Computers are now so ubiquitous that it is hard to imagine a time when the very concept of computer didn’t exist. The word computer, referring to a person who carried out calculations, or computations, was probably used for the first time in the seventeenth century, and continued to be used in that sense until the middle of the twentieth century. A computer is someone or something that executes sequences of simple calculations—sequences that can be programmed. Several mechanical calculating devices were built in the sixteenth and seventeenth centuries, but none of them was programmable. Charles Babbage was the first to design and partially build a fully programmable mechanical computer; he called it the Analytical Engine.
The Analytical Engine
The Analytical Engine was a successor to the Difference Engine, a calculator designed and built by Babbage to automate the computation of astronomical and mathematical tables. Its workings were based on a tabular arrangement of numbers arranged in columns. The machine stored one decimal number in each column and could add the value of one cell in column n + 1 to that of one cell in column n to produce the value of the next row in column n. This type of repetitive computation could be used, for example, to compute the values of polynomials.
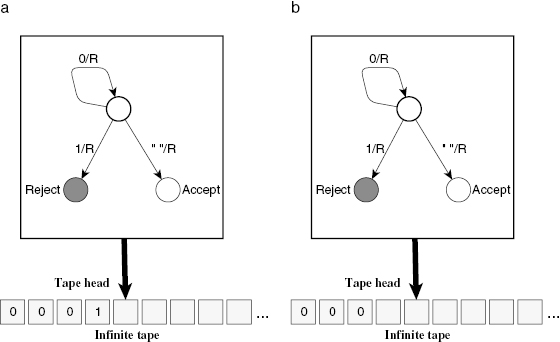
To understand the operation of the Difference Engine, it is useful to look at a concrete example. Consider, for instance, the function defined by the polynomial P(x) = x2 + 2x + 2. Tabulating its values for the first few values of x, and the successive differences, yields the table shown here as table 4.1. As is clear from this table, the second-order differences for this polynomial are constant. This is a general characteristic of polynomials of degree 2. This characteristic enables us to compute the value of the polynomial at any point without any multiplication. For instance, the value of the polynomial at x = 7 can be obtained by summing 2 (the constant in column D2) and the value 13 in column D1 and then adding the result and the value 50 in column P(x) to obtain 65.
Table 4.1 Differences used by the Difference Engine.
The Difference Engine was programmed by setting the initial values on the columns. Column P(x) was set to the value of the polynomial at the start of the computation for a number of rows equal to the degree of the polynomial plus 1. The values in column D1 were obtained by computing the differences between the consecutives points of the polynomial. The initial values in the next columns were computed manually by subtracting the values in consecutive rows of the previous column. The engine then computed an arbitrary number of rows by adding, for each new row, the value in the last cell in a column to the value in the last cell in the previous column, starting with the last column, until it reached column P(x), thereby computing the value of the polynomial for the next value of x.
The Difference Engine performed repetitive computations, but it couldn’t be programmed to perform an arbitrary sequence of them; therefore, it cannot be considered a programmable computer. Babbage’s second design, the Analytical Engine, was much more ambitious, and is usually considered the first truly programmable computer.
Babbage conceived carefully detailed plans for the construction of the Analytical Engine and implemented parts of it. (One part is shown here in figure 4.1.) The program and the data were to be given to the engine by means of punched cards (the same method used in the Jacquard loom, which was mentioned in chapter 2 as one of the results of the first industrial revolution). The Analytical Engine would generate its output using a printer, but other output devices would also be available—among them a card puncher that could be used to generate future input.
Figure 4.1 A part of the Analytical Engine now on exhibition at the Science Museum in London.
The machine’s memory was to hold 1,000 numbers of 50 decimal digits each. The central processing unit would perform the four arithmetic operations as well as comparisons. The fundamental operation of the Analytical Engine was to be addition. This operation and the other elementary operations—subtraction, multiplication, and division—were to be performed in a “mill”. These operations were to be performed by a system of rotating cams acting upon or being actuated by bell cranks and similar devices.
The programming language to be employed by users was at the same level of abstraction as the assembly languages used by present-day CPUs. An assembly language typically enables the programmer to specify a sequence of basic arithmetic and logic operations between different memory locations and the order in which these operations are to be performed. The programming language for the Analytical Engine included control instructions such as loops (by which the computer would be instructed to repeat specific actions) and conditional branching (by which the next instruction to be executed was made to depend on some already-computed value).
Had it been built, the Analytical Engine would have been a truly general-purpose computer. In 1842, Luigi Menabrea wrote a description of the engine in French; it was translated into English in the following year (Menabrea and Lovelace 1843), with annotations by Ada Lovelace (Lord Byron’s daughter), who had become interested in the engine ten years earlier. In her notes—which are several times the length of Menabrea’s description—Lovelace recognizes the machine’s potential for the manipulation of symbols other than numbers:
Again, it might act upon other things besides number, were objects found whose mutual fundamental relations could be expressed by those of the abstract science of operations, and which should be also susceptible of adaptations to the action of the operating notation and mechanism of the engine. Supposing, for instance, that the fundamental relations of pitched sounds in the science of harmony and of musical composition were susceptible of such expression and adaptations, the engine might compose elaborate and scientific pieces of music of any degree of complexity or extent.
She also proposes what can be considered the first accurate description of a computer program: a method for using the machine to calculate Bernoulli numbers. For these contributions, Ada Lovelace has been considered the first computer programmer and the first person to recognize the ability of computers to process general sequences of symbols rather than only numbers. The programming language Ada was named in her honor.
Technical and practical difficulties prevented Charles Babbage from building a working version of the Analytical Engine, although he managed to assemble a small part of it before his death in 1871. A working version of Babbage’s Analytical Engine was finally built in 1992 and is on display in the Science Museum in London.
Turing Machines and Computers
After Babbage, the next fundamental advance in computing came from the scientist and mathematician Alan Turing, who proposed a model for an abstract symbol-manipulating device used to study the properties of algorithms, programs, and computations. (See Turing 1937.)
A Turing machine isn’t intended to be a practical computing machine; it is an abstract model of a computing device. A deterministic Turing machine (which I will refer to in this chapter simply as a Turing machine or as a machine) consists of the following:
An infinite tape divided into cells. Each cell contains a symbol from some finite alphabet. The alphabet contains a special blank symbol and one or more other symbols. Cells that have not yet been written are filled with the blank symbol.
A tape head that can read and write symbols on the tape and move the tape left or right one cell at a time.
A state register that stores the present state of the machine. Two special states may exist, an accept state and a reject state. The machine stops when it enters one of these states, thus defining whether the input has been accepted or rejected.
A state-transition graph, which specifies the transition function. For each configuration of the machine, this graph describes what the tape head should do (erase a symbol or write a new one and move left or right) and the next state of the machine.
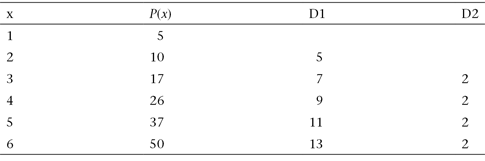
Figure 4.2 is a schematic diagram of a Turing machine. The state-transition graph describes the way the finite-state controller works. In this particular case, the state-transition graph has four states (represented by circles) and a number of transitions between them (represented by arrows connecting the circles). The controller works by changing from state to state according to the transitions specified. Each transition is specified by an input/output pair, the input and the output separated by a “slash.” In the simple case illustrated in figure 4.2, the Turing machine has no input. Therefore, the transitions do not depend on the input, and only the outputs are shown. Figure 4.4 illustrates a slightly more complex case in which each transition is marked with an input/output pair.
Figure 4.2 A Turing machine that writes an infinite succession of zeroes and ones with spaces in between.
Figure 4.2 is based on the first example proposed by Turing in his 1937 paper. The machine has four states: the initial state b (emphasized by a bold outline) and the states c, e, and f. Since the machine has no accept state and no reject state, it runs forever and simply writes the infinite sequence ‘0’, ‘ ’, ‘1’, ‘ ’, ‘0’, ‘ ’, ‘1’ … on the tape. Its behavior is simple to understand. The machine starts in state b, with the tape filled with blank symbols. The state-transition graph tells the machine to write a zero (P0), move to the right (R), and change to state c. In state c, the machine is told to move to the right (R) and not write anything, leaving a blank on the tape. The succeeding moves will proceed forever in essentially the same way. In figure 4.2, the controller is in state f and the machine will proceed to state b, moving the head to the right. Although this example is a very simple one, and the machine performs a very simple task, it isn’t difficult to understand that much more complex tasks can be carried out. For example, a Turing machine can be programmed to add two binary numbers, written on the tape, and to write the result back on the tape. In fact, a Turing machine can be programmed to compute any number or to perform any symbol-manipulation task one can describe as a sequence of steps (an algorithm). It can compute the value of a polynomial at a certain point, determine if one equation has integer solutions, or determine if one image (described in the tape) contains another image (also described in another part of the tape).
In particular, a sufficiently powerful Turing machine can simulate another Turing machine. This particular form of simulation is called emulation, and this expression will be used every time one system simulates the behavior of another complete system in such a way that the output behavior is indistinguishable.
In the case of emulation of a Turing machine by another Turing machine, is it necessary to specify what is meant by “sufficiently powerful.” It should be obvious that some machines are not powerful enough to perform complex tasks, such as simulating another machine. For instance, the machine used as an example above can never do anything other than write zeroes and ones. Some Turing machines, however, are complex enough to simulate any other Turing machine. A machine A is universal if it can simulate any machine B when given an appropriate description of machine B, denoted <B>, written on the tape together with the contents of the tape that is the input to machine B. The notation <B> is used to designate the string that is to be written on the tape of machine A in order to describe machine B in such a way that machine A can simulate it.
The idea of universal Turing machines gives us a new way to think about computational power. For instance, if we want to find out what can be computed by a machine, we need not imagine all possible machines. We need only imagine a universal Turing machine and feed it all possible descriptions of machines (and, perhaps, their inputs). This reasoning will be useful later when we want to count and enumerate Turing machines in order to assess their computational power.
A Turing machine is an abstraction, a mathematical model of a computer, which is used mainly to formulate and solve problems in theoretical computer science. It is not meant to represent a realistic, implementable, design for an actual computer. More realistic and feasible computer models, that are also implementable designs, have become necessary with the advent of actual electronic computers. The most fundamental idea, which resulted in large part from the work of Turing, was the stored-program computer, in which a memory, instead of a tape, is used to store the sequence of instructions that represents a specific program. In a paper presented in 1946, in the United Kingdom, to the National Physical Laboratory Executive Committee, Turing presented the first reasonably finished design of a stored-program computer, a device he called the Automatic Computing Engine (ACE). However, the EDVAC design of John von Neumann (who was familiar with Turing’s theoretical work) became better known as the first realistic proposal of a stored-program computer.
John von Neumann was a child prodigy, born in Hungary, who at the age of 6 could divide two eight-digit numbers in his head. In 1930 he received an appointment as a visiting professor at Princeton University. At Princeton he had a brilliant career in mathematics, physics, economics, and computing. Together with the theoretical physicists Edward Teller and Stanislaw Ulam, he developed some of the concepts that eventually led to the Manhattan Project and the atomic bomb.
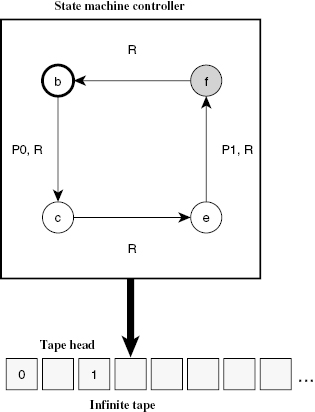
One of von Neumann’s many contributions to science was what eventually became known as the von Neumann architecture. In “First Draft of a Report on the EDVAC” (von Neumann 1945), he proposes an architecture for digital computers that includes a central processing unit, a control unit, a central memory, external mass storage, and input/output mechanisms. The central processing unit (CPU) contains a control unit (CU) and an arithmetic and logic unit (ALU). The ALU computes arithmetical and logical operations between the values stored in the registers in the CPU. The control unit includes a program counter, which points to the specific point in memory that contains the current instruction and is used to load the instruction register (one of the registers in the CPU) with the code of the operation to be performed. The memory, which is used to store both data and instructions, is accessed using the registers in the CPU. Finally, external mass storage is used to store permanently instructions and data, for future use, while input and output devices enable the computer to communicate with the external world. The memory and the external mass storage replace the tape in the Turing machine, while the internal structure of the central processing unit makes it more efficient in the manipulation of information stored in memory and in permanent storage.
In the so-called von Neumann architecture, the same pathway is used both to load the program instructions and to move the working data between the CPU and the memory—a restriction that may slow down the operation of the computer. The so-called Harvard architecture, named after the Harvard Mark I relay-based computer, uses separate pathways (or buses) to move the working data between the CPU and the memory and to load the program instructions. Some modern computers, including computers dedicated to digital signal processing, use the Harvard architecture; others use a combination of the Harvard architecture and the von Neumann architecture.
Figure 4.3 Von Neumann architecture of a stored-program computer.
Modern machines have multiple buses and multiples CPUs, and use complex mechanisms to ensure that different CPUs can access the available memory, which may be organized in many different ways. However, all modern computers work in essentially the same way and are, essentially, very fast implementations of the stored-program computers designed by Alan Turing and John von Neumann.
Computability and the Paradoxes of Infinity
The advantage of a Turing machine over more complex computer models, such as the stored-program computer, is that it makes mathematical analysis of its properties more straightforward. Although a Turing machine may seem very abstract and impractical, Turing proved that, under some assumptions (which will be made clear later in the book) such a machine is capable of performing any conceivable computation. This means that a Turing machine is as powerful as any other computing device that will ever be built. In other words, a Turing machine is a universal computer, and it can compute anything that can be computed.
We now know almost all computing models and languages in existence today are equivalent in the Turing sense that what can be programmed in one of them can be programmed in another. This leads to a very clear definition of what can be computed and what cannot be computed. Such a result may seem surprising and deserves some deeper explanation. How is it possible that such a simple machine, using only a single tape as storage, can be as powerful as any other computer that can be built? Exactly what is meant by “anything that can be computed”? Are there things that cannot be computed? To dwell further on the matter of what can and what cannot be computed, we must answer these questions clearly and unequivocally. To do this, we use the concept of language.
A language is defined as a set of sequences of symbols from some given alphabet. For instance, the English language is, according to this definition, the set of all possible sequences of alphabet symbols that satisfy some specific syntactic and semantic rules. For another example, consider the language L1 = {0, 00, 000, 0000, 00000, … }, which is constituted by all strings consisting only of zeros. There are, of course, an infinite number of such strings and, therefore, this language has infinitely many strings.
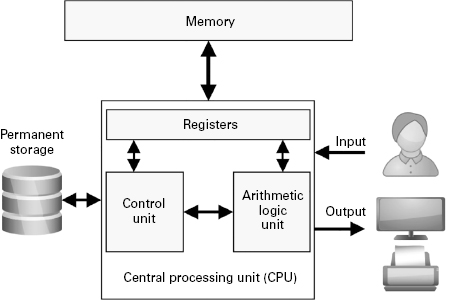
A language L is said to be decidable if there exists a Turing machine that, given a string written on the tape, stops in the accept state if the string is in L and stops in the reject state if the string is not in L. Language L1 is decidable, since there is a machine (illustrated here in figure 4.4, performing two different computations) that does exactly that. The two parts of figure 4.4 illustrate two computations performed by this Turing machine, showing the state of the machine after two inputs—0001 (figure 4.4a) and 000 (figure 4.4b)—have been processed. In figure 4.4a, the machine has just rejected the string, with the controller having moved into the reject state after seeing a 1 in the fourth cell of the tape. In figure 4.4b, the machine has just accepted the string, after seeing a space on the tape following a string of zeroes.
Figure 4.4 A Turing machine that accepts the language L1.
A language L is said to be recognizable when there exists a machine that stops in the accept state when processing a string in L but may fail to stop in the reject state if the string is not in L. Decidable languages are, therefore, “simpler” than recognizable languages, since a Turing machine can definitely answer the question “Does a string belong to L?” in a decidable language, but can only answer in one direction—if the answer is yes—if L is a recognizable language.
What is the relationship between languages and problems? Informally, we use the word problem to refer to a question that has a specific answer. If one restricts the analysis to problems that can be answered either Yes or No, it is possible to define a correspondence between problems and languages. Each instance of the problem is encoded as a string, and all the strings that correspond to instances with Yes answers define the language that corresponds to the problem. The other strings either fail to correspond to any instance or correspond to instances with No answers. A problem that corresponds to a decidable language is said to be decidable. Otherwise, a problem is said to be undecidable or, equivalently, non-computable.
In more practical and useful terms, undecidable problems are those for which there is no algorithm that is guaranteed to always find a solution. This means that no fixed set of instructions, executing in finite time by a computer, is guaranteed to lead to a solution. The fact that some problems are undecidable was one of Alan Turing’s major contributions to the theory of computation. Alonzo Church (1936) used a different formalism and arrived at a different definition of computability, now known to be equivalent to Turing’s definition. Kurt Gödel’s (1931) famous incompleteness theorem dealing with the existence of mathematical truths that cannot be demonstrated or derived from a fixed set of axioms is also ultimately equivalent to Turing’s result that there are problems that are undecidable, or non-computable.
It is important to understand why undecidable problems necessarily exist. To do so, we have to go a little deeper into the concepts of computability and infinity. To prove that undecidable problems necessarily exist, we must first become more familiar with the concept of infinity and with the fact that not all infinite sets have the same number of elements. Consider the set of natural numbers, {1, 2, 3, … }, and the set of even numbers, {2, 4, 6, … }, both of infinite cardinality. Do they have the same cardinality, the same number of elements? One may be tempted to say there are more natural numbers than even numbers, because every even number is also a natural number, and the natural numbers also include all the odd numbers. However, as table 4.2 shows, we can create a one-to-one correspondence between the set of natural numbers and the set of even numbers.
Table 4.2 Lists of natural and even numbers, in one-to-one correspondence.
Natural numbers
Even numbers
1
2
2
4
3
6
4
8
5
10
…
…
Now, it is eminently reasonable to argue that if a one-to-one correspondence can be established between the elements of two sets, then the two sets will have the same number of elements—that is, the same cardinality. This is exactly the mathematical definition of cardinality that was proposed in 1874 by the mathematician Georg Cantor, and the only one that can reasonably be used when the number of elements in the sets is infinite.
There are, therefore, as many even numbers as natural numbers. Consider now the set of all positive rational numbers, the numbers that can be written as the ratio of two positive integers. These numbers include 0.5 (1/2), 0.25 (1/4), 0.3333… (1/3), and 1.428571428571… (10/7), among infinitely many others. Certainly there are more positive rational numbers than natural numbers, since, intuition would tell us, an infinite number of rational numbers exists between any two integers. In fact, the situation is even more extreme, because an infinite number of rational numbers exists between any two chosen rational numbers.
Alas, intuition fails us again. The cardinality of the set of rational numbers is no larger than the cardinality of the set on integers. Using a somewhat smarter construction, it is possible to build a list of all rational numbers. If an ordered list of all rational numbers can be built, then they can be put in one-to-one correspondence with the natural numbers, and the cardinality of the set of rational numbers is the same as the cardinality of the set of naturals.
To list the positive rational numbers, let us first consider those for which the numerator plus the denominator sum to 2, then those for which they sum to 3, then those for which they sum to 4, and so on. We should be careful to not include the same number twice. For instance, since 1/2 is already there, we should not include 2/4. Listing all positive rational numbers using this approach will lead to table 4.3. It should be clear that every positive rational number will show up somewhere in this list and that there is a one-to-one correspondence between the rational numbers and the natural numbers. This demonstrates they have the same cardinality.
Table 4.3 Lists of natural and rational numbers, in one-to-one correspondence.
Natural numbers
Rational numbers
1
1/1
2
1/2
3
2/1
4
1/3
5
3/1
6
1/4
7
2/3
…
…
Like the list of even numbers, the set of positive rational numbers is said to be countable, since it can be put in correspondence with the natural numbers (the set we use to count). It would seem that, by using similar tricks, we can create tables like those above for just about any infinite set. As long as the elements of the set can be listed in some specific order, the set will be no larger than the set of natural numbers. This would mean that all infinite sets have the same cardinality, called א0 (aleph zero)—the cardinality of the set of natural numbers. Alas, this is not the case, because, as Cantor demonstrated, there are sets whose elements cannot be put in an ordered list. These sets have higher cardinality than the set of natural numbers, as can be demonstrated with a simple argument.
Imagine that you could build a list of the real numbers between 0 and 1. It would look something like table 4.4, where each αi, each βi, each γi, and so on is a specific digit. Now consider the number 0.αβγδε …, where α ≠ α1, β ≠ β2, γ ≠ γ3, and so on. For instance, this number has digit α equal to 5 unless α1 = 5, in which case it has digital α equal to 6 (or any other digit different from 5). In the same way, digit β equals 5 unless β2 = 5, and in that case β equals 6. Proceed in the same way with the other digits. Such a number, 0.αβγδε…, necessarily exists, and it should be clear it is nowhere in the list. Therefore, not all real numbers between 0 and 1 are in this list. The only possible conclusion from this reasoning is that a complete list of real numbers, even only those between 0 and 1, cannot be built. The cardinality of the set of these numbers is, therefore, larger than the cardinality of the set of natural numbers.
Table 4.4 Hypothetical lists of natural and real numbers, in one-to-one correspondence.
Natural numbers
Real numbers
1
0.α1 β1 γ1 δ1 ε1 …
2
0. α2 β2 γ2 δ2 ε2 …
3
0. α3 β3 γ3 δ3 ε3 …
4
0. α4 β4 γ4 δ4 ε4 …
…
….
Now consider some fixed alphabet Σ, and consider the set of all possible finite strings that can be derived from this alphabet by concatenating symbols in Σ. We will call this language Σ*. This set is countable, since we can list all the strings in the same way we can list all rational numbers. For instance, we can build such a list by ordering the set, starting with the strings of length 0 (there is only one—the empty string, usually designated by ε), then listing the strings of length 1, length 2, and so on. Such a list would look something like (s1, s2, s3, s4, … ). Any language L defined over the alphabet Σ is a subset of Σ*, and can be identified by giving an (infinite) string of zeroes and ones, which identifies which strings in the list belong to L. For instance, if Σ were equal to {0,1} the list of strings in Σ* would look like (ε, 0, 1, 00, 01, 10, 11, 000, 001, … ). As an example, consider the languages L2, consisting of the strings starting with a 0, and the language L3, consisting of the strings having exactly an even number of zeroes. Each one of these languages (and any language defined over Σ*) can be uniquely defined by an (infinite) string of zeroes and ones, a string that has a 1 when the corresponding string in the list of strings in Σ* belongs to the language and has a 0 when the corresponding string doesn’t belong to the language. Figure 4.5 illustrates this correspondence.
Figure 4.5 An illustration of the equivalence between infinite strings of zeroes and ones and languages defined over an alphabet.
At the top of figure 4.5 we have all strings that can be written with the alphabet Σ, written in some specific order. The order doesn’t matter as long as it is fixed. At the bottom of the L2 box, we have all the strings that belong to L2. In our example, language L2 includes all the strings that begin with a 0. At the top of the L2 box, we have the infinite string of zeroes and ones that characterizes L2. In the L3 box, we have the same scheme. Recall that language L3 includes all strings with exactly an even number (including none) of zeroes. This set of strings is shown at the bottom of the box; the infinite string of zeroes and ones that characterizes L3 is shown at the top of the box. It should be clear that there is a one-to-one correspondence between each language defined over some alphabet Σ and each infinite string of zeroes and ones, defined as above. Now, as it turns out, the set of all infinite strings of zeroes and ones is not countable. We can never build a list of the elements in this set, for the same reasons we could not build a set of the real numbers. This impossibility can be verified by applying the same diagonalization argument that was used to demonstrate that the set of reals is not countable. This implies that the set of all languages over some alphabet Σ is not countable.
It turns out the set of all Turing machines that work on the alphabet Σ is countable. We can build the (infinite) list of all Turing machines listing first those with zero states, then the ones with one state, then those with two states, and so on. Alternatively, we may think that we have a universal Turing machine that can simulate any other machine, given its description of the tape. Such a universal Turing machine can emulate any Turing machine, and the description of any of these machines is a fixed set of symbols. These descriptions can be enumerated. Therefore, we can build a list of all machines. It will look something like {TM1, TM2, TM3, TM4, … }.
It is now clear that the set of all languages over some alphabet cannot be put in one-to-one correspondence with the set of Turing machines. Since a Turing machine recognizes one language at most (and some Turing machines do not recognize any language), we conclude that some languages are not recognized by any machine, since there are more languages than Turing machines. In equivalent but less abstract terms, we could say that the set of all programs is countable and the set of all problems is not countable. Therefore, there are more problems than programs. This implies there are problems that cannot be solved by any program.
This reasoning demonstrates there are uncountably many languages that cannot be recognized by any Turing machine. However, it doesn’t provide us with a concrete example of one such language. To make things a bit less abstract, I will describe one particular undecidable problem and provide a few more examples that, despite their apparent simplicity, are also undecidable.
Consider the following problem, called the halting problem: Given a machine M and a string w, does M accept w? We will see that no Turing machine can decide this problem. Suppose there is a decider for this problem (call it H) that takes as input a description of M, <M>, and the string w, <M>:w. <M>:w represents simply the concatenation of the description of M, <M>, and the string w. Machine H accepts the input (i.e., halts in the accept state) if and only if M accepts w. If M doesn’t accept w, then machine H halts in the reject state. Clearly, H is a machine that can decide whether or not another machine, M, accepts or not a given input, w.
If such a decider, H, exists, we can change it slightly to build another Turing machine, Z, that is based on H (with a few modifications) and works in the following way: On input <X>, a description of machine X, Z runs like H on input <X>:<X>, the concatenation of two descriptions of machine X. Then, if H accepts, Z rejects, and if H rejects, Z accepts. Z can easily be built from H by switching the accept and reject labels on the halting states of H. Note that running H on input <X>:<X> is nothing strange. H is expecting as input a description of a machine and a string w. Z, a trivial modification of H, runs on the description of X, <X>, and a string that, in this case, corresponds exactly to the description of X, <X>. In other words, Z is a machine that can decide whether a machine X accepts its own description as input. If X accepts <X>, then Z stops in the reject state. Otherwise, Z stops in the accept state.
We can, obviously, apply Z to any input. What happens when we run Z on input <Z>? Z must accept if Z rejects <Z> and must reject if Z accepts <Z>. This is a contradiction because no such machine can exist. The unique way out of the contradiction is to recognize that Z cannot exist. Since Z was built in a straightforward way from H, the conclusion is that H, a decider for the halting problem, cannot exist. Because no decider for this problem exists, the halting problem is undecidable. In less formal but perhaps more useful terms, you cannot build a program A that, when given another program B and an input to B, determines whether B stops or not.
Since the halting problem is, itself, rather abstract, let us consider another slightly more concrete example, which comes from the mathematician David Hilbert. At the 1900 conference of the International Congress of Mathematicians in Paris, Hilbert formulated a list of 23 open problems in mathematics (Hilbert 1902). The tenth problem was as follows: Given a Diophantine equation specified by a polynomial with more than one variable and integer coefficients, is there a set of integer values of the variables that make the polynomial evaluate to 0? For example, given the polynomial
,
is it possible to select integer values for x and y that make it evaluate to 0? Hilbert asked for a finite sequence of steps (i.e., an algorithm) that would be guaranteed to succeed in determining whether a solution exists for an equation of this type, always answering either Yes or No. Without loss of generality, and to simplify the discussion, we may assume the integer values that will be attributed to x and y are positive integers.
In terms of Turing machines, this problem has to be represented by a language, which is, as we know, a set of strings. Each string in the language represents an encoding of a particular instance of the problem—in this case, a Diophantine equation. The language that corresponds to Hilbert’s tenth problem will therefore be a set of strings, each of which encodes a particular instance of the problem. For instance, we may decide that the string {x, 2, y, 1, 0, +, 1, 5} encodes the polynomial x2y10 + 15. This language will have infinitely many strings, since the number of polynomials is infinite.
Given what we know about Turing machines, we may be able to think of a way to solve this. We can start with the input polynomial written on the tape. The machine then tries all possible combinations for the values of x and y in some specific sequence—for example, (0,0), (0,1), (1,0), (0,2), (1,1), (2,0), … . For each combination of values, the machine evaluates the polynomial. If the value is 0, it halts. Otherwise, it proceeds to the next combination. Such an approach leads to a Turing machine that halts if a solution is found, but that will run forever if there is no solution to the problem. One may think that it should be relatively simple to change something in order to resolve this minor difficulty. However, such is not the case. In fact, we now know, through the work of Martin Davis, Yuri Matiyasevich, Hilary Putnam, and Julia Robinson, that this problem is undecidable (Davis, Putnam, and Robinson 1961; Davis, Matiyasevich, and Robinson 1976). This means that no Turing machine can ever be built to recognize the strings in this language—that is, a machine that would always stop, accepting when the string corresponds to a Diophantine equation with an integer solution and rejecting when the string corresponds to an equation without integer solutions. It must be made clear that, for some specific equations, it may be possible to determine whether or not they have solutions. The general problem, however, is undecidable, since for some equations it isn’t possible to determine whether they do or don’t have integer solutions.
One might think that only very abstract problems in logic or mathematics are undecidable. Such is not the case. I will conclude this section with an example of an apparently simpler problem that is also undecidable: the Post Correspondence Problem (PCP).
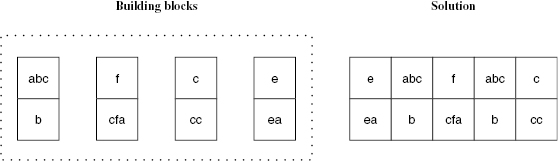
Suppose you are given a set of dominos to use as building blocks. Each half of a domino has one particular string inscribed. For instance, one domino may have abc at the top and b at the bottom. Given a set of these dominoes, and using as many copies of each domino as necessary, the Post Correspondence Problem consists in determining if there is a sequence of dominoes that, when put side by side, spells the same string at the top and at the bottom. For instance suppose you are given the set {abc/b, f/cfa, c/cc, e/ea}. Is there a sequence of (possibly repeating) dominoes that spells the same string at the top and at the bottom? The answer, in this case, is Yes. The sequence {e/ea, abc/b, f/cfa, abc/b, c/cc} spells the string “eabcfabcc” at the top and at the bottom, as shown in figure 4.6.
Figure 4.6 Illustration of the Post Correspondence Problem, known to be undecidable.
It turns out that the problem that corresponds to the apparently simple puzzle just discussed is also undecidable (Post 1946), which implies that no algorithm is guaranteed to always work. If an algorithm to solve this problem exists, then it can also be used to solve the halting problem (Sipser 1997), which, by contradiction, implies that no such algorithm exists. Note that in some cases it may be possible to answer in a definite way, either positively or negatively, but it isn’t possible to devise a general algorithm for this problem that is guaranteed to always stop with a correct Yes or No answer.
Algorithms and Complexity
We have learned, therefore, that some problems are undecidable—that is, no algorithm can be guaranteed to find a solution in all cases. The other problems, which include most of the problems we encounter in daily life, are decidable, and algorithms that solve them necessarily exist. In general, algorithms are designed in abstract terms as sequences of operations, without explicit mention of the underlying computational support (which can be a stored-program computer, a Turing machine, or some other computational model). The algorithms can be more or less efficient, and can take more or less time, but eventually they will stop, yielding a solution.
I have already discussed algorithms and their application in a number of domains, ranging from electronic circuit design to artificial intelligence. Algorithm design is a vast and complex field that has been at the root of many technological advances. Sophisticated algorithms for signal processing make the existence of mobile phones, satellite communications, and secure Internet communications possible. Algorithms for computer-aided design enable engineers to design computers, cars, ships, and airplanes. Optimization algorithms are involved in the logistics and distribution of almost everything we buy and use. In many, many, cases, we use algorithms unconsciously, either when we use our brain to plan the way to go to the nearest coffee shop or when we answer a telephone call.
An algorithm is a sequence of steps that, given an input, achieves some specific result. To make things less abstract, I will give a few concrete examples of commonly used algorithms in a specific domain: the domain of cities, maps, and road distances. From the point of view of these algorithms, the map of cities, roads, and distances will be represented by a graph. A graph is a mathematical abstraction used to represent many problems and domains. A graph consists of a set of nodes and a set of edges. The edges connect pairs of nodes. Both the nodes and the edges can have weight, and the edges can be either directed or non-directed, depending on the nature of the problem. The number of edges that connects to a given node is called the degree of the node. If the graph is directed, the number of incoming vertices is called the in-degree and the number of outgoing vertices is called the out-degree.
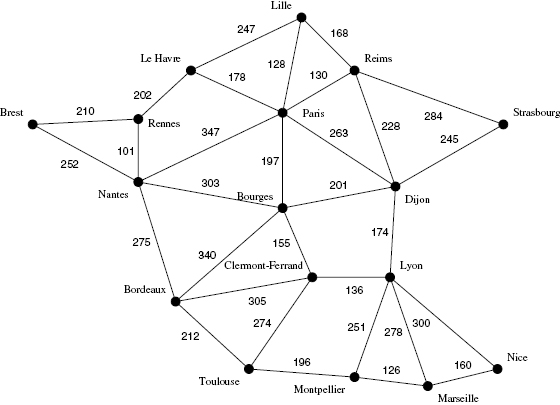
Let the graph shown in figure 4.7 represent the roads and the distances between two nearby cities in France. Now consider the familiar problem of finding the shortest distance between two cities on a map. Given any two cities, the algorithm should find the shortest path between them. If, for example, one wants to go from Paris to Lyon, the shortest way is to go through Dijon, for a total distance of 437 kilometers (263 from Paris to Dijon plus 174 from Dijon to Lyon). It is relatively easy to find the shortest path between any two cities, and there are a number of efficient algorithms that can compute it efficiently. The first such algorithm, proposed by Edsger Dijkstra in 1956, finds the shortest path to any node from a single origin node. (See Dijkstra 1959.) As the graph gets larger, the problem becomes more challenging and the execution time of the algorithm increases; however, the increases are progressive, and very large graphs can be handled.
Figure 4.7 A graph of the distances between French cities.
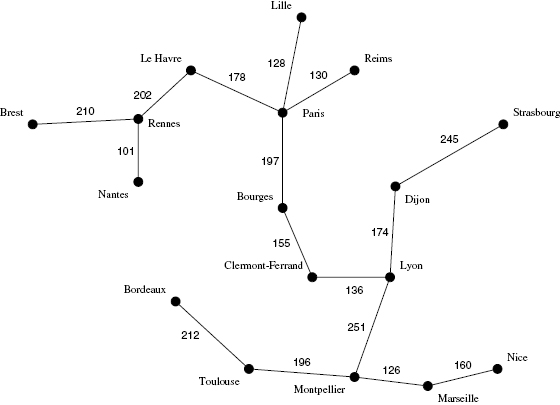
It is also easy to answer another question about this graph: What is the set of roads with shortest total length that will keep all the cities connected? This problem, known as the minimum spanning tree, has many practical applications and has even been used in the study of brain networks (discussed in chapter 9). An algorithm to solve this problem was first proposed as a method of constructing an efficient electricity network for Moravia (Borůvka 1926).
The minimum spanning tree can be found by a number of very efficient algorithms. Prim’s algorithm is probably the simplest of them. It simply selects to include in the spanning tree, in order, the shortest road still unselected that doesn’t create, by being chosen, a road loop (Prim 1957). The algorithm stops when all the cities are connected. If applied to the road map shown in figure 4.7, it yields the tree shown in figure 4.8.
Other, more challenging problems can be formulated on this graph. Imagine you are a salesman and you need to visit every city exactly once and then return to your starting city. This is called the Hamiltonian cycle problem after William Rowan Hamilton, who invented a game (now known as Hamilton’s Puzzle) that involves finding a cycle in the edge graph of a dodecahedron—that is, a platonic regular solid with twelve faces. Finding a Hamiltonian cycle in a graph becomes complex rapidly as the size of the graph increases. If you want to visit all the cities as quickly as is possible, by the shortest possible route, the challenge is called the traveling salesman problem. Again, the problem is easy when there are only a few cities, but becomes harder very rapidly when there are many cities.
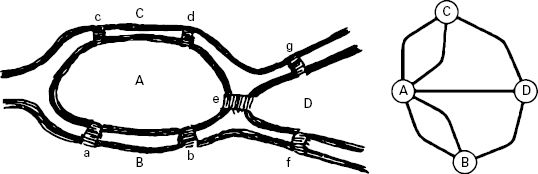
Another simple problem that can be formulated in graphs is the Eulerian path problem, the name of which recalls Leonhard Euler’s solution of the famous Seven Bridges of Königsberg problem in 1736. The city of Königsberg had seven bridges linking the two sides of the Pregel River and two islands. (See figure 4.9.) The problem was to find a walk through the city that would cross each bridge once and only once. The problem can be represented by a graph with a node standing for each island and each margin of the river and with each edge representing a bridge. (In this case the graph is called a multi-graph, because there are multiple edges between the same two nodes.) A path through a graph that crosses each edge exactly once is called an Eulerian path. An Eulerian path that returns to the starting point is called an Eulerian cycle. By showing that a graph accepts an Eulerian path if and only if exactly zero or two vertices have an odd degree, Euler demonstrated it was not possible to find a walk through Königsberg that would cross each bridge exactly once. If there are zero vertices with an odd degree, then all Eulerian paths are also Eulerian cycles. (We will encounter Eulerian paths again in chapter 7.)
Figure 4.9 A drawing (by Leonhard Euler) and a graph representation of the Seven Bridges of Königsberg problem.
Designing algorithms is the art of designing the sequence of steps that, if followed, arrives at a correct solution in the most efficient way. The efficiency of algorithms is basically the time they take to be executed when run on a computer. Of course, the actual time it takes to run an algorithm depends on the specific computer used. However, even the fastest computer will take a very long time to execute an algorithm that is very inefficient, in a very large problem, and even a relatively slow computer can execute an efficient algorithm in a problem of reasonable size. This is because the run time grows very rapidly with the size of the problem when the computational complexity of the algorithm is high. The computational complexity of algorithms is measured by the way they scale with the dimension of the problem. Usually the dimension of the problem is the size of the input needed to describe the problem. In our examples, the size of the graph can be the number of nodes (locations) plus the number of edges (roads or bridges) in the problem description. Technically we should also worry about the length of the description of each node and edge; in many cases, however, we may assume that this factor is not critical, since each of them can be described by a small and constant number of bits. For instance, if the size of the problem is N and the time of execution of an algorithm grows linearly with the size of the problem, we will say that the complexity of the algorithm is on the order of N. On the other hand, the run time can also grow with the square of the size of the problem; in that case, the complexity of the algorithm is on the order of N2, and the run time of the algorithm quadruples when the size of the problem doubles. However, the run time of an algorithm can grow even faster. For instance, when the complexity is on the order of 2N, if the size of the problem increases by only one, the run time of the algorithm doubles.
There is a big difference between the growth rate of algorithms that have polynomial complexity (for example, N2) and those that have exponential complexity (for example, 2N). The reason is that algorithms with exponential complexity become too time consuming, even if one uses fast computers and deals only with small problems. On the other hand, algorithms with polynomial complexity can usually solve very large problems without spending inordinate amounts of time.
Imagine a computer that can execute a billion (109) operations per second and three different algorithms that take, respectively, N, N2, and 2N operations to solve a problem of size N. It is easy to see that, for a problem of size 1,000, an algorithm that requires N operations will spend one microsecond of computer time. Nonetheless, it is instructive to compute how the execution time grows with N for each of the three algorithms. Table 4.5 gives the time it would take for this hypothetical computer (comparable to existing computers) to solve this problem with algorithms of varying complexity. Entries in the table contain the symbol ∞ if the run time is larger than the known age of the universe (about 14 billion years). As becomes clear from the table, even moderately large problems take too long to be solved by algorithms with exponential complexity. This is, again, a consequence of the now-familiar properties of exponential functions, which grow very rapidly even when starting from a very low base.
Table 4.5 Execution times for algorithms of varying complexity. Here ∞ stands for times that are longer than the age of the universe.
On the other hand, algorithms with polynomial complexity can handle very large problems, although they may still take a long time if the problem is very large and the degree of the polynomial is higher than one. For these reasons, polynomial time algorithms are usually called efficient algorithms, even though, in some cases, they may still take a long time to terminate. Problems are called tractable if algorithms that solve them in polynomial time are known, and are called intractable otherwise. This division into two classes is, in general, very clear, because there is a class of problems for which polynomial time algorithms exist, and there is another class of problems for which no polynomial time algorithms are known.
The problem of finding the shortest path between two cities and the traveling salesman problem belong to these two different classes of complexity. In fact, a number of polynomial time algorithms are known that solve the shortest-path problem (Dijkstra 1959; Floyd 1962) but only exponential time algorithms are known that solve the traveling salesman problem (Garey and Johnson 1979). The Eulerian path problem can also be solved in polynomial time, with an algorithm that grows only linearly with the size of the graph (Fleischner 1990).
One might think that, with some additional research effort, a polynomial time algorithm could be designed to solve the traveling salesman problem. This is, however, very unlikely to be true, because the traveling salesman problem belongs to a large class of problems that are, in a sense, of equivalent complexity. This class, known as NP, includes many problems for which no efficient solution is known to exist. The name NP stands for Non-deterministic Polynomial-time, because it is the class of decision problems a non-deterministic Turing machine can solve in polynomial time. A non-deterministic Turing machine is a machine that, at each instant in time, can take many actions and (non-deterministically) change state to many different states. A decision problem is a problem that is formulated as a question admitting only a Yes or a No answer.
Non-deterministic Turing machines are even stranger and less practical than the deterministic Turing machines described before. A non-deterministic Turing machine is only a conceptual device. A non-deterministic Turing machine cannot be built, because at each instant in time it could move to several states and write several symbols at once—in parallel universes, so to speak. As time goes by, the number of configurations used by a non-deterministic Turing machine grows exponentially because each new action, combined with the previous actions, creates new branches of the computation tree. It is believed that a non-deterministic Turing machine could be exponentially faster than a deterministic one, although, as we will see, the question remains open.
For present purposes it is sufficient to know that the class NP coincides exactly with the class of decision problems whose solution can be verified efficiently in polynomial time. This alternative definition of the class NP is possible because a non-deterministic Turing machine solves these problems by “guessing” the solution, using its non-deterministic abilities to write on the tape many solutions in parallel and then checking if the solution is right. If that is the case, then the machine stops and accepts the input. All computations of the machine that do not lead to solutions fail to finish in the accept state and are ignored.
Some problems in the class NP are particularly hard in the sense that, if an efficient (i.e., polynomial time) solution for one of them exists, then an efficient solution for all the problems in NP must also exist. These problems are called NP-hard. (The traveling salesman problem is such a problem.) Decision problems that are NP-hard and are in NP are called NP-complete.
The traveling salesman problem, as formulated above, is not a decision problem, because it asks for the shortest path. However, it can be reformulated to become a related decision problem: Given a graph, is there a tour with a length smaller than a given number? The solution for the decision problem may be very hard to find (and is, in this case), but it is very easy to verify: Given a solution (a list of traversed cities, in order), verify, by simply summing all the inter-city distances in the path, if the total length of the trip is smaller than the given number.
Another class, P, is a subset of NP, and includes all decision problems that can be solved by a (deterministic) Turing machine in polynomial time. The decision problem associated with the shortest-path problem is in P: Is there a path between city A and city B shorter than a given number?
Stephen Cook (1971) showed that if an efficient algorithm is found for an NP-complete problem, that algorithm can be used to design an efficient algorithm for every problem in NP, including all the NP-complete ones. Richard Karp (1972) proved that 21 other problems were NP-complete, and the list of known NP-complete problems has been growing ever since. Interestingly, both Cook and Karp were at the University of California at Berkeley when they did the work cited above, but Cook was denied tenure in 1970, just a year before publishing his seminal paper. In the words of Richard Karp, “It is to our everlasting shame that we were unable to persuade the math department to give him tenure.”
No one really knows whether an algorithm that solves NP-complete problems efficiently exists, but most scientists believe that it does not. If a polynomial time algorithm is discovered for one NP-complete problem (any problem will do), then that polynomial time algorithm can be adapted to solve efficiently (i.e., in polynomial time) any problem in NP, thereby showing NP is actually equal to P.
Whether P is equal to NP or different from NP is one of the most important open questions in computing and mathematics (perhaps the most important one); and it was also introduced in Cook’s 1971 paper. It is, in fact, one of the seven Millennium Prize Problems put forth by the Clay Mathematics Institute in 2000. A prize of $1 million is offered for a correct solution to any of them.
Most scientists doubt that the P-vs.-NP problem will be solved any time soon, even though most believe that P is different from NP. If, as I find likely, there are problems in NP that are not in P, these problems will forever remain difficult to solve exactly and efficiently.
One problem known to be in NP but not necessarily in P is the problem of determining the factors of a composite number. A composite number is an integer that can be written as the product of two or more smaller integers. Given two numbers, it is very easy to verify if the first is a factor of the second by performing standard long division, which computers can do very, very rapidly.
Manindra Agrawal, Neeraj Kayal, and Nitinby Saxena (2004) have shown that it is also possible to determine, in polynomial time, whether a number is prime. However, if the factors of a very large integer are not known, finding them is very difficult. In such a case, the size of the description of the problem is the number of digits the number contains. All known algorithms for this problem take more than polynomial time, which makes it very difficult and time consuming to factorize numbers that have many digits. One may think this is a problem without practical relevance, but in fact the security of Internet communications rests largely on a particular cypher system: the RSA algorithm (Rivest, Shamir, and Adleman 1978), which is based on the difficulty of factorizing large composite numbers. Proving that P equals NP, were it to happen, would probably break the security of the RSA algorithm, which would then have to be replaced by some yet-unknown method.
Other computing paradigms, not necessarily equivalent to Turing machines, may move the border between tractable and intractable problems. Quantum computing, an experimental new approach to computing that uses the principle of superposition of quantum states to try a large number of solutions in parallel, can solve the factorization problem efficiently (Shor 1997). Working quantum computers that can deal with interesting problems, however, do not exist yet and aren’t likely to become available in the next few decades. Very small quantum computers that are essentially proof-of-concept prototypes can work with only a few bits at a time and cannot be used to solve this problem or any problem of significant dimension. Many people, including me, doubt that practical quantum computers will ever exist. However, in view of the discussion of the evolution of technology in chapter 2 we will have to wait and see whether any super-Turing computing paradigms, based on machines strictly more powerful than Turing machines, ever come into existence.
Despite the fact that there are many NP-complete problems, for which no efficient algorithms are known, efficient algorithms have been developed for many fields, and most of us make use of such algorithms every day. These algorithms are used to send sounds and images over computer networks, to write our thoughts to computer disks, to search for things on the World Wide Web, to simulate the behaviors of electrical circuits, planes and automobiles, to predict the weather, and to perform many, many other tasks. Cell phones, televisions, and computers make constant use of algorithms, which are executed by their central processing units. In some cases, as in the example of the traveling salesman problem, it isn’t feasible to find the very best solution, but it is possible to find so-called approximate solutions—that is, solutions that are close to the best.
Algorithms are, in fact, everywhere, and modern life would not be the same without them. In fact, a well-accepted thesis in computing, the Church-Turing thesis, is that any computable problem can be solved by an algorithm running in a computer. This may also be true for problems at which humans excel and computers don’t, such as recognizing a face, understanding a spoken sentence, or driving a car. The fact that computers are not good at these things doesn’t mean that only a human will ever excel at them. It may mean that the right algorithms for the job have not yet been found. On the other hand, it may mean that humans somehow perform computations that are not equivalent to those performed by a Turing machine.
The Church-Turing Thesis
Let us now tackle a more complex question: What can be effectively computed? This question has a long history, and many eminent thinkers and mathematicians have addressed it. Alan Turing, Alonzo Church, and Kurt Gödel were central to the development of the work that led to the answer. The Church-Turing thesis, now widely accepted by the scientific community even though it cannot be proved mathematically, results from work by Turing and Church published in 1936. The Church-Turing thesis states that every effectively computable function can be computed by a Turing machine. This is equivalent to the statement that, except for differences in efficiency, anything that can be computed can be computed by a universal Turing machine. Since there is no way to specify formally what it means to be “effectively computable” except by resorting to models known to be equivalent to the Turing model, the Church-Turing thesis can also be viewed as a definition of what “effective computability” means.
Technically, the concept of computability applies only to computations performed on integers. All existing computers perform their work on integers, which can be combined to represent good approximations of real numbers and other representations of physical reality. This leaves open the question of whether physical systems, working with physical quantities, can be more powerful than Turing machines and perform computations that no Turing machine can perform.
The Physical Church-Turing thesis, a stronger version of the Church-Turing thesis, states that every function that can be physically computed can be computed by a Turing machine. Whereas there is strong agreement the Church-Turing thesis is valid, the jury is still out on the validity of the Physical Church-Turing thesis. For example, it can be shown that a machine that performs computations with real numbers is more powerful than a Turing machine. Indeed, a number of computational models that might be strictly more powerful than Turing machines have been proposed. However, it remains unclear whether any of these models could be realized physically. Therefore, it isn’t completely clear whether physical systems more powerful than Turing machines exist.
Whether or not the Physical Church-Turing thesis is true is directly relevant to an important open problem addressed in this book: Can the human brain compute non-computable functions? Do the physics of the human brain enable it to be more powerful than a Turing machine? More generally, can a physical system be more powerful than a Turing machine, because it uses some natural laws not considered or used in the Turing model?
In a 1961 article titled “Minds, Machines and Gödel,” John Lucas argued that Gödel’s first incompleteness theorem shows that the human mind is more powerful than any Turing machine can ever be. Gödel’s theorem states that any mathematical system that is sufficiently powerful cannot be both consistent and complete. Gödel’s famous result on the incompleteness of mathematical systems is based on the fact that, in any given formal system S, a Gödel sentence G stating “G cannot be proved within the system S” can be formulated in the language of S. Now, either this sentence is true and cannot be proved (thereby showing that S is incomplete) or else it can be proved within S and therefore S is inconsistent (because G states that it cannot be proved).
Lucas argued that a Turing machine cannot do anything more than manipulate symbols and that therefore it is equivalent to some formal system S. If we construct the Gödel sentence for S, it cannot be proved within the system, unless the system is inconsistent. However, a human—who is, Lucas assumes, consistent—can understand S and can “see” that the sentence is true, even though it cannot be proved within S. Therefore, humans cannot be equivalent to any formal system S, and the human mind is more powerful than any Turing machine.
There are a number of flaws in Lucas’ theory, and many arguments have been presented against it. (One is that humans aren’t necessarily consistent.) Furthermore, in order to “see” that a sentence is valid within S, the human has to be able to thoroughly understand S—something that is far from certain in the general case. Therefore, not many people give much weight to Lucas’ argument that the human mind is strictly more powerful than a Turing machine.
Lucas’ argument was revisited by Roger Penrose in his 1989 book The Emperor’s New Mind. Using essentially the same arguments that Lucas used, Penrose argues that human consciousness is non-algorithmic, and therefore that the brain is not Turing equivalent. He hypothesizes that quantum mechanics plays an essential role in human consciousness and that the collapse of the quantum wave function in structures in the brain make it strictly more powerful than a Turing machine. Penrose’s argument, which I will discuss further in chapter 10, is that the brain can harness the properties of quantum physical systems to perform computations no Turing machine can emulate.
So far no evidence, of any sort, has been found that the human brain uses quantum effects to perform computations that cannot be performed by a Turing machine. My own firm opinion is that the human brain is, in fact, for all practical purposes, Turing equivalent. I am not alone in this position. In fact, the large majority of the scientific community believes, either explicitly or implicitly, that the human brain is Turing equivalent, and that only technological limitations and limited knowledge stop us from recreating the workings of the brain in a computer.
Later in the book we will take a deeper look at the way the brain works. In the next few chapters, I will argue that the brain is effectively an immensely complicated analog computer performing computations that can be reproduced by a digital computer to any desirable degree of accuracy. Given a sufficiently precise description of a human brain, and of the inputs it receives, a digital computer could, in principle, emulate the brain to such a degree of accuracy that the result would be indistinguishable from the result one obtains from an actual brain. And if this is true for brains, it is also true for simpler physical systems, and, in particular, for individual cells and bodies. The idea that intelligent behavior can be the result of the operation of a computer is an old one, and is based, in large part, on the principle that the computations performed by human brains and by computers are in some sense equivalent. However, even if brains are, somehow, more powerful than computers, it may still be possible to design intelligent machines. Designing intelligent machines has, indeed, been the objective of a large community of researchers for more than fifty years. The search for intelligent machines, which already has a long history of promises, successes, and failures, is the subject of the next chapter.


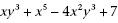 ,
,