Chapter 2
Water and Macromolecules
Organisms are made up of a lot of different chemicals. These vary in size, from small molecules like water to large molecules like DNA. In this chapter we will introduce some basic concepts of how these chemicals are made and how they interact to generate the processes of life. We will then describe the most important of these chemicals: water, carbohydrates, nucleotides, amino acids, and lipids.
The Chemical Bond: Sharing Electrons
Water is the most abundant substance in living cells. Cytoplasm consists of organelles floating in a watery cytosol that also contains proteins. The situation is not so different outside our cells. Although we are land animals living in air, most of our cells are bathed in a watery extracellular medium. We will therefore start by considering water itself.
Figure 2.1A shows a molecule of water, consisting of one atom of oxygen and two hydrogen atoms, joined to form an open V shape. The lines represent covalent bonds formed when atoms share electrons, each seeking the most stable structure. Oxygen has a greater affinity for electrons than does hydrogen so the electrons are not distributed equally. The oxygen grabs a greater share of the available negative charge than do the hydrogen atoms. The water molecule is polarized, with partial negative charge on the oxygen and partial positive charges on the two hydrogens. We write the charge on each hydrogen as δ+ to indicate that it is smaller than the charge on a single hydrogen nucleus. The oxygen atom has the small net negative charge 2δ−. Molecules that, like water, have positive regions sticking out one side and negative regions sticking out the other are called polar. Two linked atoms with an unequal distribution of charge form a dipole; water therefore has two dipoles.
Figure 2.1 Water is a polar molecule, while the chlorine molecule is nonpolar.
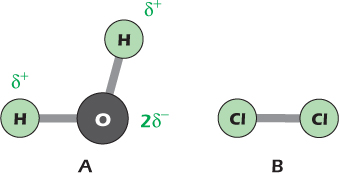
Figure 2.1B shows a molecule of chlorine gas. It consists of two chlorine atoms, each of which consists of a positively charged nucleus surrounded by negatively charged electrons. Like oxygen, chlorine atoms tend to accept electrons when they become available, but the battle is equal in the chlorine molecule: the two atoms share their electrons equally and the molecule is nonpolar.
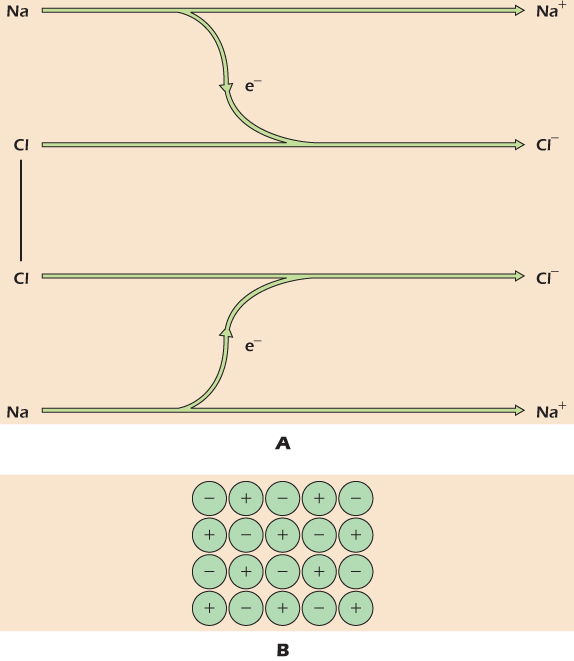
Figure 2.2A shows what happens when a chlorine molecule is allowed to react with the metal sodium. Each atom of chlorine captures an electron from a sodium atom. This leaves each sodium atom with a single positive charge because it now has one less electron than there are positive charges in its nucleus. Similarly, each chlorine atom now has a single negative charge because it now has one more electron than there are positive charges in its nucleus. Chemical species that have either gained or lost electrons, and therefore bear an overall charge, are ions. The reaction of chlorine and sodium has produced sodium ions and chloride ions. Positively charged ions like sodium are cations while negatively charged ones like chloride are anions. The positively charged sodium ions and the negatively charged chloride ions now attract each other strongly. If there are no other chemicals around, the ions will arrange themselves to minimize the distance between sodium and chloride, and the resulting well-packed array of ions is a crystal of sodium chloride, shown in Figure 2.2B.
Figure 2.2 Formation of sodium chloride, an ionic compound.
Interactions with Water: Solutions
Ionic Compounds Will Dissolve Only in Polar Solvents
Figure 2.3A shows one molecule of octane, the main constituent of gasoline. Octane is an example of a nonpolar solvent. Electrons are shared equally between carbon and hydrogen, and the component atoms do not bear a net charge.
Figure 2.3 (A) Structure of the nonpolar compound octane. (B) Ionic compounds are insoluble in nonpolar solvents.
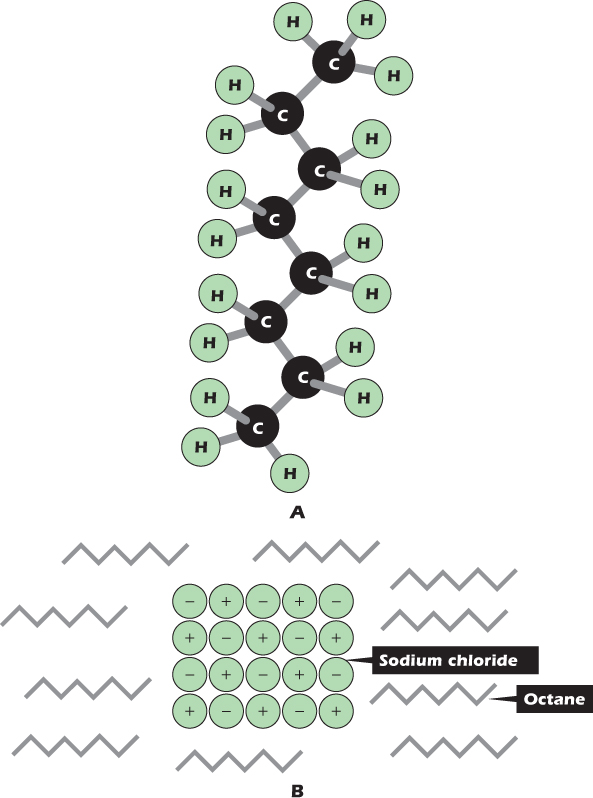
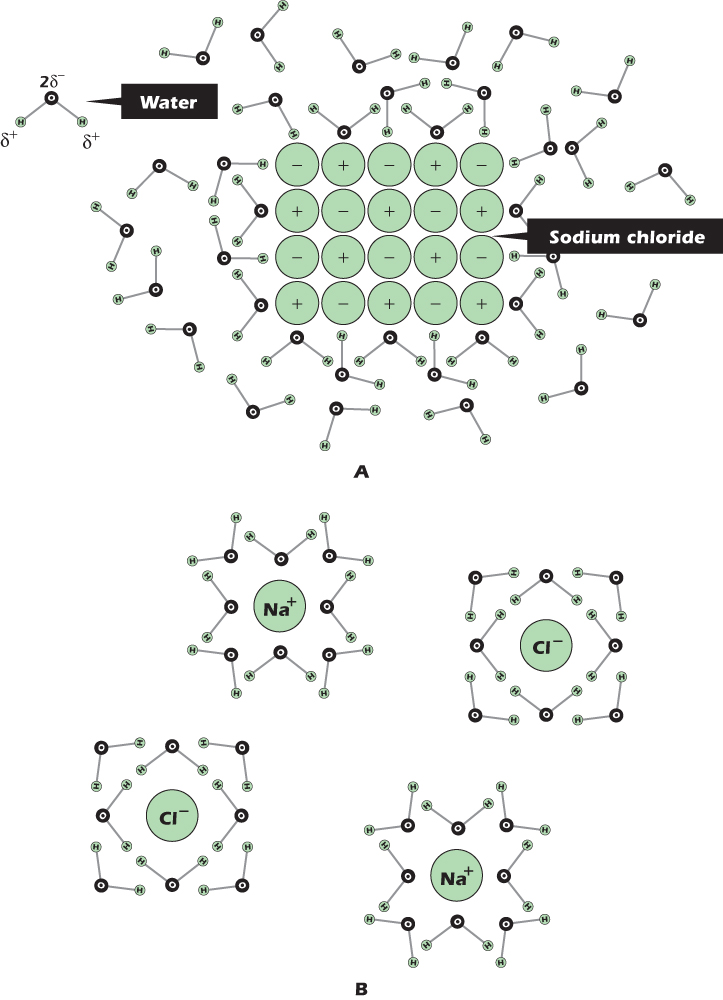
Figure 2.3B shows a small crystal of sodium chloride immersed in octane. At the edge of the crystal, positively charged sodium ions are being pulled in toward the center of the crystal by the negative charge on chloride ions, and negatively charged chloride ions are being pulled in toward the center of the crystal by the positive charge on sodium ions. The sodium and chloride ions will not leave the crystal. Sodium chloride is insoluble in octane. However, sodium chloride will dissolve in water, and Figure 2.4A shows why. The chloride ion at the top left is being pulled into the crystal by the positive charge on its sodium ion neighbors, but at the same time it is being pulled out of the crystal by the positive charge on the hydrogen atoms of nearby water molecules. Similarly, the sodium ion at the bottom left is being pulled into the crystal by the negative charge on its chloride ion neighbors, but at the same time it is being pulled out of the crystal by the negative charge on the oxygen atoms of nearby water molecules. The ions are not held in the crystal so tightly and can leave. Once the ions have left the crystal, they become surrounded by a hydration shell of water molecules, all oriented in the appropriate direction (Fig. 2.4B)—oxygen inward for a positive ion like sodium, hydrogen inward for a negative ion like chloride. A chemical species in solution, whether in water or in any other solvent, is called a solute. Liquids whose main constituent is water are aqueous.
Example 2.1 Salad Dressing Is a Mixture of Solvents
Vinegar is a dilute solution of acetic acid in water. Acetic acid gives up an H+ to water to leave the negatively charged acetate ion. The simplest salad dressing is a shaken-up mixture of olive oil and vinegar. Olive oil is hydrophobic and so does not dissolve in the water; the two liquids remain as separate droplets and soon separate again after shaking. However much one shakes, all the acetate will remain in the water because it is an ion. If salt (Na+Cl−) is added to the dressing, it also dissolves in the water, with none dissolving in the oil. In contrast, if you add chilies to the salad dressing, the active chemical component capsaicin will dissolve in the oil because it is nonpolar. Only by shaking up the mixture can you get all the tastes together.
Figure 2.4 Ionic compounds dissolve readily in water, forming hydrated ions.
Acids Are Molecules That Give H+ to Water
When we exercise, our muscle cells can become acidic, and this is what creates the pain of cramping muscles and the heart pain of angina. Acidity is important in all areas of biology, from the acidity gradient that drives our mitochondria to the failure of coral reefs resulting from CO2 buildup in the oceans.
Acidic solutions contain a high concentration of hydrogen ions. The hydrogen atom is unusual in that it only has one electron while, in its most common isotope, its nucleus comprises a single proton. In gases at very low pressure it is possible for bare protons to exist alone and be manipulated, for example, in linear accelerators. However in water protons never exist alone but always associate with another molecule, for example with water to create the H3O+ ion. Acidic solutions are those with an H3O+ concentration higher than 100 nanomoles per liter (nmol liter−1).
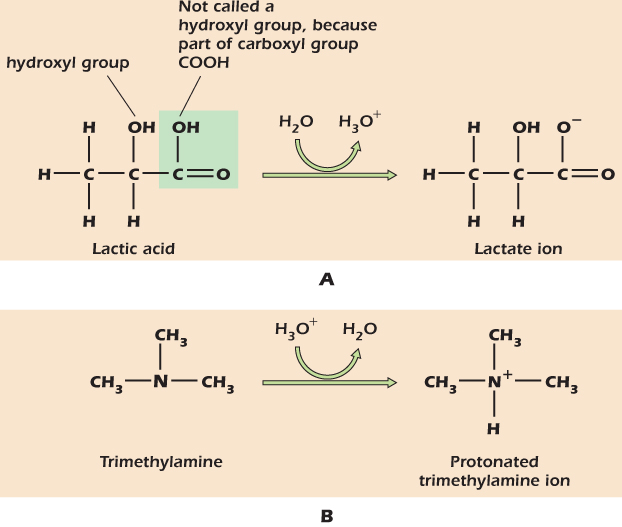
Sour cream contains lactic acid. Pure lactic acid has the structure shown at the left of Figure 2.5A. The —COOH part in the box is a carboxyl group. Both oxygens have a tendency to pull electrons away from the hydrogen and, in aqueous solution, the hydrogen is donated with a full positive charge to a molecule of water. The electron is left behind on the now negatively charged lactate ion:
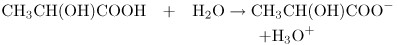
For convenience we often forget about the water and write this as
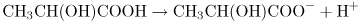
Here we are using H+ as a convenient symbol to denote H3O+. We do not mean that there are real H+ ions, that is, bare hydrogen nuclei, in aqueous solutions.
Figure 2.5 Acids and bases, respectively, give up and accept H+ when dissolved in water.
The equilibrium constant Ka for the dissociation of lactic acid is defined as
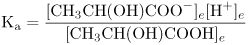
where the square brackets refer, by convention, to concentrations and the subscripts, e, denote that these are the concentrations of each species at equilibrium, that is, when the rate of the forward reaction
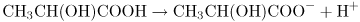
and the backward reaction

are the same.
Dissolving lots of lactic acid in water produces an acidic solution, that is, one with a high concentration of H+ (really H3O+) ions. For historical reasons, the acidity of a solution is given as the pH, defined thus:
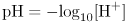
where [H+] is measured in moles per liter. Pure water has a pH of 7, corresponding to [H+]=100 nmol liter−1. This is said to be neutral as regards pH. If the pH is lower than this, then there is more H+ about and the solution is acidic. Cytosol has a pH that lies very slightly on the alkaline side of neutrality, at about 7.2.
The pH of a solution determines the ratio of lactate to undissociated lactic acid. As the H+ concentration rises and pH falls, the equilibrium is pushed over from lactate toward lactic acid. At pH 3.9, the concentrations of lactate and lactic acid become equal. Looking at the equation above, we can therefore see that when this happens Ka=[H+]. Just as acidity is given on the logarithmic pH scale, so is the scale of strengths of different acids, pKa being defined as −log10Ka. The pKa is the pH at which the concentration of the dissociated acid is equal to the concentration of the undissociated acid. For an acid that is weaker than lactic acid, the pKa is higher than 3.9, meaning that the acid is less readily dissociated and needs a lower concentration of hydrogen ions before it will give up its H+. For an acid that is stronger than lactic acid, the pKa is less than 3.9: such an acid is more readily dissociated and needs a higher H+ concentration before it will accept H+ and form undissociated acid.
Medical Relevance 2.1 Diabetic Acidosis
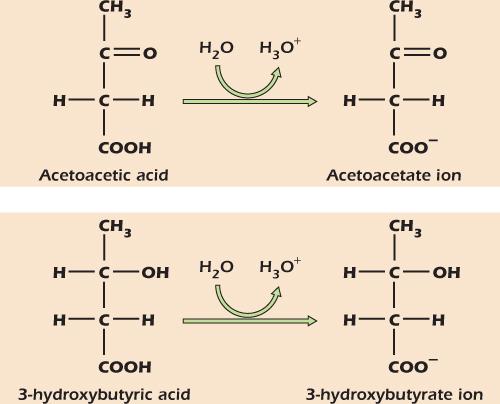
During starvation, the body mobilizes fat reserves by converting fat into the small, soluble compounds acetoacetic acid and 3-hydroxy butyric acid, collectively called ketone bodies . These componds have pKa values of 4 and 5, respectively, and therefore give H+ to water at the near-neutral pH of body fluids.
In untreated type 1 diabetes the body activates fat mobilization to an extreme degree, generating large amounts of ketone bodies. These in turn release large amounts of H+, making the body dangerously acidic in a condition known as diabetic acidosis.
Bases are Molecules that Take H+ from Water
Trimethylamine is the compound that gives rotting fish its unpleasant smell. Pure trimethylamine has the structure shown at the left of Figure 2.5B. When trimethylamine is dissolved in water, it accepts an H+ to become the positively charged trimethylamine ion shown on the right of the figure. We refer to molecules that have accepted H+ ions as protonated, using “proton” as a short way of saying “hydrogen nucleus.” Dissolving lots of trimethylamine in water produces an alkaline solution, that is, one with a low concentration of H+ ions and hence a pH greater than 7. The solution never runs out of H+ completely because new H+ are formed from water:
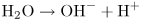
Thus if we keep adding trimethylamine to water and using up H+, we end up with an alkaline solution: one with a low concentration of H+, but lots of OH−.
The pH of a solution determines the position of equilibrium between protonated and deprotonated trimethylamine, and as before we define the pKa as the pH at which the concentration of protonated and deprotonated base are the same. The pKa of trimethylamine is 9.7, meaning that the concentration of H+ must fall to the low level of 10−9.7 mol liter−1, that is, 0.2 nmol liter−1, before half of the trimethylamines will give up their H+s.
Isoelectric Point
The large molecules called proteins have many acidic and basic sites that will give up or accept an H+ as the pH changes. In alkaline solutions proteins will tend to have an overall negative charge because the acidic sites have lost H+ and bear negative charge. As the pH falls, the acidic sites accept H+ and become uncharged, and basic sites also accept H+ to gain positive charge. Thus as the pH falls from an initial high value, the overall charge on the protein becomes less and less negative and then more and more positive. The pH at which the protein has no overall charge is the isoelectric point. The isoelectric points of different proteins are different, and this property is useful in separating them during analysis (see “In Depth ”). The majority of intracellular proteins have an isoelectric point that is less than 7.2, so that at normal intracellular pH they bear a net negative charge.
A Hydrogen Bond Forms When a Hydrogen Atom Is Shared
We have seen how oxygen tends to grab electrons from hydrogen, forming a polar bond. Nitrogen and sulfur are similarly electron-grabbing. If a hydrogen attached to an oxygen, nitrogen or sulfur by a covalent bond gets close to a second electron-grabbing atom; then that second atom also grabs a small share of the electrons to form what is known as a hydrogen bond (Fig. 2.6). The atom to which the hydrogen is covalently bound is called the donor because it is losing some of its share of electrons; the other electron-grabbing atom is the acceptor. For a strong hydrogen bond to form, the donor and acceptor must be within a fixed distance of one another (typically 0.3 nm) with the hydrogen on a straight line between them.
Figure 2.6 The hydrogen bond.
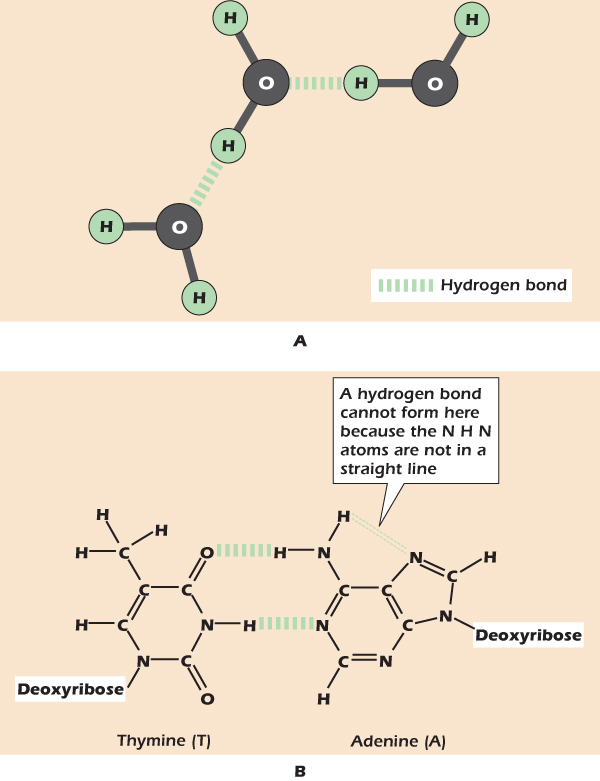
Liquid water is so stable because the individual molecules can hydrogen bond (Fig. 2.6A). Hydrogen bonding also plays a critical role in allowing DNA to store and replicate genetic information. Figure 2.6B shows how the base pairs of DNA form hydrogen bonds in which hydrogen atoms are shared between nitrogen and oxygen and between nitrogen and nitrogen.
Very large molecules, or macromolecules, are central to the working of cells. Large biological molecules are polymers: they are assembled by joining together small, simpler molecules, which are therefore called monomers. Chemical technology has mimicked nature by producing many important polymers—polyethylene is a polymer of ethylene monomers. Cells make a number of macromolecules that we will introduce, together with their monomer building blocks, in this chapter.
Carbohydrates: Candy and Canes
Carbohydrates—sugars and the macromolecules built from them—have many different roles in cells and organisms.
An Assortment of Sweets
All carbohydrates are formed from the simple sugars called monosaccharides. Figure 2.7 shows the monosaccharide glucose. The form shown at the top has five of its carbons, plus an oxygen atom, arranged in a ring. In addition to the oxygen in the ring, glucose has five other oxygens, each in an –OH (hydroxyl) group. Glucose easily switches between the three forms, or isomers, illustrated in Figure 2.7. The two ring structures are stereo isomers: although they comprise the same atoms connected by the same bonds, they represent two different ways of arranging the atoms in space. The two stereo isomers, named α and β, continually interconvert in solution via the open-chain form.
Figure 2.7 Glucose, a monosaccharide, easily switches between three isomers.
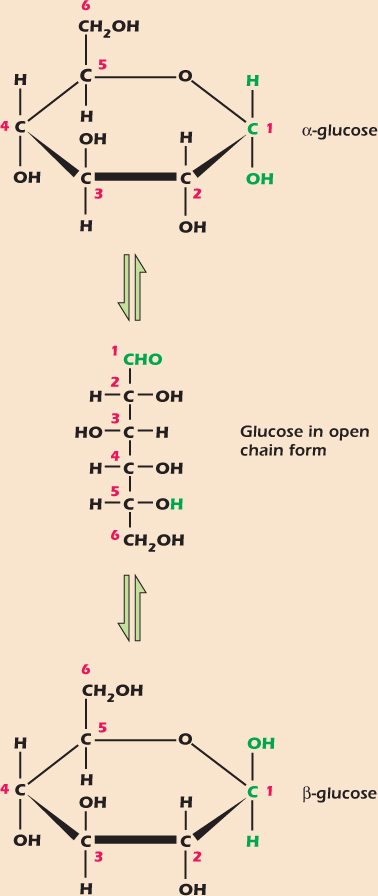
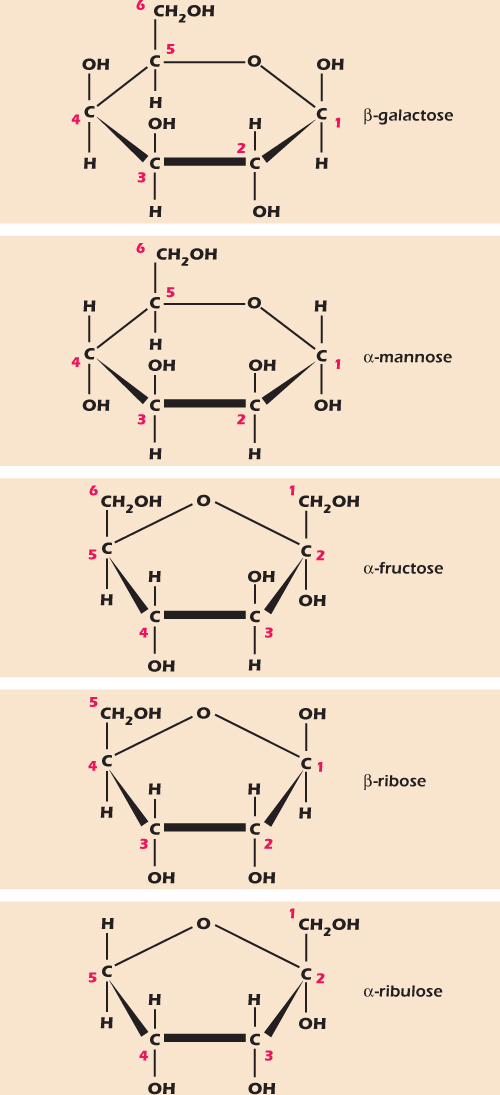
Figure 2.8 shows five other monosaccharides that we will meet again in this book. Like glucose, each of these monosaccharides can adopt an open-chain form and a number of ring structures. In Figure 2.8 we show each sugar in a form that it adopts quite often. These sugars share with glucose the two characteristics of monosaccharides: they can adopt a form in which an oxygen atom completes a ring of carbons, and they have many hydroxyl groups. The generic names for monosaccharides are derived from the Greek for the number of their carbon atoms, so glucose, galactose, mannose, and fructose are hexoses (six carbons) while ribose and ribulose are pentoses (five carbons). Classically, a monosaccharide has the general formula Cn(H2O)n, hence the name carbohydrate. All the monosaccharides shown in Figures 2.7 and 2.8 fit this rule—the four hexoses can be written as C6(H2O)6 and the two pentoses as C5(H2O)5.
Figure 2.8 Some monosaccharides, each shown as a common isomer.
It is worth noting that although both sugars and organic acids contain an –OH group, the behavior of an –OH group that forms part of a carboxyl group is very different from one that is not next to a double-bonded oxygen. In general the –OH group in a carboxyl group will readily give up an H+ to water or other acceptors; this is not true of –OH groups in general. We therefore reserve the term hydroxyl group for –OH groups on carbon atoms that are not also double-bonded to oxygen (Fig. 2.5A).
Disaccharides
Monosaccharides can be easily joined by glycosidic bonds in which the carbon backbones are linked through oxygen and a water molecule is lost. The bond is identified by the carbons linked. For example, Figure 2.9 shows lactose, a sugar found in milk that is formed when galactose and glucose are linked by a (1→4) glycosidic bond. Sugars formed from two monosaccharides are called disaccharides. Whenever a more complicated molecule is made from simpler building blocks we call the remnants of the individual building blocks residues. Thus lactose is made of one galactose residue and one glucose residue.
Figure 2.9 The disaccharide lactose.
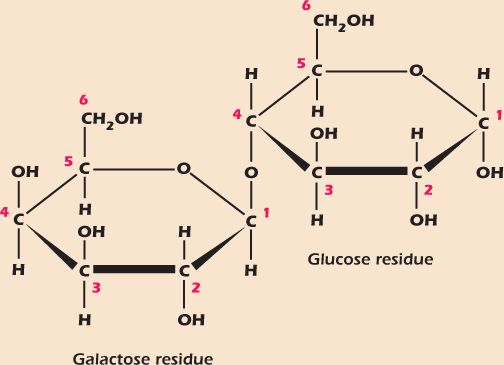
A complication arises here. Although free monosaccharides can easily switch between the α and β forms, formation of the glycosidic bond locks the shape. Thus, although galactose in solution spends time in the α and β forms, the galactose residue in lactose is locked into the β form, so the full specification of the bond in lactose is β(1→4).
Out of the Sweet Comes Forth Strength
Formation of glycosidic bonds can continue almost indefinitely. A chain of up to 100 or so monosaccharides is called an oligosaccharide, from the Greek word oligo meaning few. Longer polymers are polysaccharides and have characteristics very different from those of their monosaccharide building blocks. Figure 2.10A shows part of a molecule of glycogen, a polymer made exclusively of glucose monomers organized in long chains with α(1→4) links. The glycogen chain branches at intervals, each branch being an α(1→4) linked chain of glucose linked to the main chain with an α(1→6) bond. Solid lumps of glycogen are found in the cytoplasm of muscle, liver, and some other cells. These glycogen granules are 10–40 nm in diameter with up to 120,000 glucose residues. Glycogen is broken down to release glucose when the cell needs energy (Chapter 13).
Figure 2.10 The polysaccharides glycogen and cellulose.
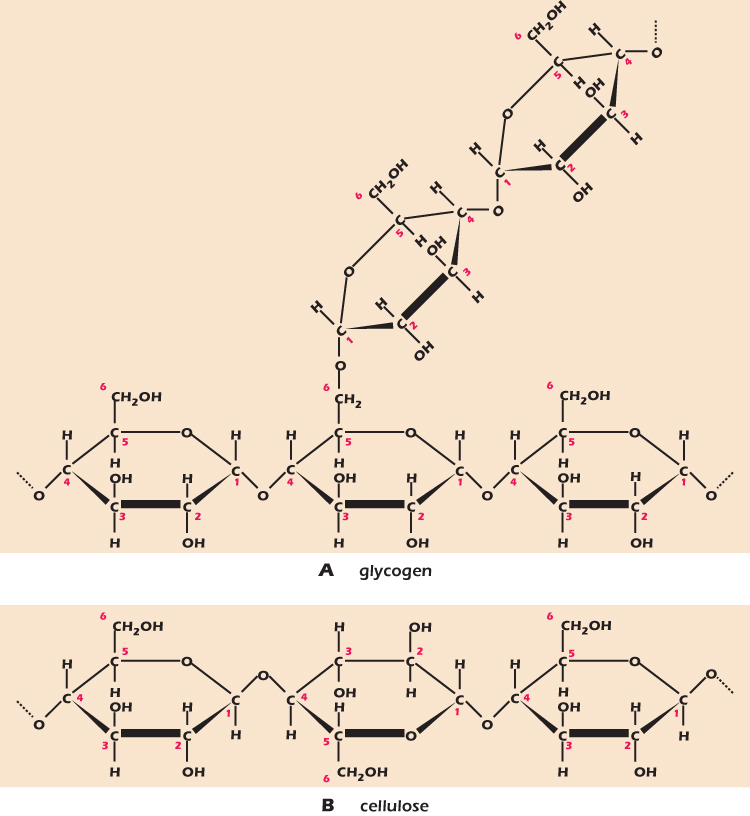
Cellulose makes up the cell wall of plants and is the world's most abundant macromolecule. Like glycogen, cellulose is a polymer of glucose, but this time the links are β(1→4). It is shown in Figure 2.10B. Drawn on the flat page, it looks very like glycogen. However, the difference in bond type is critical. Glucoses linked by α(1→4) links arrange themselves in a floppy helix, while glucoses linked by β(1→4) links form extended chains, ideal for building the rigid plant cell wall. Animals have enzymes (protein catalysts) that can break down the α(1→4) bond in glycogen, but only certain bacteria and fungi can break the β(1→4) link in cellulose. All animals that eat plants rely on bacteria in their intestines to provide the enzymes to digest cellulose.
Modified Sugars
A number of chemically modified sugars are important in biology. Figure 2.11 shows three. Deoxyribose is a ribose that is missing the –OH group on carbon number two. Its main use is in making deoxyribonucleic acid—DNA. N-acetyl glucosamine is a glucose in which an – NHCOCH3 group replaces the –OH on carbon two. It is used in a number of oligosaccharides and polysaccharides, for example, in chitin, which forms the hard parts of insects. Mannose-6-phosphate is a mannose that has been phosphorylated, that is, had a phosphate group attached, on carbon number six. We will meet more phosphorylated sugars in the next section.
Figure 2.11 Deoxyribose, N-acetyl glucosamine and mannose-6-phosphate are modified sugars.
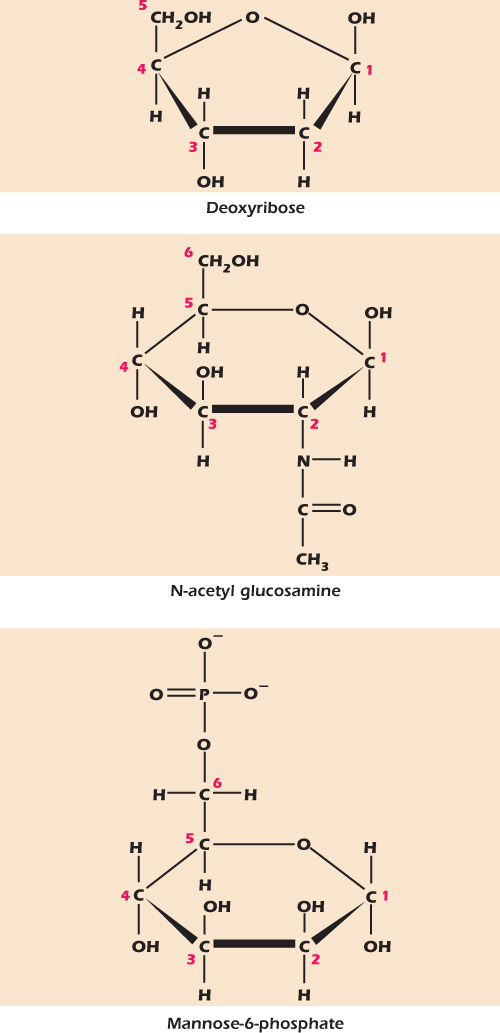
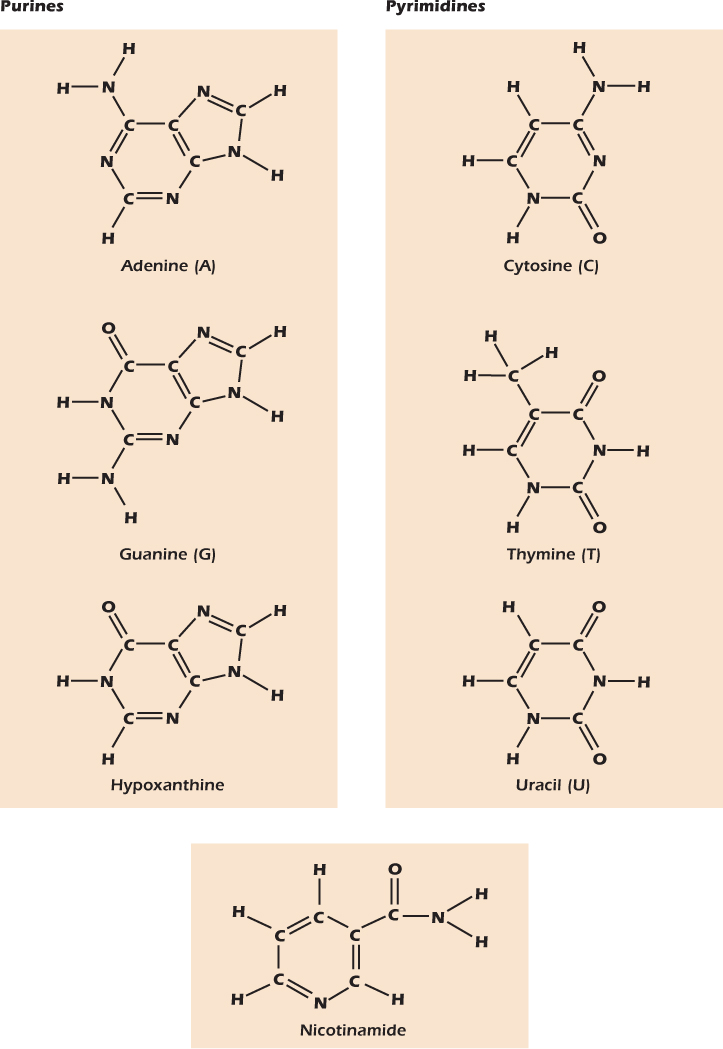
Figure 2.12A shows a nucleoside called adenosine. It is composed of ribose coupled to a nitrogen-rich compound called adenine. The numbers on the sugar—1′, 2′; and so forth—are the same numbering system we have seen before; the ′symbol is pronounced “prime” and is there to indicate that we are identifying the atoms of the sugar, not the atoms of the adenine. The name nucleoside reflects the fact that phosphorylated nucleosides are the building blocks of the nucleic acids that form the genetic material in the nucleus. However, nucleosides also play important roles in other places inside and outside the cell. Seven different compounds are commonly used to generate nucleosides (Fig. 2.13). All seven contain many nitrogen atoms and one or more ring structures.
They are the three purines adenine, guanine and hypoxanthine; the three pyrimidines cytosine, thymine, and uracil; and an odd man out called nicotinamide. These ring compounds are called bases. Historically, the name arose because the compounds are indeed bases in the sense used earlier in this chapter—they will accept an H+ from water. The roots of the name are now forgotten by most molecular biologists, who now use the word base to mean a purine, a pyrimidine, or nicotinamide. In general, a nucleoside is formed by attaching one of these bases to the 1′-carbon atom of ribose.
Figure 2.12 A nucleoside comprises a base and a ribose; a nucleotide comprises a nucleoside plus phosphate.
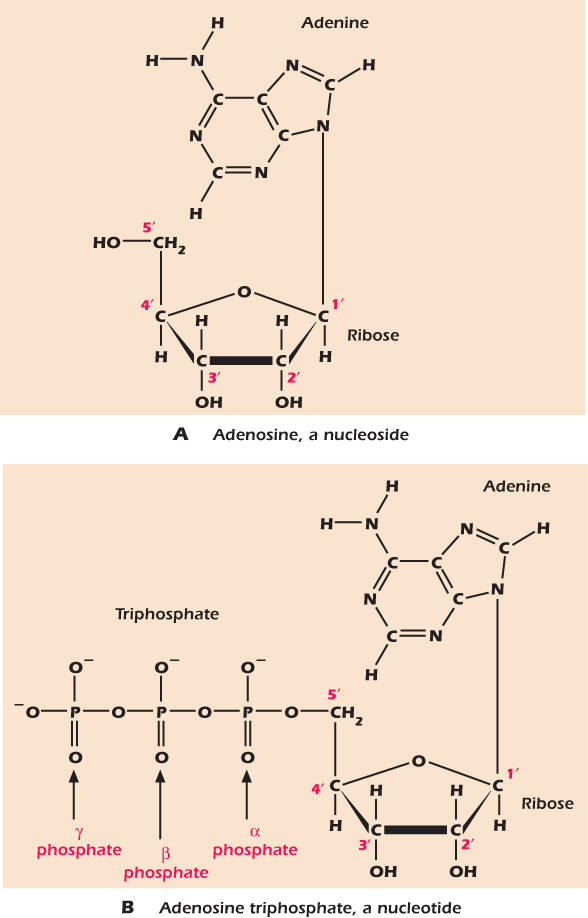
Figure 2.13 Seven bases found in nucleosides.
Phosphorous, although by weight a relatively minor fraction of the whole cell, plays a number of critical roles. In solution phosphorous is mainly found as a phosphate ion with a single hydrogen atom still attached, HPO42− (Fig. 2.14A). We often indicate phosphate ions with the symbol Pi, meaning inorganic phosphate. Where phosphate becomes important, however, is when it is attached to an organic, that is, carbon-containing, molecule. Phosphate can substitute into any C–OH group with the loss of a water molecule (Fig. 2.14B). The equilibrium in the reaction shown lies far to the left, but cells have strategies for attaching phosphate groups to organic molecules. Once one phosphate group has been added, more can be added to form a chain (Fig. 2.14C). Once again, the equilibrium in the reaction shown lies far to the left, but cells can achieve this result using other strategies.
Figure 2.14 Phosphate groups can attach to hydroxyl groups or to other phosphate groups.
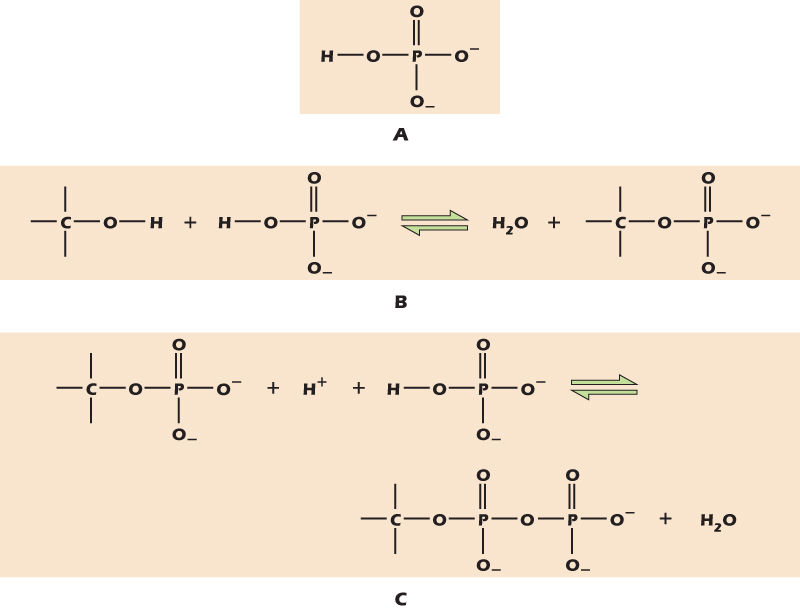
Figure 2.12B shows adenosine with a chain of three phosphate groups attached to the 5′ carbon of the ribose. This important molecule is adenosine triphosphate (ATP), and we will meet it many times in the course of this book. The three phosphate groups are denoted by the Greek letters α, β, and γ. Phosphorylated nucleosides are called nucleotides.
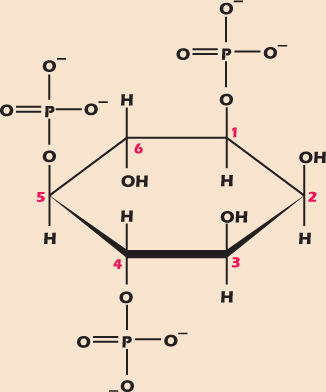
Molecules with several OH groups can become multiply phosphorylated. Figure 2.15 shows inositol trisphosphate (IP3), an important messenger molecule we will
meet again in Chapter 15. Both ATP and IP3 have three phosphate groups, but to indicate the fact that in ATP these are arranged in a chain, while in IP3 they are attached to different carbons, we use the prefix tri in adenosine triphosphate and the prefix tris in inositol trisphosphate. Similarly, a compound with two phosphates in a chain is called a diphosphate, while one with one phosphate on each of two different carbons is a bisphosphate.
Figure 2.15 Inositol trisphosphate, a multiply phosphorylated polyalcohol.
Oxidation and Reduction Involve the Movement of Electrons
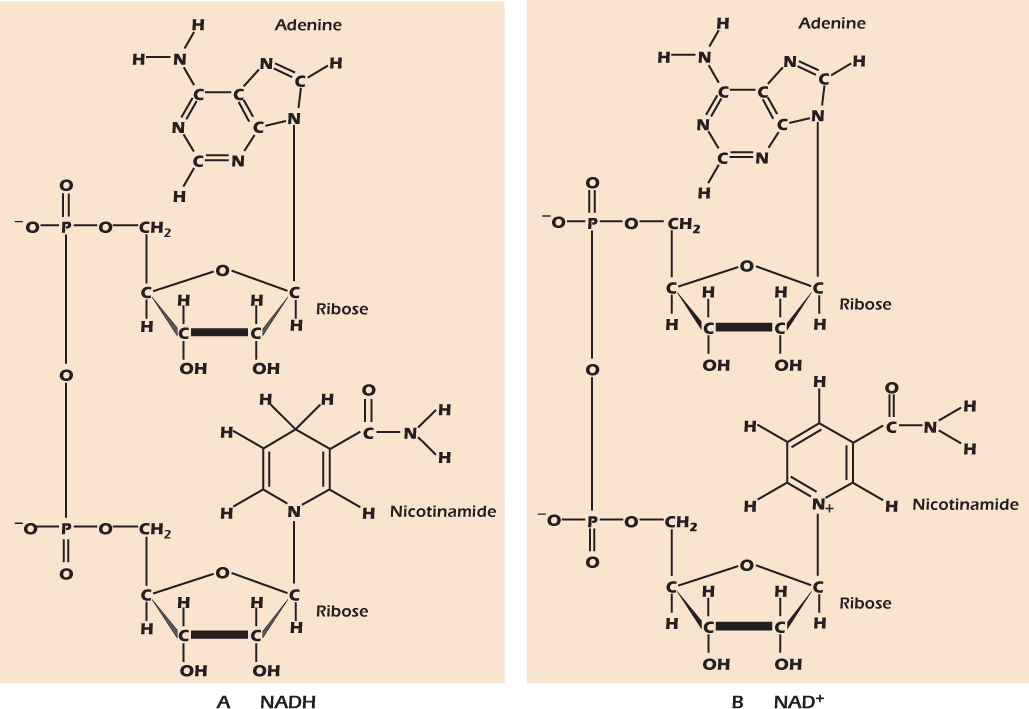
Figure 2.16A shows another important molecule formed from adenosine. Here adenosine and a nicotinamide nucleotide are joined through their phosphate groups. The resulting molecule, reduced nicotinamide adenine dinucleotide (NADH), is a strong reducing agent.
Figure 2.16 Nicotinamide adenine dinucleotide is formed of two nucleotides joined via their phosphate groups. The reduced form, NADH (A), is a strong reducing agent and energy currency. The oxidized form, NAD+, is shown in (B).
Addition of hydrogen atoms to molecules, or the removal of oxygen atoms, is called reduction. The opposite of reduction is oxidation, the addition of oxygen or the removal of hydrogen atoms. When they form bonds, hydrogen atoms give up a generous share of their electrons, while oxygen atoms tend to take more than their fair share of electrons in any bonds they make. Thus addition of oxygen to a compound means removal of electrons, and vice versa, so the most general definition of oxidation is the loss of electrons, with reduction being defined as the gain of electrons (a silly but useful mnemonic is “LossElectronsOxidation the lion says GainElectronsReduction”). Oxidation and reduction occur together, so that one reactant is oxidized while the other is reduced. Figure 2.17 shows the interconversion of pyruvate and lactate, an important reaction in metabolism . In the forward reaction pyruvate gains two hydrogens (and two electrons), so it is reduced. At the same time NADH loses one electron plus a hydrogen atom to become NAD+ (Fig. 2.16B). The NADH lost two electrons, so it has been oxidized.
Figure 2.17 The reversible reduction of pyruvate to lactate.
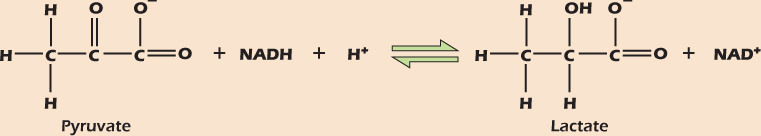
Amino Acids, Polypeptides, and Proteins
Amino acids contain both a carboxyl group, which readily gives an H+ to water and is therefore acidic, and a basic amino group (NH2), which readily accepts H+ to become NH3+. Figure 2.18A shows two amino acids, leucine and γ-amino butyric acid (GABA), in the form in which they are found at normal pH: the carboxyl groups have each lost an H+ and the amino groups have each gained one, so that the molecules bear both a negative and a positive charge.
Figure 2.18 Amino acids and the peptide bond.
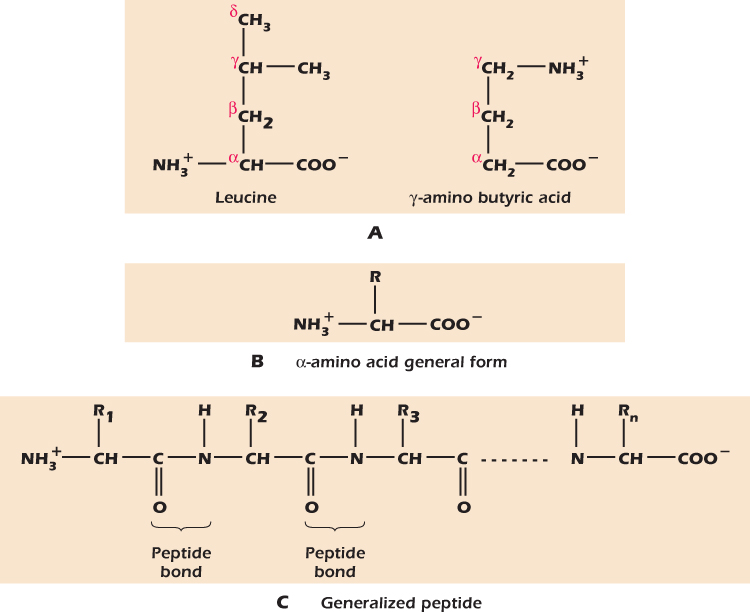
We name organic acids by labeling the carbon adjacent to the carboxyl group α, the next one β, and so on. When we add an amino group, making an amino acid, we state the letter of the carbon to which the amino group is attached. Hence leucine is an α-amino acid while GABA stands for gamma-amino butyric acid. α-Amino acids are the building blocks of proteins. They have the general structure shown in Figure 2.18B where R is the side chain. Leucine has a simple side chain of carbon and hydrogen. Other amino acids have different side chains and so have different properties. It is the diversity of amino side chains that give proteins their characteristic properties .
α-Amino acids can link together to form long chains through the formation of a peptide bond between the carboxyl group of one amino acid and the amino group of the next. Figure 2.18C shows the generalized stucture of such a chain of α-amino acids. If there are fewer than about 50 amino acids in a polymer we tend to call it a peptide.
More and it is a polypeptide. Polypeptides that fold into a specific shape are proteins. Peptides and polypeptides are formed inside cells by adding specific amino acids to the end of a growing polymer. As we will see in Chapter 4, the particular amino acid to be added at each step is defined by the instructions on a molecule called messenger ribonucleic acid (mRNA), which in turn contains a copy of the information recorded in the cell's DNA that is stored in the nucleus. This is the central dogma of molecular biology: DNA makes RNA makes protein.
Most of the components of the machinery of the cell—the chemicals that carry out the processes of life—are proteins. From Chapter 8 onwards this book will largely be describing proteins and structures made out of them. However the central dogma dictates that we should concentrate on DNA and RNA first, as we do in Chapters 4 through 7.
IN DEPTH 2.1 NOMENCLATURE
T. S. Eliot wrote “I tell you a cat must have three different names. First there's the name that the family use daily…” Chemicals that we use daily often have traditional, easy-to-say names such as butyric acid for CH3CH2CH2−COOH. There is no clue in the name as to the structure, but once learned, the name is convenient.
For many years biologists have used a naming system for organic acids in which the carbon atoms are given Greek letters. The α carbon is the one next to the COOH group, the β carbon the next one along, and the γ carbon the third one along and so on. For long chain fatty acids the last letter in the Greek alphabet (omega) is used to denote the carbon farthest from the carboxyl group. Thus the compound at the top right of Figure 2.18 is γ-amino butyric acid, GABA for short.
Like Eliot's cats, chemicals have a third name. Chemists need a nomenclature that will allow the unequivocal naming of all compounds, so the International Union of Pure and Applied Chemistry (IUPAC) generated such a system. IUPAC has a different convention for organic acids: the carbons are numbered 1, 2, 3, and so on, and number one is the carbon in the COOH group. Thus in the IUPAC system, GABA is 4-aminobutanoic acid.
In this book we will alternate between nomenclatures, using the most common name for each compound.
Unlike the chemical groups we have so far mentioned, the term lipid is not a single chemical class. Instead it refers to all of the water-insoluble chemicals that can be extracted from a cell using a solvent such as octane. Included under lipids are fats (triacylglycerols), phospholipids, and sterols such as cholesterol.
Figure 2.19A shows the fatty acid oleic acid. It comprises a carboxyl group plus a long tail of carbons and hydrogens. At neutral pH oleic acid gives up its H+ to become the oleate ion (Fig. 2.19B). The two ends of the oleate ion are very different. The carboxyl group is negatively charged and hence will associate readily with water molecules. The hydrocarbon tail is nonpolar and does not readily associate with water. The molecule is said to be amphipathic, from the Greek for “hating both,” meaning that one half does not like to be in water while the other half does not like to be in a nonpolar environment like octane. An alternative word with the same meaning is amphiphilic (“loving both”).
Figure 2.19 Oleic acid, oleate, and glycerol.
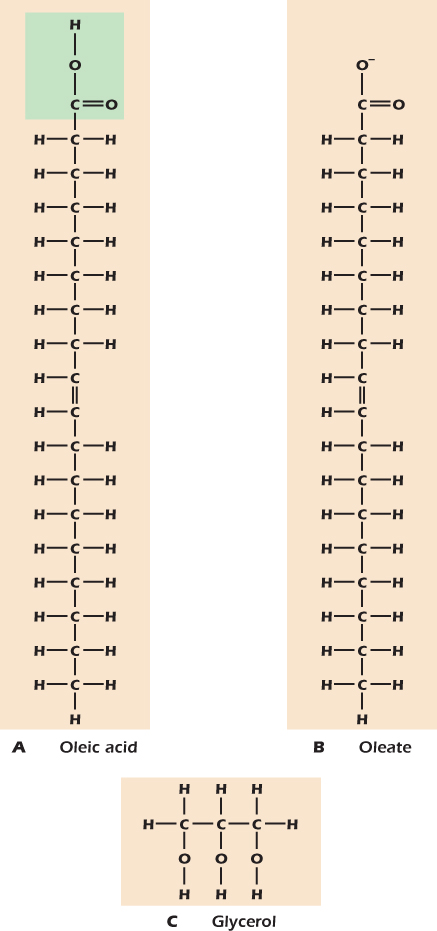
Figure 2.19C shows the small molecule glycerol. Like sugars, glycerol has many hydroxyl groups and, like sugars, tastes sweet, as its name suggests. However, it is not a sugar because it cannot adopt an oxygen-containing ring structure. Rather, because compounds containing hydroxyl groups are called alcohols, glycerol is a polyalcohol.
Cells can join fatty acids and glycerol to make glycerides. The bond is formed by removing the elements of water between the carboxyl group of the fatty acid and a hydroxyl group of glycerol. Any bond of this type, between a carboxyl group and a hydroxyl group, is called an ester bond. Figure 2.20 shows two glycerides. In Figure 2.20A is trioleoylglycerol, the main component of olive oil. It is a triacylglycerol (or triglyceride) formed from three molecules of oleic acid and one molecule of glycerol. The fatty acid residues are called acyl groups. Formation of the ester bonds has removed the charged carboxyl groups that rendered the oleate amphipathic. Almost all of the triacylglycerol molecule is simple hydrocarbon chains that cannot hydrogen bond with water molecules. For this reason, olive oil and other triacylglycerols do not mix with water. They are therefore said to be hydrophobic. Triacylglycerols that are liquid at room temperature are called oils, those that are solid are called fats, but they are all the same sort of molecule.
Figure 2.20 Glycerides and the lipid bilayer.

Cells contain droplets of triacylglycerol within their cytoplasm. These are usually small, but in fat cells, which are specialized as fat stores, the droplets coalesce into a single large globule so that the cell's cytoplasm is squeezed into a thin layer surrounding the fat globule. During fasting triacylglycerols are broken down into free fatty acids and glycerol. The fatty acids and the glycerol then enter the circulation for use by tissues.
Figure 2.20B shows phosphatidylcholine, an example of the phospholipids that make the plasma membrane and other cell membranes. Like triacylglycerols, phospholipids have fatty acids attached to glycerol, but only two of them. In place of the third fatty acid is a polar, often electrically charged head group. The head group is joined to the glycerol through phosphate in a structure called a phosphodiester link. The combination of head group and negatively charged phosphate is able to associate strongly with water—it is said to be hydrophilic. The two acyl groups, on the other hand, form a tail that, like olive oil, is hydrophobic. Phospholipids can therefore neither dissolve in water (because of their hydrophobic tails) nor remain completely separate, like olive oil (because then the head group could not associate with water). Phospholipid molecules therefore spontaneously form lipid bilayers (Fig. 2.20C) in which each part of the molecule is in its preferred environment. Cell membranes are lipid bilayers plus some added protein.
IN DEPTH 2.2 THE KINKS HAVE IT: DOUBLE BONDS, MEMBRANE FLUIDITY AND EVENING PRIMROSES
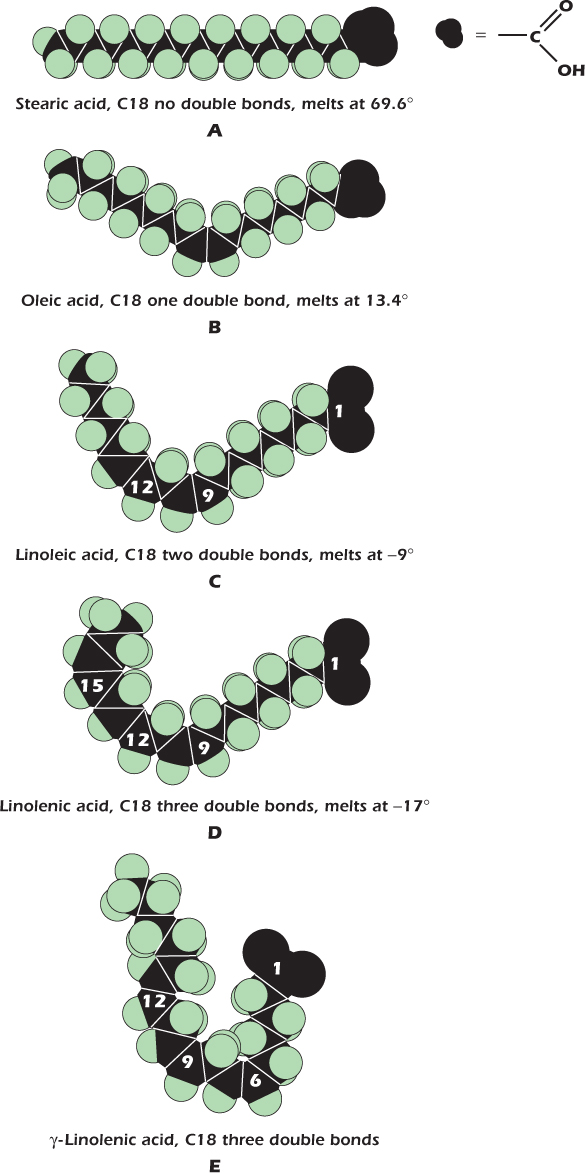
One of the fatty acids commonly found as a component of animal fat is stearic acid, illustrated as A in the diagram. Its 18 carbon atoms are joined by single bonds, making a long straight molecule. In contrast, oleic acid (B) has a double bond between the ninth and tenth carbons. This introduces a kink in the chain. A fatty acid with kinks is less able to solidify because it is less able to pack in a regular fashion. The more double bonds in a fatty acid, the lower its melting point. Thus stearic acid melts at 70°C, while oleic acid melts at 13°C and is therefore liquid at room temperature. Fatty acids containing double bonds between the carbon atoms are said to be unsaturated. Polyunsaturated fatty acids have more than one double bond, more than one bend, and therefore even lower melting points. Linoleic acid (C) has two, and melts at −9°C; linolenic acid (D) has three and a melting point of −17°C.
For the triacylglycerols inside our cells, and the phospholipids in our membranes, the same rule applies: the more double bonds in the acyl groups, the lower the melting point. The large masses of triacylglycerols containing stearic acid in animal bodies are liquid at body temperature but form solid lumps of fat at room temperature, while trioleoylglycerol is liquid at room temperature (but should not be kept in the fridge!). Membranes must not solidify: if they did, then they would crack and the cell contents would leak out each time the cell was flexed. Unsaturated fatty acids play an essential role in maintaining membrane liquidity.
Mammals are unable to introduce double bonds beyond carbon 9 in the fatty acid chain. This means that linoleic and linolenic acids must be present in the diet. They are known as essential fatty acids. Fortunately, the biochemical abilities of plants are not so restricted, and plant oils form a valuable source of unsaturated fatty acids.
The normal form of linolenic acid, shown in D, is α-linolenic acid, which has its double bonds between carbons 9 and 10, 12 and 13, and 15 and 16. Some plant seed oils contain an isomer of linolenic acid with double bonds between carbons 6 and 7, 9 and 10, and 12 and 13. This is γ-linolenic acid (E). The attractive, yellow-flowered evening primrose (Oenethera perennis) has seeds that contain an oil with γ-linolenic in its triacyglycerols. The 6 to 7 double bond introduces a kink closer to the glycerol. This is thought to increase fluidity when incorporated into membrane lipids. No one really knows if it really has the marvelous health effects that some claim for it, or if it does, how it works. This ignorance has not stopped people from making lots of money from evening primrose oil. It is included in cosmetics and in alternative medicines for internal and external application. γ-Linolenic acid occurs in other plants—the seeds of borage (Borago officinalis) are one of the richest sources. It is even found in some fungi. However, these lack the romance of the evening primrose!
Many of the macromolecules of which cells are made are generated from their individual building blocks by the removal of the elements of water. Equally, macromolecules can be broken into their individual building blocks by hydrolysis—breakage by the addition of water. Figure 2.21 shows three examples. Lactose is hydrolyzed to the monosaccharides galactose and glucose by the addition of one water molecule. Next, we show a dipeptide being broken into individual amino acids by hydrolysis. Here, the reaction would just be called hydrolysis, but when the peptide bonds in a protein are hydrolyzed, breaking it into separate fragments, we call this proteolysis. Enzymes catalyse these hydrolysis reactions all the time in our intestines, though some people lose the ability to hydrolyze lactose as they get older: they are lactose intolerant. Third, we show the dimeric (formed of two parts) inorganic phosphate ion pyrophosphate being hydrolyzed to regular phosphate ions. The hydrolysis of pyrophosphate is catalyzed by enzymes found throughout the body, both inside cells and out. Later in the book we will meet a number of instances where a reaction creates pyrophosphate, but as soon as the pyrophosphate is produced it will be hydrolyzed to regular phosphate. In Figure 2.22 we show the complete hydrolysis of the phospholipid phosphatidylcholine. Five molecules result: one phosphate ion together with choline, glycerol, and two fatty acids. This hydrolysis also occurs in our intestines, where it is a multistage process.
Figure 2.21 Hydrolysis is the breaking of covalent bonds by the addition of the elements of water.
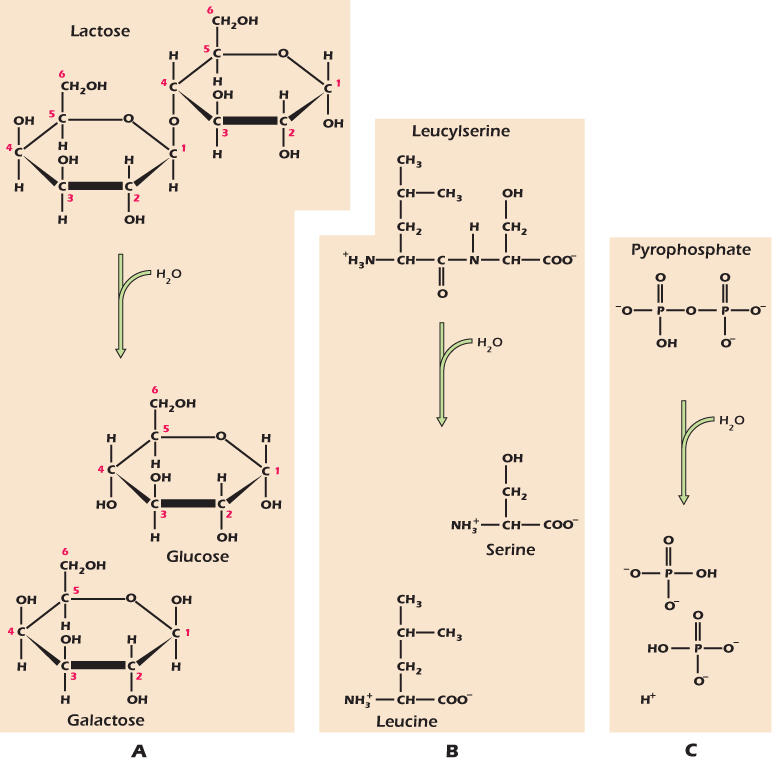
Figure 2.22 Hydrolysis of a phospholipid.

Hydrolysis reactions usually proceed rapidly in living tissue when the appropriate catalyst is present, because water is present at high concentration, although the uncatalysed rates are usually very slow. In contrast the generation of macromolecules from their constituent building blocks, often by the elimination of the elements of water between constituent building blocks, usually requires the expenditure of energy by the cell. We will see how these reactions are performed in later chapters.
Medical Relevance 2.2 Protease Inhibitors as AIDS Therapy
HIV, the virus that causes AIDS, uses a transcription factor called NFκB that is already present in the host cell. NFκB triggers the generation of mRNA from the viral DNA genome. Most of the NFκB in the host cell is present in a large inactive form. Proteolysis cleaves this large protein to release the smaller, active transcription factor. The virus itself contains an enzyme called a protease that does this job, and because this enzyme is distinct from the host cell's enzymes, it is possible to find drugs that inhibit it without dramatically affecting the host cell. Protease inhibitors are used in antiviral therapy in the treatment of AIDS.
1. When two atoms interact, electrons may be shared between the two to form a covalent bond, or may pass completely from one atom to another, forming ions.
2. In water the electrons are not shared equally but are displaced toward the oxygen atom, so that the molecule is polar.
3. Ionic compounds will only dissolve in polar solvents.
4. Acids are molecules that give an H+ to water, forming H3O+. Dissolving an acid in water produces a solution of pH less than 7.
5. Bases are molecules that accept an H+ from water, leaving OH−. Dissolving a base in water produces a solution of pH greater than 7.
6. Pure water has the neutral pH of 7.0.
7. A hydrogen bond can form when a hydrogen atom takes up a position between two electron-grabbing atoms (oxygen, nitrogen, or sulfur), the three forming a straight line.
8. Monosaccharides are compounds with a central skeleton of carbon to which many OH groups are attached. They can switch between two oxygen-containing ring structures via an open-chain configuration.
9. Monosaccharides can join together to form disaccharides such as lactose and to form long chains such as glycogen and cellulose.
10. Adenine, guanine, hypoxanthine, cytosine, thymine, uracil, and nicotinamide are nitrogen-rich ring-shaped molecules called bases. Bases combine with ribose or deoxyribose to form nucleosides. Phosphorylation of a nucleoside on the 5′ carbon produces a nucleotide.
11. Amino acids are compounds with a carboxyl acidic group and an amino basic group. At neutral pH these groups will, respectively, lose and gain an H+ to become –COO− and –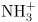 .
.
12. Polypeptides are polymers of α-amino acids linked by peptide bonds. The sequence of amino acids is determined by instructions on the cell's DNA. Proteins are polypeptides that fold into a specific shape.
13. Many lipids are formed by the attachment of hydrophobic long-chain fatty acids to a glycerol backbone. Phospholipids also have a hydrophilic head group and spontaneously form lipid bilayers.
14. Hydrolysis is the breakage of covalent bonds by the addition of the elements of water.
REVIEW QUESTIONS
2.1 Theme: Types of Organic Chemicals
A. adenine
B. adenosine
C. adenosine triphosphate
D. galactose
E. lactic acid
F. lactose
G. leucine
H. oleic acid
I. ribose
J. trimethylamine
From the above list of specific chemicals, select the chemical that belongs to each of the broader classes below.
1. A disaccharide
2. A fatty acid
3. A nucleoside
4. A nucleotide
5. a pentose sugar
2.2 Theme: Chemical Groups and Bonds
2. Diagrams i and ii show two small organic compounds, while diagram iii shows part of a macromolecule. The bonds indicated --- are connections to other parts of the macromolecule. The red letters A through I indicate particular groups and bonds.

3. Use the letters to identify examples of each of the groups and bonds listed below.
1. amino group
2. carboxyl group
3. hydroxyl group
4. phosphate group
5. ester bond
6. glycosidic bond
7. hydrogen bond
8. peptide bond
9. phosphodiester link
2.3 Theme: Acids and Bases
4. Acetic acid (ethanoic acid), CH3COOH, is a simple organic acid that is the main ingredient in vinegar. The pKa of the reaction CH3COOH ↔ CH3COO−+H+ is 4.8. The gas ammonia dissolves in water and the dissolved NH3 is a base which accepts a proton to become the ammonium ion NH4+. The pKa of the reaction NH3+H+ ↔ NH4+ is 9.2.
Consider a solution of ammonium acetate, that is, a solution that initially contains both ammonium ions and acetate ions. By adding acid or alkali (for example, HCl or NaOH) the pH can be changed.
A. pH=3
B. pH=5
C. pH=7
D. pH=9
E. pH=11
F. the described condition is impossible
From the above list, choose the pH at which each of the conditions described below applies. Note that at least one of the conditions is impossible: for this/these, select answer F.
1. Considering the acetate, both the protonated form CH3COOH and the deprotonated form CH3COO− are present at significant concentrations.
2. Considering the ammonium, both the protonated form NH4+ and the unprotonated form NH3 are present at significant concentrations.
3. The vast majority of both the acetate and the ammonium are in their protonated forms, CH3COOH and NH4+ respectively.
4. The vast majority of both the acetate and the ammonium are in their unprotonated forms, CH3COO− and NH3 respectively.
5. The vast majority of both the acetate and the ammonium are in their ionic forms, CH3COO− and NH4+ respectively.
6. The vast majority of both the acetate and the ammonium are in their uncharged forms, CH3COOH and NH3 respectively.
THOUGHT QUESTION
If you add HCl (hydrochloric acid) to water it dissociates completely into H+ and Cl−. What is the pH of the solution generated when HCl is dissolved in pure water to a final concentration of (i) 10−4 mole liter−1 (ii) 10−8 mole liter−1?
Voet, D., and Voet, J. (2011). Biochemistry, 4th edition, John Wiley & Sons, Hoboken.