The radical, young, and dynamic sport of mixed martial arts has seen an incredible boom in popularity over the last few decades, rivaling classical combat sports such as boxing. There have even been recent attempts to feature star athletes from both MMA and boxing in head-to-head competition to determine the relative athleticism of both sports. Regardless of the outcomes and subsequent conclusions derived about the superiority of either sport or its athletes in such attempts, it is clear to most that in a real combat scenario – one free of gloves, a ring, and a referee – the probabilistic advantage would lie with the athlete who can more readily respond to a wider variety of attacks.
Bruce Lee, a famous martial artist and Hollywood film star, has at different times been attributed the title of the “Father of Mixed Martial Arts.” He founded a methodology, or paradigm, known as “Jeet Kune Do,” or “The Way of the Intercepting Fist,” in 1967 that sought to do away with the stringent nature of traditional martial arts styles and patterns. He vehemently rejected this paradigm being classified as “his own style” as, in his mind, it was really the absence of style. He believed that the classical styles were too rigid and unrealistic in real combat and that by combining the strengths of different styles and removing any unnecessary movements from them, a martial artist would be free to react to the spontaneity of combat in an efficient manner. Alternatively, if an athlete were to stick to only a single paradigm, for example, Fujian White Crane or Black Tiger Fist, they may be bound by the patterns they know and are familiar with, which might leave them vulnerable to the known exploitations of that style.
In a similar vein of thought, it has been said that “When all you have is a hammer, everything looks like a nail.” Meaning that if you are only familiar with a single paradigm, you may inadvertently apply it to everything with a confirmation bias that deems it correct even if there is a better way. It is thus an easy leap in logic to suggest that at least being familiar with multiple paradigms is important in assessing a wide variety potential solutions to problems. Said another way, if you have multiple tools in your tool belt, you will be best equipped to know which tool to use for each problem. When assessing software engineering paradigms, it’s imperative to remember to use the best tool for the job.
The three main programming paradigms in software engineering include procedural programming, object-oriented programming, and functional programming. All three paradigms have their strengths and weaknesses, along with their fanatical zealots who will blindly defend them to their retirement. However, it is important to understand them all to form a personal understanding for when they are best used and which you prefer when tackling a particular engineering problem.
The main reason Scala is used in this book is to be able to demonstrate multiple paradigms in a single language. Hopefully by learning each paradigm in Scala, you will be best equipped to draw from the strengths of each while sloughing the unnecessary from your repertoire. If, by the end of this chapter, you decide to subscribe to a multi-paradigm approach to software engineering, it would not be incorrect to classify yourself as a disciple of Jeet Kune Do – the style free of styles.
Procedural Programming
A demonstration of structured procedural programming
You’ll notice the two functions in this listing are almost identical, but one is labeled with a comment suggesting that it is structured and the other is not. So what is the difference? In the structured version of this function, there is only one logical branch in which this function can terminate. Each of the branches is mutually exclusive – there will always be a single entry point and a single exit point. Because of this, coupled with the capability of functions in Scala to imply the return value based on the last line in a function, the return keyword can be eliminated from the structured function. However, the unstructured function does not have an exclusive path that could be executed – each of the if statements could evaluate to false and it will kick out of those branches which requires it to return a fallback or default value outside of a conditional branch. Thus, the non-structured function must explicitly provide a return statement for each condition. It’s worthy to note that the non-structured style of this particular function is typically more popular in practice; however, it is logically less structured in a strict and disciplined sense of programming.
Thus far, most of the programming you’ve seen in this book would be considered procedural programming, especially any programs that were written as scripts or directly in the REPL. The benefit of writing in a procedural fashion is that it is often very easy to follow and clear to read. Thinking of things in chronological sequences tends to be more natural and intuitive, which is why most introductory programming examples are written in a procedural style. Keeping programs simple and intuitive enables long-term maintainability and collaboration among peers. Procedural programs also tend to be really lightweight programs with less compile time and runtime overhead simply due to the nature of what you can do procedurally. A common theme among procedural programmers is to create a program that only does one thing and does it really well, which coincides directly with the concept of modularity. Also, because of its simplicity, procedural programming often requires less coordination regarding overall architecture and integration with other programs. This makes debugging a procedural program much easier since you can step through each line of a program individually to determine the source of any problems without dealing with a spiderweb of dependencies or non-intuitive branching.
That being said, in order to do anything interesting with a procedural program, it often requires the mutation of application state. Application state is the value of all variables at different times throughout the runtime execution of a particular program. Many procedural programs will initialize variables at the beginning of the program and then change them as the program moves from one line to the next as needed. If the procedural program were to crash during runtime and needed to be started over, the application state would be set back to its initialized state rather than the state that was changed or mutated throughout the course of its previous execution.
A good example of application state is demonstrated in our Nebula OS script. At the beginning of our program, after we print out our welcome message, we initialize the variable command to an empty string. Then we execute a continuous loop that takes in user input, mutates the command variable, and performs a pattern matching action based on the new application state. If we shut down our Nebula shell and start it over, we now have an application state wherein command is set back to an empty string.
As procedural programs grow in size and complexity, it becomes difficult to hold application state in a global context, meaning all the variables are accessible in the same global namespace. Eventually you might run into a place where you want two variables of the same name to have different contexts. This is called a namespace collision. When running into namespace collisions, you will often see developers unintentionally updating the application state of a variable that they were not aware existed somewhere else in the procedure. Then, later on in the program when the program tries to access the state of the unintentionally mutated variable, the procedure will run into runtime semantic errors. This is the danger of mutation. Both the object-oriented programming and functional programming paradigms attempt to remedy this danger through encapsulation and “pure” functions, respectively. It is worthy to note that larger, more complex programs that primarily use object-oriented or functional styles can still have aspects of procedural programming laced throughout them. If you encounter a program that seems unnecessarily complex, consider how you might be able to safely refactor a piece of it into a simple, linear procedure.
Object-Oriented Programming
Java, the language for which the JVM was developed, is a pure object-oriented programming language that was created by Sun Microsystems in 1995. Object-oriented programming is a paradigm whose primary purpose is to provide a strategy to deal with complexity, as opposed to procedural programming which requires simplicity. In the object-oriented paradigm, all aspects of a program use classes defined to instantiate objects. Nothing in traditional object-oriented programming, including programs written in Java, can exist outside of some form of object. As you know, objects create encapsulations that guard protected variables and provide a namespace for public variables which directly combats namespace collisions. However, object-oriented programming takes the capabilities of classes further by introducing the concepts of inheritance, polymorphism, interfaces, and abstract classes. To understand the benefits of object-oriented programming, we must dive into the details of each of these topics individually.
Inheritance
Prior to object-oriented programming, when executing a method on a data type, the programmer would be forced to write an exhaustive pattern matching statement to determine what type the method was being applied to and then perform the specific implementation of that type’s method. For example, if the developer were trying to call a “print” method, they must first check the data type that “print” was being applied to and call the specific implementation of print. That print implementation might be the same for an integer or a double but might be different for a string. As more data types and methods were added to a program, the dependency complexity for this type of exhaustive checking became exponential, leading to unscalable maintainability problems.
In object-oriented programming, in order to tackle this complexity, it was determined that each data type should define the possible methods that can be applied to it within the object itself. This reduced the complexity dramatically as all methods are encapsulated within a single module of code. The downside to this methodology was that each new data type required the developer to re-implement every single method, which violated the DRY principle in scenarios where two data types might share the same implementation of a method. To combat this, object-oriented programming includes the notion of inheritance.
Demonstration of inheritance
You’ll notice in this example that the extends keyword defines the inheritance relationship between the Knife class and the Sword class. You’ve seen an example of this inheritance relationship before by using the extends App syntax to inherit the default entry point functionality of the App class. In this example, the Knife class does not need to define the length property, the attackDamage property, or the attack method but has access to all three. However, the Knife class in this example provides its own parameter list that allows it to override the constructor of the superclass (the Sword class) to set its own length and attackDamage property defaults and allows the user to set separate values for the Knife if desired using the override keyword preceding the parameter declarations. If these values are not presented at the time of instantiation, they will default to 3 and 2 for a Knife and 10 and 5 for a Sword. If you do not provide a parameter list for the child or sub-class when defining the sub-class, (the Knife class in this example), it will always inherit the default properties of the Sword, 10 and 5.
Refactor Knife class to add additional functionality that the Sword class does not have
If you wish, you can also override methods from a superclass by simply preceding the definition of the method with the override keyword. This is particularly useful when you want to inherit several methods from a parent class but need to change just one or two of them. When you find yourself overriding everything about a parent class, you may realize that it would be better to simply rewrite a new class from scratch rather than extend anything at all (and perhaps what you really want is an interface which will be covered later in this section). Hopefully, given this demonstration of inheritance, you can see how object-oriented programming allows for productive, non-repeating code.
Polymorphism
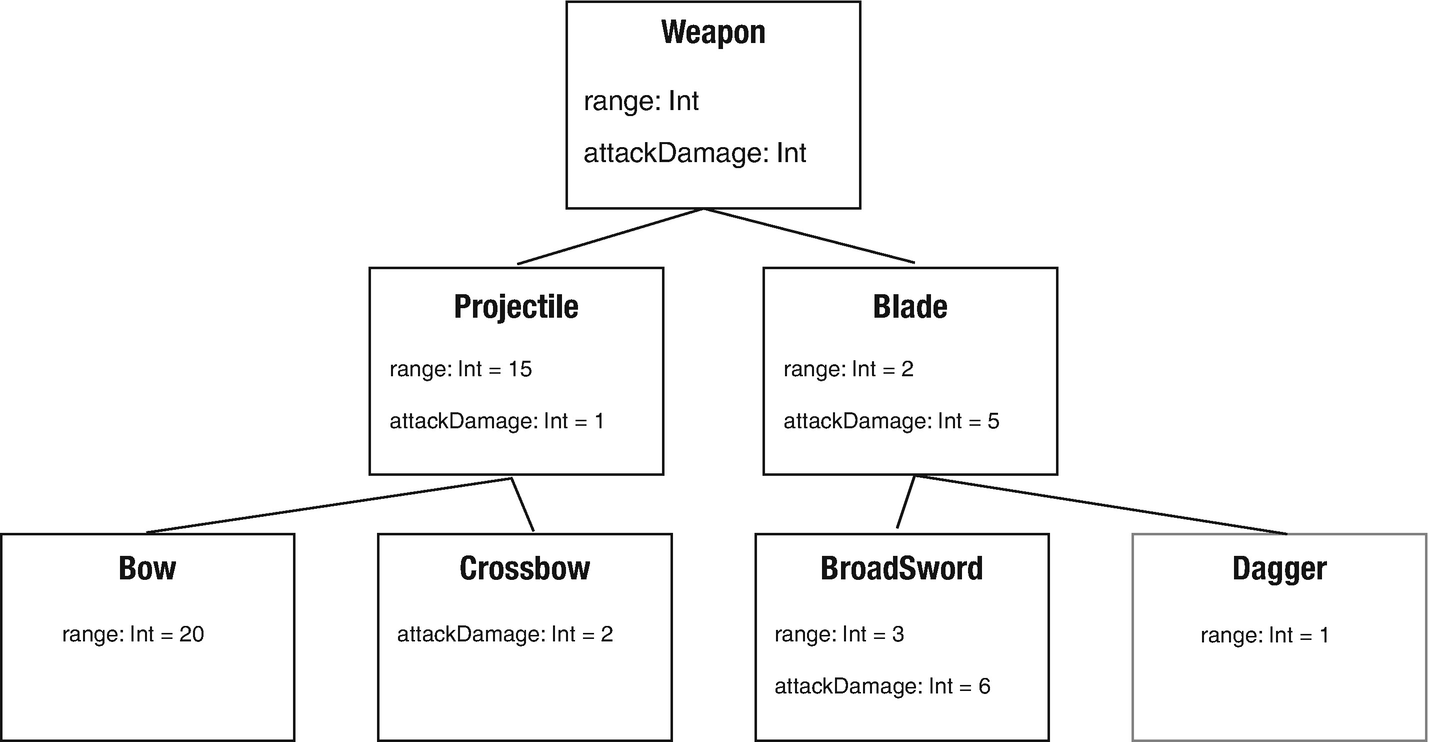
Demonstration of a polymorphic inheritance model wherein each class inherits the properties and methods of its parent or superclass with its own overridden defaults where necessary
Now that you have all of these defined, let’s assume you want to create a property on your Fighter class to allow you to give the fighter a weapon. Since all of these Weapon types are now available and they have been written in such a way so that you don’t have to repeat any code, how can you add a property with a defined type to your Fighter class? You might assume that you have to explicitly provide a specific type upfront, therefore limiting the Fighter class to only one weapon type. Your intuition might lead you to believe that you should create a class for each fighter depending on what type of Weapon you want them to have and have those classes inherit from the base Fighter class. These new classes might be called something like SwordFighter, KnifeFighter, CrossbowFighter, Archer, etc. The SwordFighter class might have a constructor method like SwordFighter(var weapon: BroadSword, var hp: Int = 20). However, polymorphism provides you a mechanism that prevents you from having to do this.
Demonstration of polymorphic inheritance by providing a Weapon type as a property to the Fighter class and then assigning sub-classes to that property during instantiation
- 1)
The Fighter class has been given a property weapon that has a type of Weapon.
- 2)
The Fighter class has been given an attack method that wraps the attack method from whichever Weapon was provided to the fighter during instantiation.
- 3)
There is a main scala class that extends App as an entry point to our program so we can run it and demonstrate how these scala classes can interact with one another.
Note
In scenarios where you have created a lot of new Scala classes that all need to be compiled, you can compile them using the command scalac *.scala.
This command utilizes the asterisk character which the compiler will treat like a wildcard. The compiler will search for every file with a .scala extension in the current directory and compile them all which prevents you from having to type out each class name individually.
Remember to compile your code, then type scala CombatGame.run (which is a reference to the run.scala class that was defined to extend the App object) to run the main application. The main program will create two new fighters, Thief and Knight, and assign them weapons upon their construction, a Dagger and a BroadSword respectively. Next, we call the attack method for both Fighters and pass their opponent to the method. Finally, we print their hp property (the number of hit points the fighter has left which is defaulted to 20 in the Fighter class constructor) to see how they have been impacted by the attacks. The println method will print out (14,15) to show that the Thief has 14 hit points left and the Knight has 15 hit points left. This is because the BroadSword deals 6 damage, since it overrides the default Blade damage of 5, and the Dagger only deals 5, since it inherits its damage dealt directly from the Blade class.
The key takeaway from this example is that you did not need to provide a specific Weapon type to the Fighter class constructor. By giving it the generic Weapon type, the fighter can take any weapon that extends the Weapon class. Thus the fighter can wield a weapon “in many forms.” As you can see, polymorphism, in addition to inheritance, also prevents you from having to repeat code throughout your project leading to massive productivity gains.
Interfaces and Abstract Classes
You might notice from the example in the previous section that the Weapon class and its corresponding sub-categorization classes, Blade and Projectile, can also be instantiated and passed to the Fighter class. From a software design perspective, this doesn’t make a lot of sense since those classes were simply designed as a method of categorizing like functionality. Interfaces and abstract classes allow for defining classes like these categorization classes that can be created for architectural design without allowing them to be instantiated.
Adding the abstract keyword in front of a class prevents it from being instantiated
Illustration of an abstract method
Notice that the attack method in the Weapon abstract class does not contain a body with implementation details and the Blade class implements it instead. If the Blade class did not implement the attack method and you tried to compile this project, the compiler would fail and provide an error suggesting that the Dagger and BroadSword classes need to be abstract since they don’t implement the attack method either. If you did make those two classes abstract, then you would not be able to instantiate them and the run Scala object would fail. Hence, when extending abstract classes it is important to ensure that all abstract methods are implemented by the sub-classes.
It might not be overly intuitive as to why you would use abstract methods. However, it might become clearer when trying to create design specifications for a large project that you are trying to architect but not necessarily implement all by yourself. You could create abstract classes with several abstract methods, therefore defining a contract between collaborating developers that must be fulfilled in order to extend your class. By defining that contract, the compiler guarantees that any class that extends your abstract class, and therefore can be categorized as your generic polymorphic type, has all of the methods that you deem necessary for your software architecture.
Using a Scala trait as an interface
Syntax for a class implementing multiple traits
Traits in Scala are an example of the interface paradigm that is common in object-oriented programming. Interestingly, they have additional functionality in Scala that is not present in other languages. Traits in Scala can also be extended by static objects or added to an instance of an object at its instantiation. Because of this, traits don’t comply with the strict definition of an object-oriented interface. They can provide static blocks of code that exist outside of methods and properties that will be executed whenever the extending object is instantiated. This falls outside of the scope of the object-oriented programming pattern but is a worthy topic for further investigation if you find yourself needing such functionality.
Exercise 10-1
Implement the left branch of the Weapon inheritance tree model represented in Figure 10-1. Use an abstract class for the Projectile class that extends the Weapon Trait.
Try implementing class-specific functionality for the Crossbow and Bow classes.
As you can see, object-oriented programming allows for organizational and architectural design patterns to wrangle the complexity of large code bases. It provides a good method for classifying the real world around us using interfaces and abstract classes that can be extended. Its polymorphism enables a rich customizable type system that gives you the capability to add generic types to your class properties and static variables all while providing strategies to minimize code duplication.
However, there are typically two disadvantages associated with object-oriented programming. The first is that it is often known to be overly verbose. As you could tell in the examples in this section, it took a lot of different files to demonstrate the functionality (and these were very basic examples). The second is that it requires a lot of upfront planning and very thoughtful architectural considerations. When deciding whether or not to use object-oriented programming, consider the size and complexity of the project and weigh that against the opportunity cost of upfront planning and extra code that needs to be written. You will find that for smaller projects, the time savings may often favor procedural programming. However, a good compromise between the two paradigms might be the functional programming paradigm, if you feel comfortable with its style.
Functional Programming
Haskell, Clojure, and early forms of JavaScript are great examples of common languages which follow the functional programming paradigm. It could be said that these languages aim to provide a solution to complexity, much like object-oriented languages, but in a concise and less error-prone way. After all, Steve Jobs once said at a visiting lecture at MIT that the easiest code to maintain and debug is the code you don’t have to write. So how, then, does functional programming tackle complexity without adding more code to write? The early pioneers of functional programming turned to math to answer that question.
Functional programming is a paradigm whose roots date back to the concepts of lambda calculus in the 1930s. In this paradigm, the entire program is written as a series of inputs and outputs to mathematical functions, and all variables and data structures are immutable by nature. By approaching programming in this way, entire applications can be written in mathematical-like expressions, similar to what you were introduced to in the expressions chapter. If you can recall back to that chapter, there was not yet any notion of state that could be mutated, simply expressions that evaluated to an explicit result.
Expanding upon the thought of immutability, the main objective of functional programming is to minimize (or eliminate entirely) “side effects.” A “side effect,” in programming, is an action that mutates the existing state of the application, whether that be changing a variable or a piece of a data structure stored in memory. The motivation behind removing side effects is to eliminate errors in your code. If, for example, multiple functions within a code base are accessing a global variable and one of those functions mutates the variable without the other function knowing about the change, it could create some runtime semantic errors. This is especially true for multi-threaded or parallel process applications which could be touching the application state in an unpredictable order. In these types of applications, their processes are essentially racing to the variables in order to obtain their values before the other process has a chance to mutate it. This is known as a “race condition” and is extremely vulnerable to errors in your code. Functional programming combats race conditions through the use of “pure functions.”
A function is said to be a “pure function” if, and only if, it takes in inputs and returns an output without mutating application state in the process. Pure functions are guaranteed to always return the same result for the same inputs. This is known as referential transparency. As a counterexample of a pure function, in Listing 10-7 in the previous section, refer to the attack method of the Blade class. That method takes a Fighter as an input and then directly mutates the state of that fighter’s hit points by reducing that property’s value by the number represented by the weapon’s attackDamage property. The act of changing the hit points within the function is the side effect.
- 1.
Does your program have functions which take no input parameters?
- 2.
Does your program have functions with no return type?
- 3.
Does your program explicitly import mutable data structures?
- 4.
Do you find yourself using a lot of variables defined with the var assignment keyword rather than val assignment keyword?
Representation of duplicating an object rather than mutating it in the functional programming paradigm
As you can see in this example, rather than directly accessing and changing the hp property of the opponent parameter in this attack function, we instead instantiate a new Fighter object, passing in the existing weapon as a parameter to the new object’s constructor as well as the existing hp minus the amount of damage that you would like to apply. This guarantees that the Fighter that was passed into the function does not have any side effects applied to it but still allows the developer who calls this function to have access to a Fighter whose hit points have been reduced by the appropriate damage. That developer may assign the return object to a variable that used to hold the previous fighter object, thus mutating state which violates the pure functional nature of the application, but at least this function is now considered a pure function.
It is worthy to note that sometimes writing a completely functional program in Scala or any other functional language can sometimes be really difficult to accomplish. Oftentimes you will notice that applications written in functional languages tend to be written almost entirely of pure functions at its core with minor side effects sprinkled at the fringes of the program – often to read or write data to and from files and/or databases or to print messages to the user via the user interface. You will also find that there are some use cases that simply require mutable variables or data structures. This tends to be acceptable if they are limited to a very controlled scope within a function that only your function can access and mutate. As long as your function maintains referential transparency, it is okay to occasionally use mutable variables and data structures. However, as you are starting out with functional programming, try to not use them at all so that you can get used to the pattern.
Higher-Order Functions
One of the benefits of writing applications in the functional programming style is that it affords you the opportunity to write extremely rich expressions. By doing so, oftentimes you will see functional programs that lack any procedural style whatsoever. What that means is that you will not see any for loops, very few conditional branches, and few if any try/catch blocks or null handlers. In order to accomplish the same things as procedural programming through expressions, the functional paradigm turns to higher-order functions.
A higher-order function repeat that takes a function to be repeated as one of its inputs
This repeat function actually demonstrates two useful principles of functional programming. First, notice that it takes a second set of parameters: the function to be repeated. You use this higher-order function by calling repeat with the parameter for n, representing the number of times you want the function to repeat, followed by curly braces and then the function that you want to call. The second thing to notice in this higher-order function is that it calls itself. In the implementation details for this function, you will notice that it has a second parameter (iter) in the first set of parentheses that we did not pass an argument for since it has a default value of zero. However, in the body of the function, the code checks to see if the iter value is less than the number of times we are meant to repeat the function. If it is less, it calls the function (func) and then calls itself, but it increments the iter parameter this time. This will cause the function to continue calling itself until the if condition becomes false. This if condition can be seen as the same type of conditional check as when terminating loops. Functions that call themselves are called recursive functions, and they are a common strategy in functional programming to eliminate the need to use loops. However, just like in a while loop, you must be careful to ensure that you have a base case condition that will eventually be satisfied to terminate the recursive calls or you will crash your program by trapping it in an infinite call stack of functions.
Writing higher-order functions can be somewhat mind-bending at times. Fortunately, most functional languages, Scala included, have a lot of really handy higher-order functions built into common data structures by default (mostly iterable data structures). These will be really useful to memorize to make your code more concise and eliminate the possibility for mutable errors. I recommend using them in your code even if you ultimately end up favoring a primarily object-oriented or procedural paradigm. Let’s dive into each of them in detail.
Foreach
An example of the foreach higher-order function
In this example, we first define a collection of data: a list of MMA fighters. Next we define a function that can be passed to the higher-order foreach function. Then we call foreach on the data collection using simple dot notation. Each of these four methods of calling the foreach function results in the same action, each fighter’s name being printed to the screen. However, each implementation is markedly different in its explicitness.
The first call passes a function that we have previously defined to the foreach function. The foreach will implicitly provide each individual iteration of its data as an argument to its fighter: String parameter. Then that parameter is passed to the println function. Alternatively, we could pass that data implicitly to the println function directly as demonstrated with the second call to foreach. In the third call to foreach, we provide it with what is called an anonymous function. An anonymous function is a function that does not use the def keyword and does not provide the function with a name for later use (hence anonymous). To create an anonymous function, you can provide a list of arguments in parentheses just as if you were creating a normal function (but without the def keyword or the name of the function) and then you let Scala know that you are creating an anonymous function by following the parentheses with an arrow operator, which is the equal sign followed by the greater than sign. After the arrow operator, you provide a function scope just as you would a normal function. The last call to foreach also uses an anonymous function but with shorthand syntax. If you do not need more than one parameter and you do not need more than one line of the function body, you can leave off the parentheses and the curly braces, and Scala will understand implicitly that you are still defining an anonymous function. Each of the remaining higher-order functions will use anonymous functions in any of these same formats.
Map
Demonstration of a map higher-order function
As you can see, the map function returns a new collection and stores it in the formattedData variable. The map function is passed an anonymous function as its input. That anonymous function takes one parameter, fighter, which represents each individual fighter in the list of fighters. Each fighter is transformed with a toUpperCase function and then added to the formattedData collection. Finally, we print out the formattedData variable to see the new collection transformed to have the fighters’ names formatted with all uppercase letters.
FlatMap
Demonstration of a FlatMap higher-order function
In this example, the flatMap takes in each item of each sub-list and returns it in a single flat list. The anonymous function takes in a single parameter, item, which represents each individual item of each sub-list. That item is then simply returned to the flat list contained in the variable flattenedData. We could have done any other transform we wanted to the individual item from the sub-lists; however, in this particular example, we are just returning it unaltered just to demonstrate that it comes back in a flattened state, which you can see in the final step where the flattenedData variable is printed to the terminal.
Filter
A demonstration of a Filter higher-order function
As you can see from the final println function, the resulting filteredData collection contains all of the fighters from the original list except Ronda Rousey, whose competition weight, at 134, is less than the condition 140 that evaluates and returned a Boolean. In this example, since we did not define any types for our sub-lists and they contain mixed types, Scala implies that they are lists that contain Any types. Because of this, when evaluating the condition, we first pull out the index position from the list, (1) which is the second item in the list, and then cast it to an integer so that it can be correctly compared to the integer 140.
Find
A demonstration of a Find higher-order function
As you can see in this example, the anonymous function defines a single parameter item that represents each item in the list. Each individual item is simply the sub-list at each index position. In order to access the name of the MMA fighter within the sub-list, we access the first index position (0) of the item that is currently being iterated on. Then, because it is an Any type, we cast it to a string in order to have access to the contains method. Then we check to see if the name contains the word “Chuck.” There are two sub-lists in our data list that contain the word “Chuck” in their first index position. However, since “Chuck Norris” is encountered first, that item is the only item returned to the final findData list, as you can see from result of the println function.
Reduce
A demonstration of a Reduce higher-order function
In this example, we are looking to find the total weight of all of the fighters in our data collection. To do that, first we map over the original collection and pull out just their weights by accessing the second index position (1) for each item (sub-list). After that map function is completed, we can chain on the reduce function. We can do this because we know that the expression data.map is evaluated to a new List that can also take higher-order functions. The reduce function in this example simply takes wildcards (_ + _) that suggest that whatever the two parameters that are being passed to it are, simply add them together and return their result. This can be written out in long form like so: (a, b) => a + b. Once we have reduced the weight data and print it out, you can see that it is the sum of all the weights with a value of 650.
Fold
A demonstration of a Fold higher-order function
This fold function is seeded with the value 100. Thus, 100 is passed as the value to the first parameter in the anonymous function and the second value is populated with the first value from the collection. The value returned by that first operation (100 plus the first weight in the collection, 141, which equates to 241) is then passed back to the anonymous function as the first parameter value and the second parameter value is populated with the second item in the collection. You can see from the final result of the print function that by seeding this fold higher-order function with a value of 100, the result is 100 more than the result of the reduce higher-order function from the last section.
Zip
A demonstration of a Zip function
Putting It All Together
An example of how functional programming can chain together higher-order functions to create rich expression. This example takes two lists and returns a single string that contains the names and weights of fighters whose names contain the string “Chuck”
This example takes two lists, names and weights, and zips them together. Next it filters the resulting list by items whose first tuple value contains the string “Chuck.” If we simplify the expression up to this point, we know that we should have a list of tuples that is of length two that contains the names and weights of both of the “Chuck” fighters. Next, we map over this new List and convert our tuples to Lists so that we can perform a flat map on them. After the flatMap, we should now have a flat collection of Any values that contains names and weights. Finally, we call a reduce function that constructs a single string with a space delimiter between values in our flat list. The resulting variable if this chained expression, data, then contains a single string, which when printed returns “Chuck Norris 170 Chuck Liddell 205” to the terminal.
Exercise 10-2
Go back to our Nebula OS model command-line shell and try to refactor any procedural code with functional code. If you open up the Utilities.scala file, the showTextFiles() and list() methods use procedural iteration that could be changed to higher-order functions.
As you might have gathered, it is often the goal of many in the functional programming paradigm to represent all aspects of the program in terms of mathematical formulas or expressions. While this creates safe and concise code, there are cases where it can become confusing and hard to follow. If you find an expression that is too long and hard to understand, try breaking it into smaller pieces and perhaps refactoring into a procedural style for parts of the program.
Summary
In this chapter, you learned about the three major programming paradigms: procedural programming, object-oriented programming, and functional programming. In procedural programming, you learned that the goal is to do one simple thing and to do it really well in an easy-to-follow linear format. In object-oriented programming, you learned how to tackle complexity with upfront planning and simulating the problem you are trying to tackle using objects that can inherit, take many forms, and be represented in an abstract way. In functional programming, you learned how to tackle complex problem sets using a series of chainable expressions with no side effects to eliminate the possibility of semantic errors in your code. This paradigm proved to be less verbose than its counterparts.
While each of these programming paradigms represented their own strengths and weaknesses, it is important that you understand that no single paradigm can be considered a silver bullet. When choosing a paradigm, ensure that you are using the right tool for the job rather than the paradigm you like the most or are most familiar with. Channel your inner Bruce Lee and find the strengths in each paradigm while minimizing their weaknesses. Finally, and probably most importantly, ensure that you are open-minded to other paradigms. Paradigm tolerance tends to be a hard thing to come by among software developers. Many choose a paradigm and never grow or adapt beyond it. The best software engineers are those who can see the advantages of each paradigm and can identify the best time to use each. It is worthy to note, also, that many languages are starting to fuse these paradigms together, so knowing them all will give you a leg up if you begin to learn those languages. Knowing all the paradigms and how to use them in Scala may also help you to convince your colleagues that they should be using Scala for all of their projects since they can accomplish all paradigms using this one powerfully flexible language.