice communications:
Use formal management of voice capabilities, which includes change management, procedure documentation, and configuration management.
Back up all configuration information in PBX and other supporting equipment so you can recover those systems.
Identify all integration points between PBX, other supporting equipment, and other internal networks, systems, and applications.
Formally document all such interfaces and integration points, both in terms of configuration and operations procedures.
Identify all integration points between PBX, other supporting equipment, and external service providers, including telecommunications service providers and other entities.
Formally document all these interfaces and integration points.
Identify integration points between voice communications and other forms of communications, including but not limited to voice mail, e-mail, and wireless.
Identify business continuity planning efforts that support customer contact centers and other business functions that rely heavily on inbound and outbound voice communications.
Make sure that you have ample coordination between business continuity and disaster recovery planning efforts because the two are symbiotic in nature.
Consider alternative carriers, service providers, and other contingencies for emergency voice communications in the event of a disaster.
Remember that much of an organization’s voice communications capabilities depend on external suppliers and service providers, whose disaster response may or may not translate into rapid and timely restoration of the services that your organization needs.
Develop emergency contact lists for emergency operations personnel, other responders, and parties who will be involved in disaster operations.
Include several means for contacting these individuals. A regional disaster may result in the widespread failure of several forms of communications.
Because of the wide variety of complexity and integration with other systems, your own needs may vary from the preceding list.
Once considered a nice-to-have mode of communication, e-mail is now con-sidered critical in most organizations. People use e-mail not only to communicate routine messages, but also as a file transfer mechanism and a formal alerting mechanism. Increasingly, applications send and receive e-mail as part of their normal function. Take away e-mail, and nearly everything stops dead.
Aspects of e-mail that typical DR projects need to address include
E-mail clients
E-mail servers
E-mail gateways to the outside world
E-mail gateways and interfaces to internal applications
E-mail security
You can look at these areas in more detail in the following sections.
E-mail clients
In most architectures, users who send and receive e-mail do so by using client software that’s installed on their workstations. This software provides the user interface with which users read, create, and send e-mail, and often also locally store e-mail messages. Some issues to consider about e-mail clients include
Configuration: E-mail clients often have several configuration items that deal with a user’s identity, the location of mail servers in the organization, where local messages are stored on the workstation, and so on.
Local e-mail storage: Many e-mail clients locally store e-mail messages, enabling the user to read and compose e-mail messages while offline.
Address lists: E-mail clients often allow the user to create local lists of recipients, groups, and aliases within his or her own address list. In some environments, these local lists may also be stored on the e-mail server.
Filters and forwarding rules: Many e-mail clients include the ability to store, delete, or forward messages based on criteria.
You’d be surprised at the number of organizations that depend on these user-centric features on the critical path of important business processes.
E-mail servers
E-mail servers receive, store, and forward e-mail to and from other e-mail servers and users. Larger organizations have several e-mail servers, with a portion of the workforce assigned to each server. One of these e-mail servers may also send and receive mail from external entities and the Internet, or separate servers may be dedicated for this purpose.
You need to address several issues when considering e-mail and servers:
E-mail storage: E-mail servers store e-mail messages in users’ mailboxes, and often they permanently store all sent and received e-mail messages for all users in the organization (except in cases in which a user can archive or remove his or her messages).
Recipient directories: E-mail users need to be able to locate other e-mail recipients in online address books. These recipients consist of other users in the organization, plus other entries, such as group addresses and external recipients that e-mail administrators put into the directory.
Groups, distribution lists, and aliases: E-mail servers often contain other e-mail recipients, including groups, distribution lists, and aliases.
Filtering and forwarding rules: E-mail servers often use rules for forwarding, filing, and deleting incoming messages.
The preceding list gives you just the highlights; your servers may have more features and functions that you need to identify, dissect, and incorporate into your DR plans.
E-mail gateways and Internet connectivity
In addition to transmitting e-mail among users within an organization, users can also send e-mail to recipients outside the organization. And e-mail from outside sources arrives for delivery to local recipients. In some environments, the main mail servers perform all these duties, but in others, separate systems handle these functions. You have plenty of issues to consider regarding your e-mail servers:
Configuration: The gateways and other systems that process e-mail have configurations that permit them to do their work properly. These configurations include information about neighboring mail servers and ways to get e-mail messages to the outside world.
Local storage: Often, these gateways store messages, usually but not always temporarily, while those messages wait to be transmitted to their final destinations.
E-mail gateway configurations are usually custom-built for an organization, and sometimes, no one fully documents the details of these configurations. If your organization doesn’t have this configuration documentation anywhere, someone needs to create it now.
E-mail interfaces
Organizations increasingly use e-mail to send messages and data to and from applications, not just people. Many systems and server applications can routinely send e-mail messages for a vast array of reasons, including
Status: Some applications and tools send information about their status to the people who maintain them.
Reports: Some applications send the results of reports and queries via e-mail to people who request or run them.
Errors: Applications can send e-mail messages to specific personnel when errors occur.
You can probably find a half dozen other examples of applications, tools, and systems that originate e-mail messages intended for recipients (or other applications, tools, and systems); the preceding list gives you just a few examples.
E-mail security
It’s becoming common practice for IT departments to configure e-mail systems to apply protection of various kinds to e-mail messages. This protection takes on various forms, and both servers and end users use it. The primary means for protecting e-mail messages are
Encryption: To scramble the contents of messages so that eavesdroppers can’t read them while those messages are in transit, users and systems apply encryption algorithms to the contents of e-mail messages.
Digital signatures: E-mail systems can use digital signatures, often known as hashing, to protect e-mail. Digital signatures don’t hide the contents of e-mail messages like encryption does, but they do tell the recipient whether the contents of the message were altered anywhere along the way between the originator and the recipient. Digital signatures also provide a way to verify the identity of a message’s originator.
Anti-spam: E-mail systems often employ spam filters that block and remove (or quarantine) incoming e-mail messages that the filters think might be spam. Spam filters can block spam in four ways:
• Server-based: Spam-blocking programs can run on the same system as the e-mail server.
• Appliance: A separate hardware appliance can block incoming spam so the spam doesn’t enter the e-mail server.
• Client: Spam blocking software can run on the client workstations, blocking spam messages after they arrive in a user’s inbox.
• Service provider: All e-mail coming into an organization is sent to a spam-blocking provider’s server, which filters the spam and sends the good e-mail to the organization’s mail server.
Anti-virus: E-mail servers often have anti-virus software that removes viruses and other malware from incoming e-mail messages before they’re delivered to end users.
Recovery notes for e-mail
E-mail is the message plumbing in organizations, with wider scope and application than you probably know about. As you scrounge around in your e-mail environment and begin building your prevention and recovery plans, keep these tips in mind:
Know how e-mail flows into, around, and out of the organization — including servers, clients, gateways, and so on.
Document all the facts about your organization’s Internet domain registrations, which include MX Records that determine where incoming e-mail from the Internet should be delivered. Making the changes your business’s domain servers need to be prepared when a disaster strikes can take considerable time.
Trace all uses of e-mail through business processes to determine the e-mail addresses, distribution lists, filtering rules, and other features that those e-mail messages require to make it to their destinations.
Ensure that any replacement spam- and virus-blocking mechanisms that you introduce in temporary recovery scenarios don’t inadvertently block critical messages.
Make sure that e-mail servers have ample storage capacity during disaster scenarios. In disasters, e-mail may accumulate more than usual, resulting in far greater storage needs than on a typical sunny day.
Consider an e-mail service provider that uses an external service to receive and store all incoming e-mail during a disaster scenario. With this kind of provider, users log in to read e-mail over the Web. Make sure the provider can handle special-purpose messages, such as those that are sent from (or to) applications.
Consider pre-registering critical users (and non-human recipients) with an alternate e-mail server, just in case.
Archive all encryption keys and tools that your business uses to encrypt e-mail so you can still encrypt and decrypt e-mail messages in a disaster scenario.
Back up e-mail folders and systems so you can recover them if you need to. In a disaster scenario, you may need the ability to recover existing messages, not just send and receive new ones.
As you survey and analyze your end-user e-mail environment and identify all the critical-process touch points, you’ll probably uncover additional issues critical to your recovery.
Fax machines
Many organizations still rely heavily on facsimile (or fax) to transmit business documents, such as contracts, receipts, invoices, and so on. Although many organizations are making the transition to digital imaging, fax machines are nonetheless critical for many key business processes.
Here are some factors to consider for faxing in a business environment:
Directories: People who need to send faxes need to know those destination phone numbers. Capture your business’s fax numbers in process documentation, if those numbers aren’t already included.
Incoming fax numbers: Some organizations use widely advertised or publicized fax numbers. In a disaster scenario, the organization may need to have incoming faxes routed to another fax machine or fax server. You can coordinate this rerouting with a local telecommunications service provider.
Fax server configuration: Fax servers are systems that are connected to phone lines or T-1 circuits, and fax servers can accept larger volumes of incoming faxes than fax machines in an office environment can.
Fax server have rules for storing faxes, forwarding them to other faxes, and forwarding them to e-mail recipients in the form of attached image files. You need to know these rules for business processes that rely on faxes for critical tasks so incoming and outgoing faxes can continue to work properly in a disaster scenario.
An organization that relies on faxes for critical business processes needs to consider these tips for disaster preparation and recovery:
Record and document critical incoming and outgoing fax numbers in business processes.
Route critical incoming fax numbers to other locations in the event of a disaster that damages a facility or cripples communications.
Consider online fax for inbound or outbound fax needs. Several commercial services, such as eFax (www.efax.com), offer fax-to-e-mail and e-mail-to-fax services that are performed in remote, hardened data centers.
Record and back up fax server configuration and processing rules so you can recover critical faxes that use fax servers by whatever means you need.
Consider using the scan-and-e-mail approach for processes that currently use fax so you can reduce your business’s reliance on fax machines and phone lines.
You need to collect all the fax facts in your organization in order to expedite recovery.
Instant messaging
Instant messaging, or IM, is frequently considered an ad hoc, counterculture, or underground communications tool in many organizations. Still, many organizations use IM, and although it might not be on the critical path for business processes, it’s still handy for casual communications, such as
Hey, the conference call has started. Are you joining us or what?
Where are you?
My e-mail program just died. What’s the number for today’s online meeting?
These kinds of communications might be handy in a disaster scenario, when too few people are doing too many things in an unfamiliar environment.
Although IM might not be on your critical path, being able to use it during a disaster may help hold teams together. Consider these tips for recovering instant messaging:
Publish emergency response team members’ IM addresses on emergency contact lists.
Don’t rely on a single IM provider, in case that provider is involved in the same disaster you are.
If your organization uses a centrally managed IM server, consider setting up an external service as a backup.
If your organization uses only outside IM services, consider internalizing it and making it available in disaster scenarios.