CHAPTER 5
Knowledge
or “I Need to Know”
I came to academia late—I didn’t even get my B.A. until I was well into my thirties—but I had known Ian Cross’s name many years before we first met, principally from two important books he co-edited on musical structure and from articles on the cognitive representations of musical form. The field of music cognition is relatively small; there are probably only two hundred and fifty people in the world who would consider it their specialty. Contrast this with a field like neuroscience, which draws 30,000 attendees to its annual conference in the United States alone. Most university psychology and music departments don’t have anyone doing music cognition, and those that do rarely have more than one. This makes the annual meetings of the three main societies (the North American, the European, and the Pan-Asian) a big deal—it is an opportunity for people in the field to meet and learn about the latest findings, to resolve scientific controversies, and to schmooze.
In graduate school I completed some new work on absolute pitch, and I presented it at the European conference one year to get feedback on it before sending it out for publication. Research scientists are famously intolerant of logical arguments or experimental designs that are flawed, or young researchers who make claims that are not fully supported by the data. This is trial by fire for a student, but there is no better training. Attendees may shoot your work full of holes, but in the end if you are able to plug up the holes, the paper becomes stronger. As my doctoral advisor, Mike Posner, counseled me, it’s better to know before the paper is published if there are any flaws; printing retractions is embarrassing and career-stopping.
On the first morning of the conference I came down for breakfast and sat at a large round Formica table with some other students whom I had met on the bus ride in—two of them were Ian’s students. They were a friendly bunch, curious to know about my background and about the paper I was going to give, what graduate school was like in America, if I had ever met a Hollywood actor (of course! America is crawling with them!), what bands I liked to listen to. Ian came in later, wearing a sharply pressed suit, and, to my surprise, sat down at the table with us students. I had assumed that meals at the conference would be similar to my family’s Thanksgiving dinners, where there were separate tables for the adults and the children. (And where, no matter how old I became, I still was relegated to the children’s table because my parents’ generation were still filling up the adult table. Last Thanksgiving several of us second-generation family members teetered uncomfortably on half-sized, low chairs at a correspondingly low table—the same chairs we’ve been sitting in for forty years.)
Ian introduced himself to everyone and struck up conversations with us all. He had himself done some work on absolute pitch and so was looking forward to my talk, he said. How often do professors go out of their way to get to know students like this? (Not often!) My first impression of Ian was of his generosity, and his indifference to social rank. We had another thing besides absolute pitch research in common: Ian was a guitarist, and although he played classical guitar and I played blues, we both had spent our lives listening to each other’s favorite music and understood it. That night after dinner, some of the attendees took turns taking the stage to play music for the group. Ian insisted that I borrow his classical guitar to play something for everyone, and so I sang and played a song I had just taught myself that month, Stevie Ray Vaughan’s “Pride and Joy.” Mine was the only nonclassical contribution to the evening, but everyone seemed to be having a good time. To this day, I still run into people from that conference who remember me as “that guy who played Stevie Ray Vaughan.” I’ve known Ian fifteen years now and he continues to astonish me with his clarity of thought, his scholarship, and his insights into music cognition. Over the past ten years, Ian has written a number of papers on the evolutionary origins of music, and they have become influential in the field.
We were both invited to deliver addresses at the International Music Meets Medicine conference hosted by the Gyllenberg Foundation in Espoo, just outside of Helsinki, in summer 2007. The days were long, with twenty-one hours of sunlight. I had never been that far north before, and Ian and I both noticed how different the color spectrum of the sun appeared—everything seemed a bit more yellow to us. We walked around the conference center taking in the new-to-us vegetation. The trees looked similar to trees we knew from our respective childhood homes, Scotland and California, but we noticed subtle differences in bark patterns, in the color of leaves, and—on the conifers—needles. We speculated about whether these were different species of trees than the ones we grew up with, or simply genetic variations that had adapted to fluctuations in the amount of sunlight they would be exposed to, varying seasonally from two to twenty-two hours a day. The fauna were also different—as we sat at a picnic table and talked about musical origins, our conversation paused frequently when we heard an unfamiliar bird, which prompted a spontaneous joint effort to try to see it and identify it.
We were also distracted by the calls of frogs in the pond next to our picnic table, and eventually were able to see some small, smooth-skinned brown ones that were unlike any we had seen in our own countries. The frogs and toads that Ian and I knew from childhood croaked together in a kind of amphibious symphonic tutti. The Finnish frogs—or at least those in our pond in Espoo—used what biologists call antiphonal calling. This, we read later in a field guide, is to maximize the chance that a female frog will be able to find her favored male. Frogs choose their mates largely on the basis of sound. A female frog can be swept off her legs by just the sound of a suitably enticing male frog call played over a loudspeaker, even trying to mate with a stuffed replica of a male. The reason that most frogs synchronize their calls is that it makes it more difficult for predators to locate them; the antiphonal calling in Espoo must have developed as a competitive advantage in mate attraction for those males who employed it, somewhat at their own increased risk of being eaten by predators.1
Ian began our conversation on musical origins by considering what the requirements might be for any system of animal or human communication. “Clearly,” he said, “the survival prospects of individuals and groups are enhanced by a capacity to communicate certain information about states of affairs in the physical world, and in the social world that concerns the organism. Even more so by the ability to organize action in response to those states of affairs,” actions such as running, hiding, fighting, cooperating, and sharing.
“Of course,” I interjected, “as David Huron would say, survival is only enhanced by sorting out fact from fiction, meaning that the organism requires the ability to detect liars, manipulators, and exaggerators.”2 This is exactly the argument that Huron and others have made for the value of music over language. This is a bold and controversial notion that is gaining favor among researchers. What you want for a communication medium is one in which honesty can be readily detected, what ethologists call an honest signal. For a number of reasons, it appears that it is more difficult to fake sincerity in music than in spoken language. Perhaps this is simply because music and brains co-evolved precisely to preserve this property, perhaps because music by its nature is less concerned with facts and more concerned with feelings (and perhaps feelings are harder to fake than supposed facts are). Music’s direct and preferential influence on emotional centers of the brain and on neurochemical levels supports this view.3
Ian continued that the ideal communication system would allow individuals to communicate knowledge about current conditions such as the availability and locations of resources, to make possible their sharing; perceptions of dangers would need to be identified and appropriate actions coordinated; finally social relationships would need to be articulated and sustained. Why is music necessary and even better than language for such tasks? I think it is because music, especially rhythmic, patterned music of the kind we typically associate with songs, provides a more powerful mnemonic force for encoding knowledge, vital and shared information that entire societies need to know, teachings that are handed down by parents to their children and that children can easily memorize. I believe that this is such a fundamentally important function of music that it may even have been the root of the first song (notwithstanding Sting’s and Rodney Crowell’s Chapter 3 lobbying for joy songs as the primeval musical form).
Imagine an early ancestor of ours, maybe a hundred thousand years ago, standing above a river where there is a gathering of crocodiles. Another early human is near them, and our ancestor hears one of the crocs make a certain noise before chasing and then devouring the nearby human. Our ancestor has learned that this noise is the signal that the croc is about to attack. Due to a random, unexplained mutation, his frontal lobe is a bit larger than anyone else’s. He has a greater than normal capacity to reason and to communicate; in particular, he has a perspective-taking ability, albeit a rudimentary one, an ability to imagine what other people are thinking. He realizes that this knowledge that he has is not knowledge that his children have. They are precious to him. He wants to warn them.
He runs home and (like all other humans at that time) has no language, but he feels it necessary to communicate to his children the danger he just witnessed. He doesn’t want to bring them to the scene; too dangerous—they could become dessert. He needs to communicate the danger symbolically. He imitates a croc. He gestures, wiggles on the ground, uses his body to make the motions of a croc. He brings his arms and hands together to mimic the jaws opening and closing, then makes the noise. This type of symbolic gesture may be practiced for thousands of years until a further refinement is introduced, precipitated by an even more enlarged frontal lobe. The young children don’t necessarily pay attention to this vital message; they are playing, babbling, making noises, laughing, moving, wiggling. The father incorporates their behaviors into his in order to attract their attention. He laughs, moves, makes funny noises. He surrounds the important message about the crocodile and the crocodile’s noise with an attention-getting dance, accompanied by pitched and rhythmic vocalizations. The first song is born, and it is born to simultaneously educate, grab the attention of, and entertain children. Today children are remarkably attuned to the music around them; they rock and sway to music in their environment, and within their first two years develop their own preferences for music. They are also attuned to the music within them, genetically encoded, entering a period of musical babbling often even before their linguistic babbling begins.
Children’s penchant for music seems to begin in infancy. By seven months, infants can remember music for as long as two weeks and can distinguish particular strains of Mozart they’ve heard versus very similar ones they haven’t, suggesting an innate—and evolutionary—basis for music perception and memory.4 And as Sandra Trehub has shown, mother-infant vocal interactions exhibit striking similarities across a wide range of cultures.5 These interactions tend to be musical, with wide pitch ranges, repetitive rhythms, and with clear emotional and instructive (knowledge-giving) content. Instinctively, mothers and infants co-regulate affect through these interactions, mothers reassuring their infants that they are nearby and attending to them. Mothers also use these musiclike vocalizations to direct their infants’ attention to important perceptual features in the immediate environment.6
David Huron suggests that the first song may have been more related to pride than fear, as in my crocodile scenario. “Imagine,” he says, “you’ve gone out on the hunt and you’ve come back—a group of you—and you want to share what happened with the others who weren’t there. And yet, you want to give them an aesthetic experience of it; you don’t want to report the way a bee would, ‘This is where the meat is.’ You want to report in an artistic fashion; in a highly stylized form to convey the sense of danger, your difficulties, your ultimate accomplishment.” This may have begun as pantomime and evolved into something recognizable as music-dance.
Alternatively, Ian Cross suggests, the first song may have grown out of a children’s chanting game, a turn-taking game such as “Patty-Cake” that helped them to coordinate their movements with those of another person.
In all cultures that have a number system, children have counting songs, rhyming ditties, to help them learn their number line by rote. In our culture these can be partly sung and partly spoken, and they typically do double duty to train motor coordination as in jumping rope songs:
Down by the river, down by the sea,
Johnny broke a bottle and blamed it on me.
I told ma, ma told pa,
Johnny got a spanking so ha ha ha.
How many spankings did Johnny get?
1, 2, 3 … [keep counting until the jumper makes a mistake]
or
Cinderella, dressed in yella
went upstairs to kiss a fella
made a mistake
and kissed a snake
how many doctors
did it take?
1, 2, 3 … [keep counting until the jumper makes a mistake]
By the age of three, many children are already making up their own songs, or versions of songs they’ve been taught, generating variations on the heard melodic/rhythmic patterns of their culture in much the same way they generate variations of speech patterns. This sort of spontaneous experimentation suggests that the predisposition toward melody and rhythm variation is hardwired in the brain; it may have been necessary to our ancestors, contributing to reproductive fitness.
Ian and I continued to talk by the Espoo pond. “Ultimately,” Ian continued, “music developed as a ‘communicative medium optimally adapted for the management of social uncertainty.’” Whether music preceded or followed language is not the point, Ian argued, because for tens of thousands of years both would have existed, and evolution, the brain, and culture would have accommodated to both.
“The very thing that music lacks—external referents—makes it optimal for situations of uncertainty,” Ian continued. “When social situations are difficult, confrontational—such as encounters with strangers, changes in social affiliations, disputed courses of action—the fact that language so unambiguously denotes individual feelings, attitudes, and intentions can tip situations into dangerous physical conflict. Language can become a social liability. But let’s imagine the possibility of access to a parallel system of communication, one that by its very nature tends to promote a sense of affiliation, unity, bonding. And …” Ian paused, his eyes reflecting the water of the pond, “one that conveys an honest signal—a window into the true emotional and motivational state of the communicator.”
And as a signal of emotion, there may be none better than music. Consistently, across all cultures we know of, music induces, evokes, incites, and conveys emotion. This is especially true of the music in traditional societies. And in laboratories, music is probably the most reliable (nonpharmaceutical) agent we have for mood induction. If music and mood/emotion are that closely tied, there must be an evolutionary explanation.
One evolutionary explanation for the relationship between music and emotion comes from the awareness that emotion is intimately related to motivation in humans and animals. So in looking for the connection, we might first ask: How could music have served as a motivator among nonhuman animals? Brains co-evolved with the world and have incorporated certain physical regularities and principles of the physical world. One of those principles is that larger objects, because of their increased mass, tend to make sounds of a lower pitch when they impact with the earth, or when they are struck (because in the latter case, their resonant frequency is lower as a function of their larger size).
The ancestral mouse that learned to pay attention to low-pitched sounds would have avoided being stepped on by elephants. In fact, very few of those that lacked this ability would have ended up being ancestors to any future mice, because they would have gotten stepped on. A sensitivity to certain frequencies, and to intensity and rhythm, would have been important. You don’t want to be too sensitive and startle to everything, or you end up staying in your mousehole all the time and you never get out to acquire food or a mouse mate. You need to startle to all the right things but only those. At the same time, if low-frequency signals indicate large size, some mice might have stumbled upon the fact that if they made low-pitched sounds with their throats and mouths, it might serve to intimidate other mice (if not elephants).7
It may be a long way from frequency sensitivity in mice to music in man, but it is a robust beginning. Thousands of small adaptations would have helped different species to find their ecological niche. It only takes one line of mutations in a single family tree to combine pitch selectivity with rhythmic sensitivity, and the foundations of the musical brain are there, waiting to be exploited when an enlarged prefrontal cortex figures out what to do with all that auditory discriminability. Before looking at how these brain developments may have occurred, however (which I’ll unpack in Chapter 7), I’d like to look more closely at just what knowledge songs really are and how they work.
Today, music is produced by few and consumed by many. But this is a situation of such historical and cultural rarity that it should hardly be considered. The dominant mode of musicality throughout the world and throughout history has been communal and participatory. We’ve seen the change even in a few generations. One hundred years ago, families would gather around after supper and sing and play music together to pass the time. In her memoir of 1880s Manhattan, Paula Robison writes:
Vicarious musical plea sure by radio and phonograph, while it encourages listening to good music, seems to put a damper on musical self-expression.8 [In our childhood] we sang more. Children sang at school and in their play. Folks sang as they worked, indoors and out. Even drunks do not sing in the streets and buses as entertainingly as in [those] days.
We see echoes of our shared history today in summer camps and on school buses. Knowledge songs may well have been the first, and David Huron observes that the flavor and sense of them is preserved here in North America in what he calls “yellow school bus songs.” These are songs such as “99 Bottles of Beer on the Wall” and “The Ants Go Marching” and even “The Wheels on the Bus Go Round and Round.” Songs like this are primarily teaching songs. “99 Bottles” and “The Ants” teach children to count. “The Wheels on the Bus” helps to construct and reinforce the physical and social order of the environment, encoding the perceptions into age-appropriate schemata: The baby in the bus cries, the wheels go round and round, the wipers go whoosh-whoosh, and so on. These songs simultaneously teach children things they need to know about the world and about musical forms and structure.
Another class of songs sung or chanted by children all over the world is selection or counting-out rhymes, the most famous of which in North America is probably this one:
Eenie, Meenie, Miney, Moe
Catch a tiger by the toe
If he hollers, let him go
Eenie, Meenie, Miney, Moe
[At this point, regional variations kick in; one researcher found several dozen different endings. The one I learned went like this:]
My mother told me to pick the very best one and you are not it.
[The person pointed to is “out,” and the game continues until only one player is “in.” That person then is “it” in whatever activity is being selected for.]
The interesting thing about such rhymes is that they are passed on almost entirely by oral tradition. No child reads the rhyme in a book, and typically children learn them from other children, not from adults. The rhythmic aspects of the songs and the vocal-motor coordination required to point and recite them effectively are practice for more adult activities. Children who are part of such a circle of counting out are very vigilant about violations of pointing or counting, making the reciter start over if there is even the slightest mistake. The game is socially reinforced and serves as preparation for more sophisticated songs that children inevitably learn, and that carry more important meaning. Across all of North America, the fixedness and similarity of different versions is extraordinary.
Many children’s songs also help to train memory, and although the songs themselves do not impart knowledge, they are the juvenile precursors of epics and ballads that do. “I Know an Old Lady Who Swallowed a Fly,” or “An Only Kid, An Only Kid” are examples of songs that continue on, with each verse invoking earlier verses in an interconnected narrative, so that by the end of the song the memory load is quite high. Young children typically remember isolated phrases and try to emulate older children who can make it all the way (or nearly all the way) through the entire story. Vivid imagery and animals—both things that appeal to children’s developing imaginations—help to preserve the concepts of these songs, and the children may learn the words as secondary, or subsidiary, to their mental images of the story. The most effective of these songs additionally use poetic devices—rhyme, alliteration, and assonance—to help constrain the possible words and give children a jump start in memorizing them. It is through songs such as “I Know an Old Lady” that many children first learn about the food chain: The spider swallows the fly, the bird eats the spider, the cat eats the bird, and so on. (It is also the first exposure of many children to a more adultlike vocabulary word, “absurd” [placed to rhyme with “bird” in the second verse].)
Ubiquitous also in every culture are the kinds of knowledge songs that encode information vital to the survival of every member of the group, not warnings about crocodile aggression, but day-to-day guides such as how to cook certain dark green leaves so that they are less bitter, or where to get fresh drinking water without invading the territory of a neighboring tribe:
Over here is where we get our
water Over here is where we get our water
Where the large-winged birds drink
Once a long time ago the father of Erdu
Went to the watering place over there
Where the women of the Baklata go
And the men of the Baklata killed him
We never go there, we never go there
Over here is where we get our water
Early in our history, songs like this would have encoded knowledge about which foods were safe to eat and which weren’t, probably in the sort of singsong rhymes we know today as the yellow school bus songs. These knowledge songs were essentially “how to” songs: how to skin an animal; how to make a spear, a water jug, or a watertight boat. We see versions of them today in pop music, in songs such as “How to Save a Life” by the Fray, “The Locomotion” by Little Eva (and later by Grand Funk Railroad), “The Heist” by Busta Rhymes (“that’s how we make movies”), or the whimsical “How to Build a Time Machine” by Aussie singer Darren Hayes.
Some of these knowledge songs would naturally but unintentionally have encoded things that weren’t true, of course—superstitions or folk theories. Superstitions are nothing more than inaccurate conclusions drawn from observations, experience, or hearsay. They are mentioned in contemporary popular songs as diverse as Devo’s “Whip It” (“step on a crack/break your mother’s back”), Janet Jackson’s “Black Cat,” Keith Urban’s “A Little Luck of Our Own” (“Black cat sittin’ on a ladder/Broken mirror on the wall”), and the Rolling Stones’ “Dandelion” (with the implicit message that to blow on this particular plant will give you the power to foretell the future).
With the invention of the printing press, the need for knowledge songs started to fade. In preliterate societies, they were the sole repository of cultural knowledge, history, and day-to-day procedures. They would have been fundamental to information transmission. Today knowledge songs are of a different stripe. The most well-known today is the alphabet song—every child in Western culture learns it. (“Thirty days has September” has musical aspects of rhyme, even though it is usually chanted rather than sung.) But new knowledge songs are being composed all the time. The children’s television show of the 1990s Animaniacs featured songs that a generation of kids used to learn such things as the states of the United States and their capitals (set to the melody of “Turkey in the Straw”) and the nations of the world (set in rhyme to the tune of the “Mexican Hat Dance”). The impressive thing about the latter composition is that composer Randy Rogel not only got the countries to rhyme, but mentions 160 of them more or less according to geographic region. Although he doesn’t mention every nation in the world, he excludes only a relatively small number of lesser-knowns, and even manages to slip in a joke:
United States, Canada, Mexico, Panama, Haiti, Jamaica, Peru Republic Dominican, Cuba, Caribbean, Greenland, El Salvador too Puerto Rico, Colombia, Ven-e-zu-e-la, Honduras, Guyana and still Guatemala, Bolivia, then Argentina, and Ecuador, Chile, Brazil …
Norway, and Sweden, and Iceland, and Finland, and Germany, now in one piece
Switzerland, Austria, Czechoslovakia, Italy, Turkey, and Greece Poland, Romania, Scotland, Albania, Ireland, Russia, Oman Bulgaria, Saudi Arabia, Hungary, Cyprus, Iraq, and Iran
Ethiopia, Guinea-Bissau, Madagascar, Rwanda, Mahore, and Cayman
Hong Kong, Abu Dhabi, Qatar, Yugoslavia …
Crete, Mauritania
then Transylvania
Monaco, Liechtenstein
Malta, and Palestine
Fiji, Australia, Sudan
Several of my undergraduates every year gleefully sing to me the “Parts of the Brain” as they learned them from this show, set to the melody of “De Camptown Races,” with a high-pitched voice chiming in the words “brain stem” where the “doo-dahs” would go: “neocortex, frontal lobe (brain stem, brain stem)/hippocampus, neural node, right hemi sphere.” By combining laboratory experiments with real-life ethnographic studies, psychologists are just beginning to understand how these and other parts of the brain are able to encode and preserve so much information in music.
In the 1930s, Albert Lord and Milman Parry recorded folk songs in the mountains of (then) Yugoslavia (but not Crete, Mauritania, then Transylvania).9 For hundreds of years or longer, traveling singers there, mostly Muslim, have gone from town to town, staying for a few days at a time and singing oral histories that can be thousands of lines long and take several evenings to complete. Experienced singers in this tradition might know thirty to a hundred such epics. Some of them memorize their songs with very high accuracy: In one case, a singer heard a song once and then brought it into his repertoire; tape recordings seventeen years later show astonishing consistency, with only very minor errors of wording.10
The Gola of West Africa place a particularly high value on the preservation and transmission of tribal history.11 Part of the reason for maintaining the histories is practical. The knowledge of kinship origins can help establish among contemporaries familial connections and the reciprocal responsibilities attendant to those; being able to claim a relative when you have no food can mean the difference between life and death in a subsistence culture. In addition, ancestors are viewed as distinct personalities who continue to exert influence over the course of present events, even when they’ve been long dead. Much of this rich oral history is held in musical form by oral Golan historians.
The ancient Hebrews set the entire Torah—the first five books of the Old Testament—to melody and recalled it from memory for more than a thousand years before they ever wrote it down. Even today many Orthodox rabbis can sing every word by heart. The so-called Oral Torah, the commentaries, instructions, emendations, and explanations contained in the written Talmud, have also been memorized verbatim by many, also set to music.
Songwriters know implicitly that setting something to music is the best guarantee that it will be remembered. In contemporary society, writing things down on paper, a PDA, or a computer may seem more practical, but it may not be more powerful. Songs stick in our heads, play back in our dreams, pop into our consciousness at unexpected times. Oliver Sacks tells the story of a song he could not get unstuck from his head, Mahler’s Kindertotenlieder (songs on the death of children). Unable to identify the piece—which grew to create in him a sense of “melancholy horror”—Oliver sang it for a friend. “Have you abandoned some of your young patients, or destroyed some of your literary children?” the friend asked. “Both,” Oliver answered. “Yesterday I resigned from the children’s unit at the hospital … and I burned a book of essays.” Oliver’s mind had brought up Mahler’s song of mourning for the death of children, a reflexive, inventive, and subversive way of symbolizing the previous day’s events.12
When Genesis sings “All this time, I still remember everything you said,” or when Bryan Adams sings “I remember the smell of your skin/I remember everything/I remember all of your moves,” they are encoding their personal memories in song.13, 14 By bonding the sentiments to evocative chords, rhythms, and melodies, they are tapping into a millenia-old and powerful way to save primitive, pure emotional reactions to feelings and events that are important to them. The music itself, even without words, can be very effective at evoking the right sentiment. (Research shows that people are very accurate at identifying the intended emotion of a piece of novel instrumental music.) Adding in the words and their interaction with melody, harmony, and rhythm can print the message indelibly in memory for a lifetime; even longer as new generations of listeners hear the song, learn it, and pass it on.
Some knowledge songs are written as a plea for the listener to remember something specific and important to the writer, as in “The Last Song,” by indie rockers Sleater-Kinney:
I need you out of me before I turn into
you I can’t stand to look at you,
Until you remember everything
The recipient’s only hope for saving the relationship is to “remember everything,” and the song serves as a reminder that this is what (s)he needs to do.
Often songwriters are not asking for others to remember, but write for themselves to remember. Take one of Johnny Cash’s most famous songs, “I Walk the Line”:
I find it very, very easy to be true
I find myself alone when each day is through
Yes, I’ll admit that I’m a fool for you
Because you’re mine, I walk the line
On the surface, it seems like a sweet love song, sung by the man to his sweetheart back home. But in the third verse, Cash explicitly invokes memory as he pledges to think of her:
As sure as night is dark and day is light
I keep you on my mind both day and night
And happiness I’ve known proves that it’s right
Because you’re mine, I walk the line
My reading of this verse is that Cash is not in fact singing the song to her, but to himself. The ironic underpinning is that in fact he doesn’t find it very, very easy to be true. He wants to be, but it is a struggle. The song’s function is to remind him why he’s doing this—because of the “happiness [he’s] known” with her and that he doesn’t want to risk. “I Walk the Line” is the song of a man in conflict, on the road, with a wandering eye, hoping against all odds and knowledge of his own weakness that he will be true. “I Walk the Line” is a knowledge song, a song of feelings encoded in song so that he will remember “when each day is through” what he promised himself he would do.
popular songs such as “I Walk the Line” or Genesis’s “In Too Deep” are only a dozen or two dozen lines long. How are Homerian epics, or the long oral histories and ballads of the Yugoslavians, the Gola, or the ancient Hebrews, remembered? Psychologists Wanda Wallace and David Rubin, among others, believe that the mutually reinforcing, multiple constraints of songs are crucially what keeps oral traditions stable over time.15 In most cases, it turns out, the songs are not remembered verbatim, word for word. Rather, broad outlines of the story are remembered, perhaps using visual imagery, and structural constraints of the song are memorized. This is a much more efficient use of memory than pure rote memorization of the words, using up far fewer mental resources. In Chapter 1 I spoke about the importance of form in poetry, and in song, form is the critical feature that helps to recall lyrics.
The mutually reinforcing, multiple constraints that help us to remember song lyrics are principally rhyme, rhythm, accent structure, melody, and clichés, along with various poetic devices such as those we saw in Chapter 1, including alliteration and metaphor.
The rhyming scheme we find in most songs constrains the words that can appear in the last position of rhyming lines. Even though there may exist several words rhyming with the correct word, semantic constraints will prevent most of those words from working in the context of the song. Say, for example, I know a song that begins:
The sun goes down, old friends drink and chat
The wind’s in the trees, the dog growls at the ——.
Although words such as “hat,” “fat,” and “mat” could fill in the blank and maintain the rhyme, our brains reject them almost instantly, unconsciously, because they are considerably less likely than an alternative (“cat”) in terms of semantics, not to mention in terms of our life experience of storytelling norms in our culture, in which cats are far more frequently mentioned in the same sentence as dogs than are hats, chats, mats, gnats, wine-making vats, or baseball bats. All work syntactically and poetically; one is far more likely semantically.
In Rodney Crowell’s song “Shame On the Moon,” suppose you just can’t remember the word at the end of the first line in the second verse, and all you can remember is that the lines rhyme with each other (a structural memory):
Once inside a woman’s heart, a man must keep his ——
Heaven opens up the door, where angels fear to tread
There are perhaps a dozen or so words that rhyme with tread: bed, bread, red, shed, but none of these seem likely in terms of semantics. Even if you can’t remember the correct word (“head”), your brain can figure it out more or less on the spot during reconstruction of the song. In fact, there now exists a wealth of research that what we think of as our ability to remember is grossly over-inflated, and that many dozens or hundreds of times a day we are creating bits and pieces of recollections on the spot. Our brains stitch these creations together seamlessly with our actual recollections and we’re none the wiser. In the jargon of cognitive science, this is called the constructive aspect of memory, and it happens so often, so spontaneously, and so quickly that we usually don’t know which parts of a recollection are faithful copies of our memory and which are simply plausible inferences our brains made for us. If bits and pieces of a song lyric can be generated on the spot, according to rules, then less of the song actually has to be remembered, and this is far more efficient for the brain.
We engage in this kind of parsimonious and rule-based memory retrieval all the time in other domains, for example in memorizing phone numbers. I have several friends in San Francisco and I’ve memorized their seven-digit phone numbers. When I go to call them, I remember that they’re in San Francisco, and that the area code for San Francisco is 415. Instead of having to memorize an extra three digits for all of my friends, I memorized the rule (San Francisco: add 415 to the number). I didn’t do this consciously, this isn’t some sort of mnemonic strategy I employed—it is automatic.
An example of a constructed memory is if I were to ask you about the last time you went to a restaurant. You might respond that you walked in the door, were met by a host or hostess, shown to your seat, where you were given a menu, your order was taken, your food was brought, and so on. Now suppose your narrative doesn’t mention the server bringing you the bill at the end of the meal, and I ask you, “Did the server bring you the bill after you were finished eating?” In laboratory experiments like this, many people say yes, they remember being brought the bill, but there exists ample evidence that they aren’t actually remembering, they’re merely assuming (or “constructing” the memory in the jargon of cognitive science), because this is part of our shared, common knowledge about what types of things usually happen in restaurants. We don’t have to remember all the events for any specific restaurant visit, because some of them are so similar and tightly scripted (and indeed, we tend to remember only if something distinctive occurs, such as the server bringing you the wrong bill).
Interestingly, we engage in a very similar process when we recall a conversation, piece of text, or speech, using what psychologists call gist memory. We tend to recall the gist, but rarely the precise words. Again, this is a demonstration of parsimony in memory and the fact that in a world of constantly changing environments, literal recall is seldom important.16 Most messages then are encoded using only a few words or concepts, and our knowledge of the English language and how to form sentences allows us to recreate something similar to what was said—close in meaning, but perhaps different in specific expression. We also do something analagous with melodies. When I was in a high school marching band, we played John Philip Sousa’s famous march, “The Stars and Stripes Forever.” There are several points in the piece where the wind instruments play a low note, followed by a rapid flurry of notes all leading up to a much higher note. It would be inefficient and also unnecessary to try to memorize every single note of that flurry. Instead, research shows that in cases like this, musicians typically memorize the low note, the high note, and how many beats there are available to get from one to the other. Then, using their knowledge of scales and tonality—rules—they construct the intermediate notes as and when they’re needed.
The very poor typical recall of text stands in stark contrast to the very good typical recall of song lyrics, especially in the case of long epic ballads and the information-set-to-music that I call knowledge songs. Again, this is because songs provide form and structure that jointly serve to fix and constrain possible alternatives. We don’t need to store every word of the lyric in our brain’s memory banks; we only need to store some of them, along with the story and knowledge of the structure of the song. Structural knowledge may include things like the rhyming pattern (the fact that lines one, two, and three all rhyme while four doesn’t; or the fact that line one rhymes with line three and line two rhymes with line four, and so on).
If all this seems far-fetched, this is only because it happens unconsciously and automatically, not subject to introspection. Most brain processes, when reduced to neuroanatomical or cognitive description, seem far-fetched, and this is because evolution has created a number of illusions with respect to thought, illusions that serve adaptive purposes. The most elaborate and largest illusion evolution has given us concerns consciousness itself, something I’ll return to in Chapter 7. It may also seem, based on introspection, that your brain is not generating all the possible rhymes for a forgotten word, but research has shown that this is in fact what’s happening, and that in the first five hundred milliseconds or so, dozens of alternatives are considered by your brain (subconsciously) and then filtered through a sieve of cognitive constraints.17
Songs also have a rhythm, of course, and this constrains the syllables that can be comfortably squeezed into a given amount of time, and thus again limits the possible words when we don’t recall each and every one of them. Take the first line of “I’ve Been Workin’ on the Railroad.” If you forgot the name of the song and whatever that thing is you’ve been workin’ on all the live-long day, and the lyric brought you to the dead end of “I’ve been workin’ on the blank-blank,” it is relatively clear from the rhythm that a two syllable word is what’s missing. If you sing “I’ve been working on the tra-acks,” it sounds funny because the two-note melody there doesn’t really support an elongated one-syllable word. A phrase longer than two syllables, such as “the Union and Pacific Rail Line,” seems too crowded.
The rhythm interacts with melody and accent structure during the word “railroad.” The higher note sounds like it is accented by virtue of its position in the rhythm, falling on a strong beat (the “one” in a four-beat measure of music) while the lower note falls on a weaker beat (the “three”). In this way the rhythmic structure implies a word whose accent is on the first syllable, like “r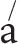 il-road,” as opposed to say, “gui-tr,” whose accent is on the second syllable.
il-road,” as opposed to say, “gui-tr,” whose accent is on the second syllable.
Clichés, or less pejoratively, common word combinations, also help us to remember lyrics. Expressions such as “I’ll love you until the end of time” or “letting the cat out of the bag” are so common that if we hear (or recall) only a few of the words, the rest of them follow. For example, you might remember only the first four words of this lyrical phrase: “We used to fight like cats and ——.” Even a child could fill in the missing lyric, because this phrase occurs so often in ordinary speech. In fact, this exact phrase “fight like cats and dogs” is found in dozens of pop lyrics including songs by Dolly Parton (“Fight and Scratch”), Paul Mc-Cartney (“Ballroom Dancing”), Harry Chapin (“Stranger with the Melodies”), Tom Waits, Nanci Griffith, and Indigo Girls (“Please Call Me, Baby”), and Phil Vassar (“Joe and Rosalita”). Another common idiom, the phrase “spill the beans,” shows up in songs by six artists that couldn’t be more diverse: Yes (“Hold On”), Lard (“Pineapple Face”), DJ Jazzy Jeff & the Fresh Prince (“I’m All That”), Boomtown Rats (“Tonight”), Carly Simon (“We You Dearest Friends”), and Smash Mouth (“Padrino”). In all these cases, songwriters are taking advantage of the brain’s ability to retrieve sequences of pre-stored information when cued with only a small piece.
Poetic features of lyrics, such as assonance or alliteration, also help to bring up words from memory; if we remember that the song has these features, we again don’t necessarily have to store every word. Great feats of memory are all about parsimony, cognitive economy—using rules that will generate dozens or hundreds of correct answers on the spot rather than memorizing and having to recollect each item.
Some songwriters flout these customary principles, and this itself can become a memory aid. When Paul McCartney sings “Hey Jude/Don’t make it bad/Take a sad song …,” each word falls right on a melody note in perfect time, just as you would expect. But on the final line of that first verse, he makes a “mistake,” one that sounds odd, singing: “… and make it bet-ter-er-er,” stretching the second syllable of the word “better” out over four notes. On first listening, it is jarring. But we remember it for its distinctiveness. Even if you forget the word “better” (or fail to encode it, although neither possibility is likely, because the very distinctiveness of this compositional move virtually guarantees it will become solidly encoded in memory), you can re-create the word just by remembering that there was something funny going on there, a two-syllable word stretched out to four syllables. Given the semantic constraints of the text before, there just aren’t that many words that can fit in that final slot. (Paul uses the same technique later in the song, of course, stretching out the word “be-gi-in” to three syllables.)
The individual effects of rhyme, rhythm, accent structure, melody, cliché, and poetic device can be subtle. The idea of mutually reinforcing constraints is that the effects are additive—no single effect is always enough to help us generate a missing word, but together they can turn an incomplete memory into a near perfect performance. The interaction of these different cues allows the lyrics of ballads and other knowledge songs to remain relatively stable over centuries.
In Wallace and Rubin’s studies of expert ballad singers, they found that even when the singers made word errors, they seldom misremembered the structure of the song—the rules describing its invariant features. The end-rhyme sound, the number of beats per line, and the number of lines per verse remain relatively constant within a particular ballad, and the singers studied rarely made errors about these. Ballads in general are stabilized by the common characteristics they share—well-known, stylistic norms within a given tradition whether it is Yugoslavian, Golan, Indonesian, North Carolinian, or Ancient Greek. These common characteristics are so embedded in the idiom that when singers of a given tradition are asked to write a new ballad, encoding a new event, they tend to employ all of the same tools and incorporate the same structural characteristics of that form.18
In one song Wallace and Rubin studied extensively, “The Wreck of the Old 97,” the form of the ballad was clearly serving as a memory aid. “Words and music,” they write, “are intertwined. The words have a metrical pattern, which must correspond to the rhythmical pattern, the beat structure, and the time signature of the music …. In this ballad, the meter consists of two unstressed syllables followed by a stressed syllable. Usually the unstressed syllables are shorter in length than the stressed syllable …. The meter and rhythm are closely related in that the number of stressed syllables equals the number of beats in the music …. Thus, the music and words constrain each other.”
If these multiple and reinforcing structural constraints are such an important ingredient in remembering song lyrics, it follows that a song with fewer of them would be recalled with more errors. Wallace and Rubin created just that situation for an ingenious experiment—they changed twenty-four words in “The Wreck” to eliminate assonance, alliteration, and rhyme.19 Notice that they specifically made changes that affected poetic characteristics of the words, the weakest of the structural constraints I listed above. (No end rhymes were altered, and the number of syllables in each word and the stress patterns were maintained.) The unaltered and the new version of the song were then taught to people who had never heard it before. Analyzing the words that had been changed, Wallace and Rubin found that singers were more than twice as likely to recall a word verbatim if it possessed these poetic elements (the original version) than if it did not (the altered version). This shows just how constraining—or helpful—the relatively weak factor of poetics is.
As of this writing, a popular television show in the United States features hapless contestants misremembering song lyrics, which on the surface may seem to undermine my arguments. First, what makes the show funny is that millions of viewers remember the lyrics that the contestants forgot and can’t understand how they could have forgotten them. Second, understand that network television is entertainment, and that the producers undoubtedly go out of their way to pre-select people with a bad lyrical memory; they may represent only a minority of the population, but they are the ones that make for the most entertaining spectacle. Third, recall that the average person today is exposed to tens of thousands of songs. The average oral historian may have only been responsible for memorizing and retelling thirty or forty in the days before radio. Finally, our ability to recognize that we’ve heard songs and to repeat portions of them should not be confused with the potential ability we all may have to truly commit songs to memory when we focus our attention and energy on doing so; asking people to sing back songs that they may have only ever heard in the background at a shopping mall or on a car radio is not the most rigorous test of their abilities (and not a scientific experiment!).
Now here comes the amazing part of Wallace and Rubin’s study (and why they are my heroes). It’s based on the principle of constructive memory—that we don’t actually remember all the details we think we do, we fill in many of them subconsciously by making plausible inferences. Wallace and Rubin looked at the errors made by those singers who were asked to learn the altered version of the song (and heard only that version). Many of them spontaneously, and without prior knowledge, recovered the poetic words that had been removed by the experimenters. In other words, the stylistic norms of assonance and alliteration—the tendency for them to be prominent in these sorts of epics and ballads—was something that the subjects in their experiment had encoded in their long-term memory. When they tried to remember the song—involving a process of reconstructing the words—they “remembered” the words that originally belonged in the song. For example, if the original song contained the alliterative phrase “real rough road,” and the altered version was rewritten and learned as “real tough road,” some singers (wrongly?) sang it back as “real rough road.”
In family and tribal histories, ballads commemorating important battles, and so on, minor errors in wording are probably so insignificant as to be not worth mentioning. There are at least two cases, however, where errors are completely unacceptable. One is those knowledge songs that were created to preserve precise, practical information about how to do something, such as make a watertight raft, prepare food or medicine that might otherwise be poisonous, or accomplish some other action where both the order of the steps and the details of the procedure are critical. A second case is those knowledge songs that are intended to convey religious information, where every single word must be preserved verbatim because it is considered sacred and divinely given—there are strong cultural pressures to recall such material accurately or not at all.20 In cases like these, humans exhibit a remarkable ability for virtually perfect recall. How could this be?
When people accurately recall texts of great length, they are typically texts set to music—songs. It is far rarer for such prodigious memory to be demonstrated with straight, musicless text, and the reason for that appears to be the theory of multiple, reinforcing constraints. Insight into the matter comes from another very clever experiment by Rubin.21
Rubin asked fifty people to recall the words of the Preamble to the United States Constitution (try it yourself now before reading any further; the words are in an endnote at the back of the book).22 This of course does not have music, but that’s the point—the kinds of errors that people made here were profoundly different than those made by people trying to recollect songs.23 One group of people remembered the first three words (“We the people”) and then … stopped. You hardly ever see this in song recollection. When they forget the words, people singing a song typically continue on humming or singing la-la-la or something else, along with the melody that continues, uninterrupted, to play in their heads, and they pick up words here and there along the way, sometimes recalling entire stretches of the song at a later point down the line. Another group of Rubin’s subjects recalled the first seven words (“We the people of the United States”) and then quit. Nearly every one of his fifty subjects stopped cold when they failed to recall the next word in the sequence, whatever that word was.
The places in the text where people got stuck were far from arbitrary: 94 percent tended to get stuck at phrase boundaries, natural breaks where one would pause to take a breath. Rubin replicated these findings with the Gettysburg Address. Songs, because of their rhythmic momentum, are far more easy to “keep on going” in our heads without the words; this gives our brains a chance to jump in whenever a word or word fragment becomes available again, making lyric recall in songs typically better than lyric recall without them. This is one reason why the average person probably has a more intimate and emotional connection to music than to poetry—because he or she can recall more of it, and more effortlessly.
It’s important to look in more detail at how rhythm plays its role in aiding recollection of lyrics. When we recall a song, rhythm provides an internally consistent hierarchy of temporal units—syllables form poetic feet, which in turn form lines, which form phrases, verses, or stanzas—and these rhythmic units usually coincide with the units of meaning in oral traditions.24 These rhythmic units with their accent structure create positions in the music where words must go—they don’t permit us to omit part of a rhythmic unit, thus conspiring to preserve the integrity of lines and verses. (If any omission is to occur, it would generally be at the level of a large-scale repeating unit such as a verse, and then different mnemonic processes come into play to maintain its integrity.)
Recall from Chapter 1 that a mark of most effective poetry is that it has its own rhythm, a music about it that we hear when we recite it out loud. If poetic rhythm, combined with the sorts of other poetic devices we looked at in Chapter 1, really helps us to remember poetic text, you might expect that people would have better memory for poems than straight text, and moreover, that their errors would be more similar to those we find in music recollection. Both of these turn out to be true. David Rubin asked undergraduates to recite from memory the 23rd Psalm, which contains many poetic elements but (in the English version) lacks rhyme. Here, most undergraduates started up again at a later point in the psalm after they stopped (and it was usually at the beginning of a new section that they came in). It seems as though the internal rhythms of the psalm kept on playing in the students’ heads, and they jumped in whenever they could recall a word. (Don’t forget that the Psalms, as originally composed, were set to music.)
Additional evidence for the notion that people “play back” such recollections in their heads comes from my own experiments with Princeton computer scientist Perry Cook. We found that when college undergraduates sang their favorite songs from memory, they tended to sing them at almost exactly the right tempo. If they forgot words, they kept going and jumped in later, again at what would have been the right place if they’d kept on going, as though the band kept playing and they simply came in at the next appropriate moment. And from their own subjective reports, all of them had vivid mental imagery of the music. They weren’t so much trying to reproduce the song from memory as singing along with a track in their heads.
Getting back to the memorization of text, when very long word sequences are involved, we typically resort to two tried-and-true mnemonic techniques: rote memorization and chunking. Rote memorization is simply reciting a sequence back over and over again (often in the quiet privacy of our own minds) until we’ve got it. This is how most of us learned our multiplication tables in grammar school, the Pledge of Allegiance, the Gettysburg Address, or the Preamble to the Constitution. The interesting thing here, though, is that not all words are created equal in rote memorization. Some words take on more importance because of the expressive emphasis we are taught to give them, some because they evoke particularly pleasant or vivid imagery, and some because they contain certain (preplanned, on the part of their writers) poetic qualities. Internal rhymes, assonance, and alliteration of a Cole Porterish quality help to reinforce the Gettysburg Address for example (maybe because assonance makes the heart grow fonder):
Four score and seven years ago
Our fathers brought forth
We see the repetition of the f sound here acting as a mnemonic, as well as the repetition of the long o sound in four, score, ago, forth.
When the text we’re trying to memorize is more than a dozen or so words long, we tend very naturally and without coaching to break it up into bite-sized, more readily memorized, sanitized and organized units, or chunks, and then stitch these chunks together later. This is also how musicians memorize pieces they perform. With the exception of special neurological cases of people with photographic memory (or the auditory equivalent, what I call phonographic memory), most musicians, dancers, actors, and other performance artists, young and old, do not sit down and learn a new piece from front to back all at once. They concentrate on getting a small part of it just right and then they learn another small part. They then spend some time learning the transitions from one part to another. The evidence for this process remains long after the piece has been committed to memory and its performance is flawless: Actors who have to redo a take often ask to go back to the beginning of the line, paragraph, or scene. Musicians return to the beginning of the phrase. Bring out the score, point to an arbitrary note where you’d like them to start in a memorized piece, and most musicians will ask to start somewhere else, at the beginning of some chunk that they learned. When musicians make errors in prepared pieces, these errors provide additional clues to the way the piece was originally learned. It is more common for a musician to skip an entire section (a failure to remember how the chunks were stitched together) than for a musician to skip a note or short group of notes within a section. Between-section errors are far more common than within-section errors. Not all notes or words are equally salient.
The Gettysburg Address is substantially easier to memorize than multiplication tables, which typically require pure rote memorization. Personally, I remember having great difficulty with these in grammar school. I made a little card with them written down, and while I walked to school or had a spare minute, I would glance at the card and test my memory. With no rhythm or melody to attach the numbers to, pure brute force of repetition was required: two times two is four; two times three is six; two times four is eight. I got up to the sixes without too much difficulty, but well into high school I couldn’t remember the “twelves” unless I started from a part of the tables that had personal meaning for me, the one that represented my height in inches at the time I was originally trying to memorize them: Twelve times four is forty-eight. If I wanted to recall twelve times eight, I’d have to start my “poem” at this salient point and work my way up: twelve times four is forty-eight; twelve times five is sixty; twelve times six is seventy-two; twelve times seven is eighty-four; twelve times eight is ninety-six. Because of incessant teasing from my neighbor in third grade, Billy Latham (an excellent drummer at the time, by the way), who had learned his tables all the way up to twelve times twelve, I had also memorized the one that Billy taunted and drilled me with most frequently: twelve times nine.
The reality of these chunks has been demonstrated many times in psychology laboratories.25 Asked to sing song lyrics from memory, beginning from an arbitrary point, people have great difficulty. Asked even to answer simple questions about lyrics they know, people are influenced by the hierarchical structure of the lyrics—revealing in the laboratory certain organizational properties of human memory. Here’s an example. Does the word my appear anywhere in the lyrics to the song “Hotel California”? What about the word welcome? Both words do appear, my is the ninth word in the song, and welcome is the ninety-sixth word. But people take longer to say yes to the first question than to the second, and psychologists believe this is because welcome is the first word of the chorus, a privileged position in the hierarchy of your memory for the piece.
Most North American children learn the alphabet by learning the letters set to the melody of “Twinkle Twinkle Little Star” (the same melody as the beginning of “Ba Ba Black Sheep”). The song has phrase boundaries because of its rhythmic structure, gaps between the letters g and h, k and l, p and q, s and t, and v and w, forming natural “chunks”:
abcd efg hijk lmnop qrs tuv wxyz
Indeed, most children don’t memorize this all at one sitting, but rather they work their way up, memorizing these small units. The rhyming scheme helps too: The ends of all the chunks rhyme with each other except chunks three and five. Even though as adults we know the letters of the alphabet (or think we do), many of us still rely on that song when searching for the specific location of a letter. In one experiment, it was found that it takes college undergraduates much longer to say what letter comes just before h, l, q, or w than before g, k, p, and v.26 Crossing the chunked boundary carries with it some cognitive cost.
Notwithstanding what I said about errors at phrase boundaries, some professional musicians and Shakespearean actors do indeed have perfect recall for a memorized string and can begin anywhere; this ability probably develops from overlearning processes, and under stress it may disappear.27 Something like it shows up in even semiprofessional or amateur actors and musicians when they need to start from the very beginning of a piece. Effectively, their “stitching together” of subcomponents has worked so well that the entire piece, though at one time consisting of small units, has become a single memory trace, not easily disassembled, occasionally indestructible, lasting a lifetime, and sometimes outlasting even the memory of their own family members’ names.
The use of chunking and the occasional inviolability of long, overlearned sequences is not confined to contemporary Western society. The Greeks discussed these ideas in formulating instructions for mnemonics two thousand years ago, and the anthropologist Bruce Kapferer (from the University of Bergen in Norway) has observed them in researching the myths of Sri Lanka. In trying to form a catalog of different demons and their characteristics in a cultural group he was studying, he would ask a local oral historian to describe the myth of a particular demon. The historian would respond that the exact details were contained in a certain song. “I will sing it and you tell me when the demon you want has his name mentioned.28 Then I will go slow so that you can put it onto your tape recorder.” The myth information was stored in the song, and the song was known only sequentially, and only from the beginning.
Getting back to the Greeks, the 2,500-year-old Iliad and the Odyssey represent great feats of memorization, without music, but with clear poetic, rhythmic constraints doing much of the work and thus creating less demand on the brain. Their prosody is very tightly constrained. As just one example, the number of syllables per line is almost always constant, and the last five syllables in a line are almost always long-short-short followed by long-short. The ordering of short and long syllables, and the preferred locations for word breaks are formulaic—not just any word will fit the rules. For example, words containing a long-short-long or short-short-short syllabic structure can’t be used in Homeric epic at all.29 Obviously, if one has learned the rules for such a form, opportunities for inserting the wrong words are extremely limited.
According to Jewish tradition, the complete Torah (the first five books of the Old Testament) was completely memorized by Moses, and then taught to the elders and leaders of the Hebrew people in the Sinai Desert, who in turn taught it to the million or so people who left Egypt as part of the Exodus, sometime around 1500 B.C.E. We know that the Hebrews had written language (the tablets of the Ten Commandments were written), but on Moses’s strict instruction, not one word of the Torah was to be written down, and for more than one thousand years the history, knowledge, religious customs, and practices were reportedly handed down only through oral transmission. And the form of that oral transmission, according to all accounts, was song.
Jewish mystics believe that the very sound of the words will bring divine favor, even if the speaker doesn’t understand the words themselves. Similarly, in the Zoroastrian tradition, it is believed that the soul (Urvaan) can be reached by the specific vibrations that come from chanting the Avesta Manthras.30 It’s not just the meaning of the prayers, but also their sound that matters, for the “attunement” of the soul. In Zoroastrianism, Staota Yasna is the theory of auditory vibration. That’s why the prayers are still recited in the original language, Avesta, even though it isn’t spoken any more.
The Qur’an was also set to rhythm and melody—a chant—and learned in a similar fashion, although it is explicitly not considered “music” and is structurally very different from Arab music we hear today; in fact singing the Qur’an is strictly forbidden. The Qur’an itself describes the means of its recitation (tarteel) in verse four: “and recite the Qur’an in slow measured rhythmic tones.” The power of song to aid memory is evidenced in a following fatwa against singing. Islamic scholars believe that “music and singing carry ing obscene content, instigating to sin, lechery, destroying noble intentions and leading into temptation, are inadmissible (haram) ….31 The degree of inadmissibility becomes higher if an obscene vocabulary acquires a musical accompaniment that contributes to a better remembering and thus enhances its impact.”
In the case of the Torah, the melody itself contained clues not only to the words, form, and structure of the narrative, but also to interpretation of words or passages that might otherwise be ambiguous. That is, the assignment of words to melody (and vice versa) was not arbitrary—it helped not only as an aid to memorization and recall but also to ensure the correct interpretation.
This sort of interplay is not at all unusual 3,500 years later. In the song “Superstar” as sung by the Carpenters (written by Leon Russell), Karen Carpenter sings the line “Long ago, and oh so far away” using a vocal technique that artfully reinforces the meaning of the words. She delays the pronunciation of the word “far,” reinforcing the idea of distance. While holding the word “away,” she brings out a subtone in her voice that conveys the sense of deep loss and separation. In Steve Earle’s “Valentine’s Day,” the singer is surprised by the arrival of the day, and realizes too late that he has forgotten to get his girlfriend a present. He writes her a song instead. The appearance of surprising and nonstandard chords underscores the meaning of the words, adding tension and deeper meaning to the lyric.
The reasons for the insistence that the Torah be transmitted orally are a matter of speculation. One proposal is that the success of the Jewish people, one of the oldest continuously living civilizations in the world, is due to especially close ties between parents and children and the bond created through the oral transmission of knowledge—knowledge which, in the case of the Torah, intimately binds family history, moral lessons, po litical history, codes of daily conduct, and instructions for maintaining an orderly, just society. If the information had been written down and learned by reading, the knowledge transmission would have flowed in one direction, from book to student. The oral transmission enabled—virtually required—interaction, questioning, participation; what the physicist-turned-Torah-scholar Aryeh Kaplan called a living teaching. Indeed, the ancient Hebrew scholars wrote that “the Torah is meant to be alive, to be spoken.” Like the poetry we encountered in Chapter 1, it is meant to be heard, both in the ears of the people and in the minds of those who have learned it and can play the song of it back in their heads at will, in times of scholarship, trouble, or praise. It’s also been proposed (somewhat less logically) that the restriction on writing the Torah down existed because some knowledge of customs and traditions would be lost if it was committed to writing—that the sum total of the knowledge known by the people exceeded what could be written down. When the rabbis decided sometime between 150 B.C.E. and 200 C.E to commit all the teachings to writing, much debate and disagreement indeed ensued, about many details. (All of the debate is captured in the Talmud—in fact, that is primarily what the Talmud is—a record of what were essentially judicial proceedings and deliberations about what precisely the oral teachings were and how they were to be interpreted.)32
From a memory standpoint, the cantillation (as the Torah melody is known) provides the same sorts of constraints that other songs do—perhaps even more—facilitating the memorization and preservation of an enormous amount of text. Without recordings, however, it is impossible to know for sure how well the original words of sacred texts such as the Torah and the Qur’an were preserved through their oral transmission. We don’t know, and can’t know, the extent to which melodies changed, rhythms were rewritten, emphases were altered. But the fact that different subgroups of contemporary Jews sing different melodies suggests that there was no one magic formula for preserving the information—time and tide would have caused minor changes as in the child’s game of telephone, and over generations these differences could have become considerable, and they would have become amplified. Humans are a highly adaptive species. As we moved to new locations, to communities with their own musical cultures and traditions, original melodies may well have become altered or distorted by the influence of local songs. Even the prosody of the new languages (the “music” of the language) has been shown to influence the songs of that linguistic culture. As the Mongols entering southern Europe on horseback, the Armenians dispersing to Paris, and Italian-Americans crooning in Hoboken found, local sounds pull at the immigrants’ long-preserved melodies and rhythms, creating new hybrids that continue the cultural evolution of their songs, at the possible expense of losing some of their original (melodic and textual) information.
The existence of different melodies for Torah today suggests that errors may indeed have crept into the text when it was transmitted orally—if melodies can change, so can words.33 (In fact, much of the discussion during the compilation of the Talmud in the first few centuries C.E. acknowledged that some errors by then had already crept in, and concerned how to resolve those errors.) Indeed, the discovery of the Dead Sea Scrolls reveals that multiple versions of the sacred texts exist. From both a cognitive and a theological perspective, the errors are mostly relatively minor and unimportant, of the type we saw in Rubin’s study of ballads.
Across all these examples, a common thread emerges: Knowledge songs tell stories, recount an ordeal, a saga, a particularly noteworthy hunt—something to immortalize. The demonstrated power of song-as-memory-aid has been known to humans for thousands and thousands of years. We write songs to remind ourselves of things (as in Johnny Cash’s “I Walk the Line”) or to remind others of things (as in Jim Croce’s “You Don’t Mess Around with Jim” or Fleetwood Mac’s “Don’t Stop”). We write songs to teach our young, as in alphabet songs and counting songs. We write them to encode lessons that we’ve learned and don’t want to forget, often using meta phor or devices to raise the message up to the level at which art meets science (rather than simple observation), making it at once more memorable and more inspiring, as Andy Partridge does in “Dear Madam Barnum” (performed by his band XTC). The name Madam Barnum is clearly made up, meant to portray her as the ringleader in some abusive emotional circus she has subjected the poor songwriter to, and from which he now hopes to extricate himself:
I put on a fake smile
And start the evening show
The public is laughing
I guess by now they know
So climb from your high horse
And pull this freak show down
Dear Madam Barnum
I resign as clown
Songwriters often invoke a well-known tale or legend in the context of a new song. In “Dear John,” the writer of this song (Aubry Gass, and as sung by Hank Williams) is again encoding an experience into a song, presumably so that he won’t forget that it was his own misbehavior that caused his woman to leave him; he weaves into the message two well-known Old Testament references:34
Well when I woke up this mornin’,
There was a note upon my door,
Said “don’t make me no coffee babe,
’cause I won’t be back no more,”
And that’s all she wrote, Dear John,
I’ve sent your saddle home.
Now Jonah got along in the belly of the whale,
Daniel in the lion’s den,
But I know a guy that didn’t try to get along,
And he won’t get a chance again,
And that’s all she wrote, Dear John,
I’ve fetched your saddle home.
Note the interesting shift to the third person in the second verse (“I know a guy that didn’t try to get along”), a conceit to make us think that it isn’t actually he who was left by a woman, a move that underscores the point that he’s sending the message out to others as a warning: Don’t do what I did; treat your woman right.
Hard-won lessons are a staple of knowledge songs, from Paul Simon’s “Run That Body Down” to Ani DiFranco’s aptly titled “Minerva” (after the Roman goddess of knowledge) to the Magnetic Fields’ “You Love to Fail.” As with Aubry Gass’s, the songs seem to be simultaneously directed from the songwriter to him-or herself and to all of us. Guy Clark, one of my all-time favorite song-writers, brings a lifetime of lessons seemingly learned the hard way into his song “Too Much,” a romp that is made all the more fun (and memorable) by the form he imposed on himself: Every line of the verse begins with the same two words (“too much”), compiling a litany of everyday pleasures, too much of which will cause the various calamities specified at the end of each line:
Too much workin’ll make your back ache
Too much trouble’ll bring you a heartbreak
Too much gravy’ll make you fat
Too much rain’ll ruin your hat
Too much coffee’ll race your heart tick
Too much road’ll make you homesick
Too much money’ll make you lazy
Too much whiskey’ll drive you crazy
…
Too much limo’ll stretch your bud get
Too much diet’ll make you fudge it
…
Too much chip’ll bruise your shoulder
Too much birthday’ll make you older
Part of what makes the song memorable is the obvious fun that the composer had in writing it, reflected in the joy the performers bring to playing it. The sense of whimsy is enhanced by decomposing the familiar idiom “carry ing a chip on your shoulder” to yield “too much chip’ll bruise your shoulder.” In “too much limo’ll stretch your bud get,” he taps into our memory associations of limos and “stretch limos” to use both senses of the word stretch. (It is no wonder that Clark is a favorite of many of the best songwriters in the business, including Rodney Crowell, whom Guy mentored.)
A song like “Too Much” turns the memory process into a game—the first part of each line cuing the second part or vice versa. If we forget the line, logic can often deliver it to us just as it does in “I Know an Old Lady Who Swallowed a Fly.” It is worth making the cultural point that these sorts of songs are found in every society we know of. And the fact that children tend to love these songs is evidence that our ancestors found this sort of mental play both rewarding and an efficient form of learning and information transmission.
Up until this point, I’ve been considering songs as they are recalled and sung by one individual at a time. But knowledge songs—from Huron’s yellow school bus songs to Torah cantillation—are more typically sung by groups of people. In this context their position as a foundation of culture and their durability become even more apparent. I’ve already described the social bonding that comes from synchronous music making, and the neurochemical effects of singing, but there are manifest cognitive benefits that are conferred to the group-as-a-whole, apart from any benefits to the individual when people sing together.35 Group singing shows a special ability in retrieving information that a lone individual might not be able to recall, an emergent property. Emergent behavior occurs when groups can do things that individuals cannot. Ant and bee communities are examples of emergence where intelligence arises out of a multiplicity of relatively simple and seemingly unmotivated actions. No single ant “knows” that the hill needs to relocate, for example, but the actions of tens of thousands of ants result in the hill being moved, efficiently, effectively, even “intelligently.”36 The Stanford biologist Deborah Gordon writes, “The basic mystery about ant colonies is that there is no management.” No ant stands at the periphery of the colony directing traffic.: “Hey you! Stop playing ‘rub-the-feelers’ with that worker ant and get a move-on! Come on guys, break it up, there’s enough moldy peanut for every—HEY BUDDY! What’re you, taking a break? Go help those guys carry ing the heavy praying mantis carcass!” With no ant in charge, how on earth do ants get anything done?
Ant colonies exhibit behavior very similar to that of other systems with a very large number of units or components, all of which interact, and the consequences of whose interactions change over time. Physicists call these nonlinear dynamical systems. (They’re called nonlinear because the effects of these interactions can’t simply be added up, they sometimes have to be expressed as powers, or other higher mathematical functions. They’re called dynamical because the influence of one event at the beginning can have profound effects later in time as that initial effect is carried forward.) In systems like these—which include rain forests, stellar transits, the stock market, and even the faddish propagation of hit songs—small, seemingly chaotic, and unrelated behaviors can end up having large effects as they interact, spread, and develop over time.37 In other words, extraodinarily simple individual units—like ants, neurons, atoms, or musical notes—can generate complicated and often counterintuitive global behavior.
On the surface, you might think that groups remember knowledge songs better because they spread out the memory burden among a greater number of people. But it’s not the case that ten singers each remember a different line—there is no prior agreement, no coordination of the learning or recall. Instead, due to a variety of differences among individuals (and these differences can be genetic, environmental, based on IQ, personal motivation, personal taste, and random factors) some people are going to remember some parts of a song better than they remember other parts. There may be nothing systematic about it, and the remembered parts could even change from day to day and week to week.
But something special happens when a group starts to sing together—something extraordinary from a cognitive (and dynamic complex systems) perspective, something you’ve probably experienced yourself in any place where people come together to sing: football games, church, campfires, or political rallies. On your own, you might get stuck after the first line of the song. Singing with a single friend, your companion might remember the first word of the second line and that keeps you going for another few words, but then neither of you can remember the third line just now. In a large group, no one has to be able to recollect the entire song. Just one person singing the first syllable of a word can trigger a recollection in another group member to bring the second syllable of that same word, which in turn can cue a group of people to that whole word and the next three words after it. Imagine this notion propagated through a large group of dozens or hundreds of people, and throughout every syllable of the song—a sort of group consciousness emerges in which no single member of the group can be said to know the song, but the group itself does.
Even in a non-emergent system, if someone misrecollects and offers a wrong syllable, musical note, or word, he will likely be overpowered by the greater number of people who correctly remember it. (This is a version of Oliver Selfridge’s famous connectionist pandemonium model of human perception.) The reason for this is that, although it is relatively likely that any part of the song will be misremembered at any given moment by any member of the group, it is relatively unlikely that all of the misrememberers will misremember it in the same way. The correct rememberers will tend to outnumber any of the various schools of misrememberers (and with a large group, it becomes increasingly unlikely that a substantial number of individuals will forget at exactly the same time and in the same way). In a dynamical system, every second new information is revealed and this influences the future development of the system. At least some of those who misremembered will correctly remember when given the right cue. This is the fundamental mechanism by which extraordinarily long stretches of textual information have been preserved, handed down, and communicated across hundreds or thousands of years. Errors do of course creep in, but the more tightly constrained the poetic/musical form of the song (such as we see in Homerian epics or even in the twelve-bar blues), the more likely the message will arrive intact, unaltered, and resistant to future distortions.
Nonlinear dynamical systems are thus characterized by (1) local propagation of information among individuals (a neighbor providing the right lyric) through a (2) nonlinear mechanism (individual and group memory and cognition in this case) involving (3) individual variability (e.g., heterogeneous song recollection). These three properties lead to (and are required for) the emergence of low and asynchronous occurrence of errors in the whole group despite the high probability of error observed in single individuals.
The existence of group memory and group singing may itself have been selected for by evolution, which may have favored those individuals who could bond into groups for the purpose of collective action. I believe that this group selection process and the survival and reproductive advantages conferred upon members of large groups (as opposed to lone individuals) is fundamental to how human societies were eventually formed. While synchronized singing positively affects the psychological state of individuals, synchronous occurrence of errors in singing has to be avoided at all costs. An individual must balance self-confidence in her singing compared to a willingness to align with her neighbors. This trade-off is itself nonlinear and dynamic, changing throughout the course of a performance (and it is found in many other dynamic systems, such as ecosystems).38
The power of knowledge songs to encode and preserve information, to engage even young children in their recollection and transmission, points to an ancient evolutionary basis for them. Viewed from a larger context, knowledge songs can be seen as a special instance of art, and in particular, of the kind of art that seeks to inform. Art and science are seen by many as inhabiting opposite ends of a continuum, a line that runs from abstraction to specificity, or from romance to logic. I’ve spent my life in pursuit of knowledge in both domains, and surrounded by people who have pursued either or both. Many musicians I’ve known pursue their music in the kind of systematic, deliberate, studious fashion that could only be described as scientific: Frank Zappa, Sting, Michael Brook, and David Byrne for example. Others pursue it more intuitively, including Carlos Santana, Jerry Garcia, Billy Pierce, and Neil Young. This is not to say that the latter four haven’t worked at it, but their approach to the work strikes me as based more on feeling than on any sort of system. Bill Evans, my favorite pianist, sums up the latter approach:
“Words are the children of reason and, therefore, can’t explain it [music].39 They really can’t translate feeling because they’re not part of it. That’s why it bugs me when people try to analyze jazz as an intellectual theorem. It’s not. It’s feeling.”
I’ve come to see art and science as occupying two ends of a continuum that wraps around on itself like a circle, so that the two meet at a common point. Both art and science involve perspective-taking, representation, and rearrangement—the three foundational ingredients of the musical brain. When these three are combined, we get meta phor (letting one object or concept stand for another) and abstraction (letting a hierarchically larger concept stand for subordinate elements). Both art and science rely on meta phor and abstraction because they take sensory, sensual, and perceptual observations and distill them to an essence. In both, we can get more meaning out of a single piece of information than if that information were delivered in its raw, literal form. Art and science are about extracting and abstracting world knowledge in a form that makes it more readily understandable and memorable—what they share is a sense of overview and unifying themes, decisions about which facts-of-the-world are relevant and which are not. Art and science are not able to represent everything; instead they entail (require) difficult choices about what is the most important.
Science is a not the simple reporting of facts—that’s only the preliminary step in any scientific investigation. Real science, the kind that offers a parsimonious and predictive understanding of how the world works, involves taking those facts and generalizing global principles from them; abstraction is required for this, as is creativity, rationality, intuition, and a sensitivity to form, similar to what is required in the creation of long-lasting art. It may be self-evident that music requires these things, less so perhaps that you can’t have science without the musical brain.
A single painting of a sunset tells us how the sunset felt to the artist and can convey those feelings forever. A mathematical model of the movement of the solar system (including the material constitution of the sun, and local environmental conditions) allows us to predict whether a given sunset will be spectacular, run-of-the-mill, or completely obscured by clouds. Both can inform our behavior and serve our memories, both grab us at the nexus of feeling and thought, emotion and interpretation, brain and heart.
Knowledge is emotion. Some people say that science just is, that it is merely a collection of facts and measurements that exist outside of the realm of emotion and caring. But I disagree. Of the millions (perhaps infinity) of possible facts about the world we memorize, document, and pass on to others, we select those that we think are important, and this is an emotional judgment. We are motivated to care about some and not others, and as we saw earlier, emotion and motivation are two sides of the same neurochemical coin. It is true that the mere fact that 2 + 2 = 4, or that hydrogen is the lightest element we know of, is without emotional content. But the fact that we know these things, have gone to the trouble to learn them, reflects interests, priorities, motivation—in short, reflects emotion. Scientists are motivated by intense curiosity and a desire to interpret and represent reality in terms of higher truths—to take collections of observations and formulate them into a coherent whole that we call a theory. Of course artists do the same thing, taking their observations and trying to formulate them into a coherent whole that we call the painting, the symphony, the song, the sculpture, the ballet, and so on. Knowledge songs are perhaps the crowning triumph of art, science, culture, and mind, encoding important life lessons in an artistic form that is ideally adapted to the structure and function of the human brain. We need to know. And we need to sing about it.
Science, like nature,
Must also be tamed
With a view towards its preservation.
Given the same
State of integrity,
It will surely serve us well.
Art as expression,
Not as market campaigns
Will still capture our imaginations.
Given the same
State of integrity,
It will surely help us along.
The most endangered species,
The honest man,
Will still survive annihilation.
Forming a world
State of integrity,
Sensitive, open and strong.
(From “Natural Science” by Rush)
I’ve been dropping the new science and kicking the new knowledge
An M.C. to a degree that you can’t get in college
…
It’s the sound of science
(From “Sounds of Science” by the Beastie Boys)
Thanks for the ride. Big Science. Hallelujah.
Big Science. Yodelay-hee-hoo.
(From “Big Science” by Laurie Anderson)