The work that led Charles Darwin to write On the Origin of Species by Means of Natural Selection probably didn’t begin as an effort to start what would become the major scientific revolution of all time, a paradigm shift that would change people’s views of the world more deeply than any other in human history.
It is not likely any other idea in human history has had such a large impact on the way we think today. Many other important paradigm shifts have changed people’s view of the world profoundly, among them Copernicus’ removal of the Earth from the center of the universe, Newton’s laws of motion, Einstein’s theory of relativity, the atomic theory, quantum mechanics, the internal combustion engine, and integrated circuits. However, none of those breakthroughs changed the way we view the world and ourselves as profoundly as the theory that Darwin developed in order to explain why there are so many different species on our planet.
The Ultimate Algorithm
Darwin’s early interest in nature led him to pursue a passion for natural science, which culminated with his five-year voyage on the Beagle. The publication of his journal of the voyage made him famous as a popular author. Puzzled by the geographical distribution of wildlife and the types of fossils collected on the voyage, Darwin conceived his theory of natural selection. Other scientists, among them Alfred Wallace, had arrived at similar conclusions, but Darwin was the first to publish them. In fact, when Darwin became aware of Wallace’s ideas, he had to rush to complete and publish his own work, which he had been developing at a more leisurely pace until then.
The simple but powerful idea that Darwin described is that different species of living beings appear because of selective pressure acting differentially on the reproductive success of individuals by selecting qualities that are advantageous, even if only to a small degree:
If then we have under nature variability and a powerful agent always ready to act and select, why should we doubt that variations in any way useful to beings, under their excessively complex relations of life, would be preserved, accumulated, and inherited? Why, if man can by patience select variations most useful to himself, should nature fail in selecting variations useful, under changing conditions of life, to her living products? What limit can be put to this power, acting during long ages and rigidly scrutinising the whole constitution, structure, and habits of each creature,—favouring the good and rejecting the bad? I can see no limit to this power, in slowly and beautifully adapting each form to the most complex relations of life. The theory of natural selection, even if we looked no further than this, seems to me to be in itself probable. (Darwin 1859)
The central point of Darwin’s argument is that species tend to reproduce themselves in accordance with an exponential law because, in each generation, an individual can give rise to multiple descendants. Darwin understood that a single species, growing at an exponential rate, would fill the planet and exhaust all available resources if natural selection didn’t limit the growth of populations. Competition between species ensures that those better adapted to the environment have a competitive advantage, measured by the number of surviving offspring. Differences (perhaps small ones) in the rate of growth of populations with different characteristics led, over time, to the selection of advantageous traits. The same principle could be applied as naturally to the feathers of peacocks, the tails of dolphins, the necks of giraffes, and the human brain.
More damaging to the prevailing view that the human species had a central role on Earth, if not in the universe, was the fact that this argument could be applied as well to the appearance of all the characteristics we recognize in humans. In On the Origin of Species, Darwin didn’t even make this view explicit. He simply alluded, en passant, that “light will be thrown on the origin of man and his history,” thus recognizing that the human species was no different from the other species, since it also evolved as a result of the pressure imposed by natural selection.
That Darwin formulated the concept of evolution by natural selection in such a clear way that his ideas remain unchanged by 150 years of scientific development is, in itself, remarkable. We now understand that evolution by natural selection, as proposed by Darwin, can occur only if discrete units of genetic inheritance are somehow able to replicate themselves in the bodies of the offspring. These units, which we now call genes, are passed from generation to generation almost unchanged.
Even more remarkable is that Darwin reached his conclusions, which are still valid today, without having the slightest hint about the underlying mechanisms that enabled specific characteristics to be passed down from parents to their descendants. Because he was unaware of contemporary work by Gregor Mendel (see Mendel 1866), Darwin had few ideas—and the ones he had weren’t correct (Charlesworth and Charlesworth 2009)—about the physical mechanisms that were behind the working of genes, the discrete units of inheritance necessary for the theory of evolution to work. If physical characteristics were passed from parents to descendants by means of continuous analog encoding, the process of evolution probably wouldn’t have started in the first place.
In most species, individuals reproduce by mating, generation after generation. For that reason, even if a specific characteristic such as height were to be selectively advantageous, it would become diluted over successive generations if the genetic makeup of individuals weren’t encoded in a discrete way. To understand why this is so, imagine a set of glasses full of dyed water. Some glasses have more dye, some have less. Now imagine that selection acts upon this set of glasses by selecting, for instance, those containing darker-colored water. To obtain the next generation, the glasses with the darker water are selected and combined among themselves. The next generation will, indeed, be more heavily dyed than the original, and the population of glasses, as a whole, will contain darker water than the original population. However, since the water in the glasses was combined to obtain the next generation, this generation is much more uniform than the preceding one. As generations go by, all the glasses will become the same color, and no further darkening of the water can take place.
The story is very different if the amount of dye in each glass is recorded with a discrete encoding, and it is this discrete number that is probabilistically passed to the descendants, not the dyed water itself. Now the problem of convergence of the population to the average of the best individuals is avoided, since different concentrations of dye, even the highest, can still be present in the population many generations from the initial one. Add to this a somewhat rare, but not impossible, event, such as a mutation, and the conditions for endless and open-ended evolution are in place.
The actual mechanisms that define genetic inheritance were brought to light through the work of Mendel. Mendel, the father of genetics, became an Augustinian friar in order to obtain an education. He conducted his studies on the variation of plants by cultivating, between 1856 and 1863, almost 29,000 pea plants. He selected and studied seven plant characteristics, including seed form, pod form, seed color, pod color, and flower color. We now know that it is the encoding of these traits by genes in different chromosomes that leads to the independence between traits that characterizes Mendel’s model.
Mendel’s extensive experimental results led him to identify the mechanisms that are now known as Mendel’s laws of inheritance. His results, published in an obscure and largely unnoticed journal (Mendel 1866), showed that genetic traits are passed to the descendants in a digital, on/off way, and also that the organisms he worked with (pea plants) have two copies of each gene, one of which is passed to the following generation. In fact, Mendel’s results apply to all diploid organisms (i.e., organisms with two copies of each chromosome). Most animals and plants are diploid. Some, however, are polyploid—a salmon, for example, has three copies of each chromosome.
Mendel further deduced that different traits are independently passed to the next generation—something that was true of the traits he studied, but that, in general, applies only to characteristics encoded by independent genes. It is worthwhile to consider his results in more detail.
Suppose that a certain trait in a plant is encoded by a gene that can take one of only two values, called alleles: the value A (which we will assume dominant) or the value a (which we will assume recessive). A specific value of an allele is called dominant if it masks the other value the allele can take. In this example, we are assuming that there are only two alleles for each gene and two copies of each chromosome, and thus we have four possible values in each locus: AA, Aa, aA, and aa. Since allele A is dominant, the plants with the AA, Aa, and aA variants will exhibit the trait, and the plants with the aa variant will not. When a plant reproduces, the offspring inherit one copy of the gene from each of the progenitors. With this information at hand, we can proceed with the analysis performed by Mendel, which remains the basis of modern genetics.
We begin the experiment with some plants with the AA variant and some with the aa variant. When we cross an AA plant with an aa plant, we obtain plants with Aa, which, like the AA parent, exhibit the trait because the A allele dominates the a allele. Things get more interesting in the second generation, when we cross the Aa plants with other Aa plants. Since the next generation will inherit one gene from each parent, we will now get AA plants (roughly 25 percent), Aa and aA plants (roughly 50 percent ), and aa plants (roughly 25 percent). Since the AA and Aa plants exhibit the trait whereas the aa plants do not, we expect a ratio of 3:1 between the plants that exhibit the trait and the plants that do not. This is exactly the result that Mendel obtained.
Mendel’s careful experimental procedure led to a very conclusive verification of the hypothesis that traits are passed on to the next generation in a discrete way by combining the genes of the parents. In fact, the conclusions he reached were so clear, precise, and convincing that, many years later, a dispute arose about the plausibility of the extremely high precision of his experimental results. The statistician and geneticist Ronald Fisher (1936) pointed out the experimental ratios Mendel obtained in his experiments were implausibly close to the ideal ratio of 3:1. Fisher analyzed the results that led to the 3:1 ratio in the second generation and found that re-running the experiments would give results closer to this theoretical ratio less than once per thousand attempts. Thus, either Mendel was extremely lucky or there was something to be explained about Mendel’s results. The controversy is far from over, as is witnessed by the many books and articles on the subject still being published. Although few people would accuse Mendel of doctoring the data, the results have continued to be mysterious for many. Among many explanations, it has been suggested Mendel may have either dropped or repeated some results that were not considered sufficiently consistent with his hypothesis (Franklin et al. 2008; Pires and Branco 2010).
Mendel’s work was largely ignored in his time, and it wasn’t widely accepted until many years after his death, when the need for a discrete model for inheritance became clear. The physical and molecular reasons for Mendel’s results would not become clear until 90 years later, when James Watson and Francis Crick (1953) identified deoxyribonucleic acid (DNA) as the molecule responsible for genetic inheritance and discovered its helical structure.
Despite the minor difficulty caused by the fact that no mechanism, known at the time, could support the type of inheritance necessary for evolution to work, Darwin’s ideas survived all discussions that ensued. In present-day terms, Darwin had simply proposed that life, in all its diversity, was the result of a blind algorithmic process that had been running on Earth for about 4 billion years. That evolution can be seen as an algorithm should come as no surprise to readers now familiar with the concept. Daniel Dennett (1995) expressed this idea clearly and beautifully:
The theoretical power of Darwin’s abstract scheme was due to several features that Darwin firmly identified, and appreciated better than many of his supporters, but lacked the terminology to describe explicitly. Today we would capture these features under a single term. Darwin had discovered the power of an algorithm.
The idea that life on Earth, in all its forms, was created by an algorithm— a process that blindly, step by step, applied fixed and immutable rules to derive the immense complexity of today’s world—caught people by surprise. The ages-old question of how the different species appeared on the planet had, after all, a simple and self-evident answer. Natural selection sufficed to explain the wide variety of species found in the tree of life. To be fair, many questions remained unanswered. The most vexing one was, and still is, related to the question of how evolution began. After all, natural selection can be used to explain differential rates of reproduction only after the reproduction scheme is in place, after organisms that reproduce and exhibit variations exist. Darwin didn’t try to answer that question. Even today, we have only the foggiest idea of what were the first systems that could, in some way, replicate themselves.
Many arguments have been made against the theory of evolution, and there are still many skeptics. Creationists believe that life was created, in its present form, by a divine entity, perhaps only a few thousand years ago. Of the many arguments that have been leveled at the theory of evolution, the strongest is the argument that such complex designs as we see today could not have originated in a succession of random changes, no matter how sophisticated the blind algorithm conducting the process. At some point in the course of billions of years, the argument goes, some intelligent designer intervened. If we see a watch (a complex device), we naturally deduce that there is a watchmaker. Yet, the argument continues, we look at an eye—something far more complex than a watch—and believe it has evolved by an almost random accumulation of small changes. Many authors have presented beautiful answers to this argument, and I could do no better than quote one of the most eloquent of them, Richard Dawkins (1986):
Natural selection is the blind watchmaker, blind because it does not see ahead, does not plan consequences, has no purpose in view. Yet the living results of natural selection overwhelmingly impress us with the appearance of design as if by a master watchmaker, impress us with the illusion of design and planning.
And yet, even though most of us are ready to accept that evolution, a blind process, has created all creatures, big and small, we may still be somewhat convinced that the end product of this process is the creature known as Homo sapiens. This is very unlikely to be the case. Evolution did not set out to create anything in particular. If the process was to be run all over again, it is extremely unlikely that something like the human species would come out of it. Too many accidents, too many extremely unlikely events, and too much randomness were involved in the evolution of complex creatures. The development of the first self-reproducible entity, the evolution of eukaryotic cells, the Cambrian explosion, the extinction of dinosaurs, and even the fact that Homo sapiens was lucky enough to survive many difficult challenges and evolutionary bottlenecks (unlike its cousins) are just a few examples of historical events that might have ended differently. Had they not occurred, or had they ended in a different way, the history of life on Earth would have been very different, and Earth might now be populated by an entirely different set of species. In the words of one famous evolutionary biologist,
We are glorious accidents of an unpredictable process with no drive to complexity, not the expected results of evolutionary principles that yearn to produce a creature capable of understanding the mode of its own necessary construction. (Gould 1996)
By the same reasoning, it is extremely unlikely that Homo sapiens is the final result of this multi-billion-year process. However, it is true that, for the first time in the history of the planet, one species has the tools to control evolution. We have been controlling evolution for centuries, by performing human-driven selection of crops and of dogs, horses, and other domestic animals. But today we are on the verge of developing technologies that can be used to directly control the reproductive success of almost all forms of life on Earth, and we may even become able to create new forms of life.
It is important to remember that natural selection doesn’t evaluate and reward the fitness of individuals. True, the number of descendants is statistically related to the fitness of a specific individual. But, given the mechanisms of genetic inheritance, and the dimension of the Library of Mendel (which was discussed in chapter 2), even very fit individuals are likely to exist only once in the whole history of the universe. No future copies of exceptional individuals will be selected for future reincarnation by natural selection. In general, at least in organisms that reproduce sexually, the offspring will be very different from even the most successful individuals. Instead, specific versions of those elusive entities called genes will be preserved for future generations. Though it may be intuitive to think that natural selection is selecting individuals, it is more reasonable to view the gene as the basic unit of selection.
The genes were the original entities that, roughly 4 billion years ago, managed to find some process that would replicate them. They became, therefore, replicators. Successful genes became more common, and, therefore, increased in number at an exponential rate, if selective pressure didn’t act to curtail their expansion. The result is that the most common genes in a population are those that, in the average, through a large number of genotypes and in a large number of situations, have had the most favorable effects on their hosts. In other words, we should expect selfish genes to flourish, meaning that they will promote their own survival without necessarily promoting the survival of an organism, a group, or even a species. This means that evolutionary adaptations are the effects genes have on their hosts, in their quest to maximize their representation in the future generations. An adaptation is selected if it promotes host survival directly or if it promotes some other goal that ultimately contributes to successful reproduction of the host.
With time, these genes encoded more and more complex structures—first simple cells, then complex eukaryotic cells, then bodies, and finally brains—in order to survive. In fact, organisms, as we know them today, exist mainly to ensure the effective replication of these units, the genes (Dawkins 1986). In the most extreme view, organisms exist only for the benefit of DNA, making sure that DNA molecules are passed on to the next generation. The lifetimes of genes—sequences of DNA encoding for a specific protein or controlling a specific process—are measured in millions of years. A gene lasts for many thousands of generations, virtually unchanged. In that sense, individual organisms are little more than temporary vehicles for DNA messages passed down over the eons.
We may think that, with the passage of time, things have changed and evolution is now centered on organisms, and not on the genetic units of inheritance we now know to be encoded in the form of specific combinations of DNA bases. We may think these original and primitive replicators are now gone, replaced by sophisticated organisms, but that would be naive. Perhaps many millions of years after mankind is gone from the Earth, the most effective replicators will still populate the planet, or even the known universe. We have no way of knowing how these replicators will look millions of years from now. Maybe they will be very similar to today’s genes, still encoding specific characteristics of cells—cells that will form organisms much like the ones that exist today. But I do not believe that. One of my favorite passages by Dawkins (1976) makes it clear we are no more than vehicles for the survival of genes, and that we should be aware that they are ingenious entities indeed:
Was there to be any end to the gradual improvement in the techniques and artifices used by the replicators to ensure their own continuation in the world? There would be plenty of time for their improvement. What weird engines of self-preservation would the millennia bring forth? Four thousand million years on, what was to be the fate of the ancient replicators? They did not die out, for they are the past masters of the survival arts. But do not look for them floating loose in the sea; they gave up that cavalier freedom long ago. Now they swarm in huge colonies, safe inside gigantic lumbering robots, sealed off from the outside world, communicating with it by tortuous indirect routes, manipulating it by remote control. They are in you and me; they created us, body and mind; and their preservation is the ultimate rational for our existence. They have come a long way, those replicators. Now they go by the name of genes, and we are their survival machines.
Given the characteristics of exponential growth of entities that reproduce themselves at some fixed rate, we can be sure that replicators, in some form, will still be around millions of years from now. Many of them may no longer use DNA as their substrate to encode information, but some of them will certainly remain faithful to that reliable method.
The essence of a replicator is not the medium used to store the information; it is the information that is stored. As long as mechanisms to replicate the entities are available, any substrate will do. In the beginning, DNA probably wasn’t the substrate of choice, because it requires complicated reproduction machinery that wasn’t available then. In fact, there is another molecule that is extensively used to store and transmit genetic information inside the cells: ribonucleic acid (RNA). It may have been a precursor of DNA as the substrate to store biological information. RNA plays various biological roles inside cells. Unlike DNA, it is usually a single-stranded coil.
According to the RNA World Hypothesis, RNA molecules were precursors of all current life on Earth before DNA-based life developed. That widely discussed hypothesis is favored by many researchers because there is some evidence that many old and very stable cellular structures are based on RNA. However, even supporters of the RNA World Hypothesis believe that other, even less developed supports probably existed before RNA. What they were remains, however, an open question.
In the future, other substrates may be better able than DNA to store and process the information required by replicators to survive and reproduce. We are all familiar with computer viruses, and know well the potential they have to replicate themselves, in an exponential fashion, when the right conditions are present. And yet, these computer viruses are very primitive replicators, brittle and unsophisticated. In the future, much more sophisticated entities that can replicate themselves in the memories and CPUs of computers may come into existence. These may be the replicators of the future, and they will be as similar to today’s DNA-based creatures as today’s creatures are similar to the replicators that populated the warm ponds on Earth 4 billion years ago.
Cells and Genomes
Now that we understand the algorithm that led to evolution by natural selection and are aware of the existence of those somewhat mysterious units of inheritance called genes, we can proceed to understand how the basic replicators of yore, the genes, managed to evolve the complex structures that are now used to keep them alive: multi-cellular organisms.
Even after the publication and assimilation of Darwin’s work, biology remained a relatively calm and unfashionable field of research. The principle of evolution by natural selection and the basic tenets of genetics opened the door to the treatment of biology as a science based on first principles. For a long time, however, ignorance of the physical mechanisms that supported life and ignorance of genetics stood in the way of a truly principled approach to biology. In fact, for most of the twentieth century the fundamental mechanisms underlying evolution and speciation were unknown, since the biochemical basis for life was poorly understood, and little was known about the way genetic characteristics were passed from generation to generation. In fact, until 1953 no one knew exactly how genetic characteristics were passed from parents to their descendants.
While Darwin worked on the theory of evolution, a number of biologists were homing in on the central importance of the cell in biology. In 1838 Theodor Schwann and Matthias Schleiden began promoting the idea that organisms were made of cells and that individual cells were alive. (See Schwann 1839; Schleiden 1838.) By about 1850, most biologists had come to accept that cells were the basic units of living beings, were themselves alive, and could reproduce. By 1900, many pathways of metabolism, the way molecules interact with each other, were known. Improved techniques such as chromatography (mixture-separation techniques based on the use of gels) and electrophoresis (the use of electromagnetic fields to separate differently charged particles) led to advances in biochemistry and to a reasonable understanding of some of the basic biochemical mechanisms found in cells.
Oswald Avery, Colin MacLeod, and Maclyn McCarty (1944) demonstrated that DNA was the substance responsible for producing inheritable change in some disease-causing bacteria and suggested that DNA was responsible for transferring genetic information to offspring. However, not until 1953, when Watson and Crick demonstrated that the DNA molecule was the carrier of genetic information, did genetics begin to play the central role it has today. Until then, the role of DNA was mostly unknown. The biophysicist Max Delbrück even called it a “stupid molecule,” noting that it monotonously repeated the four bases A, C, T, and G (for adenine, cytosine, thymine, and guanine), whereas proteins were known to be extraordinarily versatile in form and function. Watson and Crick, using x-ray data collected by Rosalind Franklin and Maurice Wilkins, proposed the double-helix structure of the DNA molecule, thereby solving a centuries-old question about how genetic information was passed from cell to cell and from parents to their descendants.
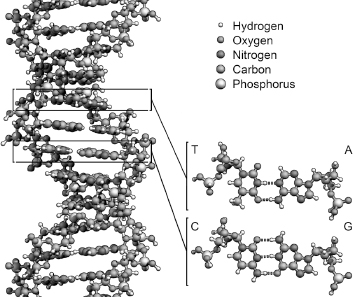
When Watson and Crick identified the double helix of DNA as the repository for genetic information, stored in digital format in a molecule that until then hadn’t been thought of as very exciting, they opened the door to the most exciting decades in the history of biological sciences. Suddenly, the discrete encoding mechanism of genetics inherent to Mendel’s ideas and to Darwin’s evolution mechanism was discovered, in the form of a molecule with a simple, repetitive structure. Each segment of each one the strands of the double helix of a DNA molecule contains one base, or nucleotide, encoding one of possible four values, A, C, T, and G. The nature of the chemical bonds between the two strands of the helix makes sure that an A is always paired with a T, and that a C is always paired with a G, as shown in figure 6.1. This redundancy makes it possible to create two copies of a DNA molecule by splitting the double helix into two single helices, which then act as templates for two new, double-stranded DNA molecules.
Figure 6.1 The structure of the double helix of the DNA molecule, in which A-T and C-G base pairing creates the redundancy needed for DNA duplication when cells split or organisms reproduce. Drawing by Richard Wheeler (2011), reproduced with permission; also available at Wikimedia Commons.
This giant step in our understanding of the way nature passed characteristics from a cell to other cells, and from an organism to its descendants, eventually led to another revolution—a revolution that is still underway. With this discovery, it became finally clear that the replicators in today’s world are made of DNA, and that this molecule is at the center of all cellular activity. It is DNA that carries the genetic information as cells divide, and from parents to offspring. Therefore, DNA must contain, encoded in its long sequence of bases, the structures that represent the elementary units of inheritance.
We now know that DNA encodes information used in the cells in many different ways, many of them only partially understood. However, its most central role is the encoding of the sequence of amino acids in proteins. Proteins are sequences of amino acids that, once formed, fold in complex three-dimensional structures to perform many different functions inside the cells. They can be thought of as very versatile nano-machines.
The knowledge that DNA encodes the proteins used to build cells, and therefore to build all living beings, opened the doors to enormous advances in our understanding of cells and biological systems. Since DNA (which stores, in each position, only one of four possible values) is used to encode the sequence of each protein, and there are twenty amino acids used by proteins, it was soon postulated that sets of three bases (at least) would be required to encode each amino acid. In fact, two nucleotides could encode only sixteen (42) different combinations and could not be used to encode each of the twenty amino acids used in proteins.
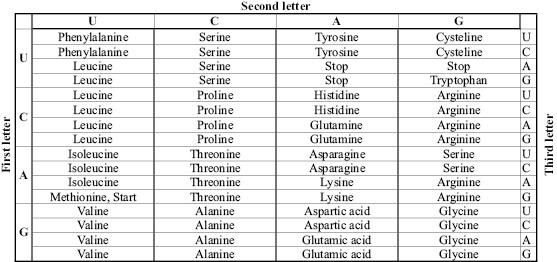
Additional experiments by a number of scientists led to the discovery of the genetic code, which specifies how each set of three DNA bases encodes a specific amino acid. Marshall Nirenberg and Philip Leder (1964), building on work done by Crick et al. (1961) which demonstrated that three bases of DNA code for one amino acid, deciphered the codons of the standard genetic code.
In figure 6.2, the entries marked “Start” and “Stop” signal the beginning and the end of each protein sequence, although we now know that, in reality, the process of translation from DNA to protein is significantly more complex, and other mechanisms may be used to initiate or terminate translation.
Figure 6.2 The standard genetic code. Each codon is composed of three bases and encodes one amino acid.
We now know that some organisms use slightly different genetic codes than the one shown in figure 6.2. Barrell, Bankier, and Drouin (1979) discovered that the constituents of human cells known as mitochondria use another genetic code. Other slight variants have been discovered since then, but the standard genetic code shown in figure 6.2 remains the reference, used in the majority of the cases.
With the discovery of the genetic code and the basic mechanisms that lead from DNA to protein and to cells, the complete understanding of a biological system becomes possible and, apparently, within reach. With time, it was indeed possible to identify structures in DNA, the genes, which encoded specific proteins, the molecular machines central to cellular behavior. However, in contrast with the cases Mendel studied, most genes do not have a direct effect on a visible trait of the organism. Instead, genes encode for a specific protein that will have many functions in the cells of the organism. Still, the understanding of the structure of the DNA, coupled with the development of many techniques dedicated to the study of cells, led to a much better understanding of cells. The quest to understand in a detailed and principled way how cells work was one of the most fascinating endeavors of the last four decades of the twentieth century, and it will certainly be one of the most interesting challenges of the twenty-first.
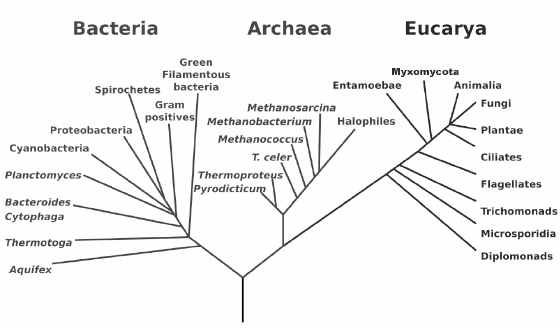
A cell is a highly complex machine, crafted by evolution over several billion years. All cells share common ancestors: single-cell organisms that were present at the origin of life roughly 4 billion years ago. One of these organisms must be the most recent common ancestor of all existing life forms. It is known by the affectionate name LUCA, standing for Last Universal Common Ancestor. LUCA is believed to have lived more than 3 billion years ago. We know, from the analysis of DNA sequences, that all the organisms in existence today, including bacteria, archaea, and eukarya (figure 6.3), evolved from this common ancestor.
Figure 6.3 A phylogenetic tree of life based on genomic data. Source: Woese 1990 (available at Wikimedia Commons).
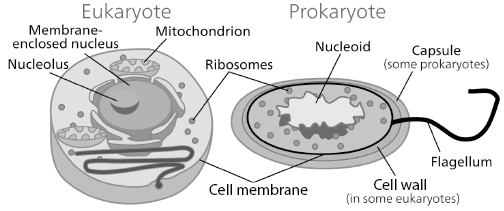
Bacteria and archaea are prokaryotes (simple single-celled organisms). They are very numerous and proliferate in almost any imaginable environment. All multi-cellular plants and animals, including humans, belong to the eukarya domain. They are eukaryotes, meaning they are built out of eukaryotic cells. Eukaryotic cells are estimated to have appeared sometime between 1.5 billion and 2.7 billion years ago (Knoll et al. 2006; Brocks et al. 1999), after several billion years of evolution of prokaryotic cells. Eukaryotic cells probably originated in a symbiotic arrangement between simpler prokaryotic cells that, in the end, became a single, more complex cell. We don’t know exactly how eukaryotic cells appeared, but they represent a major event in the development of complex life. In a prokaryotic cell the majority of the genetic material is contained in an irregularly shaped region called the nucleoid. The nucleoid is not surrounded by a nuclear membrane. The genome of prokaryotic organisms is generally a circular, double-stranded piece of DNA, of which multiple copies may exist.
Eukaryotic cells are more complex and are composed of a large number of internal membranes and structures, called organelles. A detailed description of the structure of a eukaryotic cell would require several large volumes. A number of excellent references exist that describe in more detail how cells work; one is Cooper and Hausman 2000. Here, I will give only a brief and simplified overview of the general architecture of eukaryotic cells, using figure 6.4 as an illustration.
Figure 6.4 Simplified views of eukaryotic and prokaryotic cells (NCBI 2007).
The most central structure in a eukaryotic cell is the nucleus, which contains the chromosomes and is surrounded by a membrane. Outside the nucleus, in the cytoplasm, are a number of structures that play different roles. Mitochondria are organelles involved in a number of tasks. They are mostly known as the cell’s power generators, because they generate the majority of the cell’s supply of chemical energy. It is believed that mitochondria were once separate organisms that were absorbed or otherwise incorporated in cells. They have their own separate, DNA, which, in humans is passed mostly along the feminine line. Ribosomes are complex molecular machines, with a mass equivalent to about 3 million hydrogen atoms, which synthesize proteins from messenger RNA in a process known as translation (described below). Most eukaryotic cells have a cytoskeleton, composed of microtubules and microfilaments, that plays an important role in defining the cell’s organization and shape.
Eukaryotic DNA is divided into several linear bundles called chromosomes. The process by which DNA is read and by which its instructions are translated into operating cell machinery, the so-called central dogma of biology, is now relatively well understood, although many aspects remain insufficiently clear. What follows is a simplified and somewhat schematic description of the way DNA code is turned into working proteins in a eukaryotic organism.
The process begins with transcription. During transcription, the information contained in a section of DNA in the nucleus is transferred to a newly created piece of messenger RNA (mRNA). A number of proteins are involved in this process, among them RNA polymerase (which reads the information contained in the DNA) and other auxiliary proteins, including the proteins known as transcription factors. Transcription factors are important because not all genes present in the DNA are transcribed at equal rates, and some may not be transcribed at all. The rate of transcription is controlled by the presence of the transcription factors, which can accelerate, reduce, or even stop the transcription of specific genes. This is one of the mechanisms that lead to cell differentiation. Cells with exactly the same DNA can behave differently in different tissues or at different instants in time. In eukaryote cells the primary messenger RNA transcript is often changed via splicing, a process in which some blocks of mRNA are cut out and the remaining blocks are spliced together to produce the final mRNA. This processed mRNA finds its way out of the nucleus through pores in the nuclear membrane and is transported into the cytoplasm, where it binds to a ribosome (the cell’s protein-making machine).
The ribosome reads the mRNA in groups of three bases, or codons, usually starting with an AUG codon. Each codon is translated into an amino acid, in accordance with the genetic code. Other molecular machines bring transfer RNAs (tRNAs) into the ribosome-mRNA complex, matching the codon in the mRNA to the anti-codon in the tRNA, thereby adding the correct amino acid to the protein. As more and more amino acids are linked into the growing chain, the protein begins to fold into the working three-dimensional conformation. This folding continues until the created protein is released from the ribosome as a folded protein. The folding process itself is quite complex and may require the cooperation of many so-called chaperone proteins.
Proteins perform their biological functions by folding into a specific spatial conformation, or conformations, imposed by the atom interactions. Interactions between atoms result from a number of phenomena that lead to attractive and repulsive forces. Hydrogen atoms, for instance, form H2 molecules by sharing electrons between them, and are kept together by what is called a covalent bond, as opposed to the non-covalent bonds that exist between atoms that don’t share electrons. Non-covalent bonds result from the electrostatic interactions between charged ions or polar molecules. Molecules of water are formed by one atom of oxygen and two atoms of hydrogen. The arrangement of the atoms in these molecules is such that one part of the molecule has a positive electrical charge while the other part has a negative charge. Such molecules, called polar molecules, interact with other polar molecules through electromagnetic forces.
The resulting set of forces that exists either between atoms of the protein or between these atoms and molecules in the environment (most commonly water molecules) imposes a structure on the proteins. Protein structure is an important topic of research in biology. Many techniques, including x-ray crystallography and nuclear magnetic resonance spectroscopy, are used to elucidate the structures of proteins. It is conventional to consider four levels of protein structure: primary, secondary, tertiary, and quaternary.
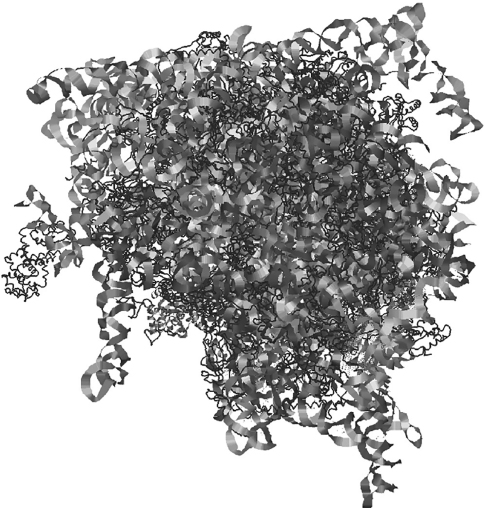
The primary structure of a protein is the linear sequence of amino acids in the amino acid chain. It is determined by the sequence of DNA that encodes the protein. The secondary structure refers to regular sub-structures in parts of the protein, which lead to specific geometrical arrangements of the amino acid chain. There are two main types of secondary structures: alpha helices and beta sheets (Pauling, Corey, and Branson 1951). Tertiary structure refers to the three-dimensional arrangement of protein molecules. Alpha helices and beta sheets are folded, together with the rest of the amino acid chain, into a compact structure that minimizes the overall energy of the molecule, in contact with the environment (usually either water or other proteins) that surrounds it. The folding is driven by a number of different atomic interactions, which include the positioning of hydrophobic residues away from water, but the structure is mostly defined by specific atom to atom interactions, such as non-covalent bonds, hydrogen bonds, and compact packing of side chains. Quaternary structure refers to the interaction between different proteins, and consists in determining the ways different proteins interact and dock with each other. Protein complexes range from fairly simple two-protein arrangements (dimers) to complexes with large numbers of sub-units. The ribosome complex illustrated in figure 6.5 is made up of dozens of proteins.
Figure 6.5 The structure of the human 80S ribosome (Anger et al. 2013), from the Protein Data Bank (Berman et al. 2000). Drawn using Jmol (Herraez 2006).
Many computational methods have been developed to determine, in a computer, the secondary, tertiary, and quaternary structures of proteins. The ability to determine the structures of a given protein is critical for the understanding of many biological phenomena and for the design of new drugs. Today it is possible to predict, in a computer, the spatial configurations of a protein, by considering both its similarity to other proteins and the overall energy of each configuration (Söding 2005; Roy, Kucukural, and Zhang 2010). There are a number of competitions in which different methods are tested and their accuracies are compared. One such competition, known as CASP (Critical Assessment of Structure Prediction), has taken place every two years since 1994.
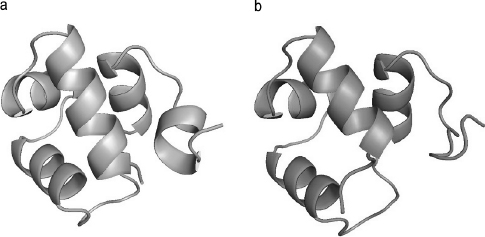
However, the problem remains largely unsolved when the protein under analysis is not similar, at least in part, to other known proteins, because the search for the right spatial configuration is, in this case, computationally demanding. Figure 6.6a shows a schematic view of the tertiary structure of the small protein 1R69p, which comprises only five short alpha helices (Mondragon et al. 1989). Even for such a small protein, it isn’t easy to determine its spatial configuration ab initio (that is, using only the primary sequence and not using information about its similarity with other known proteins). Figure 6.6b shows the result of an ab initio determination of tertiary structure of this protein by computational methods (Bugalho and Oliveira 2008) that obtains only an approximate result.
Figure 6.6 The tertiary structure of the protein 1R69p.
Many other processes, other than transcription and translation, go on inside a cell at any given moment. Some of these processes are reasonably well understood; others are still mostly unknown. Different biochemical processes regulate the flow of nutrients and wastes that enter and leave the cell, control the reproduction cycle, and make sure that adequate amounts of energy are available to enable the cell to operate. Because many processes inside a cell require energy, a significant fraction of the cell’s activities are dedicated to obtaining energy. A cell uses the chemical energy stored in adenosine 5´-triphosphate (ATP), generated mostly by the mitochondria, to drive many energetically unfavorable chemical reactions that must take place. In the glycolysis process, which is common to almost all cells, conversion of glucose into pyruvate results in a net gain of two molecules of ATP. This is why glucose, a type of sugar, is needed to drive biological processes in almost all living cells. This process and many other complex metabolic processes are reasonably well understood, and the conversion pathways are well documented (Cooper and Hausman 2000).
Most eukaryotic cells range in size from 2 to 100 µm (micrometers). This may seem small, but we must keep in mind that the radius of an atom of carbon is roughly 70 picometers, and the diameter of a ribosome is on the order of 0.3 nanometers. If a typical eukaryotic cell, with a diameter of 25 µm, were to be blown up to be a mile wide, a carbon atom would be about the size of a blueberry, and a ribosome would be only 6 feet wide. This means that there is enough space in one eukaryotic cell to contain hundreds or even thousands of ribosomes and millions of other cellular machines. Despite the enormous effort invested in understanding cellular behavior, our understanding of cellular mechanisms is still fragmentary and incomplete in all but the simpler processes.
The ultimate objective of biology is to understand not only the behavior of specific cellular processes but also the behavior of organs and even whole organisms. This is done, nowadays, using computers and algorithms to process and model the data obtained by experiments. Before I describe how computers and algorithms can be used to study and model biological systems, I must discuss why bodies and brains became essential for the survival of eukaryotic cells.
Bodies and Brains
Multi-cellular organisms have arisen independently a number of times, the first appearance probably beginning more than a billion years ago (Knoll et al. 2006). A major and sudden increase in the number of the most complex multi-cellular organisms, animals, occurred about 600 million years ago, before and during the Cambrian explosion, a period of dramatic changes in Earth’s environment (Grosberg and Strathmann 2007).
Multi-cellular organisms may arise either because cells fail to separate during division or because cells get stuck together accidentally. If natural selection favors this new form of life, it will survive and prosper. There are many possible advantages for multi-cellular organisms. Since there is always an ecological niche for larger organisms, evolution may favor larger species, which are necessarily multi-cellular. As organisms get larger, they have to develop specialized cell types in order to move toward the greater complexity required to sustain larger bodies.
Over time, the blind algorithmic process of evolution led to differentiated cell types and to increasingly complex multi-cellular organisms. Differentiated cells types led to different organs in complex animals, and ultimately to the development of an organ specialized in information processing: the brain. It is now becoming apparent that much of the complexity observed in multi-cellular organisms is due not to major innovations at the level of cellular machinery but, mainly, to gene regulation mechanisms, some of them post-transcriptional, that lead to cell differentiation and specialization. It may be somewhat disheartening to some people to think that their bodies are made of rather common cells—cells very similar to those of many other animals, and even somewhat similar to unicellular organisms such as baker’s yeast. In fact, humans have approximately the same number of genes as mice and rats, and have fewer genes than rice and some other species. It isn’t likely that there is any specialized set of genes used specifically to make the human brain. Not only do we have approximately the same number of genes as a mouse, but the genes are very similar. Even the humble fruit fly shares many genes with us. The genes that lay out the body plan are very similar in a fruit fly and in a human being, and were inherited from a distant common ancestor—some sort of flatworm that lived about 600 million years ago. The human brain probably is encoded by essentially the same genes that encode monkeys’ brains, with some small tweaks in gene regulation that lead to dramatically different brain characteristics.
From the point of view of the replicators, bodies are simply a convenient mechanism to ensure success in replication. Isolated cells, swimming alone in the seas, were too vulnerable to attacks from many sources. The multi-cellular organism, with highly specialized cells that share the same genetic material, was a convenient way to ensure that many cells were working toward the successful replication of the same genes. Over time, bodies became highly specialized, and brute force was no longer sufficient to ensure survival. The replicators, therefore, came up with a new trick. They mutated in order to encode and generate information-processing cells that could be used to sense the environment and anticipate the results of possible actions. These cells could transmit information at a distance and combine data from different sources to help in decisions. Some of these cells began transmitting information using electrical signals, which travel faster than biochemical signals and can be used in a more flexible way.
Many of the mechanisms needed to transmit electrical signals, and to modulate them through chemical signals, have been found in single-celled organisms known as choanoflagellates, which are the closest living relatives of the animals. A choanoflagellate is an organism that belongs to a group of unicellular flagellate eukaryotes with an ovoid or spherical cell body and a single flagellum. The movement of the flagellum propels a free-swimming choanoflagellate through the water.
Choanoflagellates are believed to have separated from the evolutionary line that led to humans about 900 million years ago (Dawkins 2010), and so the mechanisms to transmit electrical signals, if they have the same origin (a likely hypothesis), arose no later than that. Somewhere around that time, cells developed the potential to communicate with other cells by using electrical pulses as well as the chemical signals that were used until then.
With time, neurons—cells able to generate electric impulses—evolved long extensions, which we call axons, to carry electrical signals over long distances. Neurons transmit these signals on to other neurons by releasing chemicals. They do so only at synapses, where they meet other neurons (or muscle cells). The ability to convey messages using electric signals (instead of only chemical signals) gave the early organisms that possessed these cells a competitive edge. They could react more rapidly to threats and could find food more efficiently. Even a few neurons would have been useful in the fight for survival in the early seas.
Distinguishing light from darkness or having the ability to hear noises is useful; however, being able to sense the outside world, and being able to anticipate the results of specific actions without having to perform those actions, are tricks even more useful for survival. A more sophisticated brain enables an organism to choose the best of several possible actions without running the risk of trying them all, by simply estimating the probability of success of each action. Different connections of neurons, defined by different genetic configurations, evolved to combine information in different ways, some more useful than others, and led some animals to safer or less safe behaviors. The most useful neuron structures proliferated, since they gave their owners a competitive edge, and this information-processing apparatus became progressively more sophisticated as millions of generations went by. What started as simple information-processing equipment that could tell light from darkness, or sound from silence, evolved into complex information-processing circuits that could recognize the presence of enemies or prey at a distance, and could control the behavior of their owner accordingly.
The first neurons were probably dispersed across the bodies of early animals. But as neuron complexes became increasing sophisticated, neurons began to group together, forming the beginnings of a central nervous system. Proximity of neurons meant that more sophisticated information processing could take place rapidly—especially where it was most needed: near the mouth and the light-sensing devices (which would later become eyes). Although it isn’t yet clear when or how many times primitive brains developed, brain-like structures were present in the ancient fish-like creatures that were ancestors of the vertebrates. The “arms race” that ensued as more and more sophisticated information-processing devices were developed led to many of the structures that are found in the human brain today, including the basal ganglia (which control patterns of movements) and the optic tectum (which is involved in the tracking of moving objects). Ultimately, as a direct result of evolutionary pressure, this “arms race” led to more and more intelligent brains. “Intelligence,” Darwin wrote in On the Origin of Species, “is based on how efficient a species became at doing the things they need to survive.”
About 200 million years ago, the descendants of the early vertebrates moved onto land and evolved further. One of the evolutionary branches eventually led to the mammals. Early mammals had a small neocortex, a part of the brain responsible for the complexity and flexibility of mammalian behavior. The brain size of mammals increased as they struggled to contend with the dinosaurs. Increases in brain size enabled mammals to improve their senses of smell, vision, and touch. Some of the mammals that survived the extinction of the dinosaurs took to the trees; they were the ancestors of the primates. Good eyesight, which helped them in that complex environment, led to an expansion of the visual part of the neocortex. Primates also developed bigger and more complex brains that enabled them to integrate and process the information reaching them and to plan and control their actions on the basis of that information.
The apes that lived some 14 million years ago in Africa were, therefore, smart, but probably not much smarter than their non-human descendants—orangutans, gorillas, and chimpanzees. Humans, however, evolved rapidly and in a different way. We don’t know exactly what led to the fast development of the human brain, which began around 2.8 million years ago with the appearance of Homo habilis in Africa. It is likely that some mutation, or some small set of mutations, led to a growth of the brain that made the various species of the genus Homo smart enough to use technology and to develop language. The most salient development that occurred between earlier species and members of the genus Homo was the increase in cranial capacity from about 450 cubic centimeters in preceding species to 600 cubic centimeters in Homo habilis (Dawkins 2010).
Within the genus Homo, cranial capacity again doubled from Homo habilis to Homo heidelbergensis roughly 600,000 years ago, leading to a brain size comparable to that of Homo sapiens—roughly 1,200 cubic centimeters. Many different species of Homo have co-existed in the intervening millennia, including Homo neanderthalensis, which went extinct roughly 40,000 years ago (Higham et al. 2014), and Homo floresiensis, which lasted until about 12,000 years ago (Harari 2014).
By what may happen to be a historical coincidence, we humans have been, for twelve millennia, the only representatives of the genus Homo on Earth—a situation that may well be singular since the appearance of the genus nearly 3 million years ago. Homo sapiens’ unique abilities to organize in large societies and to change its environment probably have been more responsible for this unique situation than any other factor (Harari 2014).
All the developments mentioned above led to the modern human brain, the most complex information-processing machine known to us. The modern human brain appeared in Africa about 200,000 years ago with the rise of Homo sapiens. Understanding how such a brain works is one of the most interesting challenges ever posed to science. But before we address this challenge, we must take a detour to survey the role computers have played in our understanding of complex biological systems and how computers can be used to model the human brain.